Spark性能优化四 内存
文章目录
- (一)性能优化分析
-
- 内容怎么被消耗的
- 如何预估程序会消耗多少内存呢
- (二) 性能优化方案
-
- 1)高性能序列化类库
- 2)持久化或者checkpoint
- 3)JVM 垃圾回收调优
- 4)提高并行度
- 5)数据本地化
(一)性能优化分析
一个计算任务的执行主要依赖于CPU、内存、带宽
Spark是一个基于内存的计算引擎,所以对它来说,影响最大的可能就是内存,一般我们的任务遇到了性能瓶颈大概率都是内存的问题,当然了CPU和带宽也可能会影响程序的性能,这个情况也不是没有的,只是比较少。
Spark性能优化,其实主要就是在于对内存的使用进行调优。
内容怎么被消耗的
- 每个Java对象,都有一个对象头,会占用16个字节,主要是包括了一些对象的元信息,比如指向它的类的指针。如果一个对象本身很小,比如就包括了一个int类型的field,那么它的对象头实际上比对象自身还要大。
- Java的String对象的对象头,会比它内部的原始数据,要多出40个字节。因为它内部使用char数组来保存内部的字符序列,并且还要保存数组长度之类的信息。
- Java中的集合类型,比如HashMap和LinkedList,内部使用的是链表数据结构,所以对链表中的每一个数据,都使用了Entry对象来包装。Entry对象不光有对象头,还有指向下一个Entry的指针,通常占用8个字节。
所以把原始文件中的数据转化为内存中的对象之后,占用的内存会比原始文件中的数据要大
如何预估程序会消耗多少内存呢
通过cache方法,可以看到RDD中的数据cache到内存中之后占用多少内存,这样就能看出了
代码如下:
object TestMemoryScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestMemoryScala")
.setMaster("local")
val sc = new SparkContext(conf)
val dataRDD = sc.textFile("hdfs://bigdata01:9000/hello_10000000.dat").cache()
val count = dataRDD.count()
println(count)
//while循环是为了保证程序不结束,方便在本地查看4040页面中的storage信息
while(true){
;
}
}
执行代码,访问localhost的4040端口界面
这个界面其实就是spark的任务界面,在本地运行任务的话可以直接访问4040界面查看
(二) 性能优化方案
- 高性能序列化类库
- 持久化或者checkpoint
- JVM垃圾回收调优
- 提高并行度
- 数据本地化
- 算子优化
1)高性能序列化类库
在任何分布式系统中,序列化都是扮演着一个重要的角色的。
如果使用的序列化技术,在执行序列化操作的时候很慢,或者是序列化后的数据还是很大,那么会让分布式应用程序的性能下降很多。所以,进行Spark性能优化的第一步,就是进行序列化的性能优化。
Spark默认会在一些地方对数据进行序列化,如果我们的算子函数使用到了外部的数据(比如Java中的自定义类型),那么也需要让其可序列化,否则程序在执行的时候是会报错的,提示没有实现序列化,这个一定要注意
Spark的初始化工作是在Driver进程中进行的,但是实际执行是在Worker节点的Executor进程中进行的;当Executor端需要用到Driver端封装的对象时,就需要把Driver端的对象通过序列化传输到Executor端,这个对象就需要实现序列化。
注意:遇到这种没有实现序列化的对象,解决方法有两种
- 如果此对象可以支持序列化,则将其实现Serializable接口,让它支持序列化
- 如果此对象不支持序列化,针对一些数据库连接之类的对象,这种对象是不支持序列化的,所以可以把这个代码放到算子内部,这样就不会通过driver端传过去了,它会直接在executor中执行。
Spark实际上提供了两种序列化机制:Java序列化机制和Kryo序列化机制, Spark只是默认使用了java这种序列化机制
Spark对于序列化的便捷性和性能进行了一个取舍和权衡。默认情况下,Spark倾向于序列化的便捷性,使用了Java自身提供的序列化机制——基于 ObjectInputStream 和ObjectOutputStream 的序列化机制,因为这种方式是Java原生提供的,使用起来比较方便.
