Java面试题(每天10题)-------连载(27)
目录
多线程篇
1、ReentrantReadWriteLock读写锁的使用
2、CyclicBarrier和CountDownLatch的用法以及区别
3、 Condition接口以及其实现原理
4、Fork/Join框架的理解
5、wait()和sleep()的区别
6、现成的五个状态(五种状态:创建、就绪、运行、阻塞和死亡)
7、start()方法和run()方法的区别
8、Runnable接口和Callable接口的区别
9、volatile关键字的作用
10、Java中如何获取到线程dump文件
多线程篇
1、ReentrantReadWriteLock读写锁的使用
1 、读写锁:分为读锁和写锁,多个读锁不互斥,读锁与写锁互斥,这是由 jvm ⾃⼰控制的,你只要上好相应的锁即可。2 、如果你的代码只读数据,可以很多⼈同时读,但不能同时写,那就上读锁;3 、如果你的代码修改数据,只能有⼀个⼈在写,且不能同时读取,那就上写锁。总之,读的时候上读锁,写的时候上写锁!
2、CyclicBarrier和CountDownLatch的用法以及区别
、 CyclicBarrier和CountDownLatch 都位于java.util.concurrent 这个包下:
CountDownLatch CyclicBarrier 减计数方式 加计数方式 基数为0时释放所有等待的线程 计数达到指定值时,释放所有等待线程 计数为0时,无法重置 计数达到指定值时,计数置为0重新开始 调用countDown()方法计数减一,调用await()方法只进行阻塞,对计数没有任何影响 调用await()方法计数加一,若加1后的值不等于构造方法的值,则线程阻塞 不可重复利用 可重复利用
3、 Condition接口以及其实现原理
1. 在 java.util.concurrent 包中,有两个很特殊的⼯具类, Condition 和 ReentrantLock ,使⽤过的⼈都知道,ReentrantLock(重⼊锁)是 jdk 的 concurrent 包提供的⼀种独占锁的实现。2. 我们知道在线程的同步时可以使⼀个线程阻塞⽽等待⼀个信号,同时放弃锁使其他线程可以能竞争到锁。3. 在 synchronized 中我们可以使⽤ Object 的 wait ()和 notify ⽅法实现这种等待和唤醒。4. 但是在 Lock 中怎么实现这种 wait 和 notify 呢?答案是 Condition ,学习 Condition 主要是为了⽅便以后学习 blockqueue 和concurrenthashmap的源码,同时也进⼀步理解 ReentrantLock 。
4、Fork/Join框架的理解
1、Fork就是把⼀个⼤任务切分为若⼲⼦任务并⾏的执⾏。2、Join就是合并这些⼦任务的执⾏结果,最后得到这个⼤任务的结果。
5、wait()和sleep()的区别
1、 sleep ()⽅法是线程类( Thread )的静态⽅法,让调⽤线程进⼊睡眠状态,让出执⾏机会给其他线程,等到休眠时间结束后,线程进⼊就绪状态和其他线程⼀起竞争cpu 的执⾏时间。因为 sleep () 是 static 静态的⽅法,他不能改变对象的机锁,当⼀个 synchronized 块中调⽤了 sleep () ⽅法,线程虽然进⼊休眠,但是对象的机锁没有被释放,其他线程依然⽆法访问这个对象。2 、 wait ()wait ()是 Object 类的⽅法,当⼀个线程执⾏到 wait ⽅法时,它就进⼊到⼀个和该对象相关的等待池,同时释放对象的机锁,使得其他线程能够访问,可以通过notify , notifyAll ⽅法来唤醒等待的线程。
