初识Scrapy:Python中的网页抓取神器
Scrapy是一个基于Python的快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。它广泛应用于数据挖掘、监测和自动化测试等领域。Scrapy的强大之处在于它是一个框架,可以根据实际需求进行修改和扩展。
Scrapy的主要特点
- 高速抓取:Scrapy使用异步网络库来处理并发请求,使得它能够高效地抓取web页面,并快速提取所需数据。
- 定制性强:Scrapy提供了丰富的接口和中间件,允许用户根据需求定制爬虫的各个组件,如请求处理、数据提取、存储等。例如Selenium中间件,借助Redis分布式爬取,使用Pipeline的机制来实现将数据推送到Kafka等.
- 数据提取:Scrapy内置了强大的选择器(Selector),可以方便地解析HTML、XML等格式的页面,提取出结构化的数据。
- 多线程支持:Scrapy支持多线程并发处理请求,能够快速地爬取大量网页。
- 错误处理:Scrapy提供了完善的错误处理机制,可以帮助用户快速定位和处理爬虫程序中的问题。
- 自动重试:Scrapy能够自动重试失败的请求,提高爬虫程序的稳定性。
- 支持各种数据库:Scrapy可以将提取的数据存储到各种数据库中,如MySQL、MongoDB等。
好了,说了这么多scrapy的优点那接下来就介绍一下它的几个核心组件.
Scrapy的五大核心组件及其工作流程:
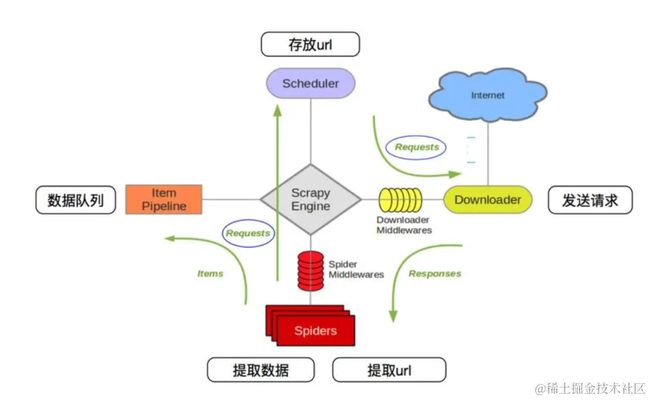
- 引擎(Scrapy Engine):这是整个系统的核心,负责处理数据流,并触发事务。它主要负责接收并处理由调度器发过来的请求,以及调度爬虫、下载器和项目管道的工作。
- 调度器(Scheduler):这个组件主要用来接受引擎发过来的请求。它由过滤器过滤重复的url并将其压入队列中,在引擎再次请求的时候返回。可以想象成一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是什么。
- 下载器(Downloader):这个组件用于下载网页内容,并将网页内容返回给爬虫。Scrapy下载器是建立在twisted这个高效的异步模型上的。
- 爬虫(Spiders):爬虫是主要干活的,它可以生成url,并从特定的url中提取自己需要的信息,即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
- 项目管道(Pipeline):这个组件负责处理爬虫从网页中抽取的实体。主要的功能是持久化存储,例如将提取的数据存储到数据库或进行进一步的数据清洗等。
这些组件通过Scrapy的架构协同工作。当引擎接收到一个请求时,它会调度给调度器进行处理。调度器会查看URL是否已经存在于队列中,如果不存在,它就会添加到队列中并返回给引擎。然后引擎会再次请求下载器来下载这个URL对应的网页内容,下载器会将网页内容返回给爬虫进行处理。爬虫会从网页中提取出所需的信息,并将这些信息封装成Item对象,然后通过项目管道进行进一步的处理和存储。
以上就是Scrapy的五大核心组件及其工作流程。这些组件相互协作,使得Scrapy能够高效地完成网页抓取和数据提取的任务。
而除了这五大组件外还有Middleware中间件也是非常重要的,例如有些网站需要动态获取一些信息,我们可以通过编写自定义的Selenium中间件来执行操作.然后将获取到数据组装成response对象返还给对应的spiders爬虫,以供它去提取解析信息.
