聊点技术|100%降本增效!Bonree ONE 通过 Clickhouse实现了
10月20日,数智融,ONE向新——博睿数据2023秋季产品发布会圆满落幕,全新一代一体化智能可观测平台Bonree ONE 2023秋季正式版焕新发布,重点升级了数据采集、全局拓扑、数据分析、会话回放等多个功能模块,为组织提供了更加轻盈、有序、精准的超智能运维体验。
文章信息
作者|博睿数据数智中心大数据负责人-娄志强;本文已被InfoQ发表。
背景
Bonree ONE 是博睿数据发布的国内首个一体化智能可观测平台。会话数据是 Bonree ONE 平台重要的业务模块,在切换到 Clickhouse 之前是基于 ElasticSearch 进行存储的。ElasticSearch(下文简称 ES)是一种基于 Lucene 的分布式全文搜索引擎,主要使用场景在全文检索方向。
ES存储会话数据的痛点
会话数据的写入量很大,而且涉及一些联动数据,比如基于对象存储的快照数据,查询效率要求在秒级到亚秒级返回,在日志场景,ES存在以下痛点:
· 写入同步慢、写入效率差,业务写入会话数据到ES的同时,相关联的快照数据写入对象存储系统,相对于快照数据的写入时间,ES数据写入返回响应需要等待至少亚秒级的延迟,导致产品上会有查询不到数据的现象,影响体验;
· 数据占用存储多,压缩不好,随着数据量的上涨,成本会越来越高;
· 查询效率低,海量数据近30天经常查不出来;
· 维护成本高,IO资源开销大,尤其私有化混部场景,对部署在同一个机器上的其他组件,影响较大;
基于Clickhouse存储会话
ES存在的诸多问题,使得我们迫切寻找一个新的存储方案来进行升级,解决写入和查询的性能问题以及集群管理。
为什么选择Clickhouse
新的存储方案需要具备高写入吞吐、高读取效率、集群管理方便的特点。
写入效率:Clickhouse写入可以达到100M/秒,同时在延迟性上,受攒批效率的影响,实现了亚秒级别的数据写入延迟,而且稳定性相对于ES来说更强。在ES里,随着数据量积累增加,索引的更新成本是在逐步增长的相对的,写入稳定性也在受影响。
读取效率:在会话场景里,业务查询数据的时间范围以及对应的统计分析都是不确定的,Clickhouse基于高频查询确认主键字段,基于常用高优查询指定索引等优化手段,保证查询效率稳定。而ES在应对非固定查询的场景下,会占用大量内存,同时由于索引块换入换出的问题,会引起IO较高的问题。
集群管理:我们自研了Clickhouse集群的管理平台,支持对Clickhouse服务的数据写入、读取、节点状态等的监控,以及常用运维操作,比如扩缩容、数据均衡等。在ES的集群管理上,没有足够的手段覆盖到监控、数据迁移等运维操作。
易用性:Clickhouse基于sql查询,业务接入直接基于jdbc的方式或者http的方式就可以直接使用。在ES中,大段的Json格式的查询,有一定的学习门槛。
用Clickhouse存储会话数据
基于ES存储数据的架构如下:
基于Clickhouse存储会话的架构如下:
使用基于Clickhouse的方式进行存储,实现了多租户管理、查询资源管控、业务写入追踪和个性化调优等手段,让业务在写入效率和查询效率上提升明显。
