《Flink原理、实战与性能优化》(Flink知识梳理一)
Flink原名Stratosphere
Flink是基于事件驱动的,而Spark Streaming微批模型,生成微小的数据批次
Spark的弱点:
Spark基于批处理原理,对流式计算相对较弱(本质上是对Hadoop架构进行了一定的升级和优化)
有状态流式计算架构:
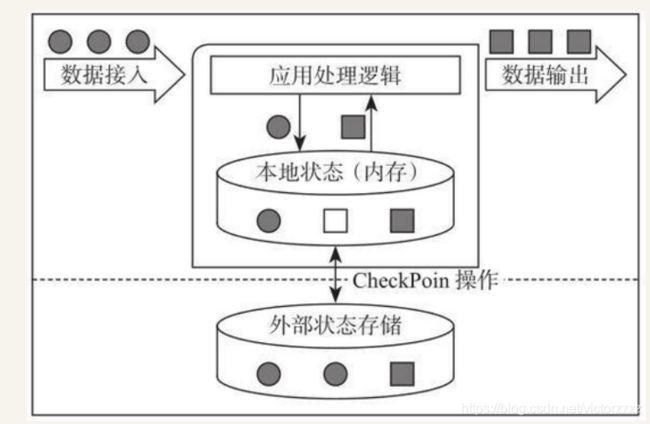
Flink通过实现Google Dataflow流式计算模型实现了高吞吐、低延迟、高性能兼具实时流式计算框架,支持高度容错状态管理,防止状态在计算过程中因为系统异常而丢失。周期性通过分布式快照技术Checkpoint来实现状态的持久化维护。
优点:
- 同时支持高吞吐、低延迟、高性能
Spark Streaming流式计算无法做到低延迟保证
Apache Storm只能支持低延迟和高性能,无法做到高吞吐
- 支持事件时间的概念
- 支持有状态计算
- 支持高度灵活的窗口操作
- 基于轻量级分布式快照实现容错
- 基于JVM实现独立的内存管理
- Save Points 保存点
应用场景:
- 实施智能推荐
- 复杂事件处理
- 实时欺诈检测
- 实时数仓与ETL
- 流数据分析
- 实时报表分析
Flink 基本组件栈
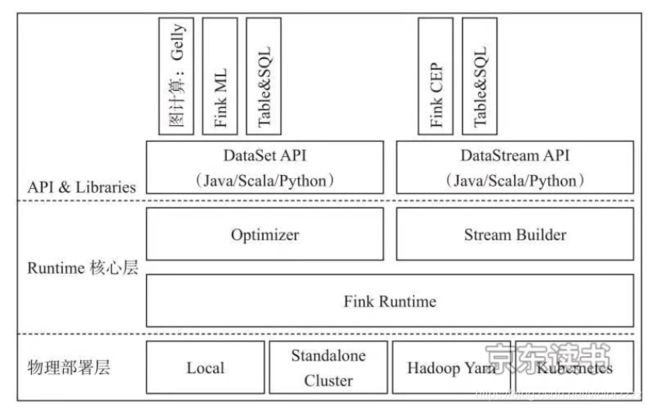
Flink 基本架构图
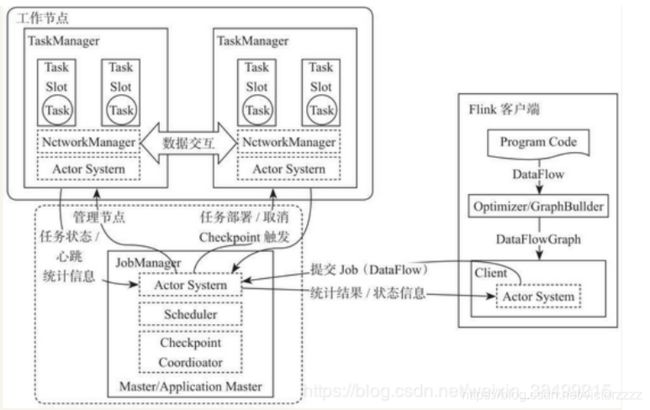
- Client :构建Akka连接,提交到JobManager
- JobManager : 与TaskManager之间通过Actor System进行通信
- TaskManager :使用slot资源启动Task
Flink 项目模板创建方式:
- Maven Archetype:
mvn archetype:generate \
-DarchetypeGroupId = org.apache.flink \
-DarchetypeArtifactId = flink-quickstart-java \
-DarchetypeCatalog = https://repository.apache.org/content/repositories/snapshots \
-DarchetypeVersion=1.7.0- quickstart
curl https://flink.apache.org/q/quickstart-SNAPSHOT.sh | bash -s 1.6.0程序运行:
批量计算:val textBatch = benv.fromElements(......)
流式计算:val textStreaming = senv.fromElements(......)
Flink 编程模型
| DataStream | 无界数据集 | 流计算 |
| DataSet | 有界数据集 | 批处理计算 |
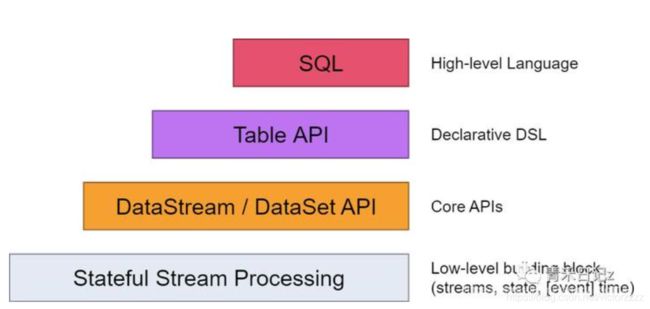
- SQL
- Table API:在原有的DataStream 和 DataSet 基础上增加Schema信息,将数据类型统一抽象成表结构
- DataStream / DataSet API
- Runtime:Statefule Stream Processing:是Flink中处理Stateful Stream最底层的接口,用户可以使用Stateful Stream Process接口操作状态,时间等底层数据
步骤:
1. Execution Environment
Execution Environment三种方式:
- StreamExecutionEnvironment.getExecutionEnvironment
- StreamExecutionEnvironment.createLocalEnvironment(5)
- StreamExecutionEnvironment.createRemoteEnvironment("JobManagerHost",6021,5,"/user/application.jar")
2.初始化数据: val text:DataStream[String] = env.readTextFile("file:///path/file")
3.执行转换操作: 可以通过Lambada表达式,也可以通过定义好的算子
- 普通转换
val counts:DataStream[(String,Int)] = text.flatMap(_.toLowerCase.split(" "))
.filter(_.nonEmpty)
.map((_,1))
.keyBy(0)
.sum(1)- 通过创建Class实现Function接口
val dataStream: DataStream[String] = env.fromElements("hello","flink");
dataStream.map( new MyMapFunction)
class MyMapFunction extends MapFunction[String,String]{
override def map(t:String):String = { t.toUpperCase()}
}- 通过创建匿名类实现Function接口
val dataStream: DataStream[String] = env.fromElements("hello","flink");
dataStream.map( new MyMapFunction[String,String]{
override def map(t:String):String = { t.toUpperCase()}
})- 通过实现RichFunction接口
RichFunction用于比较高级的数据处理场景,RichFunction接口中有open,close,getRuntimeContext、setRuntimeContext获取状态等
data.map( new RichMapFunction[String,Int]{def map(in:String):Int={in.toInt}} )4.分区key指定
常见的有join,coGroup,groupBy类算子,需要先将DataStream 或 DataSet数据集转换成相应的KeyedStream 和 GroupedDataSet
主要是将相同key值的数据路由到相同的Pipeline中,然后进行下一步操作 (虚拟的key,仅仅只是帮助后面基于key的算子使用)
- 根据字段位置
//keyBy 指定key转化为重新分区的keyedStream
val result = dataStream.keyBy(0).sum(1)
val dataSet = env.fromElements(("hello",1),("flink",3))
val groupedDataSet:GroupedDataSet[(String,Int)] = dataSet.groupBy(0)
groupedDataSet.max(1)- 根据字段名称
persionDataStream.keyBy("_1")- 根据Key选择器指定
case class Person(name:String,age:Int)
val person = env.fromElements(Person("hello",1),Person("flink",4))
val keyed:KeyedStream[WC] = person.keyBy(new KeySelector[Person,String](){
override def getKey(person:Person):String = person.word
})5.输出结果
counts.writeAsText("file://path/to/saveFile")
counts.print()6.程序触发
env.execute("App Name")Flink数据类型
数据类型由TypeInformation定义
主要有BasicTypeInfo、TupleTypeInfo、CaseClassTypeInfo、PojoTypeInfo等
- 原生数据类型,通过实现BasicTypeInfo,能够支持任意Java原生基本类型
val intStream:DataStream[Int] = env.fromElements{3,1,2,1,5}
val dataStream:DataStream[String] = env.fromElements("hello","world")