区别:
- Java序列化机制:默认情况下,Spark使用Java自身的ObjectInputStream和ObjectOutputStream机制进行对象的序列化。只要你的类实现了Serializable接口,那么都是可以序列化的。Java序列化机制的速度比较慢,而且序列化后的数据占用的内存空间比较大,这是它的缺点
- Kryo序列化机制:Spark也支持使用Kryo序列化。Kryo序列化机制比Java序列化机制更快,而且序列化后的数据占用的空间更小,通常比Java序列化的数据占用的空间要小10倍左右。
如何使用Kryo序列号机制
- 首先要用 SparkConf 设置 spark.serializer 的值为 org.apache.spark.serializer.KryoSerializer ,就是将Spark的序列化器设置为 KryoSerializer 。这样,Spark在进行序列化时,就会使用Kryo进行序列化了。
- 使用Kryo时针对需要序列化的类,需要预先进行注册,这样才能获得最佳性能——如果不注册的话,Kryo也能正常工作,只是Kryo必须时刻保存类型的全类名,反而占用不少内存。
- Spark默认对Scala中常用的类型在Kryo中做了注册,但是,如果在自己的算子中,使用了外部的自定义类型的对象,那么还是需要对其进行注册。
什么场景下使用Kryo序列号
一般是针对一些自定义的对象,例如我们自己定义了一个对象,这个对象里面包含了几十M,或者上百M的数据,然后在算子函数内部,使用到了这个外部的大对象.
在这种情况下,比较适合使用Kryo序列化类库,来对外部的大对象进行序列化,提高序列化速
度,减少序列化后的内存空间占用。
案例代码:
object CryoserScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("CheckpointOpScala")
.setMaster("local")
//使用指定kryo序列号机制
.set("spark.serializer","org.apache.serializer.KryoSerializer")
.registerKryoClasses(Array(classOf[Person]))
val sc = new SparkContext(conf)
val dataRdd = sc.parallelize(Array("hello you","hello me"))
val wordsRdd = dataRdd.flatMap(_.split(" "))
val personRdd =wordsRdd.map(word=>Person(word,18)).persist(StorageLevel.MEMORY_ONLY_SER)
personRdd.foreach(println(_))
while(true){
;
}
}
case class Person(name:String,age:Int ) extends Serializable
2)持久化或者checkpoint
针对程序中多次被transformation或者action操作的RDD进行持久化操作,避免对一个RDD反复进行计算,再进一步优化,使用Kryo序列化的持久化级别,减少内存占用
为了保证RDD持久化数据在可能丢失的情况下还能实现高可靠,则需要对RDD执行Checkpoint操作
3)JVM 垃圾回收调优
由于Spark是基于内存的计算引擎,RDD缓存的数据,以及算子执行期间创建的对象都是放在内存中的,所以针对Spark任务如果内存设置不合理会导致大部分时间都消耗在垃圾回收上。
原因
对于垃圾回收来说,最重要的就是调节RDD缓存占用的内存空间,和算子执行时创建的对象占用的内存空间的比例。
默认情况下,Spark使用每个 executor 60% 的内存空间来缓存RDD,那么只有 40% 的内存空间来存放算子执行期间创建的对象
在这种情况下,可能由于内存空间的不足,并且算子对应的task任务在运行时创建的对象过大,那么一旦发现 40% 的内存空间不够用了,就会触发Java虚拟机的垃圾回收操作。因此在极端情况下,垃圾回收操作可能会被频繁触发。
修改方法
使用 SparkConf().set(“spark.storage.memoryFraction”, “0.5”) 可以进行修改,就是将RDD缓存占用内存空间的比例降低为 50% ,从而提供更多的内存空间来保存task运行时创建的对象。
因此,对于RDD持久化而言,完全可以使用Kryo序列化,加上降低其executor内存占比的方式,来减少其内存消耗。给task提供更多的内存,从而避免task在执行时频繁触发垃圾回收。
