8月10日TensorFlow学习笔记——TensorFlow 数据类型、创建、索引与切片、维度变换、前向传播
文章目录
- 前言
- 一、Numpy 回归问题实战
-
- 1、Step 1:compute loss
- 2、Step 2:compute Gradient and update
- 二、手写数字识别
-
- 1、Step 1:X and Y
- 2、Step 2:network structure
- 3、Step 3:循环计算 Loss、梯度并更新参数
- 三、数据类型
-
- 1、tf.constant()
- 2、Tensor Property
-
- (1)、.device
- (2)、.numpy()
- (3)、.ndim
- 3、Check Tensor Type
- 4、Convert
- 5、tf.Variable
- 四、创建 Tensor
-
- 1、From Numpy、List
- 2、tf.zeros & tf.zeros_like / tf.ones
- 3、tf.fill
- 4、tf.random.normal & tf.random.truncated_normal 初始化
- 5、tf.uniform
- 6、Random Permutation
- 五、常见维度
-
- 1、Loss
- 2、Vector
- 3、Matrix
- 4、Dim=3
- 5、Dim=4
- 6、Dim=5
- 六、索引与切片
-
- 1、[idx]… & [idx, idx, …]
- 2、start : end : step
- 3、…
- 4、tf.gather & tf.gather_nd
- 5、tf.boolean_mask
- 七、维度变换
-
- 1、tf.reshape()
- 2、tf.transpose
- 3、expand_dims
- 八、Broadcasting
- 九、数学运算
- 十、前向传播
前言
本文为8月10日TensorFlow学习笔记,分为十个章节:
- Numpy 回归问题实战;
- 手写数字识别;
- 数据类型;
- 创建 Tensor;
- 常见维度;
- 索引与切片;
- 维度变换;
- Broadcasting;
- 数学运算;
- 前向传播。
一、Numpy 回归问题实战
1、Step 1:compute loss
l o s s = ∑ i ( w x i + b − y i ) 2 loss = {\textstyle \sum_{i}} (wx_i + b -y_i)^2 loss=∑i(wxi+b−yi)2
def compute_error_for_line_given_points(b, w, points):
totalError = 0
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
# MSE
totalError += (y - (w * x + b))**2
# 平均误差
return totalError / float(len(points))
2、Step 2:compute Gradient and update
w ′ = w − l r ∂ l o s s ∂ w b ′ = b − l r ∂ l o s s ∂ b w' = w - lr\frac{\partial loss}{\partial w}\\ b' = b - lr\frac{\partial loss}{\partial b} w′=w−lr∂w∂lossb′=b−lr∂b∂loss
def step_gradient(b_current, w_current, points, learningRate):
b_gradient = 0
w_gradient = 0
N = float(len(points))
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
# dLoss/db = 2(wx+b-y)
b_gradient += (2/N) * ((w_current * x + b_current) - y)
# dLoss/dw = 2(wx+b-y)*x
w_gradient += (2 / N) * x * ((w_current * x + b_current) - y)
# 更新参数
new_b = b_current - (learningRate * b_gradient)
new_w = w_current - (learningRate * w_gradient)
return [new_b, new_w]
def gradient_descent_runner(points, starting_b, starting_w, learning_rate, num_iterations):
b = starting_b
w = starting_w
# 循环更新
for i in range(num_iterations):
b, w = step_gradient(b, w, np.array(points), learning_rate)
return [b, w]
二、手写数字识别
1、Step 1:X and Y
# Dataloader
(xs, ys), _ = datasets.mnist.load_data()
print('datasets: ', xs.shape, ys.shape)
# 将数据类型装换为 Tensor
xs = tf.convert_to_tensor(xs, dtype=tf.float32) / 255.