val dataStream:DataStream[Int] = env.fromElements(Array(3,1,2,1,5))- Java Tuples类型
val tupleStream2:DataStream[Tuple2[String,Int]] = env.fromElements(new Tuple2("a",1), new Tuple2("c",2))- Scala Case Class 类型
case class WordCount(word:String,count:Int)
val input = env.fromElements(WordCount("hello",1),WordCount("world",2))
val keyStream1 = input.keyBy("word")
val keyStream2 = input.keyBy(0)- POJOs类型 (就是一个类的定义)
通过实现PojoTypeInfo来描述任意的POJOs,描述复杂的数据结构
在Flink中使用POJOs有以下要求:
- Pojos类必须是Public修饰且必须独立定义,不能是内部类
- Pojos类必须含有默认空构造器
- Pojos类中所有的Fields必须是Public或者具有Public修饰的getter和setter方法
- Pojos类中的字段必须是Flink支持的
例如:
public class Person{
public String name;
public int age;
public Person(){}
public Person(String name,int age){this.name = name; this.age = age;}
}
val personStream = env.fromElements(new Person("Peter",14), new Person("Linda",25))- Flink Value类型
Value数据类型实现了org.apache.flink.types.Value 包括 read() 和 wirte() 两个方法实现序列化和反序列化操作。相对于通用的序列化工具会有着比较高效的性能
目前Flink支持的Value类型包括:IntValue、DoubleValue、StringValue等
- 特殊数据类型
支持例如Scala中的List、Map、Either、Option、Try数据类型,还有Hadoop中的Writable数据类型。
这些类型需要借助TypeHint提示数据类型信息
TypeInformation信息获取:
Scala类型推断:Scala使用了Manifest和类标签,在编译器运行时获取类型信息。不会出现类型擦除问题。Flink使用了Scala Macros框架,在编译代码过程中推断函数输入参数和返回类型信息,同时在Flink中注册成TypeInformation以支持上层计算算子使用
Java类型推断:使用类型提示。例如TypeHint
。在使用POJOs类型数据时,PojoTypeInformation为POJOs所有字段创建序列化器。对于标准类型,使用Flink自带的序列化器。对于其他类型,直接调用Kryo序列化器(enableForceKryo()) 对Kyro自定义添加序列化器:env.getConfig().addDefaultKryoSerializer(Class type,Class> serializerClass)
(Kryo序列化无法对Pojos类序列化时,可以使用Avro Pojos序列化:env.getConfig().enableForceAvro())
自定义TypeInformation
@TypeInfo(CustomTypeInfoFactory.class)
public class CustomTuple{
public T0 field0;
public T1 field1;
}
public class CustomTypeInfoFactory extends TypeInfoFactory{
@Override
public TypeInformation createTypeInfo(Type t,Map> genericParameters){
return new CustomTupleTypeInfo(genericParameters.get("T0"),genericParameters.get("T1"));
}
} DataStream API
DataStream = DataSource 数据接入+ Transformation 转换操作 + DataSink 数据输出
DataSource
内置数据源
- 文件数据源:readTextFile、readFile:文件读取类型WatchType、检测文件间隔、文件过滤条件
WatchType:
- PROCESS_CONTINUOUSLY:一旦检测到文件发生变化,Flink会将文件全部内容加载到Flink系统中进行处理
- PROCESS_ONCE:当文件发生变化时,只会将变化的数据读取到Flink中,数据都只会被处理一次
val textStream = env.readTextFile("/usr/local/data_example.log")
val csvStream = env.readFile(new CsvInputFormat[String](new Path(".....")){
override def fillRecord(out:String, objects:Array[AnyRef]) :String = { return null},
"/usr/local/data_example.csv"
})- Socket数据源
val socketDataStream = env.socketTextStream("localhost",9999)
//可以使用nc -lk 9999触发访问监听的端口- 集合数据源
List arrayList = new ArrayList<>();
arrayList.add(“hello flink”);
DataStream dataList = env.fromCollection(arrayList);
env.fromElements(Tuple2(1L,3L),Tuple2(1L,2L)) 外部数据源
- 仅支持读取数据:Twitter Streaming API,Netty
- 仅支持输出数据:Apache Cassandra、ElasticSearch、Hadoop FileSystem
- 既支持数据输入,也支持数据输出:Apache Kafka、Amazon Kinesis、RabbitMQ
使用过程中用户在maven中自己引入需要的依赖Connector
DataStream转换操作
- 单Single-DataStream
- Map [DataStream -> DataStream]
- FlatMap [DataStream -> DataStream]
- Fliter [DataStream -> DataStream]
- KeyBy [DataStream -> KeyedStream]
- Reduce [KeyedStream -> DataStream]
- Aggregations [KeyedStream -> DataStream]
- Multi-DataStream操作
- Union [DataStream -> DataStream]
- Connect,CoMap,CoFlatMap [DataStream -> DataStream]
例如:dataStream1:(String,Int) , dataStream2:Int 通过connect形成[(String,Int),Int]
dataStream1:(String,Int) , dataStream2:Int 自定义CoMapFunction或CoFlatMapFunction输出(Int, String)
val dataStream1:DataStream[(String,Int)] = env.fromElements(("a",3),("d",4)) val dataStream2:DataStream[Int] = env.fromElements(1,2,3,4,5) val connectedStream:ConnectedStreams[(String,Int),Int] = dataStream1.connect(dataStream2) val resultStream = connectedStream.map(new CoMapFunction[(String,Int),Int,(Int,String)]){ override def map1(in1:(String,Int)):(Int,String) = {(in1._2,in1._1)} override def map2(in2:Int):(Int:String) = {(in2, "default")} })
