用于语义分割模型的t-SNE可视化
前言
在之前的博客t-SNE可视化-Python实现中,对t-SNE的原理进行了一个简单的介绍,也给出了一个简单的使用案例。这篇博客在之前的基础上实现在语义分割模型上的t-SNE可视化。
语义分割模型中使用t-SNE的目的是,从模型的特征层面进行一定的可视化解释。比如属于同一类别的特征向量彼此聚集在一起,而属于不同类别的特征向量彼此相远。
值得一提的是,分割模型中使用t-SNE较多的场景还是域自适应和域泛化分割任务上。在这些任务上,我们往往需要从特征层面上来解释网络缩小域差异的能力。即来自不同域(也就是数据集)而属于同一类别的特征向量在t-SNE的可视化中聚集在一起了。
为了更好的解释,这里给出一个示例。该示例来自于文献CVPR 2022:Pin the Memory: Learning to Generalize Semantic Segmentation
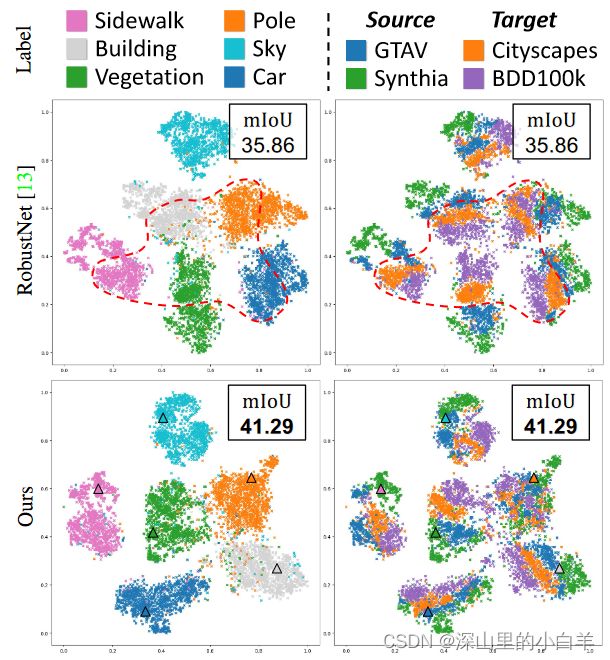
图中每个点就表示一个特征向量,而每个点的颜色就是该特征向量的类别(左图)和来自的域(右图)。
该博客的t-SNE代码也是借鉴于该文章,github地址为:https://github.com/Genie-Kim/PintheMemory/blob/main/tsnelib.py
这里我当了一个搬运工,提供一个使用的方法和一定的参数解释。
环境
如果本地没有环境,可以使用我的docker镜像。
从阿里云拉取(推荐,国内速度很快):
docker pull registry.cn-hangzhou.aliyuncs.com/renwu527/auto-emseg:v6.1
或者从dockerhub拉取:
docker pull renwu527/auto-emseg:v6.1
特别地,不一定非要使用我的镜像,该镜像里面没有什么特殊的包。只要你本地有满足基本的运行环境即可,例如pytorch等。
里面主要环境的版本为:
Python 3.8.5
Pytorch 1.12.1
matplotlib 3.3.2
cuda 10.2
Ubuntu 18.04
直接使用sklearn.manifold里面的TSNE是可以的,唯一的问题就是速度太慢,这里推荐使用另外两个优秀的t-SNE包,即tsnecuda和Multicore-TSNE
安装t-SNE
安装tsnecuda:
pip install tsnecuda
安装Multicore-TSNE:
pip install Multicore-TSNE
这是官网提供的安装方法,但遗憾的是我并没有这样安装成功,于是我选择了从源码编译。特别地,还需要提前安装cmake包才行,不然不会安装成功,这里参考了博客mac上MulticoreTSNE安装及测试:
pip install cmake==3.18.4
git clone https://github.com/DmitryUlyanov/Multicore-TSNE.git
cd Multicore-TSNE/
pip install .
