NLP-分词器:SentencePiece【参考Chinese-LLaMA-Alpaca在通用中文语料上训练的20K中文词表并与原版LLaMA模型的32K词表进行合并的代码】
背景
随着ChatGPT迅速出圈,最近几个月开源的大模型也是遍地开花。目前,开源的大语言模型主要有三大类:ChatGLM衍生的大模型(wenda、ChatSQL等)、LLaMA衍生的大模型(Alpaca、Vicuna、BELLE、Phoenix、Chimera等)、Bloom衍生的大模型(Bloomz、BELLE、Phoenix等)。其中,ChatGLM-6B主要以中英双语进行训练,LLaMA主要以英语为主要语言的拉丁语系进行训练,而Bloom使用了46种自然语言、13种编程语言进行训练。
| 模型 | 训练数据量 | 模型参数 | 训练数据范围 | 词表大小 | HF分词器的分词算法 | HF分词器(Tokenizer) |
|---|---|---|---|---|---|---|
| LLaMA | 1T~1.4T tokens(其中,7B/13B使用1T,33B/65B使用1.4T) | 7B~65B | 以英语为主要语言的拉丁语系 | 32000 | BBPE | LlamaTokenizer(基于SentencePiece工具实现 )/LlamaTokenizerFast(基于Huggingface底层的BaseTokenizer实现) |
| ChatGLM-6B | 约 1T tokens | 6B | 中英双语 | 130528 | BBPE | ChatGLMTokenizer(基于SentencePiece工具实现) |
| Bloom | 1.6TB预处理文本,转换为 350B 唯一 tokens | 300M~176B | 46种自然语言,13种编程语言 | 250680 | BBPE | BloomTokenizerFast(基于Huggingface底层的BaseTokenizer实现) |
目前来看,在开源大模型中,LLaMA无疑是其中最闪亮的星。但是,与ChatGLM-6B和Bloom原生支持中文不同。LLaMA 原生仅支持 Latin 或 Cyrillic 语系,对于中文支持不是特别理想。原版LLaMA模型的词表大小是32K,而多语言模型(如:XLM-R、Bloom)的词表大小约为250K。以中文为例,LLaMA词表中的中文token比较少(只有几百个)。这将导致了两个问题:
- LLaMA 原生tokenizer词表中仅包含少量中文字符,在对中文字进行tokenzation时,一个中文汉字往往被切分成多个token(2-3个Token才能组合成一个汉字),显著降低编解码的效率。
- 预训练中没有出现过或者出现得很少的语言学习得不充分。
为了解决这些问题,我们可能就需要进行中文词表扩展。比如:在中文语料库上训练一个中文tokenizer模型,然后将中文 tokenizer 与 LLaMA 原生的 tokenizer 进行合并,通过组合它们的词汇表,最终获得一个合并后的 tokenizer 模型。
本文将介绍使用SentencePiece工具如何使用中文语料训练一个分词模型。
预备知识
讲解 SentencePiece 之前,我们先讲解下分词器(Tokenizer)。
那什么是分词器?简单点说就是将字符序列转化为数字序列,对应模型的输入。
通常情况下,Tokenizer有三种粒度:word/char/subword
- word: 按照词进行分词,如:
Today is sunday. 则根据空格或标点进行分割[today, is, sunday, .] - character:按照单字符进行分词,就是以char为最小粒度。 如:
Today is sunday.则会分割成[t, o, d,a,y, .... ,s,u,n,d,a,y, .] - subword:按照词的subword进行分词。如:
Today is sunday.则会分割成[to, day,is , s,un,day, .]
