实时数仓入门训练营:Hologres性能调优实践
视频链接:https://developer.aliyun.com/learning/course/807/detail/13889
内容简要:
一、Hologres建表最佳实践
二、Hologres性能问题分析与优化
一、Hologres建表最佳实践
(一)建表优化的必要性
为什么Hologres建表优化非常重要?
首先,对于整个的查询性能以及写入性能来讲,一个好的建表跟一个比较差的建表,性能上面有非常大的区别。
其次,建表优化需要尽早做,是因为Hologres在改 DDL的同时,有可能需要用户重复进行一些数据导入,这种重复的工作使得我们希望尽早完成建表优化。
最后,一个好的建表对于用户的数据存储成本也有一定的帮助。如果建表做得不恰当,可能导致建一些不必要的Index,然后导致数据多了一些冗余的存储,从而提升了成本。
因此,建表优化是非常重要的,这也是把它作为本文第一部分的原因。
(二)业务建模是性能优化的前提

说完建表的重要性之后,我们再看建表优化之前要去做整个业务建模的优化。在考虑使用Hologres的同时,我们要知道通过Hologres能够解决什么样的业务问题,以及通过什么样的方式解决。
Hologres本身是一个HASP产品,在使用Hologres的同时就需要跟业务场景结合,我们要知道这个场景到底是分析场景还是在线服务场景。如果是一个分析型,就用Hologres的列存比较友好,如果是一个在线服务型场景,就用行存比较友好,这些是跟业务场景相关的。
第二个是要能够结合Hologres本身的产品优势。Hologres是一个在线服务以及交互式分析的产品,它并不适合ETL以及海量数据拖取的场景。因此,在把业务往Hologres上面搬的时候,不能搬所有的场景,否则可能导致Hologres做一些不太适合本身的事情,信任就会不太好。
第三个是需要做一些取舍。为了达到预期的性能,可能需要做一些类似预计算或者数据加工的提前操作,减少后续计算复杂度,加快计算速度。
以上这些都跟预先数据建模以及整个业务期望息息相关。
(三)存储方式的选择
做完以上准备工作之后,我们需要进行Hologres管理存储方式的选择。
Hologres本身支持两种存储方式,分别是行存和列存。
行存主要的应用场景是对主键进行高QPS查询,并且当我们表比较宽的时候,一次查询会读取大量列,这种场景适用Hologres是非常适合的。
除此之外, Blink的维表查询必须是用行存,因为一般情况下Blink的维表是高QPS、基于Key的查询,列存没有办法扛住这么高的压力。
列存适用于复杂的交互式分析查询,比如一个查询里面,它有关联、聚合等等各种各样的复杂计算。同时它覆盖的场景非常多,包括过滤、聚合等,列存是比较通用的存储方式。
行存主要适用于在线服务类的场景,列存主要适用于分析型的场景,这是两个存储方式的选择区别。
(四)优化Shard数
Shard_count: Shard实现了物理分表的效果,多个Shard并行服务查询。
增加Shard可以增加查询的分布式并行度,更多Shard不一定查询更快,也会带来并发查询的调度开销。
说完存储方式,接下来我们看Shard数。
Hologres在存储的时候,是把物理表分成一个个Shard存储,每个表会按照一定的分布方式分布到所有的物理节点上面,然后每个Shard可以去并发进行查询,Shard数越多,相当于整个查询的并发度越高。但是Shard数也不是越多越好,因为它本身有一些额外的开销,所以我们需要根据整个查表的数据量以及查询复杂度来设计每个表的Shard数。
在集群扩容的时候,比如我们原本是128 Core的实例,扩容到256 Core之后,我们需要对整个Shard数进行一定的调整,这样才能享受扩容带来的性能提升。
因为我们整个并发度是在Shard数上面,假如实例扩容了,但是Shard数没变,那么相当于整个计算的并发度没变,这种情况会导致虽然扩容了,但是查询性能没有提升。
一般情况下,我们会建议用户将Shard数设置成跟实例规格差不多的数量,比如一个64 Core的,Shard数设成40或64这种比较贴近于实例规格的数量。当规格往上涨之后,我们希望Shard数也能往上涨,从而提高整个查询的并发度。
(五)优化Distribution Key
然后说完Shard数之后,我们再看一下Hologres里面非常重要的Distribution Key,它主要是用来决定数据如何分到每个Shard上面。
Distribution_key:均衡地分发数据到多个Shard中,令查询负载更均衡,查询时直接定位到对应Shard。
