YOLOv8网络结构+代码
YOLOv8网络结构+代码
- 0.yolov8概述
- 1.网络结构解析
- 2.yolo实操
-
- 2.1 引言
- 2.2 代码下载
- 2.3 环境准备
-
- 2.3.1 anaconda创建新环境
- 2.3.2 安装依赖
- 2.3.3 安装ultralytics
- 2.3.4 手动下载权重
- 2.4 测试运行
- 2.5. 训练自己的数据集
-
- 2.5.1 数据准备
- 2.5.2 标签格式转换
- 2.5.3 按比例划分
- 2.5.4 xml_to_yolo
- 2.5.5 修改数据加载配置文件
- 2.6 模型训练/验证/预测/导出
-
- 2.6.1 模型训练
- 2.6.2 模型验证
- 2.6.3 模型预测
- 2.6.4 模型导出
0.yolov8概述
yolov8算法核心改动总结如下:
- Backbone:使用的依旧是CSP的思想,不过将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数。同时YOLOv8依旧使用了YOLOv5等架构中使用的SPPF模块;
- PAN-FPN:YOLOv8依旧使用了PAN的思想,不过通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8将YOLOv5中PAN-FPN上采样阶段中的CBS 1*1的卷积结构删除了,同时也将C3模块替换为了C2f模块;
- Decoupled-Head:YOLOv8使用了Decoupled-Head;即通过两个头分别输出cls与reg的输出;
- Anchor-Free:YOLOv8抛弃了以往的Anchor-Base,使用了Anchor-Free的思想;
- Loss:YOLOv8使用VFL Loss作为分类损失(实际训练中并未使用),使用DFL Loss+CIOU Loss作为分类损失;
- label assignmet:YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner匹配方式;
- Train:训练的数据增强部分引入了 YOLOX 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度。

1.网络结构解析
卷积神经网络
在ultralytics/nn/modules.py文件中定义了yolov8网络中的卷积神经单元。
autopad
- 功能: 返回pad的大小,使得padding后输出张量的大小不变。
- 参数:
k: 卷积核(kernel)的大小。类型可能是一个int也可能是一个序列。p: 填充(padding)的大小。默认为None。d: 扩张率(dilation rate)的大小, 默认为1。普通卷积的扩张率为1,空洞卷积的扩张率大于1。
假设k为原始卷积核大小,d为卷积扩张率(dilation rate),加入空洞之后的实际卷积核尺寸与原始卷积核尺寸之间的关系:k =d(k-1)+1。
通常,如果我们添加ph行填充(大约一半在顶部,一半在底部)和pw列填充(大约一半在左侧,一半在右侧),则输出的形状为( nh − kh + ph + 1 ) × ( nw − kw + pw + 1 )
当设置ph = kh − 1和pw = kw − 1时,输入和输出具有相同的高度和宽度。
假设p为填充(padding)的大小(通常,ph = pw = p/2)。一般来说kh = kw = k,且为奇数。
则当p=k//2时,padding后输出张量的大小不变。
def autopad(k, p=None, d=1): # kernel(卷积核), padding(填充), dilation(扩张)
# 返回pad的大小,使得padding后输出张量的shape不变
if d > 1: # 如果采用扩张卷积,则计算扩张后实际的kernel大小
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] #
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # 自动pad
return p
Conv
- 功能: 标准的卷积。
- 参数:输入通道数(
c1), 输出通道数(c2), 卷积核大小(k,默认是1), 步长(s,默认是1), 填充(p,默认为None), 组(g, 默认为1), 扩张率(d,默认为1), 是否采用激活函数(act,默认为True, 且采用SiLU为激活函数)。

