Python 数据采集-爬取学校官网新闻标题与链接(进阶)
Python 爬虫爬取学校官网新闻标题与链接(进阶)
- 前言
- 一、拼接路径
- 二、存储
- 三、读取翻页数据
- 四、完整代码展示
- 五、小结
前言
⭐ 本文基于学校的课程内容进行总结,所爬取的数据均为学习使用,请勿用于其他用途
- 准备工作:
- 爬取地址:https://www.hist.edu.cn/index/sy/kyyw.htm
- 爬取目的:爬取全部新闻的标题与链接(绝对路径)并存储
- 了解前导文章 Python 数据采集-爬取学校官网新闻标题与链接(基础)
- 环境需求:安装扩展库 BeautifulSoup、urllib(⭐不会安装点这里 Python 下载安装第三方库)
- 基本知识:
- 了解网页的基本知识
- 掌握 python 基础语法
- 掌握 python 文件写入的语法
一、拼接路径
上一篇文章中,我们获得的网页链接是网页的相对路径,不是可以即时使用的链接,如下所示:

而我们常见的链接都是形如以下:
https://blog.csdn.net/Pola_/article/details/121316947?spm=1001.2014.3001.5501
这种链接都是可以即时使用的链接,那么能不能把上面的链接也换成可以即时使用的形式呢?我们需要用到 urllib 库的 urljoin() 去拼接地址,urljoin() 的第一个参数是基础母站的 url, 第二个是需要拼接成绝对路径的 url,利用 urljoin,我们可以将之前爬取到的 url 的相对路径拼接成绝对路径。
首先我们需要知道之前爬取到的 url 的基础母站是谁?很简单,将新闻的链接与我们爬取到的链接对比一下就可以知道基础母站,如下所示,基础母站即为 https:www.hist.edu.cn/:
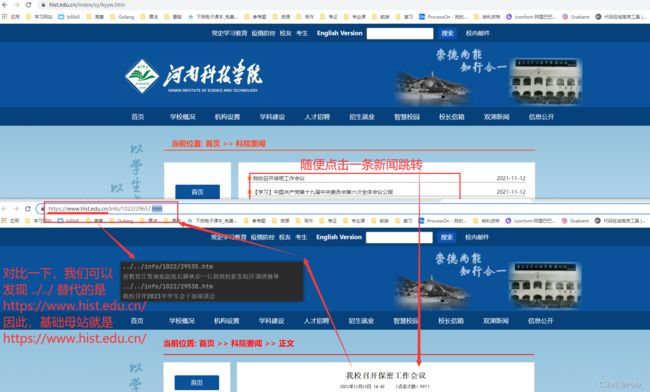
其次是知道需要拼接成绝对路径的 url,也就是我们之前爬取到的 url
两个参数具备之后,我们就可以使用 urljoin() 进行拼接路径了,具体如下:
import urllib.request
from urllib.parse import urljoin
from bs4 import BeautifulSoup
# 读取给定 url 的 html 代码
response = urllib.request.urlopen('https://www.hist.edu.cn/index/sy/kyyw.htm')
content = response.read().decode('utf-8')
# 转换读取到的 html 文档
soup = BeautifulSoup(content, 'html.parser', from_encoding='utf-8')
# 获取转换后的 html 文档里属性 class=list-main-warp 的 div 标签的内容
divs = soup.find_all('div', {'class': "list-main-warp"})
# 从已获取的 div 标签的内容里获取 li 标签的内容
lis = divs[0].find_all('li')
# 遍历获取到的 lis 列表,并从中抓取链接和标题
for li in lis:
url1 = "https://www.hist.edu.cn/" # 基础母站
# 需要拼接成绝对路径的 url,也就是我们之前爬取到的 url(相对路径形式)
url2 = li.find_all('a')[0].get("href")
# 使用 urllib 的 urljoin() 拼接两个地址
# urljoin 的第一个参数是基础母站的 url, 第二个是需要拼接成绝对路径的 url
# 利用 urljoin,我们可以将爬取的 url 的相对路径拼接成绝对路径
url = urljoin(url1, url2)
# 我们爬取到的新闻标题
title = li.find_all('a')[0].get("title")
# 打印拼接的路径和对应的新闻标题
print(url)
print(title)
输出结果如下(只截取部分):

可以看到,我们之前爬取的链接的相对路径已经通过 urljoin() 与基础母站拼接成绝对路径,此时的链接就可以即时使用了
二、存储
前面我们已经获取了新闻的链接与标题,接下来我们希望可以将爬取到的数据存储下来,例如,将每条新闻的链接与对应的标题以逗号分隔存入 txt 文件中,txt 文件命名为 urlList.txt。
已经熟悉 Python 文件操作的同学肯定会说一句 “这波操作我熟悉”,确实,完成我们想要的功能只需要掌握文件写入的知识即可
难度不大,我就直接放代码了,注释也比较详细,有问题可以在评论里提出
