Django测试环境搭建及ORM查询(创建外键|夸表查询|双下划线查询)
文章目录
- 一、表查询数据准备及测试环境搭建
- 二、ORM操作相关方法
- 三、ORM常见查询关键字
- 四、双下划线查询
- 五、ORM底层SQL语句
- 六、ORM外键字段创建
- 七、外键字段数据操作
- 八、正反向概念
- 九、基于对象夸表查询(子查询)
- 十、双下划线夸表查询(连表操作)
一、表查询数据准备及测试环境搭建
1.首先连接上我们的数据库 Django有自带一个小型本地数据库Sqlite3
该数据库功能非常有限 并且针对日期类型的数据兼容性极差 所以我们还是需要连接MySQL数据库
2.Django切换切换MySQL数据库
找到settings.py文件中找到DATABASES8把里面书记Sqlite3更改为MySQL以及下面的数据库信息
NAME、HOST、PORT、USER、PASSWORD、CHARSET (版本区别请查看博主之前文章讲解)
3.定义模型
class User(models.Model):
uid = models.AutoField(primary_key=True, verbose_name='编号')
name = models.CharField(max_length=32, verbose_name='姓名')
age = models.IntegerField(verbose_name='年龄')
join_time = models.DateField(auto_now_add=True)
日期字段参数
auto_now: 每次操作数据并保存都会自动更新当前时间
auto_now_add: 只在创建数据的那一刻自动获取当前时间 之后如果不人为更改则不变
4.执行数据库迁移命令
每次输入完关于SQL语句都需要去写入到数据库
makemigrations 输入完命令之后app里面会自动创建一个py文件记录了创建了那些数据
migrate 输入完命令之后真正的执行到数据库里面去创建了
5.模型层测试环境准备
我们刚创建完我们的模型 但是现在需要查看数据 发现在当前文件下查看无论怎么输入都会报错 所以我们需要创建一个测试环境
方式1:
首先需要到自带的文件manage.py中复制前四行代码 到任意空的py文件夹中准备环境
import os
def main(): # 前三行
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'Django003.settings')
import django # 导入模块不能放在上面 否则会报错
django.setup()
from app01 import models
print(models.User.objects.filter())
if __name__ == '__main__': # 运行脚本不能忘
main()
方式2:
Pycharm提供的测试环境
Python console命令测试环境

二、ORM操作相关方法
我们现在的表格里面没有任何数据 需要去创建 也有三种方式
方式1: Create()
from app01 import models
res = models.User.objects.create(name='Lisa', age=20)
print(res) # create方法有一个返回值 打印出来是一个用户对象 User object (2)
print(res.uid)
print(res.name)
print(res.age)
print(res.pk) # PK是获取当前表格的主键字段 防止有很多张表的时候难以查询 不用查看真正的主键名称 直接PK即可
方式2:利用类类实例化对象然后调用save方法创建
user_ojb = models.User(name='Jack', age=25) # 仅仅产生一个对象 并不会操作数据库
user_ojb.save() # 用对象调用内置方法 Save才会保存到数据库
方式3:直接通过Pycharm右侧database创建
创建Create 更新Update 删除Delete

三、ORM常见查询关键字
| 名称 | 语法 | 说明 |
|---|---|---|
| filter | res1 = models.User.objects.filter(name=‘Like’, age=20) | 筛选数据 返回值是一个QuerySet(可以看成是列表套数据对象) 括号内不写查询条件 默认就是查询所有 括号内可以填写条件 并且支持多个 逗号隔开 默认是and关系 |
| all | res2 = models.User.objects.all() | 查询所有数据 返回值是一个QuerySet(可以看成是列表套数据对象) |
| first | res3 = models.User.objects.first() | 获取Queryset中第一个数据对象 如果为空则返回None |