class Conv(nn.Module):
# 标准的卷积 参数(输入通道数, 输出通道数, 卷积核大小, 步长, 填充, 组, 扩张, 激活函数)
default_act = nn.SiLU() # 默认的激活函数
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False) # 2维卷积,其中采用了自动填充函数。
self.bn = nn.BatchNorm2d(c2) # 使得每一个batch的特征图均满足均值为0,方差为1的分布规律
# 如果act=True 则采用默认的激活函数SiLU;如果act的类型是nn.Module,则采用传入的act; 否则不采取任何动作 (nn.Identity函数相当于f(x)=x,只用做占位,返回原始的输入)。
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x): # 前向传播
return self.act(self.bn(self.conv(x))) # 采用BatchNorm
def forward_fuse(self, x): # 用于Model类的fuse函数融合 Conv + BN 加速推理,一般用于测试/验证阶段
return self.act(self.conv(x)) # 不采用BatchNorm
DWConv
深度可分离卷积,继承自Conv。
g=math.gcd(c1, c2) 分组数是输入通道(c1)和输出通道(c2)的最大公约数。(因为分组卷积时,分组数需要能够整除输入通道和输出通道)。
class DWConv(Conv):
# 深度可分离卷积
def __init__(self, c1, c2, k=1, s=1, d=1, act=True): # ch_in, ch_out, kernel, stride, dilation, activation
super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)
DWConvTranspose2d
带有深度分离的转置卷积,继承自nn.ConvTranspose2d。
groups=math.gcd(c1, c2) 分组数是输入通道(c1)和输出通道(c2)的最大公约数。(因为分组卷积时,分组数需要能够整除输入通道和输出通道)。
class DWConvTranspose2d(nn.ConvTranspose2d):
# Depth-wise transpose convolution
def __init__(self, c1, c2, k=1, s=1, p1=0, p2=0): # 输入通道, 输出通道, 卷积核大小, 步长, padding, padding_out
super().__init__(c1, c2, k, s, p1, p2, groups=math.gcd(c1, c2))
ConvTranspose
和Conv类似,只是把Conv2d换成了ConvTranspose2d。
class ConvTranspose(nn.Module):
# Convolution transpose 2d layer
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=2, s=2, p=0, bn=True, act=True):
super().__init__()
self.conv_transpose = nn.ConvTranspose2d(c1, c2, k, s, p, bias=not bn)
self.bn = nn.BatchNorm2d(c2) if bn else nn.Identity()
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv_transpose(x)))
DFL(Distribution Focal Loss)
[https://ieeexplore.ieee.org/document/9792391]提出了GFL(了Generalized Focal Loss)。GFL具体又包括Quality Focal Loss(QFL)和Distribution Focal Loss(DFL),其中QFL用于优化分类和质量估计联合分支,DFL用于优化边框分支。
class DFL(nn.Module):
# Integral module of Distribution Focal Loss (DFL) proposed in Generalized Focal Loss
def __init__(self, c1=16):
super().__init__()
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
x = torch.arange(c1, dtype=torch.float)
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))
self.c1 = c1
def forward(self, x):
b, c, a = x.shape # batch, channels, anchors
return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
# return self.conv(x.view(b, self.c1, 4, a).softmax(1)).view(b, 4, a)
TransformerLayer
关于Transformer的理解和torch.nn.MultiheadAttention 的用法,请参考博客《详解注意力机制和Transformer》
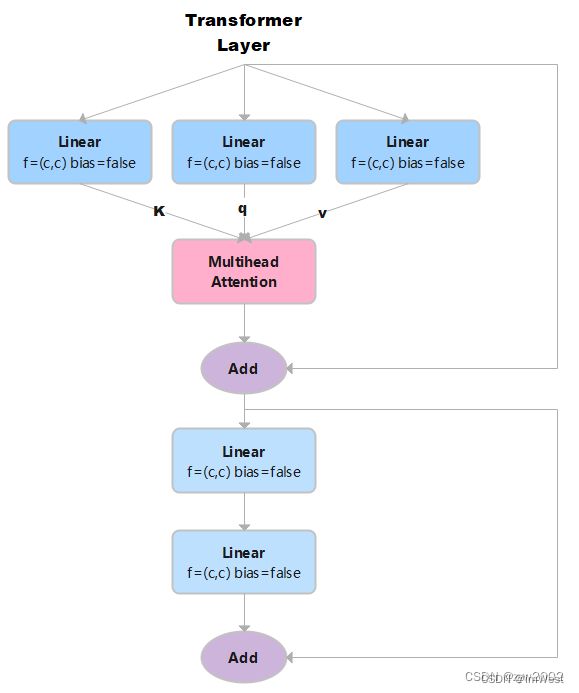
class TransformerLayer(nn.Module):
# Transformer layer (LayerNorm layers removed for better performance)
def __init__(self, c, num_heads): # c: 词特征向量的大小 num_heads 检测头的个数。
super().__init__()
self.q = nn.Linear(c, c, bias=False)# 计算query, in_features=out_features=c
self.k = nn.Linear(c, c, bias=False)# 计算key
self.v = nn.Linear(c, c, bias=False)# 计算value
self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads) # 多头注意力机制
self.fc1 = nn.Linear(c, c, bias=False)
self.fc2 = nn.Linear(c, c, bias=False)
def forward(self, x):
x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x # 多头注意力机制+残差连接
x = self.fc2(self.fc1(x)) + x # 两个全连接层+ 残差连接
return x
如果输入是x,x的大小是(s,n,c) 。 其中n是batch size, s是源序列长度,c是词特征向量的大小(embed_dim)。
然后x分别通过3个Linear层 (线性层的结构相同,但是可学习参数不同)计算得到键k、查询q、值v。因为线性层的输入特征数和输出特征数均等于c, 所以k,q,v的大小也是(s,n,c)。
接着,把k、q、v作为参数输入到多头注意力ma中,返回两个结果attn_output(注意力机制的输出)和attn_output_weights(注意力机制的权重)。在这里,我们只需要注意力机制的输出就可以,因此,我们取索引self.ma(self.q(x), self.k(x), self.v(x))[0],它的大小是(s,n,c)。+x 表示残差连接,不改变x的形状。
self.fc2(self.fc1(x)) 表示经过两个全连接层,输出大小是(s,n,c)。+x 表示残差连接,不改变x的形状。因此最终输出的形状大小和输入的形状一样。
Transformer Block
TransformerBlock是把若干个TransformerLayer串联起来。
对于图像数据而言,输入数据形状是 [batch, channel, height, width],变换成 [height × width, batch, channel]。height × width把图像中各个像素点看作一个单词,其对应通道的信息连在一起就是词向量。channel就是词向量的长度。

