PythonWeb开发框架---Flask
1. 创建虚拟环境
1.1 安装virtualenv
pip install virtualenv virtualenvwrapper-win
1.2 查询虚拟环境
workon
1.3 创建虚拟环境
mkvirtualenv flask2env
1.4 删除虚拟环境
rmvirtualenv flask2env
1.5 进入虚拟环境
workon flask2env
创建路径
C:\Users\你的用户名\Envs\flask2env\Scripts\python.exe
2. run启动参数详情
# host: 主机,默认是127.0.0.1,指定为0.0.0.0代表同网段的所有IP都可以访问
# port: 端口号,默认5000
# debug: 是否开启调试模式,开启后,修改代码会自动重启
if __name__ == '__main__':
# 启动服务器
app.run(host=host, port=port, debug=debug)
3. 如何在HTML页面导入本地样式
4. Flask路由参数
| 序号 | 函数 | 含义 | 示例 |
|---|---|---|---|
| 1 | String | 字符串 | 默认 |
| 2 | int | 整形 | |
| 3 | float | 浮点型 | |
| 4 | path | 支持带/的字符串 | |
| 5 | uuid | 随机数 | |
| 6 | any | 自定义类型 |
4.1 String字符串
# String 这两种方式都可以,string:可以默认不写
# @blue.route('/string/')
@blue.route('/string/')
def get_string(username):
print(username, type(username))
return 'hello'
4.2 Int整形
# int
@blue.route('/int/')
def get_id(id):
print(id, type(id))
return str(id)
4.3 Float浮点型
# float
@blue.route('/float/')
def get_float(money):
print(money, type(money))
return str(money)
4.4 Path
# path 支持/的字符串
# 例如:http://127.0.0.1:5000/path/hell/0 ---> 输出:hell/0
@blue.route('/path/')
def get_path(name):
print(name, type(name))
return str(name)
4.5 UUID
# 766b6a13-dc8b-4b72-b893-e7706fe5b769
@blue.route('/uuid/')
def get_uuid(id):
print(id, type(id))
return str(id)
生成UUID
uuid.uuid4()
4.6 any自定义类型
# any 只能传递自己定义的值
# 用于性别等有限数据
@blue.route('/any/')
def get_any(fruit):
print(fruit, type(fruit))
return str(fruit)
5. Flask的请求与响应
- Request请求
| 序号 | 函数 | 含义 | 示例 |
|---|---|---|---|
| 1 | request.method | 获取请求的方式【GET、POST】 | |
| 2 | request.args | 获取GET请求携带的参数 | request.args[‘name’]【采用这种方式,如果参数不存在会报错,尽量不要采用这种方式】 request.args.get(‘name’)【使用这种方式获取参数,如果参数不存在会返回一个None】 |
| 3 | request.form | 获取POST请求携带的参数 | request.form.get(‘name’) |
| 4 | request.cookies | 获取请求携带的cookie | |
| 5 | request.url | 获取请求的URL地址 | http://127.0.0.1:5000/request |
| 6 | request.base_url | 获取请求的URL完整地址 | http://127.0.0.1:5000/request |
| 7 | request.remote_addr | 获取请求的URL地址 | 127.0.0.1 |
| 8 | request.host_url | 获取请求的URL地址+端口号 | http://127.0.0.1:5000/ |
| 9 | request.path | 获取端口后面请求的路由 | /request |
| 10 | request.files | 获取上传的文件 | |
| 11 | request.headers | 获取请求头 | |
| 12 | request.user_agent | 获取用户代理,包括浏览器和操作系统的信息 |
- Response响应的几种方式
| 序号 | 函数 | 含义 | 示例 |
|---|---|---|---|
| 1 | return ‘response ok’ | 直接返回字符串 | |
| 2 | return render_template(‘index.html’, name=‘张三’, age=33) | 前后端不分离-模板渲染 | |
| 3 | return jsonify({‘name’: ‘张三’, ‘age’: 33}) | 前后端分离-将json转化为字符串 |
- 重定向的几种方式
| 序号 | 函数 | 含义 | 示例 |
