大规模的I/O流中有效识别大数据并增强时间局部性
一篇热数据识别存储外文翻译,本文主要在讲思想
原文题目:
翻译:大规模的I/O流中有效识别热数据并增强时间局部性
外文网址:http://dsc.jnu.edu.cn/paper/2015/ICA3PPCH.pdf
本文主要讲里面的具体算法及思想
第一作者:陈嘉豪
论文简单摘要:
热数据对于优化现代计算机是非常重要的。热数据识别能增加闪存的寿命,但是对低存储消耗和低运行时间开销是一个挑战,本文提出了“热数据捕获器(HDCat)”,能通过增强时间局限性在大规模I/O流中识别热数据。HDCat包含两条队列,一条热数据队列,一条候选热数据队列。HDCat采用了D位计数器和最近位并且能有效地降低冷热数据的转换。最后使用了实例测试。
论文中几个概念:
热数据:用户访问率很高
时间局部性:如果一个信息项正在被访问,那么近期它可能还会被再次访问
闪存:断电数据不会丢失,像USB
论文背景:
传统的热数据识别算法仅仅记录了当前的数据项,忽视了对应数据集的体积。然而,大多数采用传统方法识别热数据会造成大的存储消耗和高运行时间开销,并且没有考虑时间局部性对热数据识别有很大的影响。为了克服这个问题,Hsieh提出了多哈希函数框架识别热数据。这个算法采用了多哈希函数和一个布尔过滤器去捕获数据访问频率,因此采用了一个计数器去准确捕获访问频率信息。但是算法中存在的指数衰减模式使它很难去获得数据访问的时间局部性。
热数据识别方法在不同场景中有应用,缓存是一种典型的场景。缓存的缺点:不能在已有数据的位置进行更新,受冷热数据转换影响大,减少使用寿命,造成延时,写入次数有限,备份花费高。本文提出了HDCat,主要思想是:
1、根据最近位更新D位计数器,最近访问的数据D位计数器增长更快比最近没有范文的数据
2、过滤机制是基于最低位的,当算法需要去移除数据,一定是D位计数器值最小,并且最近位为0
3、算法能有效解决运行时间消耗和存储问题
实现结果表明:当维持低存储消耗和低运行时间开销时,识别热数据准确性提高。
Hash算法: Hash可以通过散列函数将任意长度的输入变成固定长度的输出,也可以将不同的输入映射成为相同的相同的输出,而且这些输出范围也是可控制的,所以起到了很好的压缩映射和等价映射功能。Hash为什么会有这种 压缩映射和等价映射功能,主要是因为Hash函数在实现上都使用到了取模。常用的Hash函数:
直接取余法:f(x):= x mod maxM ; maxM一般是不太接近 2^t 的一个质数。