TransformerBlock实现代码如下:
class TransformerBlock(nn.Module):
def __init__(self, c1, c2, num_heads, num_layers):
super().__init__()
self.conv = None
if c1 != c2:
self.conv = Conv(c1, c2)
self.linear = nn.Linear(c2, c2) # learnable position embedding
self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))
self.c2 = c2
def forward(self, x): # x:(b,c1,w0,h0)
if self.conv is not None:
x = self.conv(x) # x:(b,c2,w,h)
b, _, w, h = x.shape
p = x.flatten(2).permute(2, 0, 1) # flatten后:(b,c2,w*h) p: (w*h,b,c2)
# linear后: (w*h,b,c2) tr后: (w*h,b,c2) permute后: (b,c2,w*h) reshape后:(b,c2,w,h)
return self.tr(p + self.linear(p)).permute(1, 2, 0).reshape(b, self.c2, w, h)
1)输入的x大小为(b,c1,w,h)。其中b为batch size,c1是输入通道数大小,w和h分别表示图像的宽和高。
2)经过Conv层:Conv层中的2d卷积,卷积核大小是1x1,步长为1,无填充,扩张率为1。因此不改变w和h,只改变输出通道数,形状变为(b,c2,w,h)。Conv层中的BN和SiLU不改变形状大小。输出的x大小为(b,c2,w,h)。
3)对x进行变换得到p:x.flatten(2)后,大小变为 (b,c2,w*h) ;permute(2, 0, 1)后,p的大小为(w*h,b,c2)。
4)将p输入到线性层后,因为线性层的输入特征数和输出特征数相等,因此输出的大小为(w*h,b,c2)。+p进行残差连接后,大小不变,仍为(w*h,b,c2)。
5)然后将上一步的结果输入到num_layers个TransformerLayer中。w*h相当于序列长度,b是批量的大小,c2相当于词嵌入特征长度。每个TransformerLayer的输入和输出的大小不变。经过若干个TransformerLayer后,大小是(w*h,b,c2)。
6)permute(1, 2, 0)后:形状变为(b,c2,w*h) ;reshape(b, self.c2, w, h)后:(b,c2,w,h)。
Bottleneck
先试用3×3卷积降维,剔除冗余信息;再使用3×3卷积升维。

class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1) # 输入通道: c1, 输出通道:c_ , 卷积核:3x3, 步长1
self.cv2 = Conv(c_, c2, k[1], 1, g=g) # 输入通道:c_ , 输出通道c2, 卷积核:3x3, 步长1
self.add = shortcut and c1 == c2 # 当传入的shortcut参数为true,且c1和c2相等时,则使用残差连接。
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
第一层卷积,输入通道: c1,输出通道:c_,卷积核:3x3,步长1。
第二层卷积,输入通道: c_,输出通道:c2,卷积核:3x3,步长1。
其中c _ = c 2 2 c_=\frac{c_2}{2}c_= 2c 2。当c1和c2相等时,采用残差连接。
BottleneckCSP

class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
# 输出x的大小是(b,c1,w,h)
self.cv1 = Conv(c1, c_, 1, 1) # cv1的大小为(b,c_,w,h)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False) # cv2的大小为(b,c_,w,h)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False) # m通过Conv2d,变成cv3,大小是(b,c_,w,h)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.SiLU()
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
# cv1通过n个串联的bottleneck,变成m,大小为(b,c_,w,h)
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x))) # (b,c_,w,h)
y2 = self.cv2(x) # (b,c_,w,h)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), 1))))
# cat后:(b,2*c_,w,h) 返回cv4: (b,c2,w,h)
1)输出x的大小是(b,c1,w,h),然后有两条计算路径分别计算得到y1和y2。
y1的计算路径:先x通过cv1,大小变成(b,c_,w,h) 。cv1通过n个串联的bottleneck,变成m,大小为(b,c_,w,h)。m通过cv3,得到y1,大小是(b,c_,w,h)。
y2的计算路径:x通过cv2得到y2,大小是(b,c_,w,h)。
2)y1和y2在dim=1处连接,大小是(b,2*c_,w,h), 然后再通过BN和SiLU,大小不变。
3)最终,通过cv4,返回结果的大小是(b,c2,w,h)。
C3
与 BottleneckCSP 类似,但少了 1 个 Conv、1 个 BN、1 个 Act,运算量更少。总共只有3次卷积(cv1, cv2, cv3)。

class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
C2
C2只有两个卷积(cv1, cv2)的CSP Bottleneck。