可以看到这三种粒度分词截然不同,各有利弊。
对于word粒度分词:
- 优点:词的边界和含义得到保留;
- 缺点:1)词表大,稀有词学不好;2)OOV(可能超出词表外的词);3)无法处理单词形态关系和词缀关系,会将两个本身意思一致的词分成两个毫不相同的ID,在英文中尤为明显,如:cat, cats。
对于character粒度分词:
- 优点:词表极小,比如:26个英文字母几乎可以组合出所有词,5000多个中文常用字基本也能组合出足够的词汇;
- 缺点:1)无法承载丰富的语义,英文中尤为明显,但中文却是较为合理,中文中用此种方式较多。2)序列长度大幅增长;
最后为了平衡以上两种方法, 又提出了基于 subword 进行分词:它可以较好的平衡词表大小与语义表达能力;常见的子词算法有Byte-Pair Encoding (BPE) / Byte-level BPE(BBPE)、Unigram LM、WordPiece、SentencePiece等。
- BPE:即字节对编码。其核心思想是从字母开始,不断找词频最高、且连续的两个token合并,直到达到目标词数。
- BBPE:BBPE核心思想将BPE的从字符级别扩展到子节(Byte)级别。BPE的一个问题是如果遇到了unicode编码,基本字符集可能会很大。BBPE就是以一个字节为一种“字符”,不管实际字符集用了几个字节来表示一个字符。这样的话,基础字符集的大小就锁定在了256(2^8)。采用BBPE的好处是可以跨语言共用词表,显著压缩词表的大小。而坏处就是,对于类似中文这样的语言,一段文字的序列长度会显著增长。因此,BBPE based模型可能比BPE based模型表现的更好。然而,BBPE sequence比起BPE来说略长,这也导致了更长的训练/推理时间。BBPE其实与BPE在实现上并无大的不同,只不过基础词表使用256的字节集。
- WordPiece:WordPiece算法可以看作是BPE的变种。不同的是,WordPiece基于概率生成新的subword而不是下一最高频字节对。WordPiece算法也是每次从词表中选出两个子词合并成新的子词。BPE选择频数最高的相邻子词合并,而WordPiece选择使得语言模型概率最大的相邻子词加入词表。
- Unigram:它和 BPE 以及 WordPiece 从表面上看一个大的不同是,前两者都是初始化一个小词表,然后一个个增加到限定的词汇量,而 Unigram Language Model 却是先初始一个大词表,接着通过语言模型评估不断减少词表,直到限定词汇量。
- SentencePiece:SentencePiece它是谷歌推出的子词开源工具包,它是把一个句子看作一个整体,再拆成片段,而没有保留天然的词语的概念。一般地,它把空格也当作一种特殊字符来处理,再用BPE或者Unigram算法来构造词汇表。SentencePiece除了集成了BPE、ULM子词算法之外,SentencePiece还能支持字符和词级别的分词。
下图是一些主流模型使用的分词算法,比如:GPT-1 使用的BPE实现分词,LLaMA/BLOOM/GPT2/ChatGLM使用BBPE实现分词。BERT/DistilBERT/Electra使用WordPiece进行分词,XLNet则采用了SentencePiece进行分词。
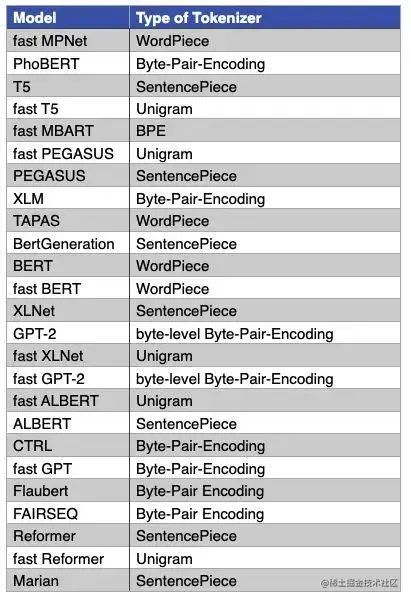
从上面的表格中我们也可以看到当前主流的一些开源大模型有很多基于 BBPE 算法使用 SentencePiece 实现分词器,从Huggingface Transformers库的源码中也能看到很多分词器基于SentencePiece工具实现,下面来讲解SentencePiece工具的具体使用。
SentencePiece 简介
SentencePiece 是一种无监督的文本 tokenizer 和 detokenizer,主要用于基于神经网络的文本生成系统,其中,词汇量在神经网络模型训练之前就已经预先确定了。 SentencePiece 实现了subword单元(例如,字节对编码 (BPE))和 unigram 语言模型),并可以直接从原始句子训练字词模型(subword model)。 这使得我们可以制作一个不依赖于特定语言的预处理和后处理的纯粹的端到端系统。
SentencePiece 特性
唯一Token数量是预先确定的
神经网络机器翻译模型通常使用固定的词汇表进行操作。 与大多数假设无限词汇量的无监督分词算法不同,SentencePiece 在训练分词模型时,使最终的词汇表大小固定,例如:8k、16k 或 32k。
从原始句子进行训练
以前的子词(sub-word)实现假设输入句子是预标记(pre-tokenized)的。 这种约束是有效训练所必需的,但由于我们必须提前运行依赖于语言的分词器,因此使预处理变得复杂。 SentencePiece 的实现速度足够快,可以从原始句子训练模型。 这对于训练中文和日文的tokenizer和detokenizer很有用,因为在这些词之间不存在明确的空格。
空格被视为基本符号
自然语言处理的第一步是文本 tokenization。
例如,标准的英语分词器(tokenizer)将对文本Hello world进行分段。 分为[Hello] [World] [.]这三个token。 这种情况将导致原始输入和标记化(tokenized)序列不可逆转换。 例如,“World”和“.”之间没有空格的信息。空格将从标记化序列中删除,例如:Tokenize(“World.”) == Tokenize(“World .”)
