TDengine 落地协鑫能科,数百亿数据压缩至 600GB
作者 | 温金雄、彭涛、周玉峰
小 T 导读:为了解决广大新能源汽车车主面临的充电效率问题,协鑫能科打造了以换电为核心业务的移动能源品牌「协鑫电港」,需要对各种数据流进行科学管理、合理运用与智能调度,在数据库的选择上尤为重要。本文分享了他们对于数据库架构的搭建思考以及 TDengine 的应用心得。
企业简介
协鑫能源科技股份有限公司(证券简称:协鑫能科 002015.SZ) 系协鑫(集团)控股有限公司旗下企业,主营业务为清洁能源运营、移动能源运营以及综合能源服务。公司倾力打造从清洁能源生产、补能服务到储能的便捷、经济、绿色的出行生态圈,为电动化出行提供一体化能源解决方案,致力于成为领先的移动数字能源科技运营商。
1、业务痛点
随着新能源汽车的广泛普及,补能的效率问题逐渐成为了广大车主面临的痛点难题。为了解决此难题,作为一家头部的新能源公司,协鑫能科创新突破,切入能源服务领域,打造了以换电为核心业务的移动能源解决方案品牌「协鑫电港」。
由于这是一个在全新领域中打造的全新项目,想要获得成功,需要对各种数据流进行科学管理、合理运用与智能调度,所以针对该场景,我们一开始便把量级最大的物联网数据处理方案锁定在了时序数据库(Time Series Database)上,重点对比了 InfluxDB、OpenTSDB 以及 TDengine。
最终,TDengine 以其独特而科学的设计和优秀的测试表现成为我们选中的时序数据处理引擎,承担了用户车辆数据、电池设备数据以及换电港工作设备等的海量数据存储分析任务,为我们解决了该项目上难度最大的一个环节。最终,我们决定使用 TDengine 2.4.0.10 版本,并在电信的天翼云上落地了该项目。
2、架构与搭建
从流量削峰以及数据安全的角度出发,我们会先通过使用某 MQTT 消息服务器把这些不同种类的设备数据先统一转发给到 Kafka。其中不同类型的数据,将会分别上传到不同的 Kafka topic,最后再通过 Java 连接器把数据写入 TDengine。具体架构如下图所示:

在整体架构上,除了 TDengine,也有一些其它数据库共同支持系统服务,其中 MySQL 负责存储订单、流水等需要精细查询的关系型数据,但由于 MySQL 可以承受的数据量比较有限,为了做一些大表的连接查询,因此我们也接入了 TiDB,负责分析报表类数据的存储。
目前接入 TDengine 最主要的入库数据是车辆传感器(如:车辆里程、经纬度等)以及换电站电池相关的传感器(电池的各种指标)数据。当前共有 55 张超级表,子表数量达到 11 万张。
我们当前在 TDengine、TiDB、MySQL 中存储的数据量比例大概为 6:3:1,仅仅使用了三台 4C+16G 的服务器,TDengine 便挑起了整个系统数据存储的大头,轻松支撑起了我们的服务。在数据库的选择上,我们一直认为不同数据库之间术业有专攻,不得不承认,TDengine 在存储引擎上的独特设计,在降低成本方面的效果十分显著。

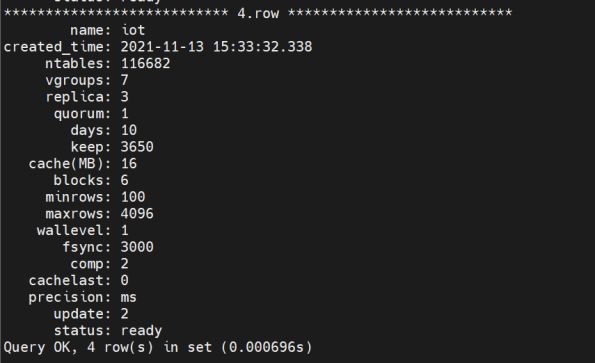
对于 TDengine,我们一开始使用的是单节点,在稳定运营了几个月后,于今年 3 月完成了动态扩容,发展到了 3 节点集群模式,把数据库也升级到了三副本(从图中可以看出来)。
TDengine 的动态扩展非常方便,只要确保一些必要的参数保持一致,就可以直接通过 “create dnode”把新的计算资源加进来。加入后,再通过 “alter database iot replica 3” 这个命令,即可直接在线令数据库变为 3 副本,从而实现数据的备份及高可用。

3、效果分析
当前,我们在 TDengine 中一共存储了数百亿级别的数据量(由于表结构各异,不方便统计,不在本篇文章中展示),存储空间大概占用 600GB 左右(200GB*3),CPU 日常使用为 15% 左右,内存使用在 20% 左右。

在查询方面,在此列举一些我们常用的 SQL,TDengine 的响应速度都很快,完全可以满足我们的需求:
select max(pmk)-min(pmk) from aodong_109 where sid='P42100001' and sd=0 and ts>'2021-12-01 00:00:00'
select last(sv),last(st) from aodong_112 where bn='001PB0GM000002B3L0300067';

4、关于 TDengine 的一些思考
由于我们业务是 24*7 不间断运转 ,所以没有时间做版本升级。我们首先计划抽出时间把 TDengine 版本升级到比较新的版本,再做一些碎片重组压缩的工作来加强查询效率。此外,我们还计划使用 Flink 从 TDengine 中读取数据做流式计算(看到了官方发布了 Flink 适配 TDengine 的文章)。
随着业务快速增长,TDengine 集群存储的数据量也会越来越大,而数据又需要长期保留,大数据量的运维对于 TDengine 来说将是一个巨大的挑战。伴随数据量级的增长,备份、迁移、库、表的运维都会受到影响,也有可能遇到我们之前没有经历过的问题,这就需要 TDengine 集群实现升级、扩展、拆分、维护等运维操作。未来我们希望能积累更多的经验分享给社区,让更多的人了解 TDengine。
对于 TDengine 未来的发展,我们也有自己的期待:
- 希望能增加动态修改参数功能,减少停机维护次数。
- 实现类似慢 SQL 日志功能,降低高负载、调优事后分析定位、回溯故障原因。
- 进一步权衡 udp 带来的好处和导致的各种问题。我们经常连接报错 Ref is not there ,目前来看在客户端添加 rpcForceTcp 1 应该是有效的。
- 增强报错信息可读性,很多报错提示不够明确,无法快速判断出具体原因。
总而言之,希望 TDengine 后面越来越好,也希望我们的合作能更上一层楼。
想了解更多 TDengine Database的具体细节,欢迎大家在GitHub上查看相关源代码。