如何使用Scrapy
使用Scrapy来创建一个爬虫程序非常简单。首先需要安装Scrapy框架,可以通过pip命令进行安装:
pip install scrapy
接下来,可以按照以下步骤创建一个简单的爬虫程序:
- 创建一个新的Scrapy项目:
scrapy startproject myproject
- 创建一个爬虫类:
scrapy genspider myspider cnblogs.com
- 在爬虫类中定义要爬取的URL和数据提取规则:
class Myspider(scrapy.Spider):
name = 'myspider'
allowed_domains = ['cnblogs.com']
start_urls = ['http://www.cnblogs.com/']
def parse(self, response):
# 在这里定义数据提取规则,使用选择器(Selector)提取所需数据
# ...
- 运行爬虫程序:
scrapy crawl myspider
以上就是使用Scrapy创建爬虫程序的基本步骤。需要注意的是,Scrapy要求爬虫程序必须按照一定的规范来编写,比如必须定义name、allowed_domains和start_urls等变量,以及实现parse方法来处理页面数据。这使得Scrapy具有很强的可读性和可维护性。
接下来我们要介绍一下Scrapy爬虫中的钩子函数,以供加深大家对它的生命周期的了解。
Scrapy爬虫中的钩子函数
Scrapy爬虫中的钩子函数(Hook Functions)是在爬虫的生命周期中触发的特定事件时执行的函数。以下是一些常见的Scrapy爬虫钩子函数以及它们的用途:
- start_requests(self) : 用于生成初始的请求对象。
def start_requests(self):
# 返回初始请求对象
yield scrapy.Request(url='https://example.com', callback=self.parse)
- parse(self, response) : 用于处理响应数据并提取信息。
def parse(self, response):
# 在这里提取信息
title = response.css('h1::text').extract_first()
yield {'title': title}
- parse_item(self, response) : 用于处理提取的数据并生成爬取的数据项。
def parse_item(self, response):
item = MyItem()
item['title'] = response.css('h1::text').extract_first()
yield item
- closed(self, reason) : 在爬虫关闭时执行的函数。
def closed(self, reason):
# 执行一些清理工作
pass
- process_request(self, request) : 用于在发送请求之前进行预处理。
def process_request(self, request):
# 修改请求头或URL等
request.headers['User-Agent'] = 'Custom User-Agent'
- process_response(self, response) : 用于在接收响应后进行处理。
def process_response(self, response):
# 对响应进行处理,如重试或过滤
return response
- process_item(self, item, spider) : 用于在生成数据项后进行处理。
def process_item(self, item, spider):
# 对数据项进行后处理,如存储到数据库
return item
这些钩子函数可以在Scrapy爬虫中根据需要覆盖和定制,以实现特定的爬虫行为。
下面是一个爬虫示例:
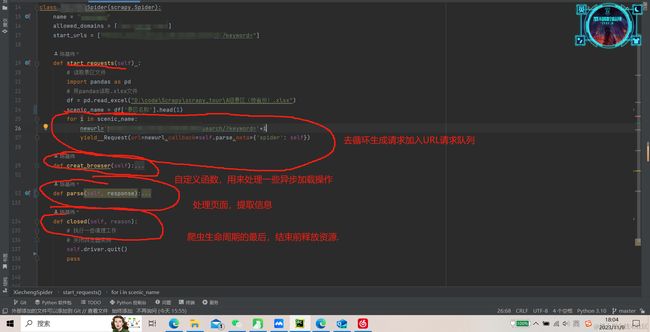
如上图所示是一个旅游爬虫的示例,该爬虫通过搜索页面来获取详细页面的URL,再由爬虫进行解析以及模拟点击操作来获取动态数据再次解析.最后清除浏览器实例,释放资源.
Scrapy的应用场景
Scrapy被广泛应用于各种web抓取和数据挖掘任务中。例如,可以用来抓取电商网站上的商品信息、价格、评论等数据,分析竞争对手的销售情况;可以用来抓取新闻网站上的新闻文章、评论等数据,进行舆情分析和新闻聚合;还可以用来抓取社交媒体网站上的用户数据,进行用户行为分析和社交网络分析等。总之scrapy收集的数据经过清洗,预处理和挖掘后将会产生出新的价值.
希望大家读完本篇文章后能对scrapy爬虫框架有一个较为清晰的认识,如果内容对您有帮助,请一键三连(づ ̄3 ̄)づ╭❤~.