Elasticsearch SQL 详解
Elasticsearch SQL 是一个 X-Pack 组件,允许用户使用类似 SQL 的语法在 ES 中进行查询。用户可以在 REST、JDBC、命令行中使用 SQL 在 ES 执行数据检索和数据聚合操作。ES SQL 有以下几个特点:
- 本地集成,SQL 模块是 ES 自己构建的,直接集成到发布的版本中。
- 不需要外部的组件,使用 SQL 模块不需要额外的依赖,如硬件、运行时库等。
- 轻量高效,SQL 模块不抽象 ES 和其搜索能力,而是暴露 SQL 接口,允许以相同的声明性、简洁的方式进行适当的全文搜索。
下面的内容我们基于 ES 7.13 来学习一下 Elasticsearch SQL 模块提供的功能。
如果你对 ES 感兴趣,欢迎订阅我的Elasticsearch 从入门到实践小册,我们一起学习进步!
一、Elasticsearch SQL 使用
在开始使用 SQL 模块提供的功能前,在 kibana 执行以下指令来创建数据:
PUT /library/_bulk?refresh
{"index":{"_id": "Leviathan Wakes"}}
{"name": "Leviathan Wakes", "author": "James S.A. Corey", "release_date": "2011-06-02", "page_count": 561}
{"index":{"_id": "Hyperion"}}
{"name": "Hyperion", "author": "Dan Simmons", "release_date": "1989-05-26", "page_count": 482}
{"index":{"_id": "Dune"}}
{"name": "Dune", "author": "Frank Herbert", "release_date": "1965-06-01", "page_count": 604}
导入数据完成后,可以执行下面的 SQL 进行数据搜索了:
POST /_sql?format=txt
{
"query": "SELECT * FROM library WHERE release_date < '2000-01-01'"
}
如上实例,使用 _sql 指明使用 SQL模块,在 query 字段中指定要执行的 SQL 语句。使用 format 指定返回数据的格式,数据格式可选项有以下几个,它们都是见名识意的:
| format | Accept Http header | 说明 |
|---|---|---|
| csv | text/csv | 逗号分隔 |
| json | application/json | Json 格式 |
| tsv | text/tab-separated-values | tab 分隔 |
| txt | text/plain | 文本格式 |
| yaml | application/yaml | yaml |
| cbor | application/cbor | 简洁的二进制对象表示格式 |
| smile | application/smile | 类似于 cbor 的另一种二进制格式 |
上述 SQL 执行的结果如下:

更多的返回格式,你可以自己尝试。
除了直接执行 SQL 外,还可以对结果进行过滤,使用 filter 字段在参数中指定过滤条件,可以使用标准的 ES DSL 查询语句过滤 SQL 运行的结果,其实例如下:
POST /_sql?format=txt
{
"query": "SELECT * FROM library ORDER BY page_count DESC",
"filter": {
"range": {
"page_count": {
"gte" : 500,
"lte" : 600
}
}
},
"fetch_size": 5
}
如上实例,其结果为:
author | name | page_count | release_date
----------------+---------------+---------------+------------------------
James S.A. Corey|Leviathan Wakes|561 |2011-06-02T00:00:00.000Z
另外可以使用 ‘?’ 占位符来传递参数,然后将参数和语句组装成完整的 SQL 语句:
POST /_sql?format=txt
{
"query": "SELECT YEAR(release_date) AS year FROM library WHERE page_count > ? AND author = ? GROUP BY year HAVING COUNT(*) > ?",
"params": [300, "Frank Herbert", 0]
}
如上示例,使用 ‘?’ 占位符来传递参数。
二、传统 SQL 和 Elasticsearch SQL 概念映射关系
