Mybatis学习笔记-映射文件,标签,插件
目录
概述
mybatis做了什么
原生JDBC存在什么问题
MyBatis组成部分
Mybatis工作原理
mybatis和hibernate区别
使用mybatis(springboot)
mybatis核心-sql映射文件
基础标签说明
1.namespace,命名空间
2.select,insert,update,delete为不同类型的sql标签
映射标签的属性说明
1.id
2.parameterType
简单类型
实体类
实体类嵌套
Map
@Param注解
3.resultType
简单类型
实体类
实体类列表
Map
4.resultMap标签
resultMap属性
id,标记这个resultMap,通过id可以使用该resultMap
type,指定映射的实体类
result
association
collection
5.jdbcType的作用
常见类型关系
6.useGeneratedKeys和keyProperty组合
7.statementType
8.useCache&flushCache
mybatis缓存
属性说明
开启缓存后还可以在任意的具体sql中配置缓存的访问控制
select语句
insert,update,delete语句
动态sql标签
1.if test="..."
注意点
判空
判断某个值
嵌套
2.where
3.set
4.choose,when,otherwise
5.isNotEmpty property="xxx"...
6.isEqual property="xxx" compareValue="1"
sql标签
foreach标签
属性说明
注意
如果入参直接传递一个List或者Array
bind标签
selectKey标签
作用
注意
属性
keyProperty
keyColumn
resultType
order
statementType
CDATA
${}和#{}区别
#{value}
${value}
mybatis插件
mybatisX自动生成基础代码
概述
前身是apache开发的iBatis,迁移到goole code后改名为MyBatis,2013年迁移到GitHub
在springboot的背景下,我们不关注原本ssm项目的xml配置,只关注mybatis本身
mybatis做了什么
解决了原生jdbc的弊端,开发者只需要关注sql本身
原生JDBC存在什么问题
1.频繁的获取连接和释放资源
每次需要执行JDBC就会获取连接,执行结束释放资源,浪费系统资源
解决:mybatis使用数据库连接池解决问题
2.将sql语句硬编码,变动sql就要改变java代码
解决:将Sql语句配置在XXXXmapper.xml文件中与java代码分离
3.sql传参麻烦,参数数量可能会变化,而占位符和参数数量要保持一致
解决:mybatis自动映射
4.处理结果也是硬编码,sql变化导致解析结果变化就要改变java代码
解决:mybatis自动映射
MyBatis组成部分
mapper.xml:sql映射文件,配置了操作数据库的sql语句,此类文件需要在SqlMapConfig.xml中加载
SqlSessionFactoryBuilder:SqlSessionFactoryBuilder用于创建SqlSessionFacoty,SqlSessionFacoty是单例,所以一旦创建完成就不再需要SqlSessionFactoryBuilder
SqlSessionFactory:即会话工厂,MyBatis配置完整就可以获取SqlSessionFactory
sqlSession:即会话,由会话工厂SqlSessionFactory创建,操作数据库增删改查需要在会话中进行,通常来说,每个线程创建各自的sqlSession,使用完就close()
Executor:操作数据库,mybatis底层自定义了Executor执行器接口操作数据库,Executor接口有两个实现,一个是基本执行器,一个是缓存执行器
Mapped Statement:Mapped Statement也是mybatis一个底层封装对象,可以简单的理解为一条完整的sql入参,查询,返回就是一个Mapped Statement对象
1.它封装了mybatis配置信息及sql映射信息等,mapper.xml文件中一个sql对应一个Mapped Statement对象,sql的id即是Mapped statement的id
2.它对sql执行输入参数进行定义,包括HashMap、基本类型、pojo,Executor通过Mapped Statement在执行sql前将输入的java对象映射至sql中,输入参数映射就是jdbc编程中对preparedStatement设置参数
3.它对sql执行输出结果进行定义,包括HashMap、基本类型、pojo,Executor通过Mapped Statement在执行sql后将输出结果映射至java对象中,输出结果映射过程相当于jdbc编程中对结果的解析处理过程
Mybatis工作原理
