内存知识梳理2. Linux 页表的建立过程-x86
Linux的寻址机制的正常运行机制的正常运行,有赖于在启动过程中足部建立的内核页和页表。本节讲述内核页表的建立过程。
bootloader加载内核镜像
操作系统启动前时启动bootloader,并用bootloader加载和解压内核镜像到内存中。实模式下bootloader(示例中是grub)不能访问1MB以上的内存,需要暂时开启保护模式,将保护模式内核放入1MB以上的地址空间。加载完成后的内存布局如图。

Bootloader执行完使命后跳转到内核arch/x86/boot/header.S的_start处开始执行。
准备进入第一次保护模式(内存管理:野蛮)
内核汇编代码要设置堆栈(ss,esp)和清理bss段,然后跳入C语言的arch/x86/boot/main.c执行
==================== arch/x86/boot/main.c 134 183 ====================
134 void main(void)
135 {
181 /* Do the last things and invoke protected mode */
182 go_to_protected_mode();
183 }
调用go_to_protected_mode()进入保护模式(pm.c)。
==================== arch/x86/boot/pm.c 104 126 ====================
104 void go_to_protected_mode(void)
105 {
121 /* Actual transition to protected mode... */
122 setup_idt();
123 setup_gdt();
126 }
为了进入保护模式,需要先设置gdt,这个时候的gdt为boot_gdt,代码段和数据段描述符中的基址都为0,设置完后就开启保护模式。
==================== arch/x86/boot/pm.c 66 90 ====================
66 static void setup_gdt(void)
67 {
68 /* There are machines which are known to not boot with the GDT
69 being 8-byte unaligned. Intel recommends 16 byte alignment. */
70 static const u64 boot_gdt[] __attribute__((aligned(16))) = {
71 /* CS: code, read/execute, 4 GB, base 0 */
72 [GDT_ENTRY_BOOT_CS] = GDT_ENTRY(0xc09b, 0, 0xfffff),
73 /* DS: data, read/write, 4 GB, base 0 */
74 [GDT_ENTRY_BOOT_DS] = GDT_ENTRY(0xc093, 0, 0xfffff),
75 /* TSS: 32-bit tss, 104 bytes, base 4096 */
76 /* We only have a TSS here to keep Intel VT happy;
77 we don't actually use it for anything. */
78 [GDT_ENTRY_BOOT_TSS] = GDT_ENTRY(0x0089, 4096, 103),
79 };
80 /* Xen HVM incorrectly stores a pointer to the gdt_ptr, instead
81 of the gdt_ptr contents. Thus, make it static so it will
82 stay in memory, at least long enough that we switch to the
83 proper kernel GDT. */
84 static struct gdt_ptr gdt;
85
86 gdt.len = sizeof(boot_gdt)-1;
87 gdt.ptr = (u32)&boot_gdt + (ds() << 4);
88
89 asm volatile("lgdtl %0" : : "m" (gdt)); //加载段描述符
90 }其中GDT_ENTRY宏的定义如下:
==================== arch/x86/include/asm/segment.h 4 11 ====================