虽然 SQL 和 Elasticsearch 对于数据的组织方式(以及不同的语义)有不同的术语,但本质上它们的用途是相同的。下面是它们的映射关系表:
| SQL | Elasticsearch | 说明 |
|---|---|---|
| column | field | 在 Elasticsearch 字段时,SQL 将这样的条目调用为 column。注意,在 Elasticsearch,一个字段可以包含同一类型的多个值(本质上是一个列表) ,而在 SQL 中,一个列可以只包含一个表示类型的值。Elasticsearch SQL 将尽最大努力保留 SQL 语义,并根据查询的不同,拒绝那些返回多个值的字段。 |
| row | document | 列和字段本身不存在; 它们是行或文档的一部分。两者的语义略有不同: 行row往往是严格的(并且有更多的强制执行),而文档往往更灵活或更松散(同时仍然具有结构)。 |
| table | index | 在 SQL 还是 Elasticsearch 中查询针对的目标 |
| schema | implicit | 在关系型数据库中,schema 主要是表的名称空间,通常用作安全边界。Elasticsearch没有为它提供一个等价的概念。 |
虽然这些概念之间的映射在语义上有些不同,但它们间更多的是有共同点,而不是不同点。
三、SQL Translate API
SQL Translate API 接收 JSON 格式的 SQL 语句,然后将其转换为 ES 的 DSL 查询语句,但是这个语句不会被执行,我们可以可以用这个 API 来将 SQL 翻译到 DSL 语句,其实例如下:
POST /_sql/translate
{
"query": "SELECT * FROM library ORDER BY page_count DESC",
"fetch_size": 10
}
如上实例,翻译出来的 DSL 如下:
{
"size": 10,
"_source": false,
"fields": [
{ "field": "author" },
{ "field": "name" },
{ "field": "page_count" },
{
"field": "release_date",
"format": "strict_date_optional_time_nanos"
}
],
"sort": [
{
"page_count": {
"order": "desc",
"missing": "_first",
"unmapped_type": "short"
}
}
]
}
四、SQL 语法介绍
下面来学习一下 ES 提供的 SQL 语法和语义。
1、词法结构
ES SQL 的词法结构很大程度上类似于 ANSI SQL 本身。ES SQL 当前一次只能接受一个命令,这里的命令是由输入流结尾结束的 token 序列。这些 token 可以是关键字、标识符(带引号或者不带引号)、文本(或者常量)、特殊字符符号(通常是分隔符)。
- 关键字
关键词这个其实跟我们写 SQL 语句那种关键字的定义是一样的,例如 SELECT、FROM 等都是关键字,需要注意的是,关键字不区分大小写。
SELECT * FROM my_table
如上示例,共有 4 个 token:SELECT、 * 、FROM 、my_table,其中 SELECT、 * 、FROM 是关键词,表示在 SQL 具有固定含义的词。而 my_table 是一个标识符,其表示了 SQL 中实体,如表、列等。
可以看到,关键词与标识符都有相同的词汇结构,在 SQL 中长的差不多,有时候难以分辨。ES SQL 支持的关键字有很多这里就不一一列出了,你可以参考官方文档。
- 标识符
标识符有两种类型:带引号的和不带引号的,示例如下:
SELECT ip_address FROM "hosts-*"
如上示例,查询中有两个标识符分别为不带引号的 ip_address 和带引号的 hosts-*(通配符模式)。因为 ip_address 不与任何关键字冲突,所以可以不带引号。而 hosts-* 与 - (减号操作)和 * 冲突,所以要加引号。
对于标识符来说,应该尽量避免使用复杂的命名和与关键字冲突的命名,并且在输入的时候使用引号作为标识符,这样可以消除歧义。
- 直接常量
ES SQL 支持两种隐式的类型常量:字符串和数字。
- 字符串,字符串可以用单引号进行限定,例如:‘mysql’。如果在字符串中包含了单引号,则需要使用另一个单引号进行转义,例如:‘Captain EO’‘s Voyage’。
- 数值常量,数值常量可以使用十进制和科学计数法进行表示,其示例如下:
1969 -- integer notation
3.14 -- decimal notation
.1234 -- decimal notation starting with decimal point
4E5 -- scientific notation (with exponent marker)
1.2e-3 -- scientific notation with decimal point