JDK动态代理,Mybatis运行时会使用JDK动态代理为Mapper接口生成代理对象MappedProxy,代理对象会拦截接口方法,根据类的全限定名+方法名,唯一定位到一个MapperStatement并调用执行器执行所代表的sql,然后将sql执行结果返回
mybatis和hibernate区别
1.mybatis是半自动ORM框架,需要程序员编写sql,更灵活,因此更容易满足复杂场景,能更好的控制sql性能
2.mybatis由于要开发者自己编写sql,意味着不同数据库就要学习不同的语法,编写不同的sql,可能增大学习成本和工作量
3.mybatis门槛低,几乎可以说,只要会写sql就等于会用mybatis,而hibernate的配置更繁琐,个人学习成本很高,同时要求团队的所有人都需要精通hibernate,不利于团队开发效率
4.hibernate不需要开发者关注sql,而是集中精力在业务逻辑上,但在处理复杂场景时,更繁琐,甚至可以说繁琐的有些变态,一个动态条件在mybatis中是一个标签两行代码,而hibernate可能需要写几十倍的代码来实现
5.随着mybatis-plus的出现,绝大部分的WEB项目更倾向于选用mybatis
使用mybatis(springboot)
1.在springboot的背景下,不再需要自己配置xml,通过直接导入启动器依赖即可
2.配置Mapped Statement的文件路径,让mybatis知道要执行的sql位置
3.编写mapper接口
4.编写mapper接口对应的Mapped Statement
org.mybatis.spring.boot
mybatis-spring-boot-starter
2.2.2
mybatis:
mapper-locations: classpath:mapper/*.xml
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
@Mapper
public interface CustomerMapper {
int insert(Customer record);
}
mybatis核心-sql映射文件
基础标签说明
1.namespace,命名空间
指向mapper接口的位置,mapper接口的方法名对应这里sql的id
每个命名空间都是独立的,不同命名空间可以存在相同id的sql
比如TeacherMapper和StudentMapper都可以配置id为queryById的sql
2.select,insert,update,delete为不同类型的sql标签
映射标签的属性说明
1.id
statement的id,可以理解为sql的标识
2.parameterType
输入参数类型,在sql中使用#{value},${value}获取到入参,二者是不同的,后面单独说明
简单类型
比如Integer,String
#{value},${value}的value是接口方法的形参名
select * from student where id = #{value};
实体类
#{value},${value}的value是实体类的属性名
实体类需要有getter,setter方法,否则mybatis无法操作实体类的成员(取值,赋值)
select * from student where name = #{name} and age = #{age};
实体类嵌套
实体类的一个属性是另外一个实体类
包装对象要implements serializable实现序列化接口
使用#{student.name},${student.name}获取属性
Map
#{value},${value}的value为map的key
select * from student where name = #{name} and age = #{age};
@Param注解
低版本的mybatis,只传一个参数时必须在接口上使用@Param声明该参数
高版本的mybatis,只传一个参数时不会报错;传多个参数不使用实体类封装时,每个参数都要用@Param声明
3.resultType
结果映射类型 ,sql查询结果的类型
简单类型
sql结果为简单类型,比如int,String
select count(*) from student;
实体类
sql结果为一条记录,包含多个字段,封装到实体类对象中,比如Student
select * from student where id = #{value};
实体类列表
sql结果为多条记录,包含多个字段,分别封装到实体类中,即对象集合/数组
虽然结果是List,但实际配置的resultType仍然为实体类,即List中所存对象的类型
select * from student;
Map
直接用map接收,会生成List这样的结构
查询结果列名即为map的key,map.get("xxx")可以获取结果的值
可以自定义,指定哪一列映射到key,哪一列映射到value,但这本质上并不是Map,只是看起来像
4.resultMap标签
