【Attack】针对GNN-based假新闻检测器
Attacking Fake News Detectors via Manipulating News Social Engagement
- Abstract
- Motivation
-
- Contributions
- Formulation
- Methodology
-
- Attacker Capability(针对挑战1)
- Agent Configuration(针对挑战3)

WWW’23, April 30-May 4, 2023, Austin, TX, USA.
Markov game, Deep Q-learning, Graph Neural Network
- 马尔科夫链博弈(Markov game)是指一个包含多个智能体(agents)的博弈过程,其中每个智能体的行动和状态演变是基于马尔科夫链的。马尔科夫链是指一个状态转移过程,未来的状态仅依赖于当前状态,与过去的状态无关。在博弈中,每个智能体的决策和行动都受到系统当前状态的影响,而系统状态的演变则遵循马尔科夫链的性质。
- DQN 使用 Q-learning 的更新规则,通过最小化 Q 函数的均方差损失来调整神经网络的参数。这涉及到使用目标网络计算目标 Q 值,然后更新主网络的参数以逼近这个目标。
Abstract
本文提出了第一个针对基于图神经网络(GNN)的假新闻检测器的对抗性攻击框架。具体来说,我们利用多代理强化学习(multi-agent reinforcement learning, MARL)框架来模拟社交媒体上欺诈者的对抗行为。研究表明,在现实世界中,欺诈者相互协调,分享不同的新闻,以逃避假新闻检测器的检测。因此,我们将我们的MARL框架建模为一个马尔可夫博弈,其中包含bot, cyborg, crowd worker agents。然后我们使用deep Q-learning(DQN)来搜索最大化奖励的最佳策略。
Motivation
真实世界的虚假信息活动为攻击模拟带来了三个不小的挑战:
1、为了在社交媒体上推广假新闻时逃避检测,malicious actor只能操作受控制的账户来分享不同的社交帖子,然而,大多数以前的GNN对抗攻击工作假设所有节点和边都可以被扰动,这是不切实际的。(也就是说,以前的对抗攻击方法假设可以对网络中的任何部分进行修改,但是比如在社交媒体上,malicious actor只能操作一部分受控制的账户进行虚假信息分享,而不能直接修改其他用户的节点和边。)
2、一些已部署的GNN模型用于虚假新闻检测,但由于这些模型的grey-box特性以及针对异构用户-帖子图的不同模型架构,以前的梯度优化攻击方法可能无法直接应用于这些模型。
3、各种协调的malicious actors参与了错误信息活动。不同类型的malicious actors具有不同的能力、预算和风险偏好。例如,关键的意见领袖比社交bot更大的影响力,但培养成本更高。
为了模拟分享不同帖子的欺诈者的真实行为,我们利用深度强化学习框架,通过修改分享帖子的用户的连接来翻转目标新闻节点的分类结果。
Contributions
- 第一个从社会参与(social engagement)的角度探索基于GNN的假新闻检测器的鲁棒性的工作。
- 利用MARL框架对基于GNN的假新闻检测器进行有针对性的攻击,以模拟真实世界的虚假信息活动。具体来说,我们将欺诈者建模为具有不同成本,预算和影响力的代理人。
- 实验结果表明,本文提出的MARL框架可以有效地翻转GNN预测结果。我们讨论了基于GNN的假新闻检测器的漏洞,并提供了攻击策略和对策的见解。
Formulation
攻击方法的目标:通过操纵受控恶意社交媒体用户帐户来分享新帖子,从而翻转目标社交帖子的GNN分类结果。
请注意,我们假设攻击者只能通过控制恶意用户共享新闻帖子来扰乱图,而不能删除现有的共享新闻帖子。
攻击目标正式定义为:
(最大化目标社交帖子的错误分类率)