class C2(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
# 假设输入的x大小是(b,c1,w,h)
self.c = int(c2 * e) # hidden channels e=0.5,对输出通道进行平分。
self.cv1 = Conv(c1, 2 * self.c, 1, 1) # cv1的大小是(b,c2,w,h)
self.cv2 = Conv(2 * self.c, c2, 1) # optional act=FReLU(c2)
# self.attention = ChannelAttention(2 * self.c) # or SpatialAttention() #此处可以使用空间注意力或者跨通道的注意力机制。
self.m = nn.Sequential(*(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))) # a通过n个串联的Bottleneck后的到m,m的大小是(b,c,w,h)
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), 1)# 对cv进行在维度1进行平分,a和b的大小都是(b,c,w,h)
return self.cv2(torch.cat((self.m(a), b), 1)) # 把m和b在维度1进行cat后,大小是(b,c2,w,h)。最终通过cv2,大小是(b,c2,w,h)
1)输出x的大小是(b,c1,w,h), 通过Conv层,得到cv1,cv1的大小是(b,c2,w,h)。
2)然后再dim=1的维度上对cv1进行分割,a和b的大小都是(b,c2/2,w,h)。
3)a通过n个串联的Bottleneck后的到m,m的大小是(b,c,w,h)。
4)把m和b在维度1进行cat后,大小是(b,c2,w,h)。最终m通过cv2,输出的大小是(b,c2,w,h)。
C2f
C2f与C2相比,每个Bottleneck的输出都会被Concat到一起。

class C2f(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
# 假设输入的x大小是(b,c1,w,h)
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1) # cv1的大小是(b,c2,w,h)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n)) # n个Bottleneck组成的ModuleList,可以把m看做是一个可迭代对象
def forward(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
# cv1的大小是(b,c2,w,h),对cv1在维度1等分成两份(假设分别是a和b),a和b的大小均是(b,c2/2,w,h)。此时y=[a,b]。
y.extend(m(y[-1]) for m in self.m)
# 然后对列表y中的最后一个张量b输入到ModuleList中的第1个bottleneck里,得到c,c的大小是(b,c2/2,w,h)。然后把c也加入y中。此时y=[a,b,c]
# 重复上述操作n次(因为是n个bottleneck),最终得到的y列表中一共有n+2个元素。
return self.cv2(torch.cat(y, 1))
# 对列表y中的张量在维度1进行连接,得到的张量大小是(b,(n+2)*c2/2,w,h)。
# 最终通过cv2,输出张量的大小是(b,c2,w,h)
1)cv1的大小是(b,c2,w,h),对cv1在维度1等分成两份(假设分别是a和b),a和b的大小均是(b,c2/2,w,h)。此时y=[a,b]。
2)然后对列表y中的最后一个张量b输入到ModuleList中的第1个Bottleneck里,得到c,c的大小是(b,c2/2,w,h)。然后把c也加入y中。此时y=[a,b,c]。
3)上述步骤重复上述操作n次(因为是n个Bottleneck),最终得到的y列表中一共有n+2个元素。
4)对列表y中的张量在维度1进行连接,得到的张量大小是(b,(n+2)*c2/2,w,h)。
5)最终通过cv2,输出张量的大小是(b,c2,w,h)。
ChannelAttention
通道注意力模型: 通道维度不变,压缩空间维度。该模块关注输入图片中有意义的信息。
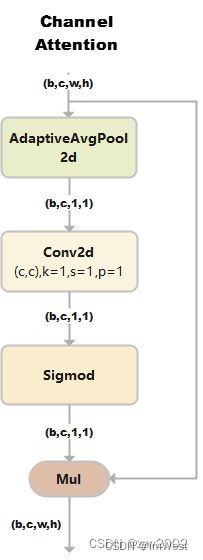
class ChannelAttention(nn.Module):
# Channel-attention module https://github.com/open-mmlab/mmdetection/tree/v3.0.0rc1/configs/rtmdet
def __init__(self, channels: int) -> None:
super().__init__()
self.pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化后,大小为(b,c,1,1)
self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)
self.act = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
return x * self.act(self.fc(self.pool(x)))
1)假设输入的数据大小是(b,c,w,h)。
2)通过自适应平均池化使得输出的大小变为(b,c,1,1)。
3)通过2d卷积和sigmod激活函数后,大小是(b,c,1,1)。
4)将上一步输出的结果和输入的数据相乘,输出数据大小是(b,c,w,h)。
SpatialAttention
空间注意力模块:空间维度不变,压缩通道维度。该模块关注的是目标的位置信息。

class SpatialAttention(nn.Module):
# Spatial-attention module
def __init__(self, kernel_size=7):
super().__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7' # kernel size 的大小必须是3或者7
padding = 3 if kernel_size == 7 else 1 # 当kernel_size是7时,padding=3; 当kernel_size是3时,padding=1
self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.act = nn.Sigmoid()
def forward(self, x):
return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))
1) 假设输入的数据x是(b,c,w,h),并进行两路处理。
2)其中一路在通道维度上进行求平均值,得到的大小是(b,1,w,h);另外一路也在通道维度上进行求最大值,得到的大小是(b,1,w,h)。
3) 然后对上述步骤的两路输出进行连接,输出的大小是(b,2,w,h)。
4)经过一个二维卷积网络,把输出通道变为1,输出大小是(b,1,w,h)。
5)将上一步输出的结果和输入的数据x相乘,最终输出数据大小是(b,c,w,h)。
CBAM
CBAM就是把ChannelAttention和SpatialAttention串联在一起。