如果创建了Primary Key索引(用于数据更新),默认为distribution_key, Distribution_key如果为空,默认是Random,Distribution_key需是Primary Key的子集。
一个好的Distribution Key设计,首先要求用户的数据在Distribution Key上划分比较均匀。
比如用户ID或者是商品宝贝ID,一般情况下Key只有一个,所以它是非常均匀的,是用来作为Distribution Key非常好的例子。但是像年龄或者性别这种就不太适合作为Distribution Key,因为它可能会使大量的数据Shuffle到一个节点上,导致整个数据的分布不是很均匀。
Distribution Key主要的作用是减少关联查询、聚合运算里数据的Shuffle。
如果用户没有设置Distribution Key,那么我们默认是Random,因为我们会保证用户的数据能够尽可能均匀地分布到所有Shard上面。
接下来我们看一下Distribution Key主要的作用。
在Hologres里面我们会有不同的表,放到不同的TableGroup里面,对于Shard数相同的表,都会放到一个TG下面。
假设两个表做关联,如果都按照关联的Key去设计Distribution Key,那么这两个表的关联就可以做一个Local Join,如上图左边所示。所有的数据不需要做额外的Shuffle,每个表在每个Shard上面,做完关联之后直接产生结果。
假如数据量增大,之后可能需要扩容,我们希望在这个TG下面所有表都会进行扩容,这样能保证数据分布的一致性,维持住整个Local Join,而不会因为扩容导致做不了Local Join。
Local Join相比于非Local Join,性能差别非常大,通常会有一个数量级左右的差异。
跟Local Join最相关的就是Distribution Key的设计,如果Distribution key设计不合理时,在Join时,可能引起大量的Data Shuffle,影响效率。
如上图所示,假设表A跟表B要做一个关联,如果不是Distribution Key的场景,那么我们就需要把表A的数据跟B的数据都按照它的Join Key做Shuffle, Shuffle会带来非常高昂的成本,同时影响整个查询的效率。
所以通常情况下,对于需要连接的表,可以把Join关系设为distribution key,实现Table在同一个Shard内Local Join。
(六)优化分区表
分区表:也是物理表,具备一样的Shard能力,但多了一个根据分区键进行Table Pruning的能力。
如上图所示,假设查询的过滤条件只命中了部分的分区,那么剩下的分区表就不需要进行扫描,这能够大大节约整个查询的IO,加快查询速度。
通常情况下,分区的Key是静态的,并且数量不会太多,最适合做分区Key的是日期。例如有的业务方是一天一个分区,或者按小时分区,那么查询的时候也会按照某一段时间来过滤数据。
通过分区表,当用户的查询条件包含时间过滤时,就可以把不必要的分区过滤掉,对查询性能有很大的的提升。
通常将日期列等基数低(小于一万)的字段用于做分区字段,如果分区表过多, 而查询时不带有分区过滤条件,性能会下降。
(七)优化Segment Key
Shard是一个逻辑数据单位,物理上是一组文件(分发到同一个Shard的多个表,以及对应的索引)。
Segment Key主要是作用于列存。
在列存上面,文件是存成一个个Segment,当查询到了某一个Shard上,因为Shard内部有一堆的文件,我们要去找哪些文件会命中这个查询,需要进行扫描,Segment Key是用来跳过不需要查找的文件。
假设Segment设成了一个时间,数据按照时间写入,比如10点到11点是一个文件,11点到12点是一个文件,12点到13点是一个文件。当我们要查询12:15~12:35区间范围的数据,对于这种情况,通过Segment Key就能快速找到12点到13点这个文件命中查询,所以只要打开这一个文件就可以了。通过这种方式就可以快速跳过不必要的文件扫描,减少IO,让整个查询更快。
上图主要是介绍了整个数据的写入流程,帮助大家理解Segment Key到底是什么样的。
刚才提到当数据写入Hologres,会写到内存表里面,内存写满了,异步Flush到文件,Append Only写入,写入效率最高。因为写入时为了性能,没有全局排序和单文件更新,文件之间存在Overlap。
这是什么意思?