| last | res4 = models.User.objects.last() | 获取Queryset中最后一个数据对象 如果为空则返回None |
| get | res5 = models.User.objects.get(pk=2) | 直接根据条件查询具体的数据对象 但是条件不存在直接报错 不推荐使用 |
| values | res6 = models.User.objects.values(‘name’, ‘age’) | 指定查询字段 结果是Queryset(可以看成是列表套字典数据) |
| values_list | res7 = models.User.objects.values_list() | 指定全部字段 结果是Queryset(可以看成是列表套元组数据) |
| order_by | res8 = models.User.objects.order_by(‘age’) 升序 res8_1 = models.User.objects.order_by(‘-age’, ‘name’)降序 |
指定字段排序 默认是升序 在字段前加负号则为降序 并且支持多个字段排序 |
| count | res9 = models.User.objects.count() | 统计orm查询之后结果集中的数据格式 |
| distinct | res10 = models.User.objects.values(‘name’, ‘age’).distinct() | 针对重复的数据集进行去重 一定要注意数据对象中的主键 |
| exclude | res11 = models.User.objects.exclude() | 针对括号内的条件取反进行数据查询 QuerySet(可以看成是列表套数据对象) |
| reverse | res12 = models.User.objects.all().order_by(‘age’).reverse() | 针对已经排了序的结果集做颠倒 |
| exists | res13 = models.User.objects.exists() | 判断查询结果集是否有数据 返回布尔值 但是几乎不用因为所有数据自带布尔值 |
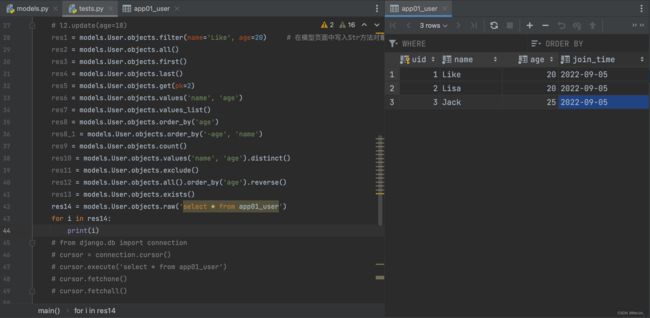
| raw | res14 = models.User.objects.raw(‘select * from app01_user’) | 执行SQL语句 |
1.当需要查询数据主键字段值的时候 可以使用pk忽略掉数据字段真正的名字
2.在模型类中可以定义一个__str__方法 便于后续数据对象被打印展示的是查看方便
3.Queryset中如果是列表套对象那么直接for循环和索引取值但是索引不支持负数
4.虽然queryset支持索引但是当queryset没有数据的时候索引会报错 推荐使用first
四、双下划线查询
比较运算符
大于 _ _ gt res = models.User.objects.filter(age__gt=25)
小于 _ _ lt res1 = models.User.objects.filter(age__lt=25)
大于等于 _ _ gte res2 = models.User.objects.filter(age__gte=24)
小于等于 _ _ lte res3 = models.User.objects.filter(age__lte=24)

成员运算符
在上面里面 _ _ in res = models.User.objects.filter(name__in=['Like', 'Lisa', 'Nana'])
范围查询(数字)
在上面范围内 _ _ range res1 = models.User.objects.filter(age__range=(20, 25))
模糊查询
忽略大写的 _ _ contains res2 = models.User.objects.filter(name__contains='l')
忽略大小写的 _ _ icontains res3 = models.User.objects.filter(name__icontains='l')
日期处理
年 _ _ year res4 = models.User.objects.filter(join_time__year=2022)
月 _ _ month res5 = models.User.objects.filter(join_time__month=9)
日 _ _ day res6 = models.User.objects.filter(join_time__day=5)

五、ORM底层SQL语句
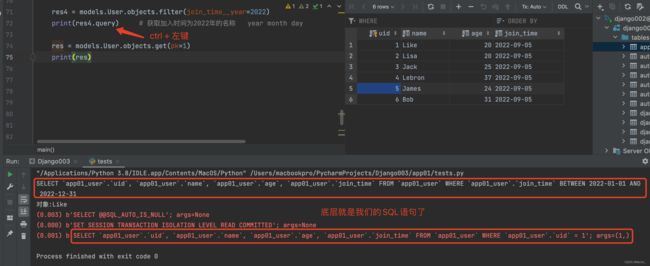
我们现在知道了怎么查询数据了但是它的底层语句逻辑是什么呢?