特别地,在有cuda的环境下强烈推荐使用tsnecuda,安装简单,速度很快。
t-SNE源码
import os
import torch
import numpy as np
import torch.nn.functional as F
import matplotlib.pyplot as plt
class RunTsne():
def __init__(self,
selected_cls, # 选择可视化几个类别
domId2name, # 不同域的ID
trainId2name, # 标签中每个ID所对应的类别
trainId2color=None, # 标签中每个ID所对应的颜色
output_dir='./', # 保存的路径
tsnecuda=True, # 是否使用tsnecuda,如果不使用tsnecuda就使用MulticoreTSNE
extention='.png', # 保存图片的格式
duplication=10): # 程序循环运行几次,即保存多少张结果图片
self.tsne_path = output_dir
os.makedirs(self.tsne_path, exist_ok=True)
self.domId2name = domId2name
self.name2domId = {v:k for k,v in domId2name.items()}
self.trainId2name = trainId2name
self.trainId2color = trainId2color
self.selected_cls = selected_cls
self.name2trainId = {v:k for k,v in trainId2name.items()}
self.selected_clsid = [self.name2trainId[x] for x in selected_cls]
self.tsnecuda = tsnecuda
self.extention = extention
self.num_class = 19
self.duplication = duplication
self.init_basket() # 初始化
if self.tsnecuda:
from tsnecuda import TSNE
self.max_pointnum = 9000 # 最大特征向量的数量
self.perplexity = 30 # 未知
self.learning_rate = 100 # t-SNE的学习率
self.n_iter = 3500 # t-SNE迭代步数
self.num_neighbors = 128 # 未知,以上几个参数是针对t-SNE比较重要的参数,可以根据自己的需要进行调整
self.TSNE = TSNE(n_components=2, perplexity=self.perplexity, learning_rate=self.learning_rate, metric='innerproduct',
random_seed=304, num_neighbors=self.num_neighbors, n_iter=self.n_iter, verbose=1)
else:
from MulticoreTSNE import MulticoreTSNE as TSNE
self.max_pointnum = 10200
self.perplexity = 50
self.learning_rate = 4800
self.n_iter = 3000
self.TSNE = TSNE(n_components=2, perplexity=self.perplexity, learning_rate=self.learning_rate,
n_iter=self.n_iter, verbose=1, n_jobs=4)
def init_basket(self):
self.feat_vecs = torch.tensor([]).cuda() # 特征向量
self.feat_vec_labels = torch.tensor([]).cuda() # 特征向量的类别
self.feat_vec_domlabels = torch.tensor([]).cuda() # 特征向量的域信息
self.mem_vecs = None # 聚类中心的向量
self.mem_vec_labels = None # 聚类中心的类别
def input_memory_item(self,m_items):
self.mem_vecs = m_items[self.selected_clsid]
self.mem_vec_labels = torch.tensor(self.selected_clsid).unsqueeze(dim=1).squeeze()
def input2basket(self, feature_map, gt_cuda, datasetname):
b, c, h, w = feature_map.shape
features = F.normalize(feature_map.clone(), dim=1)
gt_cuda = gt_cuda.clone()
H, W = gt_cuda.size()[-2:]
gt_cuda[gt_cuda == 255] = self.num_class
gt_cuda = F.one_hot(gt_cuda, num_classes=self.num_class + 1)
gt = gt_cuda.view(1, -1, self.num_class + 1)
denominator = gt.sum(1).unsqueeze(dim=1)
denominator = denominator.sum(0) # batchwise sum
denominator = denominator.squeeze()
features = F.interpolate(features, [H, W], mode='bilinear', align_corners=True)
# 这里是将feature采样到跟标签一样的大小。当然也可以将标签采样到跟feature一样的大小
features = features.view(b, c, -1)
