汇编——操作符和常用指令
操作符
操作符分为四大类,算数操作符、关系操作符、数值回送操作符和属性操作符。
算数操作符
加减乘除和求模,这个就不说了。
注:这里指的是[sp+8]这样的加法,而不是我们的add指令。
关系运算符
- EQ 等于
- NE 不等于
- LT 小于
- LE 小于等于
- GT 大于
- GE 大于等于
注记:有E的就含有等于项。
如果为真,返回0fffh,否则为0000h。
其实这个不太常见,一般比较的时候,我们都是配合跳转指令来的,而跳转指令中直接cmp比较,然后看标志位就行了。(其实标志位都不需要你看,直接使用对应的跳转指令就行了。)
数字回送操作符
有一点像C的sizeof,返回类型的信息。
- type,返回类型字节数
- length,返回长度(几个单位)
- size,返回总长度(单个的字节数 * 单位数,即type * length)
上述操作符主要是针对我们的dup,如果是dw "abcd"length的返回值仍为1。
还有两个老生常谈的offset和seg指令,用来对物理地址求偏移地址和段地址。
属性操作符
short:修饰跳转的操作符。跳转分为近跳转和远跳转,short为近跳,-128~127个字节范围内)
high/low,返回字的高字节和低字节。
highword/lowword,返回双字的高字部分和低字部分。
数据传送指令
数据传输难免碰到数据类型的问题,这里我们讲一下。
首先,如果是有两个参数的指令,两个参数的类型一定要对上;
如果是只有一个,或者是有一个为地址(没有参数类型),则以有类型的参数的类型为类型(老不说人话了,就是谁有类型看谁)
如果是都没有,比如将一个地址的内容赋值到另一个地址上,那么我们就需要ptr标志数据类型了。
比如 mov byte ptr [bx],0
通用数据传送指令
mov、pop、push(popa、pusha)、xchg和xlat。
mov
格式:mov a,b ,将b的值赋值给a。
要求:
- 两个操作数的类型要相同(属于两个都有操作数的)
- 两个操作数不能都是段寄存器
- 不能将立即数给段寄存器
- 目的操作数(也就是被赋值的a)不能是立即数和CS,给立即数赋值可还行,cs是因为比较重要不能乱动。
- 两个操作数不能都是存储器寻址,这样实现起来难度较大。
- ip不能作为操作数(道理和cs差不多)
mov指令不影响标志位,另外存储器寻址就是指在内存中取数,分为五种方式,具体见博客。
pop、push
针对的是压栈和出栈,两个都是单操作数,不论是存储器、寄存器还是段寄存器都可以,但是不能是立即数。
另外不能pop cs。
pop和push指令不影响标志位,另外要记住压栈是从高到低的。
popa、pusha
是将AX、BX、CX、DX以及该指令执行前的SP、BP、SI、DI这八个寄存器都按照顺序压栈和按照相反顺序出栈的指令。
我们要知道,在出栈的过程中SP指针会变,那么会不会导致出栈的过程中导致BX出栈出现意外?
当然不会。
SP出栈只是修改了指针使其后的BX能够出栈,而堆栈中原先由PUSHA指令存入的SP的原始内容被丢弃,并未真正送到SP寄存器中。
最终SP仍为SP+16,16个字节也就是8个寄存器的大小。
和pop那一对一样,不影响标志位。
xchg
xchg指令为交换指令,目的是将两个操作数进行交换,不影响标志位。
我们要保证两个操作数至少有一个为寄存器,且不能出现段寄存器。
比如:XCHG BX, [ BP+SI ]
xlat
换码指令,后面可以有操作数也可以没有,只是一个可读性问题。
执行的操作是(AL) = ( (BX)+(AL) )。
比如我们将0-9转换成七段数码管的输出,我们就需要进行转码。
这时先建立一个字节表格,将对应的下标输入对应的输出,比如0位置就应该是1111_1100。
然后将表格(数组)的首地址放在BX寄存器中,将需要转换的数据放在AL寄存器中,就可以将其进行替换。
mov bx,offset biaoge ;biaoge就是表格
mov al,0
xlat (biaoge) ;加括号表示有没有都行
这样我们al寄存器的内容就变成1111_1100了。
注意我们译码是放在al中的,al长为8位不要超了。
至于为什么七段数码管是这样的,博客在这里,还算比较有趣,Verilog语言,看一下思路得了。
地址传送指令
lea、lds和les