class CBAM(nn.Module):
# Convolutional Block Attention Module
def __init__(self, c1, kernel_size=7): # ch_in, kernels
super().__init__()
self.channel_attention = ChannelAttention(c1)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
return self.spatial_attention(self.channel_attention(x))
C1
总共只有3次卷积(cv1,cv2,cv3)的Bottleneck。

class C1(nn.Module):
# CSP Bottleneck with 1 convolution
def __init__(self, c1, c2, n=1): # ch_in, ch_out, number
super().__init__()
self.cv1 = Conv(c1, c2, 1, 1)
self.m = nn.Sequential(*(Conv(c2, c2, 3) for _ in range(n)))
def forward(self, x):
y = self.cv1(x)
return self.m(y) + y
1)假设输入的数据是(b,c1,w,h)。
2) 首先通过一个Conv块,得到y, 大小为(b,c2,w,h)。
3) 然后让y通过n个3x3的Conv块,得到m。
4) 最后让m和y相加。
C3x
C3x继承自C3, 变换的是Bottleneck中的卷积核大小变为(1,3)和(3,3)。
class C3x(C3):
# C3 module with cross-convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
self.c_ = int(c2 * e)
self.m = nn.Sequential(*(Bottleneck(self.c_, self.c_, shortcut, g, k=((1, 3), (3, 1)), e=1) for _ in range(n)))
C3TR
C3TR继承自C3, n个Bottleneck更换为1个 TransformerBlock。

class C3TR(C3):
# C3 module with TransformerBlock()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e)
self.m = TransformerBlock(c_, c_, 4, n)# num_heads=4, num_layers=n
SPP
空间金字塔模型:三个MaxPool并行连接,kernel size分别为55,99和13*13。
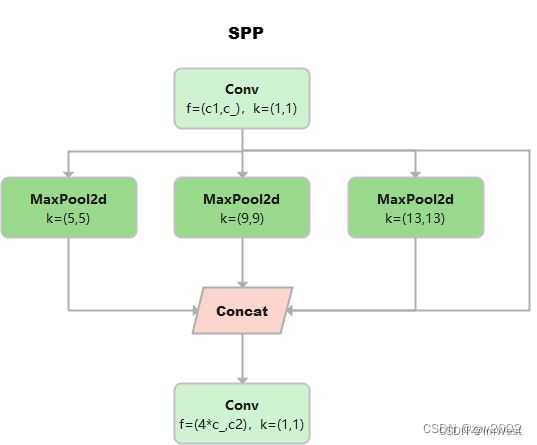
class SPP(nn.Module):
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
def __init__(self, c1, c2, k=(5, 9, 13)):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
SPPF
这个是YOLOv5作者Glenn Jocher基于SPP提出的,速度较SPP快很多,所以叫SPP-Fast。
三个MaxPool 串行连接,kerner size都是5*5。效果等价于SPP,但是运算量从原来的52+92+132=275减少到了3⋅52=75。
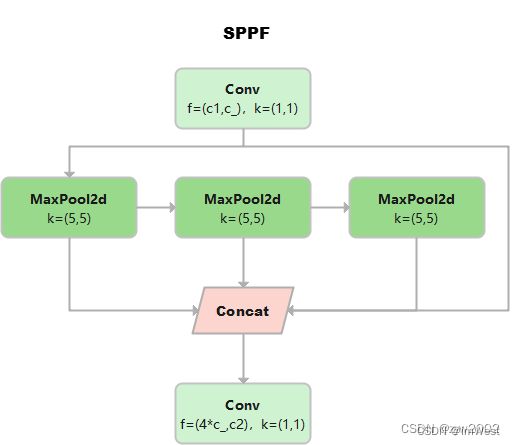
池化尺寸等价于SPP中kernel size分别为5*5,9*9和13*13的池化层并行连接。
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
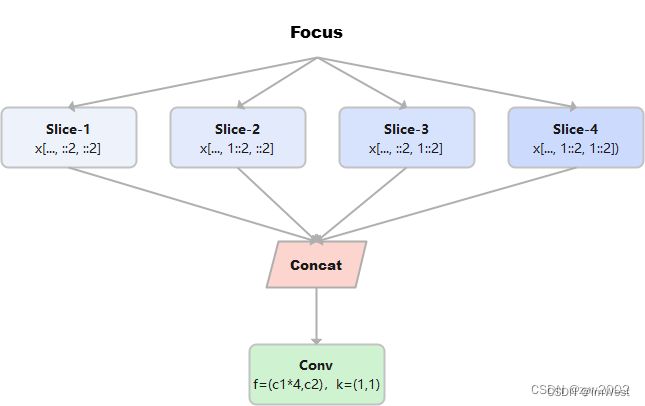
Focus
Focus模块在v5中是图片进入backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长的差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
例如: 原始的640×640×3的图像输入Focus结构,采用切片操作,先变成320×320×12的特征图,再经过一次卷积操作,最终变成320×320×32的特征图。切片操作如下:

class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act=act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))
# return self.conv(self.contract(x))
假设x的定义如下:

第一个切片: x[…, ::2, ::2]

第二个切片: x[…, 1::2, ::2]

第三个切片: x[…, ::2, 1::2]

第四个切片: x[…, 1::2, 1::2]

