大数据基础设施搭建 - Linux环境
文章目录
- 一、阿里云服务器购买
-
- 1.1 使用密码登录Linux云服务器
- 1.2 修改主机名
- 二、阿里云服务器Linux环境配置
-
- 2.1 关闭防火墙
- 2.2 配置静态内网ip
- 2.3 配置SSH免密登陆(免密登陆远程机器普通用户)
- 2.4 文件分发工具
- 2.5 命令同步执行工具
一、阿里云服务器购买
默认安全组除linux/windows远程连接端口开放外,其他端口不开放
硬件配置:cpu:2核 内存:8g 硬盘:40g
主机名称:hadoop102、hadoop103、hadoop104
1.1 使用密码登录Linux云服务器
步骤1: 重置密码
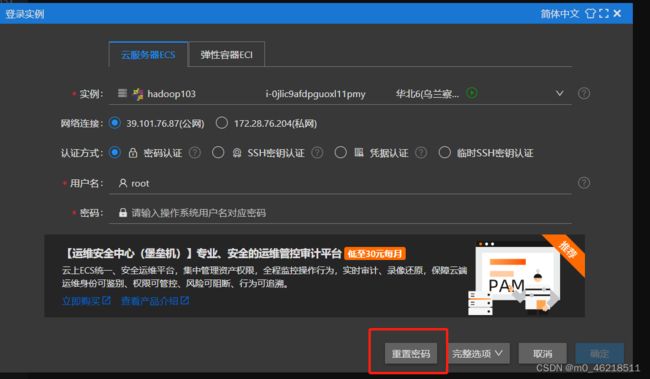
步骤2: 通过VNC连接实例

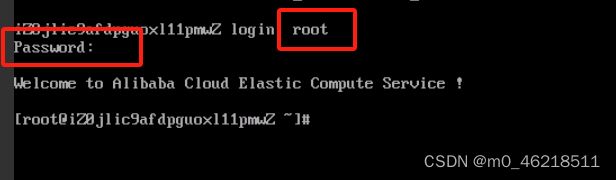
步骤3: 修改SSH服务的配置文件
该问题是由于SSH服务对应配置文件/etc/ssh/sshd_config中的参数PasswordAuthentication被设置为no,表示禁止以密码方式登录ECS实例,需要修改为yes。
vi /etc/ssh/sshd_config
# 划到最后,将PasswordAuthentication no修改为PasswordAuthentication yes
步骤4:重启SSHD服务
service sshd restart
1.2 修改主机名
vi /etc/hostname
reboot
二、阿里云服务器Linux环境配置
检验标准:静态内网ip、三台服务器互相可以ssh免密通信、hadoop102可向其他两台机器同步文件
2.1 关闭防火墙
目的: 防止hadoop各个节点间通信出现问题,只是内网间关闭了,阿里云服务器有安全组会限制外网的访问,所以不会出现安全问题
命令:(永久关闭)
systemctl disable firewalld
验证:systemctl status firewalld
2.2 配置静态内网ip
目的: linux系统默认ip地址是动态获取的,如果不配置ip,每次重启服务器,ip都会改变,这对于访问系统中的项目是很不友好的
步骤1: 编辑/etc/cloud/cloud.cfg配置文件
vim /etc/cloud/cloud.cfg
目的: 按i键切换至编辑模式,在# Example datasource config内容上增加以下配置,关闭cloud-init中的自动配置网络的参数,避免网卡配置文件内容被覆盖。
network:
config: disabled
图示: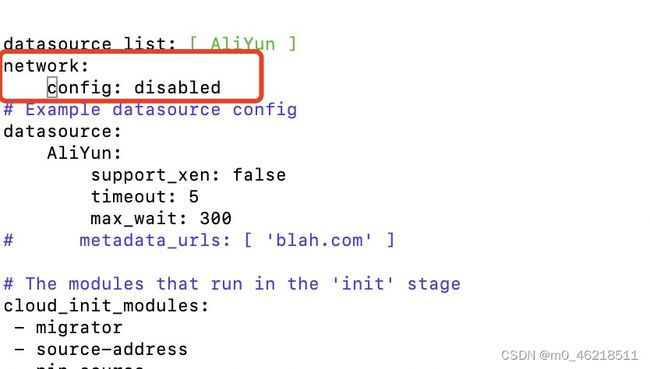
步骤2: 查看并记录Linux实例的网卡信息
ifconfig
目的:查看实例的IP地址、子网掩码
图示:

route -n
目的:查看实例的网关信息
图示:

步骤3: 编辑/etc/sysconfig/network-scripts/ifcfg-eth0配置文件
vim /etc/sysconfig/network-scripts/ifcfg-eth0
描述:按i键切换至编辑模式,将BOOTPROTO的值修改为static,并将以上步骤中记录的IP地址、网关信息、子网掩码填写到该配置文件中,修改之后的内容如下所示。
BOOTPROTO=static
DEVICE=eth0
ONBOOT=yes
STARTMODE=auto
TYPE=Ethernet
USERCTL=no
IPADDR=172.28.76.217
NETMASK=255.255.240.0
GATEWAY=172.28.79.253
图示:
验证:重启服务器后观察内网ip是否发生改变;或重启网络,systemctl restart network重启网络后需重新进行连接,如果ip没变的话就成功了;
2.3 配置SSH免密登陆(免密登陆远程机器普通用户)
目的:
1、配置免密后,执行ssh或者scp时不需要输密码,方便快捷。这点不是必要的原因
2、安装hadoop集群完成后,通常在master侧执行start-all.sh脚本来启动整个集群,脚本会ssh到各个slave来执行启动命令。如果没有配置免密,那么启停集群时要手动输入很多密码,这是致命的
使用root用户配置存在的问题,会将root账号对应的公钥发送到远程机器,不安全。
步骤1: 添加普通用户
三台需要都添加相同的普通用户,因为向远端发送公钥时,默认发送的是和当前登陆账号相同的远端账号
[root@hadoop102 ~]# useradd <用户名>
[root@hadoop102 ~]# passwd <用户名>
[root@hadoop103 ~]# useradd <用户名>
[root@hadoop103 ~]# passwd <用户名>
[root@hadoop104 ~]# useradd <用户名>
[root@hadoop104 ~]# passwd <用户名>
验证:[root@hadoop102 ~]# su - <用户名>
步骤2: 给普通用户添加sudo权限
[root@hadoop102 ~]# vim /etc/sudoers
[root@hadoop103 ~]# vim /etc/sudoers
[root@hadoop104 ~]# vim /etc/sudoers
#在“root ALL=(ALL)ALL”这一行下面,加一行(用户名 ALL=(ALL) ALL),并强制保存
步骤3: 在普通用户登陆的情况下配置SSH免密登陆
#1、修改hosts文件
[root@hadoop102 ~]$ vim /etc/hosts
172.23.11.149 hadoop102 hadoop102
172.23.11.150 hadoop103 hadoop103
172.23.11.151 hadoop104 hadoop104
#2、从root用户切换导普通用户
[root@hadoop102 ~]# su - hadoop
#3、生成公钥和私钥
#然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
[hadoop@hadoop102 ~]$ ssh-keygen -t rsa
#3、将公钥拷贝到要免密登录的目标机器上
[hadoop@hadoop102 ~]$ ssh-copy-id hadoop102
[hadoop@hadoop102 ~]$ ssh-copy-id hadoop103
[hadoop@hadoop102 ~]$ ssh-copy-id hadoop104
#4、其他节点相同
2.4 文件分发工具
开发:需要在root用户下
使用:需要在hadoop用户下,因为配置的是普通用户的SSH免密登陆
步骤1: 脚本编写
[root@hadoop102 ~]# vim /usr/bin/mytools_rsync
脚本:
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送,即 执行脚本后链接目录
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
步骤2: 安装rsync
[root@hadoop102 ~]# yum install rsync
步骤3: 赋予该脚本以可执行权限
[root@hadoop102 ~]# chmod +x /usr/bin/mytools_rsync
步骤4: 测试脚本
2.5 命令同步执行工具
开发:需要在root用户下
使用:需要在hadoop用户下,因为配置的是普通用户的SSH免密登陆
步骤1: 脚本编写
[root@hadoop102 ~]# vim /usr/bin/mytools_call
脚本:
#!/bin/bash
# 1.获取参数个数,小于1个参数报错
if [ $# -lt 1 ]
then
echo "No Args command Input..."
exit ;
fi
# 2.获取当前机器的路径
currDir=$pwd
# 3.ssh到每一台机器,切换到执行脚本机器的当前目录并执行相应命令,这里执行的命令只支持3个参数,可自己根据实际情况扩展,一般用于查看路径或文件内容
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host "cd $currDir;$1 $2 $3;"
done
步骤2: 赋予该脚本以可执行权限
[root@hadoop102 ~]# chmod +x /usr/bin/mytools_call
步骤3: 测试脚本