- Split [DataStream -> SplitStream]
- Select [SplitStream -> DataStream]
- Iterate [DataStream -> IterativeStream -> DataStream]
物理分区操作:作用是根据指定的分区策略将数据重新分配到不同节点的Task案例上执行
如果数据发生倾斜时,需要用户调节分区。就需要定义物理分区策略进行重新分区。常见分区包括:
- 随机分区 shuffle
val shuffleStream = dataStream.shuffle- Roundrobin 分区 rebalance()
重点侧重数据倾斜。通过循环的方式对集中的数据进行重分区,数据会全局性地通过网络介质传输到其他节点完成数据地重新平衡
val shuffleStream = dataStream.rebalance()- Rescaling 分区 rescale()
仅会对上下游继承地算子数据进行重平衡
val shuffleStream = dataStream.rescale()- 广播操作 broadcast()
将输入的数据集复制到下游算子的并行Tasks实例中,下游算子中Tasks可以直接从本地内存中获取广播数据集
val shuffleStream = dataStream.broadcast()- 自定义分区 partitionCustom
object customPartitioner entends Partitioner[String]{
val r = scala.util.Random
override def partition(key:String, numPartitions:Int):Int = {
if(key.contains("flink")) 0 else r.nextInt(numPartitions)
}
}
dataStream.partitionCustom(customPartitioner,"field_name");
dataStream.partitionCustom(customPartitioner,0)DataSinks 数据输出
- 基本数据输出:writeAsCsv、writeAsText、writeToSocket
- 第三方数据输出:基于SinkFunction将数据输出到外部第三方系统中
时间概念
Event Time 事件产生 ------> Ingestion Time 事件进入 ------> Processing Time 事件处理
- 事件生成时间 Event Time,通常为事件中的时间戳
是每个独立事件在产生它的设备上发生的时间,在进入Flink之前就已经嵌入到事件中
可以用来还原事件的先后关系
- 事件接入时间 Ingestion Time
数据进入Flink系统的时间,依赖于Source Operator所在主机的系统时钟处理时间 Processing Time
不能处理乱序事件
- 事件处理时间 Processing Time (默认时间)
指操作算子计算过程中获取到的所在主机的时间
适用计算精度要求不是特别高的计算场景
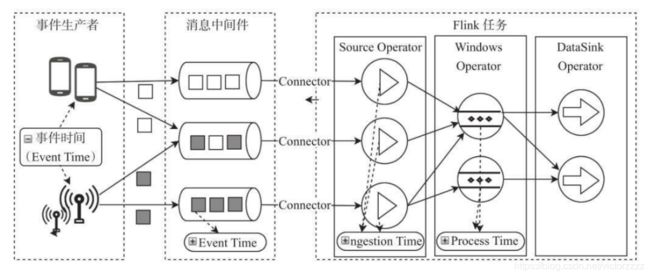
时间获取:
val env = StreamExecutionEnvironment.getExecutionEnvironment()
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) // 其他时间需要指定水位线WaterMarks
不能无限期等待,到一个特定时间就要触发计算任务。watermark 的作用,他们定义了何时不再等待更早的数据。
用于衡量数据处理进度,保证时间数据到达Flink系统,或在乱序或延迟到达时能跟预期一样得到正确并连续的结果
具有时间戳t的watermark可以被理解为断言了所有时间戳小于或等于t的事件都(在某种合理的概率上)已经到达了。
何时停止等待? 当收到时间戳为xxx(或更大)的watermark时
用户配置的支持最大延迟时间长度 = 进入系统的最新时间 - 固定时间间隔
事件时间 与 Watermarks的关系
- 顺序事件中的Watermarks
Watermark会随着数据元素的事件时间顺序生成,当Watermark时间大于Windows结束时间就会触发Windows计算
- 乱序事件中的Watermarks
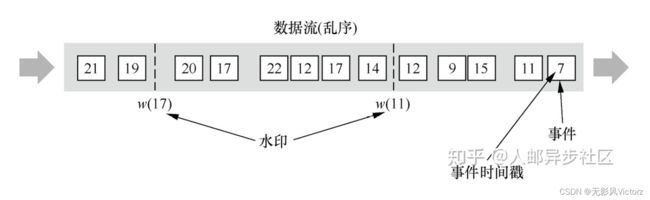
- 并行数据流中的Watermarks
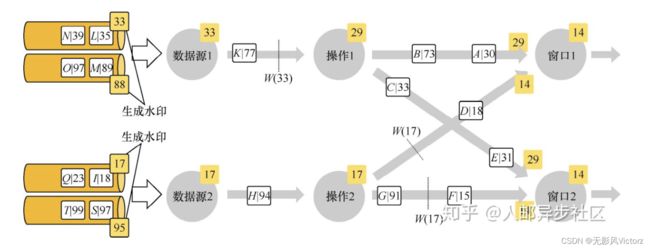
过程:
当事件接入到Flink系统时,会在Sources Operator中根据当前最新事件时间产生Watermarks时间戳,记为X;
之后接下来进入Flink系统的数据事件时间,记为Y
- 如果Y
- 或者Y>=X,但是窗口EndTime 小于 Watermark,也会触发计算
Watermarks的生成
- 指定Timestamps生成Watermarks
(1)在Source Function中直接定义Timestamps和Watermarks
数据进入到Flink系统就直接分配EventTime 和 Watermark
val input = List(("a",1L,1),("b",1L,1))
val source:DataStream[(String,Long,Int)] = env.addSource(
new SourceFunction[(String,Long,Int)](){
override def run(ctx:SourceContext[(String,Long,Int)]):Unit = {
input.foreach(value =>{
ctx.collectWithTimestamp(value,value._2)
ctx.emitWatermark(new Watermark(value._2-1 ))
})
ctx.emitWatermark(new Watermark(Long.MaxValue))
}
override def cancel() : Unit = {}
})(2)通过Flink自带的Timestamp Assigner指定Timestamp和生成Watermark
Assigner会覆盖Source Function中定义的逻辑
Watermarks的两种类型:
- Periodic Watermarks:周期性间隔的Watermarks(借助AssignerWithPeriodicWatermarks)
- 使用AscendingTimestamp Assigner
- 将数据中的Timestamp根据指定字段提取,用当前的Timestamp作为最新的Watermark,比较适合事件顺序生成的情况
- 使用AscendingTimestamp Assigner
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val input = env.fromCollection(List(("a",1L,1),("b",1L,1)))
//使用系统默认的Ascending分配事件信息和watermark
val withTimestampsAndWatermarks = input.assignAscendingTimestamps(t=>t._3)
//对数据进行窗口计算
val result = withTimestampsAndWatermarks.keyBy(0).timeWindow(Time.seconds(10)).sum("_2")- 使用固定时延间隔的Timestamp Assigner
val withTimestampsAndWatermarks = input.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[(String,Long,Int)])(Time.seconds(10)){
//定义抽取EventTime Timestamp逻辑
override def extractTimestamp(t:(String,Long,Int)):Long = t._2
