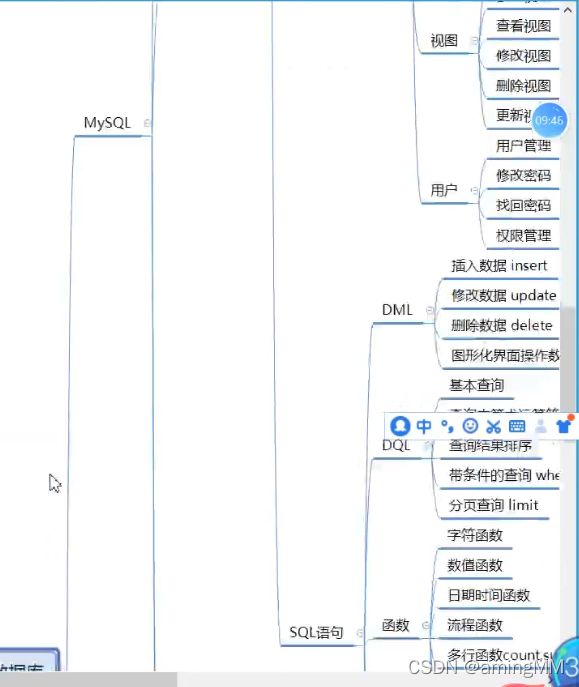
开发知识点-Python

Python从小白到入土
- python渗透测试安全工具开发锦集
- Python安全工具编程基础
- 第一章 Python在网络安全中的应用
-
- 第一节 Python黑客领域的现状
- 第二节 我们可以用Python做什么
- 第三节 第一章课程内容总结
- 第二章 python安全应用编程入门
-
- 第一节 Python正则表达式
- 第二节 Python Web编程
-
- requests
- 第三节 Python多线程
-
- 线程进程
- thread
- threading
- queue
- 第四节 Python网络编程
-
- socket
- 反弹shell
- 第五节 Python数据库编程
-
- MySQLdb
- 数据库 结构
- 第三章 Python爬虫技术实现
-
- 第一节 Python爬虫BeautifulSoup模块的介绍
-
- 解析html文件
- BeautifulSoup
- 第二节 Python爬虫hackhttp模块的介绍
- 第三节 结合BeautifulSoup和hackhttp的爬虫实例
- 第四节 爬虫多线程
- threading 构造类 稳定
-
- 初始化 导入生产者模块
- Python安全工具编程进阶
-
- Python信息收集工具编写
- 第一节 高精度字典生成
- 第二节 WEB目录扫描程序
- 第三节 C段WEB服务扫描
- 基础
-
- 六种数据类型
- 异常
- 装饰器
- global
- 运算符
-
- 位运算符
- 累加 累积
- 标准库模块
- 内置库/函数
-
- setuptools
- 模块
- GUI
- anaconda
- 爬虫
- 打包
- python-pip命令
-
- print() 输出颜色
-
-
- 显示方式
-
- 项目 重新打开
-
- 删掉 venv
- 正则表达式(regular expression)
- re.compile 函数
-
- 特殊的字符序列
-
-
-
-
- 作用: 检查一个字符串是否与 某种模式 匹配
-
-
- re.match(pattern, string, flags=0) 函数
-
- reportlab
- 字典
- 变量
-
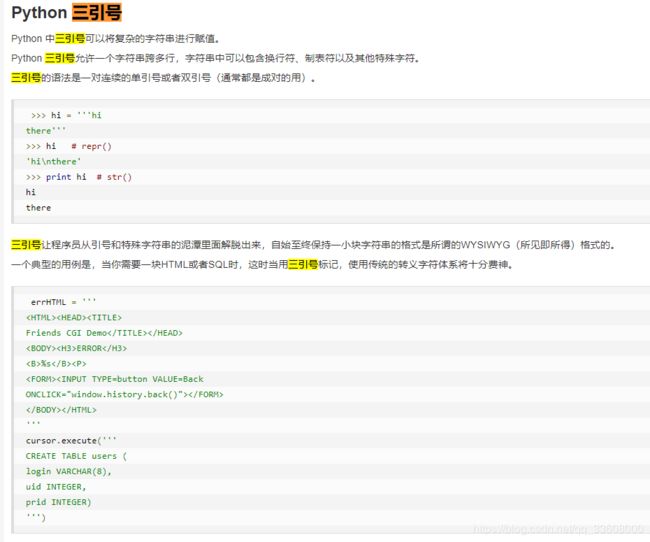
- 1.Python的自述
- 2.Python简介
- 3.Python开发环境的安装
- Python爬虫——新闻热点爬取
- Python爬虫——使用Python爬取代理数据
-
- 结构的分析以及网页数据的提取
- IP代理池
- 环境搭建
-
-
- linux 环境配置
- #虚拟环境搭建#
-
- 我们使用 virtualenvwrapper (包装的env)
-
-
-
- virtualenv
-
-
- python爬虫——入门(1)
-
-
- #认识爬虫#
- #知识储备#
-
- #学习问题#
- #爬虫正能量#
- #robots协议#
-
- Opencv for python
- opencv 简介
- 安装
-
-
- opencv包安装
-
- 简单图像处理
-
-
-
- 图像像素存储形式
- 图像读取和写入
- 图像像素获取和编辑
-
-
- QQ/微信 邮件 群发技术实现
-
-
- 由于外包开发 ,自己也需要 所以开发点 常用账号的 软件
-
- 添加依赖
- 实验原理
-
- 微信itchat 手册 https://itchat.readthedocs.io/zh/latest/
- 关键点
-
- 安装好之后,在程序中引用该库
- QQ群发实现
-
-
-
- 安装时用 pip install 然后直接把 whl 文件拖到 cmd 里就生成路径了
-
- 邮件群发
-
-
- 循环结构正弦幂级数展开及图像
- 重写数组类对象结构实现
-
-
- 重写数组类
- 从数组中取下标 打印数组中元素
-
- 搭建python环境
- 走进python
-
- (Python 3.0+)
- 解析器
-
-
-
- Xpath
-
- 节点选取
-
-
- 爬取文章自动发送QQ群
-
-
-
-
- Python的re模块 正则表达式
-
- 正则表达式处理函数
- - 如果匹配成功则返回一个Match Object对象,该对象有以下属性、方法:
- 语法
- 反斜杠的困扰
- lxml中etree
-
- 采用的etree去选取对应的xpath
- requests.get()参数
- web客户端验证 参数-auth
-
-
-
- 模拟登陆自动刷新
-
-
-
-
- urllib2库的基本使用
-
-
-
- Python黑帽子-Pentesters手记
- 视觉识别实战&&coreML
-
-
-
- 人工智能接口
-
-
python渗透测试安全工具开发锦集
Python安全工具编程基础
第一章 Python在网络安全中的应用
第一节 Python黑客领域的现状
-
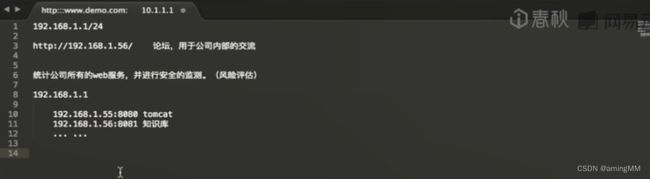
漏扫平台 poc suite

-
敏感目录
-
常见文件
-
常见漏洞扫描



第二节 我们可以用Python做什么

- 正则表达式 匹配
- 爬虫 收集 后台、敏感目录文件 数据
- 效率
- 在网络上 发送数据 反弹 、木马等

第三节 第一章课程内容总结

pycharm sublime



自动补全 分屏 快捷键
规范
方法函数 小写
类 头字母大写
默认规范
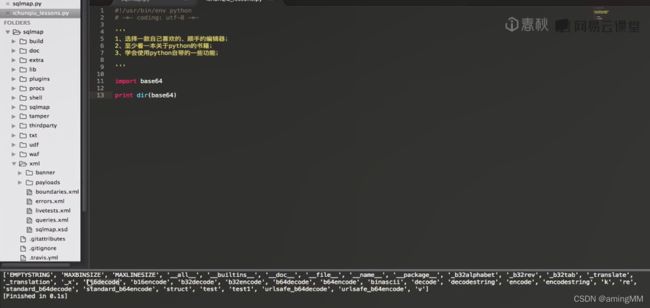
- 编程语言本身自带 功能
b16 b32 b64 encode decode





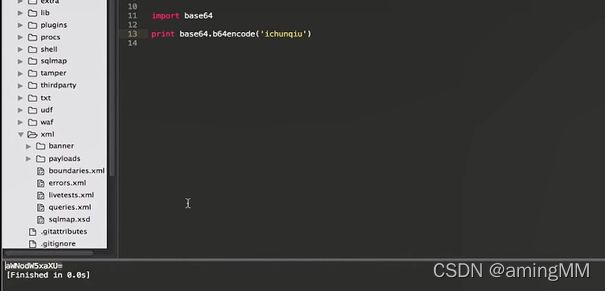
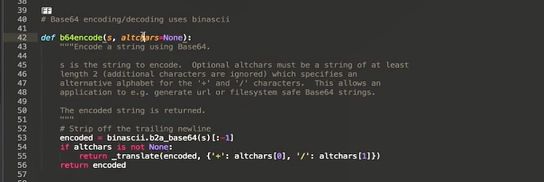
将 二进制 转换为 ascii码


加号 与 斜线的 替换 第二个参数
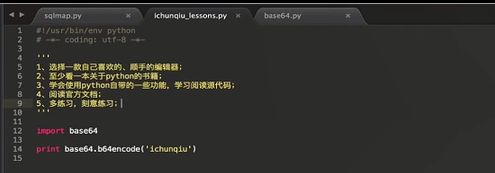
第二章 python安全应用编程入门
第一节 Python正则表达式
python 安全 编程

python 核心编程
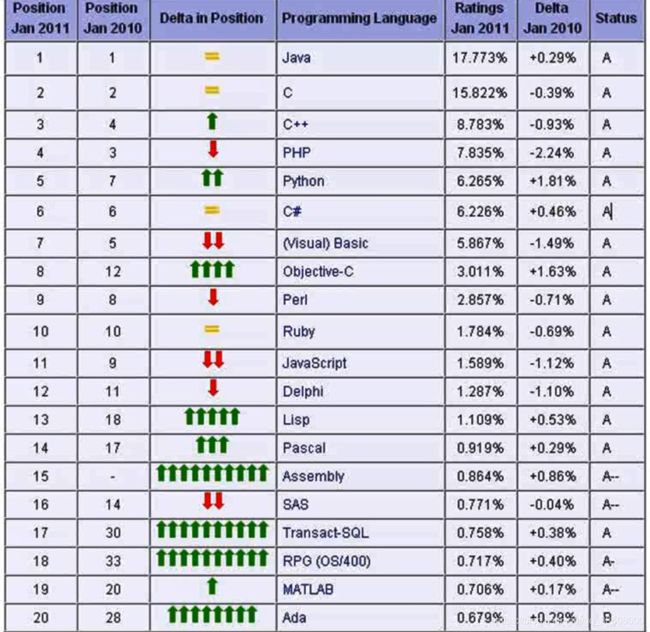
知道创宇 python技能表
https://blog.knownsec.com/Knownsec_RD_Checklist/index.html

简单 功能强大


















r 原生字符
匹配标题 内容


字符编码

遍历 获取

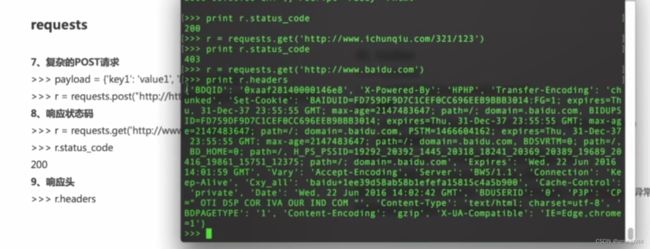
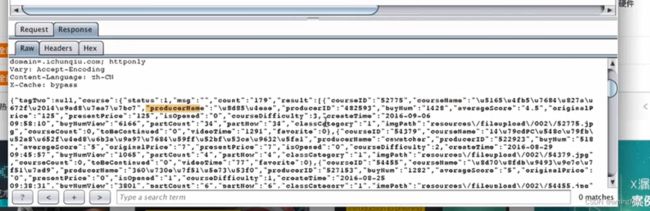
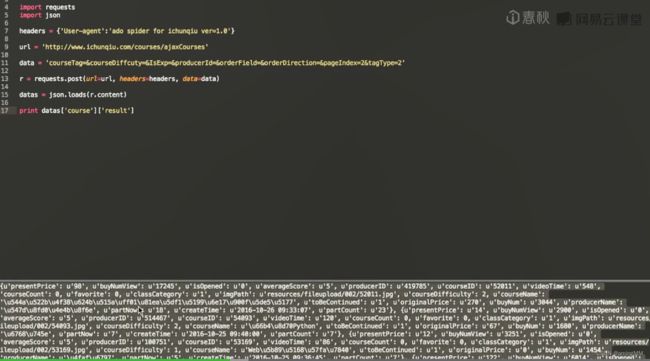
第二节 Python Web编程





requests

![]()


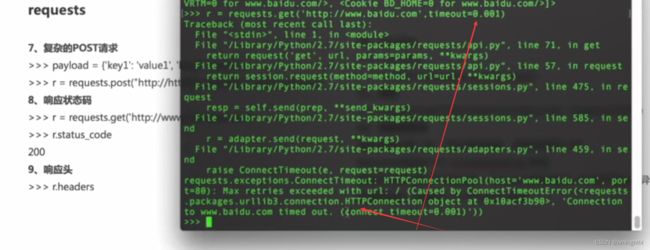

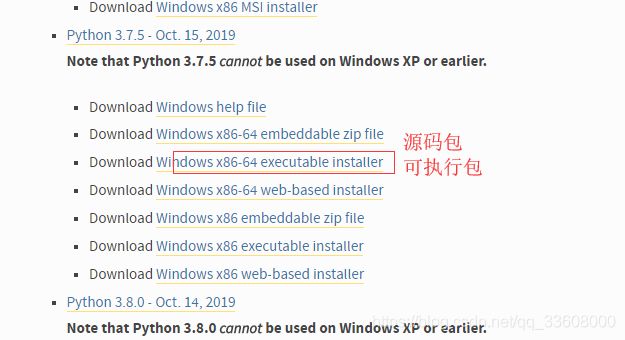
- 目录扫描
- 缺陷程序 --> 漏扫 -->识别web 漏洞
- 登录界面


防爬处理


json格式





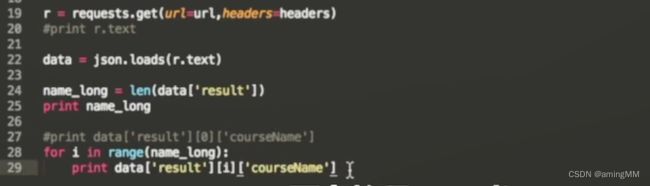


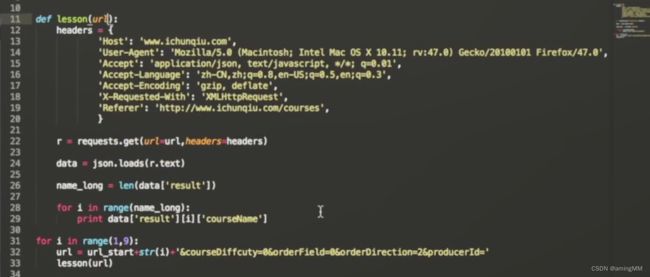

第三节 Python多线程


线程进程



thread

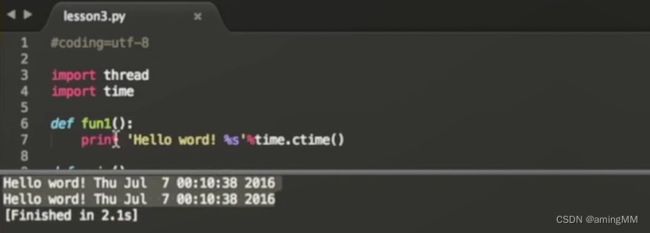






threading




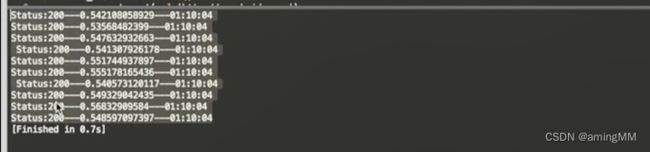


queue


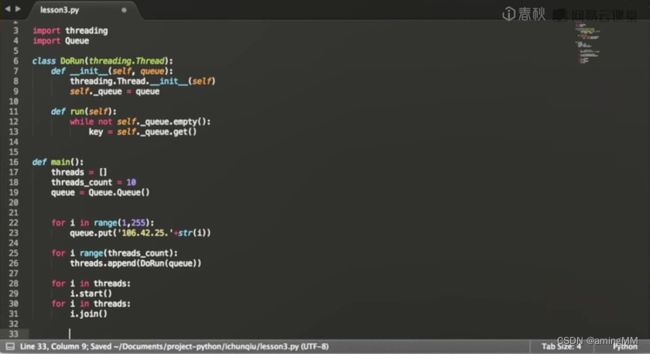
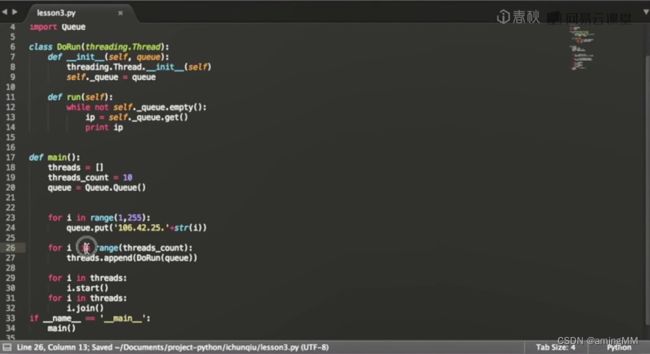
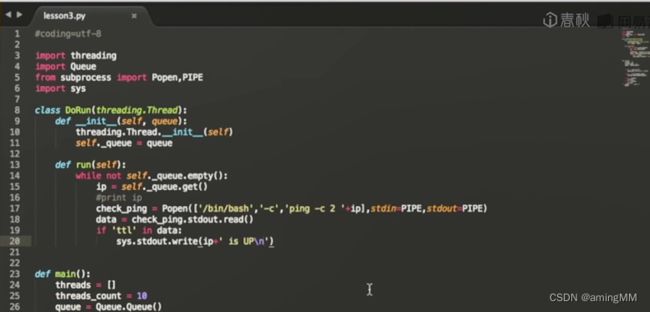


