主从数据库
主从数据库详解
一、什么是主从复制?
主从复制,是用来建立一个和主数据库完全一样的数据库环境,称为从数据库;主数据库一般是准实时的业务数据库。
像在mysql数据库中,支持单项、异步赋值。在赋值过程中,一个服务器充当主服务器,而另外一台服务器充当从服务器。此时主服务器会将更新信息写入到一个特定的二进制文件中。并会维护文件的一个索引用来跟踪日志循环。这个日志可以记录并发送到从服务器的更新中去。
当一台从服务器连接到主服务器时,从服务器会通知主服务器从服务器的日志文件中读取最后一次成功更新的位置。然后从服务器会接收从哪个时刻起发生的任何更新,然后锁住并等到主服务器通知新的更新。
二、主从复制的作用(好处,或者说为什么要做主从)重点!
1、做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。
2、架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。
3、读写分离,使数据库能支撑更大的并发。在报表中尤其重要。由于部分报表sql语句非常的慢,导致锁表,影响前台服务。如果前台使用master,报表使用slave,那么报表sql将不会造成前台锁,保证了前台速度。
(1)在从服务器可以执行查询工作(即我们常说的读功能),降低主服务器压力;(主库写,从库读,降压)
(2)在从主服务器进行备份,避免备份期间影响主服务器服务;(确保数据安全)
(3)当主服务器出现问题时,可以切换到从服务器。(提升性能)
三、主从复制的原理(重中之重,面试必问):
1.数据库有个bin-log二进制文件,记录了所有sql语句。
2.我们的目标就是把主数据库的bin-log文件的sql语句复制过来。
3.让其在从数据的relay-log重做日志文件中再执行一次这些sql语句即可。
4.下面的主从配置就是围绕这个原理配置
5.具体需要三个线程来操作:
- (1)binlog输出线程:每当有从库连接到主库的时候,主库都会创建一个线程然后发送binlog内容到从库。
在从库里,当复制开始的时候,从库就会创建两个线程进行处理:
- (2)从库I/O线程:当START
SLAVE语句在从库开始执行之后,从库创建一个I/O线程,该线程连接到主库并请求主库发送binlog里面的更新记录到从库上。从库I/O线程读取主库的binlog输出线程发送的更新并拷贝这些更新到本地文件,其中包括relaylog文件。 - (3)从库的SQL线程:从库创建一个SQL线程,这个线程读取从库I/O线程写到relay log的更新事件并执行。
可以知道,对于每一个主从复制的连接,都有三个线程。拥有多个从库的主库为每一个连接到主库的从库创建一个binlog输出线程,每一个从库都有它自己的I/O线程和SQL线程。
主从复制如图 帮助理解:

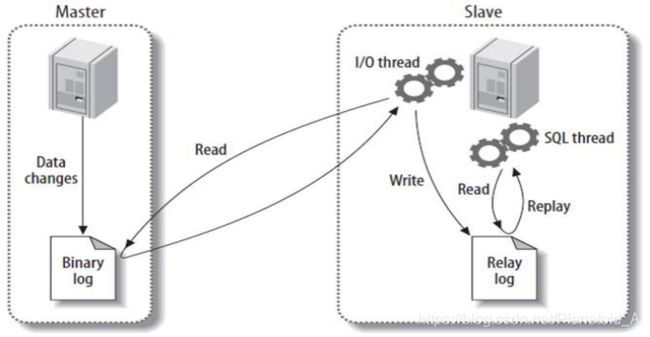

步骤一:主库db的更新事件(update、insert、delete)被写到binlog
步骤二:从库发起连接,连接到主库
步骤三:此时主库创建一个binlog dump thread线程,把binlog的内容发送到从库
步骤四:从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log.
步骤五:还会创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db.
四、主从数据库的优点
① 方便做数据的热备份。
② 架构的扩展更容易。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。
③ 读写分离,使数据库能支撑更大的并发。在报表中尤其重要。
五、 常见的主从形式
1、一从一主
一主一从是最常见的主从架构,实施起来简单并且有效,不仅可以实现HA,而且还能读写分离,进而提升集群的并发能力。
2、一从多主
提高系统的读性能。
3、多主一从
多主一从可以将多个MySQL数据库备份到一台存储性能比较好的服务器上。
4、双主复制
双主复制,也就是互做主从复制,每个Master既是Master,又是另外一台服务器的slave。这样任何一方所做的变更,都会通过复制应用到另外一方的数据库中。
5、级联复制
级联复制模式下,部分slave的数据同步不连接主节点,而是连接从节点。因为如果主节点有太多的从节点,就会损耗一部分性能用于replication,那么可以让3~5个从节点连接主节点,其它从节点作为二级或者三级与从节点连接,这样不仅可以缓解主节点的压力,并且对数据一致性没有负面影响。
六、数据库读写分离
RD:数据量太大,数据库扛不住了,帮忙申请一个从库,读写分离。DBA:数据量多少?RD:5000w左右。DBA:读写吞吐量呢?RD:读QPS约200,写QPS约30左右。额,数据库读写分离虽然不难,但并不是所有的“数据库扛不住”的场景,都应该用读写分离。
1、什么是数据库读写分离?