nominator = torch.matmul(features, gt.type(torch.float32))
nominator = torch.t(nominator.sum(0)) # batchwise sum
for slot in self.selected_clsid:
if denominator[slot] != 0:
cls_vec = nominator[slot] / denominator[slot] # mean vector
cls_label = (torch.zeros(1, 1) + slot).cuda()
dom_label = (torch.zeros(1, 1) + self.name2domId[datasetname]).cuda()
self.feat_vecs = torch.cat((self.feat_vecs, cls_vec.unsqueeze(dim=0)), dim=0)
self.feat_vec_labels = torch.cat((self.feat_vec_labels, cls_label), dim=0)
self.feat_vec_domlabels = torch.cat((self.feat_vec_domlabels, dom_label), dim=0)
def draw_tsne(self, domains2draw, adding_name=None, plot_memory=False, clscolor=True):
feat_vecs_temp = F.normalize(self.feat_vecs.clone(), dim=1).cpu().numpy()
feat_vec_labels_temp = self.feat_vec_labels.clone().to(torch.int64).squeeze().cpu().numpy()
feat_vec_domlabels_temp = self.feat_vec_domlabels.clone().to(torch.int64).squeeze().cpu().numpy()
if self.mem_vecs is not None and plot_memory:
mem_vecs_temp = self.mem_vecs.clone().cpu().numpy()
mem_vec_labels_temp = self.mem_vec_labels.clone().cpu().numpy()
if adding_name is not None:
tsne_file_name = adding_name+'_feature_tsne_among_' + ''.join(domains2draw) + '_' + str(self.perplexity) + '_' + str(self.learning_rate)
else:
tsne_file_name = 'feature_tsne_among_' + ''.join(domains2draw) + '_' + str(self.perplexity) + '_' + str(self.learning_rate)
tsne_file_name = os.path.join(self.tsne_path,tsne_file_name)
if clscolor:
sequence_of_colors = np.array([list(self.trainId2color[x]) for x in range(19)])/255.0
else:
sequence_of_colors = ["tab:purple", "tab:pink", "lightgray","dimgray","yellow","tab:brown","tab:orange","blue","tab:green","darkslategray","tab:cyan","tab:red","lime","tab:blue","navy","tab:olive","blueviolet", "deeppink","red"]
sequence_of_colors[1] = "tab:olive"
sequence_of_colors[2] = "tab:grey"
sequence_of_colors[5] = "tab:cyan"
sequence_of_colors[8] = "tab:pink"
sequence_of_colors[10] = "tab:brown"
sequence_of_colors[13] = "tab:red"
name2domId = {self.domId2name[x] : x for x in self.domId2name.keys()}
domIds2draw = [name2domId[x] for x in domains2draw]
name2trainId = {v:k for k,v in self.trainId2name.items()}
trainIds2draw = [name2trainId[x] for x in self.selected_cls]
domain_color = ["tab:blue", "tab:green","tab:orange","tab:purple","black"]
assert len(feat_vec_domlabels_temp.shape) == 1
assert len(feat_vecs_temp.shape) == 2
assert len(feat_vec_labels_temp.shape) == 1
# domain spliting
dom_idx = np.array([x in domIds2draw for x in feat_vec_domlabels_temp])
feat_vecs_temp, feat_vec_labels_temp, feat_vec_domlabels_temp = feat_vecs_temp[dom_idx, :], feat_vec_labels_temp[dom_idx], \
feat_vec_domlabels_temp[dom_idx]