4 /* Constructor for a conventional segment GDT (or LDT) entry */
5 /* This is a macro so it can be used in initializers */
6 #define GDT_ENTRY(flags, base, limit) \
7 ((((base) & 0xff000000ULL) << (56-24)) | \
8 (((flags) & 0x0000f0ffULL) << 40) | \
9 (((limit) & 0x000f0000ULL) << (48-16)) | \
10 (((base) & 0x00ffffffULL) << 16) | \
11 (((limit) & 0x0000ffffULL)))由于尚未开启分页,所以写入gdtr寄存器的需要是物理地址,上面87行说明了在实模式下段式寻址的过程,将变量的地址加上段地址才是物理地址。
第一次进入保护模式,为了解压内核(内存管理:野蛮)
进入arch/x86/boot/compressed/head_32.S中的startup_32(),用于解压剩余的内核。
==================== arch/x86/boot/pm.c 121 125 ====================
121 /* Actual transition to protected mode... */
122 setup_idt();
123 setup_gdt();
124 protected_mode_jump(boot_params.hdr.code32_start,
125 (u32)&boot_params + (ds() << 4));第二次进入保护模式(第二次设置gdtr)
由于整个vmlinux的编译链接地址都是从线性地址0xc0000000开始的,有必要重新设置下段寻址。这一次设置的原因是在之前的处理过程中,指令地址是从物理地址0x100000开始的,而此时整个vmlinux的编译链接地址是从虚拟地址0xC0000000开始的,所以需要在这里重新设置boot_gdt的位置。
===================arch/x86/boot/compressed/head_32.S ====================
34 ENTRY(startup_32)
82 testb $(1<<6), BP_loadflags(%esi)
83 jnz 1f
84
85 cli
86 movl $__BOOT_DS, %eax
87 movl %eax, %ds
88 movl %eax, %es
89 movl %eax, %fs
90 movl %eax, %gs
91 movl %eax, %ss
92 1:
102 leal (BP_scratch+4)(%esi),%esp //设置栈顶小结
启动过程中压缩内核被搬移到64MB处,然后解压到1MB开始的物理地址处,(在PC机上,前1MB物理空间包含BIOS数据和图形卡,不能被内核使用)内核是从第二个MB开始的。假设Linux内核需要小于3MB的RAM,图示了x86的前3MB物理地址分配。
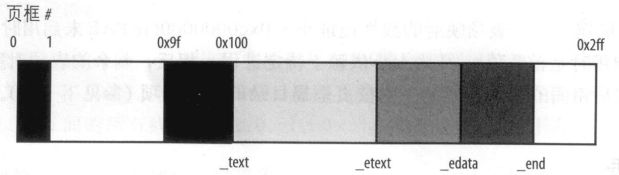
内核在编译过程中都是使用的0xc0000000开始的线性地址,因此需要立即开启分页。
开启第一次分页(建立临时内核页表)
内核中编有一个初始页全局目录initial_page_table,静态分配好了空间。
662 ENTRY(initial_page_table)
663 .fill 1024,4,0 //填充一个页面(4k)的空间有了全局目录,还需要分配页表空间。在链接vmlinux时,有一个BRK段,其开始地址为brk_base(有的版本称为pg0变量,紧挨着_end)。这个段的作用是保留给用户通过brk()系统调用向内核申请内存空间用的,我们先不管它的这个用处,在这个步骤中页表空间就从brk_base分配。假设我们需要映射8MB空间,则只需要不超过2048个页表项。
内核把页目录的0和768项指向同样的页表、1和769项指向同样的页表,使得线性地址0和0xc0000000指向同样的物理地址,把其余页目录项全部清零,使得其他地址都未映射。来看初始化后的页表和页目录。
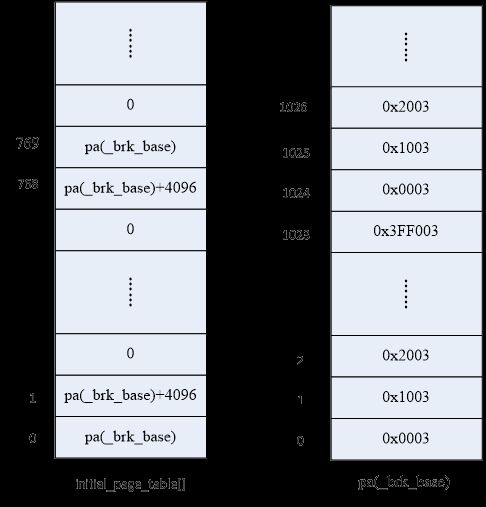
设置好页目录和页表项后,将initial_page_table的值赋给CR3,就开启了页式寻址。
movl $pa(initial_page_table), %eax