把上述四个切片连接在一起, 可以看到w,h是原始数据的一半,通道数变为原来的四倍。

GhostConv
Ghost卷积来自华为诺亚方舟实验室,《GhostNet: More Features from Cheap Operations》发表于2020年的CVPR上。提供了一个全新的Ghost模块,旨在通过廉价操作生成更多的特征图。原理如下图所示:

Ghost Module分为两步操作来获得与普通卷积一样数量的特征图:
Step1:少量卷积(比如正常用128个卷积核,这里就用64个,从而减少一半的计算量);
Step2:cheap operations,用图中的Φ表示,Φ是诸如33、55的卷积,并且是逐个特征图的进行卷积(Depth-wise convolutional,深度卷积)。

class GhostConv(nn.Module):
# Ghost Convolution https://github.com/huawei-noah/ghostnet
def __init__(self, c1, c2, k=1, s=1, g=1, act=True): # ch_in, ch_out, kernel, stride, groups
super().__init__()
c_ = c2 // 2 # hidden channels
self.cv1 = Conv(c1, c_, k, s, None, g, act=act)
self.cv2 = Conv(c_, c_, 5, 1, None, c_, act=act) # 分组数=c_=通道数,进行point-wise的深度分离卷积
def forward(self, x):
y = self.cv1(x)
return torch.cat((y, self.cv2(y)), 1)
GhostBottleneck
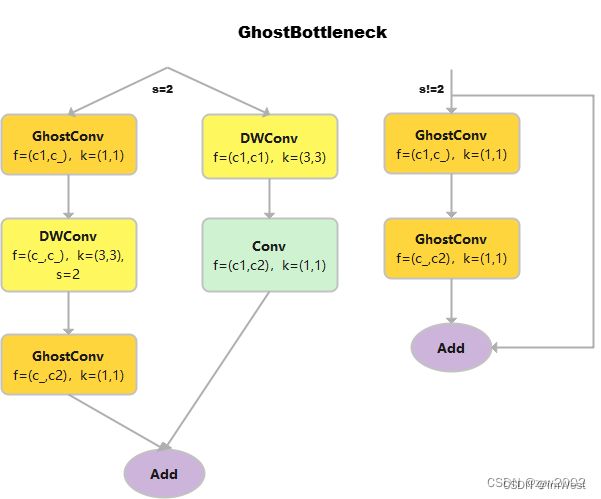
class GhostBottleneck(nn.Module):
# Ghost Bottleneck https://github.com/huawei-noah/ghostnet
def __init__(self, c1, c2, k=3, s=1): # ch_in, ch_out, kernel, stride
super().__init__()
c_ = c2 // 2
self.conv = nn.Sequential(
GhostConv(c1, c_, 1, 1), # 卷积核的大小是1*1,属于point-wise的深度可分离卷积
DWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(), # 输入通道数和输出通道数相等,属于depth-wise的深度可分离卷积
GhostConv(c_, c2, 1, 1, act=False)) #point-wise的深度可分离卷积,且不采用偏置项。
self.shortcut = nn.Sequential(DWConv(c1, c1, k, s, act=False), Conv(c1, c2, 1, 1,
act=False)) if s == 2 else nn.Identity()
def forward(self, x):
return self.conv(x) + self.shortcut(x)
C3Ghost
C3Ghost继承自C3,Bottleneck更换为GhostBottleneck。