|---|---|---|---|
| 1 | return redirect(‘https://www.qq.com’) | 跳转别的项目网页 | |
| 2 | return redirect(‘/response’) | 跳转自己项目里面的路由 | |
| 3 | redirect(url_for(‘user.get_request’, name=‘王五’, age=66)) | url_for(‘蓝图名称.视图函数’)----反向解析 |
6. Flask会话技术
| 序号 | 函数 | 含义 | 示例 |
|---|---|---|---|
| 1 | cookie | ||
| 2 | session |
6.1 cookie
cookie本身由游览器保存,通过Response将cookie写到浏览器上,下次访问,浏览器会根据不同的规则携带cookie过来
- 作用:
让服务器能够认识浏览器 - 应用场景:
常用于登录 - 特点:
客户端会话技术、浏览器的会话技术
数据全都是存储在客户端中
存储使用的键值对结构进行存储 - 特性:
支持过期时间
默认会自动携带本网站的所有cookie
根据域名进行cookie存储
不能跨域名
不能跨浏览器
cookie是通过服务器的Response来创建的 - 操作:
| 序号 | 函数 | 含义 | 参数 |
|---|---|---|---|
| 1 | response.set_cookie | 设置cookie | max_age=过期时间,单位是秒 expires=datetime.datetime(2023, 4, 15)过期日期,不能连用 |
| 2 | request.cookies.get(key) | 获取cookie | |
| 2 | request.delete_cookie(key) | 删除cookie |
6.2 Session
服务器端会话技术,依赖于cookie
- 特点:
服务端的会话技术
所有数据存储在服务器中
默认存储在内存中
存储结构也是key-value形势,键值对
session是离不开cookie的
Flask中的Session是全局对象(之前的request也是Flask的一个全局对象) - 操作:
| 序号 | 函数 | 含义 | 参数 |
|---|---|---|---|
| 1 | session[‘key’] = ‘value’ | 设置session | |
| 2 | session.get(key, default=None) | 获取session | |
| 3 | session.pop(key) | 删除session | |
| 4 | session.clear() | 清空session |
6.3 Cookie与Session的区别
- cookie:
在浏览器中存储
安全性比较低
可以减轻服务器的压力 - session:
在服务器存储
安全性高
对服务器要求较高
依赖与cookie
7. 模板Template
模板是呈现给用用户的界面
在MVT中充当T的角色,实现了MT的解耦,开发中VT有这N:M的关系,一个V可以调用任意T,一个T可以被任意V调用
-
模板处理分为两个过程:
1. 加载HTML
2. 模板渲染(模板语言) -
模板代码包含两个部分:
1. 静态HTML
2. 动态插入的代码段(模板语言)
7.1 Jinja2
Flask中使用JinJa2模板引擎,JinJa2由Flask作者开发,一个现代化设计和友好的Python模板语言,模仿Django的模板引擎
- 优点:
速度快,被广泛使用
HTML设计和后端Python分离
减少Python复杂度
非常灵活,快速和安全
提供了控制,继承等高级功能 - 模板语法
1. 变量使用{{ }}接收展示,比如:视图传递给模板的数据,前面定义出来的数据,变量不存在,默认忽略
2. 标签使用{% %}的形式,比如:控制逻辑,使用外部表达式,创建变量,宏
- 结构标签
1 block块:一般情况下是结合继承使用的,单独使用意义不大
父模板挖坑,子模板填坑
{% block xxx %}
{% endblock %}
2 extend继承:
{% extends 'xxx' %}
继承后保留块中的内容
{{ super() }}
3 include:
包含,将其他HTML包含进来
{% include 'xxx' %}
4 marco【了解】
宏定义,可以在模板中定义函数,在其他地方调用
{% macro hello(name) %}
{{ name }}
{% endmarco %}
宏定义可导入
{% from 'xxx' import xxx %}
- 循环
for循环
{% for item in cols %}
AA
{% else %}
BB
{% endfor %}
可以使用和Python一样的for...else
在for循环中可以获取loop信息
| 序号 | 函数 | 含义 | 参数 |
|---|---|---|---|
| 1 | loop.first | 判断是否是第一个元素 | |
| 2 | loop.last | 判断是否是最后一个元素 | |
| 3 | loop.index | 从1开始的下标 | |
| 4 | loop.index0 | 从0开始的下标 | |
| 5 | loop.revindex | 反向下标,不包含0 | |
| 6 | loop.revindex0 | 反向下标,包含0 |
- 过滤器
语法:{{ 变量|过滤器|过滤器... }}
例子:{{ name | capitalize}}
{# 第一个字符大写 #}
其他函数:capitalize、lower、upper、title、trim、reverse、striptags、safe、default(1)、last、first、length、sum、sort
8. Flask项目拆分