movl %eax,%cr3 /* set the page table pointer.. */
movl $CR0_STATE,%eax
movl %eax,%cr0 /* ..and set paging (PG) bit *///开启分页机制!这些工作都完成后,就完成了将物理地址0x00000000到内核_end内存空间映射到线性地址0x00000000开始和0xc0000000开始的内存空间。这样的话,用逻辑地址0x00000000或者0xc0000000类似的地址都能访问到物理地址0x00000000开始的空间。
第三次开启保护模式(第三次设置gdtr)
上面过程中分段模式一直开启,但gdtr写入的一直是物理地址,这时候需要将其重新配置为线性地址。
第二次设置分页(第二次设置cr3)
在start_arch()中把initial_page_table复制给swapper_pg_dir,在这以后swapper_pg_dir就一直当做全局目录表使用了。随后设置cr3,弃用以前的initial_page_table。
873 /*
874 * copy kernel address range established so far and switch
875 * to the proper swapper page table
876 */
877 clone_pgd_range(swapper_pg_dir + KERNEL_PGD_BOUNDARY,
878 initial_page_table + KERNEL_PGD_BOUNDARY,
879 KERNEL_PGD_PTRS);
880
881 load_cr3(swapper_pg_dir);真正的内存管理
下面进入第一个真正的内核管理函数:setup_memory_map()。
前面在实模式的main函数中,曾经获取过物理内存结构并将其存放在e820结构体数组中,这里利用结构体得到最大物理页框号max_pfn,与MAXMEM_PFN进行比较取小赋给max_low_pfn,比较结果决定是否需要开启高端内存,如果需要,二者取差得到highmem_pages表示高端内存总页框数。高端内存的问题在后续介绍。
1. struct e820map {
2. __u32 nr_map;
3. struct e820entry map[E820_X_MAX];//E820MAX定义为128
4.};
5.
6.struct e820entry {
7. __u64 addr; /* start of memory segment */
8. __u64 size; /* size of memory segment */
9. __u32 type; /* type of memory segment */
10.} __attribute__((packed));小结
我们来总结下现在内核的状态。
- 已经设置了最终gdt,开启了段式内存管理,段基址都是0,因此逻辑地址和线性地址相同。
- 已经设置了cr3,开启了分页式内存管理。最后的全局目录表是swapper_pg_dir,页表还是在__brk_base开始。将物理地址0x00000000~_end的空间映射到虚拟地址(线性地址)0x00000000开始和0xc0000000开始(即全局目录同时从0项和767项分配)。因此由虚拟地址0xc0000000开始链接的内核可以正常寻址到物理地址上。
- 内核通过int 0x15获取物理内存布局,并存在e820全局数组中。
需要注意的是,这个时候内核基本不能动态分配管理内存,唯一动态分配内存的方式也仅仅是从brk中分配页表。
着手建立最终内核页表
注意这时候swapper_pg_dir里只映射到了内核所在的空间(上面假设的8MB),这时候需要将所有物理空间都进行映射,即建立最终页表。建立时分为三种情况:
- 第一种:RAM小于896MB时,也就是没有高端内存的情况。
这种情况是把所有的RAM全部映射到0xc0000000开始。由内核页表所提供的最终映射必须把从0xc0000000开始的线性地址转化为从0开始的物理地址,主内核页全局目录仍然保存在swapper_pg_dir变量中。 - 第二种:RAM在896MB到4GB之间,也就是存在高端内存的情况。
这种情况就不能把所有的RAM全部映射到内核空间了,Linux在初始化阶段只是把一个具有896MB的RAM映射到内核线性地址空间。如果一个程序需要对现有RAM的其余部分寻址,那就需要使用896MB~1GB的这段线性空间中的一部分来分时映射到所需的RAM,在下一讲中详述。这时候页目录初始化方法和上一种情况相同。 - 第三种:RAM在4GB以上。