})- Punctuated Watermarks:根据接入的数据量生成Watermarks(借助AssignerWithPunctuatedWatermarks)
(3)自定义Timestamp Assigner 和 Watermark Generator
- Periodic Watermarks自定义
class PeriodicAssigner extends AssignerWithPeriodicWatermarks[(String,Long,Int)]{
val maxOutOfOrderness = 1000L
val currentMaxTimestamp:Long = _
override def extractTimestamp(event:(String,Long,Int),previousEventTimestamp:Long):Long = {
val currentTimestamp = event._2
currentMaxTimestamp = max(currentTimestamp,currentMaxTimestamp)
currentMaxTimestamp
}
override def getCurrentWatermark():Watermark = {
new Watermark(currentMaxTimestamp - maxOutOrderness)
}
}- Punctuated Watermarks自定义
class PunctuatedAssigner extends AssignerWithPunctuatedWatermarks[(String,Long,Int)]{
override def extractTimestamp(element:(String,Long,Int),previousElementTimestamp:Long):Long = {
element._2
}
override def checkAndGetNextWatermark(lastElement:(String,Long,Int),extractedTimestamp:Long):Watermark = {
if(lastElement._3 == 0) new Watermark(extractedTimestamp) else null
}
}Window窗口计算
将窗口抽象成独立的Operator,且在Flink DataStream API中已经内建了大多数窗口算子。包括:
- Window Assigner(*必须):指定窗口的类型,定义如何将数据流分配到一个或多个窗口
- Window Trigger:窗口触发器
- Evictor:数据剔除器
- Lateness:时延设定,标记是否处理迟到数据,当迟到数据到达窗口中是否触发计算
- Output Tag:输出标签,通过getSideOutput将窗口中的数据根据标签输出
- Windows Function(*必须):定义窗口上的数据处理逻辑
stream.keyBy(......) //是keyed类型数据集
.window(......) //指定窗口分配器类型
[.trigger(......)] //指定触发器类型
[.evictor(......)] //指定evictor或不指定
[.allowedLateness(......)] //指定是否延迟处理数据
[.sideOutputLateData(......)] //指定Output Lag
.reduce / aggregate / fold / apply //指定窗口计算函数
[.getSideOutput(......)] //根据Tag输出数据
Keyed 和 Non-Keyed
- 上游数据集如果是KeyedStream类型,调用DataStream API 的 windows方法指定Windows Assigner,根据Key统计结果
用户选择对key进行分区,能够对相同key数据分配到一个分区
例如统计同一个用户在5分钟内不同的登录IP地址属
inputStream.keyBy(input => input.id).window(new MyWindowsAssigner())
- 如果是Non-Keyed类型,调用windowsAll方法指定Windows Assigner,所有数据路由到一个Task中计算,并得到全局统计结果
对窗口上的数据进行全局统计计算,例如统计某一段时间内某网站所有的请求数
inputStream.windowAll(new MyAllWindowsAssigner())
Windows Assigner
- 基于时间的窗口
- 基于数量的窗口
滚动窗口 Tumbling Windows:
根据固定时间或大小进行切分,且窗口和窗口之间元素不重叠(会导致前后关系的数据计算结果不准确)

使用方式:
- TumblingEventTimeWindows
val tumblingEventTimeWindow = inputStream.keyBy(_.id).window(TumblingEventTimeWindows.of(Time.seconds(10))).process(窗口函数)- TunblingProcessTimeWindows
val tumblingEventTimeWindow = inputStream.keyBy(_.id).window(TumblingProcessTimeWindows.of(Time.seconds(10))).process(窗口函数)- timeWindow
inputStream.keyBy(_.id).timeWindow(Time.seconds(1)).process(窗口函数)滑动窗口 Sliding Windows: 在滚动窗口基础上增加了窗口滑动时间,且允许窗口数据发生重叠
- 当Slide time小于Windows size便会发生窗口重叠
- 当Slide size大于Windows size就会出现窗口不连续,数据可能在任何一个窗口内计算
- Slide size 和 Windows size相等时,Sliding Windows其实就是Tunbling Windows
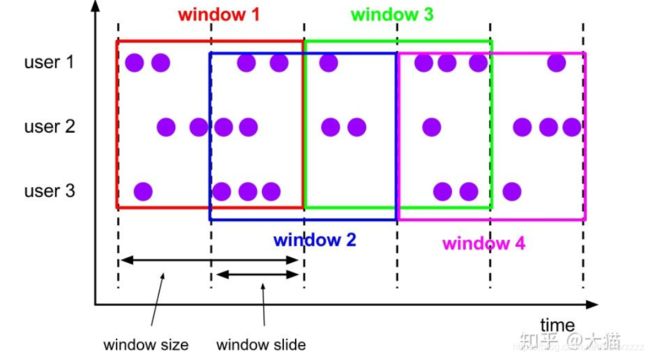
会话窗口
将某段时间内活跃度较高的数据聚合成一个窗口进行计算,窗口的触发条件是Seesion Gap
只需要规定不活跃数据的时间上限即可(session gap),适合非连续数据或周期产生的数据,例如:用户在线上某段时间内的活跃度对用户行为的统计
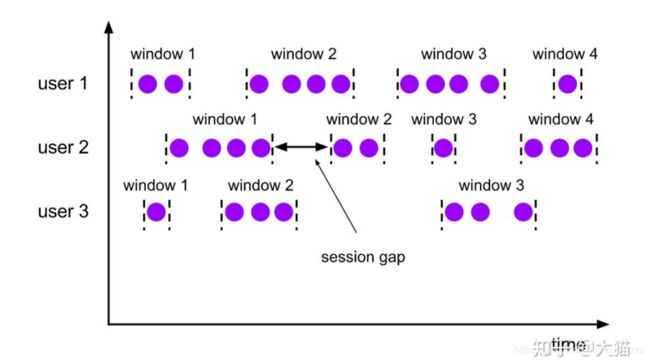
使用方法:
- EventTimeSessionWindows.withGap()
val eventTimeSessionWindows = inputStream.keyBy(_.id).window(EventTimeSessionWindows.withGap(Time.milliseconds(10))).process(...)- ProcessingTimeSessionWindows.withGap()
val processingTimeSessionWindows = inputStream.keyBy(_.id).window(ProcessingTimeSessionWindows.withGap(Time.milliseconds(10))).process(...)- 动态调整Session Gap
val eventTimeSessionWindows = inputStream.keyBy(_.id)
.window(EventTimeSessionWindows.withDynamicGap(
new SessionWindowTimeGapExtractor[String] {
override def extract(element:String):Long = {//动态返回结果}
}
))全局窗口
将所有相同的key的数据分配到单个窗口中计算结果,窗口没有起始和结束时间,需要借助Trigger触发计算
需要指定:
- 触发器(Trigger)
- 数据清理机制

Windows Function
窗口内的计算逻辑
- ReduceFunction
- AggregateFunction
- FoldFunction:将窗口中的输入元素与外部的元素合并的逻辑
- ProcessWindowFunction:基于窗口之上的状态数据
- Incremental Aaggregation 和 ProcessWindowsFunction
窗口触发器