但是,SentencePiece 将输入文本视为一系列 Unicode 字符。 空格也作为普通符号处理。 为了明确地将空格作为基本标记处理,SentencePiece 首先使用元符号 "▁" (U+2581) 转义空格。
Hello▁World.
然后,将这段文本分割成小块,例如:
[Hello] [▁Wor] [ld] [.]
由于空格保留在分段文本中,我们可以毫无歧义地对文本进行detokenize。
ini
复制代码
detokenized = ''.join(pieces).replace(' ', ' ')
此特性可以在不依赖特定于语言的资源的情况下执行detokenization。
注意: 在使用标准分词器拆分句子时,我们不能应用相同的无损转换,因为它们将空格视为特殊符号。 标记化(Tokenized)序列不保留恢复原始句子所需的信息。
子词正则化和 BPE-dropout
子词正则化和 BPE-dropout 是简单的正则化方法,它们实际上通过实时子词采样来增强训练数据,这有助于提高神经网络机器翻译(NMT)模型的准确性和鲁棒性。
为了启用子词正则化,你可以将 SentencePiece 库(C++/Python)集成到 NMT 系统中,以便为每个参数更新采样一个分段,这与标准的离线数据准备不同。
下面是 Python 库的示例。
less
复制代码
>>> import sentencepiece as spm >>> s = spm.SentencePieceProcessor(model_file='spm.model') >>> for n in range(5): ... s.encode('New York', out_type=str, enable_sampling=True, alpha=0.1, nbest_size=-1) ... ['▁', 'N', 'e', 'w', '▁York'] ['▁', 'New', '▁York'] ['▁', 'New', '▁Y', 'o', 'r', 'k'] ['▁', 'New', '▁York'] ['▁', 'New', '▁York']
您会发现New York在每个 SampleEncode (C++) 或 使用 enable_sampling=True (Python)进行编码的调用时的分段方式都不同。 采样参数的详细信息可在 sentencepiece_processor.h 中找到。
SentencePiece 技术优势
- 纯数据驱动:SentencePiece 从句子中训练 tokenization 和 detokenization 模型。 并不总是需要Pre-tokenization(Moses tokenizer/MeCab/KyTea) 。
- 独立于语言:SentencePiece 将句子视为 Unicode 字符序列。 没有依赖于语言的逻辑。
- 多子词算法:支持 BPE 和 unigram 语言模型。
- 子词正则化:SentencePiece 实现子词正则化和 BPE-dropout 的子词采样,有助于提高 NMT 模型的鲁棒性和准确性。
- 快速且轻量级:分割速度约为 50k 句子/秒,内存占用约为 6MB。
- Self-contained:只要使用相同的模型文件,就可以获得相同的tokenization/detokenization。
- 直接词汇 ID 生成:SentencePiece 管理词汇到 ID 的映射,可以直接从原始句子生成词汇 ID 序列。
- 基于 NFKC 的 normalization:SentencePiece 执行基于 NFKC 的文本 normalization。
SentencePiece与其他实现的比较
| 特性 | SentencePiece | subword-nmt | WordPiece |
|---|---|---|---|
| 支持的算法 | BPE, unigram, char, word | BPE | BPE* |
| 是否开源? | Yes | Yes | Google internal |
| 是否支持子词正则化 | Yes | No | No |
| 是否提供 Python 库 (pip) | Yes | No | N/A |
| 是否提供 C++ 库 | Yes | No | N/A |
| 是否需要预分割? | No | Yes | Yes |
| 是否可自定义 normalization (例如:NFKC) | Yes | No | N/A |
| 是否直接id生成 | Yes | No | N/A |
注意:WordPiece 中使用的 BPE 算法与原始 BPE 略有不同。
环境安装
SentencePiece分为两部分:训练模型和使用模型。其中,训练模型部分是用C语言实现的,可编译二进程程序执行,训练结束后生成一个model文件和一个词典文件。
模型使用部分同时支持二进制程序和Python调用两种方式,训练完生成的词典数据是明文,可编辑,因此,也可以用其他任何语言进行读取和使用。
从 C++ 源构建和安装 SentencePiece 命令行工具
由于我们需要命令行工具模型训练,因此,我们需要先安装 SentencePiece 命令行工具。
构建 SentencePiece 需要以下工具和库:
- cmake
- C++11 编译器
- gperftools 库(可选的,可以获得 10-40% 的性能提升)
在 Ubuntu 上,可以使用 apt-get 安装构建工具:
arduino
复制代码
sudo apt-get install cmake build-essential pkg-config libgoogle-perftools-dev
接下来,按如下方式构建和安装命令行工具。
bash
复制代码
git clone https://github.com/google/sentencepiece.git cd sentencepiece mkdir build cd build cmake .. make -j $(nproc) make install ldconfig -v
查看命令使用文档:
bash
复制代码
spm_train --help
使用pip安装sentencepiece库
SentencePiece 提供了支持 SentencePiece 训练和分割的 Python 包装器。 由于后续会基于Python语言使用模型,因此,使用 pip 安装 SentencePiece 的 Python 二进制包。