第四节 Python网络编程



socket








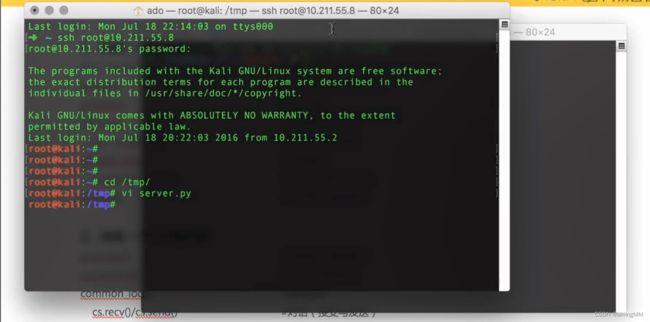


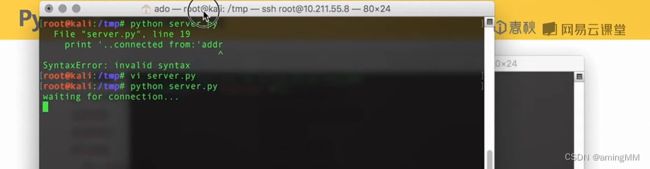

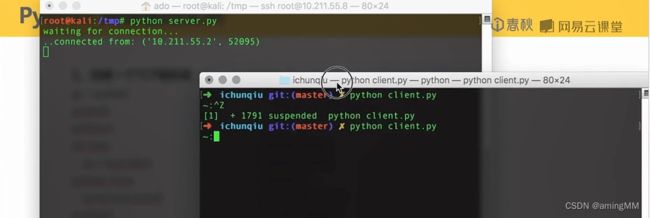
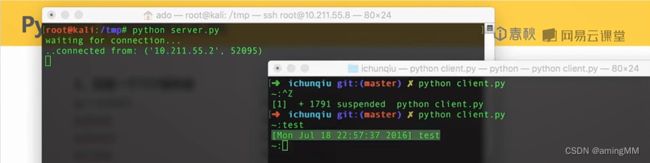

反弹shell



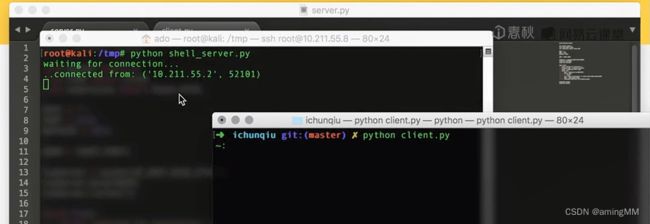


第五节 Python数据库编程








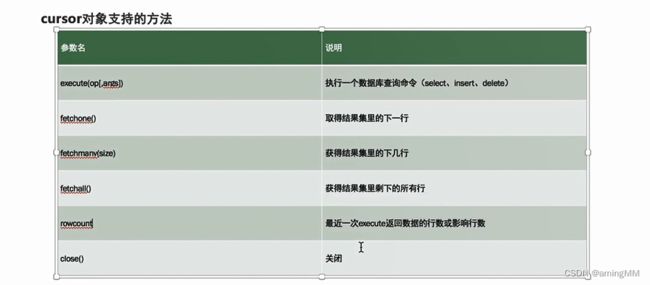
MySQLdb
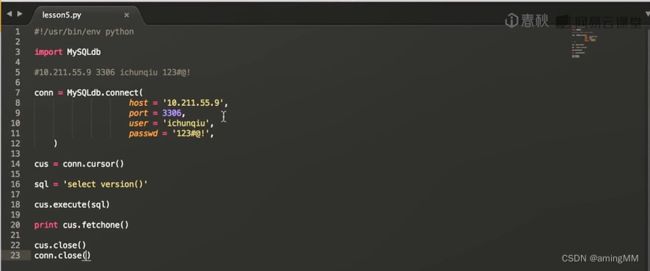





数据库 结构
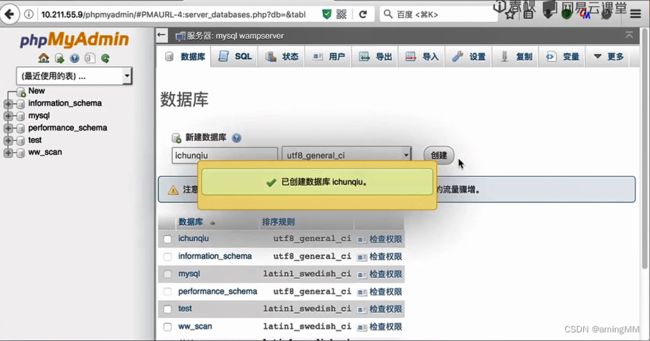





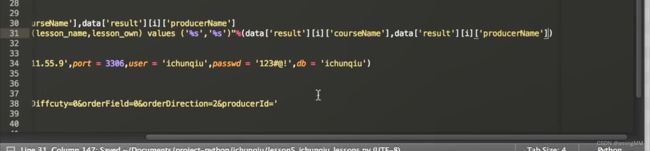








第三章 Python爬虫技术实现
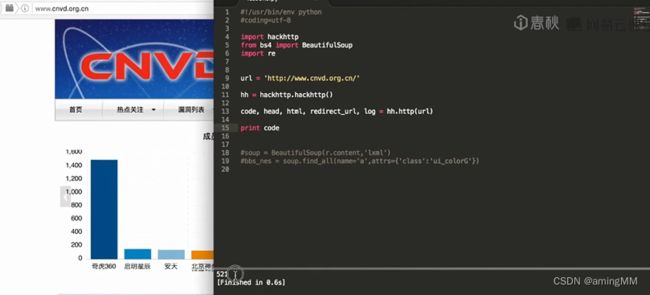
第一节 Python爬虫BeautifulSoup模块的介绍

解析html文件
bugscan 四叶草 hackhttp







BeautifulSoup










re 更 精确 但是 有 None
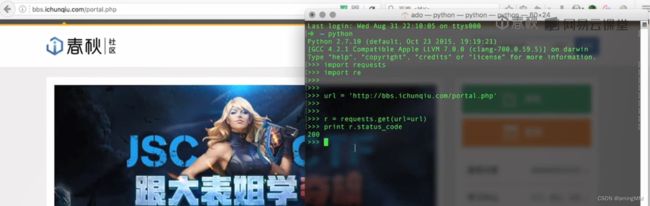
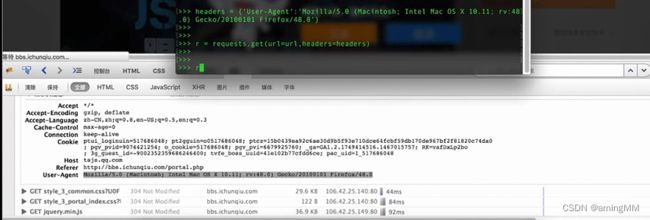
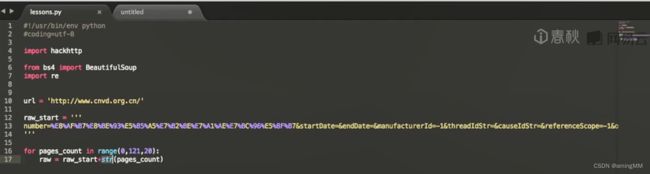
第二节 Python爬虫hackhttp模块的介绍






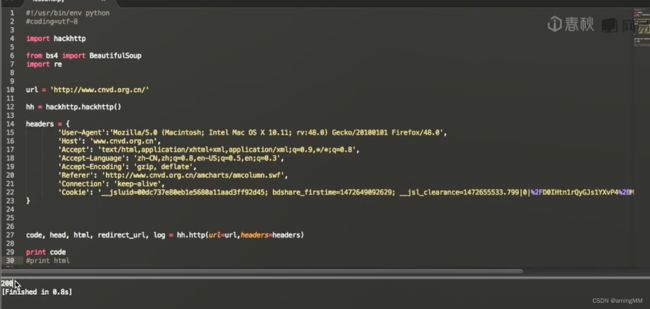

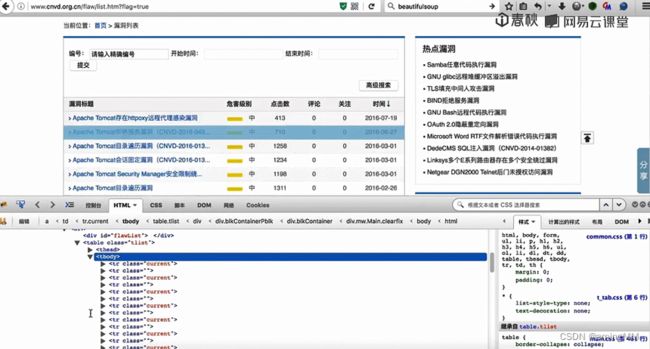
第三节 结合BeautifulSoup和hackhttp的爬虫实例
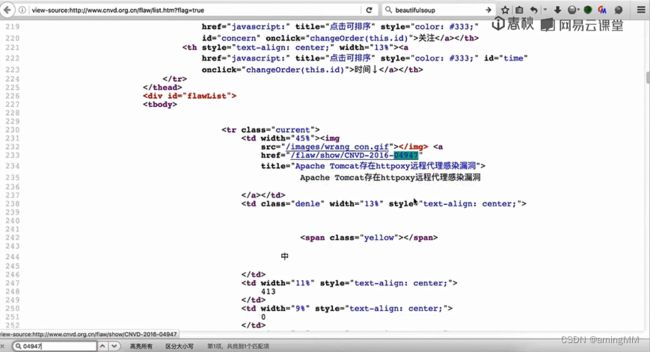


分别抓包 post 内容分析
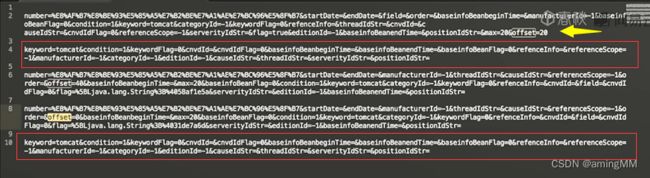

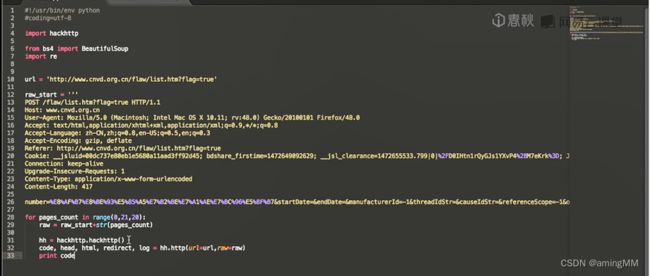

re 模块 字符串匹配
soup 基于 html 标签 来 匹配




第四节 爬虫多线程

- 多线程
- 正则表达式







threading 构造类 稳定
初始化 导入生产者模块

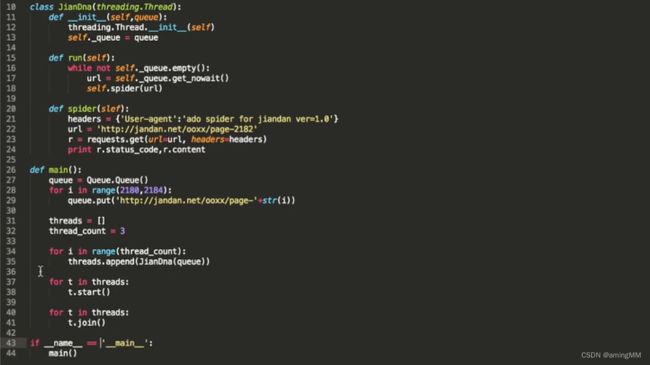

Python安全工具编程进阶
Python信息收集工具编写
i春秋\08 Python安全编程\第四章
第一节 高精度字典生成
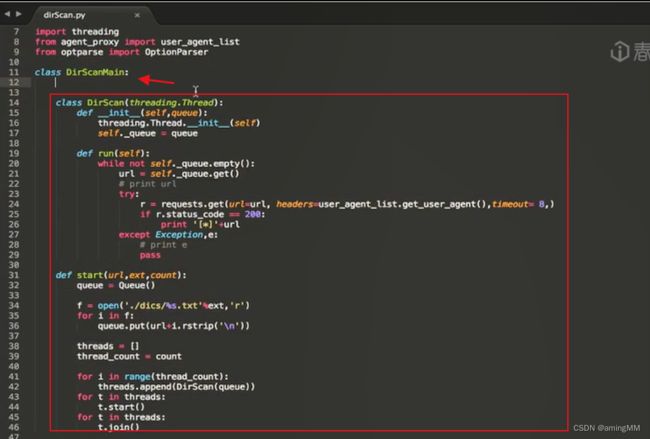
第二节 WEB目录扫描程序