参考:flaskPro3项目拆分_blueprints
9. 模型基础
参考:E:\repo\BigData\MyPython\框架\flask\code\flaskPro8模型基础
Flask通过Model操作数据库,不管你数据库的类型是MySQL或者Sqlite,Flask自动帮你生成相应数据库类型的SQL语句,
所以不需要关注SQL语句,对数据的操作Flask帮我们自动完成,只要会写Model就可以了,
Flask使用对象关系映射(ORM)框架去操作数据库
ORM对象关系映射,是一种程序技术,用于实现面向对象变成语言里不同类型系统的数据之间的转换
将对象的操作转化为原生SQL
9.1 安装依赖
ORM
pip install flask-sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simple
数据迁移
pip install flask-migrate==4.0.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
MySQL驱动
pip install pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple
9.2 连接数据库
- SQLite
DR_URI = sqlite:///sqlite3.db
- MySQL
DB_URI = 'mysql+pymysql://{}:{}@{}:{}/{}'.format('root', 'root', 'localhost', 3306, 'flask_db')
9.3 创建模型
模型与表是一一对应的关系
"""
模型,数据库相关的操作
模型 数据库
类 ===> 表
类属性 ===> 字段
一个对象 ===> 表的一行数据
模型发生改变就需要执行一边数据迁移:
直接从第二步生成迁移文件开始,不需要在执行初始化的操作
"""
class User(db.Model):
# 表名
__tablename__ = 'tb_user'
# 字段
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(db.String(30), unique=True, index=True)
age = db.Column(db.Integer, default=1)
sex = db.Column(db.Boolean, default=True)
salary = db.Column(db.Float, default=10000, nullable=False)
- 常用属性
| 序号 | 函数 | 含义 | 参数 |
|---|---|---|---|
| 1 | primary_key=True | 设置主键 | |
| 2 | autoincrement=True | 自增长 | |
| 3 | unique=True | 唯一约束 | |
| 4 | index=True | 为该列创建索引,提升查询效率 | |
| 5 | default=1 | 设置默认值=1 | |
| 6 | nullable=True | 是否允许为空 |
9.4 数据迁移
| 序号 | 函数 | 含义 | 参数 |
|---|---|---|---|
| 1 | flask db init | 创建迁移文件夹migrates,只调用一次 | |
| 2 | flask db migrate | 在migrate/version中生成迁移文件 | |
| 3 | flask db upgrade | 执行迁移文件中的升级 | |
| 4 | flask db downgrade | 执行迁移文件中的降级 |
10. 单表的CRUD操作
10.1 SQLAlchemy常用方法
| 序号 | 函数 | 含义 | 参数 |
|---|---|---|---|
| 1 | filter() | 把过滤器增加到原数据上,返回一个新查询 | |
| 2 | filter_by() | 把等值过滤器增加到原查询上,返回一个新查询 | |
| 3 | limit() | 使用指定的值限制原查询返回的结果数量,返回一个新查询 | |
| 4 | offset() | 偏移原查询返回的结果,返回一个新查询 | |
| 5 | order_by() | 根据指定条件对原查询结果进行排序,返回一个新查询 | |
| 6 | group_by() | 根据指定条件对原查询结果进行分组,返回一个新查询 | |
| 7 | all() | 以列表形式返回查询的所有结果,返回列表 | |
| 8 | first() | 返回查询的第一个结果,如果没有结果,则返回None | |
| 9 | first_or_404() | 返回查询的第一个结果,如果没有结果,则终止请求,返回404错误相应 | |
| 10 | get() | 返回指定主键对应的行,如果没有对应的行,则返回None | |
| 11 | get_or_404() | 返回指定主键对应的行,如果没找到指定的主键,则终止请求,返回404错误响应 | |
| 12 | count() | 返回查询结果的数量 | |
| 13 | paginate() | 返回一个Paginate对象,它包含指定范围内的结果 | |
| 14 | contains | 模糊查询 | |
| 15 | startswith | 以。。开始 | |
| 16 | endswith | 以。。结尾 | |
| 17 | in_ | 枚举 | |
| 18 | __gt__ |
大于 | |
| 19 | __ge__ |
大于等于 | |
| 20 | __lt__ |
小于 | |
| 21 | __le__ |
小于等于 | |
| 22 | and_ | 与 | |
| 23 | or_ | 或 | |
