大数据之hadoop-hdfs伪分布式环境搭建(详细步骤真实可用)
目录
版本
1,基础设施
2,Hadoop的配置(应用的搭建过程)
3,启动
4,简单使用
5,上传自定义块的大小
版本
centos7 + jdk1.8 + hadoop2.6.5
1,基础设施
设置网络:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=10.0.0.11
GATEWAY=10.0.0.2
NETMASK=255.255.255.0
DNS1=10.0.0.2
DNS2=1.2.4.8
设置主机名:
vi /etc/hostname centos6
hostnamectl set-hostname xxx centos7
设置本机的ip到主机名的映射关系
vi /etc/hosts
10.10.0.11 node01
10.10.0.12 node02
关闭防火墙
service iptables stop
chkconfig iptables off
关闭 selinux
vi /etc/selinux/config
SELINUX=disabled
做时间同步
yum install ntp -y
vi /etc/ntp.conf
server ntp1.aliyun.com
service ntpd start
chkconfig ntpd on
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
server ntp1.aliyun.com
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst安装JDK:
rpm -i jdk-8u181-linux-x64.rpm
*有一些软件只认:/usr/java/default
vi /etc/profile
export JAVA_HOME=/usr/java/default
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
ssh免密:
ssh localhost 1,验证自己还没免密 2,被动生成了 /root/.ssh.
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
[root@node11 .ssh]# ll
total 16
-rw-r--r--. 1 root root 601 Oct 25 04:48 authorized_keys
-rw-------. 1 root root 668 Oct 25 04:48 id_dsa
-rw-r--r--. 1 root root 601 Oct 25 04:48 id_dsa.pub
-rw-r--r--. 1 root root 171 Oct 25 04:43 known_hosts
如果A 想 免密的登陆到B:将A的公钥放入到/.ssh/authorized_keys即可实现免密。
A:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
B:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
结论:B包含了A的公钥,A就可以免密的登陆
2,Hadoop的配置(应用的搭建过程)
规划路径:
mkdir /opt/bigdata
tar xf hadoop-2.6.5.tar.gz
mv hadoop-2.6.5 /opt/bigdata/
pwd
/opt/bigdata/hadoop-2.6.5
vi /etc/profile
export JAVA_HOME=/usr/java/default
export HADOOP_HOME=/opt/bigdata/hadoop-2.6.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile配置hadoop的角色:
必须给hadoop配置javahome要不ssh过去找不到
cd $HADOOP_HOME/etc/hadoop
vi hadoop-env.sh
export JAVA_HOME=/usr/java/default
给出NN角色在哪里启动
vi core-site.xml
fs.defaultFS
hdfs://node01:9000
配置hdfs 副本数为1.。。。
vi hdfs-site.xml
dfs.replication
1
dfs.namenode.name.dir
/var/bigdata/hadoop/local/dfs/name
dfs.datanode.data.dir
/var/bigdata/hadoop/local/dfs/data
dfs.namenode.secondary.http-address
node01:50090
dfs.namenode.checkpoint.dir
/var/bigdata/hadoop/local/dfs/secondary
配置DN这个角色再那里启动
vi slaves
node01
3,启动
hdfs namenode -format
start-dfs.sh
第一次:datanode和secondary角色会初始化创建自己的数据目录