后台爆破
phpinfo() php环境变量
网站敏感信息泄露
上传地址

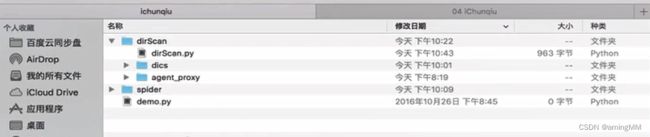

多线程类
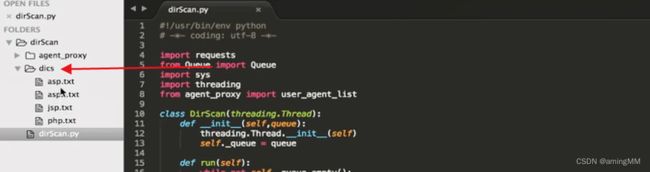
put到queue
用多线程进行调用 等待结果

取出执行

随机 UA头
加上代理





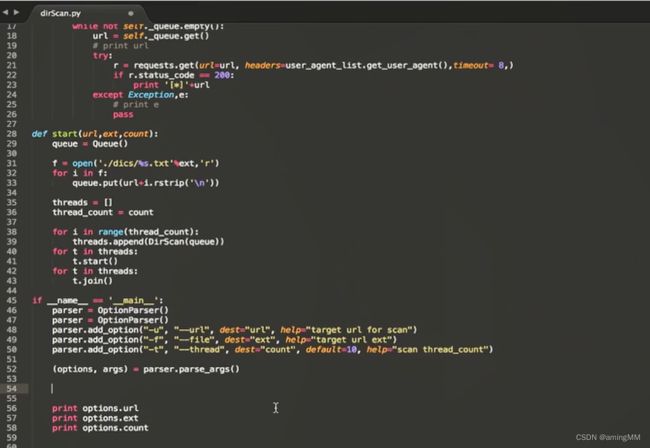













第三节 C段WEB服务扫描







基础
六种数据类型
1、数组List(列表)
pop() 函数用于列表(list),表示移除列表中的一个元素(默认最后一个元素)
# List
l = [1, 2, 3, 4, 5] # 列表
print (l [0]) # 索引
print (l [1:3]) # 切片
for x in l: # 遍历
print (x)
l.append (6) # 添加元素
l.remove (2) # 删除元素
l.sort () # 排序
List(列表):由逗号分隔的一组有序的可变的值,用方括号括起来,可以进行切片、索引、遍历、添加、删除、排序等操作。
2、Tuple(元组)
Tuple(元组):由逗号分隔的一组有序的
不可变的值,用圆括号括起来,可以进行切片、索引、遍历等操作。
# Tuple
t = (1, 2, 3, 4, 5) # 元组
print (t [0]) # 索引
print (t [1:3]) # 切片
for x in t: # 遍历
print (x)
3、dict Dictionary(字典)
# Dictionary
d = {"name": "Bing", "age": 10, "gender": "male"} # 字典
print (d ["name"]) # 访问键对应的值
d ["age"] = 11 # 添加或修改键值对
del d ["gender"] # 删除键值对
for k,v in d.items (): # 遍历键值对
print (k,v)
修改
dicts[new_name] = dicts.pop(old_name)
例子:
dicts = {
"xx": 1,
"zz": 2,
"yy": 3
}
dicts['yy'] = dicts.pop('xx')
print(dicts)
结果:
{'zz': 2, 'yy': 1}
新增
dicts[new_name] = value
例子:
dicts = {
"xx": 1,
"zz": 2,
"yy": 3
}
dicts["aa"] = 4
print(dicts)
结果:
{'xx': 1, 'zz': 2, 'yy': 3, 'aa': 4}
删除
del dicts[del_name]
例子:
dicts = {
"xx": 1,
"zz": 2,
"yy": 3
}
del dicts['xx']
print(dicts)
结果:
{'zz': 2, 'yy': 3}
使用 for 循环,直接遍历字典的键,并使用 dict [key] 获取它们对应的值。例如:
dict = {"id": 1, "second": "abcd"}
for key in dict:
print(key, dict[key])
使用 dict.items () 方法,返回一个包含字典中所有键值对的可迭代对象,并使用 for 循环遍历它们。每个键值对是一个元组,可以使用解包赋值的方式获取键和值。例如:
dict = {"id": 1, "second": "abcd"}
for key, value in dict.items():
print(key, value)
使用 dict.keys () 方法,返回一个包含字典中所有键的可迭代对象,并使用 for 循环遍历它们。这与直接遍历字典的键类似,但可以在需要时转换为列表或集合等其他数据结构。例如:
dict = {"id": 1, "second": "abcd"}
for key in dict.keys():
print(key, dict[key])
使用 dict.values () 方法,返回一个包含字典中所有值的可迭代对象,并使用 for 循环遍历它们。这在只需要字典的值而不需要键时很有用。例如:
dict = {"id": 1, "second": "abcd"}
for value in dict.values():
print(value)
Dictionary(字典):由键值对组成的一组无序的可变的值,用花括号括起来,可以进行访问、添加、删除、遍历等操作。
4、Number(数字)
Number(数字):包括整数、浮点数、复数等,可以进行算术运算和逻辑运算。
3、int
# Number
a = 10 # 整数
b = 3.14 # 浮点数
c = 1 + 2j # 复数
print (a + b) # 算术运算
print (a > b) # 逻辑运算
5、Set(集合)
Set(集合):由逗号分隔的一组无序的不重复的值,用花括号括起来,可以进行交集、并集、差集、对称差等操作。
# Set
s1 = {1, 2, 3, 4, 5} # 集合
s2 = {3, 4, 5, 6, 7} # 集合
print (s1 & s2) # 交集
print (s1 | s2) # 并集
print (s1 - s2) # 差集
print (s1 ^ s2) # 对称差
6、String(字符串
String(字符串):由单引号或双引号括起来的一系列字符,可以进行切片、索引、拼接、格式化等操作。
# String
s = "Hello, world!" # 字符串
print (s [0]) # 索引
print (s [1:5]) # 切片
print (s + " Python") # 拼接
print ("My name is %s" % "Bing") # 格式化
异常
用于抛出一个异常,即一个运行时错误。message是一个字符串,用于描述异常的原因。例如:
raise Exception("Invalid input")
这会抛出一个异常,显示“Invalid input”作为错误信息。
assert
Python中的assert是一个用于调试和测试代码的关键字。assert可以让你检查代码中的某个条件是否为真,如果不为真,就会抛出一个AssertionError异常。你可以在异常中写一个消息来说明条件为假的原因,例如:
x = "hello"
# 如果条件为真,什么都不会发生
assert x == "hello"
# 如果条件为假,会抛出AssertionError
assert x == "goodbye", "x应该是'hello'"
assert的语法如下:
assert expression[, assertion_message]
其中,expression可以是任何有效的Python表达式或对象,它会被测试其真值。如果expression为假,就会抛出AssertionError。assertion_message参数是可选的,但是建议提供,以便更好地说明错误原因。
assert可以用来在代码中写一些假设或者检查,以确保代码的正确性和一致性。你可以用assert来文档化、调试和测试你的代码,在开发过程中发现和修复错误。一旦你用assert调试和测试好了你的代码,你就可以关闭它们,以提高代码在生产环境中的性能。
装饰器
Python 内置了3种函数装饰器,分别是 @staticmethod、@classmethod 和 @property
property函数字如其名,其在装饰器的主要应用在于,我们要实现
保护类的封装特性
让开发者可以使用“对象.属性”的方式操作操作类属性
global
python中global是一个关键字,
用来声明一个或多个变量为全局变量。
全局变量是指在模块(module)级别的变量,
可以被不同的函数或对象引用和修改。
如果在函数内部不使用global声明全局变量,
而直接对其进行赋值或修改,
会报错或者创建一个新的局部变量。
如果只是读取全局变量的值,不需要使用global声明。
运算符
位运算符
page_url_set |= set(urls)这个语句是使用了Python中的位运算符|=,它表示按位或赋值,即将page_url_set和set(urls)进行按位或运算,然后将结果赋值给page_url_set。按位或运算符|在Python中也可以用于集合类型,表示集合的并集,即将两个集合中的所有元素合并在一起,去除重复的元素。因此,这个语句的意思是将page_url_set和set(urls)两个集合合并为一个集合,并赋值给page_url_set。例如:
# 定义一个集合
page_url_set = {"https://www.example.com", "https://www.foo.com"}
# 定义一个列表
urls = ["https://www.bar.com", "https://www.example.com"]
# 使用|=运算符
page_url_set |= set(urls)
# 打印结果
print(page_url_set) # 输出 {'https://www.example.com', 'https://www.foo.com', 'https://www.bar.com'}
在上面的例子中,我们将page_url_set和set(urls)两个集合进行了并集运算,并将结果赋值给了page_url_set。可以看到,结果集合中包含了两个集合中的所有元素,但是去除了重复的"https://www.example.com"元素。
累加 累积
code += _ 是一个赋值语句,它将变量 code 的值增加 _ 的值。这与 code = code + _ 是等价的。这种写法通常用于累加或累积变量的值。
标准库模块
内置库/函数
setuptools
setuptools是PEAK的一个副项目,
它 是一组Python的 distutilsde工具的增强工具
(适用于 Python 2.3.5 以上的版本,64 位平台则适用于 Python 2.4 以上的版本),
其功能可以使程序员更方便的创建和发布 Python 包,特别是那些对其它包具有依赖性的状况
模块
GUI
anaconda
爬虫
打包
python-pip命令
pip -V 显示pip版本
pip list 列出已经安装的包
pip show numpy 显示特定安装包的信息
pip check tensorflow 检查依赖包是否已经安装
pip hash numpy-1.19.1-cp36-cp36m-win_amd64.whl 计算安装包的hash值
pip install numpy 安装numpy包
pip install --upgrade tensorflow 或 pip install -U tensorflow安装最新版本tensorflow(升级)
pip install numpy==1.13.3 安装指定版本包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow
指定从清华服务器下载tensorflow 安装包。等效于后面的配置文件中index-url设置。
pip install -r requirements.txt 根据包需求文件批量安装,常用于复现环境
【requirements.txt内容格式为】
APScheduler==2.1.2
Django==1.5.4
MySQL-Connector-Python==2.0.1
MySQL-python==1.2.3
PIL==1.1.7
South>=1.0.2
django-grappelli==2.6.3
django-pagination==1.0.7
pip install numpy-1.19.1-cp36-cp36m-win_amd64.whl 安装当前目录中的wheel安装包文件
卸载安装包
pip uninstall numpy 卸载(加-y参数,自动完成,不再询问y/n)
pip uninstall -r requirements.txt -y 自动卸载requirements.txt中所有包(批量卸载)
下载安装包文件
pip download numpy
下载numpy包,执行后,在当前目录中下载numpy-1.19.1-cp36-cp36m-win_amd64.whl
取得当前环境包列表文件
pip freeze >requirements.txt
cache缓存命令(pip安装时,会将下载的文件进行缓存,以后再次安装此包时,不必再下载。一般用于当前用户环境时。不是虚拟环境。虚拟环境会参考此缓存。)
pip cache dir
pip cache list 列出当前缓存的安装包
pip cache info 显示缓存占用磁盘大小信息
pip cache remove gym* 删除缓存中的gym开头的包
pip cache purge 删全部缓存中包
pip wheel 安装包制作命令,以后单独整理安装包制作时进一步说明
pip wheel -r requirements.txt --wheel-dir=./wheelhouse
在当前目录下的wheelhouse目录,下载requirements.txt中所有包

flask框架
functools包 wraps
增强函数功能 高阶函数(该高阶函数的定义为作用于或返回其它函数的函数)
import parsel
scrapy内置的选择器包含re、css、xpath选择器,依赖lxml
import requests
import re
import requests
import json
from openpyxl import Workbook
import time
import hashlib
import os
import datetime
CentOS 7.2 默认安装了python2.7.5 因为一些命令要用它比如yum 它使用的是python2.7.5。
使用 python -V 命令查看一下是否安装Python
然后使用命令 which python 查看一下Python可执行文件的位置

可见执行文件在/usr/bin/ 目录下,切换到该目录下执行
ll python* 命令查看
python 指向的是python2.7
要安装python3版本,所以python要指向python3才行,目前还没有安装python3,
先备份,备份之前先安装相关包,用于下载编译python3
yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make
不能忽略相关包,我之前就没有安装readline-devel导致执行python模式无法使用键盘的上下左右键;
然后备份
mv python python.bak
2.开始编译安装python3
去官网下载编译安装包或者直接执行以下命令下载
wget https://www.python.org/ftp/python/3.6.2/Python-3.6.2.tar.xz
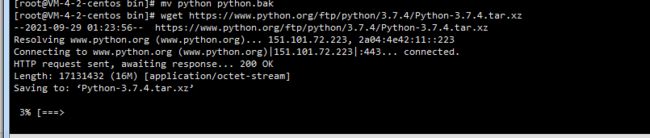
解压
tar -xvJf Python-3.6.2.tar.xz

切换进入
cd Python-3.6.2
编译安装
./configure prefix=/usr/local/python3

make && make install


安装完毕,/usr/local/目录下就会有python3了

因此我们可以添加软链到执行目录下/usr/bin
ln -s /usr/local/python3/bin/python3 /usr/bin/python
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3

可以看到软链创建完成
测试安装成功了没,执行
python -V 看看输出的是不是python3的版本

执行python2 -V 看到的就是python2的版本

因为执行yum需要python2版本,所以我们还要修改yum的配置,执行:
vi /usr/bin/yum
把#! /usr/bin/python修改为#! /usr/bin/python2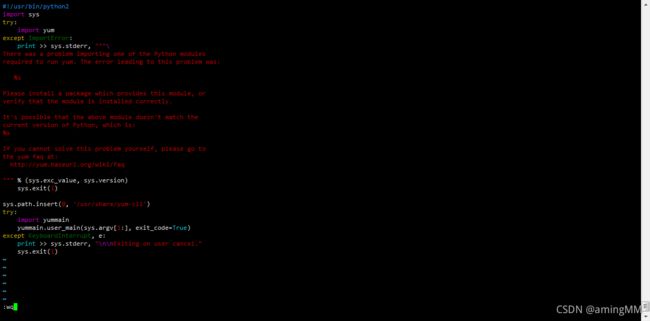
同理 vi /usr/libexec/urlgrabber-ext-down 文件里面的#! /usr/bin/python 也要修改为#! /usr/bin/python2

这样python3版本就安装完成;同时python2也存在
python -V 版本3
python2 -V 版本2
print() 输出颜色
标准格式
print("\033[显示方式;前景颜色;背景颜色m…\033[0m")
显示方式
意义 显示方式
默认 0
高亮显示 1
下划线 4
闪烁 5
反白显示 7
不可见 8
前景颜色和背景颜色
颜色 前景色 背景色
黑色 30 40
红色 31 41
绿色 32 42
黄色 33 43
蓝色 34 44
紫红色 35 45
青蓝色 36 46
白色 37 47
没有设置的话就是默认
print("\033[0;31;40m我是小杨我就这样\033[0m")
print("\033[0;32;40m我是小杨我就这样\033[0m")
print("\033[0;33;40m我是小杨我就这样\033[0m")
print("\033[0;34;40m我是小杨我就这样\033[0m")
print("\033[0;35;40m我是小杨我就这样\033[0m")
print("\033[0;36;40m我是小杨我就这样\033[0m")
print("\033[0;37;40m我是小杨我就这样\033[0m")
print("\033[0;37;41m我是小杨我就这样\033[0m")
print("\033[0;37;42m我是小杨我就这样\033[0m")
print("\033[0;37;43m我是小杨我就这样\033[0m")
print("\033[0;37;44m我是小杨我就这样\033[0m")
print("\033[0;37;45m我是小杨我就这样\033[0m")
print("\033[0;37;46m我是小杨我就这样\033[0m")
print("\033[0;30;47m我是小杨我就这样\033[0m")
项目 重新打开
![]()



删掉 venv


正则表达式(regular expression)
描述了一种字符串匹配的模式(pattern),
可以用来检查一个串是否含有某种子串、
将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
runoo+b,可以匹配 runoob、runooob、runoooooob 等
+ 号代表前面的字符必须至少出现一次(1次或多次)。
runoo*b,可以匹配 runob、runoob、runoooooob 等
* 号代表前面的字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次)。
colou?r 可以匹配 color 或者 colour
? 问号代表前面的字符最多只可以出现一次(0次或1次)。
re.compile 函数
编译正则表达式模式,返回一个对象。
可以把常用的正则表达式编译成正则表达式对象,方便后续调用及提高效率。
re.compile(pattern, flags=0)
pattern 指定编译时的表达式字符串
flags 编译标志位,用来修改正则表达式的匹配方式。支持 re.L|re.M 同时匹配
flags 标志位参数:
re.I(re.IGNORECASE) :使匹配对大小写不敏感
re.L(re.LOCAL) :做本地化识别(locale-aware)匹配
re.M(re.MULTILINE) :多行匹配,影响 ^ 和 $
re.S(re.DOTALL) :使 . 匹配包括换行在内的所有字符
re.U(re.UNICODE):根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.
re.X(re.VERBOSE):该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。
特殊的字符序列
作用: 检查一个字符串是否与 某种模式 匹配
python x>1.5
re 模块 Perl 风格-正则表达式模式
方法功能函数------一个模式字符串做为它们的第一个参数
compile 函数:编译正则表达式
根据 一个模式字符串 和 可选的标志参数
—> 生成一个正则表达式( Pattern )对象
(该对象拥有一系列方法 用于正则表达式匹配和替换)
供 match() 和 search() 这两个函数使用
re.match(pattern, string, flags=0) 函数
尝试从字符串的起始位置匹配一个模式,
- 匹配成功----------返回一个匹配的对象
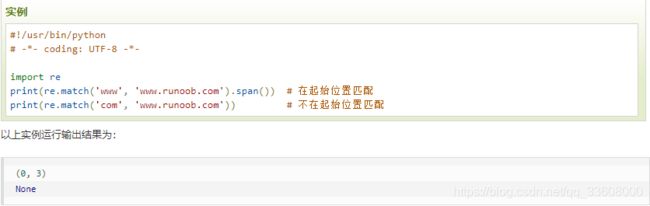
如果不是起始位置匹配成功的话,
- match()就返回none。

-
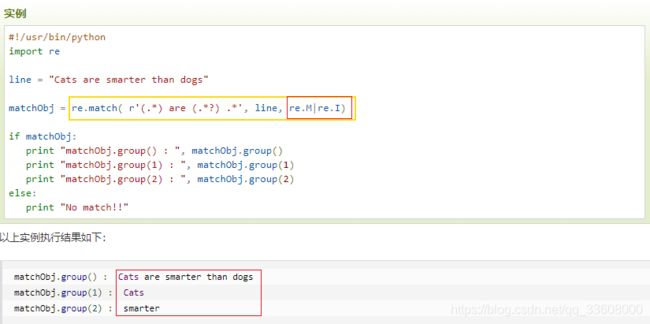
正则表达式修饰符 - 可选标志 -------控制匹配的模式
修饰符被指定为一个可选的标志。
多个标志可以通过按位 OR(|) 它们来指定。
如:::::::re.I | re.M 被设置成 I 和 M 标志:

使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。

. - 除换行符以外的所有字符。
^ - 字符串开头。
$ - 字符串结尾。
\d,\w,\s - 匹配数字、字符、空格。
\D,\W,\S - 匹配非数字、非字符、非空格。
[abc] - 匹配 a、b 或 c 中的一个字母。
[a-z] - 匹配 a 到 z 中的一个字母。
[^abc] - 匹配除了 a、b 或 c 中的其他字母。
aa|bb - 匹配 aa 或 bb。
? - 0 次或 1 次匹配。
* - 匹配 0 次或多次。
+ - 匹配 1 次或多次。
{n} - 匹配 n次。
{n,} - 匹配 n次以上。
{m,n} - 最少 m 次,最多 n 次匹配。
(expr) - 捕获 expr 子模式,以 \1 使用它。
(?:expr) - 忽略捕获的子模式。
(?=expr) - 正向预查模式 expr。
(?!expr) - 负向预查模式 expr。
一、校验数字的表达式
数字:^[0-9]*$
n位的数字:^\d{n}$
至少n位的数字:^\d{n,}$
m-n位的数字:^\d{m,n}$
零和非零开头的数字:^(0|[1-9][0-9]*)$
非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(\.[0-9]{1,2})?$
带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})$
正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
有两位小数的正实数:^[0-9]+(\.[0-9]{2})?$
有1~3位小数的正实数:^[0-9]+(\.[0-9]{1,3})?$
非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
非零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
非负整数:^\d+$ 或 ^[1-9]\d*|0$
非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
校验字符的表达式
汉字:^[\u4e00-\u9fa5]{0,}$
英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
长度为3-20的所有字符:^.{3,20}$
由26个英文字母组成的字符串:^[A-Za-z]+$
由26个大写英文字母组成的字符串:^[A-Z]+$
由26个小写英文字母组成的字符串:^[a-z]+$
由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+
禁止输入含有~的字符:[^~]+
三、特殊需求表达式
Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.?
InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
手机号码:^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\d{8}$
电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
电话号码正则表达式(支持手机号码,3-4位区号,7-8位直播号码,1-4位分机号): ((\d{11})|^((\d{7,8})|(\d{4}|\d{3})-(\d{7,8})|(\d{4}|\d{3})-(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1})|(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1}))$)
身份证号(15位、18位数字),最后一位是校验位,可能为数字或字符X:(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$)
帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在 8-10 之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])[a-zA-Z0-9]{8,10}$
强密码(必须包含大小写字母和数字的组合,可以使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
日期格式:^\d{4}-\d{1,2}-\d{1,2}
一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
钱的输入格式:
有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧。下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
中文字符的正则表达式:[\u4e00-\u9fa5]
双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
空白行的正则表达式:\n\s*\r (可以用来删除空白行)
HTML标记的正则表达式:<(\S*?)[^>]*>.*?|<.*? /> ( 首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
IPv4地址:((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}
reportlab
reportlab是Python的一个标准库,
可以画图、画表格、编辑文字,最后可以输出PDF格式。
它的逻辑和编辑一个word文档或者PPT很像。
有两种方法:
1)建立一个空白文档,然后在上面写文字、画图等;
2)建立一个空白list,以填充表格的形式插入各种文本框、图片等,最后生成PDF文档。
pip install reportlab -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
字典
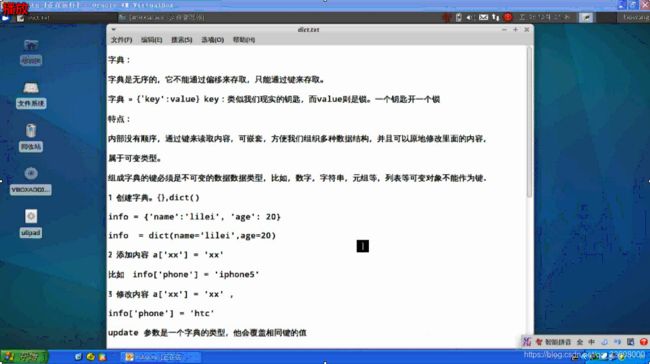









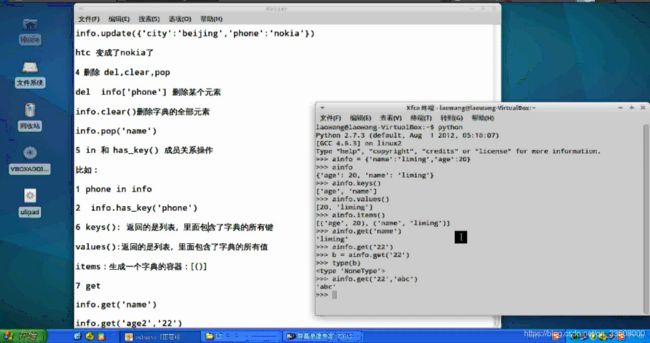
字典:
字典是无序的,它不能通过偏移来存取,只能通过键来存取。
字典 = {‘key’:value} key:类似我们现实的钥匙,而value则是锁。一个钥匙开一个锁
特点:
内部没有顺序,通过键来读取内容,可嵌套,方便我们组织多种数据结构,并且可以原地修改里面的内容,
属于可变类型。
组成字典的键必须是不可变的数据类型,比如,数字,字符串,元组等,列表等可变对象不能作为键.
1 创建字典。{},dict()
info = {‘name’:‘lilei’, ‘age’: 20}
info = dict(name=‘lilei’,age=20)
2 添加内容 a[‘xx’] = ‘xx’
比如 info[‘phone’] = ‘iphone5’
3 修改内容 a[‘xx’] = ‘xx’ ,
info[‘phone’] = ‘htc’
update 参数是一个字典的类型,他会覆盖相同键的值
info.update({‘city’:‘beijing’,‘phone’:‘nokia’})
htc 变成了nokia了
4 删除 del,clear,pop
del info[‘phone’] 删除某个元素
info.clear()删除字典的全部元素
info.pop(‘name’)
5 in 和 has_key() 成员关系操作
比如:
1 phone in info
2 info.has_key(‘phone’)
6 keys(): 返回的是列表,里面包含了字典的所有键
values():返回的是列表,里面包含了字典的所有值
items:生成一个字典的容器:[()]
7 get:从字典中获得一个值
info.get(‘name’)
info.get(‘age2’,‘22’)

变量












1.Python的自述
https://www.bilibili.com/video/BV1wD4y1o7AS?from=search&seid=7925680372439541422






2018 计算机 二级 加 Python
浙江省 2017 高考


















2020 中小学 信息素质 体测
智能化课程 设置
小学三年级

















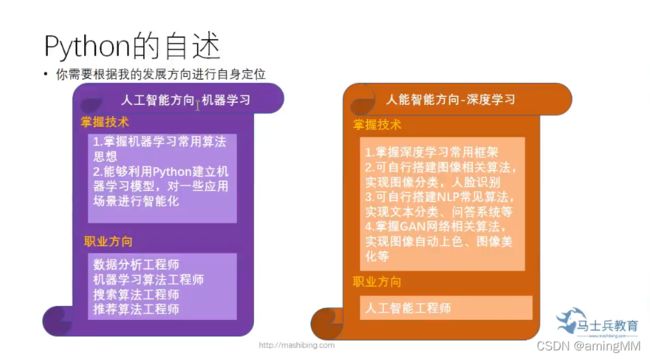
2.Python简介


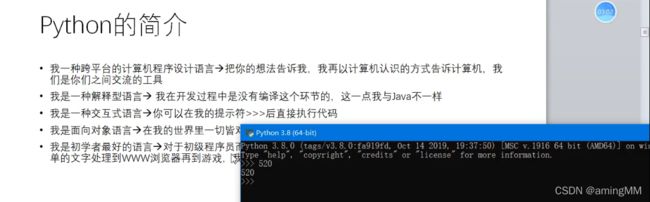
3.Python开发环境的安装
















格式化
pythn print格式化输出
格式符
格式符为真实值预留位置,并控制显示的格式。格式符可以包含有一个类型码,用以控制显示的类型,如下:
%s 字符串 (采用str()的显示)
%r 字符串 (采用repr()的显示)
%c 单个字符
%b 二进制整数
%d 十进制整数
%i 十进制整数
%o 八进制整数
%x 十六进制整数
%e 指数 (基底写为e)
%E 指数 (基底写为E)
%f 浮点数
%F 浮点数,与上相同
%g 指数(e)或浮点数 (根据显示长度)
%G 指数(E)或浮点数 (根据显示长度)
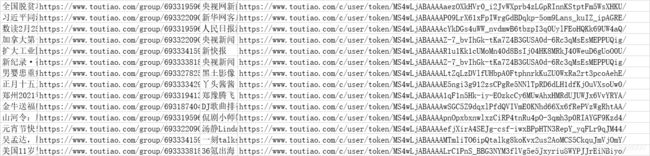
Python爬虫——新闻热点爬取
显示更多
可以看到相关的数据接口,里面有新闻标题以及新闻详情的url地址
如何提取url地址
1、转成json,键值对取值;
2、用正则表达式匹配url地址;
根据接口数据链接中的pager 变化进行翻页,其对应的就是页码。
详情页可以看到新闻内容都是在 div标签里面 p 标签内,按照正常的解析网站即可获取新闻内容。
保存方式
txt文本形式
PDF形式
整体爬取思路总结
在栏目列表页中,点击更多新闻内容,获取接口数据url
接口数据url中返回的数据内容中匹配新闻详情页url
使用常规解析网站操作(re、css、xpath)提取新闻内容
保存数据
import parsel
import requests
import re
#### 获取网页源代码
def get_html(html_url):
"""
获取网页源代码 response
:param html_url: 网页url地址
:return: 网页源代码
"""
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9", }
response = requests.get(url=html_url, headers=headers)
return response
#### 获取每篇新闻url地址
def get_page_url(html_data):
"""
获取每篇新闻url地址
:param html_data: response.text
:return: 每篇新闻的url地址
"""
page_url_list = re.findall('"url":"(.*?)"', html_data)
return page_url_list
#### 文件保存命名不能含有特殊字符,需要对新闻标题进行处理
def file_name(name):
"""
文件命名不能携带 特殊字符
:param name: 新闻标题
:return: 无特殊字符的标题
"""
replace = re.compile(r'[\\\/\:\*\?\"\<\>\|]')
new_name = re.sub(replace, '_', name)
return new_name
####保存数据
def download(content, title):
"""
with open 保存新闻内容 txt
:param content: 新闻内容
:param title: 新闻标题
:return:
"""
path = '新闻\\' + title + '.txt'
with open(path, mode='a', encoding='utf-8') as f:
f.write(content)
print('正在保存', title)
### 主函数
def main(url):
"""
主函数
:param url: 新闻列表页 url地址
:return:
"""
html_data = get_html(url).text # 获得接口数据response.text
lis = get_page_url(html_data) # 获得新闻url地址列表
for li in lis:
page_data = get_html(li).content.decode('utf-8', 'ignore') # 新闻详情页 response.text
selector = parsel.Selector(page_data)
title = re.findall('(.*?) ', page_data, re.S)[0] # 获取新闻标题
new_title = file_name(title)
new_data = selector.css('#cont_1_1_2 div.left_zw p::text').getall()
content = ''.join(new_data)
download(content, new_title)
if __name__ == '__main__':
for page in range(1, 101):
url_1 = 'https://channel.chinanews.com/cns/cjs/gj.shtml?pager={}&pagenum=9&t=5_58'.format(page)
main(url_1)
在浏览器开发者模式network下很快能找到一个‘?category=new_hot…’字样的文件,查看该文件发现新闻内容的数据全部存储在data里面,且能发现数据类型为json;
只要找到这个文件的requests url即可通过python requests来爬取网页了;
查看请求的url,
发现链接为:https://www.toutiao.com/api/pc/feed/?category=news_hot&utm_source=toutiao&widen=1&max_behot_time=0&max_behot_time_tmp=0&tadrequire=true&as=A1B5AC16548E0FA&cp=5C647E601F9AEE1&_signature=F09fYAAASzBjiSc9oUU9MxdPX3
 其中max_behot_time在获取的json数据中获得 :
其中max_behot_time在获取的json数据中获得 :
在网上找了下大神对as和cp算法的分析,
发现两个参数在js文件:home_4abea46.js中有,具体算法如下代码:
!function(t) {
var e = {};
e.getHoney = function() {
var t = Math.floor((new Date).getTime() / 1e3)
, e = t.toString(16).toUpperCase()
, i = md5(t).toString().toUpperCase();
if (8 != e.length)
return {
as: "479BB4B7254C150",
cp: "7E0AC8874BB0985"
};
for (var n = i.slice(0, 5), a = i.slice(-5), s = "", o = 0; 5 > o; o++)
s += n[o] + e[o];
for (var r = "", c = 0; 5 > c; c++)
r += e[c + 3] + a[c];
return {
as: "A1" + s + e.slice(-3),
cp: e.slice(0, 3) + r + "E1"
}
}
,
t.ascp = e
}(window, document),
python获取as和cp值的代码如下:(代码参考blog:https://www.cnblogs.com/xuchunlin/p/7097391.html)
def get_as_cp(): # 该函数主要是为了获取as和cp参数,程序参考今日头条中的加密js文件:home_4abea46.js
zz = {}
now = round(time.time())
print(now) # 获取当前计算机时间
e = hex(int(now)).upper()[2:] #hex()转换一个整数对象为16进制的字符串表示
print('e:', e)
a = hashlib.md5() #hashlib.md5().hexdigest()创建hash对象并返回16进制结果
print('a:', a)
a.update(str(int(now)).encode('utf-8'))
i = a.hexdigest().upper()
print('i:', i)
if len(e)!=8:
zz = {'as':'479BB4B7254C150',
'cp':'7E0AC8874BB0985'}
return zz
n = i[:5]
a = i[-5:]
r = ''
s = ''
for i in range(5):
s= s+n[i]+e[i]
for j in range(5):
r = r+e[j+3]+a[j]
zz ={
'as':'A1'+s+e[-3:],
'cp':e[0:3]+r+'E1'
}
print('zz:', zz)
return zz
这样完整的链接就构成了,另外提一点就是:
_signature参数去掉也是可以获取到json数据的,
import requests
import json
from openpyxl import Workbook
import time
import hashlib
import os
import datetime
start_url = 'https://www.toutiao.com/api/pc/feed/?category=news_hot&utm_source=toutiao&widen=1&max_behot_time='
url = 'https://www.toutiao.com'
headers={
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
cookies = {'tt_webid':'6649949084894053895'} # 此处cookies可从浏览器中查找,为了避免被头条禁止爬虫
max_behot_time = '0' # 链接参数
title = [] # 存储新闻标题
source_url = [] # 存储新闻的链接
s_url = [] # 存储新闻的完整链接
source = [] # 存储发布新闻的公众号
media_url = {} # 存储公众号的完整链接
def get_as_cp(): # 该函数主要是为了获取as和cp参数,程序参考今日头条中的加密js文件:home_4abea46.js
zz = {}
now = round(time.time())
print(now) # 获取当前计算机时间
e = hex(int(now)).upper()[2:] #hex()转换一个整数对象为16进制的字符串表示
print('e:', e)
a = hashlib.md5() #hashlib.md5().hexdigest()创建hash对象并返回16进制结果
print('a:', a)
a.update(str(int(now)).encode('utf-8'))
i = a.hexdigest().upper()
print('i:', i)
if len(e)!=8:
zz = {'as':'479BB4B7254C150',
'cp':'7E0AC8874BB0985'}
return zz
n = i[:5]
a = i[-5:]
r = ''
s = ''
for i in range(5):
s= s+n[i]+e[i]
for j in range(5):
r = r+e[j+3]+a[j]
zz ={
'as':'A1'+s+e[-3:],
'cp':e[0:3]+r+'E1'
}
print('zz:', zz)
return zz
def getdata(url, headers, cookies): # 解析网页函数
r = requests.get(url, headers=headers, cookies=cookies)
print(url)
data = json.loads(r.text)
return data
def savedata(title, s_url, source, media_url): # 存储数据到文件
# 存储数据到xlxs文件
wb = Workbook()
if not os.path.isdir(os.getcwd()+'/result'): # 判断文件夹是否存在
os.makedirs(os.getcwd()+'/result') # 新建存储文件夹
filename = os.getcwd()+'/result/result-'+datetime.datetime.now().strftime('%Y-%m-%d-%H-%m')+'.xlsx' # 新建存储结果的excel文件
ws = wb.active
ws.title = 'data' # 更改工作表的标题
ws['A1'] = '标题' # 对表格加入标题
ws['B1'] = '新闻链接'
ws['C1'] = '头条号'
ws['D1'] = '头条号链接'
for row in range(2, len(title)+2): # 将数据写入表格
_= ws.cell(column=1, row=row, value=title[row-2])
_= ws.cell(column=2, row=row, value=s_url[row-2])
_= ws.cell(column=3, row=row, value=source[row-2])
_= ws.cell(column=4, row=row, value=media_url[source[row-2]])
wb.save(filename=filename) # 保存文件
def main(max_behot_time, title, source_url, s_url, source, media_url): # 主函数
for i in range(3): # 此处的数字类似于你刷新新闻的次数,正常情况下刷新一次会出现10条新闻,但夜存在少于10条的情况;所以最后的结果并不一定是10的倍数
ascp = get_as_cp() # 获取as和cp参数的函数
demo = getdata(start_url+max_behot_time+'&max_behot_time_tmp='+max_behot_time+'&tadrequire=true&as='+ascp['as']+'&cp='+ascp['cp'], headers, cookies)
print(demo)
# time.sleep(1)
for j in range(len(demo['data'])):
# print(demo['data'][j]['title'])
if demo['data'][j]['title'] not in title:
title.append(demo['data'][j]['title']) # 获取新闻标题
source_url.append(demo['data'][j]['source_url']) # 获取新闻链接
source.append(demo['data'][j]['source']) # 获取发布新闻的公众号
if demo['data'][j]['source'] not in media_url:
media_url[demo['data'][j]['source']] = url+demo['data'][j]['media_url'] # 获取公众号链接
print(max_behot_time)
max_behot_time = str(demo['next']['max_behot_time']) # 获取下一个链接的max_behot_time参数的值
for index in range(len(title)):
print('标题:', title[index])
if 'https' not in source_url[index]:
s_url.append(url+source_url[index])
print('新闻链接:', url+source_url[index])
else:
print('新闻链接:', source_url[index])
s_url.append(source_url[index])
# print('源链接:', url+source_url[index])
print('头条号:', source[index])
print(len(title)) # 获取的新闻数量
if __name__ == '__main__':
main(max_behot_time, title, source_url, s_url, source, media_url)
savedata(title, s_url, source, media_url)
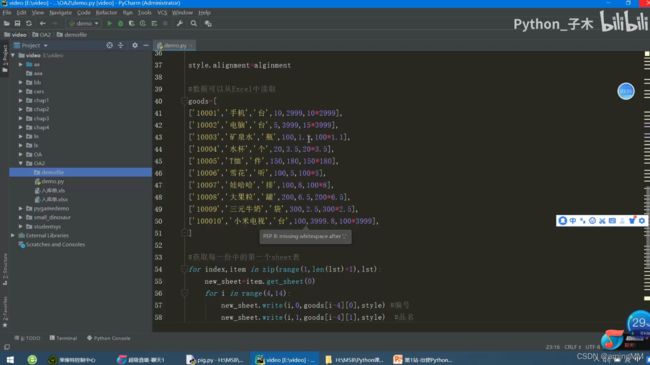
Python爬虫——使用Python爬取代理数据
结构的分析以及网页数据的提取
/2 首页分析及提取/
简单分析下页面,
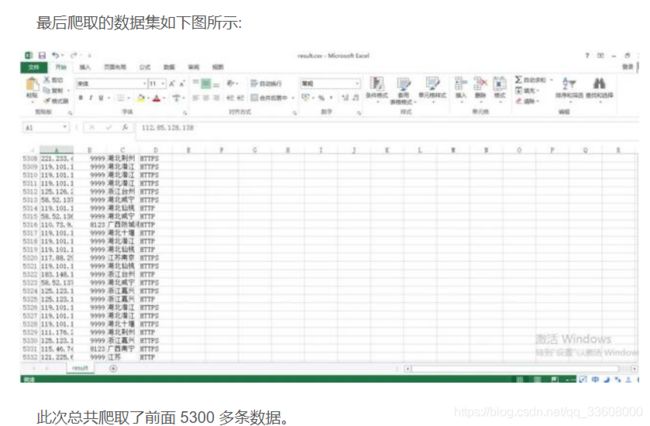
其中后面的 1 是页码的意思,分析后发现每一页有100 多条数据,
然后网站底部总共有 2700+页 的链接,
所以总共ip 代理加起来超过 27 万条数据,
但是后面的数据大部分都是很多年前的数据了,比如 2012 年,
大概就前 5000 多条是最近一个月的,所以决定爬取前面100 页。
通 过网站 url 分析,可以知道这 100 页的 url 为:

规律显而易见,在程序中,我们使用一个 for 循环即可完整这个操作:

其中 scrapy 函数是爬取的主要逻辑,对应的代码为:
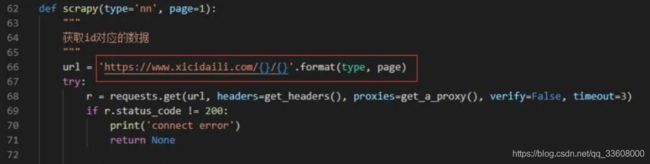
通过这个方式,我们可以得到每一页的数据
/3 网页元素分析及提取/
接下来就是对页面内的元素进行分析,提取其中的代理信息。
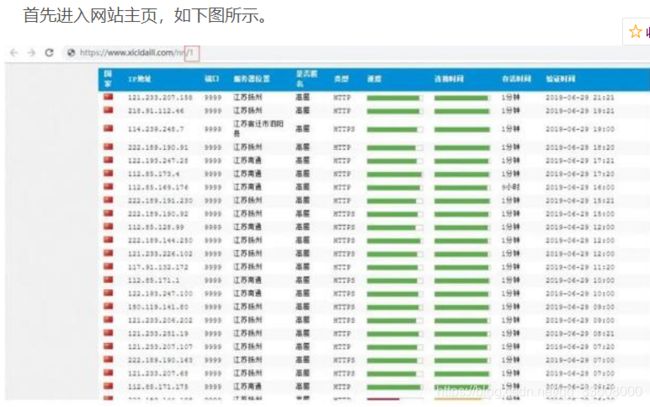
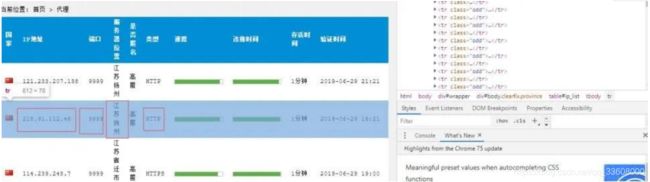
如上图,我们目的是进行代理地域分布分析,
同时,在爬取过程中需要使用爬取的数据进行代 理更新,
所以需要以下几个字段的信息:
Ip 地址、端口、服务器位置、类型
为此,先构建一个类,用于保存这些信息:
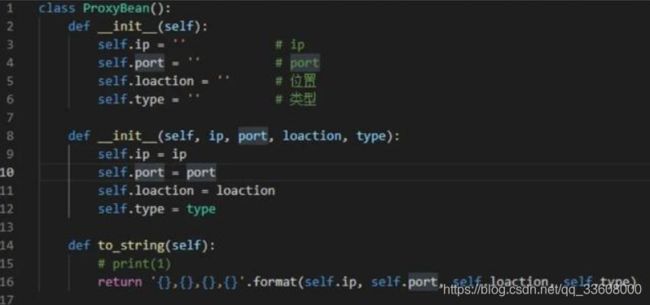
这样,每爬取一条信息,只要实例化一个 ProxyBean 类即可,非常方便。
接下来就是提取元素过程了,
在这个过程我使用了正则表达式和 BeautifulSoup 库进行关键数据提取。
首先,通过分析网页发现,所有的条目实际上都是放在一个标签中。
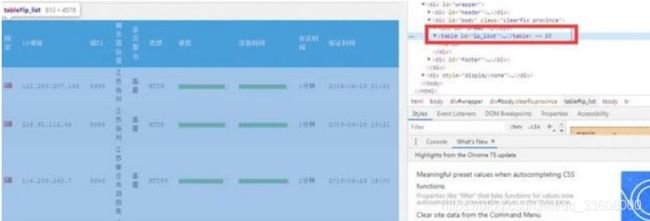
该便签内容如下:
<table id="ip_list">……</table>
我们首先通过正则表达式将该标签的内容提取出来:
正则表达式为:([\S\s]*)
,
表示搜索到
之 间的任意字符组成的数据。
Python 中的实现如下:

其中得到的 data 就是这个标签的内容了。下面进一步分析。
进入到 table 中,发现每一个代理分别站 table 的一列,
但是这些 标签分为两类,一 类包含属性 class="odd", 另一类不包含
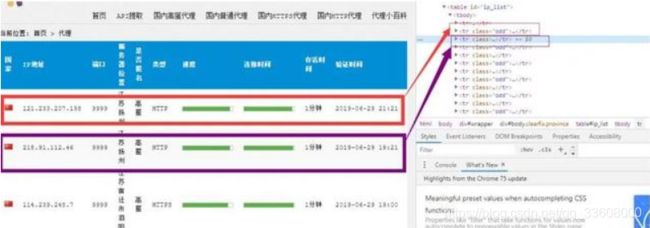
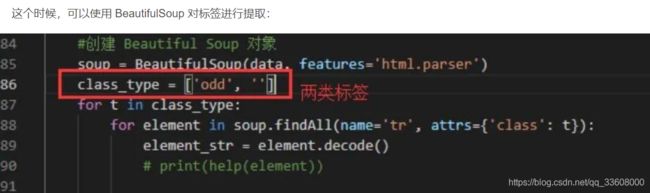
通过这种方式,就能获取到每一个列的列表了。
接下来就是从每个列中获取 ip、端口、位置、类型等信息了。进一步分析页面:
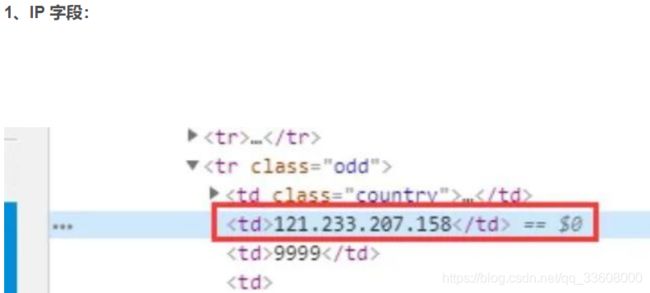
我们使用正则表达式对 IP 进行解析,IP 正则如下:
** (2[0-5]{2}|[0-1]?\d{1,2})(.(2[0-5]{2}|[0-1]?\d{1,2})){3}**

2、 端口字段
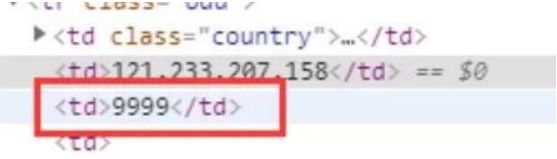
端口由包裹,并且中间全部是数字,故可构造如下正则进行提取:
([0-9]+)

3、 位置字段
位置字段如下:
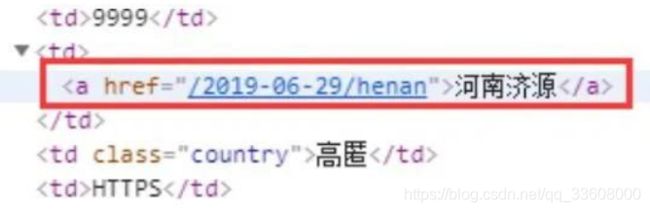
由 便签包裹,构造如下正则即可提取:
<a href="([^>]*)>([^<]*)</a>

4、类型字段
类型字段如下:
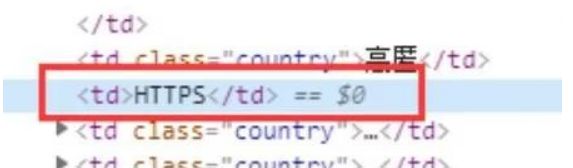
由包裹,中间为字母,构造正则如下:
<td>([A-Za-z]+)</td>

数据全部获取完之后,将其保存到文件中即可:
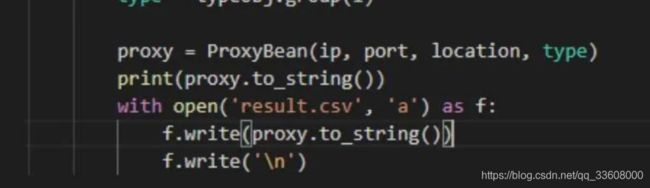
/4 小结/
本次任务主要爬取了代理网站上的代理数据。主要做了以下方面的工作:
学习 requests 库的使用以及爬虫程序的编写;
学习使用反爬虫技术手段,并在实际应用中应用这些技术,如代理池技术;
学习使用正则表达式,并通过正则表达式进行网页元素提取;
学习使用 beautifulsoup 库,并使用该库进行网页元素的提取。
IP代理池
import urllib.request
import urllib
import requests
import re
import time
import random
proxys = []
def show_interface():
choice=input("请选择功能:1.显示可用代理;2.显示可用代理并生成文本;3.退出系统:")
return choice
def get_proxyIP():
ip_title=[]#IP列表
try:
page_num=input('想要爬取多少个代理IP页面(注:每个页面包含100个IP地址,输入数值大于等于2,小于等于705):')
if int(page_num)<2 or int(page_num)>705:
print(">>>>>已经说明清楚了,再乱输的是傻逼 o -_-)=○)°O°) 给你一拳!")
return ip_title
else:
for i in range(1,int(page_num)):
url='http://www.xicidaili.com/nt/'+str(i)
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64)"}
request=urllib.request.Request(url=url,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
pattern=re.compile('(\d.*?|HTTP|HTTPS) ')
ip_page=re.findall(pattern,str(content))
ip_title.extend(ip_page)
time.sleep(random.choice(range(1,3)))
print('代理IP地址 ','\t','端口','\t','类型','\t\t\t','存活时间','\t\t','验证时间')
for i in range(0,len(ip_title),5):
if len(ip_title[i])<14 and len(ip_title[i])>10:
print(ip_title[i],' ','\t',ip_title[i+1],'\t',ip_title[i+2],'\t\t\t',ip_title[i+3],'\t\t',ip_title[i+4])
elif len(ip_title[i])<=10:
print(ip_title[i], ' ', '\t', ip_title[i + 1],'\t', ip_title[i + 2],'\t\t\t', ip_title[i + 3],'\t\t',ip_title[i+4])
else:
print(ip_title[i],' ','\t',ip_title[i+1],'\t',ip_title[i+2],'\t\t\t',ip_title[i+3],'\t\t',ip_title[i+4])
return ip_title
except ValueError:
print(">>>>>已经说明清楚了,再乱输的是傻逼 o -_-)=○)°O°) 给你一拳!")
return ip_title
proxy_ip=open('proxy_ip.txt','w')#新建文档存储有效IP
def effective_IP(ip_title):
socket.setdefaulttimeout(5)#设置全局超时时间
url='https://www.cnblogs.com/sjzh/p/5990152.html'
try:
for i in range(0,len(ip_title),5):
ip={ip_title[i+2]:ip_title[i]+":"+ip_title[i+1]}
proxy_support=urllib.request.ProxyHandler(ip)
opener=urllib.request.build_opener(proxy_support)
opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64)')]
urllib.request.install_opener(opener)
res=urllib.request.urlopen(url).read()
print(ip_title[i]+':'+ip_title[i+1],'is OK')
proxy_ip.write('%s\n'%str('\''+ip_title[i+2]+'\''+':'+'\''+ip_title[i]+':'+ip_title[i+1]+'\''))#写入IP
print('总共爬取了'+str(len(ip_title)/5)+'个有效IP')
except Exception as e:
print(i,e)
if __name__=='__main__':
print(' ')
print(' ')
print(' ◆◆ ◆◆◆◆◆ ◆◆◆◆◆◆◆◆◆◆◆◆◆◆ ')
print(' ◆◆ ◆◆ ◆◆◆ ◆ ◆◆ ◆ ◆ ◆◆◆◆ ◆◆◆◆◆◆◆ ')
print(' ◆◆ ◆ ◆◆ ◆ ◆ ◆ ◆ ◆◆◆ ◆◆◆◆◆◆◆◆ ')
print(' ◆◆◆ ◆ ◆◆◆ ◆ ◆◆◆◆◆◆◆◆◆ ◆◆ ◆◆ ◆◆◆◆ ')
print(' ◆◆◆◆◆◆◆◆◆◆◆◆◆◆ ◆ ◆ ◆ ◆ ◆◆ ◆◆ ◆◆◆ ')
print(' ◆◆◆ ◆◆ ◆ ◆ ◆ ◆ ◆◆ ◆◆ ◆◆◆◆ ')
print(' ◆◆◆ ◆◆ ◆◆◆◆◆◆◆ ◆ ◆◆ ◆◆ ◆◆◆◆◆◆◆ ')
print(' ◆ ◆ ◆◆ ◆ ◆◆◆◆◆◆◆◆◆ ◆◆ ◆◆◆◆◆◆ ')
print(' ◆ ◆◆ ◆ ◆ ◆◆ ◆◆ ')
print(' ◆ ◆◆ ◆ ◆ ◆◆ ◆◆ ')
print(' ◆ ◆◆ ◆ ◆ ◆◆◆◆◆◆◆◆◆ ◆◆ ◆◆ ')
print(' ◆ ◆◆◆ ◆◆ ◆◆◆ ◆ ◆◆◆◆◆ ◆◆◆◆◆◆ ')
print(' ◆ ◆◆ ◆◆ ◆◆◆◆ ◆ ')
print(' ◆ ◆◆◆◆ ◆◆◆◆ ◆◆◆◆◆◆◆◆◆◆◆ ')
print(' ◆ ◆◆ ')
print('')
print('')
choice = show_interface()
while True:
if choice=='1':
get_proxyIP()
i=input(">>>>>还想继续使用该系统?(Y/N):")
if i=='Y' or i=='y':
choice=show_interface()
else:
print('>>>>>欢迎再次使用*_*,我也要睡觉觉了(-_-)ZZZ')
break
if choice=='2':
ip_title=get_proxyIP()
effective_IP(ip_title)
i = input(">>>>>还想继续使用该系统?(Y/N):")
if i == 'Y' or i == 'y':
choice = show_interface()
else:
print('>>>>>欢迎再次使用*_*,我也要睡觉觉了(-_-)ZZZ')
break
if choice=='3':
print('>>>>>欢迎再次使用*_*,我也要睡觉觉了(-_-)ZZZ')
break
import requests
import parsel
import time
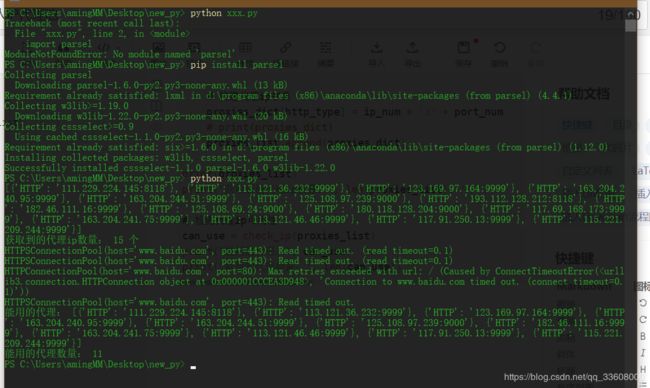
def check_ip(proxies_list):
"""检测ip的方法"""
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}
can_use = []
for proxy in proxies_list:
try:
response = requests.get('http://www.baidu.com', headers=headers, proxies=proxy, timeout=0.1) # 超时报错
if response.status_code == 200:
can_use.append(proxy)
except Exception as error:
print(error)
return can_use
import requests
import parsel
# 1、确定爬取的url路径,headers参数
base_url = 'https://www.kuaidaili.com/free/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}
# 2、发送请求 -- requests 模拟浏览器发送请求,获取响应数据
response = requests.get(base_url, headers=headers)
data = response.text
# print(data)
# 3、解析数据 -- parsel 转化为Selector对象,Selector对象具有xpath的方法,能够对转化的数据进行处理
# 3、1 转换python可交互的数据类型
html_data = parsel.Selector(data)
# 3、2 解析数据
parse_list = html_data.xpath('//table[@class="table table-bordered table-striped"]/tbody/tr') # 返回Selector对象
# print(parse_list)
# 免费 IP {"协议":"IP:port"}
# 循环遍历,二次提取
proxies_list = []
for tr in parse_list:
proxies_dict = {}
http_type = tr.xpath('./td[4]/text()').extract_first()
ip_num = tr.xpath('./td[1]/text()').extract_first()
port_num = tr.xpath('./td[2]/text()').extract_first()
# print(http_type, ip_num, port_num)
# 构建代理ip字典
proxies_dict[http_type] = ip_num + ':' + port_num
# print(proxies_dict)
proxies_list.append(proxies_dict)
print(proxies_list)
print("获取到的代理ip数量:", len(proxies_list), '个')
# 检测代理ip可用性
can_use = check_ip(proxies_list)
print("能用的代理:", can_use)
print("能用的代理数量:", len(can_use))
环境搭建