class C3Ghost(C3):
# C3 module with GhostBottleneck()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(GhostBottleneck(c_, c_) for _ in range(n)))
Concat
当dimension=1时,将多张相同尺寸的图像在通道维度维度上进行拼接。
class Concat(nn.Module):
# Concatenate a list of tensors along dimension
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat(x, self.d)
2.yolo实操
2.1 引言
Linux系统 Ubuntu20.04 cuda版本11.1 cudnn版本8.0.4
pytorch版本1.10.0 torchvision版本0.11.0
其他依赖库按照requirements.txt安装即可
2.2 代码下载
终端输入指令
git clone https://github.com/ultralytics/ultralytics.git
2.3 环境准备
2.3.1 anaconda创建新环境
conda create -n yolov8 python=3.8
激活新环境
conda activate yolov8
2.3.2 安装依赖
运行requirements.txt文件即可完成所有库的安装,torch单独安装,保证与自己的cuda版本对应。
pip install -r requirements.txt
2.3.3 安装ultralytics
ultralytics集成了yolo的各种包以及模型等,程序中直接调用。
pip install ultralytics
2.3.4 手动下载权重
下载链接:https://github.com/ultralytics/assets/releases
位置:ultralytics根目录下
2.4 测试运行
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
或
yolo predict model=yolov8n.pt source=ultralytics/assets/bus.jpg
这一步没问题代表环境配置成功。
2.5. 训练自己的数据集
2.5.1 数据准备
在ultralytics根目录下新建mydata文件夹,再在mydata文件夹下新建Annotations,images,ImagesSets,labels四个文件夹。
- Annotations:存放图片的xml文件
- images:存放数据集的图片文件
- ImageSets:之后会在Main文件夹中自动生成train.txt,val.txt,test.txt和trainval.txt四个文件
- labels:存放xml文件转换后的txt标准格式标签
2.5.2 标签格式转换
由于yolov8使用的是labels是txt格式的文件,故需要将原始数据集xml格式的标签转换成txt格式。
即将每个xml标注提取box信息为txt格式,每个图像对应一个txt文件,文件每一行为一个目标的信息,包括class, x_center, y_center, width, height格式。
在mydata文件夹下新建一个文件xml2txt.py,并运行,代码如下。
import os
import glob
import xml.etree.ElementTree as ET
xml_file=r'/home/wsj/ultralytics/VOC2007/Annotations' # 改为自己Annotations文件夹所在位置
l=['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] # 自己数据集的类别
def convert(box,dw,dh):
x=(box[0]+box[2])/2.0
y=(box[1]+box[3])/2.0
w=box[2]-box[0]
h=box[3]-box[1]
x=x/dw
y=y/dh
w=w/dw
h=h/dh
return x,y,w,h
def f(name_id):
xml_o=open(r'/home/wsj/ultralytics/VOC2007/Annotations/%s.xml'%name_id) # 修改
txt_o=open(r'/home/wsj/ultralytics/VOC2007/labels/%s.txt'%name_id,'w') # 修改
pares=ET.parse(xml_o)
root=pares.getroot()
objects=root.findall('object')
size=root.find('size')
dw=int(size.find('width').text)
dh=int(size.find('height').text)
for obj in objects :
c=l.index(obj.find('name').text)
bnd=obj.find('bndbox')
b=(float(bnd.find('xmin').text),float(bnd.find('ymin').text),
float(bnd.find('xmax').text),float(bnd.find('ymax').text))
x,y,w,h=convert(b,dw,dh)
write_t="{} {:.5f} {:.5f} {:.5f} {:.5f}\n".format(c,x,y,w,h)
txt_o.write(write_t)
xml_o.close()
txt_o.close()
name=glob.glob(os.path.join(xml_file,"*.xml"))
for i in name :
name_id=os.path.basename(i)[:-4]
f(name_id)
2.5.3 按比例划分
在mydata文件夹下新建一个文件split_train_val.py,随机分配训练/验证/测试集图片,代码如下所示。
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.9 # 训练集和验证集所占比例。 这里没有划分测试集
train_percent = 0.9 # 训练集所占比例,可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
2.5.4 xml_to_yolo
在mydata文件夹下新建一个文件xml_to_yolo.py,代码如下所示。
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ['aeroplane','bicycle','bird','boat','bottle','bus','car','cat','chair','cow','diningtable','dog','horse','motorbike','person','pottedplant','sheep','sofa','train','tvmonitor'] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
print(size[0])
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('/home/wsj/ultralytics/VOC2007/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('/home/wsj/ultralytics/VOC2007/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
# difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('/home/wsj/ultralytics/VOC2007/labels/'):
os.makedirs('/home/wsj/ultralytics/VOC2007/labels/')
image_ids = open('/home/wsj/ultralytics/VOC2007/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
if not os.path.exists('/home/wsj/ultralytics/VOC2007/dataSet_path/'):
os.makedirs('/home/wsj/ultralytics/VOC2007/dataSet_path/')
list_file = open('/home/wsj/ultralytics/VOC2007/dataSet_path/%s.txt' % (image_set), 'w')
# 这行路径不需更改,这是相对路径
for image_id in image_ids:
list_file.write('/home/wsj/ultralytics/VOC2007/JPGImages/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