我们刚刚知道,sql结果可以映射到实体类上,但这样就必须要求sql中的字段名和实体类的属性名相同才行
实际上,往往数据库的字段名和实体类的属性名是不同的,比如,数据库是customer_id,而实体类是customerId,当然我们可以在sql上给字段写别名,就可以让结果映射到实体类上,但这样意味着每条sql都要写一遍这些别名,显然不合理;
要想自动让查询结果映射到实体类,可以使用resultMap标签,resultMap标签可以将查询结果映射到某个给定的实体类上
resultMap属性
id,标记这个resultMap,通过id可以使用该resultMap
type,指定映射的实体类
result
property:实体类字段名,column:表字段名,jdbcType:数据类型
association
主实体类的字段是实体类,一对一关系
property:主实体类的字段名,javaType:子实体类类型,column:关联表的主键
collection
主实体类的字段是实体类,一对多关系
property:主实体类的字段名,ofType:子实体类类型,javaType:集合类型
//一个学生对应一个老师,一个学生对应多门课程
5.jdbcType的作用
jdbcType会用在#{},中,作用是标记数据库字段的类型
有了给定类型,mybatis就知道拿到入参后应当作为什么类型传递给数据库,拿到数据库结果以后需要处理成什么类型
在入参为空,或者结果为空时,也知道应当给定什么默认值,在这种情况下,显然,我们不能使用基本类型,而是应当使用包装类传递数据,否则值在一些情况下不会是null,而是默认值
常见类型关系
java类型 jdbcType
String VARCHAR
LocalDate DATE
LocalTime TIME
LocalDateTime TIMESTAMP
Byte/Short/Integer/Long/Float/Double/BigDecimal NUMERIC,其中基本类型也有自己对应的类型6.useGeneratedKeys和keyProperty组合
在insert语句中组合使用,可以获取指定字段操作后的值放到入参实体中,显然,通常用来获取自增主键,自生成字段
useGeneratedKeys="true" keyProperty="id"
7.statementType
通常不需要设置,默认即可
用来标记何种方式操作sql
STATEMENT 直接操作sql,不进行预编译,获取数据
PREPARED 预处理,参数,进行预编译,获取数据,默认
CALLABLE 执行存储过程
8.useCache&flushCache
通常不需要设置,默认即可
mybatis缓存
mybatis查询会先查询缓存数据,当存在入参一致的数据时,直接将缓存返回,不再查询数据库
一级缓存是针对sqlSession,每次操作数据库,都会生成sqlSession对象,缓存数据就存在sqlSession中,显然,不同的sqlSession不会互相影响
二级缓存是针对mapper,多个sqlSession操作同一个mapper的sql语句,可以共用这个mapper的二级缓存,显然,二级缓存是跨sqlSession的
sqlSession:理解为JDBC中的Connection,即针对数据库的一次连接
二级缓存需要手动开启
application.yml mybatis: configuration: #开启MyBatis的二级缓存 cache-enabled: true mapper.xml
属性说明
eviction:缓存回收策略
LRU:最少使用原则,移除最长时间不使用的对象
FIFO:先进先出原则,按照对象进入缓存顺序进行回收
SOFT:软引用,移除基于垃圾回收器状态和软引用规则的对象
WEAK:弱引用,更积极的移除移除基于垃圾回收器状态和弱引用规则的对象
flushInterval:刷新时间间隔,单位为毫秒,这里配置的100毫秒。如果不配置,那么只有在进行数据库修改操作才会被动刷新缓存区
size:引用额数目,代表缓存最多可以存储的对象个数
readOnly:是否只读,如果为true,则所有相同的sql语句返回的是同一个对象(有助于提高性能,但并发操作同一条数据时,可能不安全),如果设置为false,则相同的sql,后面访问的是cache的clone副本
开启缓存后还可以在任意的具体sql中配置缓存的访问控制
useCache:标记是否启用mybatis缓存,启用缓存后,当入参一样,mybatis将会直接将缓存中的结果返回,而不再查询数据库,每次查询后,会缓存到缓存中
flushCache:标记是否在操作后清空缓存,为了防止读到脏数据,增删改之后,应当清空缓存
select语句
useCache默认为true,即每次查询后,会将结果缓存到缓存中
flushCache默认为false,即每次操作后,不会清空缓存
insert,update,delete语句
没有useCache属性
flushCache默认为true,即每次操作后,清空缓存
动态sql标签
1.if test="..."