现代计算机,特别是些高性能的服务器内存远远超过4GB,这要求CPU支持物理地址扩展(PAE),且内核以PAE支持来编译。这时尽管PAE处理36位物理地址,但是线性地址依然是32位。如前所述,Linux映射一个896MB的RAM到内核地址空间;剩余RAM留着不映射,并由下一讲中动态重映射来处理。所不同的是使用三级分页模型。在这种情况下,即使我们的CPU支持PAE,但是也只能有寻址能力为64GB的内核页表,大量的高端内存使用动态重映射的方法,对性能产生了很大的挑战。所以如果要建立更高性能的服务器,建议改善动态重映射算法,或者干脆升级为64位的处理器。
既然要建立映射,按照从前建立临时页表的套路,应该要有个全局目录表,然后分配若干页表并初始化完成映射。这里还使用全局目录表swapper_pg_dir,调用init_memory_mapping ()函数完成低端内存的映射。
低端内存映射
它负责映射低端内存空也就是0-896MB。而这部分内存也分为两个部分开始映射:
- 首先映射0-ISA_END_ADDRESS(0x100000)的RAM
- 接着映射0x100000~896mb的RAM
先重新确定内存范围(对齐,分割、合并等)后,
start_kernel
-->setup_arch
--> init_mem_mapping
-->init_memory_mapping
-->kernel_physical_mapping_init来到kernel_physical_mapping_init(),这个才是真正的建立页表,设置页表项,进行内存映射,注意,这里没有定义PAE。
这个函数的作用是将物理内存地址都映射到从内核空间开始的地址(0xc0000000),函数从虚拟地址0xc0000000处开始映射,也就是从目录表中的768项开始设置。从768到1024这256个表项被linux内核设置为内核目录项,低768个目录项被用户空间使用。接下来就是进入循环,准备填充从768号全局目录表项开始剩余目录项的内容。
注意这里是按照Linux的四级分页模型进行的,但上级目录和中级目录在32位系统中暂不使用。它们都是只有一个数组元素的数组。
这里要继续分配页表,每个页表4KB大小即占一页,这里从已经映射的内存中分配一页内存来作为页表空间。–梯云纵。
至此,内核低端内存页表建立完毕。
896MB问题
按照固定偏移0xc0000000的方案,高于1GB的物理内存其线性地址将超出32位地址范围。这是一个Linux发展史上的历史问题,最早的内核设计者没有预想到内存空间可以发展到1GB以上,因此内核就是为1GB物理内存设计的。
当出现大容量内存后,需要这个问题。另外内核还需要在其线性地址空间内映射外设寄存器空间等I/O空间,为了解决这个问题,在x86处理器平台上给内核增添了一个经验值设置:896MB,更高的128MB线性地址空间用于映射高端内存以及I/O地址空间。就是说,如果系统中的物理内存(包括内存孔洞)大于896MB,那么将前896MB物理内存固定映射到内核逻辑地址空间0xC0000000~0xC0000000+896MB(=high_memory)上,而896MB之后的物理内存则不按照0xC0000000偏移建立映射,这部分内存就叫高端物理内存。此时内核线性地址空间high_memory~0xFFFFFFFF之间的128MB空间就称为高端内存线性地址空间。
在嵌入式系统中可以根据具体情况修改896MB这个阈值。比如,MIPS中将这个值设置为0x20000000(512MB),那么只有当系统中的物理内存空间容量大于512MB时,内核才需要配置CONFIG_HIGHMEM选项,使能内核对高端内存的分配和映射功能。
高端内存的映射方法在下一讲中讲述。进程对于高端物理内存天然地可以通过设置CR3和页目录表合法访问。
固定内存映射中的高端内存映射
我们看到内核线性地址第四个GB的前最多896MB部分映射系统的物理内存。其余至少128MB的线性地址总是留作他用,例如将IO和BIOS以及物理地址空间映射到在这128M的地址空间内,使得kernel能够访问该空间并进行相应的读写操作;还用来临时映射高端内存,使得内核能够访问高端内存。
其中有一段虚拟地址用于固定映射,也就是fixed map。固定映射的线性地址(fix-mapped linear address)是一个固定的线性地址,它所对应的物理地址是人为强制指定的。每个固定的线性地址都映射到一块物理内存页。固定映射线性地址能够映射到任何一页物理内存。
每个固定映射的线性地址都由定义于enum fixed_addresses枚举数据结构中的整型索引来表示:
enum fixed_addresses {
FIX_HOLE,
FIX_VDSO,
FIX_DBGP_BASE,