# max_pointnum random sampling.
if feat_vecs_temp.shape[0] > self.max_pointnum:
pointnum_predraw = feat_vec_labels_temp.shape[0]
dom_idx = np.random.randint(0,pointnum_predraw,self.max_pointnum)
feat_vecs_temp, feat_vec_labels_temp, feat_vec_domlabels_temp = feat_vecs_temp[dom_idx, :], feat_vec_labels_temp[dom_idx], feat_vec_domlabels_temp[dom_idx]
if self.mem_vecs is not None and plot_memory:
mem_address = feat_vecs_temp.shape[0]
vecs2tsne = np.concatenate((feat_vecs_temp,mem_vecs_temp))
else:
vecs2tsne = feat_vecs_temp
for tries in range(self.duplication):
X_embedded = self.TSNE.fit_transform(vecs2tsne)
print('\ntsne done')
X_embedded[:,0] = (X_embedded[:,0] - X_embedded[:,0].min()) / (X_embedded[:,0].max() - X_embedded[:,0].min())
X_embedded[:,1] = (X_embedded[:,1] - X_embedded[:,1].min()) / (X_embedded[:,1].max() - X_embedded[:,1].min())
if self.mem_vecs is not None and plot_memory:
feat_coords = X_embedded[:mem_address,:]
mem_coords = X_embedded[mem_address:,:]
else:
feat_coords = X_embedded
##### color means class
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(111)
for dom_i in domIds2draw:
for cls_i in trainIds2draw:
temp_coords = feat_coords[(feat_vec_labels_temp == cls_i) & (feat_vec_domlabels_temp == dom_i),:]
ax.scatter(temp_coords[:, 0], temp_coords[:, 1],
color=sequence_of_colors[cls_i], label=self.domId2name[dom_i]+'_'+self.trainId2name[cls_i], s=20, marker = 'x')
if self.mem_vecs is not None and plot_memory:
for cls_i in trainIds2draw:
ax.scatter(mem_coords[mem_vec_labels_temp == cls_i, 0], mem_coords[mem_vec_labels_temp == cls_i, 1],
color=sequence_of_colors[cls_i], label='mem_' + str(self.trainId2name[cls_i]), s=100, marker="^",edgecolors = 'black')
print('scatter plot done')
lgd = ax.legend(loc='upper center', bbox_to_anchor=(1.15, 1))
ax.set_xlim(-0.05, 1.05)
ax.set_ylim(-0.05, 1.05)
tsne_file_path = tsne_file_name+'_'+str(tries)+'_colorclass'+self.extention
fig.savefig(tsne_file_path, bbox_extra_artists=(lgd,), bbox_inches='tight')
# plt.show()
fig.clf()
##### color means domains
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(111)
for dom_i in domIds2draw:
for cls_i in trainIds2draw:
temp_coords = feat_coords[(feat_vec_labels_temp == cls_i) & (feat_vec_domlabels_temp == dom_i),:]
ax.scatter(temp_coords[:, 0], temp_coords[:, 1],
color= domain_color[dom_i], label=self.domId2name[dom_i]+'_'+self.trainId2name[cls_i], s=20, marker = 'x')
if self.mem_vecs is not None and plot_memory:
for cls_i in trainIds2draw:
ax.scatter(mem_coords[mem_vec_labels_temp == cls_i, 0], mem_coords[mem_vec_labels_temp == cls_i, 1],
color=sequence_of_colors[cls_i], label='mem_' + str(self.trainId2name[cls_i]), s=100, marker="^",edgecolors = 'black')
print('scatter plot done')
lgd = ax.legend(loc='upper center', bbox_to_anchor=(1.15, 1))
ax.set_xlim(-0.05, 1.05)
ax.set_ylim(-0.05, 1.05)
tsne_file_path = tsne_file_name+'_'+str(tries)+'_colordomain'+self.extention
fig.savefig(tsne_file_path, bbox_extra_artists=(lgd,), bbox_inches='tight')
# plt.show()
fig.clf()
# print memory coordinate
if self.mem_vecs is not None and plot_memory:
print("memory coordinates")
for i,x in enumerate(mem_vec_labels_temp):
print(mem_coords[i,:],self.trainId2name[x])
return tsne_file_path
使用案例
if __name__ == '__main__':
all_class = True # t-SNE展示全部类别,还是部分类别
if all_class:
selected_cls = ['road', 'sidewalk', 'building', 'wall', 'fence', 'pole', 'traffic light', 'traffic sign', 'vegetation',
'terrain', 'sky', 'person', 'rider', 'car', 'truck', 'bus', 'train', 'motorcycle', 'bicycle']
else:
selected_cls = ['building', 'vegetation', 'sky', 'car','sidewalk', 'pole']
# 自己指定要进行t-SNE的类别(可以根据t-SNE的效果选择最好的几个类别即可)
domId2name = {
0:'gtav',
1:'synthia',
2:'cityscapes',
3:'bdd100k',
4:'mapillary',
5:'idd'}
