java异常处理
1、java的异常
1)异常
在计算机程序运行的过程中,总是会出现各种各样的错误。
有一些错误是用户造成的,比如,希望用户输入一个int类型的年龄,但是用户的输入是abc:
// 假设用户输入了abc:
String s = "abc";
int n = Integer.parseInt(s); // NumberFormatException!
程序想要读写某个文件的内容,但是用户已经把它删除了:
// 用户删除了该文件:
String t = readFile("C:\\abc.txt"); // FileNotFoundException!
还有一些错误是随机出现,并且永远不可能避免的。比如:
- 网络突然断了,连接不到远程服务器;
- 内存耗尽,程序崩溃了;
- 用户点“打印”,但根本没有打印机;
……
所以,一个健壮的程序必须处理各种各样的错误。
所谓错误,就是程序调用某个函数的时候,如果失败了,就表示出错。
调用方如何获知调用失败的信息?有两种方法:
方法一:约定返回错误码。
例如,处理一个文件,如果返回0,表示成功,返回其他整数,表示约定的错误码:
int code = processFile("C:\\test.txt");
if (code == 0) {
// ok:
} else {
// error:
switch (code) {
case 1:
// file not found:
case 2:
// no read permission:
default:
// unknown error:
}
}
因为使用int类型的错误码,想要处理就非常麻烦。这种方式常见于底层C函数。
方法二:在语言层面上提供一个异常处理机制。
Java内置了一套异常处理机制,总是使用异常来表示错误。
异常是一种class,因此它本身带有类型信息。异常可以在任何地方抛出,但只需要在上层捕获,这样就和方法调用分离了:
try {
String s = processFile(“C:\\test.txt”);
// ok:
} catch (FileNotFoundException e) {
// file not found:
} catch (SecurityException e) {
// no read permission:
} catch (IOException e) {
// io error:
} catch (Exception e) {
// other error:
}
因为Java的异常是class,它的继承关系如下:
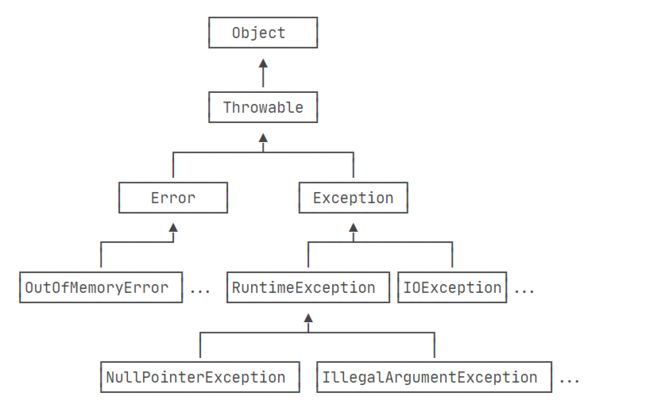


Exception又分为两大类:
- RuntimeException以及它的子类;
- 非RuntimeException(包括IOException、ReflectiveOperationException等等)
Java规定:
-
必须捕获的异常,包括Exception及其子类,但不包括RuntimeException及其子类,这种类型的异常称为Checked Exception。
-
不需要捕获的异常,包括Error及其子类,RuntimeException及其子类。
注意:编译器对RuntimeException及其子类不做强制捕获要求,不是指应用程序本身不应该捕获并处理RuntimeException。是否需要捕获,具体问题具体分析。
2)捕获异常
捕获异常使用try…catch语句,把可能发生异常的代码放到try {…}中,然后使用catch捕获对应的Exception及其子类:
// try...catch
import java.io.UnsupportedEncodingException;
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
byte[] bs = toGBK("中文");
System.out.println(Arrays.toString(bs));
}
static byte[] toGBK(String s) {
try {
// 用指定编码转换String为byte[]:
return s.getBytes("GBK");
} catch (UnsupportedEncodingException e) {
// 如果系统不支持GBK编码,会捕获到UnsupportedEncodingException:
System.out.println(e); // 打印异常信息
return s.getBytes(); // 尝试使用用默认编码
}
}
}
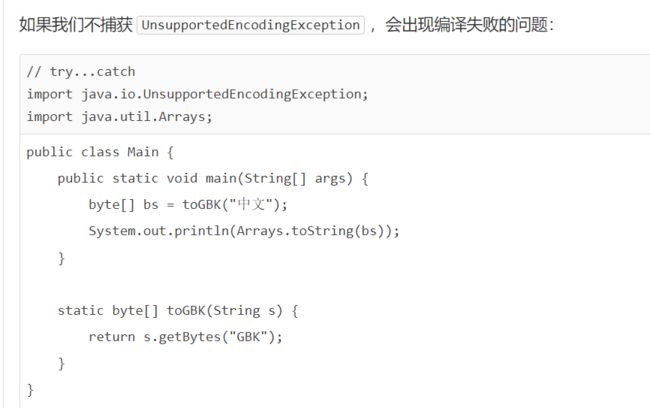
编译器会报错,错误信息类似:unreported exception UnsupportedEncodingException; must be caught or declared to be thrown,并且准确地指出需要捕获的语句是return s.getBytes(“GBK”);。意思是说,像UnsupportedEncodingException这样的Checked Exception,必须被捕获。
这是因为String.getBytes(String)方法定义是:
public byte[] getBytes(String charsetName) throws UnsupportedEncodingException {
...