import urllib.request
from urllib.parse import urljoin
from bs4 import BeautifulSoup
# 读取给定 url 的 html 代码
response = urllib.request.urlopen('https://www.hist.edu.cn/index/sy/kyyw.htm')
content = response.read().decode('utf-8')
# 转换读取到的 html 文档
soup = BeautifulSoup(content, 'html.parser', from_encoding='utf-8')
# 获取转换后的 html 文档里属性 class=list-main-warp 的 div 标签的内容
divs = soup.find_all('div', {'class': "list-main-warp"})
# 从已获取的 div 标签的内容里获取 li 标签的内容
lis = divs[0].find_all('li')
# 向 urlList.txt 文件写入内容
with open('urlList.txt', 'w', encoding='utf8') as fp:
# 遍历获取到的 lis 列表,并从中抓取链接和标题
for li in lis:
url1 = "https://www.hist.edu.cn/"
url2 = li.find_all('a')[0].get("href")
# 使用urllib的urljoin()拼接两个地址
# urljoin的第一个参数是基础母站的url, 第二个是需要拼接成绝对路径的url
# 利用urljoin,我们可以将爬取的url的相对路径拼接成绝对路径
url = urljoin(url1, url2)
title = li.find_all('a')[0].get("title")
# 写入新闻链接和标题,并以逗号分隔
fp.write(url + "," + title + '\n')
三、读取翻页数据
根据我们爬到的数据可以发现,我们目前只能爬到当前一页的数据,但是学校新闻不止一页,我们想要爬取第二页、第三页、…等所有页的数据并存储下来,如何实现呢?很明显,我们可以爬到一页的数据,但是无法爬取下一页的数据,是因为我们无法实现爬虫的翻页,如果我们可以实现翻页,那么下一页就可以当作当前页,而爬取当前页的数据我们已经做到,所以当前的问题是解决如何翻页。
我们所做的爬虫就是在模拟浏览器去获取数据,而翻页行为是我们人为手动的去点击下一页,然后浏览器跳转到下一页,因此我们需要让爬虫去模拟我们人为手动的点击下一页这一个行为,去让浏览器可以实现跳转到下一页,然后一直点击下一页直到最后一页,这样就能翻取所有页。
接下来我们调试网页,观察我们点击下一页按钮后,浏览器是如何实现跳转到下一页,如下:
观察下图可知:
- 下页按钮其实是一个下一页的链接
- 这个链接并不全,只是一部分,真的去点击的话也不会跳转到下一页的,结合之前解决相对路径的思路,我们可以使用 urljoin() 去拼接路径
- 下页链接的末尾是 410.htm,而尾页链接的末尾是1.htm,结合网页基础如识可知,这个数字就是每一页的页码,如果我们想一直翻页直到最后一页的话,我们可以利用这个数字去做循环结束的判断条件

然后我们点击下页,跳转到下一页继续观察(爬虫的过程就是我们要多观察不同之处,从而将这些不同之处作为我们代码实现的条件),如下:
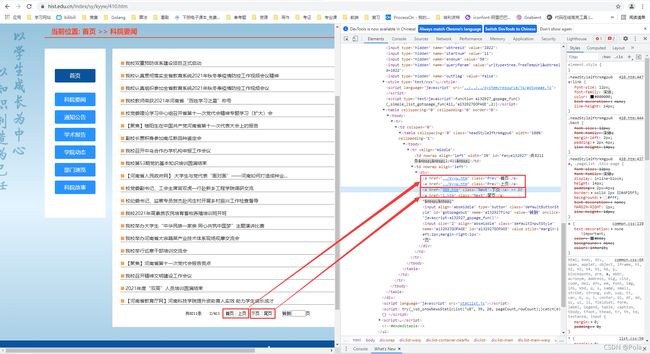
观察可以发现:
- 跳转到下一页后,网站有了首页和上页,因此下页和尾页的链接之前多了首页和上页的链接,这样一来,我们想要获取下页和尾页的链接时就需要对链接进行判断,找出下页和尾页的链接,细心一点,这个判断条件很明显,就是链接的class属性, 下页和尾页的链接的 class 属性为 class=“Next”,而首页和上页的链接的 class 属性为 class=“Prev”,因此我们可以把 tag 属性为 class=“Next” 的 a 标签作为筛选下页和尾页的链接的条件
- 此外,我们还可以发现这时候下页和尾页的链接开头相较于上图中看到的下页和尾页的链接少了 kyyw/,只剩下单独的页码了,而之后几页调试发现链接开头都少了 kyyw/,因此我们在拼接路径的时候还需要注意从新闻第一页跳转下一页时,拼接路径的基础母站为 https://www.hist.edu.cn/index/sy/,而从新闻第二页以及之后的页跳转下一页时,拼接路径的基础母站为c,我们要把缺少的 kyyw/ 给手动补上。因为只有新闻第一页跳转下一页时链接开头没有缺少 kyyw/,而之后的页全部缺少,因此我们在代码中可以这样判断:
- 当第一次跳转下一页时,选择拼接路径的基础母站为 https://www.hist.edu.cn/index/sy/
- 当第二次及之后跳转下一页时,选择拼接路径的基础母站为 https://www.hist.edu.cn/index/sy/kyyw/
根据以上调试网页的观察,我们想要爬虫实现翻页的一个思路就是:
① 从获取的第一页的网页 html 代码里筛选 tag 属性为 class=“Next” 的 a 标签,然后获取其中的下页和尾页的 href 链接
② 使用 while 循环来实现翻页,循环结束的条件是下页的 herf 链接等于尾页的 herf 链接,循环体内,
爬取当前页的新闻标题与链接,然后判断循环是否是第一次,根据判断结果确定拼接的基础母站路径,之后根据我们拼接好的路径,实现跳转到下一页,周而复始,直到循环结束,我们就可以获取到所有页的新闻标题与链接
代码实现如下:
import urllib.request
from urllib.parse import urljoin
from bs4 import BeautifulSoup
# 读取URL的HTML代码,输入 URL,输出 html
response = urllib.request.urlopen('https://www.hist.edu.cn/index/sy/kyyw.htm')
# print(response.read().decode('utf-8'))
content = response.read().decode('utf-8')
# 解析
soup = BeautifulSoup(content, 'html.parser', from_encoding='utf-8')
Pages = soup.find_all('a', {'class': "Next"})
endPage = Pages[1].get("href")
# print(endPage)
# 用来判断第一次的基础母站路径
i = 1
while Pages[0].get("href") != Pages[1].get("href"):
# while 循环之外我们已经读取到了首页的新闻内容,直接开始分析
divs = soup.find_all('div', {'class': "list-main-warp"})
lis = divs[0].find_all('li')
# 开始写入
# 需要注意,写入的方式是追加 'a+'
# 因为每读一页都会向文件中写入一次,如果还使用之前的 w 写入方式,
# 就会导致上一页的内容被当前页的内容覆盖,这样最后,文件里就被覆盖的只有最后一页的新闻标题与链接
with open('urlList.txt', 'a+', encoding='utf8') as fp:
for li in lis:
url1 = "https://www.hist.edu.cn/"
url2 = li.find_all('a')[0].get("href")
# 使用urllib的urljoin()拼接两个地址
# urljoin的第一个参数是基础母站的url, 第二个是需要拼接成绝对路径的url
# 利用urljoin,我们可以将爬取的url的相对路径拼接成绝对路径
url = urljoin(url1, url2)
title = li.find_all('a')[0].get("title")
fp.write(url + "," + title + '\n')
# 判断是否是第一次跳转下一页
if i == 1:
# 设置基础母站路径
url1 = "https://www.hist.edu.cn/index/sy/"
i = i+1
else:
# 设置基础母站路径
url1 = "https://www.hist.edu.cn/index/sy/kyyw/"
# 获取下一页链接
url2 = Pages[0].get("href")
# 拼接路径
url = urljoin(url1, url2)
# 用于提示爬到哪一页了
print(url)
# 读取下一页的内容
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
# 解析下一页的内容,同时将soup指向为下一页的内容
soup = BeautifulSoup(content, 'html.parser', from_encoding='utf-8')
Pages = soup.find_all('a', {'class': "Next"})
输出结果如下:

四、完整代码展示
import urllib.request
from urllib.parse import urljoin
from bs4 import BeautifulSoup
