boost_archive
boost_archive
-
- 0.引言
- 1.demo
- 2.Result
- 3.序列化自定义类型
- 4.save和load分离
0.引言
用了都说好:D
-
Serialization Tutorial
-
畅游C++ Boost Serialization 序列化
-
C++ Boost 序列化
-
使用Boost的Serialization库序列化STL标准容器
1.demo
ArchiveTest.cpp
#include CMakeList.txt
cmake_minimum_required(VERSION 3.0)
project(archive)
SET(CMAKE_BUILD_TYPE "Release")
# SET(CMAKE_CXX_FLAGS_DEBUG "$ENV{CXXFLAGS} -O0 -Wall -g2 -ggdb")
# SET(CMAKE_CXX_FLAGS_RELEASE "$ENV{CXXFLAGS} -O3 -Wall")
# add_compile_options(-g)
find_package(Boost REQUIRED COMPONENTS
regex
graph
chrono
thread
system
filesystem
serialization)
if (Boost_FOUND)
message(STATUS "find Boost:\"${Boost_INCLUDE_DIRS}\"")
message(STATUS "find Boost:\"${Boost_LIBRARIES}\"")
include_directories(${Boost_INCLUDE_DIRS})
add_definitions(-DENABLE_BOOST)
list(APPEND LINK_LIB_LIST ${Boost_LIBRARIES})
endif (Boost_FOUND)
include_directories(
${PROJECT_SOURCE_DIR}
${Boost_INCLUDE_DIRS}
)
add_executable(archive
ArchiveTest.cpp
)
target_link_libraries(archive
${Boost_LIBRARIES}
)
2.Result
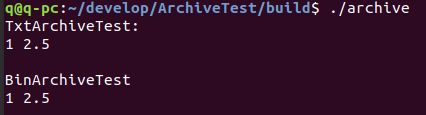

序列化一个标准类型,需要使用boost自带的头文件,在Serialization中,比如要序列化一个STL容器,要使用boost自带的头文件,不能直接#include 。类似的头文件还有vector.hpp string.hpp set.hpp map.hpp slist.hpp等等。
//STL容器
#include 3.序列化自定义类型
如果是自己定义的类别该怎么办呢?在最简单的状况下,只需要撰写一个名为serialize()的成员函数。
- 所谓“非侵入”即serialize方法不必写在类中、不属于类
- “侵入式”,就是将serialize()函数定义在目标类里面
侵入式序列化:
class CURL
{
public:
std::string sHost;
unsigned int sPort;
std::string sPath;
public:
template<class Archive>
void serialize(Archive& ar, const unsigned int version)
{
ar& sHost;
ar& sPort;
ar& sPath;
}
};
非侵入式序列化
class CURL
{
public:
std::string sHost;
unsigned int sPort;
std::string sPath;
};
// 改写成在 boost::serialization 这个 namespace 下的全域函数
namespace boost {
namespace serialization {
template<class Archive>
void serialize(Archive& ar, CURL& rURL, const unsigned int version)
{
// 如果类Archive 是一个输出存档,则操作符& 被定义为<<.
// 如果类Archive 是一个输入存档,则操作符& 被定义为>>.
ar& rURL.sHost;
ar& rURL.sPort;
ar& rURL.sPath;
}
}
}
另外,他还有一个参数是 version,这是用来纪录数据版本用的;可以根据不同的版本、进行跨版本的存储控制。不过这部分算是比较进阶的东西,暂时用不上。
4.save和load分离
将储存和读取分开处理。根据 Boost serialization 的设计下,主要是透过 serialize() 这样的单一函式,来解决输入、输出的功能,并避免可能的两个方向不一致的可能性。但是,有的时候,我们可能还是会需要输入、输出两边是不一样的状况。
例如,有的函式库的类别其实会把成员资料都设定成 private 或 proteced、仅能透过成员函式做存取,以保护资料。
比如说,可能会像下面的样子:
class CURL
{
protected:
std::string sHost;
unsigned int sPort;
std::string sPath;
public:
std::string getHost() const { return sHost; }
std::string getPath() const { return sPath; }
unsigned int getPort() const { return sPort; }
void setHost(const std::string& val) { sHost = val; }
void setPath(const std::string& val) { sPath = val; }
void setPort(const unsigned int& val) { sPort = val; }
};
这个时候,除非要去直接修改 CURL 这个类别,基本上就没办法靠单一的 serialize() 来同时处理输出和输入。如果遇到这样的情况,Boost serialization 也提供了把 serialize() 拆分成 save() / load() 两个函式的功能,让开发者可以使用。比如说,这边就可以写成:
namespace boost {
namespace serialization {
template<class Archive>
void save(Archive& ar, const CURL& t, unsigned int version)
{
ar& t.getHost();
ar& t.getPort();
ar& t.getPath();
}
template<class Archive>
void load(Archive& ar, CURL& t, unsigned int version)
{
std::string sVal;
unsigned int iVal;
ar& sVal; t.setHost(sVal);
ar& iVal; t.setPort(iVal);
ar& sVal; t.setPath(sVal);
}
}
}
BOOST_SERIALIZATION_SPLIT_FREE(CURL);这边的作法,基本上就是和撰写 serialize() 的方法依样,不过这边把程式分成 save() / load() 两个版本。
最后,则是要再通过 BOOST_SERIALIZATION_SPLIT_FREE() 这个巨集(定义在
而如果是成员函式的 serialize() 要拆分的话,则是要使用 BOOST_SERIALIZATION_SPLIT_MEMBER() 这个巨集(定义在