满足if则拼接该段sql,常用于动态条件查询
这里有一个where 1=1,这是因为如果第一个if成立,sql就为where and ....,语法错误,如果不想用where 1=1,还要规避这样的问题,那么可以使用标签 注意点
判空
对于非String类型的数据,在判空时只需要判断 !=null,如果 !=""会报错
判断某个值
对于String类型,判空需要xxx != null and != '',如果要判断是否等于某个值
嵌套
if标签可以嵌套
如下是错误的
...
因为MyBatis是使用的OGNL表达式来进行解析的,要改成
...
或者
...
if标签嵌套
AND T.TYPES = #{data.types}
AND T.STATUS = #{data.status}
2.where
自动添加where关键字,同时去掉sql语句中第一个无关的and关键字
但要注意,and前面不能有注释,否则就没法自动去掉了,这可能是低版本的BUG
3.set
自动添加set关键字,同时去除末尾的无关逗号
UPDATE T_ABOLISH T
T.ABOLISH_REASON = #{abolishReason},
T.ABOLISH_USER_NAME = #{abolishUserName},
4.choose,when,otherwise
//...
//...
5.isNotEmpty property="xxx"...
判空
6.isEqual property="xxx" compareValue="1"
判断值
sql标签
表示sql片段
然后在编写sql时,可以通过引用sql片段
select
如果引用别的namespace的sql片段,需要在refid的时候加上namespace,但通常不会这么做
id,name,age,sex
foreach标签
当传递pojo或者map的属性值为List或者Array时,需要遍历属性值,用foreach
select * from student
#{item}
属性说明
collection:遍历的集合,这里是传入pojo/map的属性名
item:遍历时的临时变量,自定义,但是和后面的#{}里面要一致
open:在前面添加的 sql 片段,上面配置的是 id in(
close:在结尾处添加的 sql 片段,上面配置的是 )
separator:指定遍历的元素之间使用的分隔符,上面配置的是,逗号,上面的sql就为 select * from student where id in('xx','xx','xx'...)
注意
如果入参直接传递一个List或者Array
此时collection属性就不能配置为属性名/key了,要为list/array
原因:mybatis处理入参的方式是创建一个map,把入参放入map中,再传给sqlSession执行
对于pojo或者mapper类型,属性名为key,属性值为value
对于Array,属性名为array,属性值为数组的值
对于List,属性名为list,属性值为列表的值
如果必须要用自定义的名称,需要在mapper中给变量增加@Param("xxx")注解
bind标签
使用 OGNL 表达式创建一个变量井将其绑定到上下文中
兼容不同数据库之间的SQL语法差异,对数据库迁移友好
常用于模糊查询,能有效防止sql注入
selectKey标签
作用
在insert,update语句中,会通过sql处理某些字段的值,通过selectKey可以直接获取某些字段sql运行后的值,而不需要单独查询一次处理后的数据,提高安全性,减少代码冗余
比如针对某个字段要在insert,update操作的前后改变这个字段的值,而且操作后需要知道这个字段变成了什么,比如自增主键,计数字段
有很多博客说selectKey是用来获取自增主键/主键的,实际上并不是,selectKey可以获取任意的字段/表达式的值,但有一定的限制(注意点)
注意
1.只能存在于insert或update的子标签中
2.入参只能是pojo,不能是String等类型
3.返回值并非是selectKey的字段,仍然是update原本的返回值,即被update的记录数
4.我们所需要的selectKey字段实际上是更新到被传入的pojo实例中
属性
keyProperty
结果集映射目标类的属性
若存在多个,则使用逗号分隔
keyColumn
目标类的属性,映射结果集的列名
若存在多个,则使用逗号分割
resultType
设置返回类型
可使用别名
order
设置此selectKey的执行顺序是早于sql语句,还是晚于sql语句
候选值:BEFORE和AFTER;
statementType
设置sql语句的映射类型,默认即可
候选值:STATEMENT,PREPARED,CALLABLE
serviceImpl