我们之前的寻址操作都是找到一个地址,将地址的内容赋值给目的数,但是这次我们是赋值地址。
lea a,b ,将b的有效地址给a,和offset差不多但是会更厉害一些,offset指令只能针对一些简单寻址方式。
lds和les两个差不多,不但能传送地址,还能同时给段寄存器和寄存器赋值(这个值也是地址)
我们拿lds举例,lds a,b 表示将b地址上的内容给a,另外将b+2的地址(一个字之后的位置)的值给DS寄存器。
虽然我们说的是a,但是很明显a一定是寄存器,这样一个指令将相邻的两个字的内容低位给寄存器高位给段寄存器,更加方便。
les的区别就是将DS改为ES。
这些都是不影响标志位的。
另外lds和les指令的目的数不能为段寄存器,源操作数需要为寄存器寻址方式。
寄存器寻址方式有五种。(上面有链接)

标志寄存器传送指令
lahf、sahf
将ah和标志位的低字节互相赋值。
lahf: (AH) = (FLAGS的低字节)
sahf: (FLAGS的低字节) = (AH)
pushf、popf
将标志寄存器压栈和出栈用的。
另外标志寄存器的内部结构长这样:(虚框为低位)
类型转换指令
其实就是进行位数扩展,比如一个字节扩展为一个字、一个字扩展为一个双字。
cbw:AL -> AX
cwd:AX -> DX+AX
拓展规则:最高位为0则拓展位全部为0(比如al = 45h,则ax为0045h),否则为全1。
(这种方式属于有符号数的扩展,遵循的是补码的原则)
该指令是没有操作数的,另外不影响标志位。
算数运算指令
加法
我们分为不带进位的加法add、带进位的加法adc和自增指令inc。
add、adc这里我们可以考虑半加器和全加器,半加器是两个输入两个输出(进位和当前位),全加器是三个输入两个输出。说白了其实就是adc指令是考虑我们从低位上来的进位。(这个进位是只看CF的)
因为是二进制数,我们的进位只可能为0或者1,所以我们就可以用标志位进行存放,也就是说这两个指令是影响标志位的,被影响的有:SF、ZF、CF和OF。
SF看是否为负数(准确来说是看最高位的数值),ZF判断是否为0;
CF和OF这对无符号数和有符号数溢出都很经典了。
这里举一个例子,我们将2个双精度的数据进行相加操作,其中DX为数据1的高位,BX为数据2的高位;AX为数据1的低位,CX为数据2的低位。(DX:AX + BX:CX,先看无符号数吧)
add ax,cx
adc dx,bx
这里注意一下,如果是判断溢出,我们需要判断高位运算的结果(adc),看低位是没意义的。
另外至于为什么是只看CF,如果是像上面的那样,无符号数是想得通的;
如果是有符号数,我们要知道,存储的内容其实是补码,所以我们对于低位来说其实就是两个无符号型,直接相加就行了。
补充:
在计算机中,其实是不知道数据的类型的,而且刚好两种计算方式是相同的,所以是将两种情况都考虑了一下,CF和OF位都给出,交给程序员判断。实际上求CF和OF的过程也很简单,只需要对最高位进行一个判断即可。
首先溢出一定是发生在同类型相加或不同类型相减。因为是在讲加法,我们只考虑同类型。
无符号数的溢出只需要看最高位,如果最高位有1但是结果最高为0(最高位相或任何和结果最高位比较),那么一定溢出;
有符号数的话,就是正数加正数(两个最高位都是1),看结果,如果也是0就没有溢出;如果是负数加负数,那么最高位如果是0就说明溢出。
inc指令:只有一个操作数,比如inc bx,能进行自增。
不影响标志位。
减法
基本上和加法差不多,分为sub和sbb(带借位),全减器还是半减器的问题(如果这两个名词都有的话),影响标志位。
另外记得有符号数的减法可以通过将减数求补转换成加法就行了。
自减指令dec,不影响标志位。
求补指令和比较指令
neg指令为求补指令,单操作数。
对标志位的影响:
CF = 0:操作数为零,否则CF为1;
OF = 1:操作数为-128(27,字节运算)或-32768(字运算),否则为0。
CF和OF位这里,其实也算上是溢出。
-128或-32768求补除了最高位全为0 。(1000_0000)
求补为0则原数为0 。
比较指令cmp,影响ZF位,如果结果为0,ZF = 1。
这个指令主要是在跳转时使用,通过比较确定分支。
乘法除法
乘法分为两种:
无符号数:mul
有符号数:imul
这里都是单操作数的指令,所以我们的类型需要由给出的操作数决定。