| 24 | not_ | 非 | |
| 25 | db.session.add(u) | 将对象增加到session中 | |
| 26 | db.session.add_all(users) | 将users列表增加到session中【增加一个列表】 | |
| 27 | db.session.delete(u) | 删除数据 | |
| 29 | db.session.commit() | 提交数据(同步到数据库中) | |
| 29 | db.session.rollback() | 数据回滚 | |
| 30 | db.session.flush() | 刷新 |
10.2 CRUD
# 添加数据---一条数据
@blue.route('/useradd')
def user_add():
u = User()
u.name = 'ikun'
u.age = 24
db.session.add(u) # 将u对象增加到session中【增加一个对象】
db.session.commit() # 提交数据(同步到数据库中)
return 'Success'
# 添加数据---多条数据
@blue.route('/useradd_double')
def user_add_double():
users = []
for i in range(10, 30):
u = User()
u.name = '冰冰' + str(i)
u.age = i
users.append(u)
try:
db.session.add_all(users) # 将users列表增加到session中【增加一个列表】
db.session.commit()
except Exception as e:
db.session.rollback() # 数据回滚
db.session.flush() # 刷新
return 'fail:' + str(e)
return 'Success'
# 删除数据
# 找到要查询的数据,然后删除
@blue.route('/userdel')
def user_del():
u = User.query.first() # 查询表中第一条数据
db.session.delete(u) # 删除数据
db.session.commit()
return 'Success'
# 修改数据
# 找到要修改的数据,然后修改
@blue.route('/userupd')
def user_upd():
u = User.query.first() # 查询表中第一条数据
u.age = 1000
db.session.commit()
return 'Success'
@blue.route('/userget')
def user_get():
# users = User.query.all() # 查询所有数据,返回值:列表
# print(users)
# users = User.query.filter(User.age == 20) # filter() 相当于SQL中的where查询条件 返回值:列表
# print(list(users))
# user = User.query.get(8) # get() 根据主键获取值 返回值:对象
# print(user)
# users = User.query.filter_by(age=21) # 只能用于等值操作,不能用作非等值操作
# print(list(users))
# user = User.query.first() # 查询第一条数据
# print(user)
# user = User.query.filter_by(age=100).first_or_404() # 查询第一条数据,如果没有返回404
# print(user)
# users = User.query.filter() # 查询一共多少条数据
# print(users.count())
# offset() 跳过前几条数据
# limit() 前几条数据
# users = User.query.offset(3).limit(4) # 查询一共多少条数据
# print(list(users))
# order_by() 排序
# users = User.query.order_by('age') # 默认升序
# print(list(users))
users = User.query.order_by(desc('age')) # 降序
# print(list(users))
# 逻辑运算 and_,or_,not_【注意:not_需要与and_,or_连用,不能单独使用】
# users = User.query.filter(and_(User.age > 20, User.age < 25)) # and_
# print(list(users))
# users = User.query.filter(or_(User.age > 25, User.age < 20)) # or_
# print(list(users))
# users = User.query.filter(not_(and_(User.age > 20, User.age < 25))) # not_
# print(list(users))
# 查询属性
# users = User.query.filter(User.name.contains('3')) # 模糊查询
# print(list(users))
# users = User.query.filter(User.age.in_([10,20,30,40,50,60])) # in_([])枚举
# print(list(users))
users = User.query.filter(User.name.startswith('冰')) # startswith(str)以...开头