}
在方法定义的时候,使用throws Xxx表示该方法可能抛出的异常类型。调用方在调用的时候,必须强制捕获这些异常,否则编译器会报错。
在toGBK()方法中,因为调用了String.getBytes(String)方法,就必须捕获UnsupportedEncodingException。我们也可以不捕获它,而是在方法定义处用throws表示toGBK()方法可能会抛出UnsupportedEncodingException,就可以让toGBK()方法通过编译器检查:

上述代码仍然会得到编译错误,但这一次,编译器提示的不是调用return s.getBytes(“GBK”);的问题,而是byte[] bs = toGBK(“中文”);。因为在main()方法中,调用toGBK(),没有捕获它声明的可能抛出的UnsupportedEncodingException。
修复方法是在main()方法中捕获异常并处理:
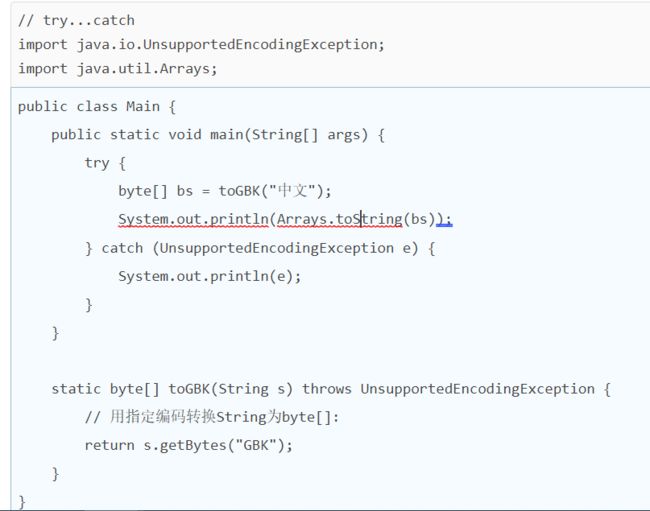
可见,只要是方法声明的Checked Exception,不在调用层捕获,也必须在更高的调用层捕获。所有未捕获的异常,最终也必须在main()方法中捕获,不会出现漏写try的情况。这是由编译器保证的。main()方法也是最后捕获Exception的机会。
如果是测试代码,上面的写法就略显麻烦。如果不想写任何try代码,可以直接把main()方法定义为throws Exception:
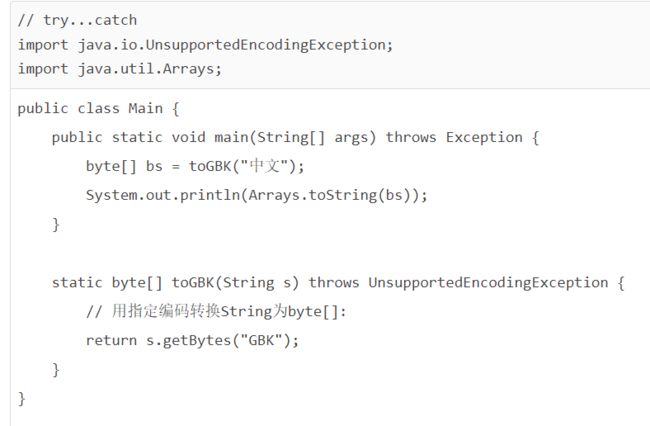
因为main()方法声明了可能抛出Exception,也就声明了可能抛出所有的Exception,因此在内部就无需捕获了。代价就是一旦发生异常,程序会立刻退出。
还有一些童鞋喜欢在toGBK()内部“消化”异常:
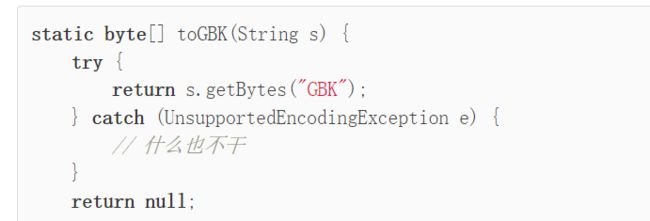
这种捕获后不处理的方式是非常不好的,即使真的什么也做不了,也要先把异常记录下来:
static byte[] toGBK(String s) {
try {
return s.getBytes("GBK");
} catch (UnsupportedEncodingException e) {
// 先记下来再说:
e.printStackTrace();
}
return null;
所有异常都可以调用printStackTrace()方法打印异常栈,这是一个简单有用的快速打印异常的方法。
3)小结
- Java使用异常来表示错误,并通过try … catch捕获异常;
- Java的异常是class,并且从Throwable继承;
- Error是无需捕获的严重错误,Exception是应该捕获的可处理的错误;
- RuntimeException无需强制捕获,非RuntimeException(Checked Exception)需强制捕获,或者用throws声明;
- 不推荐捕获了异常但不进行任何处理。
2、捕获异常
在Java中,凡是可能抛出异常的语句,都可以用try … catch捕获。把可能发生异常的语句放在try { … }中,然后使用catch捕获对应的Exception及其子类。
1)多catch语句
可以使用多个catch语句,每个catch分别捕获对应的Exception及其子类。
JVM在捕获到异常后,会从上到下匹配catch语句,匹配到某个catch后,执行catch代码块,然后不再继续匹配。
简单地说就是:多个catch语句只有一个能被执行。例如:
public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (IOException e) {
System.out.println(e);
} catch (NumberFormatException e) {
System.out.println(e);
}
}
存在多个catch的时候,**catch的顺序非常重要:子类必须写在前面。**例如:
public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (IOException e) {
System.out.println("IO error");
} catch (UnsupportedEncodingException e) { // 永远捕获不到
System.out.println("Bad encoding");
}
}
对于上面的代码,UnsupportedEncodingException异常是永远捕获不到的,因为它是IOException的子类。当抛出UnsupportedEncodingException异常时,会被catch (IOException e) { … }捕获并执行。
因此,正确的写法是把子类放到前面:
public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (UnsupportedEncodingException e) {
System.out.println("Bad encoding");
} catch (IOException e) {
System.out.println("IO error");
}
}
2)finally语句
无论是否有异常发生,如果我们都希望执行一些语句,例如清理工作,怎么写?
可以把执行语句写若干遍:正常执行的放到try中,每个catch再写一遍。例如:
public static void main(String[] args) {
try {
process1();
process2();
process3();
System.out.println("END");
} catch (UnsupportedEncodingException e) {
System.out.println("Bad encoding");
System.out.println("END");
} catch (IOException e) {
System.out.println("IO error");
System.out.println("END");
}
}
上述代码无论是否发生异常,都会执行System.out.println(“END”);这条语句。
那么如何消除这些重复的代码?Java的try … catch机制还提供了finally语句,finally语句块保证有无错误都会执行。上述代码可以改写如下:
public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (UnsupportedEncodingException e) {
System.out.println("Bad encoding");
} catch (IOException e) {
System.out.println("IO error");
} finally {
System.out.println("END");
}
}
注意finally有几个特点:
finally语句不是必须的,可写可不写;
finally总是最后执行。
如果没有发生异常,就正常执行try { … }语句块,然后执行finally。如果发生了异常,就中断执行try { … }语句块,然后跳转执行匹配的catch语句块,最后执行finally。
可见,finally是用来保证一些代码必须执行的。
某些情况下,可以没有catch,只使用try … finally结构。例如:
void process(String file) throws IOException {
try {
...
} finally {
System.out.println("END");
}
}
因为方法声明了可能抛出的异常,所以可以不写catch。
3)捕获多种异常
如果某些异常的处理逻辑相同,但是异常本身不存在继承关系,那么就得编写多条catch子句:
public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (IOException e) {
System.out.println("Bad input");
} catch (NumberFormatException e) {
System.out.println("Bad input");
} catch (Exception e) {
System.out.println("Unknown error");
}
}
因为处理IOException和NumberFormatException的代码是相同的,所以我们可以把它两用|合并到一起:
public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (IOException | NumberFormatException e) { // IOException或NumberFormatException
System.out.println("Bad input");
} catch (Exception e) {
System.out.println("Unknown error");
}
}
4)小结
使用try … catch … finally时:
-
多个catch语句的匹配顺序非常重要,子类必须放在前面;
-
finally语句保证了有无异常都会执行,它是可选的;
-
一个catch语句也可以匹配多个非继承关系的异常。
3、抛出异常
1)异常的传播
当某个方法抛出了异常时,如果当前方法没有捕获异常,异常就会被抛到上层调用方法,直到遇到某个try … catch被捕获为止:
public class Main {
public static void main(String[] args) {
try {
process1();
} catch (Exception e) {
e.printStackTrace();
}
}
static void process1() {
process2();
}
static void process2() {
Integer.parseInt(null); // 会抛出NumberFormatException
}
}
**通过printStackTrace()可以打印出方法的调用栈,**类似:
java.lang.NumberFormatException: null
at java.base/java.lang.Integer.parseInt(Integer.java:614)
at java.base/java.lang.Integer.parseInt(Integer.java:770)
at Main.process2(Main.java:16)
at Main.process1(Main.java:12)
at Main.main(Main.java:5)


2)抛出异常
当发生错误时,例如,用户输入了非法的字符,我们就可以抛出异常。
如何抛出异常?参考Integer.parseInt()方法,抛出异常分两步:
- 创建某个Exception的实例;
- 用throw语句抛出。
下面是一个例子:
void process2(String s) {
if (s==null) {
NullPointerException e = new NullPointerException();
throw e;
}
}
实际上,绝大部分抛出异常的代码都会合并写成一行:
void process2(String s) {
if (s==null) {
throw new NullPointerException();
}
}
如果一个方法捕获了某个异常后,又在catch子句中抛出新的异常,就相当于把抛出的异常类型“转换”了:
void process1(String s) {
try {
process2();
} catch (NullPointerException e) {
throw new IllegalArgumentException();
}
}
void process2(String s) {
if (s==null) {
throw new NullPointerException();
}
}
当process2()抛出NullPointerException后,被process1()捕获,然后抛出IllegalArgumentException()。
如果在main()中捕获IllegalArgumentException,我们看看打印的异常栈:
public class Main {
public static void main(String[] args) {
try {
process1();
} catch (Exception e) {
e.printStackTrace();
}
}
static void process1() {
try {
process2();
} catch (NullPointerException e) {
throw new IllegalArgumentException();
}
}
static void process2() {