我们可以对task的垃圾回收进行监测,在spark的任务执行界面,可以查看每个task执行消耗的时间,以及task gc消耗的时间
检测垃圾回收
:8080界面 ,点击生成的第一个job,再点击进去查看这个job的stage,进入第一个stage,查看task的执行情况,看这里面的GC time的数值会不会比较大,最直观的就是如果gc time这里标红了,则说明gc时间过长。
Java GC
Java堆空间被划分成了两块空间:一个是年轻代,一个是老年代。
年轻代放的是短时间存活的对象
老年代放的是长时间存活的对象。
年轻代又被划分了三块空间, Eden、Survivor1、Survivor2
内容划分比例图:
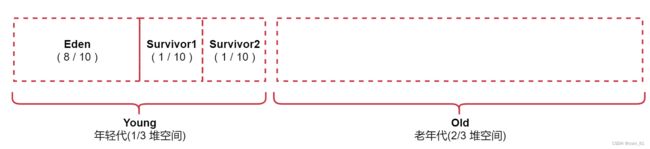
其中年轻代又被划分了三块, Eden,Survivor1,Survivor2 的比例为 8:1:1
Eden区域和Survivor1区域用于存放对象,Survivor2区域备用。
我们创建的对象,首先会放入Eden区域,如果Eden区域满了,那么就会触发一次Minor GC,进行年轻代的垃圾回收(其实就是回收Eden区域内没有人使用的对象),然后将存活的对象存入Survivor1区域,再创建对象的时候继续放入Eden区域。第二次Eden区域满了,那么Eden和Survivor1区域中存活的对象,当第三次Eden区域再满了的时候,Eden和Survivor2区域中存活的对象,会一块被移动到Survivor1区域中,按照这个规律进行循环。
如果一个对象,在年轻代中,撑过了多次垃圾回收(默认是15次),都没有被回收掉,那么会被认为是长时间存活的,此时就会被移入老年代。此外,如果在将Eden和Survivor1中的存活对象,尝试放入Survivor2中时,发现Survivor2放满了,那么会直接放入老年代。此时就出现了,短时间存活的对象,也会进入老年代的问题。如果老年代的空间满了,那么就会触发Full GC,进行老年代的垃圾回收操作,如果执行Full GC也释放不了内存空间,就会报内存溢出的错误了。
注意:
Full GC是一个重量级的垃圾回收,Full GC执行的时候,程序是处于暂停状态的,这样会非常影响性能。
垃圾回收调优目标
只有真正长时间存活的对象,才能进入老年代,短时间存活的对象只能呆在年轻代。不能因为某个Survivor区域空间不够,在Minor GC时,就进入了老年代,从而造成短时间存活的对象,长期呆在老年代中占据了空间,这样Full GC时要回收大量的短时间存活的对象,导致Full GC速度缓慢。
如果发现,在task执行期间,大量full gc发生了,那么说明,年轻代的Eden区域,给的空间不够大。
此时可以执行一些操作来优化垃圾回收行为
- 最直接的就是提高Executor的内存
在spark-submit中通过参数指定executor的内存
--executor-memory 1G
- 调整Eden与s1和s2的比值【一般情况下不建议调整这块的比值】
-XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代).设置为4,则
年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
-XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的大小比值.设置为4,则两个Survivor区与
一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
4)提高并行度
实际上Spark集群的资源并不一定会被充分利用到,所以要尽量设置合理的并行度,来充分地利用集群的资源,这样才能提高Spark程序的性能。
Spark会自动设置以文件作为输入源的RDD的并行度,依据其大小,比如HDFS,就会给每一个block创建一个partition,也依据这个设置并行度。对于reduceByKey等会发生shuffle操作的算子,会使用并行度最大的父RDD的并行度。
可以手动使用 textFile()、parallelize() 等方法的第二个参数来设置并行度;也可以使用 spark.default.parallelism 参数,来设置统一的并行度。Spark官方的推荐是,给集群中的每个cpu core 设置 2~3 个task。
最好的情况,就是每个cpu core都不闲着,一直在运行,这样可以达到资源的最大使用率,其实让一个cpu core运行一个task都是有点浪费的,官方也建议让每个cpu core运行2~3个task,这样可以充分压榨CPU的性能.