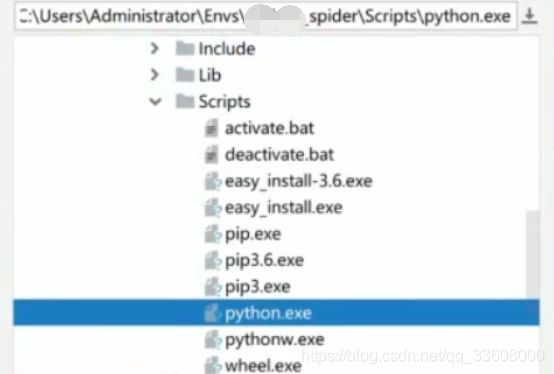
- 打开 安装
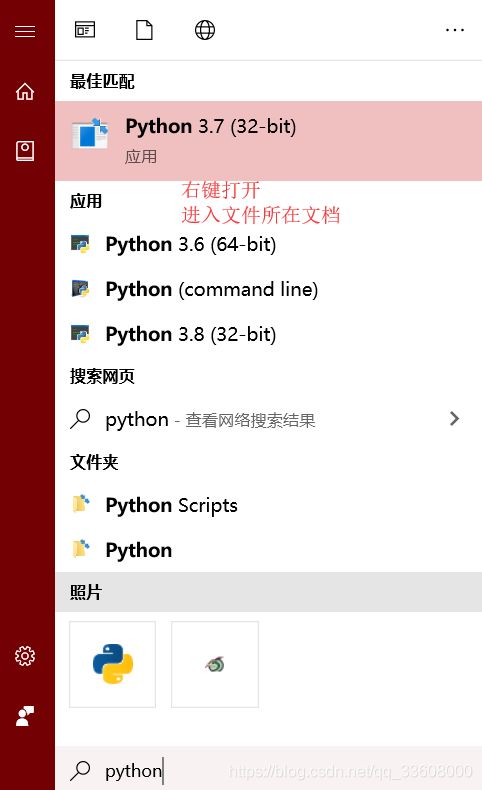
- 找到 可执行文件路径 (便于配置虚拟环境)
linux 环境配置
安装系统依赖包
sudo apt-get install libssl1.0.0 libssl-dev tcl tk sqlite sqlite3 libbz2-1.0 libbz2-dev libexpat1 libexpat1-dev libgdbm3 libgdbm-dev libreadline5 libreadline6 libreadline-dev libreadline6-dev libsqlite0 libsqlite0-dev libsqlite3-0 libsqlite3-dev openssl
上面的依赖包是ubuntu的安装源的包名,不同版本的linux包名可能不一样
下载源码包并解压
wget https://www.python.org/ftp/python/3.6.8/Python-3.6.8.tgz
tar -xzvf Python-3.6.8.tgz -C /tmp
cd /tmp/Python-3.6.8/
把Python3.6安装到 /usr/local 目录
./configure --prefix=/usr/local
make
make altinstall
上面操作执行完成以后就可以执行:
python3.6
就可以进入python的交互环境了
注:
很多linux操作系统会默认安装python和python3,大家可以在终端中输入python或者python3就能查看是否默认安装了py2和py3的版本,如果没有安装可以使用
ln -s /usr/local/bin/python3.6 /usr/bin/python
或者
ln -s /usr/local/bin/python3.6 /usr/bin/python3
生成python或者python3直接运行的python3.6的软连接
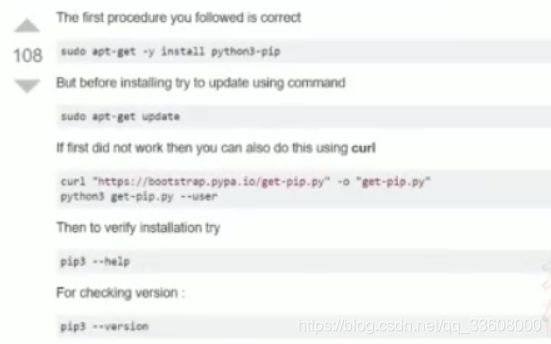
安装pip
python3对应的pip很多linux操作系统没有默认安装, 可以通过
sudo apt-get install python3-pip
安装python3的pip
安装完成以后可以终端中输入: pip3 查看是否安装成功
后续的所有的关于pip中安装的命令,这里都使用 pip3 install XXX
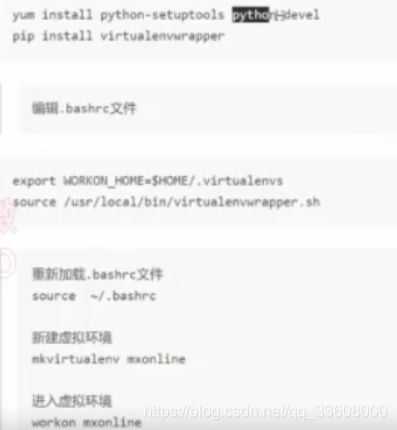
#虚拟环境搭建#
- 不同项目 不同依赖包
- python 版本不一样
- 所以需要 隔离的 py环境
我们使用 virtualenvwrapper (包装的env)
- win 可以直接使用
- linux mac 配置
- sudo apt-get install python3.6
- centos
- 再安装pip
-
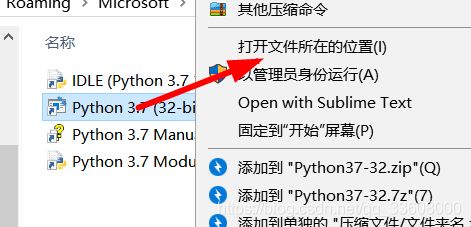
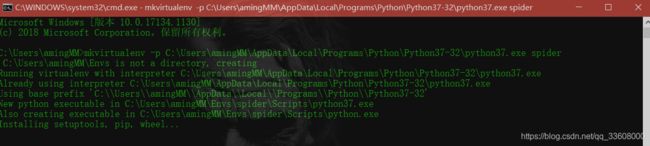
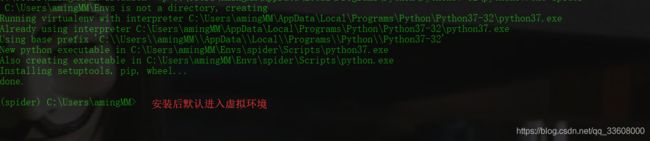
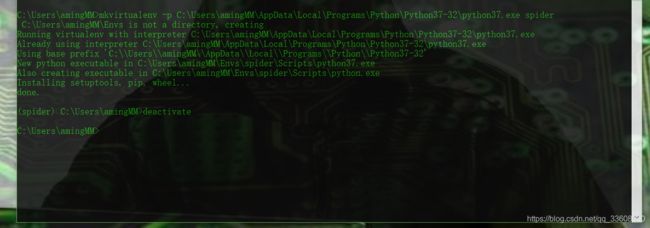
mkvirtualenv spider (基于系统py全局)
-
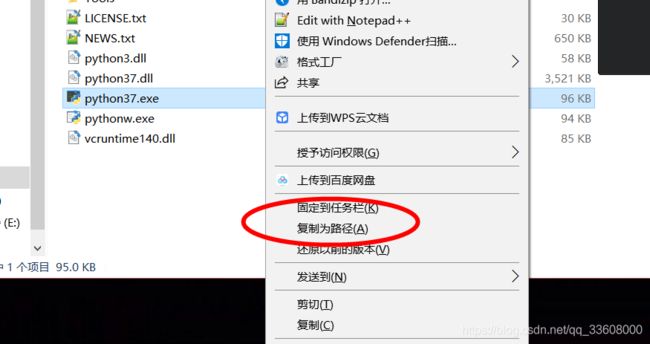
按住shift 按键 右击鼠标

-
可以基于任何 python 来建立生产环境
-
退出环境
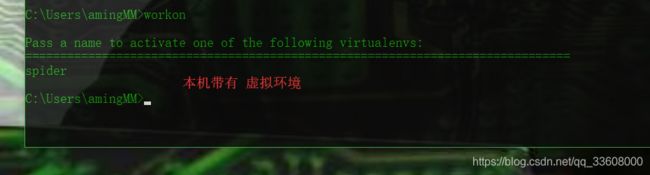
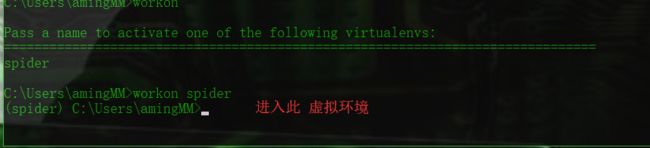
-
方便 就可以在 那个Envs 把 对应的 目录删除即可
-
如果在pycharm 里可用这么 看虚拟环境 setting 里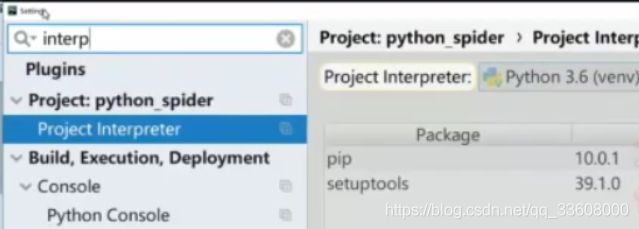
-
pycharm自带虚拟环境
-
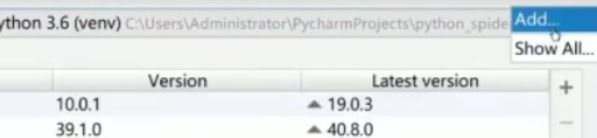
更换虚拟环境

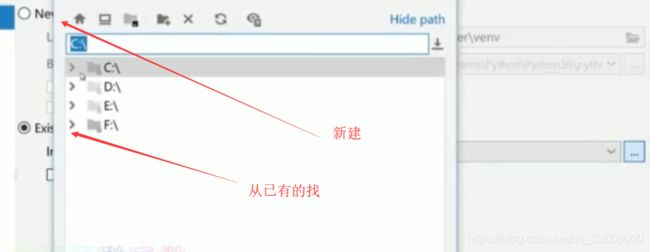

-
linux 自己设置

-
我用的 是IDEA 插件
-
win+ e
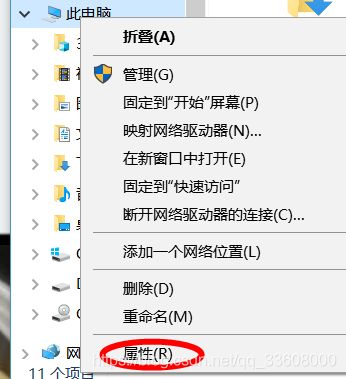
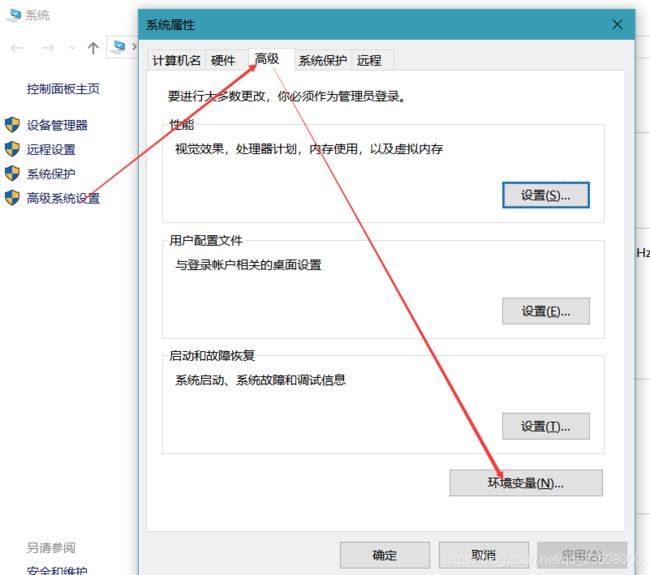
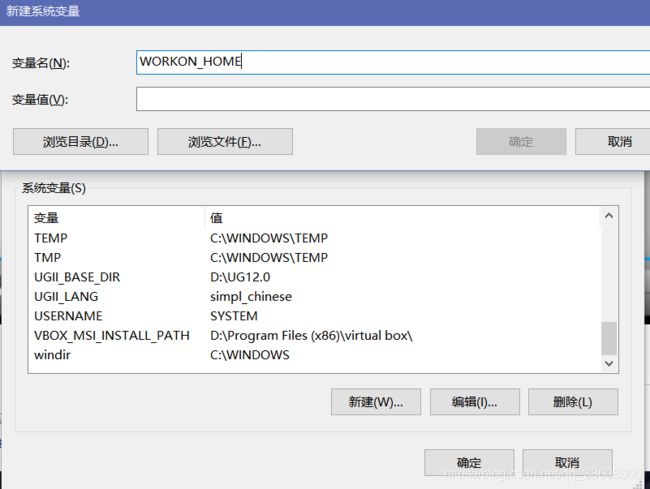
virtualenv
pip install virtualenv

-
删除 虚拟环境
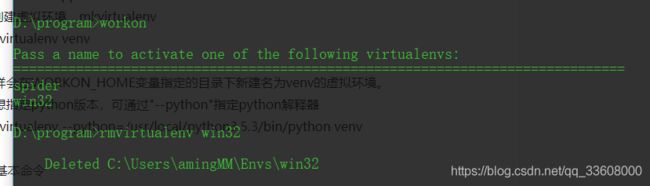
-
查看所有 env
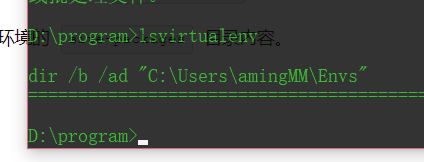
-


python爬虫——入门(1)



- pymysql orm 保存数据
- html解析方法 分析
- 抓取 静态网页 论坛
- 动态网站 电商类
- 模拟登陆cookie 社区类
- 验证突破
- 反爬虫突破
- 多线程 线程池
- scrapy
- 通用分布式爬虫框架模块
- 更新迭代采集
- 通用解析方法
- 分布存储
#认识爬虫#
- 搜索引擎 之前 输入域名访问
- 搜索引擎 主动查询代替 被动浏览
- 怎么获取所有数据(我们关心的内容)
- 产生爬虫 爬取 索引