throw new NullPointerException();
}
}

这说明新的异常丢失了原始异常信息,我们已经看不到原始异常NullPointerException的信息了。
为了能追踪到完整的异常栈,在构造异常的时候,把原始的Exception实例传进去,新的Exception就可以持有原始Exception信息。对上述代码改进如下:
public class Main {
public static void main(String[] args) {
try {
process1();
} catch (Exception e) {
e.printStackTrace();
}
}
static void process1() {
try {
process2();
} catch (NullPointerException e) {
throw new IllegalArgumentException(e);
}
}
static void process2() {
throw new NullPointerException();
}
}

在代码中获取原始异常可以使用Throwable.getCause()方法。如果返回null,说明已经是“根异常”了。
有了完整的异常栈的信息,我们才能快速定位并修复代码的问题。
捕获到异常并再次抛出时,一定要留住原始异常,否则很难定位第一案发现场!
**如果我们在try或者catch语句块中抛出异常,finally语句是否会执行?**例如:
public class Main {
public static void main(String[] args) {
try {
Integer.parseInt("abc");
} catch (Exception e) {
System.out.println("catched");
throw new RuntimeException(e);
} finally {
System.out.println("finally");
}
}
}

因此,在catch中抛出异常,不会影响finally的执行。JVM会先执行finally,然后抛出异常。
3)异常屏蔽
**如果在执行finally语句时抛出异常,那么,catch语句的异常还能否继续抛出?**例如:
public class Main {
public static void main(String[] args) {
try {
Integer.parseInt("abc");
} catch (Exception e) {
System.out.println("catched");
throw new RuntimeException(e);
} finally {
System.out.println("finally");
throw new IllegalArgumentException();
}
}
}
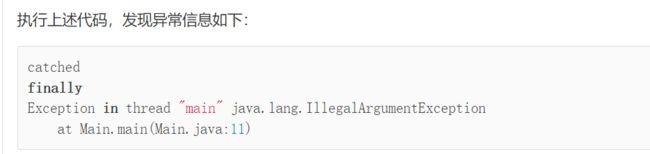
这说明finally抛出异常后,原来在catch中准备抛出的异常就“消失”了,因为只能抛出一个异常。没有被抛出的异常称为“被屏蔽”的异常(Suppressed Exception)。
在极少数的情况下,我们需要获知所有的异常。如何保存所有的异常信息?方法是先用origin变量保存原始异常,然后调用Throwable.addSuppressed(),把原始异常添加进来,最后在finally抛出:
public class Main {
public static void main(String[] args) throws Exception {
Exception origin = null;
try {
System.out.println(Integer.parseInt("abc"));
} catch (Exception e) {
origin = e;
throw e;
} finally {
Exception e = new IllegalArgumentException();
if (origin != null) {
e.addSuppressed(origin);
}
throw e;
}
}
}
当catch和finally都抛出了异常时,虽然catch的异常被屏蔽了,但是,finally抛出的异常仍然包含了它:

通过Throwable.getSuppressed()可以获取所有的Suppressed Exception。
绝大多数情况下,在finally中不要抛出异常。因此,我们通常不需要关心Suppressed Exception。
4)提问时贴出异常
异常打印的详细的栈信息是找出问题的关键,许多初学者在提问时只贴代码,不贴异常,相当于只报案不给线索,福尔摩斯也无能为力。
还有的童鞋只贴部分异常信息,最关键的Caused by: xxx给省略了,这都属于不正确的提问方式,得改。
5)小结
-
调用printStackTrace()可以打印异常的传播栈,对于调试非常有用;
-
捕获异常并再次抛出新的异常时,应该持有原始异常信息;
-
通常不要在finally中抛出异常。如果在finally中抛出异常,应该原始异常加入到原有异常中。调用方可通过Throwable.getSuppressed()获取所有添加的Suppressed Exception。
4、自定义异常
1)自定义异常
Java标准库定义的常用异常包括:

当我们在代码中需要抛出异常时,尽量使用JDK已定义的异常类型。例如,参数检查不合法,应该抛出IllegalArgumentException:
static void process1(int age) {
if (age <= 0) {
throw new IllegalArgumentException();
}
}
在一个大型项目中,可以自定义新的异常类型,但是,保持一个合理的异常继承体系是非常重要的。
一个常见的做法是自定义一个BaseException作为“根异常”,然后,派生出各种业务类型的异常。
BaseException需要从一个适合的Exception派生,通常建议从RuntimeException派生:
public class BaseException extends RuntimeException {
}
其他业务类型的异常就可以从BaseException派生:
public class UserNotFoundException extends BaseException {
}
public class LoginFailedException extends BaseException {
}
...