一个包含小数点的数值常量会被解析为 Double 类型。如果适合解析为整型,则解析为 Integer,否则解析为长整型(Long)。
- 单引号、双引号
在 SQL 中,单引号和双引号具有不同的含义,不能互换使用。单引号用于声明字符串,而双引号用于表示标识符。示例如下:
SELECT "first_name" FROM "musicians" WHERE "last_name" = 'Carroll'
如上示例,first_name、musicians、last_name 都是标识符,用双引号。而 Carroll 是字符串,用单引号。
- 特殊字符
一些非数字和字母的字符具有不同于运算符的专用含义,特殊字符有:
| 字符 | 描述 |
|---|---|
| * | 在一些上下文中表示数据表的所有字段,也可以表示某些聚合函数的参数。 |
| , | 用于列举列表的元素 |
| . | 用于数字常量或者分隔标识符限定符(表、列等) |
| () | 用于特定的 SQL 命令、函数声明,或者强制优先级。 |
- 运算符
ES SQL 中大多数的运算符它们的优先级都是相同的,并且是左关联。如果需要修改优先级,则要用括号来强制改变其优先级。下表是 ES SQL 支持的运算符和其优先级:
| 运算符 | 结合性 | 说明 |
|---|---|---|
| . | 左结合 | 限定符或者分割符 |
| :: | 左结合 | PostgreSQL-style 风格的类型转换符 |
| + - | 右结合 | 一元加减符 |
| * / % | 左结合 | 乘法、除法、取模 |
| + - | 左结合 | 加法、减法运算 |
| BETWEEN IN LIKE | 范围包含,字符匹配 | |
| < > <= >= = <=> <> != | 比较运算 | |
| NOT | 右结合 | 逻辑非 |
| AND | 左结合 | 逻辑与 |
| OR | 左结合 | 逻辑或 |
- 注释
ES SQL 支持两种注释:单行和多行注释,其示例如下:
-- single line comment,单行注释
/* multi
line
comment
that supports /* nested comments */
多行注释
*/
2、SQL 命令
下面来介绍 SQL 的命令。
- DESCRIBE TABLE
使用此命令用来查看索引的结构,其语法如下:
DESCRIBE
[table identifier |
[LIKE pattern]]
第 1 行,可以对关键字 DESCRIBE 进行缩写为 DESC。
第 2 行,单表标识符或者双引号 ES 多索引模式。
第 3 行,SQL Like 匹配模式。
DESCRIBE 命令使用示例如下:
DESCRIBE table;
- SELECT
这个其实我们很熟悉了,使用 SELECT 返回需要显示的列,其语法如下:
SELECT [TOP [ count ] ] select_expr [, ...]
[ FROM table_name ]
[ WHERE condition ]
[ GROUP BY grouping_element [, ...] ]
[ HAVING condition]
[ ORDER BY expression [ ASC | DESC ] [, ...] ]
[ LIMIT [ count ] ]
[ PIVOT ( aggregation_expr FOR column IN ( value [ [ AS ] alias ] [, ...] ) ) ]
在 ES 中使用 SELECT 查询的语法与在数据库中使用基本一致,这里就不做描述了。
- SHOW COLUMNS
使用 SHOW COLUMNS 命令可以列出表的所有列和其类型、其他属性,其语法如下:
SHOW COLUMNS [ FROM | IN ]?
[table identifier |
[LIKE pattern] ]
其使用示例如下:
SHOW COLUMNS IN emp;
SHOW COLUMNS IN emp LIKE 'birth_da%'; // 匹配 birth_da 开头的列
- SHOW FUNCTIONS
使用 SHOW FUNCTIONS 可以列出所有 SQL 支持的函数和其类型,LIKE 子句匹配对应的结果,其使语法如下:
SHOW FUNCTIONS [LIKE pattern?]?
示例如下:
SHOW FUNCTIONS;
SHOW FUNCTIONS LIKE 'ABS'; // 精确匹配
SHOW FUNCTIONS LIKE 'A__'; // 一个 '_' 表示一个字符,所以精确匹配 A + 两个字符,如 AVG、ABS。
SHOW FUNCTIONS LIKE '%DAY%'; // 匹配有 DAY 的函数
- SHOW TABLES
我们可以使用 SHOW TABLES 查看所有的表(ES中为索引),其语法如下:
SHOW TABLES
[INCLUDE FROZEN]?
[table identifier |
[LIKE pattern ]]?