FIX_EARLYCON_MEM_BASE,
#ifdef CONFIG_PROVIDE_OHCI1394_DMA_INIT
FIX_OHCI1394_BASE,
#endif
#ifdef CONFIG_X86_LOCAL_APIC
FIX_APIC_BASE, /* local (CPU) APIC) -- required for SMP or not */
#endif
#ifdef CONFIG_X86_IO_APIC
FIX_IO_APIC_BASE_0,
FIX_IO_APIC_BASE_END = FIX_IO_APIC_BASE_0 + MAX_IO_APICS - 1,
#endif
#ifdef CONFIG_X86_VISWS_APIC
FIX_CO_CPU, /* Cobalt timer */
FIX_CO_APIC, /* Cobalt APIC Redirection Table */
FIX_LI_PCIA, /* Lithium PCI Bridge A */
FIX_LI_PCIB, /* Lithium PCI Bridge B */
#endif
#ifdef CONFIG_X86_F00F_BUG
FIX_F00F_IDT, /* Virtual mapping for IDT */
#endif
#ifdef CONFIG_X86_CYCLONE_TIMER
FIX_CYCLONE_TIMER, /*cyclone timer register*/
#endif
FIX_KMAP_BEGIN, /* reserved pte's for temporary kernel mappings */
FIX_KMAP_END = FIX_KMAP_BEGIN+(KM_TYPE_NR*NR_CPUS)-1,
#ifdef CONFIG_PCI_MMCONFIG
FIX_PCIE_MCFG,
#endif
#ifdef CONFIG_PARAVIRT
FIX_PARAVIRT_BOOTMAP,
#endif
FIX_TEXT_POKE1, /* reserve 2 pages for text_poke() */
FIX_TEXT_POKE0, /* first page is last, because allocation is backward */
__end_of_permanent_fixed_addresses,
/*
* 256 temporary boot-time mappings, used by early_ioremap(),
* before ioremap() is functional.
*
* If necessary we round it up to the next 256 pages boundary so
* that we can have a single pgd entry and a single pte table:
*/
#define NR_FIX_BTMAPS 64
#define FIX_BTMAPS_SLOTS 4
#define TOTAL_FIX_BTMAPS (NR_FIX_BTMAPS * FIX_BTMAPS_SLOTS)
FIX_BTMAP_END =
(__end_of_permanent_fixed_addresses ^
(__end_of_permanent_fixed_addresses + TOTAL_FIX_BTMAPS - 1)) &
-PTRS_PER_PTE
? __end_of_permanent_fixed_addresses + TOTAL_FIX_BTMAPS -
(__end_of_permanent_fixed_addresses & (TOTAL_FIX_BTMAPS - 1))
: __end_of_permanent_fixed_addresses,
FIX_BTMAP_BEGIN = FIX_BTMAP_END + TOTAL_FIX_BTMAPS - 1,
FIX_WP_TEST,
#ifdef CONFIG_INTEL_TXT
FIX_TBOOT_BASE,
#endif
__end_of_fixed_addresses
}; 这些线性地址都位于第四个GB的末端。在初始化阶段指定其映射的物理地址。
还是回到init_mem_mapping(void)里面,当低端内存完成分配以后,紧接着还有一个函数early_ioremap_page_table_range_init(),这个函数就是用来建立固定内存映射区域的。
518 void __init early_ioremap_page_table_range_init(void)