Segment_key用于文件块的边界划分,查询时基于Segment_key可以快速定位数据所在文件块, Segment_key多列时,按照左对齐。
如上文提到的例子,11点到12点在一个文件是比较理想的情况,实际情况可能是11点到12点在一个文件,11:30~12:30是在第二个文件里面,12:30 ~13:00又是一个文件,文件之间可能存在重叠。查询可能会命中多个文件,这种场景可能就会导致需要打开多个文件。
所以在设计Segment Key的时候,尽可能不要有Overlap,尽可能顺序地递增。如果数据写入非常无序,比如写进来的数据,先是123,然后678,然后456,这种乱序的写入就会导致Segment Key可能在不同的文件内部有重复的数据,使得Segment Key完全没有起到查询过滤的作用。
因此,设计Segment Key最关键的一点就是尽可能单调,并且没有Overlap,这样才可以让我们能够尽可能跳过这种不必要的数据扫描。
Segment Key的设计主要是用在Blink的实时写入场景,并且把Key设成时间字段,因为它数据实时写入的时间是递增的,并且每个值不会有很大的 Overlap,比较适合用Segment Key。
除此之外,其他的场景不太建议用户自己设Segment Key。
(八)优化ClusteringKey
Clustering_key,文件内聚簇布局,表示排序信息,和MySQL 的聚簇索引不同,Hologres用来布局数据,不是布局索引,因此修改Clustering需要重新数据导入,且只有一个 Clustering_key,排序操作在内存中完成生成SST。
上图为一个例子,上图的左边是一个完全无序的情况,如果按照Date作为ClusteringKey,那么会变成右上角的图。按照Date做完排序之后,当进行Date查询,比如Date大于1/1,小于1/3的数据,可以快速查到对应的时间段。
假设没有做这个Index,我们就需要把所有数据都扫一遍,这就是通过ClusteringKey加速查询的原理。
假设按照Class做排序,如果将Class和Date作为ClusteringKey,那么会先按照Class做排序,然后再按照Date排序,如上图右下方所示。对于这种场景,ClusteringKey的设计是按照最左匹配的原则,就是当遇到用户的查询条件,也按照最左匹配的原则来匹配。
例如,查询的Key是Class,那么能够命中ClusteringKey,如果查询条件是Class跟Date,也能够命中ClusteringKey,但如果查询条件只有Date,则无法命中ClusteringKey。遵循的最左匹配相当于,从左往右的条件中,无论用户的查询条件有几个,最左边的条件必须匹配上才可以。
ClusteringKey主要的作用是能够加速查询的过滤,Range查询的过滤以及点查的过滤。
ClusteringKey的缺点是每个表最多只能有一个ClusteringKey,只能有一种排序方式。
(九)优化字典编码
字典编码对于字符串类型可以有效压缩,特别是基数小的列。编码值可以加快比较操作,对于Group By,Filter有好处,Holo在0.9之后自动设置。
上图为字典编码的一个例子。
如上图左边所示,有Card No和男女性别Gender。因为男女性别只有两个值,所以非常适合于用字典编码,假如把性别编码成0跟1,就变成了图中间的方式。
当进行数据查询的时候,需要对过滤条件的编码,比如想查所有男性的Card No,过滤条件就变成了Gender 0,通过这种方式进行数字查询。
但是字典编码有一个缺点,就是对于基数列比较大的场景,它的开销非常高。
因为我们对数据先进行编码,编码的过程中,假如数据一共是100万行,其中有99万行不一样的值,这会导致我们有99万个Encoded值,这种情况会造成整个编码跟查询的耗损非常高,这种情况就不太适合做字典编码。
在Hologres0.9之后,我们支持自动设置字典编码,用户无需自己去配置字典编码。
(十)优化位图索引
位图索引,对于等值过滤场景有明显的优化效果,多个等值过滤条件,通过向量比较计算。
位图索引相当于把每列的数据通过位图来标识它是否存在。
如上图所示,我们将左边表中学生的性别、班级进行位图编码,就得到了右边的图,通过这些位图信息我们可以进行快速过滤。
例如,我们要查所有男性学生,可以通过“1 0”进行过滤,得到右图中PK值为1、2、5、6这四行符合查询条件的数据。假设要过滤出三班的同学,那么我们再构建一个位图“0 0 1”,再跟班级的数据做一个过滤,就能得到PK值为2和6的信息。
可以看到,位图索引主要的应用场景是在点查,比如查询条件是男性并且年龄等于32岁,这种场景也是非常适合用位图进行查询加速。