NumberDo numberDo = numberMapper.getNumberById(id);
if (numberDo != null) {
numberMapper.plusNumberById(numberDo);
//注意这里怎么获取更新后的新值
return numberDo.getNumber();
}
mapper.xml
SELECT T.INS_NUMBER FROM T_NUMBER T WHERE T.ID = #{id}
UPDATE T_NUMBER T
T.INS_NUMBER = T.INS_NUMBER + 1
WHERE T.ID = #{id}
CDATA
当sql包含<,&符号时,会报错。这是因为<会被xml解析为新元素的开始;&会被xml解析为字符实体的开始
解决方式有两种,虽然>,',"并不会报错,但仍然建议把他们做同样处理
1.使用转义替换
< < 小于
> > 大于
& & 和号
' ' 省略号
" " 引号
select * from student where age < 18;2.使用
对于包含大量特殊符号的sql,建议使用
解析器会忽略 CDATA 部分中的所有内容
注意:
CDATA 部分不能包含字符串 "]]>"。也不允许嵌套的 CDATA 部分
标记 CDATA 部分结尾的 "]]>" 不能包含空格或换行
${}和#{}区别
#{value}
sql语句中的占位符,会根据参数类型进行预编译,可以防止sql注入
对于传入的String类型value,占位符#{}会加上单引号,即'value'
select * from student t where t.name like #{name};
select * from student t where t.name like '张三'
而在模糊查询,或者内存中传入一个sql片段,显然#{}不符合要求,所以要用到${value}
select * from student t where t.name like '%#{name}%';
select * from student t where t.name like '%'张三'%'
${value}
用于sql中的字符串拼接,不会预编译,不能防止sql注入
模糊查询的sql注入问题可以通过bind标签解决,也可以通过数据库提供的某些函数解决
select * from student t where t.name like '${value}';
select * from student t where t.name like '张三'
select * from student t where t.name like '%${value}%';
select * from student t where t.name like '%张三%'
mybatis插件
经过上面的学习,我们发现,mybatis上手是很简单,会写sql=会用mybatis,但对于每一张表,或者每一类业务,我们都需要编写resultMap返回值映射,包含所有字段的insert,delete,update,select基础语句,相当于我们要做很多次重复的事情,既麻烦又枯燥
有没有什么办法能够解决这个事情呢,当然有,mybatis提供了逆向工程工具,可以通过数据库表结构,自动生成resultMap返回值映射,包含所有字段的insert,delete,update,select基础语句,但这个逆向工程,需要我们编写一部分代码,而一些mybatis插件,比如mybatisX,mybatisPro等等,可以用图形化操作界面,只需要连接上数据库,配置指定的包路径,就能实现这些基础代码的生成,十分方便快捷,自由度也高
mybatisX自动生成基础代码
1.安装mybatisX插件
2.连接数据库
通过IDEA的database连接数据库
报错:Server returns invalid timezone. Go to ‘Advanced’ tab and set ‘serverTimezone’ property manually
解决:设置时区为当前时区,Advanced->找到serverTimezone,设置为Asia/Shanghai
3.生成mybatis代码
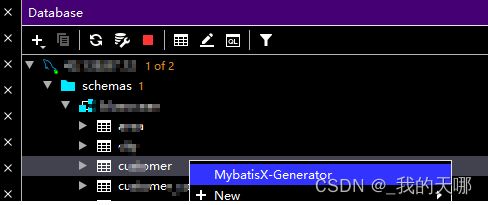
右击表名,选择mybatisX-generator
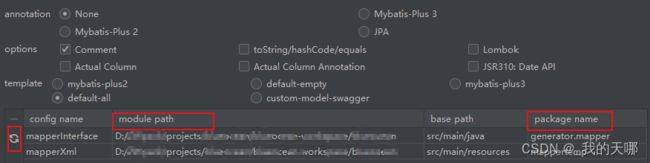
选择需要生成的类型,如果不使用mybatisplus,选择
annotation:none
template:default-all
点击确认,会发现项目中指定包下,已经生成了实体类,mapper接口,mapper.xml,已经自动生成了resultMap返回值映射,包含所有字段的insert,delete,update,select基础语句