复制代码
pip install sentencepiece
训练模型
由于官网只提供英语和日语数据,如果使用中文进行模型训练的话,需要先下载中文训练数据。本文使用 红楼梦(需要自行预先清洗下数据)进行模型训练。
css
复制代码
spm_train --input=/workspace/data/book/hongluomeng_clean.txt --model_prefix=/workspace/model/book/hongluomeng-tokenizer --vocab_size=4000 --character_coverage=0.9995 --model_type=bpe
参数说明:
- --input: 训练语料文件,可以传递以逗号分隔的文件列表。文件格式为每行一个句子。 无需运行tokenizer、normalizer或preprocessor。 默认情况下,SentencePiece 使用 Unicode NFKC 规范化输入。
- --model_prefix:输出模型名称前缀。 训练完成后将生成
.model 和 .vocab 文件。 - --vocab_size:训练后的词表大小,例如:8000、16000 或 32000
- --character_coverage:模型覆盖的字符数量,对于字符集丰富的语言(如日语或中文)推荐默认值为 0.9995,对于其他字符集较小的语言推荐默认值为 1.0。
- --model_type:模型类型。 可选值:unigram(默认)、bpe、char 或 word 。 使用word类型时,必须对输入句子进行pretokenized。
运行过程:
scss
复制代码
> spm_train --input=/workspace/data/book/hongluomeng_clean.txt --model_prefix=/workspace/model/book/hongluomeng-tokenizer --vocab_size=4000 --character_coverage=0.9995 --model_type=bpe sentencepiece_trainer.cc(77) LOG(INFO) Starts training with : trainer_spec { input: /workspace/data/book/hongluomeng_clean.txt input_format: model_prefix: /workspace/model/book/hongluomeng-tokenizer model_type: BPE vocab_size: 4000 self_test_sample_size: 0 character_coverage: 0.9995 input_sentence_size: 0 shuffle_input_sentence: 1 seed_sentencepiece_size: 1000000 shrinking_factor: 0.75 max_sentence_length: 4192 num_threads: 16 num_sub_iterations: 2 max_sentencepiece_length: 16 split_by_unicode_script: 1 split_by_number: 1 split_by_whitespace: 1 split_digits: 0 pretokenization_delimiter: treat_whitespace_as_suffix: 0 allow_whitespace_only_pieces: 0 required_chars: byte_fallback: 0 vocabulary_output_piece_score: 1 train_extremely_large_corpus: 0 hard_vocab_limit: 1 use_all_vocab: 0 unk_id: 0 bos_id: 1 eos_id: 2 pad_id: -1 unk_piece: eos_piece: pad_piece: trainer_interface.cc(423) LOG(INFO) Adding meta_piece: trainer_interface.cc(428) LOG(INFO) Normalizing sentences... trainer_interface.cc(537) LOG(INFO) all chars count=866703 trainer_interface.cc(548) LOG(INFO) Done: 99.95% characters are covered. trainer_interface.cc(558) LOG(INFO) Alphabet size=3986 trainer_interface.cc(559) LOG(INFO) Final character coverage=0.9995 trainer_interface.cc(591) LOG(INFO) Done! preprocessed 3144 sentences. trainer_interface.cc(597) LOG(INFO) Tokenizing input sentences with whitespace: 3144 trainer_interface.cc(608) LOG(INFO) Done! 3395 bpe_model_trainer.cc(159) LOG(INFO) Updating active symbols. max_freq=10909 min_freq=13 trainer_interface.cc(686) LOG(INFO) Saving model: /workspace/model/book/hongluomeng-tokenizer.model trainer_interface.cc(698) LOG(INFO) Saving vocabs: /workspace/model/book/hongluomeng-tokenizer.vocab
模型输出文件(词表及模型权重):
shell
复制代码
