【Python学习笔记】【待完善】(二十)爬虫初识:提取豆瓣电影排名前20
视频学习:Python入门+数据可视化
网络爬虫,是一种按照一定规则,自动抓取互联网信息的程序或者脚本。由于互联网数据的多样性和资源的有限性,根据用户需求定向抓取相关网页并分析已成为如今主流的爬取策略。
URL 代表着是统一资源定位符(Uniform Resource Locator)。URL 无非就是一个给定的独特资源在 Web 上的地址。
步骤:爬取网页——解析数据——保存数据
数据包
from bs4 import BeautifulSoup #网页解析·获取数据
import re #正则表达式·进行文字匹配
import urllib.request, urllib.error #制定URL·获取网页数椐
import xlwt #进行excel操作
import pymsql #进行数据库操作
访问一个URL信息
# 得到待定一个URL的网页内容
def askURL(url):
# 模拟浏览器向服务器发送信息
head = {
"User-Agent":" Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36"
}
request = urllib.request.Request(url, headers=head)
# 存储响应
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
这个地方有点小问题,有的网址能用decode("utf-8"),有的时候只能使用decode("unicode_escape")(中文乱码)
head获取:从f12的network-headers寻找,刷新之后点击最开始的一段,拖到最下面。
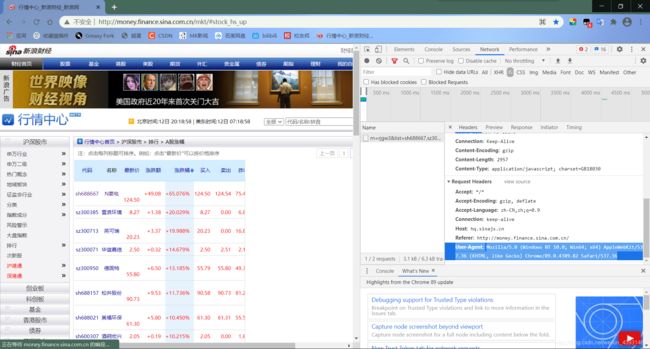
print(html)部分内容
爬取网页提取所需
根据正则表达式删选有用内容,比如影片名字。
标签解析Beautiful Soup是一个库,提供一些简单的、python式的用来处理导航、搜索、修改分析树等功能,通过解析文档为用户提供需要抓取的数据。我们需要的每个电影都在一个
的标签中,且每个div标签都有一个属性class= "item”.
正则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。Python中使用re模块操作正则表达式。
# 一些正则表达式 .*?表示由若干个字符
#影片详情链接的规则
findLink = re.compile(r'') #创建正则表达式对象,表示规则(字符串的模式)
#影片图片
findImgSrc = re.compile(r',re.S) #re.S 让换行符包含在字符中
#影片片名
findTitle = re.compile(r'(.*)')
#影片评分
findRating = re.compile(r'')
#找到评价人数
findJudge = re.compile(r'(\d*)人评价')
#找到概况
findInq = re.compile(r'(.*)')
#找到影片的相关内容
findBd = re.compile(r'(.*?)
',re.S)
# 爬取网页
def getData(baseurl):
datalist = []
for i in range(0,10): #调用获取页面信息的函数,10次
url = baseurl + str(i*25) #根据网页信息找到地址规律
html = askURL(url) #保存获取到的网页源码
# 2.逐一解析数据
soup = BeautifulSoup(html,"html.parser") #一个网页解析器
for item in soup.find_all('div',class_="item"): #查找符合要求的字符串,形成列表
data = [] #保存一部电影的所有信息
item = str(item)
#print(item)
#影片详情的链接
link = re.findall(findLink,item)[0] #re库用来通过正则表达式查找指定的字符串
data.append(link) #添加链接
imgSrc = re.findall(findImgSrc,item)[0]
data.append(imgSrc) #添加图片
titles = re.findall(findTitle,item) #片名可能只有一个中文名,没有外国名
if(len(titles) == 2):
ctitle = titles[0] #添加中文名
data.append(ctitle)
otitle = titles[1].replace("/","") #去掉无关的符号
data.append(otitle) #添加外国名
else:
data.append(titles[0])
data.append(' ') #外国名字留空
rating = re.findall(findRating,item)[0]
data.append(rating) #添加评分
judgeNum = re.findall(findJudge,item)[0]
data.append(judgeNum) #提加评价人数
inq = re.findall(findInq,item)
if len(inq) != 0:
inq = inq[0].replace("。","") #去掉句号
data.append(inq) # 添加概述
else:
data.append(" ") #留空
bd = re.findall(findBd,item)[0]
bd = re.sub('
bd = re.sub('/'," ",bd) #替换/
data.append(bd.strip()) #去掉前后的空格
#print(data)
datalist.append(data) #把处理好的一部电影信息放入datalist
return datalist
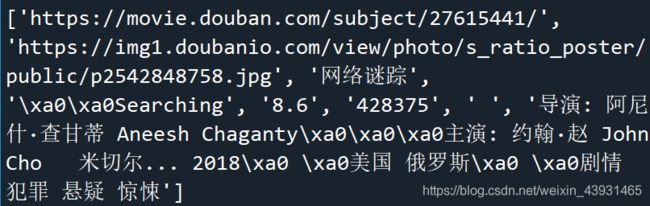
print(data)的打印内容:
提取数据到数据库【待编写】
# 保存数据
def saveData(datalist):
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='root',
database='stocks',
charset='utf8mb4') # 连接数据库
cursor = conn.cursor() # 游标获取
for obj in datalist:
sql = '''
....