-
采集网络数据
-
自动化测试 (接口 请求 验证数据)selenium
-
脱离手动 (抢票 , 微信助手,爱聊,注册账号,登陆,获取资料)
-
灰产业 (撸羊毛,网络水军,攻击)
-
数据产品 数据聚合(新闻 ,头条)
-
搜索产品
-
数据分析、人工智能元数据
-
特定领域 数据服务(二手车估价,天气预报,团购,去哪儿)
#知识储备#
- 计算机网络 (http/https协议,tcp/ip协议,socket编程)
- 前端基础
- 正则表达式(数据处理)xpath css选择器
- 数据分布式存储
- 并发处理,多线程池,协程
- 图像识别(处理反扒,验证码)
- 机器学习算法(验证码,数据解析)
#学习问题#
- 大型爬虫 采集更新策略
- 解决 数据反爬虫 机制(多变)
- 数据解析
- 数据存储
- 模拟登陆(验证码识别)
- 爬虫监控 部署
- 数据去重
#爬虫正能量#
- 注意节制 限速/代理/线程 控制 减少频率
- 数据安全 robots.txt协议
- 法律问题 (2019.11.30 并不成熟)
- 可显数据
- 反扒策略
#robots协议#
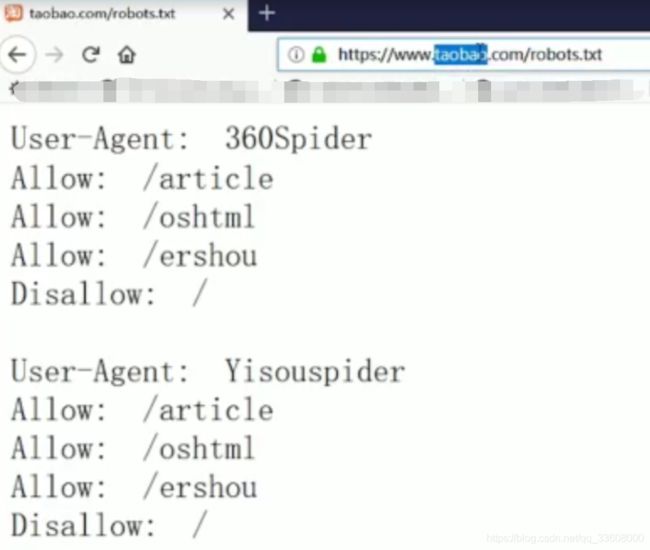
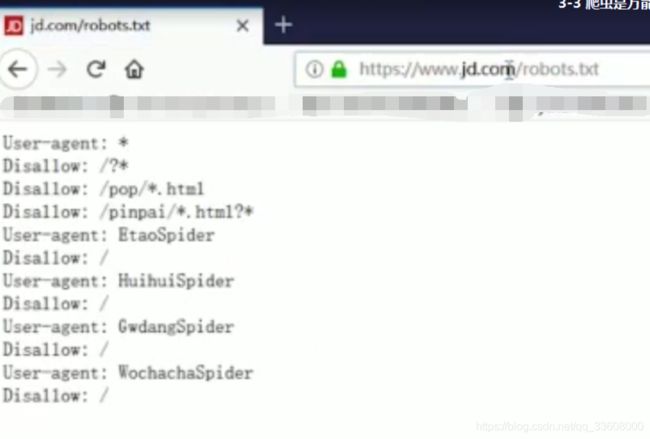
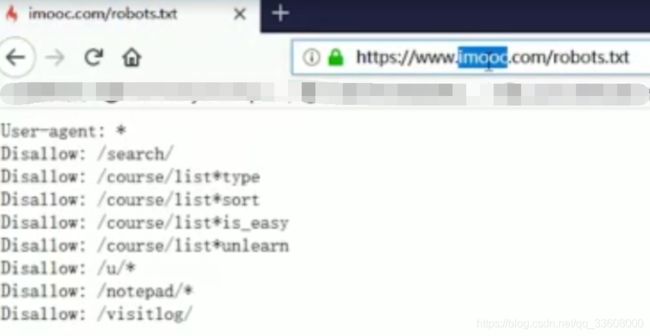
-
user-agent : 爬虫名称
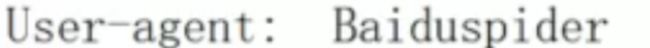
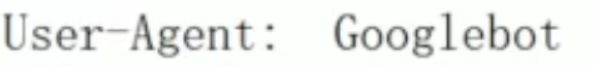
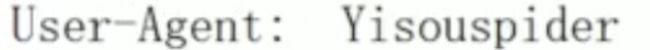

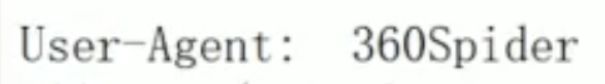

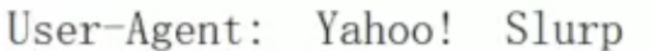

一般放在末尾
-
allow:爬虫可以访问得url (根路径下) /$为首页
-
disallow:不可以爬取 一般加入 /
Opencv for python
opencv 简介
强大的图像处理和计算机视觉库,实现了很多实用算法
安装
opencv包安装
opencv-python包(非官方):
pip install opencv-python
官方文档:https://opencv-python-tutroals.readthedocs.io/en/latest/
简单图像处理
图像像素存储形式
首先得了解下图像在计算机中存储形式:
(为了方便画图,每列像素值都写一样了)
对于只有黑白颜色的灰度图,为单通道,
一个像素块对应矩阵中一个数字,数值为0到255,
其中0表示最暗(黑色) ,255表示最亮(白色)
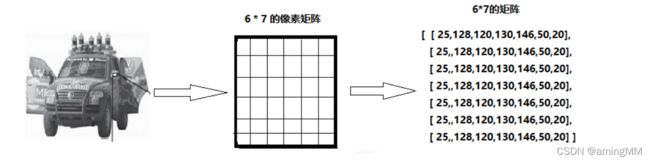
对于采用RGB模式的彩色图片,为三通道图,
Red、Green、Blue三原色,
按不同比例相加,
一个像素块对应矩阵中的一个向量, 如[24,180, 50],
分别表示三种颜色的比列,
即对应深度上的数字,如下图所示:

需要注意的是,由于历史遗留问题,opencv采用BGR模式,而不是RGB
- Caffe,全称Convolutional Architecture for Fast Feature Embedding,
是一个兼具表达性、速度和思维模块化的深度学习框架。
由伯克利人工智能研究小组和伯克利视觉和学习中心开发。
图像读取和写入
- cv2.imread()
imread(img_path,flag) 读取图片,返回图片对象
img_path: 图片的路径,即使路径错误也不会报错,但打印返回的图片对象为None
flag:cv2.IMREAD_COLOR,读取彩色图片,图片透明性会被忽略,为默认参数,也可以传入1
cv2.IMREAD_GRAYSCALE,按灰度模式读取图像,也可以传入0
cv2.IMREAD_UNCHANGED,读取图像,包括其alpha通道,也可以传入-1
- cv2.imshow()
imshow(window_name,img):显示图片,窗口自适应图片大小
window_name: 指定窗口的名字
img:显示的图片对象
可以指定多个窗口名称,显示多个图片
waitKey(millseconds) 键盘绑定事件,阻塞监听键盘按键,返回一个数字(不同按键对应的数字不同)
millseconds: 传入时间毫秒数,在该时间内等待键盘事件;传入0时,会一直等待键盘事件
destroyAllWindows(window_name)
window_name: 需要关闭的窗口名字,不传入时关闭所有窗口
- cv2.imwrite()
imwrite(img_path_name,img)
img_path_name:保存的文件名
img:文件对象
- 使用示例
#coding:utf-8
import cv2
img = cv2.imread(r"C:\Users\Administrator\Desktop\roi.jpg")
# print(img.shape)
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret,img_threshold = cv2.threshold(img_gray,127,255,cv2.THRESH_BINARY)
cv2.imshow("img",img)
cv2.imshow("thre",img_threshold)
key = cv2.waitKey(0)
if key==27: #按esc键时,关闭所有窗口
print(key)
cv2.destroyAllWindows()
cv2.imwrite(r"C:\Users\Administrator\Desktop\thre.jpg",img_threshold)
图像像素获取和编辑
- 像素值获取:
img = cv2.imread(r"C:\Users\Administrator\Desktop\roi.jpg")
#获取和设置
pixel = img[100,100] #[57 63 68],获取(100,100)处的像素值
img[100,100]=[57,63,99] #设置像素值
b = img[100,100,0] #57, 获取(100,100)处,blue通道像素值
g = img[100,100,1] #63
r = img[100,100,2] #68
r = img[100,100,2]=99 #设置red通道值
#获取和设置
piexl = img.item(100,100,2)
img.itemset((100,100,2),99)
- 图片性质
import cv2
img = cv2.imread(r"C:\Users\Administrator\Desktop\roi.jpg")
#rows,cols,channels
img.shape #返回(280, 450, 3), 宽280(rows),长450(cols),3通道(channels)
#size
img.size #返回378000,所有像素数量,=280*450*3
#type
img.dtype #dtype('uint8')
- ROI截取(Range of Interest) 矩形和多边形
#ROI,Range of instrest
roi = img[100:200,300:400] #截取100行到200行,列为300到400列的整块区域
img[50:150,200:300] = roi #将截取的roi移动到该区域 (50到100行,200到300列)
b = img[:,:,0] #截取整个蓝色通道
b,g,r = cv2.split(img) #截取三个通道,比较耗时
img = cv2.merge((b,g,r))
- 添加边界(padding)
cv2.copyMakeBorder()
参数:
img:图像对象
top,bottom,left,right: 上下左右边界宽度,单位为像素值
borderType:
cv2.BORDER_CONSTANT, 带颜色的边界,需要传入另外一个颜色值
cv2.BORDER_REFLECT, 边缘元素的镜像反射做为边界
cv2.BORDER_REFLECT_101/cv2.BORDER_DEFAULT
cv2.BORDER_REPLICATE, 边缘元素的复制做为边界
CV2.BORDER_WRAP
value: borderType为cv2.BORDER_CONSTANT时,传入的边界颜色值,如[0,255,0]
- 使用示例:
#coding:utf-8
import cv2 as cv
import matplotlib.pyplot as plt
img2 = cv.imread(r"C:\Users\Administrator\Desktop\dog.jpg")
img = cv.cvtColor(img2,cv.COLOR_BGR2RGB) #matplotlib的图像为RGB格式
constant = cv.copyMakeBorder(img,20,20,20,20,cv.BORDER_CONSTANT,value=[0,255,0]) #绿色
reflect = cv.copyMakeBorder(img,20,20,20,20,cv.BORDER_REFLECT)
reflect01 = cv.copyMakeBorder(img,20,20,20,20,cv.BORDER_REFLECT_101)
replicate = cv.copyMakeBorder(img,20,20,20,20,cv.BORDER_REPLICATE)
wrap = cv.copyMakeBorder(img,20,20,20,20,cv.BORDER_WRAP)
titles = ["constant","reflect","reflect01","replicate","wrap"]
images = [constant,reflect,reflect01,replicate,wrap]
for i in range(5):
plt.subplot(2,3,i+1),plt.imshow(images[i]),plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()

https://www.cnblogs.com/silence-cho/p/10926248.html
import cv2
import matplotlib.pyplot as plt
img =cv2.imread(r"F:\1.jpg")
# print(type(img))
# print(img.shape)
'''
<class 'numpy.ndarray'>
(675, 1200, 3)
'''
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#matplotlib的图像为RGB格式
content = cv2.copyMakeBorder(img_gray,20,20,20,20,cv2.BORDER_CONSTANT,value=[0,255,0])
ret,thre1 = cv2.threshold(img,127,255,cv2.THRESH_BINARY)
cv2.imshow("gray",thre1)
title = ["normal","gray","se"]
imgs= [img,img_gray,thre1]
for i in range(3):
plt.subplot(2,2,i+1),plt.imshow(imgs[i],"gray")
plt.title(title[i])
plt.xticks([]),plt.yticks([])
plt.show()
key = cv2.waitKey(0)
if key ==27:
print(key)
cv2.destroyAllWindows()
# https://blog.csdn.net/u010451780/article/details/106729827
# net = cv2.dnn.readNetFromCaffe()
# 用于读取已经训练好的caffe模型
# 参数说明: 1表示caffe网络的结构文本,2表示已经训练好的参数结果
# https://www.cnblogs.com/my-love-is-python/p/10455812.html
# https://www.baidu.com/s?ie=utf8&oe=utf8&wd=caffe%E6%A8%A1%E5%9E%8B%20%20openpose&tn=98010089_dg&ch=3

windows GUI python自动化
pywin32
QQ/微信 邮件 群发技术实现
由于外包开发 ,自己也需要 所以开发点 常用账号的 软件
添加依赖

pip install pyautogui
实验原理
itchat库
如果我们需要自己来分析这个接口,也不是不可以,但需要费时费力。
github用户littlecodersh已经做好了这个工作,它把接口都找出来,封装成python语言下的itchat库。
我们直接调用这个库就可以了。

微信itchat 手册 https://itchat.readthedocs.io/zh/latest/
关键点
-
微信个人号中的群发助手可以一次给30个发送消息,
-
如果要给所有所有群发,则需要自己手动发送多次,或者借助程序实现了。
-
在微信的官方网站上 https://weixin.qq.com/,提供了一个网页版的微信,地址为https://wx.qq.com/
-
登录该网页版微信后,可以在网页上给对方发送消息,通过抓包分析网页交互,可以得到发送消息的接口,
-
然后使用程序调用该接口,就可以给好友发送消息了。
-
把所有好友都找出来,然后排列依次给他们发送消息,这样就是群发。
-
win32 api获取窗口句柄
-
通过使用opencv对窗体控件进行识别,进而实现控制操作
-
对于简单的操作
(控制剪切板缓存、自动化keyboard操作、desktop光标移动、鼠标点击动作等)可以使用python的一些包进行
简单的模拟实现:pyautogui / pywin32 等。
pyautogui是美国一个知名python程序员也是优秀的python作者Al Sweigart维护的一个模块
整个模块都是python写的,可读性比较好,对一般功能的封装得很好。
pywin32就有点不一样了,这个完全是用python对win32 api接口进行python api的转换,用起来比较复杂,
对windows api及c sharp有一定了解,加上文档全但是基本就是原样包windows api的文档抄了一下,所以看起来是相当痛苦的。
(但是实际上pywin32跟pyautogui的思路都是使用windows api获取窗体程序句柄进而实现自动化操控,从
实现原理上看来,也注定这种方式是不可能完成过于复杂的UI自动化作业的。)
安装好之后,在程序中引用该库
#coding=utf-8
import itchat
import os
import time
itchat.auto_login(hotReload=True) # 热加载 缓存登陆
print('纪年科技')
print('微信营销工具')
print('微信账号测试')
print('请慎重使用')
wxfriends = itchat.get_friends()
num = len(wxfriends)
print ("此账号共有", num , "位好友")
for wxname in range(1,num):
itchat.send("微信清理,请配合您回我一条信息备注身份,否则系统会清理掉记录以及好友信息 本人xxx", toUserName=wxfriends[wxname]['UserName'])
print(f'发送到第{wxname}位好友:{str(wxfriends[wxname]["NickName"]).center(20, "x")}')
time.sleep(5)
print('此次消息发送完毕,请在系统联网查看结果')
itchat.run()
os.system('pause')
QQ群发实现
pyHook 库获取:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyhook
https://pan.baidu.com/s/1IHk4kMTSm-FtmrGFPbu-Ng 提取码: c7fq
安装时用 pip install 然后直接把 whl 文件拖到 cmd 里就生成路径了

- anaconda
- win32gui库
- env 虚拟环境

- pyautogui
邮件群发
- 一般发邮件方法
SMTP是发送邮件的协议,Python内置对SMTP的支持,可以发送纯文本邮件、HTML邮件以及带附件的邮件。
- 首先我们需要开启smtp服务器,然后会生成一个码

循环结构正弦幂级数展开及图像

import math
n = int(input('input order n(odd number): '))
x = eval(input('input x: '))
exact_sol = math.sin(x)
s = 0
flag = 1
for i in range(1, n+1, 2):
s += flag * math.pow(x, i)/math.factorial(i)
flag = -flag
number_sol = s
print('exact solution sin(%s)=%s' % (x, exact_sol))
print('numerical solution = %s' % number_sol)

重写数组类对象结构实现


重写数组类
## 2020/4/27
class Myarray: #自定义数组类
def __init__(self,arr):
"列表转换"
self.arr = list(arr)
def Ladd (self,x):
"末尾添加元素"
self.arr.append(x)
return self.arr
def Insert(self,x,con):
"指定位置添加内容"
self.arr.insert(x,con)
return self.arr
def Switch(self,x,con):
"修改元素"
self.arr[x]=con
return self.arr
def Ldel(self,x):
"删除指定元素"
self.arr.pop(x)
return self.arr
a = Myarray(range(10)) #调用类转换
print(list(range(10)))
print(a.Ladd(6))
print(a.Insert(5,777))
print(a.Switch(7,555))
print(a.Ldel(8))
从数组中取下标 打印数组中元素
arr = input("")
#输入一个一维数组,每个数之间使空格隔开
num = [int(n) for n in arr.split()]
#将输入每个数以空格键隔开做成数组
# print(num)
a = num
print(a)
#打印数组
import random
num = range(0, 100) # 范围在0到100之间,需要用到range()函数。
nums = random.sample(num, 10) # 选取10个元素
print(nums)
res = []
for x in a:
xx = nums[x-1]
res.append(xx)
print(res)
搭建python环境













走进python





























解释型、面向对象、动态数据类型的高级程序设计语言
由 Guido van Rossum 于 1989 年底发明,
第一个公开发行版发行于 1991 年。
像 Perl 语言一样, Python 源代码同样遵循 GPL(GNU General Public License) 协议。
官方宣布,2020 年 1 月 1 日, 停止 Python 2 的更新。
Python 2.7 被确定为最后一个 Python 2.x 版本。
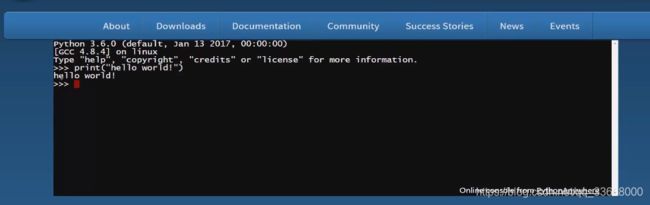
#!/usr/bin/python
print("Hello, World!")
#!/usr/bin/python3
print("Hello, World!")
(Python 3.0+)
Python 3.0+ 版本已经把 print 作为一个内置函数
解析器
解析库 – lxml
安装lxml库 (支持HTML和XML解析,支持XPath解析方式)
pip install lxml
Xpath
在 XPath 中,有七种类型的节点:
元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。
XML 文档是被作为节点树来对待的。
树的根被称为文档节点或者根节点。
节点关系
父(Parent)、子(Children) 每个元素以及属性都有一个父。

book 元素是 title、author、year 以及 price 元素的父
title、author、year 以及 price 元素都是 book 元素的子
title、author、year 以及 price 元素都是同胞:
title 元素的先辈是 book 元素和 bookstore 元素
bookstore 的后代是 book、title、author、year 以及 price 元素
节点选取
XPath 使用路径表达式在 XML 文档中选取节点。
节点是通过沿着路径或者 step 来选取的。