同样的,位图索引也有个问题,就是基数过多的列,在位图索引编码时,会形成稀疏数组(列很多,值很少),对查询性能改善影响小。
(十一)物理拓扑
上文阐述了几个索引以及整个存储方式,下面看一下如何区别它们,以及整个用户视角看起来它大概是什么样的抽象。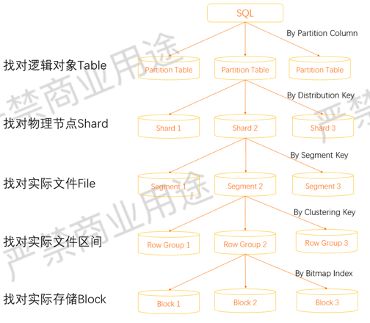
如上所示,用户写了一个SQL之后,首先会按照用户分区键路由到对应要找的表上面,找对逻辑对象Table。
第二步通过Distribution Key找到对应Shard。
第三步是Segment Key,找到Shard之后要找对应Shard上面的文件,因为实际数据是存储成一个个文件,我们通过Segment Key找到想要打开的文件。
第四步是在文件内部,数据是否有序,这是通过Clustering Key来查找的,Clustering Key帮助我们找对实际文件区间。
第五步是Bitmap。因为Hologres把数据按照一个个Batch存储,在一个Batch里面,我们需要通过Bitmap快速定位到某一行,否则需要把某一个区间范围内所有的数据扫一遍。
图中从上往下不同的过程,越来越到文件内部,越往上是越大的范围。
二、Hologres性能问题分析与优化
(一)性能白皮书
用户问得最多的问题是Hologres的性能如何,我们有一个大概的性能估量。
使用Hologres时,实时写入单Core的QPS是5000,对于离线写入的场景,比如Max Computer写入到Hologres,通常情况下单Core的QPS能到5W。对于OLAP查询,单Core处理200万数据量。对于点查场景,单Core QPS在1W左右。
用户可以根据以上信息来评估自己的查询以及业务场景需要用多少资源。
(二)实时写入与点查
对于不同的应用场景,我们优化手段是不太一样。
对于实时写入与点查的场景,首先要检查建表是否合适。对于高QPS写入以及点查来说,我们希望Distribution Key和查询条件一致。因为Distribution Key用来找到对应的Shard,在写入的QPS很高的情况下,假如过滤条件与分布Key一致,我们就可以快速路由到某一个Shard上面,这个查询就不需要发到所有Shard上,对这种场景有很大的性能提升,所以要求Distribution Key和查询条件一致。
第二个是我们的表最好是行存表,因为行存表对实时写入以及点查在性能上非常友好。
第三个场景是假设不是行存表而是列存表,我们希望Pk、Clustering Key和查询条件一致,这样才能用上Clustering Index的能力。
除了建表优化以外,还需要优化查询写入代码。因为如果写Hologres的代码设计得不合理,会带来非常高昂的额外成本。可能用户会发现QPS好像已经上不去了,但其实Hologres内部CPU使用率非常低,这是因为用户自己的写入代码不是特别高效。
对于这样的问题,首先我们希望用户尽可能通过Preparestmt的方式,它主要的好处是能够节约整个执行计划的开销。提交一个SQL之后,一般会把 SQL进行编译解析,然后生成一个执行计划,最后提交到执行引擎来执行这样的一个过程。当数据重复执行SQL的时候,使用Preparestmt就可以不用再去做生成、执行计划、解析的过程,成本大大减少,查询和写入的QPS会更高。
第二点是我们希望用户写入的数据尽可能凑批。比如说我们经常会碰到一些用户,他会先写insert into values1和insert into values2,再写insert into values2和insert into values3,然后不停地发这种小的SQL进行数据插入,这会带来非常高昂的数据RPC成本,同时整个QPS也上不去。
我们通过凑批可以让写入性能会高很多,比如通过insert into values的方式,一个values里面就包含了1000个值或者1万个值,这1万个值的写入只要一次数据传输就可以了。相比于之前的方式,性能上可能存在1万倍的差异。
第三块是整个Holo Client的使用,有的用户可能不太清楚如何优化代码,或者不能凑好批,Holo Client可以帮助用户解决这些问题。
相比于传统的JDBC Client,Holo Client帮用户做了各种各样异步化的封装以及凑批的逻辑,并且它没有SQL引擎的额外开销,不需要进行一些SQL解析的操作,所以它的写入跟查询性能相比于使用JDBC的方式会好非常多。
Holo Client也是Blink Client写入的内置插件,所以它相比用户自己的工具,写入性能会更好。
还有一点是我们连接的时候尽可能使用VPC域名进行数据的写入跟查询。