自定义的BaseException应该提供多个构造方法:
public class BaseException extends RuntimeException {
public BaseException() {
super();
}
public BaseException(String message, Throwable cause) {
super(message, cause);
}
public BaseException(String message) {
super(message);
}
public BaseException(Throwable cause) {
super(cause);
}
}
上述构造方法实际上都是原样照抄RuntimeException。这样,抛出异常的时候,就可以选择合适的构造方法。通过IDE可以根据父类快速生成子类的构造方法。
2)小结
-
抛出异常时,尽量复用JDK已定义的异常类型;
-
自定义异常体系时,推荐从RuntimeException派生“根异常”,再派生出业务异常;
-
自定义异常时,应该提供多种构造方法。
5、NullPointerException
1)NullPointerException
在所有的RuntimeException异常中,Java程序员最熟悉的恐怕就是NullPointerException了。
NullPointerException即空指针异常,俗称NPE。如果一个对象为null,调用其方法或访问其字段就会产生NullPointerException,这个异常通常是由JVM抛出的,例如:
public class Main {
public static void main(String[] args) {
String s = null;
System.out.println(s.toLowerCase());
}
}
指针这个概念实际上源自C语言,Java语言中并无指针。我们定义的变量实际上是引用,Null Pointer更确切地说是Null Reference,不过两者区别不大。
2)处理NullPointerException
如果遇到NullPointerException,我们应该如何处理?首先,必须明确,NullPointerException是一种代码逻辑错误,遇到NullPointerException,遵循原则是早暴露,早修复,严禁使用catch来隐藏这种编码错误:
// 错误示例: 捕获NullPointerException
try {
transferMoney(from, to, amount);
} catch (NullPointerException e) {
}
好的编码习惯可以极大地降低NullPointerException的产生,例如:
成员变量在定义时初始化:
public class Person {
private String name = "";
}
使用空字符串""而不是默认的null可避免很多NullPointerException,编写业务逻辑时,用空字符串""表示未填写比null安全得多。
返回空字符串""、空数组而不是null:
public String[] readLinesFromFile(String file) {
if (getFileSize(file) == 0) {
// 返回空数组而不是null:
return new String[0];
}
...
}
这样可以使得调用方无需检查结果是否为null。
如果调用方一定要根据null判断,比如返回null表示文件不存在,那么考虑返回Optional:
public Optional readFromFile(String file) {
if (!fileExist(file)) {
return Optional.empty();
}
...
