第十六届全国大学生信息安全竞赛 ——创新实践能力赛线上初赛------WP
相关wp链接:第十六届全国大学生信息安全竞赛 初赛 Writeup by X1cT34m | 小绿草信息安全实验室
2023全国大学生信息安全竞赛AGCTF战队WP-腾讯云开发者社区-腾讯云
2023年第十六届全国大学生信息安全竞赛能力赛部分(WP)_Sentry_Shork的博客-CSDN博客
题目来源:
NSSCTF的CISCN的赛后环境
【1】被加密的生产流量
用wireshark打开modbus.pcap文件,追踪TCP流

出现等号,我们知道
base32加密特征:密文由32个字符(A-Z,2-7)组成,末尾可能会有‘=’,但最多有6

进行base32解密即可得到flag值

flag{c1f_fi1g_1000}
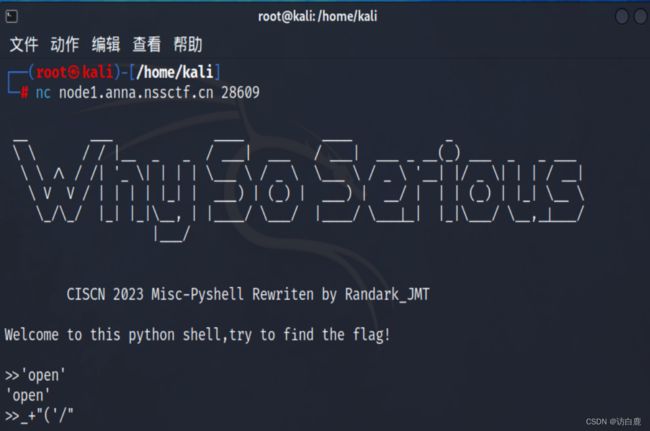
【2】Pyshell
打开题目

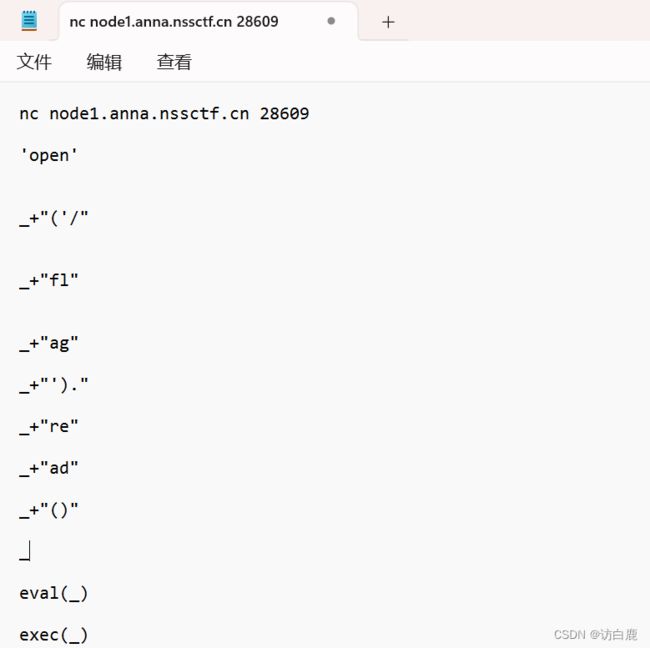
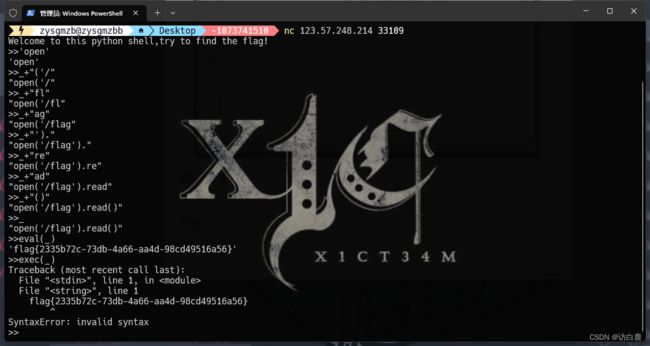
通过测试和题目名称得知存在python沙盒逃逸并且一次只能输入7个字符串,使用+进行拼接调用eval函数成功执行命令
逐条输入指令得到flag
得到flag
【3】Sign_in_passwd
打开题目
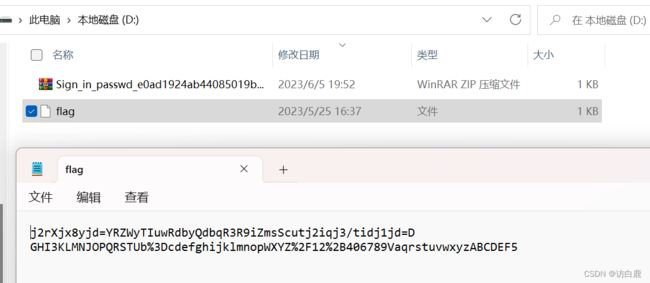
Base64加密特征:一般情况下结尾都会有 1 个或者 2 个等号,明文很少的时候可能没有;