6、现成的五个状态(五种状态:创建、就绪、运行、阻塞和死亡)
线程通常都有五种状态,创建、就绪、运⾏、阻塞和死亡。i. 第⼀是创建状态。在⽣成线程对象,并没有调⽤该对象的 start ⽅法,这是线程处于创建状态。ii. 第⼆是就绪状态。当调⽤了线程对象的 start ⽅法之后,该线程就进⼊了就绪状态,但是此时线程调度程序还没有把该线程设置为当前线程,此时处于就绪状态。在线程运⾏之后,从等待或者睡眠中回来之后,也会处于就绪状态。iii. 第三是运⾏状态。线程调度程序将处于就绪状态的线程设置为当前线程,此时线程就进⼊了运⾏状态,开始运⾏run函数当中的代码。iv. 第四是阻塞状态。线程正在运⾏的时候,被暂停,通常是为了等待某个时间的发⽣(⽐如说某项资源就绪)之后再继续运⾏。sleep , suspend , wait 等⽅法都可以导致线程阻塞。v. 第五是死亡状态。如果⼀个线程的 run ⽅法执⾏结束或者调⽤ stop ⽅法后,该线程就会死亡。对于已经死亡的线程,⽆法再使⽤start ⽅法令其进⼊就绪。
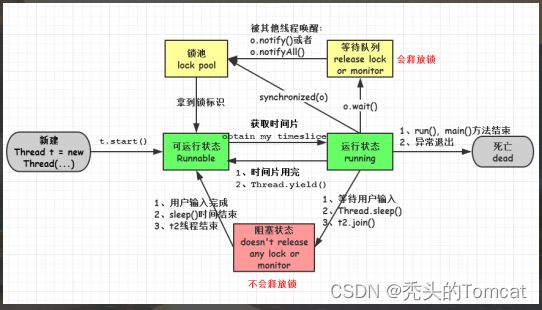

7、start()方法和run()方法的区别
1 、 start ()⽅法来启动⼀个线程,真正实现了多线程运⾏。2 、如果直接调⽤ run (),其实就相当于是调⽤了⼀个普通函数⽽已,直接调⽤ run ()⽅法必须等待 run ()⽅法执⾏完毕才能执⾏下⾯的代码,所以执⾏路径还是只有⼀条,根本就没有线程的特征,所以在多线程执⾏时要使⽤start ()⽅法⽽不是 run ()⽅法。
8、Runnable接口和Callable接口的区别
1. Runnable 接⼝中的 run ()⽅法的返回值是 void ,它做的事情只是纯粹地去执⾏ run ()⽅法中的代码⽽已;2. Callable 接⼝中的 call ()⽅法是有返回值的,是⼀个泛型,和 Future 、 FutureTask 配合可以⽤来获取异步执⾏的结果。
9、volatile关键字的作用
1. 多线程主要围绕可⻅性和原⼦性两个特性⽽展开,使⽤ volatile 关键字修饰的变量,保证了其在多线程之间的可⻅性,即每次读取到volatile 变量,⼀定是最新的数据。2. 代码底层执⾏不像我们看到的⾼级语⾔ —-Java 程序这么简单,它的执⾏是 Java 代码 –> 字节码 –> 根据字节码执⾏对应的C/C++ 代码 –>C/C++ 代码被编译成汇编语⾔ –> 和硬件电路交互, 现实中,为了获取更好的性能JVM可能会对指令进⾏重排序,多线程下可能会出现⼀些意想不到的问题。使⽤volatile则会对禁⽌语义重排序,当然这也⼀定程度上降低了代码执⾏效率。
10、Java中如何获取到线程dump文件
死循环、死锁、阻塞、⻚⾯打开慢等问题,查看线程 dump 是最好的解决问题的途径。所谓线程 dump 也就是线程堆栈,获取到线程堆栈有两步:1 、获取到线程的 pid ,可以通过使⽤ jps 命令,在 Linux 环境下还可以使⽤ ps -ef | grep java2 、打印线程堆栈,可以通过使⽤ jstack pid 命令,在 Linux 环境下还可以使⽤ kill -3 pid3 、另外提⼀点, Thread 类提供了⼀个 getStackTrace ()⽅法也可以⽤于获取线程堆栈。这是⼀个实例⽅法,因此此⽅法是和具体线程实例绑定的,每次获取到的是具体某个线程当前运⾏的堆栈。