陈天老师的Rust培训(1)学习笔记
https://tyrchen.github.io/rust-training/






跟C互操作时,加上上面图片的宏,rust会根据你的各个域的内存的占用自动去调整内存中的位置,让你的内存占用是最优的,而且rust在生成数据结构的结构的时候,它会做一些padding,然后这些padding是为了具有更好的performance,但是这样就会对结构体做一些顺序上的调整,以及加一些padding.
函数的话,如果你看rust生成的assembly code的话,所有的函数都被转换为一个奇奇怪怪的名字,所以在rust里面,如果想跟C互操作的话,对于函数需要加上#[no_mangle],不要去做函数的混淆,data struct 需要做一个repr(C)



使用unsafe还有个好处就是,当你的代码有内存泄露或者有concurrency issue的时候,你马上就知道从哪里去着手,去看问题的所在。相对于C、C++的项目出现这样一个问题,可能是大海捞针,得到处去找问题的根源,而这个问题的根源在大型C、C++项目里面是非常难找的。
有了unsafe之后,如果出现上述问题,肯定就是unsafe代码里面。

函数A call 函数B ,会给函数B生成一个新的frame,然后把一些信息填进去,比说函数A的return Address放进去,然后把这些栈帧都保留进去,然后给函数B传的参数push进去,因为编译器在编译期就知道函数B都用了哪些局部变量,这些局部变量的大小是什么,然后为这些局部变量reserve好这个栈。
一个frame一个frame去压栈。最后return的时候,一个frame一个frame的返回。





上图是单线程里面。总是可以的
但是如果是多线程,如下,就可能有问题了

T1 call一个函数,这个函数生成一个新的thread,然后这个thread把ptr move到新的thread下面。当这种情况发生的时候,compiler就没办法区别了。lifetime没有单线程的那么清晰,因为T1随时可能会结束,T1结束的时候,那么T2里面的ptr指向T1之前的那个有效内存,这个时候栈已经走了,栈走了再引用栈上的数据是非常危险的,因为已经不知道数据时什么样子的了。
Sync是把reference在多个线程之间传递,Send是支持值在多个线程间传递,然后它还加了个'static, 'static是 lifetime bound,也就是说这个F闭包里面不能使用任何借用的数据,只能使用你own的数据。
回到上上上个图,inser(&user)这是借用一个数据,上上个图T1把ptr move到T2 ,但是这是一个引用,不是一个own的data,收益在上图spawn的signature下面,编译器是不会让你编译通过的 ,所以就规避了有问题引用的发生。
Rust可以借用栈和堆上的内存,这比其他很多语言要灵活,在写C的时候,一个大忌就是不能引用栈上的内存,引来引去之后就会出错,但rust用了一套很清晰的规则,然后让你可以很安全的借用栈上的内存,借用栈上的内存效率是非常高的,栈上的内存分配和释放都是非常高效的、
但是正因为很多语言没有设置这些限制,就导致最终不得退而求其次去借用堆上的内存,比如java你去引用 只能引用堆上的内存。
pub fn strtok(s: &mut &str, pattern: char) -> &str {
match s.find(pattern) {
Some(i) => {
let prefix = &s[..i];
let suffix = &s[i + pattern.len_utf8()..];
*s = suffix;
prefix
}
None => {
let prefix = *s;
*s = "";
prefix
}
}
}

pub fn strtok<'a>(s: &'a mut &str, pattern: char) -> &'a str {
match s.find(pattern) {
Some(i) => {
let prefix = &s[..i];
let suffix = &s[i + pattern.len_utf8()..];
*s = suffix;
prefix
}
None => {
let prefix = *s;
*s = "";
prefix
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let mut s = "hello world";
assert_eq!(s.find(' '), Some(5));
// let mut s1 = &mut s;这里不是mut本身,而是mut s1指向的str,所以不需要mut
let s1 = &mut s;
let t = strtok(s1, ' ');
assert_eq!(t, "hello");
assert_eq!(*s1, "world");
assert_eq!(s, "world");
}
}

bss section
data secton
text section 就是我们常说的代码段
闭包不一定是static lifetime的
string literals是会被编译到binary里面的string section
编译好,之后内存地址固定。