U c U_c Uc:受控用户
E a E_a Ea:操纵边
V t V_t Vt:目标新闻帖子的集合
G G G:干净图
E ′ E^{'} E′是扰动边的集合
Δ u Δ_u Δu:受控用户的预算
Δ e Δ_e Δe:修改边的预算
Methodology
Attacker Capability(针对挑战1)
(1)直接攻击
假设有一个用户 ∈ 和一个目标新闻 ∈ 。如果 (, ) ∉ ,也就是说,在图中用户和目标新闻之间没有直接的边,那么通过让用户分享目标新闻,直接在用户和目标新闻之间创建一条边,就构成了直接攻击。
在实际场景中,如果一个被控制的用户之前分享了很多来自可信来源的内容,那么当这个用户分享了一篇虚假新闻时,通过创建直接边,就能够影响图结构,使得图神经网络(GNN)可能更倾向于认为这篇虚假新闻是可信的。这是因为通过直接边的添加,这个虚假新闻似乎与一个以前被认为可信的用户有了直接关联。
总的来说,直接攻击的要点是直接改变图结构中节点之间的边,以影响图神经网络的预测结果。
(2)间接攻击
对于用户 ∈ 和目标帖子 ∈ ,如果存在边 (, ) ∈ (即用户和目标新闻之间有直接边),则进行间接攻击。在这里,攻击是通过控制用户 来分享 ′ ∉ 来实施的,即用户分享了不属于可信源的内容。即,利用图神经网络(GNN)的邻居聚合机制,通过改变目标帖子的邻居来对目标帖子施加影响。
在实际场景中,如果一个被控制的用户之前分享了一篇虚假新闻,为了误导GNN对目标虚假新闻的预测,可以让这个用户分享一些来自可信来源的帖子。由于间接攻击不直接修改控制用户和目标新闻帖子之间的边,所以相对于直接攻击来说更不容易察觉。(洗白,不知道能不能这么说)
Agent Configuration(针对挑战3)
不同代理有不同的代价,比如bot user便宜但是能产生的影响也小一点,相反crowd workers昂贵但是对目标帖子的影响力更强。对不同的malicious actors group进行建模,单代理RL框架不适用,因此本文提出了multi-agent reinforcement learning(MARL)。
具体来说, 定义了三个代理。根据用户分享的新闻数量来划分用户账户:
(1)Agent1(Social Bots):由自动化程序注册并完全控制的社交机器人已被证明参与许多作品的假新闻传播。第一代理控制机器人用户,并且它具有低成本和高预算。我们随机选择数据集中只有一个连接的用户来代表新创建的机器人用户。
(2)Agent2(Cyborg Users):半机械人用户由人类注册,部分由自动化程序控制。人类和机器人之间的功能轻松切换为机器人提供了传播假新闻的独特机会。由于这些用户被归类为人类,因此他们通常具有更多的历史约定(即,与其他帖子的联系)。在我们的数据集中,我们随机选择连接数超过10的用户来代表受损用户。半机械人代理的成本、预算和影响介于其他两种代理之间。
(3)Agent3(Crowd Workers):人群工作者通常成本很高,因为他们每次活动都有报酬。同时,他们的影响力最大。我们选择了拥有20多个连接的用户,其中100%的用户连接到真实的新闻帖子,以代表人群工作者。
攻击框架:
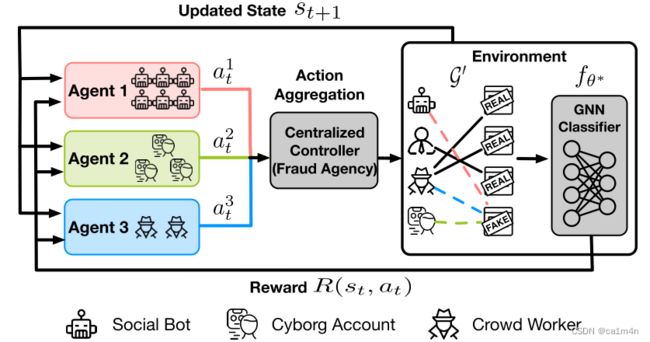
使用MARL执行间接目标攻击的结果与几个基线进行比较。实验重复五次,并报告平均成功率:
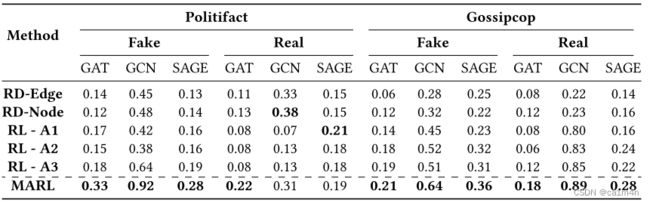
由于attacker受限的能力,MARL只和随机边、随机节点、单代理这五个baselines进行比较,而不将基于特征和梯度的攻击作为baselines。
在Politifact和Gossipcop数据集中,不同类型的代理对假新闻的间接攻击性能。GAT、GCN和GraphSAGE上的性能分别以蓝色、红色和绿色标记:

尽管我们从实验中得到了一些有希望的结果,但本文有两个主要的局限性:1)这项工作只采用了一个简单的启发式选择用户的动作聚合。2)Q网络的搜索空间相当大,导致在像Gossipcop这样的大型数据集上的计算成本很高。