・乘法取整法:f(x):=trunc((x/maxX)*maxlongit) mod maxM,主要用于实数。
・平方取中法:f(x):=(x*x div 1000 ) mod 1000000); 平方后取中间的,每位包含信息比较多。
相关工作:
布隆过滤器:目标记录低存储消耗信息
D位计数器:一个布尔值记录有限制,很多情况下不能满足需求。塑性变量花费太多存储空间。
D位计数器是一个D位数组,能记录范围0到(2的D次方-1)。开始值设为0,当相应元素出现时,设置为1,整个值超过(2的D次方-1)时,停止加1。D位计数器中包含B最大位,被叫做临界值。B位后全为0则表示数据没有超出临界值,
热数据识别算法:
TLL:两层LRU算法简称TLL包含一个热数据列表和一个候选热数据列表,长度固定,当一个请求到达时,TLL检查是否有对应的逻辑区块地址(LBA)在热数据列表中
如果有,数据被记录成热数据,否则视为冷数据,如果在候选热数据列表中,数据就变成热数据,如果两个表都没有,插入到候选表中。
优点:有好的空间有效性,仅仅需要记录热数据和候选热数据的访问信息。
缺点:性能依赖于两个表的长度,当表长短时,能减少存储消耗,但它会不适当地降低热点数据到候选列表,从而降低热数据识别准确性,并且会出现高运行时间消耗。
MHF:多hash函数框架简称MHF,采用了多hash函数和D位计数器。如图1,
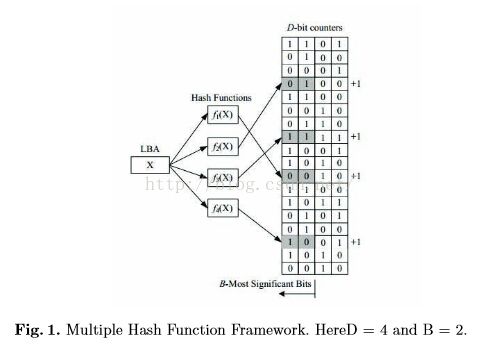
MHF记录数据访问信息通过增加相应的计数器,更新数据访问信息通过定期的使计数器除以2。如果B位后面有1,返回1,否则返回0。MHF采用K个独立的hash函数,如果K个返回值为1,则为热数据。如图1,算法使用4位计数器和2位最大位,那么4就是临界值,在例子中,用4个函数f1,f2,f3,f4标记数据X,得到4个值:0010,0100,1111,1001,其中0100返回0,则判断为冷数据。
优点:实现了低存储消耗和低运行时间开销
缺点:最近访问的信息没有
HotData Catcher:
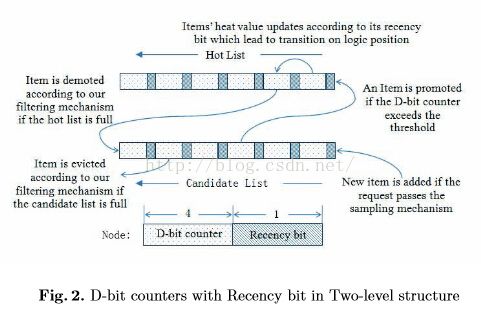
HDCat概述:
如图2所示,HDCat由一个热数据列表和一个候选热数据列表组成,列表中每一项包含一个最近位和一个D位计数器。
初始化设为空,所有数据项为冷数据,当数据到达时,先检查是否在两个列表中,任何列表如果包含改数据项,对应的D位计数器增加。如果数据在候选列表中,并且D位计数器值大于所给临界值,改数据将插入热数据列表。热数据列表为满,利用过滤机制淘汰一项数据到候选列表。如果两个列表都不包括,插入到候选列表,候选列表淘汰一项数据。
