02)JDK1.8 新特性学习 StreamAPI 并行流
StreamApiDemo01.java
1.创建stream
2.中间操作(过滤、map)
3.终止操作
package com.wying.demo.StreamApi;
import org.junit.Test;
import java.util.*;
import java.util.function.UnaryOperator;
import java.util.stream.Collectors;
import java.util.stream.Stream;
/**
* description:Stream操作的三个步骤
* Stream操作的三个步骤
* 1.创建stream
* 2.中间操作(过滤、map)
* 3.终止操作
*
* jdk1.8对java.util.stream和我们之前解除的 java.io的流没关系
* java.util.stream流就是一个对象可以反复使用 它是用于对集合Connection的操作
* 引进的Lambda的函数式编程
* 新特性Stream能够让用户以函数式的方式、更为简单的操纵集合等数据结构,并实现了用户无感知的并行计算
*
*
* java.io的流是数据传输的 和流水一样,用过了就没了
*
* date: 2021/10/28
* author: gaom
* version: 1.0
*/
public class StreamApiDemo01 {
@Test
public void test01(){
/**之前我们对集合,数据处理都是循环
* for(int i=0;i list01=new ArrayList<>();
//1.通过java集合类Collection接口的 stream()方法创建stream流
Stream stream01=list01.stream();
//数组生成流方式Arrays.stream(ary01);
Integer[] ary01=new Integer[10];
//2.通过Arrays的静态方法stream()创建stream流
Stream stream02=Arrays.stream(ary01);
//3.通过Stream的静态方法 of创建 stream流
Stream stream03=Stream.of("A","B","C","D");
// Stream API提供了两个静态方法来从函数生成流:Stream.iterate和Stream.generate。这两个操作可以创建所谓的无限流:不像从固定集合创建的流那样有固定大小的流。
//4.无限有序流iterate 0,(x)->x+2 是从0开始 每次+2
//通过迭代函数,生成一个有序无限的Int数据流。(由于是无限流,一般都是配合limit来使用)。
Stream stream04=Stream.iterate(0,(x)->x+2);
//无限流不做任何中断处理 直接执行stream04.forEach(System.out::print);
// 将会无限循环执行输出024681012141618202224262830323436384042444648505254565860626466687072747678xxxxxxxxxx,每次增加2
//直到内存溢出为止
// stream04.forEach(System.out::print);
//控制无限流 跳到第3个循环之后 不包括第三个循环 取5条数据
stream04.skip(3).limit(5).forEach(System.out::println); // 依次输出 6 8 10 12 14
//无限无序流 generate (由于是无限流,一般都是配合limit来使用)。
/** 和iterate不同的是,Stream.iterate可以通过seed入参 生成有序流
* 而Stream.generate方法返回一个无限连续的无序流,其中每个元素由提供的供应商(Supplier)生成。generate方法用于生成常量流和随机元素流。
* Math.random()表示每次执行这个函数生成一个随机数放入流中
*
*/
Stream stream05= Stream.generate(()-> Math.random());
//执行forEach 把生成的随机数输出
//无限流不做任何中断处理 直接执行stream05.forEach(System.out::println); 将会无限循环执行 直到内存溢出为止
// stream05.forEach(System.out::println);
//依次输出前10个产生的随机数
stream05.skip(0).limit(10).forEach(System.out::println);
}
@Test
public void test02(){
//****************stream流中间操作**************//
/**
* 以前很多操作我们都是在 for循环里控制 stream都提供了相应的函数操作 简化了代码
*
*循环 forEach 为stream的终止操作 这里为了输出数据查看效果 最后都是使用的forEach函数输出值
*
* filter 过滤
* 该操作会接受一个谓词(一个返回boolean的函数)作为参数,并返回一个包括所有符合谓词的元素的流。说白了就是给一个条件,filter会根据这个条件截取流中得数据。
*
* skip 舍弃 跳到指定位置
* 该方法会返回一个扔掉了前面n个元素的流。如果流中元素不足n个,则返回一个空流。
*
* limit 截取
* 该方法会返回一个不超过给定长度的流。
*
* distinct 去重
* 该操作会返回一个元素各异(根据流所生成元素的hashCode和equals方法实现)的流。
*
* sorted 排序
* 对流中得数据进行排序,可以以自然序或着用Comparator 接口定义的排序规则来排序一个流。Comparator 能使用lambada表达式来初始化,还能够逆序一个已经排序的流。