db = tf.data.Dataset.from_tensor_slices((xs, ys))
for step, (x, y) in enumerate(db):
print(step, x.shape, y.shape)
2、Step 2:network structure
# 网络结构
model = keras.Sequential([
layers.Dense(512, activation='relu')
layers.Dense(256, activation='relu')
layers.Dense(10)])
optimizer = optimizers.SGD(learning_rate=0.001)
3、Step 3:循环计算 Loss、梯度并更新参数
o u t = r e l u { r e l u { r e l u [ X @ W 1 + b 1 ] @ W 2 + b 2 } @ W 3 + b 3 } out = relu\{relu\{relu[X@W_1 + b_1] @ W_2 + b_2 \} @ W_3 + b_3 \} out=relu{relu{relu[X@W1+b1]@W2+b2}@W3+b3}
def train_epoch(epoch):
# 循环
for step, (x, y) in enumerate(train_dataset):
with tf.GradientTape() as tape:
# [b, 28, 28] ==> [b, 784]
x = tf.reshape(x, (-1, 28*28))
# 计算 out
# [b, 784] ==> [b, 10]
out = model(x)
# 计算 Loss
loss = tf.reduce_sum(tf.square(out - y) / x.shape[0])
# 计算梯度并更新参数
grads = tape.gradient(loss, model.trainable_variables)
# w' = w - lr * grad
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 100 == 0:
print(epoch, step, loss.numpy())
三、数据类型
- 标量 scalar:1.1;
- 矢量:[1.1], [1.1, 2.2, …];
- Matrix:[[1.1, 2.2], [3.3, 4.4]]
1、tf.constant()
- int:
tf.constant(1)
>>> <tf.Tensor: shape=(), dtype=int32, numpy=1>
- float:
tf.constant(1.)
>>> <tf.Tensor: shape=(), dtype=float32, numpy=1.0>
tf.constant(2., dtype=tf.double)
>>> <tf.Tensor: shape=(), dtype=float64, numpy=2.0>
- bool:
tf.constant([True, False])
>>> <tf.Tensor: shape=(2,), dtype=bool, numpy=array([ True, False])>
- string:
tf.constant('hello, world.')
>>> <tf.Tensor: shape=(), dtype=string, numpy=b'hello, world.'
2、Tensor Property
(1)、.device
with tf.device('cpu'):
a = tf.constant([1])
with tf.device('gpu'):
b = tf.range(4)
a.device
>>> '/job:localhost/replica:0/task:0/device:CPU:0'
b.device
>>> '/job:localhost/replica:0/task:0/device:GPU:0'
(2)、.numpy()
b
>>> <tf.Tensor: shape=(4,), dtype=int32, numpy=array([0, 1, 2, 3])>
b.numpy()
>>> array([0, 1, 2, 3])
(3)、.ndim
b.ndim
>>> 1
3、Check Tensor Type
- tf.is_tensor():
a = tf.constant([1.])
b = tf.constant('hello, world.')
c = np.arange(4)
tf.is_tensor(a)
>>> True
>
tf.is_tensor(c)
>>> False
- .dtype:
a.dtype
>>> tf.float32
b.dtype
>>> tf.string
4、Convert
- tf.convert_to_tensor:
a = np.arange(5)
a.dtype
>>> dtype('int32')
aa = tf.convert_to_tensor(a)
aa
>>> <tf.Tensor: shape=(5,), dtype=int32, numpy=array([0, 1, 2, 3, 4])>
aa = tf.convert_to_tensor(a, dtype=tf.int64)
aa
>>> <tf.Tensor: shape=(5,), dtype=int64, numpy=array([0, 1, 2, 3, 4], dtype=int64)>
- tf.cast:
tf.cast(aa, dtype=tf.float32)
>>> <tf.Tensor: shape=(5,), dtype=float32, numpy=array([0., 1., 2., 3., 4.], dtype=float32)>
aaa = tf.cast(aa, dtype=tf.int32)
aaa
>>> <tf.Tensor: shape=(5,), dtype=int32, numpy=array([0, 1, 2, 3, 4])>
5、tf.Variable
a = tf.range(5)
b = tf.Variable(a)
b.dtype
>>> tf.int32
四、创建 Tensor
1、From Numpy、List
- tf.convert_to_tensor():
tf.convert_to_tensor(np.ones([2, 3]))
>>> <tf.Tensor: shape=(2, 3), dtype=float64, numpy=
array([[1., 1., 1.],
[1., 1., 1.]])>
2、tf.zeros & tf.zeros_like / tf.ones
- tf.zeros / tf.zeros_like:
tf.zeros([2, 3, 3])
>>> <tf.Tensor: shape=(2, 3, 3), dtype=float32, numpy=
array([[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]], dtype=float32)>
- tf.ones:
tf.ones([2, 3])