# 为每个数据集指定一个ID
# 默认使用cityscapes里面的标签类别
import cityscapes_labels
trainId2name = cityscapes_labels.trainId2name
# trainId2name = {255: 'trailer',
# 0: 'road',
# 1: 'sidewalk',
# 2: 'building',
# 3: 'wall',
# 4: 'fence',
# 5: 'pole',
# 6: 'traffic light',
# 7: 'traffic sign',
# 8: 'vegetation',
# 9: 'terrain',
# 10: 'sky',
# 11: 'person',
# 12: 'rider',
# 13: 'car',
# 14: 'truck',
# 15: 'bus',
# 16: 'train',
# 17: 'motorcycle',
# 18: 'bicycle',
# -1: 'license plate'}
trainId2color = cityscapes_labels.trainId2color
# trainId2color = {255: (0, 0, 110),
# 0: (128, 64, 128),
# 1: (244, 35, 232),
# 2: (70, 70, 70),
# 3: (102, 102, 156),
# 4: (190, 153, 153),
# 5: (153, 153, 153),
# 6: (250, 170, 30),
# 7: (220, 220, 0),
# 8: (107, 142, 35),
# 9: (152, 251, 152),
# 10: (70, 130, 180),
# 11: (220, 20, 60),
# 12: (255, 0, 0),
# 13: (0, 0, 142),
# 14: (0, 0, 70),
# 15: (0, 60, 100),
# 16: (0, 80, 100),
# 17: (0, 0, 230),
# 18: (119, 11, 32),
# -1: (0, 0, 143)}
output_dir = './'
tsnecuda = True
extention = '.png'
duplication = 10
plot_memory = False
clscolor = True
domains2draw = ['gtav', 'synthia', 'cityscapes', 'bdd100k', 'mapillary', 'idd']
# 指定需要进行t-SNE的域,即数据集
tsne_runner = RunTsne(selected_cls=selected_cls,
domId2name=domId2name,
trainId2name=trainId2name,
trainId2color=trainId2color,
output_dir=output_dir,
tsnecuda=tsnecuda,
extention=extention,
duplication=duplication)
################ inference过程 ################
# 注意这里是伪代码,根据自己的情况进行修改
with torch.no_grad():
for dataset, val_loader in data_loaders.items(): # data_loaders里面包含多个数据集的val_loader
for val_idx, data in enumerate(val_loader):
inputs, gt_image, img_names = data
B, C, H, W = inputs.shape
gt_image = gt_image.view(-1, H, W)
inputs, gt_cuda = inputs.cuda(), gt_image.cuda()
features = net(inputs)
tsne_runner.input2basket(features, gt_cuda, dataset)
################ inference过程 ################
# 如果网络中有每个类别的聚类中心,就执行下面的语句
m_items = net.module.memory.m_items.clone().detach()
tsne_runner.input_memory_item(m_items)
# t-SNE可视化
tsne_runner.draw_tsne(domains2draw, plot_memory=plot_memory, clscolor=clscolor)
为了整体化,这里也贴上cityscapes_labels.py源码:
"""
# File taken from https://github.com/mcordts/cityscapesScripts/
# License File Available at:
# https://github.com/mcordts/cityscapesScripts/blob/master/license.txt
# ----------------------
# The Cityscapes Dataset
# ----------------------
#
#
# License agreement
# -----------------
#
# This dataset is made freely available to academic and non-academic entities for non-commercial purposes such as academic research, teaching, scientific publications, or personal experimentation. Permission is granted to use the data given that you agree:
#
# 1. That the dataset comes "AS IS", without express or implied warranty. Although every effort has been made to ensure accuracy, we (Daimler AG, MPI Informatics, TU Darmstadt) do not accept any responsibility for errors or omissions.
# 2. That you include a reference to the Cityscapes Dataset in any work that makes use of the dataset. For research papers, cite our preferred publication as listed on our website; for other media cite our preferred publication as listed on our website or link to the Cityscapes website.
# 3. That you do not distribute this dataset or modified versions. It is permissible to distribute derivative works in as far as they are abstract representations of this dataset (such as models trained on it or additional annotations that do not directly include any of our data) and do not allow to recover the dataset or something similar in character.
# 4. That you may not use the dataset or any derivative work for commercial purposes as, for example, licensing or selling the data, or using the data with a purpose to procure a commercial gain.