[root@node11 hadoop]# cd /var/bigdata/hadoop/local/dfs/
[root@node11 dfs]# ls
data name secondary
[root@node11 dfs]#
访问:http://node01:50070
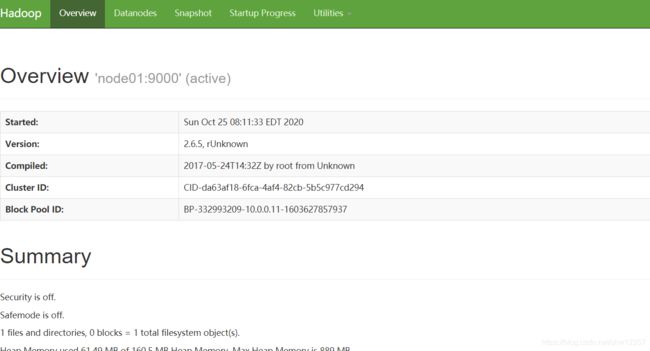
4,简单使用
hdfs dfs -mkdir /bigdata
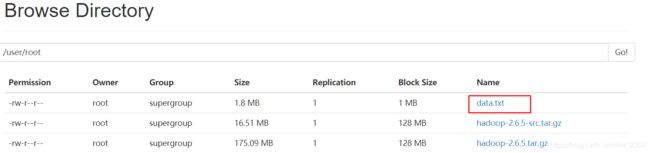
hdfs dfs -mkdir -p /user/root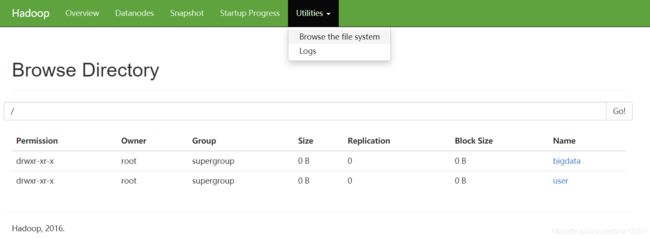
上传数据
hdfs dfs -put hadoop*.tar.gz /user/root
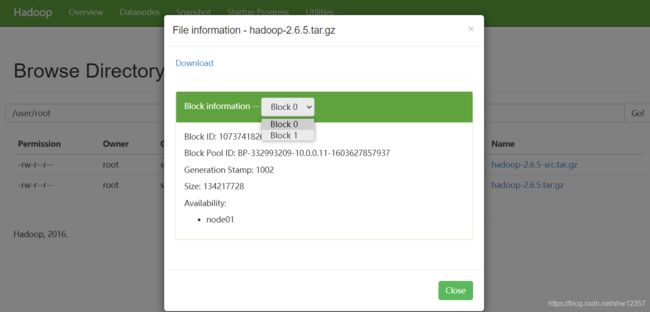
查看服务器的文件保存:
[root@node11 subdir0]# ll
total 197744
-rw-r--r--. 1 root root 17310774 Oct 25 08:32 blk_1073741825
-rw-r--r--. 1 root root 135251 Oct 25 08:32 blk_1073741825_1001.meta
-rw-r--r--. 1 root root 134217728 Oct 25 08:32 blk_1073741826
-rw-r--r--. 1 root root 1048583 Oct 25 08:32 blk_1073741826_1002.meta
-rw-r--r--. 1 root root 49377148 Oct 25 08:32 blk_1073741827
-rw-r--r--. 1 root root 385767 Oct 25 08:32 blk_1073741827_1003.meta
[root@node11 subdir0]# pwd
/var/bigdata/hadoop/local/dfs/data/current/BP-332993209-10.0.0.11-1603627857937/current/finalized/subdir0/subdir0
[root@node11 subdir0]#
5,上传自定义块的大小
[root@node11 ~]# for i in `seq 100000`;do echo "hello hadoop $i" >> data.txt ;done
[root@node11 ~]# ll -h
total 356M
-rw-------. 1 root root 1.3K Jun 27 00:01 anaconda-ks.cfg
-rw-r--r--. 1 root root 1.9M Oct 25 08:39 data.txt
-rw-r--r--. 1 root root 17M Oct 25 05:14 hadoop-2.6.5-src.tar.gz
-rw-r--r--. 1 root root 176M Oct 25 05:10 hadoop-2.6.5.tar.gz
-rw-r--r--. 1 root root 163M Oct 25 04:37 jdk-8u181-linux-x64.rpm
[root@node11 ~]# hdfs dfs -D dfs.blocksize=1048576 -put data.txt
[root@node11 ~]# cd /var/bigdata/hadoop/local/dfs/data/current/BP-332993209-10.0.0.11-1603627857937/current/finalized/subdir0/subdir0
[root@node11 subdir0]# ll
total 199612
-rw-r--r--. 1 root root 17310774 Oct 25 08:32 blk_1073741825
-rw-r--r--. 1 root root 135251 Oct 25 08:32 blk_1073741825_1001.meta
-rw-r--r--. 1 root root 134217728 Oct 25 08:32 blk_1073741826
-rw-r--r--. 1 root root 1048583 Oct 25 08:32 blk_1073741826_1002.meta
-rw-r--r--. 1 root root 49377148 Oct 25 08:32 blk_1073741827
-rw-r--r--. 1 root root 385767 Oct 25 08:32 blk_1073741827_1003.meta
-rw-r--r--. 1 root root 1048576 Oct 25 08:39 blk_1073741828
-rw-r--r--. 1 root root 8199 Oct 25 08:39 blk_1073741828_1004.meta
-rw-r--r--. 1 root root 840319 Oct 25 08:39 blk_1073741829
-rw-r--r--. 1 root root 6575 Oct 25 08:39 blk_1073741829_1005.meta