【4】国粹
相关wp链接:NSSCTF | 在线CTF平台
打开题目
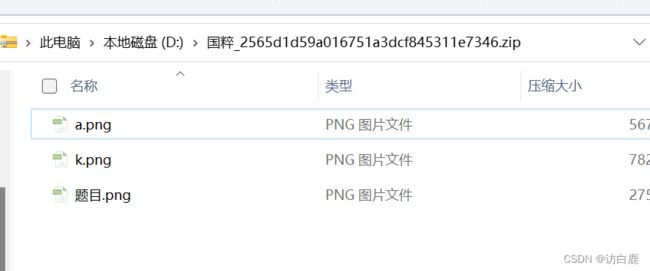
查看a.png和k.png的图片属性,发现宽都是18073的像素
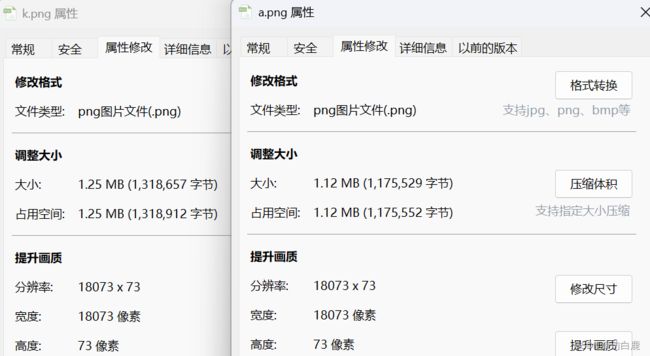
找在线因式分解的网站,对18073进行因式分解,发现11x31x53=18073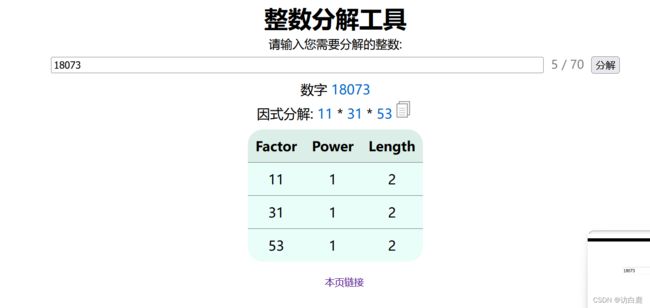
因为图片的高度为73,所以我们可以猜测每一张牌的宽度为53,共有11x31=341张牌
那a.png和b.png所列出的就各有341张牌
题目的牌数,我们可以直接数出来为42张
按照一一对应的关系,那就多出来一张牌


此时观察不难发现,a.png里面的图片,重复的大多都放在一起,k.png重复的图片就存在跳跃性,我们便可以猜测是坐标,是xy对应的关系
这时候我们就需要把a.png和k.png里面的图片按顺序切割转换为数字,将数字转换为坐标对应起来
我们只需要在网上搜索ctf图片按顺序切割脚本Python就可以将两张图片都切割出来
脚本见:CTF 图片按顺序分割脚本 Python_ctf 图片切分_青少年CTF训练平台的博客-CSDN博客
# -*- coding: utf-8 -*-
# 青少年网络安全 2022 03 30
from PIL import Image
filename = r'what.png'
img = Image.open(filename)
size = img.size
print(size)
# 大小为根号100
# 准备将图片切割成100张小图片
weight = int(size[0] // 10)
height = int(size[1] // 10)
# 切割后的小图的宽度和高度
print(weight, height)
for j in range(10):
for i in range(10):
box = (weight * i, height * j, weight * (i + 1), height * (j + 1))
region = img.crop(box)
region.save('misc\\zxsctf_{}{}.png'.format(j, i))图片大小为73x53
通过比较图片 md5 的方式进行,将 k 里的图片按照顺序生成 md5 值,将
md5 值作为键,对应的序号作为值创建字典,然后 a、k 的文件夹用 for 循环依次遍历,每
次都计算图片的 md5 值,然后去查字典,取出相应的数值,由此可以得到两个坐标数组,
但是两张不同图片分割后虽然内容相同,但是图片的md5 值不同
因此我们需要再找个脚本
将 python判断两张图片是否相同的脚本 和 md5比较脚本 结合
第一个脚本见:python 判断 图片是否相同_断言图像是否一样_AI视觉网奇的博客-CSDN博客
import cv2
import numpy as np
image1 = cv2.imread("1.png")
image2 = cv2.imread("22.png")
difference = cv2.subtract(image1, image2)
result = not np.any(difference) #if difference is all zeros it will return False
if result is True:
print("两张图片一样")
else:
cv2.imwrite("result.jpg", difference)
print ("两张图片不一样")改后的脚本为:
import cv2
import numpy as np
def check_pic(file1,file2):
image1 = cv2.imread(file1)
image2 = cv2.imread(file2)
difference = cv2.subtract(image1,image2)
result=not np.any(difference)
if result is True:
return True
else:
return False
#return image1.any() == image2.any()
x=[]
for i in range(341):
for j in range(1,43):
file1=a图片的地址+str(i)+'.png'
file2=k图片的地址+str(j)+'.png'
if check_pic(file1,file2):
x.append(j)
break
y=[]
for i in range(341):
for j in range(1,43):
file1=a图片的地址+str(i)+'.png'
file2=k图片的地址+str(j)+'.png'
if check_pic(file1,file2):
y.append(j)
break
print(x)
print(y)
运行以上脚本需要安装numpy库和cv2库,同时脚本中涉及到的地址需要用 '' \\ '' 来代替 '' \ ''
大家如果发现下载速度很慢,可以使用国内的镜像。
命令: pip install -i 国内镜像地址 numpy
国内常用源镜像地址:清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
豆瓣:http://pypi.douban.com/simple/
例如:pip install -i https://mirrors.aliyun.com/pypi/simple/ numpy
cv2库的安装教程:Python安装cv2库_cv2库怎么安装_DelaneyQ的博客-CSDN博客
但是上面的教程我自己尝试报错了