# 5. That all rights not expressly granted to you are reserved by us (Daimler AG, MPI Informatics, TU Darmstadt).
#
#
# Contact
# -------
#
# Marius Cordts, Mohamed Omran
# www.cityscapes-dataset.net
"""
from collections import namedtuple
#--------------------------------------------------------------------------------
# Definitions
#--------------------------------------------------------------------------------
# a label and all meta information
Label = namedtuple( 'Label' , [
'name' , # The identifier of this label, e.g. 'car', 'person', ... .
# We use them to uniquely name a class
'id' , # An integer ID that is associated with this label.
# The IDs are used to represent the label in ground truth images
# An ID of -1 means that this label does not have an ID and thus
# is ignored when creating ground truth images (e.g. license plate).
# Do not modify these IDs, since exactly these IDs are expected by the
# evaluation server.
'trainId' , # Feel free to modify these IDs as suitable for your method. Then create
# ground truth images with train IDs, using the tools provided in the
# 'preparation' folder. However, make sure to validate or submit results
# to our evaluation server using the regular IDs above!
# For trainIds, multiple labels might have the same ID. Then, these labels
# are mapped to the same class in the ground truth images. For the inverse
# mapping, we use the label that is defined first in the list below.
# For example, mapping all void-type classes to the same ID in training,
# might make sense for some approaches.
# Max value is 255!
'category' , # The name of the category that this label belongs to
'categoryId' , # The ID of this category. Used to create ground truth images
# on category level.
'hasInstances', # Whether this label distinguishes between single instances or not
'ignoreInEval', # Whether pixels having this class as ground truth label are ignored
# during evaluations or not
'color' , # The color of this label
] )
#--------------------------------------------------------------------------------
# A list of all labels
#--------------------------------------------------------------------------------
# Please adapt the train IDs as appropriate for you approach.
# Note that you might want to ignore labels with ID 255 during training.
# Further note that the current train IDs are only a suggestion. You can use whatever you like.
# Make sure to provide your results using the original IDs and not the training IDs.
# Note that many IDs are ignored in evaluation and thus you never need to predict these!
labels = [
# name id trainId category catId hasInstances ignoreInEval color
Label( 'unlabeled' , 0 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'ego vehicle' , 1 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'rectification border' , 2 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'out of roi' , 3 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'static' , 4 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'dynamic' , 5 , 255 , 'void' , 0 , False , True , (111, 74, 0) ),
Label( 'ground' , 6 , 255 , 'void' , 0 , False , True , ( 81, 0, 81) ),
Label( 'road' , 7 , 0 , 'flat' , 1 , False , False , (128, 64,128) ),
Label( 'sidewalk' , 8 , 1 , 'flat' , 1 , False , False , (244, 35,232) ),
Label( 'parking' , 9 , 255 , 'flat' , 1 , False , True , (250,170,160) ),
Label( 'rail track' , 10 , 255 , 'flat' , 1 , False , True , (230,150,140) ),
Label( 'building' , 11 , 2 , 'construction' , 2 , False , False , ( 70, 70, 70) ),
Label( 'wall' , 12 , 3 , 'construction' , 2 , False , False , (102,102,156) ),
Label( 'fence' , 13 , 4 , 'construction' , 2 , False , False , (190,153,153) ),
Label( 'guard rail' , 14 , 255 , 'construction' , 2 , False , True , (180,165,180) ),
Label( 'bridge' , 15 , 255 , 'construction' , 2 , False , True , (150,100,100) ),
Label( 'tunnel' , 16 , 255 , 'construction' , 2 , False , True , (150,120, 90) ),
Label( 'pole' , 17 , 5 , 'object' , 3 , False , False , (153,153,153) ),
Label( 'polegroup' , 18 , 255 , 'object' , 3 , False , True , (153,153,154) ), # (153,153,153)
Label( 'traffic light' , 19 , 6 , 'object' , 3 , False , False , (250,170, 30) ),
Label( 'traffic sign' , 20 , 7 , 'object' , 3 , False , False , (220,220, 0) ),