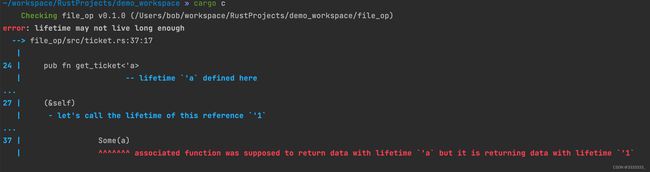
ticket.rs

传值的时候一定是在新生成的栈里面把你要传的数据拷过去,任何语言都是这么去做的。
很多时候传值并不是最大的性能杀手,最大的性能杀手其实是堆上的性能分配,因为往往你在堆上分配内存,你需要往里面拷贝东西,回头你还得释放这块内存,这里就比单纯栈上拷贝花费的更大,而堆上内存的分配,往往又涉及到调用这个操作系统的malloc。
内存布局
Rust Language Cheat Sheet

call 这个代码的时候(let writer:&mut dyn Write = &mut buf;),rust会自动生成trait object,
结构就是
ptr本身指向原来的vec,然后vec自己的ptr/cap/len是分配在栈上的, 具体的数据是ptr指向的heap上的数据。
meta可以理解为vptr,指向vtable,一个virtual table,因为当我生成一个trait object 的时候,原有的type就被抹掉了,再次使用writer的时候,并不知道writer原来的type是什么。原来它的type是个vec,但是在变成一个trait object的时候,已经没有这个信息了,然后我有的信息就是它实现了write这个trait,所以它有所有的trait method,另外,所有datastructure应该都有实现的drop trait,另外还有size alignment等其他信息。
trait object的好处它是一个在runtime生成的这么一个类型,这个类型不存具体的数据结构,那就使得我们很方便的进行动态的分发。
pub trait Formatter {
fn format(&self, input: &mut str) -> bool;
}
struct MarkdownFormatter;
impl Formatter for MarkdownFormatter {
fn format(&self, input: &mut str) -> bool {
todo!()
}
}
struct RustFormatter;
impl Formatter for RustFormatter {
fn format(&self, input: &mut str) -> bool {
todo!()
}
}
struct HtmlFormatter;
impl Formatter for HtmlFormatter {
fn format(&self, input: &mut str) -> bool {
todo!()
}
}
pub fn format(input: &mut str, formatters: Vec>) {
for formatter in formatters {
formatter.format(input);
}
}
上述代码,为什么Vec里面直接包含上述几种类型呢?我们知道在rust下面,一个vec里面包含的数据都是同一种类型,没有任何一种datastructure是Iterable的,它里面的数据类型又是不一样的,唯有把它转成trait object,然后所有类型都统一了,然后就可以去使用,这是rust的动态分发。

上述代码,为什么Vec里面直接包含上述几种类型呢?我们知道在rust下面,一个vec里面包含的数据都是同一种类型,没有任何一种datastructure是Iterable的,它里面的数据类型又是不一样的,唯有把它转成trait object,然后所有类型都统一了,然后就可以去使用,这是rust的动态分发。

use anyhow::Result;
pub trait Encoder {
fn encode(&self) -> Result>;
}
pub struct Event {
id: Id,
data: Data,
}
impl Event
where
Id: Encoder,
Data: Encoder,
{
pub fn new(id: Id, data: Data) -> Self {
Self { id, data }
}
pub fn do_encode(&self) -> Result> {
let mut result = self.id.encode()?;
result.append(&mut self.data.encode()?);
Ok(result)
}
}
impl Encoder for u64 {
fn encode(&self) -> Result> {
Ok(vec![1, 2, 3, 4, 5, 6, 7, 8, 9]) //测试使用
}
}
impl Encoder for String {
fn encode(&self) -> Result> {
Ok(self.as_bytes().to_vec())
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let event = Event::new(1, "hello world".to_string());
let _vec = event.do_encode().unwrap();
}
}
rust在实现泛型的时候跟C++很类似,它会为每种使用到的类型都生成一个版本,这也是rust在编译代码的时候比较慢,
let event = Event::new(1, "hello world".to_string());
let _vec = event.do_encode().unwrap();
let event = Event::new("hello world2".to_string(), "hello world".to_string());
let _vec = event.do_encode().unwrap();上述代码Event就会被编译成两个版本,它的所有函数也会被编程两个版本,来处理不同的类型。这就是支持泛型的语言,一般编译都比较慢,这也是为什么go迟迟不愿意加入泛型,又不影响它引以为豪的编译速度。一旦引入泛型,编译的速度一定会打折扣,这种你生成多个版本,还有一个潜在问题就是,你在release你的binary的时候,你的binary很多被当作一个商业的版本去用,因为一旦编译好,这个组件所有的泛型里面用到的具体的类型会被编译出来,泛型本身不会存在编译的binary里面。所以这东西提交给另外一个公司,公司依赖着你的binary去做coding,它是非常受限的。
到目前为止,像rust,如果要引入别人的库 ,只能通过源码来引入,你使用了泛型的,如果你不用源码的话,基本上是没办法用的。
但是swift就才用了不同的方式,生成一个xxtable。具体的可以自己查看下。




