如果我要用Python做数据分析之上手篇
开头先BB两句
开始上手之前,先来啰嗦两句,都是一些大家都知道的废话 balabala
Python 数据分析是使用 Python 编程语言进行数据处理、探索、分析和可视化的过程。
Python 作为一种高级编程语言,拥有丰富的数据处理和分析库:
如 Pandas、NumPy、Matplotlib、Seaborn、Scikit-learn 等。
这使得 Python 成为了数据科学和数据分析领域中的一种重要工具。
Python 数据分析在未来的发展前景非常广阔。随着大数据时代的到来,数据的规模和复杂性不断增加,对数据分析的需求也越来越高。
Python 作为一种灵活、简洁、易用的编程语言,具有丰富的数据处理和分析库,使得其在数据科学和数据分析领域中具有竞争优势。
同时,随着人工智能、机器学习、深度学习等技术的快速发展,Python 数据分析在这些领域中也扮演着重要角色,因为这些技术通常需要对大量的数据进行预处理、特征提取、模型训练和结果分析等操作,而Python在这些方面具有丰富的库和工具支持。
此外,Python 数据分析在各个行业和领域都有广泛的应用,包括金融、医疗、电商、社交媒体、能源、交通等,通过对各自领域的数据进行分析,可以提供深入的业务洞察和决策支持,从而推动相应领域的发展和创新。
总的来说,Python 数据分析在当今信息化时代具有重要的意义和影响,为企业、组织和科学研究等提供了强大的数据处理和分析工具,助力决策、优化业务、推动创新,同时也在未来的发展前景非常广阔,将继续在各个领域中发挥着重要作用。
最简单的数据分析
那么,由浅入深,先从最简单的数据分析开始,举例说明:
假设有一个包含学生成绩的 CSV 文件(scores.csv)
包含学生的姓名、科目和成绩信息。
使用 Python 的 Pandas 库进行数据处理和分析
scores.csv文件
姓名,科目,成绩张三,数学,80张三,英语,90李四,数学,85李四,英语,92王五,数学,78王五,英语,88
统计每个学生的平均成绩
import pandas as pd# 读取CSV文件df = pd.read_csv('scores.csv')# 按姓名分组,计算平均成绩df_grouped = df.groupby('姓名').mean()# 打印结果print(df_grouped)
输出结果:
成绩姓名 张三 85.0李四 88.5王五 83.0
以上代码使用 Pandas 的 read_csv 方法读取 CSV 文件,并使用 groupby 方法按照姓名进行分组,然后使用 mean 方法计算每个学生的平均成绩。最后,通过打印结果可以得到每个学生的平均成绩信息。
小总结
这个例子中使用了Pandas库来读取CSV文件,并对成绩数据进行了简单的处理,计算了每个人的平均成绩。除了计算平均成绩,Pandas还提供了丰富的数据操作和分析功能,例如:
- 数据筛选与过滤:可以使用Pandas提供的条件筛选、逻辑运算等功能,对数据进行过滤、查询和筛选,以满足特定需求。
- 数据排序与排名:可以使用Pandas提供的排序和排名功能,对数据进行排序和排名操作,以便进行数据分析和展示。
- 数据聚合与统计:可以使用Pandas提供的聚合和统计函数,例如sum、mean、median、min、max等,对数据进行统计分析,以便获取更多的洞察和结论。
- 数据转换与处理:可以使用Pandas提供的数据转换和处理功能,例如数据类型转换、缺失值处理、字符串处理、数据合并、数据拆分等,以便进行数据清洗和预处理。
- 数据可视化:可以使用Pandas结合其他可视化库(例如Matplotlib、Seaborn等),对数据进行可视化分析,生成图表、图形和图像,以便更好地理解数据。
- 数据统计分析:可以使用Pandas进行数据统计分析,例如描述性统计、假设检验、回归分析、时间序列分析等,以便深入挖掘数据背后的信息和趋势。
- 数据合并与连接:可以使用Pandas提供的合并和连接功能,对多个数据表进行合并和连接操作,以便进行数据整合和关联分析。
总的来说,Pandas提供了丰富的数据处理、分析和展示功能,可以在数据分析中广泛应用,从而帮助数据分析人员更加高效地处理和分析数据,得出有价值的结论。
第二个栗子
再写一个
“data.csv” 是一个示例的CSV格式数据文件。
包含了学生的成绩信息,具体的数据格式可能类似如下:
姓名,性别,年龄,语文成绩,数学成绩,英语成绩张三,男,18,80,85,90李四,男,19,85,88,92王五,女,18,90,92,88赵六,女,19,92,87,95
数据读取与展示:
import pandas as pd# 读取CSV文件df = pd.read_csv('data.csv')# 查看前5行数据print(df.head())# 查看数据的基本统计信息print(df.describe())# 查看数据的列名print(df.columns)# 查看数据的形状print(df.shape)
数据筛选与过滤:
# 筛选出数学成绩大于80的学生math_above_80 = df[df['数学成绩'] > 80]# 筛选出语文成绩大于等于90且数学成绩大于等于90的学生chinese_math_above_90 = df[(df['语文成绩'] >= 90) & (df['数学成绩'] >= 90)]
数据聚合与统计:
# 计算每个学生的平均成绩df['平均成绩'] = df.mean(axis=1)# 按性别分组,计算每个性别学生的平均数学成绩和语文成绩df_grouped = df.groupby('性别').agg({'数学成绩': 'mean', '语文成绩': 'mean'})
数据转换与处理:
# 将数学成绩从百分制转换为0-10分制df['数学成绩_0_10'] = df['数学成绩'] / 10# 填充缺失值df.fillna(0, inplace=True)# 将姓名列拆分为姓和名两列df[['姓', '名']] = df['姓名'].str.split(' ', expand=True)
数据可视化:
# 数据可视化:import matplotlib.pyplot as pltfrom matplotlib.font_manager import FontPropertiesfont_set = FontProperties(fname='ttf/msyh/msyh.ttf', size=15)# 设置中文字体# 绘制柱状图,显示每个学科的平均成绩bar = df_grouped.plot(kind='bar')# 设置x轴标签plt.xticks(range(len(df_grouped.index)), df_grouped.index,fontproperties=font_set)plt.legend(loc="upper left",prop=font_set)plt.title('平均成绩',fontproperties=font_set)plt.xlabel('学科',fontproperties=font_set)plt.ylabel('平均成绩',fontproperties=font_set)plt.show()
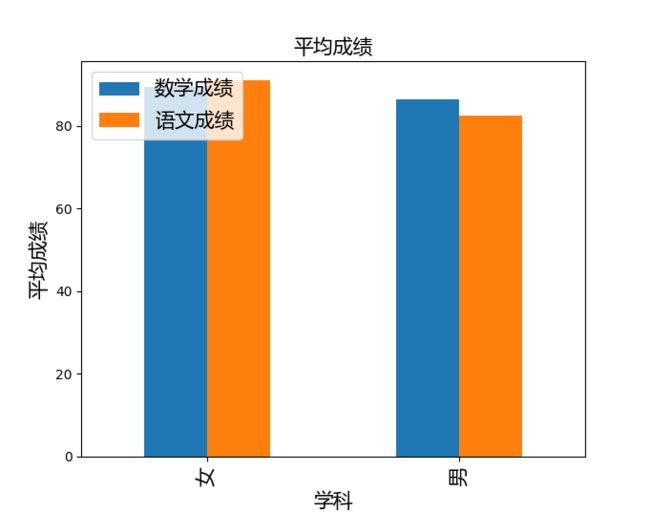
以上代码示例展示了Pandas在数据分析中的一些常见用法,具体的数据分析场景和需求会根据实际情况有所不同,可以根据实际数据和分析目标,选择合适的Pandas功能进行数据处理、分析和展示。
数据可视化,中文无法显示的问题,解决方案:
设置x轴标签、图例、标题和轴标签的字体属性为font_set,其中font_set是一个FontProperties对象,指定了使用的中文字体和字体大小。
from matplotlib.font_manager import FontPropertiesfont_set = FontProperties(fname='ttf/msyh/msyh.ttf', size=15)
具体解释如下:
plt.xticks(range(len(df_grouped.index)), df_grouped.index,fontproperties=font_set):- 这行代码用于设置x轴标签的属性。
range(len(df_grouped.index))- 生成了一个包含从0到学科数量的整数序列,作为x轴的刻度位置;
df_grouped.index作为刻度标签;fontproperties=font_set设置刻度标签的字体属性为font_set,即使用指定的中文字体和字体大小。plt.legend(loc="upper left",prop=font_set):- 这行代码用于设置图例的属性。
loc="upper left"- 指定图例位置为左上角;
- `prop=font_set
- 设置图例的字体属性为
font_set,即使用指定的中文字体和字体大小。 plt.title('平均成绩',fontproperties=font_set):- 这行代码用于设置图表的标题属性。
'平均成绩'是图表的标题;fontproperties=font_set- 设置标题的字体属性为
font_set,即使用指定的中文字体和字体大小。 plt.xlabel('学科',fontproperties=font_set):- 这行代码用于设置x轴标签的属性。
'学科'是x轴的标签; fontproperties=font_set- 设置x轴标签的字体属性为
font_set,即使用指定的中文字体和字体大小。 plt.ylabel('平均成绩',fontproperties=font_set):- 这行代码用于设置y轴标签的属性。
'平均成绩'是y轴的标签; fontproperties=font_set- 设置y轴标签的字体属性为
font_set,即使用指定的中文字体和字体大小。
通过这些设置,可以确保在绘制柱状图时,x轴标签、图例、标题和轴标签的字体都能正确显示为指定的中文字体和字体大小。
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
如果需要可以点击链接免费领取或者滑到最后扫描二v码
[CSDN大礼包:《python学习路线&全套学习资料》免费分享](安全链接,放心点击)
Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
Python实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
Python面试刷题

Python副业兼职路线

这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以点击链接免费领取或者扫描二v码免费领取【保证100%免费】
[CSDN大礼包:《python学习路线&全套学习资料》免费分享](安全链接,放心点击)
