什么是数据湖,数据湖和数据仓库的区别在哪
数据仓库是什么
| 数据仓库 | 数据湖 | |
|---|---|---|
| 数据 | 来自事务系统、运营数据库和业务线应用程序的清洗过结构化数据 | 来自 IoT 设备、网站、移动应用程序、社交媒体和企业应用程序的原始数据 |
| 架构 | 设计在数据仓库实施之前(写入型 Schema)。在存储数据之前定义架构。这需要您清理和规范化数据,这意味着架构的灵活性要低得多。 | 准备使用数据时,就给它一个定义(读取型 Schema)。在存储数据后定义架构。这需要较少的初始工作并提供更大的灵活性 |
| 性价比 | 更快查询结果会带来较高存储成本 | 更快查询结果只需较低存储成本 |
| 数据质量 | 可作为重要事实依据的高度监管数据 | 任何可以或无法进行监管的数据(例如原始数据) |
| 用户 | 业务分析师 | 数据科学家、数据开发人员和业务分析师(使用监管数据) |
| 分析 | 批处理报告、BI 和可视化 | 机器学习、预测分析、数据发现和分析 |
| 优点 | 高并发快速响应干净、安全的数据多数据源集成转换一次,多次使用 | 数据存储:大容量低成本数据保真度:数据湖以原始的格式保存数据数据使用:数据湖中的数据可以方便的被使用延迟绑定:数据湖提供灵活的,面向任务的数据绑定,不需要提前定义数据模型 |
1.Hive的一些问题
- 不可靠的更新操作
我们针对某张Hive表的数据做 load data overwrite into 操作时, 整个操作分两个部分, 删除已存在的文件,移动新的文件到分区目录下,此时如果有人任务正在读取这个数据, 受文件删除操作的影响,整个任务就GG了,Hive的操作整体是没有ACID保障的。
- column rename 问题
在使用Parquet、ORC、Avro等文件格式时, 如果我们重命名某个column的名字时,整个数据表都要重新复写,代价很大, 一些大的数据表基本是不可接受的。
- 太多分区造成的性能问题
Hive的分区元数据都是保存到目录级别,在读取Hive表做完分区下推查询以后,需要对所有过滤出来的分区做一次list操作,得到所有的明细文件然后生成任务,对于分区非常多表的来说,在云音乐目前的量级下,大量的list操作非常的耗时的,高峰期的NameNode压力非常大,大量的list操作的耗时的占比甚至和任务在计算上花费的时长相当,这也是为什么一些公司的Hive表只允许两层分区的原因之一。
- 元数据保存在元数据和文件系统两个地方
分区信息保存在元数据库, 文件信息保存在NameNode当中,整体没有原子性保障,如果文件发生变化,多了数据或者少了数据,对于元数据是不感知的,数据虽然能被正常读取,但数据的可靠性是缺乏保障的。
数据湖技术
- 最底下是分布式文件系统,云上用户 S3 和 oss 这种对象存储会用的更多一些,毕竟价格便宜很多;非云上用户一般采用自己维护的 HDFS。
- 第二层是数据加速层。数据湖架构是一个存储计算彻底分离的架构,如果所有的数据访问都远程读取文件系统上的数据,那么性能和成本开销都很大。如果能把经常访问到的一些热点数据缓存在计算节点本地,这就非常自然的实现了冷热分离,一方面能收获到不错的本地读取性能,另一方面还节省了远程访问的带宽。
- 第三层就是 Table format 层,主要是把一批数据文件封装成一个有业务意义的 table,提供 ACID、snapshot、schema、partition 等表级别的语义。一般对应这开源的 Delta、Iceberg、Hudi 等项目。对一些用户来说,他们认为Delta、Iceberg、Hudi 这些就是数据湖,其实这几个项目只是数据湖这个架构里面的一环,只是因为它们离用户最近,屏蔽了底层的很多细节,所以才会造成这样的理解。
- 最上层就是不同计算场景的计算引擎了。开源的一般有 Spark、Flink、Hive、Presto、Hive MR 等,这一批计算引擎是可以同时访问同一张数据湖的表的

iceberg的特点https://iceberg.apache.org/
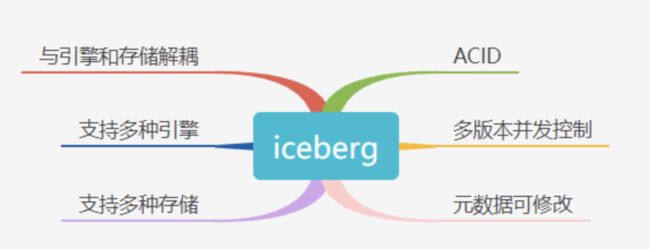
| 能力与优势 | 详情 |
|---|---|
| ACID | Iceberg提供了锁的机制来提供ACID的能力,确保表的修改是原子性的,提供了乐观锁降低锁的影响,并使用冲突回退和重试机制来解决并发所造成的冲突问题。支持隔离级别。提供“行”级别数据修改删除、能力。 |
| MVCC(多版本并发控制) | 每次写操作都会产生一个新的快照,快照始终是向后线性递增,确保了线性一致性。利用iceberg的time travel能力,提供了用户快照回滚和数据重放的能力。可以方便的基于snapshot的历史实现增量消费。 |