'''
cursor.execute(sql) # 执行语句
conn.commit() # 使数据库生效
conn.close() # 数据库关闭
半完整代码
#-*- codeing = utf-8 -*-
from bs4 import BeautifulSoup #网页解析·获取数据
import re #正则表达式·进行文字匹配
import urllib.request, urllib.error #制定URL·获取网页数椐
import xlwt #进行excel操作
import pymysql #进行数据库操作
def main():
baseurl = 'https://movie.douban.com/top250?start='
# 1.爬取网页
datalist = getData(baseurl)
# 3.保存数据到数据库
saveData(datalist)
# 一些正则表达式 .*?表示由若干个字符
#影片详情链接的规则
findLink = re.compile(r'') #创建正则表达式对象,表示规则(字符串的模式)
#影片图片
findImgSrc = re.compile(r',re.S) #re.S 让换行符包含在字符中
#影片片名
findTitle = re.compile(r'(.*)')
#影片评分
findRating = re.compile(r'')
#找到评价人数
findJudge = re.compile(r'(\d*)人评价')
#找到概况
findInq = re.compile(r'(.*)')
#找到影片的相关内容
findBd = re.compile(r'(.*?)
',re.S)
# 爬取网页
def getData(baseurl):
datalist = []
for i in range(0,10): #调用获取页面信息的函数,10次
url = baseurl + str(i*25) #根据网页信息找到地址规律
html = askURL(url) #保存获取到的网页源码
# 2.逐一解析数据
soup = BeautifulSoup(html,"html.parser") #一个网页解析器
for item in soup.find_all('div',class_="item"): #查找符合要求的字符串,形成列表
data = [] #保存一部电影的所有信息
item = str(item)
#print(item)
#影片详情的链接
link = re.findall(findLink,item)[0] #re库用来通过正则表达式查找指定的字符串
data.append(link) #添加链接
imgSrc = re.findall(findImgSrc,item)[0]
data.append(imgSrc) #添加图片
titles = re.findall(findTitle,item) #片名可能只有一个中文名,没有外国名
if(len(titles) == 2):
ctitle = titles[0] #添加中文名
data.append(ctitle)
otitle = titles[1].replace("/","") #去掉无关的符号
data.append(otitle) #添加外国名
else:
data.append(titles[0])
data.append(' ') #外国名字留空
rating = re.findall(findRating,item)[0]
data.append(rating) #添加评分
judgeNum = re.findall(findJudge,item)[0]
data.append(judgeNum) #提加评价人数
inq = re.findall(findInq,item)
if len(inq) != 0:
inq = inq[0].replace("。","") #去掉句号
data.append(inq) # 添加概述
else:
data.append(" ") #留空
bd = re.findall(findBd,item)[0]
bd = re.sub('
bd = re.sub('/'," ",bd) #替换/
data.append(bd.strip()) #去掉前后的空格
#print(data)
datalist.append(data) #把处理好的一部电影信息放入datalist
return datalist
# 得到待定一个URL的网页内容
def askURL(url):
# 模拟浏览器向服务器发送信息
# 从f12的network-headers寻找
head = {
"User-Agent":" Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36"
}
request = urllib.request.Request(url, headers=head)
# 存储响应
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
# 保存数据
def saveData(datalist):
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='root',
database='stocks',
charset='utf8mb4') # 连接数据库
cursor = conn.cursor() # 游标获取
for obj in datalist:
sql = '''
....
'''
cursor.execute(sql) # 执行语句
conn.commit() # 使数据库生效
conn.close() # 数据库关闭
# 初始数据库,建表[出了点问题不能运行]
def init_db():
sql = '''
create table movie250
(
id integer primary key autoincrement,
info_link text,
pic_link text,
cname varchar,
ename varchar,
score numeric ,
rated numeric ,
instroduction text,
info text
)
'''
#创建数据表
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='root',
database='stocks',
charset='utf8mb4') # 连接数据库
cursor = conn.cursor() # 游标获取
cursor.execute(sql) # 执行语句
conn.commit() # 使数据库生效
conn.close() # 数据库关闭
if __name__ == "__main__":
main()
print('爬取完成!')