万法缘生,皆系缘分。缘起即灭,缘生已空。
世间万物皆是幻象,一切随缘生而生,随缘灭而灭 。 若是有缘,时间、空间都不是距离;若是无缘,终是相聚也无法会意。真正的解脱之道,不是将烦恼视为负担,而是把烦恼当做修行的功课;真正的修行,修炼的不是断除烦恼本身,而是面对烦恼的心态和智慧。

Linux哲学思想:一切皆文件
但凡有操守的linux老师,在介绍linux时都不可避免的重复在说“linux的哲学思想重要的一条:一切皆文件”。然而,真正将文件在整个操作系统中的作用和实现讲清楚的却是寥寥。既然文件对于linux操作系统如此重要,下面会从不同的维度来认识文件和文件系统。
1. 文件系统的产生
文件,其实可以等同于数据。对于计算机而言,真正的工作就是用CPU处理数据(这里的数据在内存中)。
出现两个问题:
- 第一,CPU处理的是内存中的数据,内存中的数据从哪里来的?
- 第二,处理完成的数据,怎么保存?
毕竟,内存中的数据断电后就没有了,而且内存空间有限,不可能将所有数据都放在内存中。
温馨提示:此处暂不考虑数据如何输入输出到内存的问题
现在的计算机环境,一般来说数据从磁盘上来(泛指直接由硬盘或存储所提供的磁盘空间)。提及磁盘,很多名词就会从脑子里面蹦出来:盘片、磁头、磁旋臂、磁道、扇区、柱面、电机、7200转、10k、15k.....这些基于硬件的工作原理部分,在此就不做复述。这些东西都很重要,但是对于我们来说不可控,也就是不能直接操作,存在磁盘上的数据仅仅是表示0/1的磁信息,那么怎么才能将数据存入到硬盘上?
对于计算机而言,任何无法直接做到或是做起来很繁琐的事情,都可以采用抽象的方法。
文件是磁盘的抽象,进程是CPU的抽象,虚拟内存就是内存的抽象....此类的东西很多,想要学会操作系统就必须理解此类的抽象。
磁盘里有很多部件,能够正常的运转必然有一套管理系统。既然文件是磁盘的抽象,自然也需有一套“抽象的”管理磁盘的系统----文件系统。也就是说,我们想要访问和控制磁盘,就要将物理的磁盘进行逻辑化抽象,进行管理。比如物理磁盘的数据读写以扇区(sector)为单位,抽象后的文件,以块(block)为单位
这里也就解释了,为什么磁盘在出厂已经格式化,在使用磁盘时还要再进行一次文件系统格式化才能够使用的原因。
2. 文件系统分类
- ext2:早期linux中常用的文件系统
- ext3:ext2的升级版,带日志功能
- ext4:ext3的升级版,大幅度改动
- RAMFS:内存文件系统,速度很快
- NFS:网络文件系统,由SUN发明,主要用于远程文件共享
- MS-DOS:MS-DOS文件系统
- VFAT:Windows95/98操作系统采用的文件系统
- FAT:WindowsXP操作系统采用的文件系统
- NTFS:WindowsNT/XP操作系统采用的文件系统
- HPFS:OS/2操作系统采用的文件系统
- PROC:虚拟的进程文件系统
- ISO9660:大部分光盘所采用的文件系统
- ufsSun:OS所采用的文件系统
- NCPFS:Novell服务器所采用的文件系统
- SMBFS:Samba的共享文件系统
- XFS:由SGI开发的先进的日志文件系统,支持超大容量文件
- JFS:IBM的AIX使用的日志文件系统
- ReiserFS:基于平衡树结构的文件系统
- udf:可擦写的数据光盘文件系统
3. 不同视角看文件系统
以用户的角度:
- 文件名
- 操作
解释:作为用户,文件就是存取数据的基本单元。不需要知道数据真实存在具体哪个硬盘的哪个扇区里,此时用户能够看到也只有文件的名字,所在的位置(路径),是否有权限进行读写执行而已。这时的文件系统隐藏在文件名和路径之间,看不见摸不着。
以操作系统角度,内存文件系统(VFS)—> 大同
- 超级块(super block)对象
- 索引节点(inode)对象
- 目录项(dentry)对象
- 文件(file)对象
解释:在操作系统层面,文件系统有很多类型(ext4、xfs、nfs、cifs....),操作系统要识别每一种类型,并且每种类型的文件系统操作的方式不同。用户在面对不同类型文件系统要用不一样的操作,这显然不是明智的办法。
上面说过,计算机遇到复杂的问题就采用抽象的方式来解决。这时“虚拟文件系统交换(VFS,Virtual Filesystem Switch)”出现了。向上,为用户提供统一的接口,让用户忽略文件系统类型的差异和选择。向下,使用结构对象的方式,将各种类型的文件系统管理信息,在内存中建立一个数据结构,将各种系统管理起来。