因为直接用公网的话,网络之间的RT比较高。如果用VPC网络,因为是在同一个网站内,机器之间的RT比较低,能够减少整个网络上面的开销,在很多应用场景下,它的影响非常大,也非常重要。
(二)离线写入与查询常见问题
接下来我们看一下离线写入与查询常见的问题。
为什么把离线写入跟查询放在一起?这是因为离线写入跟查询是一样的原理,离线写入也是通过跑一个Query,跑Query方式的问题都是差不多的。
首先是统计信息缺失。
Hologres本身是一个分布式引擎,它要把用户写的SQL运行在分布式引擎上,因此需要去优化器生成一个执行计划,优化器需要统计信息来帮助它生成一个比较好的执行计划。当遇到用户统计信息缺失,优化器相当于丧失了输入,无法生成执行计划,这是我们在线上遇到最大也是最多的一个问题。
第二个很大的问题是建表不优,当遇到建表跟查询不一致的情况,就会导致整个查询的性能非常差。
除此之外,Hologres是一个自研的引擎,但是为了兼容Postgres的开源生态,所以会有一个联邦查询的机制,使得用户能在Postgres运行的Query也能在Hologres运行,但是它会带来一些额外的性能损失。
(三)查看执行计划
执行计划的好坏对于查询性能影响非常大。Hologres的查询优化器会根据 Cost选择执行耗时最低的查询计划来执行用户的查询,不过难免会出现一些查询计划不优的情况。用户可以通过Explain命令来查询执行计划,执行计划中一般包含以下算子:
1.数据扫描算子:Seq Scan、Table Scan及Index Scan等。
主要是用来进行数据访问,Seq Scan、Table Scan及Index Scan分别对应顺序扫描,表扫描以及基于Index的扫描。
2.连接算子:Hash Join及Nested Loop。
Hash Join的意思是两个表做关联的时候,会先把一个表做成Hash Table,另外一个表通过Hash Table的Lookup进行关联查询。
Nested Loop会把两个表做成两个For循环,在外表就是一个表 For循环遍历所有的数据,另外一个表也是For循环,这就是Hash Join与Nested Loop的区别。
3.聚合算子:Hash Aggregate及Streaming Aggregate。
基于Hash查找的AGG实现及基于排序的AGG实现。
4.数据移动算子:Redistribute Motion、Broadcast Motion及Gather Motion等。
Hologres是一个分布式的引擎,所以难免会碰到数据Shuffle的情况。Redistribute Motion主要是做数据的Shuffle,Broadcast Motion是做数据广播,Gather Motion是把数据拉到一起,这些数据移动算子主要是用来解决分布式数据的问题。
5.其他算子:Hash、Sort、Limit及Append等。
(四)统计信息缺失
我们在看Query性能的时候经常会碰到几个问题,其中一个是统计信息缺失,我们如何知道统计信息是否缺失?

上方是一个explain查询的例子。当Hologres没有统计信息,行数的默认值是1000。这里我们可以看到,当前tmp和tmp1两个表的行数都是1000,表明这两个表目前都拿不到统计信息。
没有统计信息容易出现的问题:
- 跑查询OOM
- 写入性能差
(五)更新统计信息
那么我们怎么解决没有统计信息的问题?
通过Analyze命令,用户可以更新统计信息。

还是之前的例子,通过analyze tmp;和analyze tmp1,可以看到这两个表就有统计信息了,如上方所示。
从上方可以看到,tmp1有1000万行数据,它1000万数据Join 1000行数据,此时我们发现,这个表虽然做了个Hash Join,但它的Join顺序是不对的。因为在这之前tmp的数据量非常小,而temp1数据量非常大,会导致把tmp1放到了Hash Table这一侧,然后Hash Table非常大,导致整个Join性能非常差。
通过Analyze之后,可以把Join的顺序调过来,把小的表tmp放在被Hash这一侧,把大的表tmp1放在关联的那一侧,形成一个比较好的查询计划,查询性能相比之前也有一个比较大的提升。
(六)选择合适的分布列
我们需要选择合适的分布列,也就是本文前面提到的做Local Join的情况。如果用户不设置分布列,在进行关联查询时,Hologres需要将2个表的数据根据join key shuffle到一起,保证数据的正确性。如果shuffle的数据量很大,会造成很高的查询延迟。
我们如何判断有没有做Local Join?
