机器学习常见算法
机器学习常见算法
先说算法,其实算法是个很大的概念,除了机器学习算法,还有很多非机器学习算法,如编程里解决排序的快排、堆排、冒泡,也是算法。只是机器学习太火了,一提算法,多想到的是机器学习算法。
1. 决策树
决策树,一种预测模型,代表的是对象属性与对象值之间的一种映射关系。
一般来讲通过学习样本得到一个决策树,这个决策树能够对新的数据给出正确的分类。
这里举一个简单的例子:比如说,样本数据为用户的行为信息,同时已知每个用户的分类信息,假设分类为流失用户、非流失用户。
然后我根据多个样本数据训练出的多种多样的模型,下面画了一个简单的决策模型,其中事件可以是:是否有过订单,被赞次数超过5次等等这种(事件不是啥专有名词哈,我这里是为了偷懒不去举例,而用它代替)。

此外,为了验证哪个模型更准,可以再用一组新的样本数据作为测试数据,套入模型,看看模型跑出的分类和实际分类误差多少,从此来衡量模型的准确性。
这里引入一下训练样本和测试样本,很多训练过程都是这样处理的,样本数据划分为训练样本和测试样本,训练样本用来生成模型,测试样本用来验证准确性。
同时这里面的用户的行为事件就是“特征”,分类(是否为流失用户)就是“标签”。
回顾一下:
- 特征:即数据的属性,通过数据的这些特征可以代表数据的特点。
- 标签:对数据的预测结果。
至于模型是怎么训练生成的,具体算法啥样,就不介绍了(其实是我也写不清楚)。
决策树在实际工作中基本应用于给人群分类,最好的应用场景是要把人群分类,并找到不同类别人群的不同特征,比如上面的例子,就可以做个流失模型,通过用户的行为来提前找到哪些人有流失风险,并通过专门优惠等手段挽留。也可以发现哪些关键节点导致了流失,在这些节点上加一些运营策略来减少流失。
为了防止上图误导大家,找了其他的决策树模型示例。


2. 回归算法
统计学来讲,利用统计方法来建立一个表示变量之间相互关系的方程,这样的统计方法被称为回归分析。
回归算法就可以理解是研究不同变量相关关系的一个机器学习算法。多说一句,其实很多机器学习算法都是来自统计学。
回归算法有两个重要的子类:线性回归和逻辑回归。
线性回归
这里从简单线性回归入手介绍,也就是我举得例子只是研究两个样本变量之间的线性关系。
假设我们来研究考试成绩和复习时间的关系,数据如下:
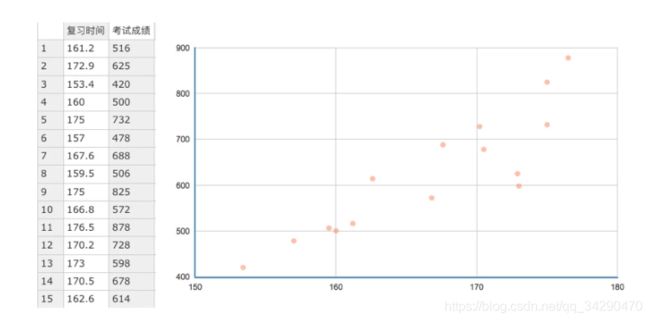
我想找出考试成绩和复习时间的规律,怎么找呢?
这里就是拟合出一条直线,所以这条直线需要“穿过”所有的点,并且与各个点的距离尽可能的小。
解释一下,简单的线性回归一般是使用“最小二乘法”来求解,最小二乘法的思想:假设我们拟合出的直线代表数据的真实值,而观测到的数据代表拥有误差的值。为了尽可能减小误差的影响,需要求解一条直线使所有误差的平方和最小。
假设拟合出的这条直线的函数如下:
学习成绩 = a * 复习时间 + b
a、b都是直线的参数。获得这些参数以后,我就可以计算出学生的成绩。
这个结果可能和实际有些偏离,由于这条直线综合考虑了大部分的情况,因此从“统计”意义上来说,这是一个最合理的预测。但是如果数据越多,模型就越能够考虑到越多的情况,由此对于新情况的预测效果可能就越好。所以其实机器学习准不准,很大程度看你喂的数据够不够多。
逻辑回归
逻辑回归是一种与线性回归非常类似的算法,属于分类算法。
逻辑回归只是对线性回归的计算结果加上了个函数进行处理,将数值结果转化为了0到1之间的概率,根据这个概率可以做预测,例如概率大于0.5,则肿瘤是否是恶性的等等。从直观上来说,逻辑回归是画出了一条分类线,见下图(也有划出非线性分类线的逻辑回归)。
假设我们有一组肿瘤患者的数据,这些患者的肿瘤中有些是良性的(图中的蓝色点),有些是恶性的(图中的红色点)。这里肿瘤的红蓝色可以被称作数据的 “标签”。同时每个数据包括两个“特征”:患者的年龄与肿瘤的大小。我们将这两个特征与标签映射到这个二维空间上,形成了我上图的数据。