如果是字节操作,我们有这样的公式 (AX) = (AL)*操作数
如果是字操作,我们就有(DX,AX) = (AX)*操作数
首先我们要知道,两个a位的二进制数乘法结果一定不超过2a位的。
另外因为要知道位数,所以我们需要将数据放在寄存器中,而不是一个立即数。
最后,乘法可能会影响CF和OF位,对于其他的标志位为无定义。
(无定义表示执行之后状态不确定)
mul指令中,如果乘积的高一半位为0,则CF = OF = 0,否则为1;
imul指令中,如果高一半为低一半的符号扩展,则CF = OF =0,否则为1。
(符号扩展,比如将一个字节扩展为一个字,因为存储的是补码,如果最高位为1,扩展的高一半都是1;否则均为0,其实上面都有)
无符号数和有符号数的乘法是不同的,所以我们一定要用对指令。
除法和乘法类似,都是只有一个操作数,分为无符号数的div和有符号数的idiv。
如果操作数是字,那么有:
AL = AX/操作数,为商;
AH = AX%操作数,为余数。
如果操作数是双字:
AX = DX:AX / 操作数
DX = DX:AX % 操作数
所有标志位均为无定义,另外操作数不能为立即数。
逻辑运算指令
and、or、not、xor和一个text
前四个就是我们所说的与或非异或,除了not都是两个操作数。(如果两个操作数位数不同,会自动补0)
not的操作数不能是立即数,而剩下的可以有一个为立即数。(对两个立即数and或者对一个立即数not,意义不大吧)
影响标志位SF(符号标志位,和最高位相同)、ZF(零标志位,检测结果是否为0)和PF(检测1的个数)。
将CF和OF置为0,这也是为什么有一些程序and ax,ax,目的就是将标志位进行置零。
另外多嘴一下,xor ax,ax可以实现计数器清零操作,而且比mov ax,0要快。
至于我们一直没提到的text,其实功能和and差不多,只不过是不修改原来数据的and。
我们可以原来作为测试,判断寄存器的内容。(可能这也是叫text的原因吧)
移位指令
话不多说,先给一张图:(其实就讲完了)
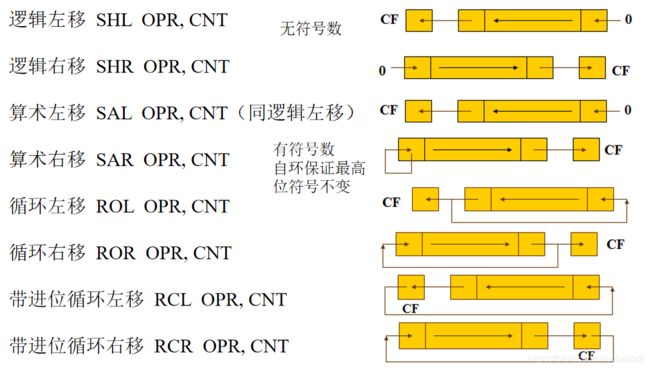
区分一下逻辑和算数:
逻辑和算数的左移都是相同的,但是对于右移来说,算数右移保证了最高位不变。
这东西有什么用,比如我在将一个有符号数进行移位,如果是采用逻辑右移,就是补0,那么就会将一个负数变成正数(对于补码来说),导致变成了无符号数,反正就是奇奇怪怪的东西。所以我们需要使用算数右移。
循环移动就是循环移动(bushi,只不过同时给CF进行了赋值,这个和移位寄存器确实很像。
带进位就是循环过程中将CF位带上一起转圈。
在计算AX寄存器1的个数时(个数不是奇偶,PF不行),我们可以先and ax,ax将CF位置零,任何将所有的位循环移动到CF上数一下。
循环移动的两个操作数也是有讲究的,其中的opr可以为除立即数以外的任何寻址方式。
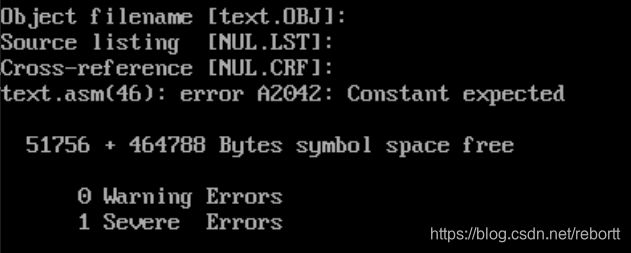
cnt则是记录移动的个数,如果是移动一位,我们可以写 shl ax,1,但如果是多位就一定要将个数放在cl寄存器中,cx也不行。
如果不是放在cl寄存器中,就会有这样的报错:
对标志位有影响:
- CF为传入的数据
- cnt=1时,如果最高位变化OF为1,否则为0
- 对于普通移位,SF、ZF、PF按照定义即可,AF无定义
- 对于循环移位,上面四个都不影响。
对于循环操作,最简单的应用就是乘2(或者是2的幂次)和除法。
串指令
这个就比较烦了,我们将指令分为两部分介绍,前缀和处理指令。
前缀:
第一个前缀是rep,是用来重复的,当CX计数器为0,就停止。
还有更强的repz和repe,停止的判断条件为两个,一个是cx计数器为0,另一个是两个操作数不相等。
不相等这个先记下,讲到后面的部分就知道了。
对应的就是repnz和repne,也就是在相等或cx为零则停止。
其实所谓的相等和不等,我们在比较两个串的过程中是有一个相当于cmp的操作的,对ZF为产生影响,所以指令是看ZF和CX的情况进行操作。
串操作指令:
- movs、movsb、movsw,和mov相似,为移动指令。
- stos、stosb、stosw为存入指令。
- lods、lodsb、lodsw为串取出指令。