Label( 'vegetation' , 21 , 8 , 'nature' , 4 , False , False , (107,142, 35) ),
Label( 'terrain' , 22 , 9 , 'nature' , 4 , False , False , (152,251,152) ),
Label( 'sky' , 23 , 10 , 'sky' , 5 , False , False , ( 70,130,180) ),
Label( 'person' , 24 , 11 , 'human' , 6 , True , False , (220, 20, 60) ),
Label( 'rider' , 25 , 12 , 'human' , 6 , True , False , (255, 0, 0) ),
Label( 'car' , 26 , 13 , 'vehicle' , 7 , True , False , ( 0, 0,142) ),
Label( 'truck' , 27 , 14 , 'vehicle' , 7 , True , False , ( 0, 0, 70) ),
Label( 'bus' , 28 , 15 , 'vehicle' , 7 , True , False , ( 0, 60,100) ),
Label( 'caravan' , 29 , 255 , 'vehicle' , 7 , True , True , ( 0, 0, 90) ),
Label( 'trailer' , 30 , 255 , 'vehicle' , 7 , True , True , ( 0, 0,110) ),
Label( 'train' , 31 , 16 , 'vehicle' , 7 , True , False , ( 0, 80,100) ),
Label( 'motorcycle' , 32 , 17 , 'vehicle' , 7 , True , False , ( 0, 0,230) ),
Label( 'bicycle' , 33 , 18 , 'vehicle' , 7 , True , False , (119, 11, 32) ),
Label( 'license plate' , -1 , -1 , 'vehicle' , 7 , False , True , ( 0, 0,143) ), # ( 0, 0,142)
]
#--------------------------------------------------------------------------------
# Create dictionaries for a fast lookup
#--------------------------------------------------------------------------------
# Please refer to the main method below for example usages!
# name to label object
name2label = { label.name : label for label in labels }
# id to label object
id2label = { label.id : label for label in labels }
# trainId to label object
trainId2label = { label.trainId : label for label in reversed(labels) }
# label2trainid
label2trainid = { label.id : label.trainId for label in labels }
# trainId to label object
trainId2name = { label.trainId : label.name for label in labels }
trainId2color = { label.trainId : label.color for label in labels }
color2trainId = { label.color : label.trainId for label in labels }
trainId2trainId = { label.trainId : label.trainId for label in labels }
# category to list of label objects
category2labels = {}
for label in labels:
category = label.category
if category in category2labels:
category2labels[category].append(label)
else:
category2labels[category] = [label]
#--------------------------------------------------------------------------------
# Assure single instance name
#--------------------------------------------------------------------------------
# returns the label name that describes a single instance (if possible)
# e.g. input | output
# ----------------------
# car | car
# cargroup | car
# foo | None
# foogroup | None
# skygroup | None
def assureSingleInstanceName( name ):
# if the name is known, it is not a group
if name in name2label:
return name
# test if the name actually denotes a group
if not name.endswith("group"):
return None
# remove group
name = name[:-len("group")]
# test if the new name exists
if not name in name2label:
return None
# test if the new name denotes a label that actually has instances
if not name2label[name].hasInstances:
return None
# all good then
return name
#--------------------------------------------------------------------------------
# Main for testing
#--------------------------------------------------------------------------------
# just a dummy main
if __name__ == "__main__":
# Print all the labels
print("List of cityscapes labels:")
print("")
print((" {:>21} | {:>3} | {:>7} | {:>14} | {:>10} | {:>12} | {:>12}".format( 'name', 'id', 'trainId', 'category', 'categoryId', 'hasInstances', 'ignoreInEval' )))
print((" " + ('-' * 98)))
for label in labels:
print((" {:>21} | {:>3} | {:>7} | {:>14} | {:>10} | {:>12} | {:>12}".format( label.name, label.id, label.trainId, label.category, label.categoryId, label.hasInstances, label.ignoreInEval )))
print("")
print("Example usages:")
# Map from name to label
name = 'car'
id = name2label[name].id
print(("ID of label '{name}': {id}".format( name=name, id=id )))
# Map from ID to label
category = id2label[id].category
print(("Category of label with ID '{id}': {category}".format( id=id, category=category )))
# Map from trainID to label
trainId = 0
name = trainId2label[trainId].name
print(("Name of label with trainID '{id}': {name}".format( id=trainId, name=name )))