当我有一个绿色的点时,该判断这个肿瘤是恶性的还是良性的呢?根据红蓝点我们训练出了一个逻辑回归模型,也就是图中的分类线。这时,根据绿点出现在分类线的左侧,因此我们判断它的标签应该是红色,也就是说属于恶性肿瘤。
3. 神经网络
神经网络算法是80年代机器学习界非常流行的算法,不过在90年代中途衰落。现在,携着“深度学习”之势,神经网络重装归来,重新成为最强大的机器学习算法之一。
神经网络的学习机理就是分解与整合。
在这个网络中,分成输入层、隐藏层和输出层。
输入层负责接收信号,隐藏层负责对数据的分解与处理,最后的结果被整合到输出层。
比方说,一个正方形,分解为四个折线进入视觉处理的下一层中。四个神经元分别处理一个折线(每个处理单元事实上就是一个逻辑回归模型,逻辑回归模型接收上层的输入,把模型的预测结果作为输出传输到下一个层次)。
每个折线再继续被分解为两条直线,然后处理,再将每条直线再被分解为黑白两个面处理。
整个过程就是一个复杂的图像变成了大量的细节进入神经元,神经元处理以后再进行整合,最后得出了看到的是正方形的结论。
4. SVM(支持向量机)
从某种意义上来说是逻辑回归算法的强化:通过给予逻辑回归算法更严格的优化条件,支持向量机算法可以获得比逻辑回归更好的分类界线。但是如果没有某类函数技术,则支持向量机算法最多算是一种更好的线性分类技术。
5. 聚类算法
聚类算法的目的则是通过训练,推测出这些数据的标签。训练数据都是不含标签的,算是典型的无监督算法,后续会介绍有无监督算法的区分。
让我们还是拿一个二维的数据来说,某一个数据包含两个特征。我希望通过聚类算法,给他们计算分类打上标签,我该怎么做呢?
简单来说,聚类算法就是计算种群中的距离,根据距离的远近将数据划分为多个族群。
聚类算法中最典型的代表就是K-Means算法
k-means聚类的目的是:把n个点(可以是样本的一次观察或一个实例)划分到k个聚类中,使得每个点都属于离他最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准。

K-means常用的场景是在不清楚用户有几类时,尝试性的将用户进行分类,并根据每类用户的不同特征,决定下步动作。(决策树也可以做这件事,但需要先定义出特征,因此在探索特征未知的领域时,聚类可能更好用一些)
6. 降维算法
也是一种无监督学习算法,其主要特征是将数据从高维降低到低维层次。
例如,房价包含房子的长、宽、面积与房间数量四个特征,也就是维度为4维的数据。可以看出来,长与宽事实上与面积表示的信息重叠了,例如面积=长 × 宽。通过降维算法我们就可以去除冗余信息,将特征减少为面积与房间数量两个特征。
7. 推荐算法
推荐系统中常用到的算法包括协同过滤算法(item_base,user_base)、用户偏好算法、关联规则算法、聚类算法、内容相似性算法(content_base),以及一些其它的补充算法。
其中最有名的算法就是协同过滤算法,核心思想是物以类聚,人以群分。具体可以分为基于用户的协同过滤算法和基于物品的协同过滤算法。
item_base是根据集体用户行为算出物品间的相似度,然后把与用户看过的物品或者购买过的物品最相似的物品推荐给该用户。
user_base是根据集体行为计算用户之间的相似度,比如A跟B计算出来非常相似,则可以把B喜欢的内容,但A还没有看过,推荐给A。
用户偏好算法是根据用户偏好算出来用户感兴趣的内容/产品,然后推荐给用户。
关联规则算法是算出物品间的支持度和置信度。最常见的应用是组合购买,啤酒和尿不湿是非常经典的例子了。
聚类算法,可以对用户进行聚类,也可以对产品进行聚类。聚类后可以针对大类进行推荐,或者继续计算用户类和产品类之间的关系。
content_base是根据物品本身的属性进行关联性运算,计算出物品间的相似性,最常见的应用是同类推荐。
机器学习算法分类(监督和无监督区别)
训练数据有标签,则为监督学习算法,没标签则为无监督学习算法,推荐算法较为特殊,既不属于监督学习,也不属于非监督学习,是单独的一类。
上述算法除了聚类、降维属于无监督学习算法,推荐是单独一类,其余都是监督学习算法。
其实还有半监督学习算法,也就是训练数据部分有标签,部分没标签。
总体来讲,相对对于监督学习,无监督学习如聚类算法效果差了些。但是监督学习需要标签,标签哪里来? 在实际应用中,标签的获取常常需要极大的人工工作量,有时甚至非常困难。现在很多做大数据的会招人工来打标签,制定打标规则啥的。
现在再看机器学习的概念,其实本质就是找到特征和标签间的关系。这样当有特征而无标签的未知数据输入时,我们就可以通过已有的关系得到未知数据标签。