print(list(users))
users = User.query.filter(User.name.endswith('2')) # startswith(str)以...结尾
print(list(users))
# __gt__ 大于
users = User.query.filter(User.age.__gt__(25))
print(list(users))
return 'Success'
10.3 分页
- 常用函数
| 序号 | 函数 | 含义 | 参数 |
|---|---|---|---|
| 1 | p.items | 返回当前页的内容列表 | |
| 2 | p.has_next | 是否还有下一页 返回值:Boolean类型 True有下一页 False没有下一页 | |
| 3 | p.has_prev | 是否还有上一页 返回值:Boolean类型 True有上一页 False没有上一页 | |
| 4 | p.next(error_out=False) | 返回下一页的Pagination对象 | |
| 5 | p.prev(error_out=False) | 返回上一页的Pagination对象 | |
| 6 | p.page | 当前页的页码(从1开始) | |
| 7 | p.pages | 总页数 | |
| 8 | p.per_page | 每页显示的数量 | |
| 9 | p.prev_num | 上一页页码数 使用时需要使用has_prev判断是否有上一页 | |
| 10 | p.next_num | 下一页页码数 使用时需要使用has_next判断是否有下一页 | |
| 11 | p.total | 查询返回的记录总数 |
- 案例
@blue.route('/paginate')
def get_paginate():
# 页码:默认显示第一页
# 获取前端的参数,如果前端没有传递参数,则使用第二个参数,设置的默认值
page = int(request.args.get('page', 1))
# 每一页显示的数量
per_page = int(request.args.get('per_page', 5))
print(page, type(page))
print(per_page, type(per_page))
p = User.query.paginate(page=page, per_page=per_page, error_out=False)
# paginate对象的属性:
# 1. items:返回当前页的内容列表
print(p.items)
# 2. has_next:是否还有下一页 返回值:Boolean类型 True有下一页 False没有下一页
print(p.has_next)
# 3. has_prev:是否还有上一页 返回值:Boolean类型 True有上一页 False没有上一页
print(p.has_prev)
# 4. next(error_out=False):返回下一页的Pagination对象
print(p.next(error_out=False).items)
# 5. prev(error_out=False):返回上一页的Pagination对象
print(p.prev(error_out=False).items)
# 6. page:当前页的页码(从1开始)
print(p.page)
# 7. pages:总页数
print(p.pages)
# 8. per_page:每页显示的数量
print(p.per_page)
# 9. prev_num:上一页页码数 使用时需要使用has_prev判断是否有上一页
print(p.prev_num)
# 10. next_num:下一页页码数 使用时需要使用has_next判断是否有下一页
print(p.next_num)
# 11. total:查询返回的记录总数
print(p.total)
return render_template('paginate.html', p=p)
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>分页功能title>
<link rel="stylesheet" href="{{ url_for('static', filename='css/bootstrap.css') }}">
head>
<body>
<div class="container">
<h2>分页功能h2>
<hr>
<ul class="list-group">
{% for user in p.items %}
<li class="list-group-item">{{ user.name }}li>
{% endfor %}
ul>
<ul class="pagination">
{# 上一页 #}
{% if p.has_prev %}
<li class="page-item">
<a class="page-link" href="/paginate?page={{ p.prev_num }}" aria-label="Previous">
<span aria-hidden="true">«span>
a>
li>
{% endif %}
{% for i in range(p.pages) %}
{% if p.page == i + 1 %}
<li class="page-item active">
{% else %}
<li class="page-item">
{% endif %}
<a class="page-link" href="/paginate?page={{ i + 1 }}">{{ i + 1 }}a>li>