>>> <tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[1., 1., 1.],
[1., 1., 1.]], dtype=float32)>
3、tf.fill
tf.fill([2, 2], 9)
>>> <tf.Tensor: shape=(2, 2), dtype=int32, numpy=
array([[9, 9],
[9, 9]])>
4、tf.random.normal & tf.random.truncated_normal 初始化
tf.random.normal([2, 2], mean=1, stddev=1)
>>> <tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[-1.7228823 , 0.5592389 ],
[ 0.958659 , 0.06300598]], dtype=float32)>
tf.random.truncated_normal([2, 2], mean=0, stddev=1)
>>> <tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[-1.1903499 , -1.0997943 ],
[-0.61278445, -1.8260463 ]], dtype=float32)>
5、tf.uniform
tf.random.uniform([2, 2], minval=0, maxval=1)
>>> <tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[0.691612 , 0.78263617],
[0.272987 , 0.16508114]], dtype=float32)>
6、Random Permutation
idx = tf.range(10)
idx = tf.random.shuffle(idx)
idx
>>> <tf.Tensor: shape=(10,), dtype=int32, numpy=array([9, 6, 2, 7, 5, 8, 4, 1, 0, 3])>
a = tf.random.normal([10, 784])
b = tf.random.uniform([10], maxval=10, dtype=tf.int32)
a = tf.gather(a, idx)
b = tf.gather(b, idx)
a
>>> <tf.Tensor: shape=(10, 784), dtype=float32, numpy=
array([[ 1.0956228 , -0.4414206 , -0.8895049 , ..., -0.46490633,
-0.15867558, 0.127609 ],
[-0.71079516, -0.26290268, 0.3766461 , ..., 0.10106482,
1.015825 , 0.03456433],
[ 0.35323364, -1.887433 , 0.6981578 , ..., 1.7753938 ,
-1.6670429 , 1.6674607 ],
...,
[ 0.8737698 , 0.17075352, 0.40575916, ..., 0.49251348,
0.67822474, 2.2669826 ],
[-1.923899 , 0.71565664, -0.76703817, ..., 0.46844977,
-0.01586642, 1.1873797 ],
[ 1.0158168 , 0.20684104, -0.5711898 , ..., -0.25193268,
-0.38850918, 0.6844528 ]], dtype=float32)>
b
>>> <tf.Tensor: shape=(10,), dtype=int32, numpy=array([9, 5, 0, 3, 6, 1, 9, 0, 0, 5])>
五、常见维度
1、Loss
out = tf.random.uniform([4, 10])
out
>>> <tf.Tensor: shape=(4, 10), dtype=float32, numpy=
array([[0.59091175, 0.2158711 , 0.8226553 , 0.7946583 , 0.8934969 ,
0.13021147, 0.3928734 , 0.69753075, 0.05204213, 0.44179153],
[0.34941113, 0.5306299 , 0.72810245, 0.22725523, 0.65103996,
0.4893322 , 0.39717567, 0.6800356 , 0.03700137, 0.01636839],
[0.97450936, 0.1764952 , 0.6414006 , 0.9587896 , 0.2077918 ,
0.6329063 , 0.06751907, 0.6738174 , 0.5489037 , 0.6840067 ],
[0.14027071, 0.19445062, 0.8057821 , 0.79019237, 0.80456376,
0.754022 , 0.74649835, 0.7692772 , 0.7237257 , 0.21629024]],
dtype=float32)>
y = tf.range(4)
y = tf.one_hot(y, depth=10)
y
>>> <tf.Tensor: shape=(4, 10), dtype=float32, numpy=
array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.]], dtype=float32)>
loss = tf.keras.losses.mse(y, out)
loss
>>> <tf.Tensor: shape=(4,), dtype=float32, numpy=array([0.31762755, 0.22093074, 0.37001872, 0.368627 ], dtype=float32)>
loss = tf.reduce_mean(loss)
loss
>>> <tf.Tensor: shape=(), dtype=float32, numpy=0.319301>
2、Vector
- Bias:
[ o u t _ d i m ] [out\_dim] [out_dim]
3、Matrix
- Input x:
[ b , v e c _ d i m ] [b, vec\_dim] [b,vec_dim]
x = tf.random.normal([4, 784])
x.shape
>>> TensorShape([4, 784])
4、Dim=3
[ b , s e q _ l e n , w o r d _ d i m ] [b, seq\_len, word\_dim] [b,seq_len,word_dim]
5、Dim=4
- Image:
[ b , h , w , 3 ] [b, h, w, 3] [b,h,w,3]
6、Dim=5
- Meta-learning:
[ t a s k _ b , b , h , w , 3 ] [task\_b, b, h, w, 3] [task_b,b,h,w,3]
六、索引与切片
1、[idx]… & [idx, idx, …]
a = tf.ones([1, 5, 5, 3])
a
<tf.Tensor: shape=(1, 5, 5, 3), dtype=float32, numpy=
>>> array([[[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]]]], dtype=float32)>
a[0][0]
>>> <tf.Tensor: shape=(5, 3), dtype=float32, numpy=
>>> array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]], dtype=float32)>
a[0][0][0][2]
>>> <tf.Tensor: shape=(), dtype=float32, numpy=1.0>
a = tf.random.normal([4, 28, 28, 3])
a[1].shape
>>> TensorShape([28, 28, 3])
a[1, 2].shape
>>> TensorShape([28, 3])
a[1, 2, 3].shape
>>> TensorShape([3])
a[1, 2, 3, 2].shape
>>> TensorShape([])
2、start : end : step
a = tf.range(10)
a
>>> <tf.Tensor: shape=(10,), dtype=int32, numpy=array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])>
a[::-1]
>>> <tf.Tensor: shape=(10,), dtype=int32, numpy=array([9, 8, 7, 6, 5, 4, 3, 2, 1, 0])>
a = tf.random.normal([4, 28, 28, 3])
a[0].shape
>>> TensorShape([28, 28, 3])
a[0, 1, :, :].shape
>>> TensorShape([28, 3])
a[:, 0, :, :].shape
>>> TensorShape([4, 28, 3])
3、…
a = tf.random.normal([4, 28, 28, 3])
a[0, ...].shape
>>> TensorShape([28, 28, 3])
a[0, ..., 2].shape
>>> TensorShape([28, 28])
a[1, 0, ..., 0].shape
>>> TensorShape([28])
4、tf.gather & tf.gather_nd
Data: [ c l a s s e s , s t u d e n t s , s u b j e c t s ] —— [ 4 , 35 , 8 ] [classes, students, subjects]——[4, 35, 8] [classes,students,subjects]——[4,35,8]
- tf.gather():
a = tf.random.normal([4, 35, 8])
tf.gather(a, axis=0, indices=[2, 3]).shape
>>> TensorShape([2, 35, 8])
tf.gather(a, axis=2, indices=[2, 3, 7]).shape
>>> TensorShape([4, 35, 3])
- tf.gather_nd():
tf.gather_nd(a, [0]).shape
TensorShape([35, 8])
tf.gather_nd(a, [0, 1]).shape
>>> TensorShape([8])
tf.gather_nd(a, [0, 1, 2]).shape
>>> TensorShape([])
tf.gather_nd(a, [[0, 1, 2]]).shape
>>> TensorShape([1])
5、tf.boolean_mask
a = tf.random.normal([4, 28, 28, 3])
tf.boolean_mask(a, mask=[True, True, False, False]).shape
>>> TensorShape([2, 28, 28, 3])
tf.boolean_mask(a, mask=[True, True, False], axis=3).shape
>>> TensorShape([4, 28, 28, 2])
七、维度变换
1、tf.reshape()
a = tf.random.normal([4, 28, 28, 3])
tf.reshape(a, [4, 784, 3]).shape
>>> TensorShape([4, 784, 3])
2、tf.transpose
a = tf.random.normal((4, 3, 2, 1))
tf.transpose(a).shape
>>> TensorShape([1, 2, 3, 4])
3、expand_dims
a = tf.random.normal([4, 35, 8])
tf.expand_dims(a, axis=0).shape
>>> TensorShape([1, 4, 35, 8])
八、Broadcasting
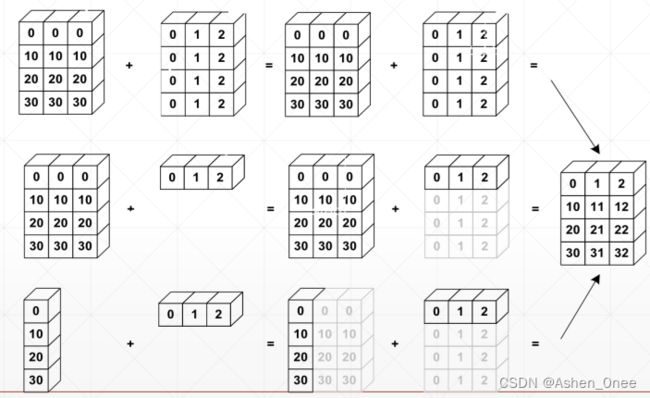
从最后一个维度开始匹配。
x = tf.random.normal([4, 32, 32, 3])
(x+tf.random.normal([4, 1, 1, 1])).shape
>>> TensorShape([4, 32, 32, 3])
(x+tf.random.normal([1, 4, 1, 1])).shape
>>> 2022-08-10 19:38:31.261422: W tensorflow/core/framework/op_kernel.cc:1733] INVALID_ARGUMENT: required broadcastable shapes
Traceback (most recent call last):
tensorflow.python.framework.errors_impl.InvalidArgumentError: required broadcastable shapes [Op:AddV2]
九、数学运算
- tf.math.log:
a = tf.ones([2, 2])
a
>>> <tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[1., 1.],
[1., 1.]], dtype=float32)>
tf.math.log(a)
>>> <tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[0., 0.],
[0., 0.]], dtype=float32)>
tf.math.log(8.) / tf.math.log(2.)