| 解耦(接口抽象程度高) | 与上层数据处理引擎和底层数据存储格式的解耦。对接上层,提供了丰富的表操作接口,非常容易与上层数据处理引擎对接(如 Flink、Hive、Spark)。对接下层,屏蔽了底层数据格式的差异,提供了对Parquet, ORC和Avro格式的支持。可支持多种存储和计算引擎,同时支持流批处理。相比于 Hudi、Delta Lake,Iceberg 的架构实现更为优雅,同时对于数据格式、类型系统有完备的定义和可进化的设计 |
| table evolution | 表schema, 分区方式可修改。schema修改支持 add, drop, rename, update(提升数据类型),recorder(调整列顺序) 可更新已有表的分区信息 (因为查询语句并不直接引用分区值) 更新是元数据更改,因此不需要重写数据文件来执行更新。 |
| 隐式分区 | iceberg可根据用户query自动进行partition pruning,过滤掉不需要数据,用户无需利用分区信息可以优化查询。 |
官方介绍:
Apache Iceberg是一种用于大型分析数据集的开放表格,Iceberge向Trino和Spark添加了使用高性能格式的表,就像Sql表一样。
Iceberg为了避免出现不变要的一些意外,表结构和组织并不会实际删除,用户也不需要特意了解分区便可进行快速查询。
(1)Iceberg的表支持快速添加、删除、更新或重命名操作
(2)将分区列进行隐藏,避免用户错误的使用分区和进行极慢的查询。
(3)分区列也会随着表数据量或查询模式的变化而自动更新。
(4)表可以根据时间进行表快照,方便用户根据时间进行检查更改。
(5)提供版本回滚,方便用户纠错数据。
Iceberg是为大表而建的,Iceberg用于生产中,其中单表数据量可包含10pb左右数据,甚至可以在没有分布式SQL引擎的情况下读取这些巨量数据。
(1)查询计划非常迅速,不需要分布式SQL引擎来读取数据
(2)高级过滤:可以使用分区和列来过滤查询这些数据
(3)可适用于任何云存储
(4)表的任何操作都是原子性的,用户不会看到部分或未提交的内容。
(5)使用多个并发器进行写入,并使用乐观锁重试的机制来解决兼容性问题
-
Iceberg使用嵌入式程序的方式工作, 我们在使用的时候只需要添加响应的jar包,指定响应的工作类即可运行工作 !
下载地址 : http://iceberg.apache.org/releases/
- 0.11.1 source tar.gz – signature – sha512 源码地址
- 0.11.1 Spark 3.0 runtime Jar spark3运行jar
- 0.11.1 Spark 2.4 runtime Jar spark2.4 运行jar
- 0.11.1 Flink runtime Jar flink 运行jar 目前flink on iceberg 仅支持到0.12.X
- 0.11.1 Hive runtime Jar hive运行时jar 推荐hive2.3.X 其他版本需要自己兼容
与flink兼容性 目前仅兼容flink1.11.X-flink1.12.0 暂未支持flink1.13.0 flink1.13有些方法返回值已经修改

目前社区内有以下组织正在推动iceberg的发展

hudi的特点https://hudi.apache.org/

- 使用快速、可插入索引进行更新、删除
- 增量查询、记录级变更流
- 事务、回滚、并发控制
- 来自 Spark、Presto、Trino、Hive 等的 SQL 读/写
- 自动文件大小调整、数据聚类、压缩、清理
- 流摄取、内置 CDC 源和工具
- 用于可扩展存储访问的内置元数据跟踪
- 向后兼容的模式演变和执行
COW和MOR
基于上述基础概念之上,Hudi提供了两类表格式COW和MOR。他们会在数据的写入和查询性能上有一些不同
Copy On Write Table
简称COW。顾名思义,他是在数据写入的时候,复制一份原来的拷贝,在其基础上添加新数据。正在读数据的请求,读取的是是近的完整副本,这类似Mysql 的MVCC的思想。
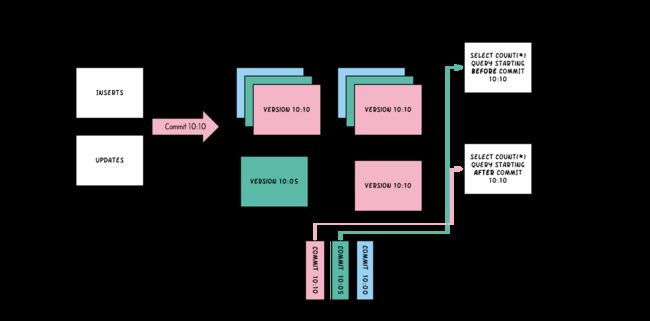
上图中,每一个颜色都包含了截至到其所在时间的所有数据。老的数据副本在超过一定的个数限制后,将被删除。这种类型的表,没有compact instant,因为写入时相当于已经compact了。