}
这样调用方必须通过Optional.isPresent()判断是否有结果。
3)定位NullPointerException
如果产生了NullPointerException,例如,调用a.b.c.x()时产生了NullPointerException,原因可能是:

从Java 14开始,如果产生了NullPointerException,JVM可以给出详细的信息告诉我们null对象到底是谁。我们来看例子:
public class Main {
public static void main(String[] args) {
Person p = new Person();
System.out.println(p.address.city.toLowerCase());
}
}
class Person {
String[] name = new String[2];
Address address = new Address();
}
class Address {
String city;
String street;
String zipcode;
}
可以在NullPointerException的详细信息中看到类似… because “.address.city” is null,意思是city字段为null,这样我们就能快速定位问题所在。
这种增强的NullPointerException详细信息是Java 14新增的功能,但默认是关闭的,我们可以给JVM添加一个-XX:+ShowCodeDetailsInExceptionMessages参数启用它:
java -XX:+ShowCodeDetailsInExceptionMessages Main.java
4)小结
-
NullPointerException是Java代码常见的逻辑错误,应当早暴露,早修复;
-
可以启用Java 14的增强异常信息来查看NullPointerException的详细错误信息。
6、使用断言
1)断言
断言(Assertion)是一种调试程序的方式。在Java中,使用assert关键字来实现断言。
我们先看一个例子:
public static void main(String[] args) {
double x = Math.abs(-123.45);
assert x >= 0;
System.out.println(x);
}
语句assert x >= 0;即为断言,断言条件x >= 0预期为true。如果计算结果为false,则断言失败,抛出AssertionError。
使用assert语句时,还可以添加一个可选的断言消息:
assert x >= 0 : "x must >= 0";
这样,断言失败的时候,AssertionError会带上消息x must >= 0,更加便于调试。
Java断言的特点是:断言失败时会抛出AssertionError,导致程序结束退出。因此,断言不能用于可恢复的程序错误,只应该用于开发和测试阶段。
对于可恢复的程序错误,不应该使用断言。例如:
void sort(int[] arr) {
assert arr != null;
}
应该抛出异常并在上层捕获:
void sort(int[] arr) {
if (arr == null) {
throw new IllegalArgumentException("array cannot be null");
}
}
当我们在程序中使用assert时,例如,一个简单的断言:
public class Main {
public static void main(String[] args) {
int x = -1;
assert x > 0;
System.out.println(x);
}
}
断言x必须大于0,实际上x为-1,断言肯定失败。执行上述代码,发现程序并未抛出AssertionError,而是正常打印了x的值。
这是怎么肥四?为什么assert语句不起作用?
这是因为JVM默认关闭断言指令,即遇到assert语句就自动忽略了,不执行。
要执行assert语句,必须给Java虚拟机传递-enableassertions(可简写为-ea)参数启用断言。所以,上述程序必须在命令行下运行才有效果:
$ java -ea Main.java
Exception in thread "main" java.lang.AssertionError
at Main.main(Main.java:5)
还可以有选择地对特定地类启用断言,命令行参数是:-ea:com.itranswarp.sample.Main,表示只对com.itranswarp.sample.Main这个类启用断言。
或者对特定地包启用断言,命令行参数是:-ea:com.itranswarp.sample…(注意结尾有3个.),表示对com.itranswarp.sample这个包启动断言。
实际开发中,很少使用断言。更好的方法是编写单元测试,后续我们会讲解JUnit的使用。
2)小结
-
断言是一种调试方式,断言失败会抛出AssertionError,只能在开发和测试阶段启用断言;
-
对可恢复的错误不能使用断言,而应该抛出异常;
-
断言很少被使用,更好的方法是编写单元测试。
7、使用JDK Logging
1)使用JDK Logging
在编写程序的过程中,发现程序运行结果与预期不符,怎么办?当然是用System.out.println()打印出执行过程中的某些变量,观察每一步的结果与代码逻辑是否符合,然后有针对性地修改代码。
代码改好了怎么办?当然是删除没有用的System.out.println()语句了。
如果改代码又改出问题怎么办?再加上System.out.println()。
反复这么搞几次,很快大家就发现使用System.out.println()非常麻烦。
怎么办?
解决方法是使用日志。
那什么是日志?日志就是Logging,它的目的是为了取代System.out.println()。
输出日志,而不是用System.out.println(),有以下几个好处:
可以设置输出样式,避免自己每次都写"ERROR: " + var;
可以设置输出级别,禁止某些级别输出。例如,只输出错误日志;
可以被重定向到文件,这样可以在程序运行结束后查看日志;
可以按包名控制日志级别,只输出某些包打的日志;
可以……
总之就是好处很多啦。
那如何使用日志?
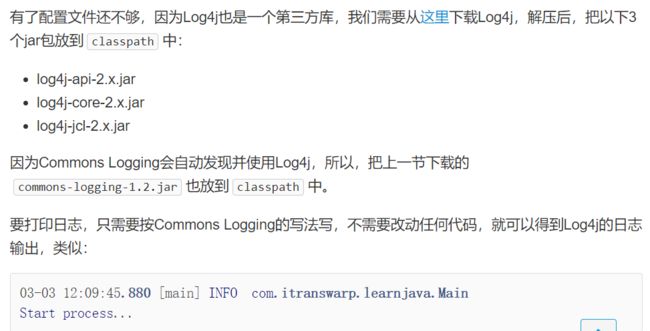
因为Java标准库内置了日志包java.util.logging,我们可以直接用。先看一个简单的例子:
// logging
import java.util.logging.Level;
import java.util.logging.Logger;
public class Hello {
public static void main(String[] args) {
Logger logger = Logger.getGlobal();
logger.info("start process...");
logger.warning("memory is running out...");
logger.fine("ignored.");
logger.severe("process will be terminated...");
}
}
运行上述代码,得到类似如下的输出:
Mar 02, 2019 6:32:13 PM Hello main
INFO: start process...