>>> <tf.Tensor: shape=(), dtype=float32, numpy=3.0>
tf.math.log(100.) / tf.math.log(10.)
>>> <tf.Tensor: shape=(), dtype=float32, numpy=2.0>
十、前向传播
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 加载数据集
# x: [60k, 28, 28]
# y: [60k]
(x, y), _ =datasets.mnist.load_data()
# 转换成Tensor
# x: [0~255] ==> [0, 1]
x = tf.convert_to_tensor(x, dtype=tf.float32) / 255.
y = tf.convert_to_tensor(y, dtype=tf.int32)
print(x.shape, y.shape, x.dtype, y.dtype)
print(tf.reduce_min(x), tf.reduce_max(x))
print(tf.reduce_min(y), tf.reduce_max(y))
train_db = tf.data.Dataset.from_tensor_slices((x, y)).batch(128)
train_iter = iter(train_db) # 迭代器
sample = next(train_iter)
print('batch: ', sample[0].shape, sample[1].shape)
# 权值
# [b, 784] ==> [b, 512] ==> [b, 128] ==> [b, 10]
# [dim_in, dim_out], [dim_out]
w1 = tf.Variable(tf.random.truncated_normal([784, 256], stddev=0.1))
b1 = tf.Variable(tf.zeros([256]))
w2 = tf.Variable(tf.random.truncated_normal([256, 128], stddev=0.1))
b2 = tf.Variable(tf.zeros([128]))
w3 = tf.Variable(tf.random.truncated_normal([128, 10], stddev=0.1))
b3 = tf.Variable(tf.zeros([10]))
lr = 1e-3
# 前向运算
for epoch in range(10): # 对整个数据集迭代
for step, (x, y) in enumerate(train_db): # 对每个 batch 迭代
# x: [128, 28, 28]
# y: [128]
# [b, 28, 28] ==> [b, 28*28]
x = tf.reshape(x, [-1, 28*28])
with tf.GradientTape() as tape: # 默认跟踪 tf.Variable
# x: [b, 28*28]
# h1 = x @ w1 + b1
# [b, 784] @ [784, 256] + [256] ==> [b, 256]
h1 = x @ w1 + tf.broadcast_to(b1, [x.shape[0], 256])
h1 = tf.nn.relu(h1)
# [b, 256] ==> [b, 128]
h2 = h1 @ w2 + b2
h2 = tf.nn.relu(h2)
# [b, 128] ==> [b, 10]
out = h2 @ w3 + b3
# 计算误差
# out: [b, 10]
# y: [b] ==> [b, 10]
y_onehot = tf.one_hot(y, depth=10)
# MSE = mean(sum(y - out)^2)
# [b, 10]
loss = tf.square(y_onehot - out)
# mean: scalar
loss = tf.reduce_mean(loss)
# 计算梯度
grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3])
# w1 = w1 - lr * w1'
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
w3.assign_sub(lr * grads[4])
b3.assign_sub(lr * grads[5])
if step % 100 == 0:
print(epoch, step, 'loss: ', float(loss))
>>> ……
>>> 9 400 loss: 0.08220599591732025