- 优点 读取时,只读取对应分区的一个数据文件即可,较为高效
- 缺点 数据写入的时候,需要复制一个先前的副本再在其基础上生成新的数据文件,这个过程比较耗时。且由于耗时,读请求读取到的数据相对就会滞后
Merge On Read Table
简称MOR。新插入的数据存储在delta log 中。定期再将delta log合并进行parquet数据文件。读取数据时,会将delta log跟老的数据文件做merge,得到完整的数据返回。当然,MOR表也可以像COW表一样,忽略delta log,只读取最近的完整数据文件。下图演示了MOR的两种数据读写方式
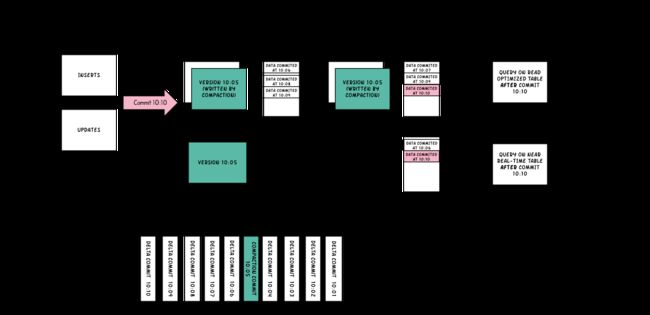
- 优点 由于写入数据先写delta log,且delta log较小,所以写入成本较低
- 缺点 需要定期合并整理compact,否则碎片文件较多。读取性能较差,因为需要将delta log 和 老数据文件合并
hudi COW MOR 对比
| COW | MOR | |
|---|---|---|
| 数据延迟 | 高 | 低 |
| 查询延迟 | 低 | 高 |
| 更新操作(I/O) | 高 (重写整个parquet) | 低 (附加日志文件) |
| 数据文件大小 | 更小 (更新操作较大) | 更大 (更新成本低) |
| delta(暂未研究) | Iceberg 0.11.X | Hudi0.9.0 | |
|---|---|---|---|
| 小文件合并 | N | Y,Iceberg 提供 API | Y,自动合并,可配置项 |
| 行级操作 | N | Y | Y |
| 多作业并发写 | N | Y | Y |
| 查询引擎 | N | Spark3、Spark2.4、Presto/Trino(原生 Connectors)、Flink1.11.X、Hive2.3.X | Hive、Spark、Presto、Trino |
| 计算引擎 | N | Spark3支持DDL、Spark2.4支持Iceberg API、Flink1.11.X、Flink1.12.X | Spark2.4.3+、Spark3.X、Flink-1.11.X集成不好 |
| 存储引擎 | N | S3、HDFS | hdfs |
| 存储格式 | N | Parquet、ORC、Avro | Parquet、Parquet+Avro |
| time travel | Y | Y | Y |
| 元数据位置 | N | hdfs、推荐hive2.3.X以供共享 metastore | hive |
| 实时性 | N | commit提交后即可见(分钟级) | commit提交后即可见(分钟级) |
| schema修改 | N | Y | Y |
| 语言支持 | Scala、Python、Java | Python、Java | Python、Java |
| ACID | Y | Y | Y |
| 流批接口支持 | N | Y | Y |
| Flink CDC | N | Y | Y |
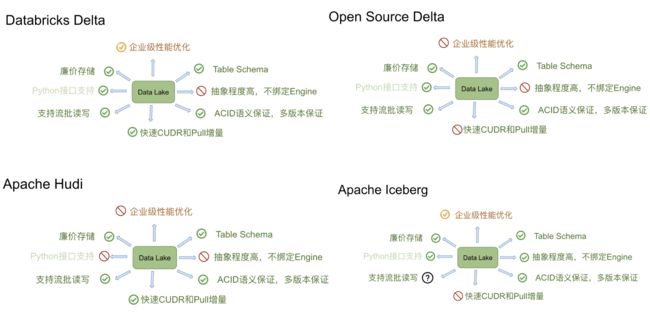
总结:
- 着急进入数据湖阶段使用目前比较成熟的hudi 目前Hudi 社区正在积极的推动和 Flink 的深度集成
- iceberg目前社区都在完善,在和各种引擎集成,由于抽象程度高,未绑定任何引擎,相对来说后续会比较厉害
- delta配套不完善,目前不主推,主要在用原因在于出现较早的数据湖架构
参考地址
-
https://www.cnblogs.com/niceshot/p/14198360.html
-
https://blog.csdn.net/huzechen/article/details/110508262?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162864673716780255227404%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=162864673716780255227404&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_v2~rank_v29-13-110508262.first_rank_v2_pc_rank_v29&utm_term=%E6%95%B0%E6%8D%AE%E6%B9%96+hudi+iceberg&spm=1018.2226.3001.4187