> ls -al /workspace/model/book total 328 drwxr-xr-x 2 root root 4096 May 19 01:55 . drwxrwxrwx 21 root root 4096 May 19 01:55 .. -rw-r--r-- 1 root root 285840 May 19 01:55 hongluomeng-tokenizer.model -rw-r--r-- 1 root root 38885 May 19 01:55 hongluomeng-tokenizer.vocab
查看词表:
bash
复制代码
> head -n20 /workspace/model/book/hongluomeng-tokenizer.vocab 0 0 :“ -0 。” -1 宝玉 -2 笑道 -3 ?” -4 太太 -5 什么 -6 凤姐 -7 了一 -8 贾母 -9 也不 -10 , -11 。 -12 了 -13 不 -14 的 -15 一 -16
使用模型
基于命令行使用模型
将原始文本编码成句子片段(token)。
shell
复制代码
> echo "白日依山尽,黄河入海流。" | spm_encode --model=/workspace/model/book/hongluomeng-tokenizer.model ▁ 白 日 依 山 尽 , 黄 河 入 海 流 。
将原始文本编码成句子片段(Token)id。注意:--output_format参数默认为piece。
shell
复制代码
> echo "白日依山尽,黄河入海流。" | spm_encode --model=/workspace/model/book/hongluomeng-tokenizer.model --output_format=id 60 254 70 333 468 400 14 733 1476 317 603 510 15
将句子片段(token) id 解码为原始文本。
shell
复制代码
> echo "60 254 70 333 468 400 14 733 1476 317 603 510 15" | spm_decode --model=/workspace/model/book/hongluomeng-tokenizer.model --input_format=id 白日依山尽,黄河入海流。
基于模型文件导出词汇表。
css
复制代码
# spm_export_vocab --model=<模型文件> --output=<输出文件> spm_export_vocab --model=/workspace/model/book/hongluomeng-tokenizer.model --output=/workspace/output/hongluomeng.vocab
其中,--output指定输出文件,里面存储着词汇列表和 emission log probabilities。 词汇表 id 对应于此文件中的行号。
官网还提供了端到端(包括:训练(spm_train),编码(spm_encode)和解码(spm_decode))示例,如下所示:
scss
复制代码
% spm_train --input=data/botchan.txt --model_prefix=m --vocab_size=1000 unigram_model_trainer.cc(494) LOG(INFO) Starts training with : input: "../data/botchan.txt" ...
基于Python库使用模型
python
复制代码
>>> import sentencepiece as spm >>> >>> sp = spm.SentencePieceProcessor() >>> >>> text="这贾雨村原系胡州人氏,也是诗书仕宦之族,因他生于末世,父母祖宗根基已尽,人口衰丧,只剩得他一身一口,在家乡无益,因进京求取功名,再整基业。" >>> >>> sp.Load("/workspace/model/book/hongluomeng-tokenizer.model") True >>> print(sp.EncodeAsPieces(text)) ['▁', '这', '贾', '雨', '村', '原', '系', '胡', '州', '人', '氏', ',', '也', '是', '诗', '书', '仕', '宦', '之', '族', ',', '因', '他', '生', '于', '末', '世', ',', '父', '母', '祖', '宗', '根', '基', '已', '尽', ',', '人', '口', '衰', '丧', ',', '只', '剩', '得', '他', '一', '身', '一', '口', ',', '在', '家', '乡', '无', '益', ',', '因', '进', '京', '求', '取', '功', '名', ',', '再', '整', '基', '业', '。']
除此之外,我们还可以将训练的新词表并与原来的词表进行合并。具体可参考Chinese-LLaMA-Alpaca在通用中文语料上基于sentencepiece训练的20K中文词表并与原版LLaMA模型的32K词表(HF实现LLaMA分词基于BBPE算法,底层调用的也是sentencepiece的方法)进行合并的代码。
结语
本文主要给大家讲解了SentencePiece的基本原理及使用方法。如果我们分析某个领域相关问题,可以基于该领域的书籍和文档使用SentencePiece去训练一个分词模型。SentencePiece并不限于被分析的内容本身。训练数据越多,模型效果越好。
参考文档:
- SentencePiece
- BPE、WordPiece和SentencePiece
- 大模型中的分词器tokenizer:BPE、WordPiece、Unigram LM、SentencePiece
- sentencepiece原理与实践
- 【OpenLLM 008】大模型基础组件之分词器-万字长文全面解读LLM中的分词算法与分词器(tokenization & tokenizers):BPE/WordPiece/ULM & beyond
- Summary of the tokenizers
大模型词表扩充必备工具SentencePiece - 掘金
sentencepiece原理与实践
https://github.com/google/sentencepiece/blob/master/python/README.md
NLP笔记:中文分词工具简介-腾讯云开发者社区-腾讯云