以磁盘文件系统角度:(磁盘上只有inode,没有一种专门称为目录的数据结构)
- 索引节点(inode)
- 数据块(block)
- 超级块(super block)
解释:这里的磁盘文件系统,就是文件系统在磁盘上真实存在的数据信息。一定要与VFS中的信息加以区别,起初没有搞清楚它们之间的逻辑关系,也是有点蒙圈。这里的inode、block、super block是固定保存在磁盘中,vfs的结构对象内容,是从磁盘文件系统中读取的,存在内存中,关机就不再存在了。所以在vfs加了对象的后缀,以示不同。
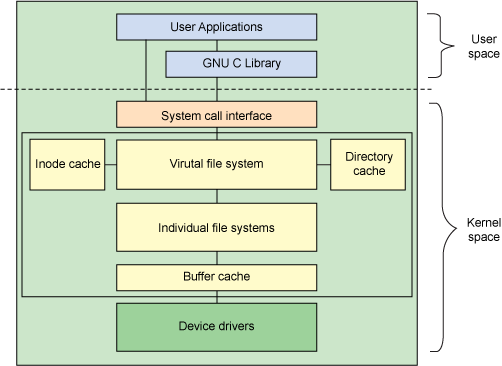
上面从用户-->操作系统-->磁盘的角度(自上而下)分别简单描述了文件系统。为了能够理清文件系统的结构,我们需要自下而上顺序,逐一来介绍。
磁盘文件系统
大家最熟悉的莫过于windows,那我们就从windows 磁盘碎片整理说起。
对于文件系统来讲,离我们最近和最早接触的就是Windows文件系统,比如FAT32、NTFS。具有一些操作经验的童鞋,都会知道windows定期进行磁盘碎片整理,读写会变快些,这是为什么呢?
硬盘是低速设备,其读写单位是扇区,为了避免频繁访问硬盘,windows文件系统以簇为单位进行读写,linux文件系统使用块为单位。(1 sector=512bytes,簇和块的大小,在进行文件系统格式化时可以进行设定,比如1 block=4K,就是8个扇区)
以下为了解释方便,簇和块,都统称为块。此处设定簇(快)的大小为4k,有一个10k的文件。
当前文件10k,大于一个块的大小,就需要用多个块来存储一个文件。如何知道文件有那些块,就要取决于文件数据块的组织形式。在windows FAT中,采用链式结构来组织,简单来说,每个数据块尾部留一些固定的空间,记录下一个块的信息。这个结构的好处,提高磁盘的利用率,节省空间,处理简单。同时缺点也就暴露出来了,因为我们无法确保每个文件的数据块都是连续的,会出现磁头反复移动才能读完数据块。比如存储的数据块在3、6、5号上,其实磁头直接读3->5->6 这样就可以读完了,但是链式方式,在读到3时,根本不知道有5这个数据块,只会读6,然后翻过头了再读5(可能盘片再旋转一次才能读到5)。
所以windows就有了碎片整理,将下一个块,尽量移动到顺序的位置,使得能够高效的读取。这样的文件系统可以称为链式文件系统或非索引文件系统
linux文件系统不存在这个问题,因为使用索引结构来组织数据。简单来说,索引文件系统将数据分为两个部分:真实数据和元数据。元数据中包括了文件对应的块信息,以inode table形式存在,即使数据块是不连续的,访问文件,会先访问inode,得到相应块的信息,然后进行排序,一次性读取。
文件 = inode(元数据) + block(真实数据)
好处,不言而喻读取和查找都会比较快。缺点,inode会占用一定空间。
- 索引节点(inode):文件的元数据(一切文件管理的相关信息,不包括文件名)
- 数据块(block):文件真实的数据
- 超级块(super block):整个文件系统的元数据
Q:每个文件都要有一个inode,inode中记录了文件的大部分信息,地位与文件数据一样重要,但如此重要的数据结构,对于用户来说,缺少文件名,为什么?
A:因为,inode是操作系统(文件系统)管理文件的重要信息,只要给出inode,就可以找到文件实际的数据。在文件系统的角度是不需要所谓文件名、路径等等抽象的东西。
Q:毕竟创建文件系统,最终都是为人服务的,但文件系统自身不需要使用文件名,作为用户,却要使用文件名进行对数据的操作,那么inode和文件名是如何关联在一起的?
A:用户在使用文件名时,无论该文件名是作为可执行的程序,或是作为参数,都离不开路径。也就是说文件名一定在某个目录(在windows中就是文件夹)下。基于linux一切皆文件的哲学思想,目录也是文件,我们这里称为目录文件。目录文件也有inode和block,inode中没有文件名,目录文件和普通文件的区别就是block的内容了。目录文件的block中记录的内容有两种:文件名和子目录对应的inode信息。