- EventTimeTrigger : 通过对比Watermark和窗口EndTime确定是否触发窗口(Watermark时间大于EndTime则触发计算)
- ProcessTimeTrigger:通过对比ProcessTime和窗口EndTime确定是否触发窗口(窗口ProcessTime大于EndTime则触发计算)
- ContinuousEventTimeTrigger:周期性触发 + EventTimeTrigger
- ContinuousProcessingTimeTrigger:周期性触发 + ProcessTimeTrigger
- CountTrigger:接入数据量是否超过设定的阈值决定是否触发计算
- DeltaTrigger:Delta是否超过指定Threshold,判断是否触发
- PurgingTrigger:任意触发器作为参数转换为Purge类型触发器
- 自定义触发器
- onElment(): 针对每一个接入窗口的元素进行触发操作
- onEventTime(): 根据接入窗口的EventTime进行触发操作
- onProcessTime(): 根据接入窗口的ProcessTime进行触发操作
- onMerge(): 对多个窗口进行Merge操作,同时进行状态的合并
- Clear(): 执行窗口及状态数据的清除方法
- 触发方法返回结果:
- CONTINUE: 当前不触发计算,继续等待
- FIRE: 触发计算,但是数据继续保留
- PURGE: 代表窗口内部数据清除,但不触发
- FIRE_AND_PURGE: 代表触发计算,并清除对应数据
Evictors 数据剔除器
- CountEvictor:保持在窗口中具有固定数量的记录,将超过的数据在计算前剔除
- DeltaEvictor:定义DeltaFunction 和 指定 threshold,计算Windows中的元素和最新元素间的delta大小,如果超过threshold则剔除
- TimeEvictor:当前窗口时间减去Interval,然后将小于该结果的数据全部剔除
- 自定义Evictor
- evictBefore:数据进入WindowFunction计算前执行的剔除操作
- evictAfter:数据在WindowFunction计算后执行的剔除操作
延迟数据处理 allowed Latenes
允许延时的最大时间,即:
Window的EndTime + allowed Lateness 作为最后被释放的结束时间,标记为P
- 当接入数据的Event Time未超过该时间P,但Watermark已经超过Window的EndTime时直接触发窗口计算
- 如果事件时间超过最大延时时间P,则只能丢弃处理
Side Output
将延时数据和结果存储到数据库中,便于后期对延时数据进行分析,需要Side Output,通过sideOutputLateData来标记数据结果,再通过getSideOutput获取标签对应的数据,之后转为独立的DataStream数据集进行处理。
val lateOutputTag = OutputTag[T]("late-data")
val input:DataStream[T] = ......
val result = input.keyBy(...).window(...).allowedLateness(lateOutputTag).process(......)
val lateStream = result.getSideOutput(lateOutputTag)多个窗口计关系
- 独立窗口计算(相互独立,针对同一个DataStream进行不同窗口的处理)
val input:DataStream[T] = ...
val windowStream1 = inputStream.keyBy(_._1).window(EventTimeSessionWindows.withGap(Time.milliseconds(100))).process(...)
val windowStream2 = inputStream.keyBy(_._1).window(EventTimeSessionWindows.withGap(Time.milliseconds(10))).process(...)- 连续窗口计算(窗口之间上下游关系)
val input:DataStream[T] = ...
val windowStream1 = inputStream.keyBy(_._1).window(TumblingEventTimeWindows.of(Time.milliseconds(10))).reduce(new Min())
val windowStream2 = windowStream1.windowAll(TumblingEventWindows.of(Time.milliseconds(10))).process(new TopKWindowFunction())- Window多流合并
inputStream1:DataStream[(Long,String,Int)] = ....
inputStream2:DataStream[(String,Long,Int)] = ....
inputStream1.join(inputStream2)
.where(_._1)
.equalTo(_._2)
.window(TumblingEventTimeWindows.of(Time.milliseconds(10)))
.apply() //指定窗口计算函数 所有的join都是Inner-Join类型,每个Stream中都要有Key,且Key值相同才能完成关联操作,输出结果
滚动窗口关联 TumblingEventTimeWindow
数据是在相同的窗口进行关联

滑动窗口关联 SlidingEventTimeWindow
在指定SlideTime的间隔内进行滑动,同时允许窗口重叠
会话窗口关联 EventTimeSessionWindow
会话窗口关联对两个Stream的数据元素进行窗口关联操作
间隔关联
和其他窗口关联不同,间隔关联的数据元素关联范围不依赖窗口化分,而是通过DataStream元素的时间加上或减去指定Interval作为关联窗口,然后和另一个DataStream的元素时间在窗口内进行Join操作
作业链:上下游的Task在同一个pipeline中执行,进而避免因为数据网络或者线程间传输导致的开销
- 关闭pipeline:
StreamExecutionEnvironment.disableOperatorChaining()
- 关闭局部pipeline:
someStream.map(...).disableChaining()
Slot资源组:Slot是Flink资源的最小单元,类似Yarn中的Container,由TaskManager进行统一管理
Flink与外部系统的交互:
- RichMapFunction 同步创建外部数据库系统的Client连接
- AsyncFunction (Asynchronous I/O) 支持通过异步方式连接外部存储系统,用来提高性能以及吞吐量
class AsyncDBFunction extends AsyncFunction[String,(String,String)]{
lazy val dbclient:DBClient = new DBClient(host,post)
implicit lazy val executor:ExecutionContext = ExecutionContext.fromExecutor(Executors.directExecutor())
override def asyncInvoke(str:String,resultFuture:ResultFuture[(String,String)]:Unit = {
val resultFutureRequested.onSuccess{
case result:String => resultFuture.complete(Iterable((str,result))
}}}
val stream:DataStream[String] = ...
val resultStream:DataStream[(String,String)] = AsyncDataStream.unorderedWait(stream, new AsyncDatabaseRequest(),1000,TimeUnit.MILLISECONDS,100)输出结果:
- 乱序模式:AsyncDataStream.unorderedWait(......)
- 顺序模式:AsyncDataStream.orderedWait(......)