*
*
*
*/
List list06=new ArrayList<>();
list06.add(6);
list06.add(4);
list06.add(8);
list06.add(8);
list06.add(9);
list06.add(2);
list06.add(11);
//sorted 排序 如果对对象 entity排序 需要使用Comparator接口比较
System.out.println("-----------正序-------------");
list06.stream().sorted().forEach(System.out::println);
System.out.println("------------倒序------------");
list06.stream().sorted(Comparator.reverseOrder()).forEach(System.out::println);
//filter 过滤 (x)->x==11 只保留 x==11的数据
System.out.println("------------ 过滤 ------------");
list06.stream().filter((x)->x==11).forEach(System.out::println); //输出11
//skip(x) 舍弃 跳到指定位置
System.out.println("------------ skip ------------");
list06.stream().sorted(Comparator.reverseOrder()).skip(1).forEach(System.out::println);
//limit(x) 该方法会返回一个不超过给定长度的流。
System.out.println("------------ limit ------------");
list06.stream().skip(1).limit(3).forEach(System.out::println);
//distinct 去重 把重复的8去掉 根据流所生成元素的hashCode和equals方法实现
System.out.println("------------ distinct ------------");
list06.stream().distinct().forEach(System.out::println);
//collect 收集 通过stream中间
List list07=list06.stream().skip(1).limit(3).collect(Collectors.toList());
System.out.println("------------ 输出原list 流的所有操作不会改变list的结构 ------------");
for(Integer i:list06){
System.out.println("for:"+i);
}
}
@Test
public void test03(){
//****************stream流终止操作**************//
/**
*
*
*
*
* 循环 forEach
* 该操作会接受一个谓词(一个返回boolean的函数)作为参数,并返回一个包括所有符合谓词的元素的流。说白了就是给一个条件,filter会根据这个条件截取流中得数据。
*
* collect 收集
* 从上面得代码已经可以看出来,collect是将最终stream中得数据收集起来,最终生成一个list,set,或者map。
*
* anyMatch
* anyMatch方法可以回答“流中是否有一个元素能匹配到给定的谓词”。会返回一个boolean值。
*
* allMatch
* allMatch方法和anyMatch类似,校验流中是否都能匹配到给定的谓词。
*
* noneMatch
* noneMatch方法可以确保流中没有任何元素与给定的谓词匹配。
*
* findAny
* findAny方法将返回当前流中的任意元素。
*
* findFirst
* findFirst方法能找到你想要的第一个元素。
*
* 归约 reduce
* 此类查询需要将流中所有元素反复结合起来,得到一个值,比如一个 Integer 。这样的查询可以被归类为归约操作(将流归约成一个值)。用函数式编程语言的术语来说,这称为折叠(fold),因为你可以将这个操
* 作看成把一张长长的纸(你的流)反复折叠成一个小方块,而这就是折叠操作的结果。
*
*
* 计算 min、max、count、average
* 匹配 anyMatch、allMatch、noneMatch、findFirst、findAny
* 汇聚 reduce
*
*
*/
List list06=new ArrayList<>();
list06.add(6);
list06.add(4);
list06.add(8);
list06.add(8);
list06.add(9);
list06.add(2);
list06.add(11);
//collect 收集 通过stream中间操作处理流的数据 生成一个新的集合
System.out.println("-----------collect-------------");
List list07=list06.stream().skip(1).limit(3).collect(Collectors.toList());
list07.stream().forEach(System.out::println);
//循环 forEach 最常用的终止操作
System.out.println("-----------forEach-------------");
list06.stream().forEach(System.out::println);
//查找匹配 anyMatch 如果list中存在数据等于100则返回true