- cmps、cmpsb、cmpsw为串比较指令。
- scas、scasb、scasw为串扫描指令。
为什么每一组都有三个,这是为了进行类型的区分。
如果是没有类型,就采用第一种,也就是每一组的第一个,同是需要给出参数(个数不一定,分为源串和目的串),方便系统确定变量类型;
如果是db和dw类型,分别使用**b、**w指令即可。
组合
对于传递(其实就是将目的串赋值为源串)、存入(即赋值)和取出操作,都是直接跑到结束就行了,但是对于串比较、串扫描(在串中寻找一个元素),则是需要在确定失配/找到时结束,所以可能需要提前停止。
所以,movs、stos和lods(以及db、dw类型)理论上都是可以和rep指令配对的;
cmps是和repe/repz指令配对,这样在失配时就可以停止;
scas则是和repne/repnz配对,保证在找到元素时停止。
提前准备
串操作可以没有操作数(也可以有操作数,但目的只是为了给出数据类型),按照乘除法的经验我们知道一定是有提前准备的。
还记得我们之前提到的SI、DI变址寄存器吗(寄存器的分类),当时就提过SI和DI在字符串操作中能用上,这里就是。
我们将源串首地址放在SI中,目的串的首地址放在DI中,另外目的串一定要给出附加段。
一般我们的搭配是ES:DI和DS:SI。
MOVS ES: BYTE PTR [DI], DS: [SI] (两个地址都没有类型,所以使用了ptr)
在标志位中有一个DF,是控制标志位,控制字符串的方向,DF = 0时从低到高。
而控制DF值的指令为CLD(置零)和STD(置一),无操作数。
(那么上面的首地址放入就不准确了,还要看DF的值)
我们还说过,CX是在rep中计数的,所以我们还需要给CX赋初值。
代码演示:
data segment
mess1 db 'personal_computer'
mess2 db 17 dup (?)
data ends
code segment
assume cs:code, ds:data
start:
mov ax, data
mov ds, ax
mov es, ax
lea si, mess1
lea di, mess2
mov cx, 17
cld
rep movsb
mov ax, 4c00h
int 21h
code ends
end start
当我们做了所有的准备工作,直接调用rep movsb指令就能解决问题。
在指令中,实现了CX寄存器的自减,实现了SI和DI的加一(db类型,DF = 0,如果是dw则加2)
同时还有每一步的cx寄存器检测。
注:这一个moa,es,ax不太好理解。因为两个操作数分别在DI和SI,所以我们需要将data数段的内容绑定到es和ds两个附加段,就相当于复制一遍到es里面。
取出和存入有一点不一样,因为只需要一个操作数,而且寄存器也有一点不同.
stos存入指令是将AX(或者AL)寄存器的内容给DI寄存器,类型决定DI每一次增加多少。
把附加段中首地址为mess2的10个字节缓冲区置为 20H:
lea di, mess2
mov al, 20H
mov cx, 10
cld
rep stosb
lods指令则相反,是将SI的内容给AL/AX寄存器。
但是很明显,如果我们直接使用rep指令,并不能实现我们的功能,所以实际上还是采用自己循环比较多。
repe/repz cmps a,b:
源串在SI中,目的串在DI中(这里不需要分太清楚其实,但是还是要有两个操作数);
cx放置个数;
DF给出方向。
当结束循环,di放置的是不匹配字符的下一位(因为会自增),cx放置未匹配的字符个数。
repne/repnz scas a
将a的内容(在DI中)和AL/AX的内容比较,当比较成功结束。
结束时di存储匹配字符的下一位,cx存储未匹配字符个数。
其实对于repe、repz(另一对同理),两者是一样的,都是看ZF存储器的值,因为我们使用的方式是相减,所以equal和zero是相同效果的。
标志处理指令
这个有点听不懂,其实就是在控制标记位的值。
CF位:
clc置零、stc置一、cmc取反
DF位:
cld置零、std置一
IF位:
cli置零、sti置一
可以看出,都是 cl* 置零,st* 置一,汇编的起名还算正常。
总结
除了这些其实应该还有功能调用的部分,以及跳转指令(放在循环一起),还有一些比较杂的,这里都没有提到。