Python 异步编程之——线程
上一篇我们讲到,进程是一个相对独立的单元。而线程则是一个进程内单一顺序的控制流,是操作系统运行调度的最小单元。因此,一个进程可以包含多个线程。比如,播放视频时,画面和声音就是不同的线程在处理。
1.创建线程
(1)使用threading.Thread()直接创建
def fun1():
print('任务1开始')
time.sleep(2)
print('任务1结束')
def fun2():
print('任务2开始')
time.sleep(4)
print('任务2结束')
thread1 = threading.Thread(target=fun1)
thread2 = threading.Thread(target=fun2)
# 守护线程,随主线程结束而结束,即不会打印“任务2结束”
thread2.setDaemon(True)
# 启动任务
thread1.start()
thread2.start()
# 主线程会等待本线程完成
thread1.join()
(2)继承Thread
class MyThread(threading.Thread):
# 可以给线程取名字
def __init__(self, name):
super().__init__(name=name)
# 需要实现的核心代码
def run(self):
print("这里写核心功能")
t = MyThread('线程1')
t.start()
t.join()2.线程间通讯
同一个进程下的线程,使用的是同一块内存。因此天然可以进行通信。此外,还可以使用队列。参看第3部分。
# 定义任意类型的全局变量都可以实现线程间通信
lst = []
def fun1():
global lst
lst.append(1)
def fun2():
global lst
dt = lst.pop()
print(dt)
thread1 = threading.Thread(target=fun1)
thread2 = threading.Thread(target=fun2)
thread1.start()
thread2.start()3.数据安全和锁的概念
先直接看一个例子
import threading
def add():
global total
for i in range(1000000):
total += 1
def desc():
global total
for i in range(1000000):
total -= 1
if __name__ == '__main__':
total = 0
thread1 = threading.Thread(target=add)
thread2 = threading.Thread(target=desc)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print(total)(1)数据安全
上面代码表示,有两个任务,分别由两个线程完成,定义了一个全局变量total。add函数可以理解为领工资,余额增加;desc函数可以理解为消费,余额减少。循环相同次数,每次变量值相同。可以想见,最终结果应该是0。可当你执行代码时,你会发现,结果不仅不为0,甚至每次结果都不相同。这样的结果,不仅不是我们想要的,而且是危险的,因为它变得不可控。而要解释这个现象,就需要了解程序是怎么执行的。
我们以为的是这样的:

(2)字节码
但实际却不是如此。因为代码在执行时,会先被编译为字节码,下面展示一个简单函数的字节码
# 定义一个简单函数
def add(a):
a += 1
return a
# 查看编译后的字节码用dis
print(dis.dis(add))
"""
3 0 LOAD_FAST 0 (a)
2 LOAD_CONST 1 (1)
4 INPLACE_ADD
6 STORE_FAST 0 (a)
4 8 LOAD_FAST 0 (a)
10 RETURN_VALUE
None
"""可以看到,一个只包含变量自增功能的函数实际是分步骤完成的。加载变量a—>加载常量1—>执行加法—>保存a。程序在执行时是按照字节码行数和时间片在不同线程之间跳转的。不是我们看到的代码级更不是函数级来切换。因此,实际执行的可能过程示例如下:

关键点就在线程2修改变量这里,线程2在线程1完成修改前就已经加载了变量total,虽然total的值被线程1修改了,但线程2不会再次加载total。因此,最终执行的是0-1=-1。因此,循环次数越大,结果就越不具有确定性。
(3)锁
原理搞清楚了,但问题还没解决。而解决线程数据不安全的方法之一就是引入锁的机制。
从锁的字面含义就已经表明其解决的方式了-通过锁来保护变量。举个生活中的例子,一个变量相当于一个房间,房门有锁。A拿到钥匙,进去了,反锁了门。那么B就只有等着。等A办完事出来,交出钥匙,B拿到钥匙才能进入,B也会把门反锁。具体代码实现如下:
"""使用互斥锁解决数据安全问题"""
import threading
def add():
global total
for i in range(1000000):
# 本线程在访问total这个变量时,其他线程不能访问
lock.acquire()
total += 1
# 释放锁
lock.release()
def desc():
global total
for i in range(1000000):
lock.acquire()
total -= 1
lock.release()
if __name__ == '__main__':
total = 0
lock = threading.Lock()
thread1 = threading.Thread(target=add)
thread2 = threading.Thread(target=desc)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print(total)锁不是万能的,使用锁会带来其他问题,比如死锁。简单讲就是A获得了锁,但A需要B的执行结果。可是B还没有获得锁,无法为A提供结果。最终出现相互等待。此外,同一个线程多次请求同一个资源,也会引起死锁。
(4)使用队列进行通信
上面的方式很基本,为了更方便实现安全的通信,可以使用queue.Queue(内部实现了锁),使用方法和多进程的队列一致。
q = queue.Queue(maxsize=10)
q.put(1)
dt = q.get()
print(dt)4.多线程和多进程
(1)多进程是开启了多个独立的单元,相互之间不影响。是真正的并行,同时进行。但是多进程是有代价的。第一,独立就意味着通信更麻烦;第二,进程与进程的切换是很消耗计算机资源的。
(2)多线程因为是共享内存,因此通信可以很方便。但太方便就意味着可能失控。因此又引入了锁的机制。实际上python自带一个大锁——GIL——全局解释器锁。GIL的存在使得同一个时刻,只有一个线程在一个CPU上执行字节码,且无法将多个线程映射到多个CPU上。实际的执行示意图如下:
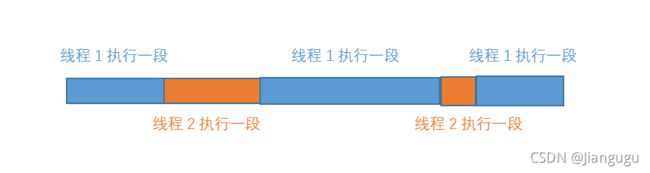
这样看来,多线程似乎是没有意义的。实际上,很多人都评论python的多线程是鸡肋。但,实际上。鸡肋吃起来还是有味道的。
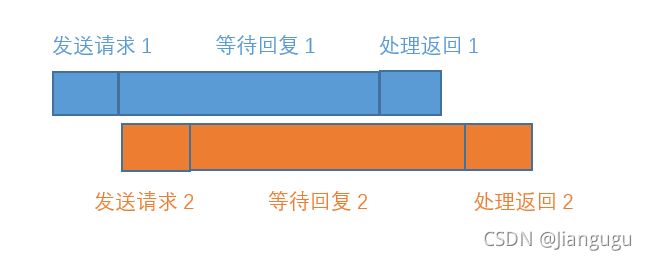
线程1发送请求后,会进入漫长的等待。如果这个时候能切换到线程2,即等待的过程我可以做其他事情。那这样就会比单线程效率更高。
(3)总结
多IO操作的任务使用多线程,多CPU的任务使用多进程。线程的切换代价低于进程,但对于某些任务可能仍然是不可接收的,那是否能在一个线程内完成任务的切换呢?这就是协程的概念了。