Clickhouse关键的参数调优:
● parts_to_throw_insert:表分区之中活跃part数目超过多少,会抛出异常。针对不同的业务量,这个数字应该是不同的,用来保证相应的资源匹配相应的写入量级。
● max_threads:用于控制一个用户的查询线程数。
● max_execution_time:单个查询最大执行时间。一般跟业务相关,是业务可容忍的最大查询时间。
● background_pool_size:表引擎操作后台的线程数。太大会影响cpu资源,太小会影响parts数量,从而可能触发parts_to_throw_insert的异常。
● max_memory_usage:单个查询最多能够使用的内存大小,应对不同的硬件配置以及不同的用户会配置不同的内存大小。
遇到的问题
问题一:too many parts
当写入超过Clickhouse服务承受的上限的时候,就会出现too many parts异常。这个异常的本意是防止Clickhouse服务在超负载的情况下挂掉,同时给维护人一个信号。因此,出现too many parts异常的时候,维护人就要关注当前服务是不是遇到超高峰数据的写入了。此时可以关注的指标如下:
● 当前服务占用的cpu是不是超预期了。关注merge任务是不是占满队列,通常写入超预期的情况下,parts数量也是暴涨,Clickhouse为了保证查询效率,merge任务就会暴涨,而merge任务是消耗硬件资源的,如果资源不够,merge任务运行缓慢,就会降低parts数量的减少效率,从而导致parts数量缓慢增加,当增加到parts_to_throw_insert的数值时,就会产生too many parts的异常。
● 关注写入数据攒批的状态,如果写入频繁,单批次数量较小,会导致parts数量增长很快,很容易触发到merge任务运行的最大值,从而引发too many parts异常。
问题二:重启耗时很长
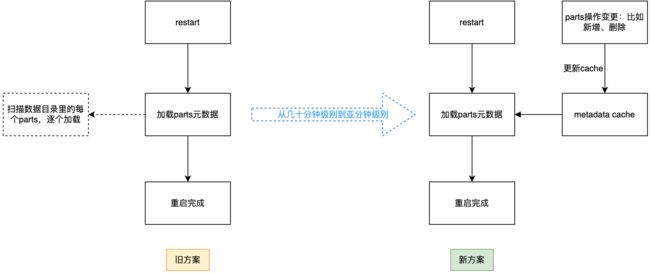
当集群容纳的数据量比较多的时候,Clickhouse的重启耗时会比较长,通常会达到几十分钟到小时级别不等。重启服务时间过长,对于整个服务的高可用会挑战很大,写入端的稳定性、容错性以及实时性,都会受到挑战。Clickhouse本身在解决超大容量服务时,也提供了解决方案,即元数据缓存。
效果展示
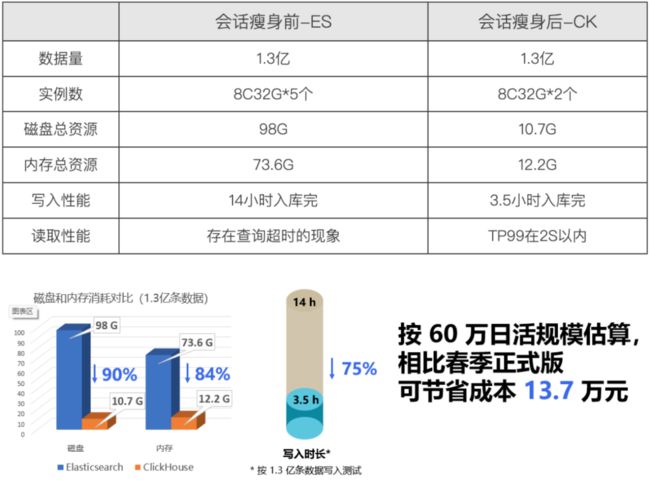
用Clickhouse存储会话模块的数据,存储资源节省明显,计算资源同样收益可观,解决了在ES存储方案中遇到的性能瓶颈和集群管理问题,同时在易用性上降低了门槛,让业务更加亲和地进行存储切换。
将会话数据从ES切换到Clickhouse,总体运维成本更低,而且提升了写入和查询效率,在用户进行会话数据统计分析和明细时,查询稳定性提升明显,用户体验得到大幅改善。
未来,我们会更加专注Clickhouse集群的精细化管理和优化,主要聚焦在以下方向:
● merge的效率提升。
● 存算分离。
● 高并发查询的优化。
以上三个方向的优化与完善都能够进一步巩固Clickhouse集群的稳定性,帮助我们应对更多的业务场景,让业务发展稳中提效。