519 {
520 pgd_t *pgd_base = swapper_pg_dir;
521 unsigned long vaddr, end;
522
523 /*
524 * Fixed mappings, only the page table structure has to be
525 * created - mappings will be set by set_fixmap():
526 */
527 vaddr = __fix_to_virt(__end_of_fixed_addresses - 1) & PMD_MASK;
528 end = (FIXADDR_TOP + PMD_SIZE - 1) & PMD_MASK; //unsigned long __FIXADDR_TOP = 0xfffff000;
529 page_table_range_init(vaddr, end, pgd_base);
530 early_ioremap_reset();
531 }fix_to_virt()函数计算从给定索引开始的常量线性地址:
========== arch/x86/mm/pgtable_32.c 98 98 ===============
unsigned long __FIXADDR_TOP = 0xfffff000;
============ arch/x86/include/asm/fixmap.h 41 41 ============
#define FIXADDR_TOP ((unsigned long)__FIXADDR_TOP)
==================== arch/x86/include/asm/fixmap.h 185 210 ====================
185 #define __fix_to_virt(x) (FIXADDR_TOP - ((x) << PAGE_SHIFT))
195 static __always_inline unsigned long fix_to_virt(const unsigned int idx)
196 {
206 if (idx >= __end_of_fixed_addresses)
207 __this_fixmap_does_not_exist();
208
209 return __fix_to_virt(idx);
210 }因此,每个固定映射的线性地址都映射一个物理内存的页框。但是各枚举标识的分区并不是从低地址往高地址分布,而是从整个线性地址空间的最后4KB即线性地址0xfffff000向低地址进行分配。在最后4KB空间与固定映射线性地址空间的顶端空留一页(未知原因),固定映射线性地址空间前面的地址空间叫做vmalloc分配的区域,他们之间也空有一页。
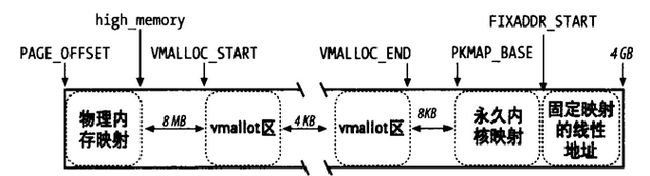
下一讲将详细描述内核线性地址空间分布图。
有了这个固定映射的线性地址后,如何把一个物理地址与固定映射的线性地址关联起来呢,内核使用set_fixmap(idx, phys)和set_fixmap_nocache(idx, phys)宏。这两个函数都把fix_to_virt(idx)线性地址对应的一个页表项初始化为物理地址phys(注意,页目录地址仍然在swapper_pg_dir中,这里只需要设置页表项);不过,第二个函数也把页表项的PCD标志置位,因此,当访问这个页框中的数据时禁用硬件高速缓存反过来,clear_fixmap(idx)用来撤消固定映射线性地址idx和物理地址之间的连接。
这个固定地址映射到底拿来做什么用呢?一般用来代替一些经常用到的指针。我们想想,就指针变量而言,固定映射的线性地址更有效。事实上,间接引用一个指针变量比间接引用一个立即常量地址要多一次内存访问。比如,我们设置一个FIX_APIC_BASE指针,其所指对象之间存在于对应的物理内存中,我们通过set_fixmap和clear_fixmap建立好二者的关系以后,就可以直接寻址了,没有必要像指针那样再去间接一次寻址。
最后init_mem_mapping()调用load_cr3()刷新CR3寄存器,__flush_tlb_all()则用于刷新TLB,由此启用新的内存分页映射。
至此,内核页表建立完毕。
因此对于内核来讲其映射是个简单的线性映射,只需要加减一个两者间的偏移量0xC0000000即可。该值在代码中称为PAGE_OFFSET,在arch/x86/include/asm/page_types.h中定义。同时PAGE_OFFSET也代表用户空间的上限,所以常数TASK_SIZE就是用它定义的(arch/x86/include/asm/processor.h)。
