Flink 整合 hudi
1、hudi介绍:
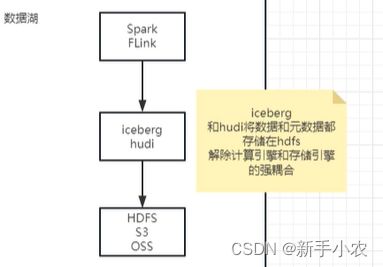
Hudi 是一个开源的大数据存储和处理框架,通过提供数据表、写入、读取、更新和删除等功能,实现了高效的增量数据处理和数据管理。它广泛应用于大数据领域,为数据湖环境下的数据操作提供了强大的支持。不仅可以存储数据,也可以将元数据存在在其中。
优点:不在只依赖于分布式的文件存储系统,对分布式具有解耦合,数据的存储位置可以不用固定,数据并不是只能存储在hdfs中了。
主要的作用:计算引擎可以是Spark、Flink ,存储系统可以是HDFS、OSS、S3,所以可以解除计算引擎和存储系统之间的强耦合。
2、Flink 整合 hudi
# 1、上传jar包到flink lib目录下
hudi-flink1.15-bundle-0.13.1.jar
# 2、重启flink集群
yarn application -list
yarn application -kill application_1699579932721_0004
yarn-session.sh -d -s 4[指定任务的并行度是4,这是hudi官网推荐的]
批处理:
-- sets up the result mode to tableau to show the results directly in the CLI
set sql-client.execution.result-mode = tableau;
CREATE TABLE t1(
uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://master:9000/data/hudi/t1',
'table.type' = 'MERGE_ON_READ' -- this creates a MERGE_ON_READ table, by default is COPY_ON_WRITE
);
-- insert data using values
INSERT INTO t1 VALUES
('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'),
('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),
('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),
('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'),
('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),
('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),
('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),
('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');想要变成流处理,需要在建表的时候指定参数:
-- 查询表
select * from t1;
'read.streaming.enabled' = 'true', 'read.start-commit' = '20210316134557','read.streaming.check-interval' = '4'
-- 流式查询,可以使用hint,修改其中的参数:
select * from t1 /*+OPTIONS('read.streaming.enabled' = 'true', 'read.start-commit' = '20210316134557','read.streaming.check-interval' = '4') */
-- 插入新的数据
INSERT INTO t1 VALUES
('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1');
--只适用于batch模式:
UPDATE t1 SET age=19 WHERE uuid in ('id1', 'id2');3、Flink CDC 整合 hudi
-- 创建Flink CDC 表:
CREATE TABLE students_cdc (
id BIGINT,
name STRING,
age BIGINT,
gender STRING,
clazz STRING,
PRIMARY KEY (id) NOT ENFORCED -- 主键
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'master',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'student',
'table-name' = 'student'
);
-- 创建hudi表
CREATE TABLE students_hudi(
id BIGINT,
name STRING,
age BIGINT,
gender STRING,
clazz STRING,
PRIMARY KEY (id) NOT ENFORCED -- 主键
)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://master:9000/data/hudi/students',
'table.type' = 'MERGE_ON_READ' -- this creates a MERGE_ON_READ table, by default is COPY_ON_WRITE
);
-- 查询cdc表将数据实时写入hudi表中
insert into students_hudi
select * from
students_cdc;
select * from students_hudi
/*+OPTIONS('read.streaming.enabled' = 'true', 'read.start-commit' = '20210316134557','read.streaming.check-interval' = '4') */;