Mar 02, 2019 6:32:13 PM Hello main
WARNING: memory is running out...
Mar 02, 2019 6:32:13 PM Hello main
SEVERE: process will be terminated...
对比可见,使用日志最大的好处是,它自动打印了时间、调用类、调用方法等很多有用的信息。
再仔细观察发现,4条日志,只打印了3条,logger.fine()没有打印。这是因为,日志的输出可以设定级别。JDK的Logging定义了7个日志级别,从严重到普通:
SEVERE
WARNING
INFO
CONFIG
FINE
FINER
FINEST
因为默认级别是INFO,因此,INFO级别以下的日志,不会被打印出来。使用日志级别的好处在于,调整级别,就可以屏蔽掉很多调试相关的日志输出。
使用Java标准库内置的Logging有以下局限:
-
Logging系统在JVM启动时读取配置文件并完成初始化,一旦开始运行main()方法,就无法修改配置;
-
配置不太方便,需要在JVM启动时传递参数-Djava.util.logging.config.file=。
因此,Java标准库内置的Logging使用并不是非常广泛。更方便的日志系统我们稍后介绍。
2)小结
-
日志是为了替代System.out.println(),可以定义格式,重定向到文件等;
-
日志可以存档,便于追踪问题;
-
日志记录可以按级别分类,便于打开或关闭某些级别;
-
可以根据配置文件调整日志,无需修改代码;
-
Java标准库提供了java.util.logging来实现日志功能。
8、使用Commons Logging
1)使用Commons Logging
和Java标准库提供的日志不同,Commons Logging是一个第三方日志库,它是由Apache创建的日志模块。
Commons Logging的特色是,它可以挂接不同的日志系统,并通过配置文件指定挂接的日志系统。默认情况下,Commons Loggin自动搜索并使用Log4j(Log4j是另一个流行的日志系统),如果没有找到Log4j,再使用JDK Logging。
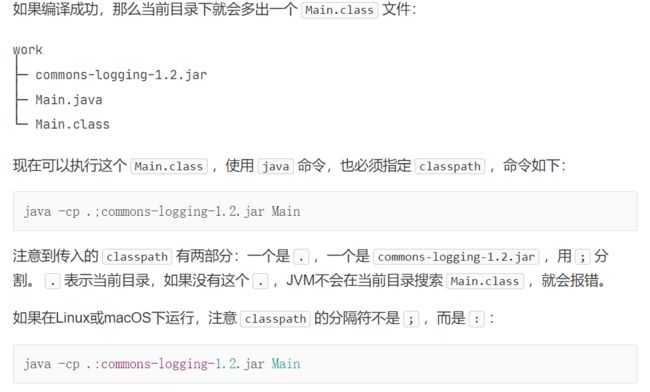
使用Commons Logging只需要和两个类打交道,并且只有两步:
第一步,通过LogFactory获取Log类的实例; 第二步,使用Log实例的方法打日志。
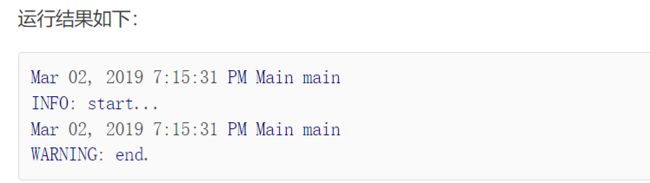
示例代码如下:
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
public class Main {
public static void main(String[] args) {
Log log = LogFactory.getLog(Main.class);
log.info("start...");
log.warn("end.");
}
}


使用Commons Logging时,如果在静态方法中引用Log,通常直接定义一个静态类型变量:
// 在静态方法中引用Log:
public class Main {
static final Log log = LogFactory.getLog(Main.class);
static void foo() {
log.info("foo");
}
}
在实例方法中引用Log,通常定义一个实例变量:
// 在实例方法中引用Log:
public class Person {
protected final Log log = LogFactory.getLog(getClass());
void foo() {
log.info("foo");
}
}
注意到实例变量log的获取方式是LogFactory.getLog(getClass()),虽然也可以用LogFactory.getLog(Person.class),但是前一种方式有个非常大的好处,就是子类可以直接使用该log实例。例如:

由于Java类的动态特性,子类获取的log字段实际上相当于LogFactory.getLog(Student.class),但却是从父类继承而来,并且无需改动代码。
此外,Commons Logging的日志方法,例如info(),除了标准的info(String)外,还提供了一个非常有用的重载方法:info(String, Throwable),这使得记录异常更加简单:
try {
...