HDCat细节:
如果最近位为0,D位计数器增加1,如果为1,则增加2
D位计数器达到最大值后,如果数据再次访问也不会增加
数据项的最近位将被设置为1,其热值将快速成长。HDCat采用了老化机制来处理这个问题,即对D位计数器并不简单地与增加,而是随着时间的推移变少
HDCat流程图:
过滤机制:如果列表满,需要淘汰元素时,最好是找到最近位为0,D位计数器最小的项,但是需要遍历整个列表,造成高运行时间消耗,过滤机制采用,只需找到D位计数器小于临界值,就遍历停止。
老化机制:固定的时间没访问数据D位计数器减半
采样机制:避免冷热数据相互频繁转换,如果数据频繁访问,而候选表中有很长没有访问的,通过采样机制可能就增大了
算法评估
评估环境:相同的衰减间隔和老化机制,三种实迹数据收集从微软的数据中心在块级别使用事件跟踪的核心服务器,时间长度144小时,
每个记录包括时间戳,请求类型,数据地址偏移,数据块大小
硬件监控(hm),测试网站服务器(wdev),研究项目(rsrch)
hm和wdev有非常大的地址空间,rsrch小
实验结果:命中率越高越好,冷热数据转换率越低越好
命中率:终端用户访问加速节点时,如果该节点有缓存住了要被访问的数据时就叫做命中,如果没有的话需要回原服务器取,就是没有命中。取数据的过程与用户访问是同步进行的,所以即使是重新取的新数据,用户也不会感觉到有延时。 命中率=命中数/(命中数+没有命中数), 缓存命中率是判断加速效果好坏的重要因素之一。
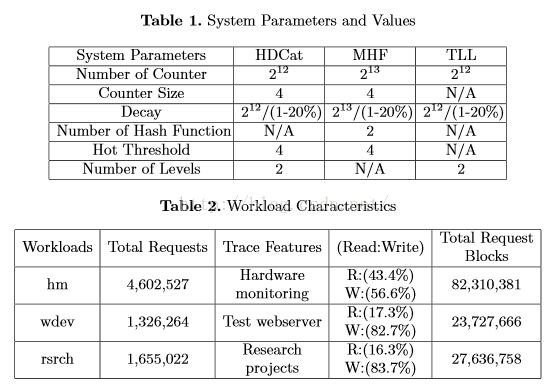
表1和表2,表示相互关系的参数表
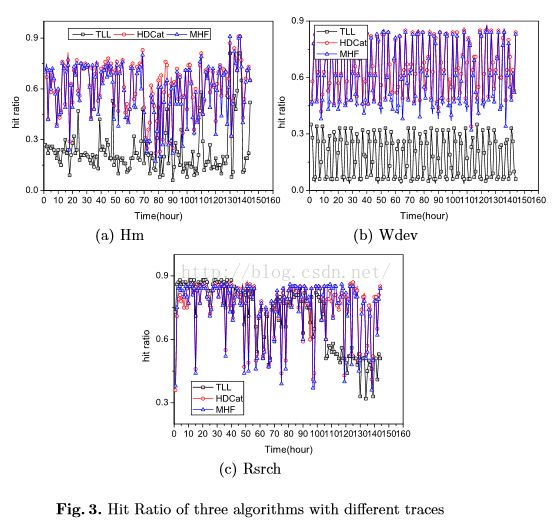
图3表示了命中率的实验结果,图4用柱状图表示:

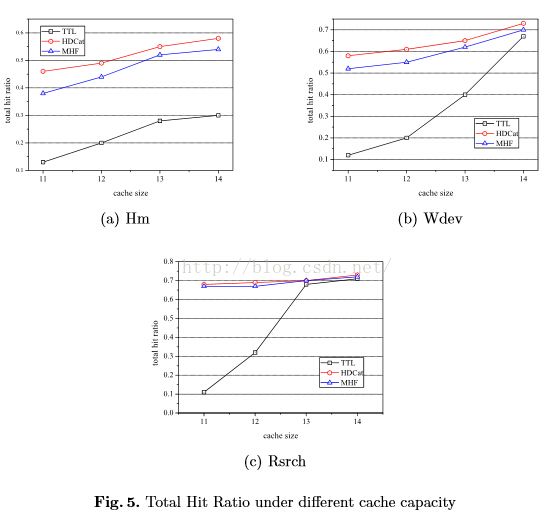
图5总结在不同缓存大小下,总的命中率大小
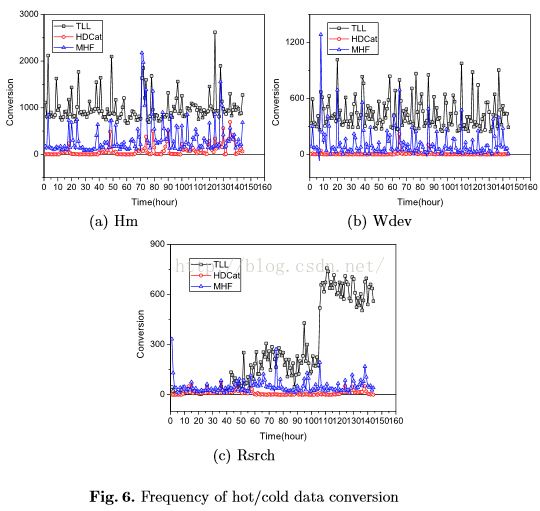
图6表示转换次数,图7为柱状图

总结
本文提出了热数据识别算法(HDCat)利用D-bit计数器和最近位,实迹用于评估,和TTL、MHF作比较,HDCat可以准确地捕捉到数据访问模式的时间局部性,实现了较高的命中率,低缓存存储性和运行时开销。此外,HDCat显著降低了数冷热数据之间的转换,从而降低写入的数操作。因此,HDCat是一个很好的候选方法的优化性能闪速存储器的可靠性。此外,我们认为HDCat可以应用到许多场景以优化的计算机系统。