方式1:
如果是Queryset对象 那么可以直接点Ctrl+左键点击query查看SQL语句
方式2:
需要到配置文件Settings中找一个空白位置复制一下代码 主要作用打印所有ORM操作对应的SQL语句
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
六、ORM外键字段创建
一对多
ORM中外键字段建在多的一方 models.ForeignKey()
会自动添加_id后缀
多对多
ORM中有三种创建多对多字段的方式 models.ManyToManyField()
方式1:直接在查询频率较高的表中填写字段即可 自动创建第三张关系表
方式2:自己创建第三张关系表
方式3:自己创建第三张关系表 但是还是要orm多对多字段做关联
一对一
ORM中外键字段建在查询频率较高的表中 models.OneToOneField()
会自动添加_id后缀
django1.X 针对 models.ForeignKey() models.OneToOneField()不需要on_delete
django2.X 3.X 则需要添加on_delete参数
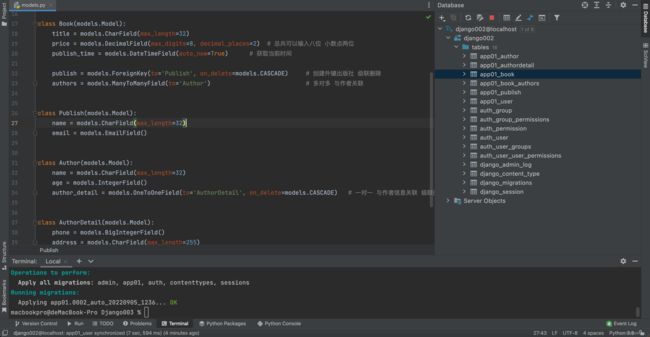
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8, decimal_places=2) # 总共可以输入八位 小数点两位
publish_time = models.DateTimeField(auto_now=True) # 获取当前时间
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE) # 创建外键出版社 级联删除
authors = models.ManyToManyField(to='Author') # 多对多 与作者关联
class Publish(models.Model):
name = models.CharField(max_length=32)
email = models.EmailField()
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
author_detail = models.OneToOneField(to='AuthorDetail', on_delete=models.CASCADE) # 一对一 与作者信息关联 级联删除
class AuthorDetail(models.Model):
phone = models.BigIntegerField()
address = models.CharField(max_length=255)
七、外键字段数据操作
models.ForeignKey(to='Publish', on_delete=models.CASCADE)
方式1:
直接给实际字段添加关联数据值 publish_id = 1
models.Book.objects.create(title='Python从入门到放弃', price=19999.88, publish_id=1)
方式2:
间接使用外键虚拟字段添加数据对象 publish=publish_obj
publish_obj = models.Publish.objects.filter(pk=2).first()
models.Book.objects.create(title='Django从入门到入土', price=28888.99, publish_id=publish_obj)
models.OneToOneField(to='AuthorDetail', on_delete=models.CASCADE) # 跟上面方法一样
方式1:
直接给实际字段添加关联数据值 author_detail_id = 1
models.Author.objects.create(phone=520, address='我爱零',publish_id=4)
方式2:
间接使用外键虚拟字段添加数据对象 author_detail=authorDetail_obj
detail_obj = models.Author.objects.filter(pk=2).first()
models.Author.objects.create(phone=110, address='警察局',publish_id=detail_obj)
models.ManyToManyField(to='Author')
方式1:
先拿到书籍的ID然后添加到第三张表的作者ID
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.add(1)
方式2:
先拿到作者的ID然后添加到第三张表的书籍ID
author_obj1 = models.Author.objects.filter(pk=1).first()
author_obj2 = models.Author.objects.filter(pk=2).first()
book_obj.author.add(author_obj1,author_obj2) # 括号内即可以填写数字值也可以填写数据对象 支持多个
remove()删除
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.remove(1 ) # 括号内即可以填写数字值也可以填写数据对象 支持多个
set()修改数据
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.set([2,]) # 括号内必须是可迭代对象
