为什么模型复杂度增加时,模型预测的方差会增大,偏差会减小?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
编辑:忆臻
https://www.zhihu.com/question/351352422
本文仅作为学术分享,如果侵权,会删文处理
为什么模型复杂度增加时,模型预测的方差会增大,偏差会减小?
作者:徐啸
https://www.zhihu.com/question/351352422/answer/862023291
题主的问题可以理解为:模型复杂度和偏差、方差之间的关系。
首先从逻辑上解释这三者之间的关系。从直觉上看,如果暂且忽略优化问题,模型的复杂度越大(这里的复杂度我觉得理解为模型的“容量、能力”更便于理解),模型的拟合能力就会越强,也就更容易发生过拟合。
那么这和方差、偏差又有什么关系呢?这里需要对偏差和方差有一定的理解:
偏差(Bias):在不同训练集上训练得到的所有模型的平均性能和最优模型的差异,可以用来衡量模型的拟合能力。
方差(Variance):在不同的训练集上训练得到的模型之间的性能差异,表示数据扰动对模型性能的影响,可以用来衡量模型是否容易过拟合,即模型的泛化能力。
所以,当模型的复杂度增加时,模型的拟合能力得到增强,偏差便会减小,但很有可能会由于拟合“过度”,从而对数据扰动更加敏感,导致方差增大。从模型评价上来看,模型复杂度增加后,出现验证集效果提升,但是测试集效果下降的现象。
接着从偏差-方差分解(Bias-Variance Decomposition),进行简要阐述,详细内容请见《神经网络与深度学习》的 2.4 节 偏差-方差分解。
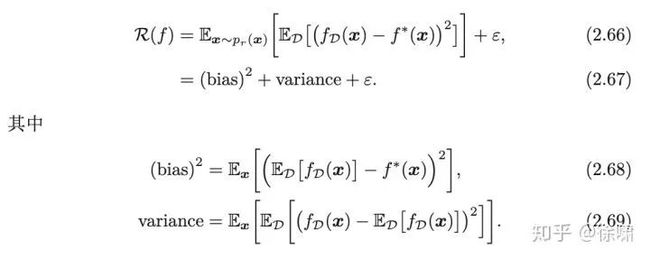
 即为偏差,
上训练得到的所有模型性能的期望值,而
即为偏差,
上训练得到的所有模型性能的期望值,而
已,所以![]() 即为方差,表示在不同的训练集上训练得到的模型之间的性能差异。
即为方差,表示在不同的训练集上训练得到的模型之间的性能差异。
通过上述公式,可以深入理解偏差与方差的含义。基于此,我们就可以理解下图中偏差与方差的四种组合情况:

以上个人浅见,如有谬误,还望指明。
作者:汪宇
https://www.zhihu.com/question/351352422/answer/862120414
如果没理解错,这里的assumption是:
模型复杂度增加,模型的能力越强,使得在训练的时候,可以更好地fit training data。
基于这个assumption,那么看这个图:
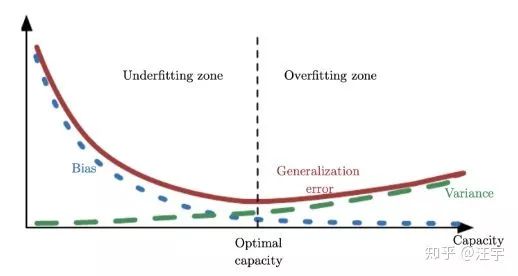
from: deeplearningbook (Goodfellow, Ian, Yoshua Bengio, and Aaron Courville.Deep learning. MIT press, 2016.)
(模型复杂度,bias, variance)的关系 和 (模型复杂度,underfitting,overfitting)的关系联系的很紧密。
Bias偏差衡量的是你的预测值和真实值的差距,也就是你的模型学的怎么样。在模型capacity不够的情况下,在underfitting的zone里,你预测的值通常跟真实值差距很大,那么bias就会比较大。随着模型capacity增加,模型越来越强,越拟合你真实的数据值,bias会降低。
Variance方差衡量的是‘how we would expect the estimate we compute from data to vary as we independently resample the dataset from the underlying data generating process’(from deeplearningbook)
也就是说,衡量的是你training data如果改变,对你的模型改变大不大。通常来说,如果你的模型capacity增大,那么就更容易overfit,那么training data的改变,就会影响你的模型,也就是方差会增大;相反,如果你的模型underfit,那么training data稍微改变一些,并不会对模型产生较大影响,方差小,模型的波动小。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