# 读取URL的HTML代码,输入 URL,输出 html
response = urllib.request.urlopen('https://www.hist.edu.cn/index/sy/kyyw.htm')
# print(response.read().decode('utf-8'))
content = response.read().decode('utf-8')
# 解析
soup = BeautifulSoup(content, 'html.parser', from_encoding='utf-8')
Pages = soup.find_all('a', {'class': "Next"})
endPage = Pages[1].get("href")
# print(endPage)
# 用来判断第一次的基础母站路径
i = 1
while Pages[0].get("href") != Pages[1].get("href"):
# while 循环之外我们已经读取到了首页的新闻内容,直接开始分析
divs = soup.find_all('div', {'class': "list-main-warp"})
lis = divs[0].find_all('li')
# 开始写入
# 需要注意,写入的方式是追加 'a+'
# 因为每读一页都会向文件中写入一次,如果还使用之前的 w 写入方式,
# 就会导致上一页的内容被当前页的内容覆盖,这样最后,文件里就被覆盖的只有最后一页的新闻标题与链接
with open('urlList.txt', 'a+', encoding='utf8') as fp:
for li in lis:
url1 = "https://www.hist.edu.cn/"
url2 = li.find_all('a')[0].get("href")
# 使用urllib的urljoin()拼接两个地址
# urljoin的第一个参数是基础母站的url, 第二个是需要拼接成绝对路径的url
# 利用urljoin,我们可以将爬取的url的相对路径拼接成绝对路径
url = urljoin(url1, url2)
title = li.find_all('a')[0].get("title")
fp.write(url + "," + title + '\n')
# 判断是否是第一次跳转下一页
if i == 1:
# 设置基础母站路径
url1 = "https://www.hist.edu.cn/index/sy/"
i = i+1
else:
# 设置基础母站路径
url1 = "https://www.hist.edu.cn/index/sy/kyyw/"
# 获取下一页链接
url2 = Pages[0].get("href")
# 拼接路径
url = urljoin(url1, url2)
# 用于提示爬到哪一页了
print(url)
# 读取下一页的内容
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
# 解析下一页的内容,同时将soup指向为下一页的内容
soup = BeautifulSoup(content, 'html.parser', from_encoding='utf-8')
Pages = soup.find_all('a', {'class': "Next"})
五、小结
又要听我说小结了哈哈哈,开头是至此…
至此,我们相较上一篇文章,完成了一些相对来说更加进阶的功能,首先是我们通过 urljoin() 拼接路径,其次是利用 Python 的文件写入将我们爬取的新闻链接与标题存储到 txt 文件当中,最后是我们实现读取翻页数据从而获取所有的新闻链接与标题。我爬取的我们学校的新闻,你也可以试试你的学校,原理都是相通的!
值得一提的是,这两篇文章结束之后,我们就基本可以摸到爬虫是个什么样的东西了,简单入个门,学校新闻网站是静态网页,所有的东西、代码我们都看得见,因此无论是网页调试还是爬取数据都会简单很多,但是还有很多网页是动态网页,里面有些数据我们是看不到的,看不到的话又该怎么爬取呢?如果你感兴趣的话,可以关注 Pola 后续爬取动态网页的文章!
不过在此之前,Pola 会更一篇词频分析的文章,你有没有发现我们只是爬取了新闻标题和链接并存储下来,但其实并没有什么很大的用途?你有没有见过年度关键词、网络热词排榜之类的词云图?我们可以利用已爬取的新闻标题和链接去获取新闻内容,并对所有的新闻内容进行分析,找出其中最高频率被提到的词语,也就是来一次简单的词频分析!根据分析结果你也可以做一个词云图!
写在最后,如果有疑惑不理解的地方或者代码调试有问题的请在文章下方评论,Pola 会和你一起解决!