获取页面元素xpath路径的快捷方式
BeautifulSoup4解析器
BeautifulSoup4是一个HTML/XML的解析器,
主要的功能是解析和提取HTML/XML的数据。和lxml库一样
lxml只会局部遍历,
而BeautifulSoup4是基于HTML DOM的,会加载整个文档,解析整个DOM树,
因此内存开销比较大,性能比较低。
BeautifulSoup4用来解析HTML比较简单,API使用非常人性化,
支持CSS选择器,是Python标准库中的HTML解析器,
也支持lxml解析器。
————————————————
BeautifulSoup4的安装
pip install beautifulsoup4


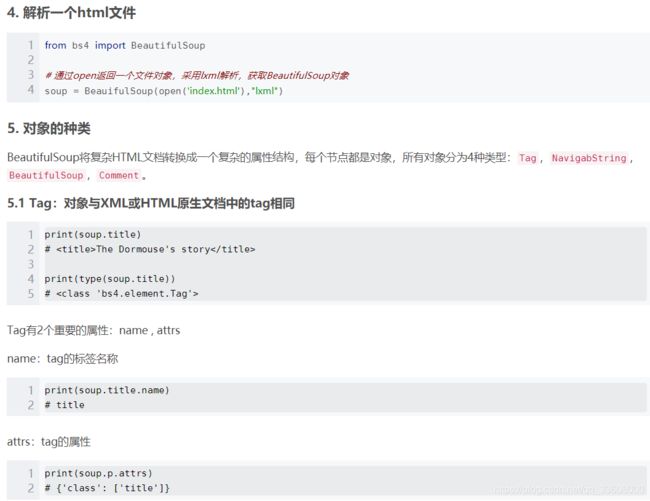
# 获取title标签
print(soup.title)
# <title>The Dormouse's story</title>
# 获取title标签名称
print(soup.title.name)
# title
# 获取title标签的内容
print(soup.title.string)
# The Dormouse's story
# 获取title的父标签
print(soup.title.parent)
# <head><title>The Dormouse's story</title></head>
# 获取title的父标签名称
print(soup.title.parent.name)
# head
# 获取p标签
print(soup.p)
# <p class="title"><b>The Dormouse's story</b></p>
# 获取p标签class属性
print(soup.p['class'])
# ['title'] #返回的是list
# 获取所有的a标签
print(soup.find_all('a'))
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
# 获取id='link3'的标签
print(soup.find(id="link3"))
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
# 获取所有的a标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
# http://example.com/elsie
# http://example.com/lacie
# http://example.com/tillie
# 获取文档中所有文字内容
print(soup.get_text())
# The Dormouse's story
#
# The Dormouse's story
# Once upon a time there were three little sisters; and their names were
# Elsie,
# Lacie and
# Tillie;
# and they lived at the bottom of a well.
# ...



文档
爬取文章自动发送QQ群
Python的re模块 正则表达式
正则表达式处理函数
特殊的字符序列 检查一个字符串是否与某种模式匹配
测试字符串内的模式。
—— 例如,可以测试输入字符串,以查看字符串内是否出现电话号码模式或信用卡号码模式。这称为数据验证。
替换文本。
—— 可以使用正则表达式来识别文档中的特定文本,完全删除该文本或者用其他文本替换它。
基于模式匹配从字符串中提取子字符串。
—— 可以查找文档内或输入域内特定的文本。
贪婪模式和非贪婪模式
正则表达式通常使用于查找匹配字符串。
python里数量词默认是贪婪的,总是尝试匹配尽可能多的字符;
非贪婪模式正好相反,总是尝试匹配尽可能少的字符。
使用非贪婪模式的话,只需要在量词后面直接加上一个问号”?”。
贪婪模式可以与固化分组结合,提升匹配效率,而非贪婪模式却不可以。
方法/属性 作用
match() 只检查 RE 是否在字符串刚开始的位置匹配
只报告一次成功的匹配,它将从 0 处开始; 不是从 0 开始的 ,不会报告
search() 扫描整个字符串,找到这个 RE 匹配的位置
findall() 找到 RE 匹配的所有子串,并把它们作为一个列表返回
finditer() 找到 RE 匹配的所有子串,并把它们作为一个迭代器返回
- 如果匹配成功则返回一个Match Object对象,该对象有以下属性、方法:
方法/属性 作用
group() 返回re整体匹配的字符串
可以一次输入多个组号,对应组号匹配的字符串
group (n,m) 返回组号为n,m所匹配的字符串,如果组号不存在,则返回indexError异常
start() 返回匹配开始的位置
end() 返回匹配结束的位置
span() 返回一个元组包含匹配 (开始,结束) 的位置
re.compile
可以把正则表达式编译成一个正则表达式对象。
可以把那些经常使用的正则表达式编译成正则表达式对象,这样可以提高一定的效率。
re.findall 以列表形式 获取字符串中 返回所有匹配的字符串
Python 2.2中,也可以用 finditer() 方法
re.split 以列表形式返回分割的字符串
re.sub 替换所有的匹配项,返回一个替换后的字符串,如果匹配失败,返回原字符串
re.search 在字符串内查找匹配,找到第一个匹配,返回Match Object,或None
语法
'.' 匹配所有字符串,除\n以外
'-' 表示范围[0-9]
'*' 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。
'+' 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+
'^' 匹配字符串开头
'$' 匹配字符串结尾 re
'\' 转义字符, 使后一个字符改变原来的意思,如果字符串中有字符*需要匹配,可以\*或者字符集[*] re.findall(r'3\*','3*ds')结['3*']
'*' 匹配前面的字符0次或多次 re.findall("ab*","cabc3abcbbac")结果:['ab', 'ab', 'a']
'?' 匹配前一个字符串0次或1次 re.findall('ab?','abcabcabcadf')结果['ab', 'ab', 'ab', 'a']
'{m}' 匹配前一个字符m次 re.findall('cb{1}','bchbchcbfbcbb')结果['cb', 'cb']
'{n,m}' 匹配前一个字符n到m次 re.findall('cb{2,3}','bchbchcbfbcbb')结果['cbb']
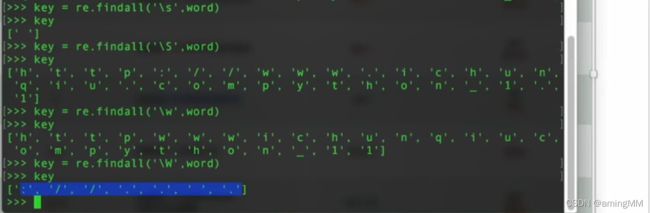
'\d' 匹配数字,等于[0-9] re.findall('\d','电话:10086')结果['1', '0', '0', '8', '6']
'\D' 匹配非数字,等于[^0-9] re.findall('\D','电话:10086')结果['电', '话', ':']
'\w' 匹配字母和数字,等于[A-Za-z0-9] re.findall('\w','alex123,./;;;')结果['a', 'l', 'e', 'x', '1', '2', '3']
'\W' 匹配非英文字母和数字,等于[^A-Za-z0-9] re.findall('\W','alex123,./;;;')结果[',', '.', '/', ';', ';', ';']
'\s' 匹配空白字符 re.findall('\s','3*ds \t\n')结果[' ', '\t', '\n']
'\S' 匹配非空白字符 re.findall('\s','3*ds \t\n')结果['3', '*', 'd', 's']
'\A' 匹配字符串开头
'\Z' 匹配字符串结尾
'\b' 匹配单词的词首和词尾,单词被定义为一个字母数字序列,因此词尾是用空白符或非字母数字符来表示的
'\B' 与\b相反,只在当前位置不在单词边界时匹配
[] 是定义匹配的字符范围。比如 [a-zA-Z0-9] 表示相应位置的字符要匹配英文字符和数字。[\s*]表示空格或者*号
'(?P...)' 分组,除了原有编号外在指定一个额外的别名
re.search(“(?P[0-9]{4})(?P[0-9]{2})(?P[0-9]{8})”,“371481199306143242”).groupdict(“city”)
结果{‘province’: ‘3714’, ‘city’: ‘81’, ‘birthday’: ‘19930614’}
反斜杠的困扰
python 的字符串中,
\ 是被当做转义字符的。
在正则表达式中,\ 也是被当做转义字符。
这就导致了一个问题:
如果你要匹配 \ 字符串,那么传递给 re.compile() 的字符串必须是"\\"。
由于字符串的转义,
所以实际传递给 re.compile() 的是"\“,然后再通过正则表达式的转义,
“\” 会匹配到字符”"。
这样虽然可以正确匹配到字符 \,但是很麻烦,而且容易漏写反斜杠而导致 Bug。那么有什么好的解决方案呢?
原始字符串很好的解决了这个问题,通过在字符串前面添加一个r,
表示原始字符串,不让字符串的反斜杠发生转义。
那么就可以使用r"\"来匹配字符\了。
正则表达式实例
[Pp]ython 匹配 "Python" 或 "python"
rub[ye] 匹配 "ruby" 或 "rube"
[aeiou] 匹配中括号内的任意一个字母
[0-9] 匹配任何数字。类似于 [0123456789]
[a-z] 匹配任何小写字母
[A-Z] 匹配任何大写字母
[a-zA-Z0-9] 匹配任何字母及数字
[^aeiou] 除了aeiou字母以外的所有字符
[^0-9] 匹配除了数字外的字符
特殊字符类
. 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。
\d 匹配一个数字字符。等价于 [0-9]。
\D 匹配一个非数字字符。等价于 [^0-9]。
\s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。
\S 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
\w 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。
\W 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。
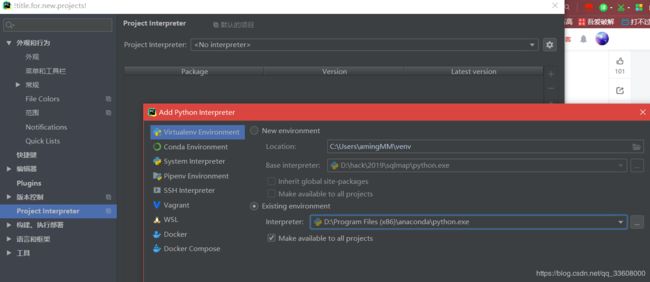
lxml中etree
- xpath解析DOM树 ( XPath是一门在 XML文档中查找信息的语言)
- 方法:etree.HTML()和etree.tostrint()
- 解析字符串格式的HTML文档对象,
将传进去的字符串转变成_Element对象。
作为_Element对象,
可以方便的使用getparent()、remove()、xpath()等方法
2.用来将_Element对象转换成字符串。
一般通过简单的xpath表达式无法得到想要的内容的时候我就会用该方法
采用的etree去选取对应的xpath
组合成文档
(这边可将获取的html写入本地文件,看看是不是可以直接获取值得)
– url 访问
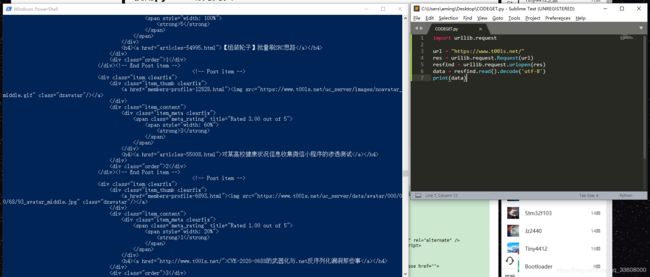
import urllib.request
url = "https://www.t00ls.net/"
res = urllib.request.Request(url)
resfind = urllib.request.urlopen(res)
data = resfind.read().decode('utf-8')
print(data)
-
xpath语法
xxxooo
-
BeautifulSoup
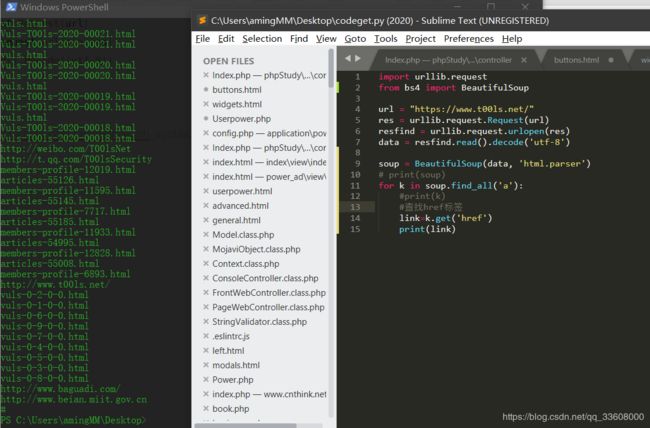
import urllib.request
from bs4 import BeautifulSoup
url = "https://www.t00ls.net/"
res = urllib.request.Request(url)
resfind = urllib.request.urlopen(res)
data = resfind.read().decode('utf-8')
soup = BeautifulSoup(data, 'html.parser')
# print(soup)
for k in soup.find_all('a'):
#print(k)
#查找href标签
link=k.get('href')
print(link)
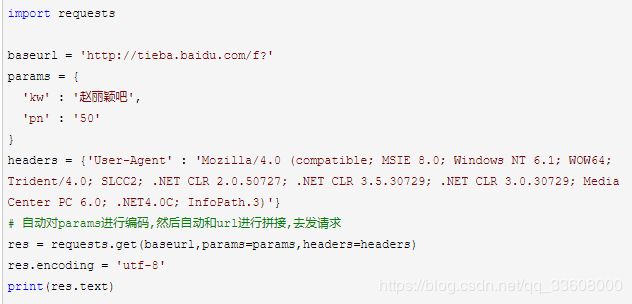
requests.get()参数
查询参数-params
1.参数类型 : 字典,字典中键值对作为查询参数
2.使用方法
1、res = requests.get(url,params=params,headers=headers)
2、特点:
- url为基准的url地址,不包含查询参数
- 该方法会自动对params字典编码,然后和url拼接
web客户端验证 参数-auth
1.作用类型
1、针对于需要web客户端用户名密码认证的网站
2、auth = (‘username’,‘password’)

from urllib import request
from bs4 import BeautifulSoup
import numpy as np
url = "https://tophub.today/"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
res = request.Request(url,headers=headers)
page = request.urlopen(res).read().decode('utf-8')
soup = BeautifulSoup(page, 'html.parser')
titles = soup.find_all('span', 't')
urls = soup.find_all('a', rel='nofollow')
urllink = []
for url in urls:
xll = url.get('href')
urllink.append(xll)
titlink = []
for title in titles:
tit = title.get_text()
titlink.append(tit)
for i in range(4):
del urllink[0]
x = {}
x[0] = urllink
x[1] = titlink
y1 = zip(x[0],x[1]) #py3改动
finish = []
for xx in y1:
xxx = np.array(xx).flatten()
# finish.extend(xxx)
# finish.extend(np.array(xx).flatten())
# print(finish)
模拟登陆自动刷新
urllib2库的基本使用
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地
urllib2 是 Python2.7 自带的模块(不需要下载,导入即可使用)
urllib2 官方文档:https://docs.python.org/2/library/urllib2.html
urllib2 源码:https://hg.python.org/cpython/file/2.7/Lib/urllib2.py
- 建立2.7的虚拟环境
- pip install virtualenv

- 选择想建立虚拟环境的文件夹

- 使用python 2.7 创建env环境


1.通过默认浏览器打开网页
import webbrowser
webbrowser.open("http://www.baidu.com")
webbrowser.open(url, new=0, autoraise=True)
在系统的默认浏览器中访问url地址,
如果new=0, url会在同一个浏览器窗口中打开;
如果new=1,新的浏览器窗口会被打开;
new=2 新的浏览器tab会被打开
2.通过os模块,启动浏览器并打开指定网页
import os
os.system(r'"C:\Program Files\internet explorer\iexplore.exe" http://www.baidu.com')
3.使用selenium
from selenium import webdriver
url='http://www.baidu.com'
driver = webdriver.Firefox()
driver.get(url)
Python黑帽子-Pentesters手记






































视觉识别实战&&coreML
- coreML 人工智能 物体识别
- 计算机从历史数据 找规律(客观数据)–>未来不确定(太阳爆炸)的场景自动决策
- 人脑判断评估局限性 (人为因素(成见,知识水平,思想层次))(迁带笔顺)
- 数据替代专家层面的学习
- 经济驱动 数据变现
- 离线学习---->模型 (用户行为模式特定变化)
- 在线学习 ----> 在线实时数据 ---->写入模型 ---->模型演化优化
(应用程序埋点–>收据数据–>数据分析---->需求分析 ---->程序撰写)

人工智能接口
- 监督学习 SupervisedML 条件分析
- 非监督学习 unSupervisedML
未来简史 从智人到神人
CS229 机器学习 (斯坦福大学)
CoreML core image —>open cv/gl
像素点 高低 —>判断
RGB299,299----> image buffer
你可能感兴趣的:(python,开发语言)