在上方示例中我们可以看到,通过explain查看执行计划,Redistribute Motion表示Shuffle算子,tmp和tmp1两个表在做关联之前都通过Join条件作了Shuffle,这说明整个关联不是一个Local Join。
解决方法是把关联Key设置成Distribution Key。
具体做法是重新建表,关联Key设成a跟b,此时我们再去查看执行计划,就没有Redistribute Motion了,这个关联就是一个Local Join。

通过这种方式就可以让整个关联从非Local Join变成了Local Join,性能相对之前也有一个比较大的改善。
(七)判断是否用上Clustering Key
接下来看一下怎么通过执行计划来看我们之前的那些建表的Index,判断是否用上Clustering Key。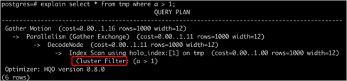
如上方所示,假如我们写了个查询:
explain select * from tmp where a > 1;
假设a字段是个Clustering Key,此时我们在explain查询的执行计划中可以看见有一个Cluster Filter,表示我们已经用上Clustering Key。
(八)判断是否用上Bitmap
接下来我们判断是否用上Bitmap。
如上图所示,我们的查询条件是:
explain select * from tmp where c = 1;
这个c是Bitmap Key,在执行计划可以看到有Bitmap Filter:(c = 1)这样一个过滤条件,此时我们就知道用上Bitmap了。
(九)判断是否用上Segment Key
接下来判断是否用上Segment Key。
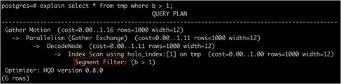
如上图所示,我们的查询条件是:
explain select * from tmp where b > 1;
这个b是Segment Key,我们在执行计划可以看到有Segment Filter:(b > 1)这样一个过滤条件,此时我们就知道用上Segment Key了。
通过以上几个explain查询的例子,我们就能知道查询是否用上之前建表的Index,如果没用上,说明有可能建表不对,或者查询模式并没有很好地适配建表。
(十)联邦查询优化

在Hologres内部有两套计算引擎,其中一套是完全自研的Holo计算引擎,它的性能卓越,但也是因为它是完全自研的,所以相较于开源的Postgres计算引擎,它无法在一开始就支持所有Postgres的功能,会有部分Postgres功能缺失。
另一套计算引擎是Postgres,它是完全开源生态的,性能方面比自研的计算引擎稍差一些,但是它完全兼容Postgres功能。
因此,在Hologres里面,一个查询有可能会既用到Holo计算引擎,也用到Postgres计算引擎。
(十一)优化联邦查询
判断是否使用了联邦查询,我们可以通过explain。
Hologres自研引擎不支持not in,对于查询:
explain select * from tmp where a not in (select a from tmp1);
如下所示:
从执行计划可以看到有External SQL(Postgres):这样的一个算子,这就标识了查询引擎跑到了Postgres引擎上面去执行。
因为Holo计算引擎不支持not in,所以说这部分的计算是在Postgres上面执行的。当看见External SQL(Postgres):这个算子,用户需要警惕当下用到了Holo计算引擎不支持的功能,此时最好通过查询改写,换成Holo支持的算子来执行它的Query,从而提升查询性能。
对于上面这个例子的场景,我们可以通过将not in 改为 not exist:
explain select * from tmp where not exists (select a from tmp1 where a = tmp.a);
当用户这个表一定是非空,那么可以把not in直接改成not exit,之后再查看执行情况,会发现整个Query都是在Holo引擎上面,没看到刚才的External SQL(Postgres)算子。
这个查询生成的执行计划相比之前在Postgres引擎上执行的计划,查询性能上可能会有数倍的差别。
通过上述所有的例子,我们就了解了Hologres性能调优整个过程,以及其中需要注意的关键点,欢迎感兴趣的同学多多关注与使用Hologres。
原文链接
本文为阿里云原创内容,未经允许不得转载。