Flink 状态
- 有状态计算:
存储Flink内部计算产生的中间结果,并提供给后续Function或算子计算结果使用
- 无状态计算:
不存储计算过程中产生的结果,也不会将结果用于下一步计算过程中,程序只会在当前计算流程中实行计算,计算完成后输出结果。
Flink状态类型:
Flink根据数据集是否按照Key进行分区,将状态分为Keyed State、Operator State两种类型
- Keyed State
Keyed State 是 Operator State的特例,区别在于 Keyed State事先按照key对数据集进行了分区,每个Key State仅对应一个Operator和Key的组合
- Operator State(Non-keyed State)
Operator State只和并行的算子实例绑定,和数据元素中的key无关,每个算子实例中持有所有数据元素中的一部分状态数据
Flink状态形式:
- 托管状态(Flink管理):
托管状态形式(Managed State),由Flink Runtime控制和管理
将状态数据转换为内存对象存储。然后将这些状态数据通过内部的借口持久化到checkpoints中,任务异常可以通过这些状态数据恢复任务
ValueStateDescriptor、ListStateDescriptor、ReducingStateDescriptor、FoldingStateDescriptor、MapStateDescriptor
- 原生状态(算子自己管理):
由算子自己管理数据结构
当触发checkpoint过程中,Flink并不知道状态数据内部的数据结构,只是将数据转换成bytes数据存储在checkpoints中,当从checkpoints恢复任务时,算子自己再反序列化出状态的数据结构
通过CheckpointedFunction 接口操作 Operator State
通过ListCheckpointed 接口定义 Operator State
Checkpoints检查点机制
Flink在输入的数据集上间隔性地生成checkpoint barrier,通过barrier将间隔时间段内的数据划分到相应的checkpoint中
checkpoint过程中的数据一般保存在一个可配置的环境中,比如JobManager节点或HDFS中
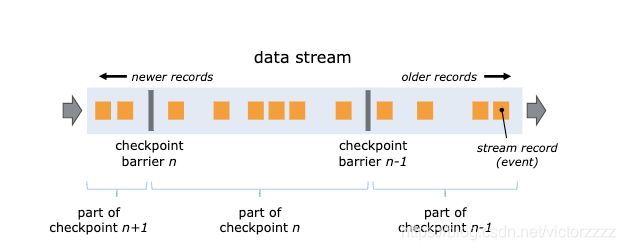
- checkpoint时间间隔设定:
env.enableCheckpointing(1000);- exactly-once:保证整个应用内端到端的数据一致性,适合于数据要求比较高,不允许出现丢数据或数据重复
- at-least-once:适合于时延和吞吐量要求非常高,但对数据一致性要求不高的场景
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)- checkpoint超时时间:
env.getCheckpointConfig().setCheckpointTimeout(60000);- 检查点之间最小时间间隔:
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);- 最大并行执行的检查点数量:
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);- 外部检查点:
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);- 出现错误时是否关闭:
env.getCheckpointConfig.setFailOnCheckpointingErrors(false)Savepoints机制(Checkpoints的一种特殊实现,以手工命令方式触发)
DataStream stream = env.addSource(new StatefulSource())
.uid("source-id").shuffle().map(new StatefulMapper()).uid("mapper-id").print() - 手动触发savepoint:
bin/flink savepoint :jobId [:targetDirectory]- 取消任务并触发savepoint:
bin/flink cancel -s [:targetDirectory]:jobId- 通过从Savepoints恢复任务:
bin/flink run -s :savepointPath [:runArgs]- 释放Savepoints数据:
bin/flink savepoint -d :savepointPathCheckpoints状态管理(StateBackend)
- MemoryStateBackend:基于内存的状态管理,全部存储在JVM堆内存中
- FsStateBackend:基于本地文件系统的状态管理
- RocksDBStateBackend:基于第三方状态管理,状态数据首先写入RockDB中,然后再异步将状态写入文件系统中
(RockDB可以提高状态数据同步性能)
Querable State:提供给Flink查询Flink内部状态的数据,通过RestfulAPI接口,直接查询Flink系统内部的状态数据

- QueryableStateClient:用于外部应用中,作为客户端提交查询请求并收集状态查询结果
- QueryableStateClientProxy:用于接收和处理客户端的请求,每个TaskManager上运行一个客户端代理
- QueryableStateServer:用于接收Client Proxy的请求,每个TaskManager上会运行一个State Server
maxInputStream.keyBy(_._1).asQueryableState("xxxxx")Querable State客户端查询:
- 引入jar(flink-core、flink-queryable-state-client-java_2.11)
- Querable State Client Proxy:QueryableStateClient client = new QueryableStateClient(hostname,port);
- 调用客户端中的getKvState()
目前支持:ValueState、ReduceState、ListState、MapState、AggregatingState
val valueDescriptor:ValueStateDescriptor[Long] = new ValueStateDescriptor[Long]("leastValue",TypeInformation.of(new TypeHint[Long](){}))
val resultFuture:CompletableFuture[ValueState[Long]] = client.getKvState{
JobID.fromHexString(jobId), "leastQueryValue", key, Types.INT, valueDescriptor
}DataSet
输入:
文件类数据:
- readTextFile(path) / TextInputFormat
- readTextFileWithValue / TextValueInputFormat
- readCsvFile(path) / CsvInputFormat
- readSequenceFile(Key, Value, path) / SequenceFileInputFormat
集合类数据:
- fromCollection(Seq)
- fromElements(elements:_*)
- generateSequence(from,to)
- readFile(inputFormat,path) / FileInputFormat
- createInput(inputFormat) / InputFormat
转换:
数据处理:
- Map
- FlatMap
- MapPartition
- Filter
聚合操作:
- Reduce
- ReduceGroup
- Aggregate
- Distinct
多表关联:
- Join
- OuterJoin
- Cogroup:将两个数据集根据相同的key记录组合在一起,相同key的记录会存放在一个group中
- Cross:返回两个数据集的笛卡尔积
集合操作:
- union
- rebalance
- hash-partition
- range-partition
- sort partition
排序操作:
- First-n:返回数据集的n条随机结果
- minby / maxby
输出:
基于文件输出接口:
- writeAsText / TextOutputFormat
- writeAsCsv / CSVOutputFormat
通用输出接口:
- xxx.output(xxxxOutputFormat)
广播变量
对小数据集采用网络传输的方式
//广播
val broadcastData = env.fromElements(1,2,3)
data.map(...).withBroadcastSet(broadcastData,"broadcastSetName")
//接收
val dataSet2:DataSet = ...