System.out.println("-----------anyMatch-------------");
boolean b1=list06.stream().allMatch((x)->x==100);
System.out.println(b1);
//findAny 返回当前流中的任意元素。
System.out.println("-----------findAny-------------");
//Optional为jdk1.8提供的处理空指针的
Optional opt1= list06.stream().findAny();
System.out.println("opt1.get():"+opt1.get());
// findFirst方法能找到你想要的第一个元素。
System.out.println("----------- findFirst-------------");
Optional opt2= list06.stream().findFirst();
System.out.println("opt2.get():"+opt2.get());
//归约 reduce
//此类查询需要将流中所有元素反复结合起来,得到一个值,比如一个 Integer 。这样的查询可以被归类为归约操作(将流归约成一个值)。用函数式编程语言的术语来说,这称为折叠(fold),因为你可以将这个操
//作看成把一张长长的纸(你的流)反复折叠成一个小方块,而这就是折叠操作的结果。
System.out.println("----------- reduce-------------");
//集合求和 0为基数
int count=list06.stream().reduce(0,(x1, x2)->x1+x2);
System.out.println("----------- 集合求和 reduce count:"+count+"-------------");
//reduce 查找最大值Integer::max 查找最小值 Integer::min
Optional maxi=list06.stream().reduce(Integer::max);
System.out.println("----------- 查找最大值 reduce maxi:"+maxi.get()+"-------------");
}
}
2.并行流 parallelStream
ParallelStream.java
package com.wying.demo.StreamApi;
import org.junit.Test;
import java.time.Instant;
import java.time.LocalTime;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
/**
* description:在jdk1.8新的stream包中针对集合的操作也提供了并行操作流和串行操作流。并行流就是把内容切割成多个数据块,
* 并且使用多个线程分别处理每个数据块的内容。Stream api中声明可以通过parallel()与sequential()方法在并行流和串行流之间进行切换。
* jdk1.8并行流底层是使用JAVA7新加入的Fork/Join框架:
*
* 这个用途很大 之前对数据处理 一个for循环太慢 要想快 最原始的不使用框架的话 得自己写代码开启新线程处理 还要控制集合的数据不要重复被取到等等
* 或者使用jdk1.7的Fork/Join框架需要自己写很多代码,考虑逻辑
* 现在stream已经内置了
*
* 不过在数据量不大的话不需要使用并行,数据量不大常规单线程效率还更快,stream和Fork/Join框架在数据量时使用效率提升明显,以空间换时间
* 和服务器的CPU 环境都有关系,不过现在服务器CPU基本都是4核 8核的
*
* date: 2021/11/12
* author: gaom
* version: 1.0
*/
public class ParallelStream {
@Test
public void test01(){
//创建一个有序无限流 从1 递增
Stream stream= Stream.iterate(1,x->x+1);
//取前1000个数字 转为集合
List list06= stream.limit(100000000).collect(Collectors.toList());
//串行流
long a = Instant.now().toEpochMilli();
System.out.println("*******串行流stream*********");
Integer count1=list06.stream().reduce(0,(x1,x2)->x1+x2);
long b = Instant.now().toEpochMilli();
System.out.println("*******串行流stream*********计算 count1:"+count1+" 耗时"+(b-a));
//并行流
System.out.println("*******并行流parallelStream*********");
Integer count2=list06.parallelStream().reduce(0,(x1,x2)->x1+x2);
long c = Instant.now().toEpochMilli();
System.out.println("*******并行流parallelStream********计算 count2:"+count2+" 耗时"+(c-b));
}
}
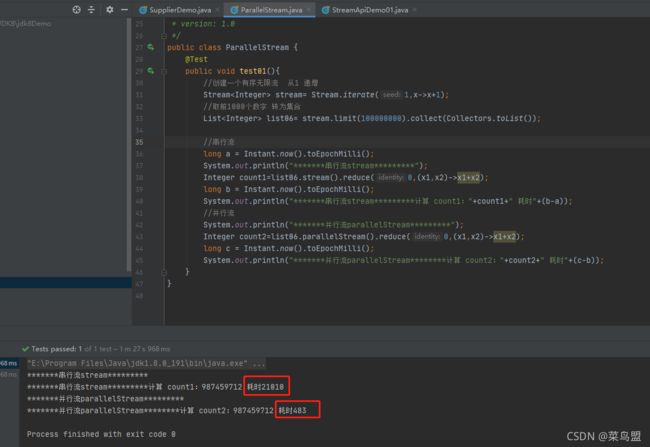
集合数据量小时执行结果测试,串行流执行速度反而更快
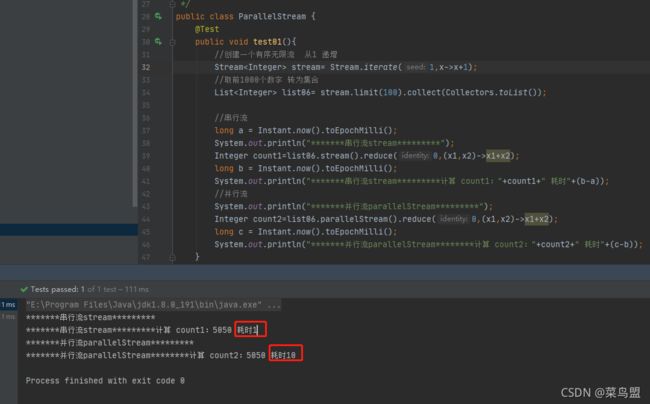
集合数据量大时执行结果测试,并行流速度比串行流快了N倍