clear()清空数据
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.clear() # 删除表中ID为1的书籍 括号内不需要任何参数
八、正反向概念
正反向的概念核心就在于外键字段在谁手上
外键在自己手上则是正向查询
外键在别人手上则是反向查询
正向查询
通过书查询出版社 外键字段在书表中
反向查询
通过出版社查询书 外键字段不在出版社表中
ORM跨表查询口诀>>>:正向查询按外键字段 反向查询按表名小写
九、基于对象夸表查询(子查询)
基于对象的正向跨表查询
1.查询主键为1的书籍对应的出版社(书>>>出版社)
1>先根据条件查询数据对象(先查书籍对象)
book_obj = models.Book.objects.filter(pk=1).first()
2>以对象为基准 思考正反向概念(书查出版社 外键字段在书表中 所以是正向查询)
print(book_obj.publish) # 通过点的方式就可以拿到外键电影的数据
2.查询主键为3的书籍对应的作者(书>>>作者)
1>先根据条件查询数据对象(先查书籍对象)
book_obj = models.Book.objects.filter(pk=3).first()
2>以对象为基准 思考正反向概念(书查作者 外键字段在书表中 所以是正向查询)
print(book_obj.authors) # app01.Author.None
print(book_obj.authors.all()
3.查询jason的作者详情
1>先根据条件查询数据对象
author_obj = models.Author.objects.filter(name='Lisa').first()
2>以对象为基准 思考正反向概念
print(author_obj.author_detail)

基于对象的反向跨表查询
4.查询南方出版社出版的书籍
1>先拿出版社对象
publish_obj = models.Publish.objects.filter(name='南方出版社').first()
2>思考正反向
print(publish_obj.book) # 报错
print(publish_obj.book_set) # app01.Book.None
print(publish_obj.book_set.all())
5.查询Like写过的书
1>先拿作者对象
author_obj = models.Author.objects.filter(name='Like').first()
2>思考正反向
print(author_obj.book) # 报错
print(author_obj.book_set) # app01.Book.None
print(author_obj.book_set.all())
6.查询电话是520的作者
1>先拿作者详情对象
author_obj = models.AuthorDetail.objects.filter(phone=520).first()
2>思考正反向
print(author_obj.author)
'''根据以上6个题目 我们发现规律 多对多会数据需要all()一对一不用 反向需要加-set'''

十、双下划线夸表查询(连表操作)
基于双下划线的正向跨表查询
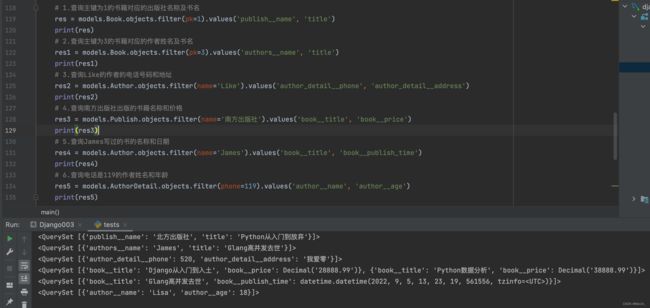
1.查询主键为1的书籍对应的出版社名称及书名
res = models.Book.objects.filter(pk=1).values('publish__name', 'title')
print(res)
2.查询主键为3的书籍对应的作者姓名及书名
res1 = models.Book.objects.filter(pk=3).values('authors__name', 'title')
print(res1)
3.查询Like的作者的电话号码和地址
res2 = models.Author.objects.filter(name='Like').values('author_detail__phone', 'author_detail__address')
print(res2)
基于双下划线的反向跨表查询
4.查询南方出版社出版的书籍名称和价格
res3 = models.Publish.objects.filter(name='南方出版社').values('book__title', 'book__price')
print(res3)
5.查询James写过的书的名称和日期
res4 = models.Author.objects.filter(name='James').values('book__title', 'book__publish_time')
print(res4)
6.查询电话是119的作者姓名和年龄
res5 = models.AuthorDetail.objects.filter(phone=119).values('author__name', 'author__age')
print(res5)
7.查询主键为1的书籍对应的作者电话号码
res6 = models.Book.objects.filter(pk=1).values('authors__author_detail__phone')
print(res6) # 这一道题涉及到三表查询
'''连表查询_ _ 表示夸字段 都是先获取到第一个主要信息再去获取后面的次要信息'''
技术小白记录学习过程,有错误或不解的地方请指出,如果这篇文章对你有所帮助请
点点赞收藏+关注谢谢支持 !!!