上图,把store shared成N份,这样锁的粒度变小

上图是golang推崇的

上图 async task适用于IO 密集的任务,所以socket处理数据的收发,适合async task
但是你对内存上面的这个data用async data 没多大意义。









上图是因为compare_exchange开销非常大,可能设计到硬件,可能还要锁总线。所以我们做一次之后,发现它返回error,我们不要一直在这句话循环,我们尝试去load这个lock。因为不需要做swap的操作,只是看当前的状态是不是等于true,如果是true,就可以先把thread 挂起,如果等于false,再回到compare_exchange去循环,这样效率会更高的。













它是有一个很轻量的用户态的线程,它有很小的stack,然后在用户态run一堆的scheduler




rust的设置应该受到了JavaScript上面设计的影响,引入状态机。所有语言的sync await 大概类似上面的东西,就是当你把一个异步的操作,在写代码的时候,你的感知是一个同步的操作,才用的方式就是,把这些东西转换成一个个状态机,去处理状态机的变化。
rust的处理是非常优美的async实现,预计未来其他的语言,尤其是新生代的语言,肯定是靠近rust这种实现方法。
从语法的层面就是async和await
从数据类型层面它是有Future,Poll,Waker
首先看 async function ,用async来修饰一个正常的function,这是一个语法糖,它内部实际上是一个返回值为impl Future的方法,这里是u8

一般自引用的类型通过pin来保证结构的类型安全。
poll里面有两个:
1、self: rust的async/await也是在pin这东西标准化后,也就是找到这么个解决办法后,async、await最终才标准化。
2、还有一个就是context,可以认为context里面含有一个waker,这个waker知道是如何把这个future再度唤醒。
然后基本的逻辑就是,这个poll function,rust future是需要不断的poll的,每次call这个poll function,要么取得进展,要么就结束了 这个future就退出了,要么future就处在这个pending的状态,它就返回,被返回到队列里面,等待下次被唤醒又继续能执行。
一个async的function,它的内部其实是有一套复杂的状态机来处理的,基本上每一个await代码的使用,你都可以认为生成一个新的状态
上图红色框,这个enum是非常节省内存的,不管多少个状态,这个enum的大小就是里面最大的那个。
ps:上图左边,是陈天老师,自己为了方便我们简单理解画的。
如上图,一开始的state是init状态,之后很快就切换到AwaitingStep1,当在这个状态的时候,它会去call step1这个future的poll,在poll里面,要么是ready,ready的话就可以把状态机切到AwaitngStep2,如果是pendding的话,就return,然后上图的整个future就先挂起,然后等待下次被唤醒,后面依次循环上述步骤,直到最后做完所有,就return ready
这个虽然内部生成的代码非常冗长,但是这个很冗长的代码,它的效率是非常高的,就是至少你手写的优化过的代码效率不会比这个高 这就是所谓的零成本,如果不用就不会生成,没有额外的cost,使用的话,生成的代码效率也是非常高。
rust的future是怎么run的呢?
分成了reactor和executor,reactor负责把这个future唤醒,executor负责具体执行这个future。
比如说socket,你有一个socket receive 的future,
现在有新的数据来了,
receiver就拿到了,
kernel就通知你这个data好了,
那reactor就把对应的future唤醒,
然后添加到run queue里面。
然后executor就从run queue里面pull出来,然后执行,要么执行完成,这个future就丢弃了,要么是pending,那么这个future就等待下一次被唤醒。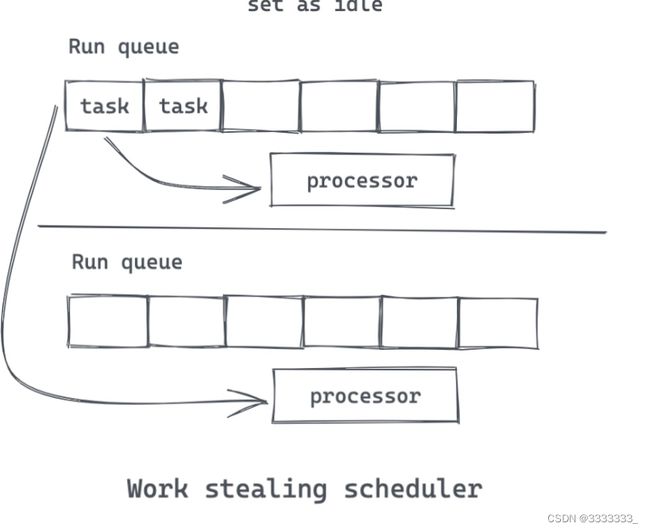
tokio 使用的是work stealing scheduler,它在每个core都有一个scheduler,如果自己的local的run queue没东西了,它就会去别的地方偷,跟golang erlang的方式大同小异,