dataSet2.map(new RichMapFunction[String,String](){
var broadcastSet:Traversable[Int] = null
override def open(config:Configuration):Unit = {
broadcastSet = getRuntimeContext().getBroadcastVariable[Int]("broadcastSetName").asScala
}
def map(intput:String):String = {
input + broadcastSet.toList
}
}).withBroadcastSet(dataSet1,"broadcastSet")语义注解
Flink提出了语义注解功能,将传入函数的字段在Function中通过注解的形式标记出来,区分哪些是需要参加函数计算的字段,哪些是直接输出的字段。提高整体应用的处理效率
- Forwarded Fileds注解
转发字段代表数据从Function进入后,对指定为Forwarded的Fileds不进行修改,且不参与函数的计算逻辑,而是根据设定的规则表达式,将Fields直接发送到Output对象中的相同位置或指定位置上
例如:f0->f2 代表将Input的第一个字段转发到Output的第三个字段上
f2 代表Input的Tuple对象第三个字段转发到Output的相同位置
f1->* 代表将input的第二个字段转发到Output的整个字段,其他字段不再输出
函数注解的方式:@ForwardedFields("_1->_2")
算子参数的方式:withForwardedFieldsFirst withForwardedFieldsSecond("_2->_3")
- Non-Forwarded Fileds注解
指定不转发的字段,对于被指定的字段必须参与到函数计算过程中,并产生新的结果进行输出
例如:f1;f3 代表输入函数的Input对象中,第二个和第四个字段不需要保留在Output对象中,其余字段全部按照原来的位置进行输出
@NonForwardedFields
NonForwardedFieldsFirst、NonForwardedFieldsSecond
- Read Fields 注解
用来指定Function中需要读取以及参与函数计算的字段,在注解中被指定的字段将全部参与当前函数结果的运算过程
@ReadFields
ReadFieldsFirst、ReadFieldSecond
Table API & SQL (基于Calcite)
统一处理批量和实时计算业务,流批统一
//获取创建TableEnvironment
TableEnvironment.getTableEnvironment()
// 批处理
val batchEnv = ExecutionEnvironment.getExecutionEnvironment();
val tBathEnv = TableEnvironment.getTableEnvironment(batchEnv);
// 流处理
val streamEnv = StreamExecutionEnvironment.getExecutionEnvironment();
val tStreamEnv = TableEnvironment.getTableEnvironment(streamEnv);CataLog
注册数据源和数据表信息,所有对数据库和表的元数据信息存放在Flink CataLog内部目录结构中,包括表结构信息、数据源信息等
- 内部Table注册:
val tableEnv = TableEnvironment.getTableEnvironment(env);
val projTable = tableEnv.scan("SensorsTable").select(...);
tableEnv.registerTable("xxx",projTable);- TableSource注册:
TableSource csvSource = new CsvTableSource(......);
tableEnv.registerTableSource("CsvTable",csvSource);- TableSink注册:
val csvSink: CsvTableSink = new CsvTableSink("path",",")
val fieldNames: Array[String] = Array("field1","field2","field3")
val fieldTypes:Array[TypeInformation[_]] = Array(Types.INT,Types.DOUBLE,Types.LONG)
tableEnv.registerTableSink("CsvSinkTable",fieldNames,fieldTypes,csvSink)DataStream、DataSet、Table转换问题
- DataStream 、DataSet ===> Table
// DataStream 注册成 Table + fromDataStream
TableEnvironment.getTableEnvironment(env).registerDataStream("table1",stream).fromDataStream(stream)
// DataSet 注册成 Table + fromDataSet
TableEnvironment.getTableEnvironment(env).registerDataSet("table1",stream).fromDataSet(stream)- Table ===> DataStream
- Append Model: 追加方式,仅将Insert更新变化的数据写入到DataStream中
- Retract Model:会通过一个Boolean类型字段笔记当Insert操作更新还是Delete操作更新的操作
tStreamEnv.toAppendStream[Row](table)
tStreamEnv.toRetractStream[Row](table)
- Table ===> DataSet
val rowDS: DataSet[Row] = tBatchEnv.toDataSet[Row](table)
外部链接器Connector
将TableSource和TableSink的定义和使用分离。形成可配置化组件,在Table API和SQL Client同时使用
tableEnvironment
.connect(......) // 指定Table Connector Descriptor (FileSystem,Kafka Connector)
.withSchema(......) // 指定数据格式 (CSV Format、JSON Format、Apache Avro Format)
.inAppendMode() //指定更新模式 (标记由于insert,update,delete哪种操作更新数据)
.registerTableSource("myTable") // 注册 TableSource窗口操作
- GroupBy Window:根据窗口类型切分成有界数据集,然后在有界数据集上进行聚合类操作
val sensors:Table = tStreamEnv.scan("Sensors") val result = sensors.window([w:Window] as 'window) .groupBy('window,'id) .select('id,'var1.sum,'window.start,'window.end,'window.rowtime)
- Tumbling Window
- Sliding Window
- Session Window
- Over Window
基于当前数据和其周围临近范围内的数据进行聚合统计,例如基于当前20条数据做聚合操作
val table = sensors.window(Over partitionBy 'id orderBy 'rowTime preceding UNBOUNDED_RANGE as 'window) .select('id, 'var1.sum over 'window, 'var2.max over 'window)
- partitionBy: 指定了一个或多个分区字段
- orderBy:操作符指定了数据排序的字段
- preceding:指定了基于当前数据需要向前纳入多少数据作为窗口的范围
- following:与preceding相反,从当前记录开始向后纳入多少数据作为计算的范围
聚合操作:
- groupby aggregation
- groupby window aggregation
- over window aggregation
- distinct aggreagation
- distinct
多表关联操作:
- inner join
- outer join
- Time-windowed join:在inner join基础上增加时间条件
- join with table function
- join with temporal table
集合操作:
- union
- unionall
- intersect
- intersectall
- minus
- minusall
- in
排序操作:
- orderby
- grouping sets
- having
- UDAGG
- insertinto...... 写入
基于Calcite的Flink SQL使用:
- sqlQuery
- sqlUpdate
val tableEnv = TableEnvironment.getTableEnvironment(env)
tableEnv.register("sensors",sensors_table)
val csvTableSink = new CsvTableSink("/path/csvfile",......)
val fieldNames:Array[String] = Array("id","type")
val fieldTypes:Array[TypeInformation[_]] = Array(Types.LONG,Types.STRING)
tableEnv.registerTableSink("csv_output_table",fieldNames,fieldTypes,csvSink)
val result:Table = tEnv.sqlQuery(
"select id sum(var1)as sumvar1 from sensors_table where type='speed' group by sensor_id"
)
tableEnv.sqlUpdata(
"insert into csv_output_table select product,amount from sensors where type='temperature'"
)Flink Table 自定义函数
- Scalar Function:标量函数,单个输入或多个输入字段计算后返回一个确定类型的标量值
- Table Function:将一个或多个标量字段作为输入参数,且经过计算和处理后返回任意数量的数据
- Aggregation Function:将一行或多行数据进行聚合后输出一个标量值(createAccumulator / accumulate / getValue)
Flink CEP 复杂事件处理
- 事件定义:简单事件、复杂事件
- 事件关系:时序关系、聚合关系、层次关系、依赖关系、因果关系
- 事件处理:事件推断、事件查因、事件决策、事件预测
CEP复杂事件步骤:
- Pattern定义
- 将pattern绑定在事件流
- 事件流select
val inputStream: DataStream[Event] = ......