原因
因为每个task执行的顺序和执行结束的时间很大概率是不一样的,如果正好有10个cpu,运行10个taks,那么某个task可能很快就执行完了,那么这个CPU就空闲下来了,这样资源就浪费了。
演示代码:
object MoreParallelismScala{
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("CheckpointOpScala")
.setMaster("local")
//设置全局并行度
conf.set("spark.default.parallelism","5")
val sc = new SparkContext(conf)
val dataRDD = sc.parallelize(Array("hello","you","hello","me","hehe","hel
dataRDD.map((_,1))
.reduceByKey(_ + _)
.foreach(println(_))
sc.stop()
}
}
Spark-submit常用配置参数
--name mySparkJobName:指定任务名称
--class com.imooc.scala.xxxxx :指定入口类
--master yarn :指定集群地址,on yarn模式指定yarn
--deploy-mode cluster :client代表yarn-client,cluster代表yarn-cluster
--executor-memory 1G :executor进程的内存大小,实际工作中设置2~4G即可
--num-executors 2 :分配多少个executor进程
--executor-cores 2 : 一个executor进程分配多少个cpu core
--driver-cores 1 :driver进程分配多少cpu core,默认为1即可
--driver-memory 1G:driver进程的内存,如果需要使用类似于collect之类的action算子向
--jars fastjson.jar,abc.jar 在这里可以设置job依赖的第三方jar包【不建议把第三方依赖
--conf "spark.default.parallelism=10":可以动态指定一些spark任务的参数,指定多个参
5)数据本地化
数据本地化对于Spark Job性能有着巨大的影响。如果数据以及要计算它的代码是在一起的,那么性能当然会非常高。但是,如果数据和计算它的代码是分开的,那么其中之一必须到另外一方的机器上。通常来说,移动代码到其它节点,会比移动数据到代码所在的节点,速度要得多,因为代码比较小。Spark也正是基于这个数据本地化的原则来构建task调度算法的。
数据本地化级别
数据本地化级别 解释
PROCESS_LOCAL 进程本地化,性能最好:数据和计算它的代码在同一个JVM进程中
NODE_LOCAL 节点本地化:数据和计算它的代码在一个节点上,但是不在一个JVM进程
RACK_LOCAL 数据和计算它的代码在一个机架上,数据需要通过网络在节点之间进行传
ANY 数据可能在任意地方,比如其它网络环境内,或者其它机架上,性能最差
Spark倾向使用最好的本地化级别调度task,但这是不现实的
如果目前我们要处理的数据所在的executor上目前没有空闲的CPU,那么Spark就会放低本地化级别。这时有两个选择:
第一,等待,直到executor上的cpu释放出来,那么就分配task过去;
第二,立即在任意一个其它executor上启动一个task。
Spark默认会等待指定时间,期望task要处理的数据所在的节点上的executor空闲出一个cpu,从而将task分配过去,只要超过了时间,那么Spark就会将task分配到其它任意一个空闲的executor上可以设置参数, spark.locality 系列参数,来调节Spark等待task可以进行数据本地化的时间
spark.locality.wait(3000毫秒):默认等待3秒
spark.locality.wait.process:等待指定的时间看能否达到数据和计算它的代码在同一个JVM
spark.locality.wait.node:等待指定的时间看能否达到数据和计算它的代码在一个节点上执行
spark.locality.wait.rack:等待指定的时间看能否达到数据和计算它的代码在一个机架上