} catch (Exception e) {
log.error("got exception!", e);
}
2)小结
-
Commons Logging是使用最广泛的日志模块;
-
Commons Logging的API非常简单;
-
Commons Logging可以自动检测并使用其他日志模块。
9、使用Log4j
1)Log4j
前面介绍了Commons Logging,可以作为“日志接口”来使用。而真正的“日志实现”可以使用Log4j。
Log4j是一种非常流行的日志框架,最新版本是2.x。
Log4j是一个组件化设计的日志系统,它的架构大致如下:
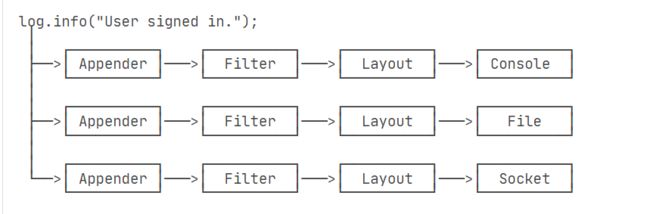
当我们使用Log4j输出一条日志时,**Log4j自动通过不同的Appender把同一条日志输出到不同的目的地。**例如:
- console:输出到屏幕;
- file:输出到文件;
- socket:通过网络输出到远程计算机;
- jdbc:输出到数据库
在输出日志的过程中,通过Filter来过滤哪些log需要被输出,哪些log不需要被输出。例如,仅输出ERROR级别的日志。
最后,通过Layout来格式化日志信息,例如,自动添加日期、时间、方法名称等信息。
上述结构虽然复杂,但我们在实际使用的时候,并不需要关心Log4j的API,而是通过配置文件来配置它。
以XML配置为例,使用Log4j的时候,我们把一个log4j2.xml的文件放到classpath下就可以让Log4j读取配置文件并按照我们的配置来输出日志。下面是一个配置文件的例子:
%d{MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36}%n%msg%n%n
log/err.log
log/err.%i.log.gz
虽然配置Log4j比较繁琐,但一旦配置完成,使用起来就非常方便。对上面的配置文件,凡是INFO级别的日志,会自动输出到屏幕,而ERROR级别的日志,不但会输出到屏幕,还会同时输出到文件。并且,一旦日志文件达到指定大小(1MB),Log4j就会自动切割新的日志文件,并最多保留10份。
2)最佳实践
在开发阶段,始终使用Commons Logging接口来写入日志,并且开发阶段无需引入Log4j。如果需要把日志写入文件, 只需要把正确的配置文件和Log4j相关的jar包放入classpath,就可以自动把日志切换成使用Log4j写入,无需修改任何代码。
3)小结
-
通过Commons Logging实现日志,不需要修改代码即可使用Log4j;
-
使用Log4j只需要把log4j2.xml和相关jar放入classpath;
-
如果要更换Log4j,只需要移除log4j2.xml和相关jar;
-
只有扩展Log4j时,才需要引用Log4j的接口(例如,将日志加密写入数据库的功能,需要自己开发)。
10、使用SLF4J和Logback
1)使用SLF4J和Logback
前面介绍了Commons Logging和Log4j这一对好基友,它们一个负责充当日志API,一个负责实现日志底层,搭配使用非常便于开发。
有的童鞋可能还听说过SLF4J和Logback。这两个东东看上去也像日志,它们又是啥?
其实SLF4J类似于Commons Logging,也是一个日志接口,而Logback类似于Log4j,是一个日志的实现。
为什么有了Commons Logging和Log4j,又会蹦出来SLF4J和Logback?这是因为Java有着非常悠久的开源历史,不但OpenJDK本身是开源的,而且我们用到的第三方库,几乎全部都是开源的。开源生态丰富的一个特定就是,同一个功能,可以找到若干种互相竞争的开源库。
因为对Commons Logging的接口不满意,有人就搞了SLF4J。因为对Log4j的性能不满意,有人就搞了Logback。
我们先来看看SLF4J对Commons Logging的接口有何改进。在Commons Logging中,我们要打印日志,有时候得这么写:
int score = 99;
p.setScore(score);
log.info("Set score " + score + " for Person " + p.getName() + " ok.");
拼字符串是一个非常麻烦的事情,所以SLF4J的日志接口改进成这样了:
int score = 99;
p.setScore(score);
logger.info("Set score {} for Person {} ok.", score, p.getName());
我们靠猜也能猜出来,SLF4J的日志接口传入的是一个带占位符的字符串,用后面的变量自动替换占位符,所以看起来更加自然。
如何使用SLF4J?它的接口实际上和Commons Logging几乎一模一样:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
class Main {
final Logger logger = LoggerFactory.getLogger(getClass());
}


%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n
%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n
utf-8
log/output.log
log/output.log.%i
1MB

从目前的趋势来看,越来越多的开源项目从Commons Logging加Log4j转向了SLF4J加Logback。
2)小结
-
SLF4J和Logback可以取代Commons Logging和Log4j;
-
始终使用SLF4J的接口写入日志,使用Logback只需要配置,不需要修改代码。