val pattern = Pattern.begin[Event]("start")
.where(_.getType == "temperature")
.next("middle")
.subtype(classOf[TempEvent])
.where(_.getTemp >=35.0)
.followedBy("end")
.where(_.getName == "end")
val patternStream = CEP.pattern(inputStream,pattern)
val result:DataStream[Result] = patternStream.select(getResult(_))模式定义:
- 指定循环次数:times(xxx)
- 要么不触发,要么指定次数:optional
- 贪婪模式,在匹配成功的前提下,尽可能多地触发:greedy()
- 触发一次或多次:oneOrMore
- 指定触发固定次数以上:timesOrMore
迭代条件:pattern.where(),pattern.or(),pattern.until()
模式序列:
- 严格邻近:所有事件都按照顺序满足模式条件
start.next("middle").where(.....)- 宽松邻近:会忽略没有成功匹配的模式条件
start.followedBy("middle").where(.....)- 非确定宽松邻近:可以忽略已经匹配的条件
start.followedByAny("middle").where(......)处理已匹配的事件策略:
- NO_SKIP: 将有可能的事件匹配输出,不忽略任何一条
- SKIP_PAST_LAST_EVENT: 忽略从模式条件开始触发到当前触发Pattern中的所有部分匹配事件
- SKIP_TO_FIRST: 忽略第一个匹配指定PatternName的Pattern其之前的部分匹配事件
- SKIP_TO_LAST: 忽略最后一个匹配指定PatternName的Pattern之前的部分匹配事件
- SKIP_TO_NEXT: 忽略指定PatternName的Pattern之后的部分匹配事件
事件获取:
- 通过Select Function抽取正常事件,每次仅仅返回一条结果
- 通过Flat Select Function抽取正常事件,每次调用可以返回任意数量结果
- 通过Select Function抽取超时事件
- 通过Flat Select Function抽取超时事件
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val input:DataStream[Event] = env.fromElement(...)
val partitionedInput = input.keyBy(event => event.getId)
val pattern = Pattern.begin[Event]("start").next("middle").where((event,ctx) => event.getType == "temperature").followedBy("end").where((event,ctx) => event.getId >=1000)
.within(Time.seconds(10))
val patternStream:PatternStream[Event] = patternStream.select(event=>selectFn(event))
def selectFn(pattern:Map[String,Iterable[Event]]):Event = {
val startEvent = pattern.get("start").iterator.next().toList(0)
startEvent
}Flink Gelly 图计算应用
- Vertext 顶点(ID、Value)
- Edge 边(SourceID、TargetID、Value)
- Graph 图 (点、边、env)
- 通过从DataSet数据集中构建 Graph: Graph.fromDataSet(vertices,edges,env)
- 通过从Collection中构建Graph: Graph.fromCollection(vertices,edges,env)
- 通过从CSV文件构建Graph: Graph.fromCsvReader(pathEdges="....",env=env)
- Map 图转化操作
- Translate 类别转换
- Filter 筛选
- Join 关联操作
- Reverse 所有的Source顶点和Target顶点进行位置交换
- Undirected 转为无向图
- Union 图合并
- Difference 图对比
- Intersect 图交集
图突变:图修改操作
邻方法:邻近边进行聚合计算
图校验:validate
迭代图处理:
- Vertex-Centric迭代:以顶点中心进行迭代,在计算过程中会以顶点为中心分别计算每个顶点上的边或邻近顶点等指标
- Scatter-Gather迭代:Scatter阶段是将一个顶点上的Message发送给其他顶点,Gather阶段接收到的Message更新顶点Value
- Gather-Sum-Apply迭代:分别为 Gather、Sum、Apply
- Gather阶段并行地在每个顶点上执行自定义GatherFunction,计算边或邻近顶点的指标,形成部分结果值
- 在Sum阶段将Gather阶段生成的部分结果进行合并,生成单一指标
- Apply阶段,会根据Sum阶段生成的结果,判断并更新Vertex上的指标
- 循环图:CirculantGraph
- 完整图:CompleteGraph
- 空图:EmptyGraph
- 星图:StarGraph
- 回声图、超立方体图、路径图、RMat图
FlinkML 机器学习应用......
Flink部署和应用
- Standalone Cluster
- Yarn Cluster
- Yarn Session Model:
这种模式中Flink会向Hadoop Yarn 申请足够多地资源,并在Yarn上启动长时间运行的Flink Session集群,用户通过RestAPI或Web页面将Flink任务提交到Flink Session集群上运行
./bin/yarn-session.sh -n 4 -jm 1024m -tm 4096m -s 16
./bin/yarn-session.sh -id [application]
./bin/flink run ./xxx.jar
- Single Job Model:
Single Job Model 和 大多数计算框架的使用方式类似,每个Flink任务单独向Yarn提交一个Application,并且每个任务都有自己的JobManager和TaskManager,当任务结束后对应的组件也会随任务释放

- Kubernetes Cluster 部署(Docker镜像模式)
kubectl
kubectl create -f jobmanager-service.yaml
kuberctl create -f jobmanager-deployment.yaml
kuberctl create -f taskmanager-deployment.yaml
内部注意SSL通信
Flink升级过程
- 执行Savepoint命令,将系统数据写入到Savepoint指定路径中
- 升级Flink集群至新的版本,并重新启动集群,将任务从之前的Savepoint数据中恢复
Flink监控指标
- Counters:为了对指标进行计数类型的统计
- Gauges: 相对于Counters指标更加通用,可以支持任何类型的数据记录和统计,且不限制返回的结果类型
- Histograms: 为了计算Long类型监控指标的分布情况,并以直方图的形式展示
- Meters: 为了获取平均吞吐量方面的统计,与Histograms指标相同
指标报表Reporter:JMX、Graphite、Prometheus、StatsD、Datadog、Slf4j
Backpressure监控、抽样与优化
Checkpoint优化:
- 最小时间间隔
如果checkpoint过程持续的时间超过了配置的时间间隔,就会出现排队情况,如果非常多的checkpoint操作在排队,就会占用额外的系统资源用于checkpoint,此时,用于任务计算的资源会减少,进而影响整个应用的性能和正常执行
- 状态容量预估
尽可能留有足够的资源来应对反压
- 异步Snapshot
- 状态数据压缩
- checkpoint delay Time
Flink内存优化
Spark的Tungsten在一定程度减轻了对JVM回收机制的依赖,更好地用JVM来处理大规模数据集
Flink JVM内存管理

Flink Managed Heap:
在Flink管理的堆内存中,在启动集群过程中直接将堆内存初始化成Memory Pages Pool,新创建的对象以序列化成二进制数据的方式存储在内存页面池中,当完成计算后Page会被置空,而不是通过JVM进行垃圾回收,保证数据对象的创建永远不超过JVM堆大小,有效避免了频繁GC的系统稳定性问题
Flink Network Buffers:缓存分布式数据,是Flink数据交互层关键内存资源
大的Network Buffers意味着高吞吐
设定规则:
NetworkBufferNums =
^2 * * 4