一个主从同步集群通常称为一个**“分组”**
一主多从,读写分离,主动同步,是一种常见的数据库架构,一般来说:
- 主库,提供数据库写服务
- 从库,提供数据库读服务
- 主从之间,通过某种机制同步数据,例如mysql的binlog
2、分组架构究竟解决什么问题?
大部分互联网业务读多写少,数据库的读往往最先成为性能瓶颈,如果希望:
(1)线性提升数据库读性能
(2)通过消除读写锁冲突提升数据库写性能
此时可以使用分组架构。一句话,分组架构主要解决“数据库读性能瓶颈”问题,在数据库扛不住读的时候,通常读写分离,通过增加从库线性提升系统读性能。
3、为什么不喜欢用 读写分离 架构?
首先需要明确的是:不是任何读性能瓶颈都需要使用读写分离,我们还可以有其他解决方案。在互联网的应用场景中,常常数据量大、并发量高、高可用要求高、一致性要求高,如果使用“读写分离”,就需要注意这些问题:
(1)数据库连接池要进行区分,哪些是读连接池,哪个是写连接池,研发的难度会增加;
(2)为了保证高可用,读连接池要能够实现故障自动转移;
(3)主从的一致性问题需要考虑。
在这么多的问题需要考虑的情况下,如果我们仅仅是为了解决“数据库读的瓶颈问题”,为什么不选择使用缓存呢?
4、为什么用缓存?
缓存,也是互联网中常常使用到的一种架构方式,同“读写分离”不同,读写分离是通过多个读库,分摊了数据库读的压力,而存储则是通过缓存的使用,减少了数据库读的压力。他们没有谁替代谁的说法,但是,如果在缓存的读写分离进行二选一时,还是应该首先考虑缓存。
为什么呢?缓存的使用成本要比从库少非常多;缓存的开发比较容易,大部分的读操作都可以先去缓存,找不到的再渗透到数据库。
当然,如果我们已经运用了缓存,但是读依旧还是瓶颈时,就可以选择“读写分离”架构了。简单来说,我们可以将读写分离看做是缓存都解决不了时的一种解决方案。当然,缓存也不是没有缺点的:对于缓存,我们必须要考虑的就是高可用,不然,如果缓存一旦挂了,所有的流量都同时聚集到了数据库上,那么数据库是肯定会挂掉的。
七、数据库水平切分架构
1、什么是数据库水平切分
对于常见的数据库瓶颈是什么呢?
其实是数据容量的瓶颈。例如订单表,数据量只增不减,历史数据又必须要留存,非常容易成为性能的瓶颈,而要解决这样的数据库瓶颈问题,“读写分离”和缓存往往都不合适,最适合的是什么呢?—— 数据库水平切分。
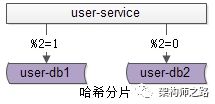
水平切分,也是一种常见的数据库架构,一般来说:
- 每个数据库之间没有数据重合,没有类似binlog同步的关联
- 所有数据并集,组成全部数据
- 会用算法,来完成数据分割,例如“取模”
一个水平切分集群中的每一个数据库,通常称为一个**“分片”**。
2、水平切分架构究竟解决什么问题?
大部分互联网业务数据量很大,单库容量容易成为瓶颈,如果希望:
(1)线性降低单库数据容量
(2)线性提升数据库写性能
此时可以使用水平切分架构。一句话总结,水平切分主要解决“数据库数据量大”问题,在数据库容量扛不住的时候,通常水平切分。
3、总结
(1)读写分离,解决“数据库读性能瓶颈”问题
(2)水平切分,解决“数据库数据量大”问题
(3)对于互联网大数据量,高并发量,高可用要求高,一致性要求高,前端面向用户的业务场景,微服务缓存架构,可能比数据库读写分离架构更合适。