{% endfor %}
{# 下一页 #}
{% if p.has_next %}
<li class="page-item">
<a class="page-link" href="/paginate?page={{ p.next_num }}" aria-label="Next">
<span aria-hidden="true">»span>
a>
li>
{% endif %}
ul>
div>
body>
html>
11.多表的CRUD操作
多表操作分为一对多、多对多两种
11.1 一对多
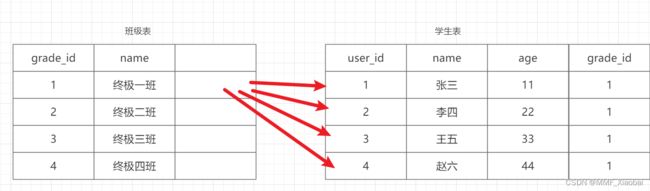
一个班级对应多个学生
class Grade(db.Model):
# 表名
__tablename__ = 'grade'
# 字段
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(db.String(30), unique=True, index=True)
# 建立关联:一对多
# 第一个参数:关联的模型名,如果模型名在下面,需要使用引号引起来
# 第二个参数:反向引用的名称,grade对象,让student去反过来得到grade对象的名称
# 第三个参数:懒加载,只有调用的时候才会生成
# 注意:这里的students不是字段,只是一个类属性
students = db.relationship('Student', backref='grade', lazy=True)
# 学生表
class Student(db.Model):
__tablename__ = 'student'
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(db.String(30), unique=True, index=True)
age = db.Column(db.Integer)
# 外键:跟Grade表中的ID字段关联
gradeid = db.Column(db.Integer, db.ForeignKey(Grade.id))
11.2 多对多
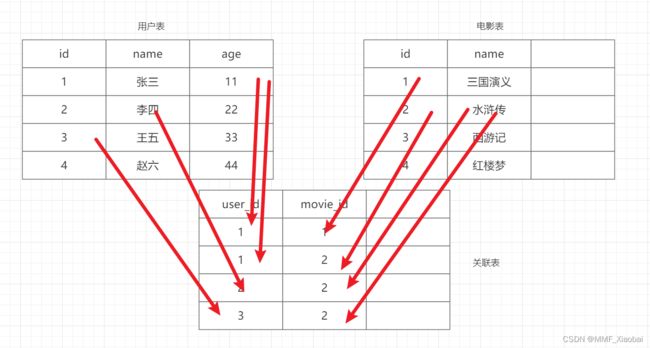
一个用户对应多部电影,并且一部电影对应多名用户,这就需要使用中间表进行构建
# 中间表:收藏表
# 第一个参数,中间表的表名
# 其余参数为外键
# 第一个参数:外键的名称
# 第二个参数:外键的类型
# 第三个参数:与其他表的哪一列关联,注意:这里模型名需要小写,并且点出属性,使用引号括起来
collect = db.Table(
'collects',
# 注意,这里的用户表要小写
db.Column('user_id', db.Integer, db.ForeignKey('usermodel.id'), primary_key=True),
db.Column('movie_id', db.Integer, db.ForeignKey('movie.id'), primary_key=True)
)
# 用户表
class UserModel(db.Model):
__tablename__ = 'usermodel'
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(db.String(30))
age = db.Column(db.Integer)
# 电影表
class Movie(db.Model):
__tablename__ = 'movie'
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(db.String(30))
# 关联
# secondary=collect 设置中间表
users = db.relationship('UserModel', backref='movies', lazy='dynamic', secondary=collect)
11.3 总结
一对多关系
需要在多的一方创建外键
# 注意:这里的外键类型需要与关联字段一致
gradeid = db.Column(db.Integer, db.ForeignKey(Grade.id))
并且在一的一方创建关联关系
# 建立关联:一对多
# 第一个参数:关联的模型名,如果模型名在下面,需要使用引号引起来
# 第二个参数:反向引用的名称,grade对象,让student去反过来得到grade对象的名称
# 第三个参数:懒加载,只有调用的时候才会生成
# 注意:这里的students不是字段,只是一个类属性
students = db.relationship('Student', backref='grade', lazy=True)
多对多关系
需要在任意多的一方创建与中间表的关联关系
# 第一个参数:用户表的模型名
# 第二个参数:反向引用的名称,用户表调用电影表时使用
# 第三个参数:懒加载,返回一个query对象(查询集),可以继续使用其他查询方法
# 第四个参数:中间表的模型名
users = db.relationship('UserModel', backref='movies', lazy='dynamic', secondary=collect)
12.作业:图书馆项目
参考:E:\repo\BigData\MyPython\框架\flask\code\flaskPro12图书馆项目
13.在Flask中如何一次性下载多个包
1 第一步:在项目的跟目录创建一个requirements.txt的文本文件
2 第二步:将需要下载的包名写入
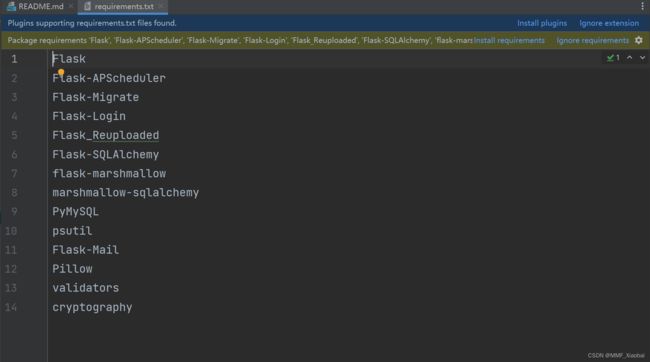
3 第三步:CMD到项目路径执行以下命令
pip install -r requirements.txt