2.5.5 修改数据加载配置文件
在ultralytics根目录下新建mydata.yaml文件,内容如下。注意txt需要使用绝对路径。
train: /home/wsj/ultralytics/VOC2007/dataSet_path/train.txt
val: /home/wsj/ultralytics/VOC2007/dataSet_path/val.txt
test: /home/wsj/ultralytics/VOC2007/dataSet_path/test.txt
# number of classes
nc: 20
# class names
names: ['aeroplane','bicycle','bird','boat','bottle','bus','car','cat','chair','cow','diningtable','dog','horse','motorbike','person','pottedplant','sheep','sofa','train','tvmonitor']
至此数据集的准备工作已完成。
2.6 模型训练/验证/预测/导出
yolov8的训练采用命令行的模式,下面为yolov8官方给定的训练/预测/验证/导出方式。
yolo task=detect mode=train model=yolov8n.pt args...
classify predict yolov8n-cls.yaml args...
segment val yolov8n-seg.yaml args...
export yolov8n.pt format=onnx args...
2.6.1 模型训练
打开终端(或pycharm等IDE),进入anaconda虚拟环境,随后进入ultralytics文件夹下,在终端输入下面指令,即可开始训练。
yolo task=detect mode=train model=yolov8n.pt data=voc.yaml batch=8 epochs=100 device=0
多卡训练
yolov8多卡训练仅需把device=0改为device=0,1既可以。
yolo task=detect mode=train model=yolov8n.pt data=voc.yaml batch=8 epochs=100 device=0,1
所有参数见下表:
| 名称 | 默认值 | 描述 |
|---|---|---|
| batch | 16 | 训练的批量大小 |
| model | null | 训练模型权重,可指定具体位置,如yolov8n.pt,yolov8n.yaml等 |
| epochs | 100 | 训练的轮次 |
| imgsz | 640 | 输入图像压缩后的尺寸 |
| device | null | 用于训练的设备,可选0或1或cpu等 |
| workers | 8 | 多线程数据加载,默认8 |
| data | null | 数据路径,使用自定义的yaml文件或者官方yaml |
| lr0 | float | 初始学习率 |
| lrf | float | 最终学习率(lr0 * lrf) |
| patience | 50 | 早期训练时,准确率如果没有显著上升则停止的轮次 |
| save | float | 是否需要保存训练的模型和预测结果 |
| cache | False | 使用缓存进行数据加载,可选True/ram, disk 或者 False |
| project | null | 项目名称 |
| name | null | 实验的名称 |
| exist_ok | False | 是否覆盖现有实验 |
| pretrained | False | 是否使用预训练模型 |
| optimizer | ‘SGD’ | 优化器,可选[‘SGD’, ‘Adam’, ‘AdamW’, ‘RMSProp’] |
| verbose | False | 是否打印详细输出 |
| seed | 0 | 重复性实验的随机种子 |
| deterministic | True | 是否启用确定性模式 |
| single_cls | False | 是否将多类数据训练为单类 |
| image_weights | False | 是否使用加权图像选择进行训练 |
| rect | False | 是否支持矩形训练 |
| cos_lr | False | 是否使用余弦学习率调度器 |
| close_mosaic | 10 | 禁用最后 10 个 epoch 的马赛克增强 |
| resume | False | 是否从上一个检查点恢复训练 |
| lr0 | 0.01 | 初始学习率(SGD=1E-2, Adam=1E-3) |
| lrf | 0.01 | 余弦退火超参数 (lr0 * lrf) |
| momentum | 0.937 | 学习率动量 |
| weight_decay | 0.0005 | 权重衰减系数 |
| warmup_epochs | 3.0 | 预热学习轮次 |
| warmup_momentum | 0.8 | 预热学习率动量 |
| warmup_bias_lr | 0.1 | 预热学习率 |
| box | 7.5 | giou损失的系数 |
| cls | 0.5 | 分类损失的系数 |
| dfl | 1.5 | dfl损失的系数 |
| fl_gamma | 0.0 | 焦点损失的gamma系数 (efficientDet默认gamma=1.5) |
| label_smoothing | 0.0 | 标签平滑 |
| nbs | 64 | 名义批次,比如实际批次为16,那么64/16=4,每4 次迭代,才进行一次反向传播更新权重,可以节约显存 |
| overlap_mask | True | 训练期间掩码是否重叠(仅限分割训练) |
| mask_ratio | 4 | 掩码下采样率 (仅限分割训练) |
| dropout | 0.0 | 使用 dropout 正则化 (仅限分类训练) |
2.6.2 模型验证
使用如下命令即可完成对验证数据的评估。
yolo task=detect mode=val model=runs/detect/train3/weights/best.pt source=VOC2007/dataSets_path/test.txt device=0
| 名称 | 默认值 | 描述 |
|---|---|---|
| val | True | 在训练期间验证/测试 |
| save_json | False | 将结果保存到 JSON 文件 |
| save_hybrid | False | 保存标签的混合版本(标签+附加预测) |
| conf | 0.001 | 用于检测的对象置信度阈值(预测时默认 0.25 ,验证时默认0.001) |
| iou | 0.6 | NMS 的交并比 (IoU) 阈值 |
| max_det | 300 | 每张图像的最大检测数 |
| half | True | 使用半精度 (FP16) |
| dnn | False | 使用 OpenCV DNN 进行 ONNX 推理 |
| plots | False | 在训练期间显示图片 |
2.6.3 模型预测
使用如下命令既可完成对新数据的预测,souce需要指定为自己图像的路径或摄像头(0)。
yolo task=detect mode=predict model=runs/detect/train/weights/best.pt source=data/images device=0
| 名称 | 默认值 | 描述 |
|---|---|---|
| source | ‘ultralytics/assets’ | 图片或视频的源目录 |
| save | False | 是否保存结果 |
| show | False | 是否显示结果 |
| save_txt | False | 将结果保存为 .txt 文件 |
| save_conf | False | 保存带有置信度分数的结果 |
| save_crop | Fasle | 保存裁剪后的图像和结果 |
| conf | 0.3 | 置信度阈值 |
| hide_labels | False | 隐藏标签 |
| hide_conf | False | 隐藏置信度分数 |
| vid_stride | False | 视频帧率步幅 |
| line_thickness | 3 | 边界框厚度(像素) |
| visualize | False | 可视化模型特征 |
| augment | False | 将图像增强应用于预测源 |
| agnostic_nms | False | 类别不可知的 NMS |
| retina_masks | False | 使用高分辨率分割蒙版 |
| classes | null | 只显示某几类结果,如class=0, 或者 class=[0,2,3] |
2.6.4 模型导出
试用以下命令既可完成训练模型的导出。
yolo task=detect mode=export model=runs/detect/train/weights/best.pt format=onnx