从内核页表建立过程可以看出,固定偏移是后续的基础。如果没有这个固定偏移,页式寻址就成为一个鸡生蛋蛋生鸡的问题了,因为进程切换时页目录表的基地址CR3是个物理地址,如果内核连这个物理地址也没办法计算,那么就没有办法实现页式寻址。实际上内核确实是使用pa()宏获得CR3里的值的。
进程的页映射在进程启动过程中确定,具体过程在第三讲详述。
Linux寻址的加速
Linux内核使用了一些技术,提高了硬件高速缓存和TLB的命中效率,实现寻址过程的加速。
高速缓存
高速缓存按照缓存行Cahce Line为单位寻址,在Pentium4之前的Intel模型中CacheLine为32字节,而Pentium 4上缓冲行为128字节。为了使高速缓存的命中率达到最优化,内核在决策中考虑体系结构:
- 一个数据结构中最常使用的字段放在数据结构的低偏移部分,以便他们能处于高速缓存的同一行。
- 当为一大组数据结构分配空间时,内核试图把它们都存放在内存中,以便所有高速缓存行都按照同一方式使用。
80x86的微处理器能够自动处理高速缓存的同步,但是有些处理器却不能。Linux内核为这些不能同步高速缓存的处理器提供了高速缓存刷新接口。
x86体系中当CR3替换时,处理器将所有TLB自动置无效。除此之外处理器不知道TLB缓存是否有效,因此不能自动同步自己的TLB高速缓存。需要由内核处理TLB的刷新。Linux内核提供了多种独立于体系结构的TLB宏,针对不同体系结构选择是否实现。
TLB
一般来讲进程切换意味着要更换活动页表集,对于过期页表,内核把新的CR3写入完成刷新,但是为了效率期间,有些情况下Linux会避免TLB刷新。
当两个使用相同页表集的普通进程之间切换时。后续进程管理章节讲述schedule()函数时候详述。
当一个普通进程和一个内核线程之间切换时。在之后第三讲进程地址空间中将会讲到,内核线程没有自己的页表集,它们使用刚刚在CPU上执行过的进程的页表集。因为内核线程基本上只使用内核地址空间的信息,这些信息与进程地址空间的高1G线性空间那部分相同。
除了进程切换外,还有一些情况内核需要刷新TLB中的一些表项。例如在内核为某个用户态进程分配页框并将它的物理地址存入页表项时,它必须刷新与相应线性地址对应的TLB表项。
为了避免无效刷新,内核使用一种叫做懒惰TLB(Lazy TLB)模式的技术。其基本思想是,如果有多个CPU在使用相同的页表,而且必须对这些CPU上的一个TLB表项进行刷新,那么在某些情况下正在运行内核线程的那些CPU上的刷新就可以延迟。
当某个CPU正在运行一个内核线程时,内核把它设置为懒惰TLB模式,当发出清除TLB表项的请求时,并不立即清除,而是标记对应的进程地址空间无效。只要有一个懒惰TLB模式的CPU用一个不同的页表集切换到一个普通进程,硬件就自动刷新,同时把CPU置为非懒惰模式。然而如果切换到一个同样页表集的进程,那么内核需要自己实施刷新操作。
内核使用一些额外的数据结构实现懒惰TLB。这些数据结构的具体用法涉及到进程调度,不在这里详细描述。
==================== arch/x86/include/asm/tlbflush.h 148 154 ====================
148 #define TLBSTATE_OK 1
149 #define TLBSTATE_LAZY 2
150
151 struct tlb_state {
152 struct mm_struct *active_mm;
153 int state;
154 };
==================== arch/x86/mm/tlb.c 16 17 ====================
16 DEFINE_PER_CPU_SHARED_ALIGNED(struct tlb_state, cpu_tlbstate)
17 = { &init_mm, 0, };总结与预告
Intel在发展过程中为了兼容过去的处理模式,采用了分段加分页的寻址实现方式,使得寻址过程异常复杂。但是硬件上的一些设计使得这种冗余模式保持了一定的效率。
Linux为了提供跨平台支持,没有跟随x86的段式管理意图,而是使得偏移量等于线性地址。完全依赖分页机制。同时还提供了一些技术实现寻址的加速。
Linux的分页机制在初始化过程中逐步建立。
下期:
页框管理、高端内存页框的内核映射、内存区管理。
本文的部分图片来自《程序员的自我修养——链接、装载与库》、《深入理解计算机系统》和《Linux内核完全注释》。
汇编部分的详细注解亦可参考http://blog.csdn.net/yu616568/article/details/7581919