简单的实例如下:
SHOW TABLES;
SHOW TABLES "*,-l*"; // 使用 ES multi-target syntax 进行匹配
SHOW TABLES LIKE 'emp'; // 精确匹配
SHOW TABLES LIKE 'emp%'; // 匹配 emp + 多个字符的表
SHOW TABLES LIKE 'em_'; // 匹配 em + 单个字符的表
SHOW TABLES LIKE '%em_'; // 匹配 多个字符 + em + 单个字符的表
- 索引模式
ES SQL 支持两种类型的模式匹配方式类匹配多个索引或者表:多索引模式和 LIKE 模式。
- 多索引模式
支持使用通配符 * 或者排他匹配,示例如下:
SHOW TABLES "*,-l*";
多索引模式是通过 ES multi-target syntax 来进行支持的。
- LIKE 模式
这个我们就比较熟悉了,上面也很多例子,这里就不在赘述了。
五、ES SQL 使用实践
在使用 SQL 前,我们先准备数据,此处我们将使用 Kibana 提供的航班数据:

如上图,在 Kibana 中点击左边栏的 Analytics 下的 Overview,弹出的页面中选择 Sample data 的 Tab,然后点击 add data 按钮即可加入航班的数据。
可以使用以下语句查看航班数据的数据结构:
POST /kibana_sample_data_flights/_search
{
"query": { "match_all": {} }
}
ok,下面来看看常用的 SQL 如何编写。
- WHERE
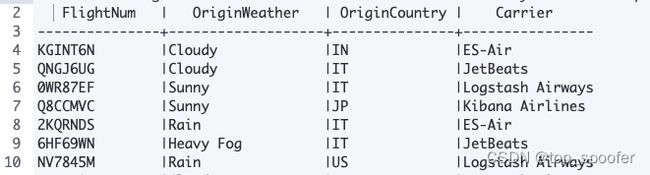
我们过滤出目的地为 US 的数据:
POST /_sql?format=txt
{
"query": "SELECT FlightNum, OriginWeather, OriginCountry, Carrier FROM kibana_sample_data_flights WHERE DestCountry = 'US'"
}
如上示例,对于用过 SQL 进行数据查询的你来说,肯定不会陌生了,最后其结果为:
- GROUP BY
可以使用 GROUP BY 语句对数据进行分组聚合统计操作,例如查询航班分组的平均飞行距离等。其示例如下:
POST /_sql?format=txt
{
"query": "SELECT count(*),max(DistanceMiles), avg(DistanceMiles) FROM kibana_sample_data_flights GROUP BY DestCountry"
}
如上示例,我们以目的地国家进行分组,然后统计每个分组的数量、最大的飞行距离,平均飞行距离。其结果如下:

- HAVING
可以使用 HAVING 对分组的数据进行二次筛选,比如筛选分组中记录数大于 100 的数据,其示例如下:
POST /_sql?format=txt
{
"query": "SELECT count(*),max(DistanceMiles), avg(DistanceMiles) FROM kibana_sample_data_flights GROUP BY DestCountry HAVING COUNT(*) > 100"
}
如上示例,我们过滤出了分组中记录数大于 100 的数据,其结果如下:

- ORDER BY
我们可以使用 ORDER BY 进行排序,例如将平均飞行距离降序排序,其示例如下:
POST /_sql?format=txt
{
"query": "SELECT count(*),max(DistanceMiles), avg(DistanceMiles) as avgDistance FROM kibana_sample_data_flights GROUP BY DestCountry HAVING COUNT(*) > 100 ORDER BY avgDistance desc"
}
如上示例,我们将数据用平均距离排序,其结果为:

- 分页
分页有多种实现方式,可以使用 limit、top、fetch_size 来进行分页。
1、limit 分页操作
POST /_sql?format=txt
{
"query": "SELECT FlightNum, OriginWeather, OriginCountry, Carrier FROM kibana_sample_data_flights WHERE DestCountry = 'US' limit 10"
}
2、使用 top 进行分页
POST /_sql?format=txt
{
"query": "SELECT top 10 FlightNum, OriginWeather, OriginCountry, Carrier FROM kibana_sample_data_flights WHERE DestCountry = 'US'"
}
3、使用 fetch_size 进行分页
POST /_sql?format=txt
{
"query": "SELECT FlightNum, OriginWeather, OriginCountry, Carrier FROM kibana_sample_data_flights WHERE DestCountry = 'US'",
"fetch_size": 10
}
- 子查询
ES SQL 是可以支持类似于 SELECT X FROM (SELECT * FROM Y) 这样简单的子查询的,其示例如下:
POST /_sql?format=txt
{
"query": "SELECT avg(data.DistanceMiles) from (SELECT FlightNum, OriginWeather, OriginCountry, Carrier, DistanceMiles FROM kibana_sample_data_flights WHERE DestCountry = 'US') as data"
}
需要注意的是,可能复杂一点的子查询会不被支持。更多的限制可以参考官方文档。
六、总结
本文详细介绍 ES SQL 的相关知识,整的来说,大部分都是基于官方文档进行直译过来的。更多关于 ES SQL 的使用方式,可以参考官方文档。