【合】Redis 实战篇——Redis 客户端(Jedis,Luttece,Redisson)
前言
起承转合,redis的篇章终于来到了结篇的篇章了,在【合】这个篇章中,我们将会通过redis的实战,包含redis的客户端,数据一致性以及高并发的问题来展开,学了之后,对工作和自己的知识体系都是很有帮助的噢~敬请期待~
正文
Redis 客户端
客户端通信原理
客户端和服务器通过 TCP 连接来进行数据交互, 服务器默认的端口号为 6379 。
客户端和服务器发送的命令或数据一律以 \r\n (CRLF 回车+换行)结尾。
如果使用 wireshark 对 jedis 抓包:
环境:Jedis 连接到虚拟机 202,运行 main,对 VMnet8 抓包。
过滤条件:ip.dst==192.168.8.202 and tcp.port in {6379} set ck 抓包:

可以看到实际发出的数据包是:
*3\r\n$3\r\nSET\r\n$8\r\nck\r\n$4\r\n2673\r\n
get ck 抓包:

*2\r\n$3\r\nGET\r\n$8\r\nck\r\n
客户端跟 Redis 之间 使用一种特殊的编码格式(在 AOF 文件里面我们看到了),叫做 Redis Serialization Protocol (Redis 序列化协议)。特点:容易实现、解析快、可读性强。客户端发给服务端的消息需要经过编码,服务端收到之后会按约定进行解码,反之亦然。
基于此,我们可以自己实现一个 Redis 客户端。
参考:myclient.MyClient.java
-
建立 Socket 连接
-
OutputStream 写入数据(发送到服务端)
-
InputStream 读取数据(从服务端接口)
基于这种协议,我们可以用 Java 实现所有的 Redis 操作命令。当然,我们不需要这么做,因为已经有很多比较成熟的 Java 客户端,实现了完整的功能和高级特性,并且提供了良好的性能。
https://redis.io/clients#java
官网推荐的 Java 客户端有 3 个 Jedis,Redisson 和 Luttuce。
| 客户端 | 描述 |
|---|---|
| Jedis | A blazingly small and sane redis java client |
| lettuce | Advanced Redis client for thread-safe sync, async, and reactive usage. Supports Cluster, Sentinel, Pipelining, and codecs. |
| Redisson | distributed and scalable Java data structures on top of Redis server |
Spring 连接 Redis 用的是什么?
RedisConnectionFactory 接口支持多种实现,例如: JedisConnectionFactory 、 JredisConnectionFactory、LettuceConnectionFactory、SrpConnectionFactory。
Jedis
https://github.com/xetorthio/jedis
特点
Jedis 是我们最熟悉和最常用的客户端。轻量,简洁,便于集成和改造。
BasicTest.java
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.set("ck", "2673");
System.out.println(jedis.get("ck"));
jedis.close();
}
Jedis 多个线程使用一个连接的时候线程不安全。可以使用连接池,为每个请求创建不同的连接,基于 Apache common pool 实现。跟数据库一样,可以设置最大连接数等参数。
Jedis 中有多种连接池的子类:
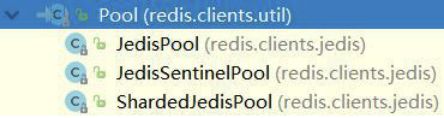
例如:ShardingTest.java
public static void main(String[] args) {
JedisPool pool = new JedisPool(ip, port);
Jedis jedis = jedisPool.getResource();
//
}
Jedis 有 4 种工作模式:单节点、分片、哨兵、集群。
3 种请求模式:Client、Pipeline、事务。Client 模式就是客户端发送一个命令,阻塞等待服务端执行,然后读取 返回结果。Pipeline 模式是一次性发送多个命令,最后一次取回所有的返回结果,这种模式通过减少网络的往返时间和 io 读写次数,大幅度提高通信性能。第三种是事务模式。Transaction 模式即开启 Redis 的事务管理,事务模式开启后,所有的命令(除了 exec,discard,multi 和 watch)到达服务端以后不会立即执行,会进入一个等待队列。
Sentinel 获取连接原理
问题:Jedis 连接 Sentinel 的时候,我们配置的是全部哨兵的地址。Sentinel 是如何返回可用的 master 地址的呢?
在构造方法中:
pool = new JedisSentinelPool(masterName, sentinels);
调用了:
HostAndPort master = initSentinels(sentinels, masterName);
查看:
private HostAndPort initSentinels(Set<String> sentinels, final String masterName) {
HostAndPort master = null;
boolean sentinelAvailable = false;
log.info("Trying to find master from available Sentinels...");
//有多个 sentinels,遍历这些个 sentinels
for (String sentinel : sentinels) {
//host:port 表示的 sentinel 地址转化为一个 HostAndPort 对象。
final HostAndPort hap = HostAndPort.parseString(sentinel);
log.fine("Connecting to Sentinel " + hap);
Jedis jedis = null;
try {
// 连接到 sentinel
jedis = new Jedis(hap.getHost(), hap.getPort());
//根据 masterName 得到 master 的地址,返回一个 list,
host= list[0], port =// list[1]
List<String> masterAddr = jedis.sentinelGetMasterAddrByName(masterName);
//connected to sentinel...
sentinelAvailable = true;
if (masterAddr == null || masterAddr.size() != 2) {
log.warning("Can not get master addr, master name: " + masterName + ". Sentinel: " + hap +"."); continue;
}
//如果在任何一个 sentinel 中找到了 master,不再遍历
sentinels master = toHostAndPort(masterAddr);
log.fine("Found Redis master at " + master); break;
} catch (JedisException e) {
//resolves #1036, it should handle JedisException there's another chance
//of raising JedisDataException
log.warning("Cannot get master address from sentinel running @ " + hap + ". Reason: " + e +". Trying next one.");
} finally {
if (jedis != null) {
jedis.close();
}
}
}
//到这里,如果 master 为 null,则说明有两种情况,一种是所有的 sentinels 节点都 down 掉了,一种是 master 节点没有被存活的 sentinels 监控到
if (master == null) {
if (sentinelAvailable) {
//can connect to sentinel, but master name seems to not
//monitored
throw new JedisException("Can connect to sentinel, but " + masterName+" seems to be not monitored...");
} else {
throw new JedisConnectionException("All sentinels down, cannot determine where is "+masterName + " master is running...");
}
}
//如果走到这里,说明找到了 master 的地址
log.info("Redis master running at " + master + ", starting Sentinel listeners...");
//启动对每个 sentinels 的监听为每个 sentinel 都启动了一个监听者 MasterListener。MasterListener 本身是一个线程,它会去订阅 sentinel 上关于 master 节点地址改变的消息。
for (String sentinel : sentinels) {
final HostAndPort hap = HostAndPort.parseString(sentinel);
MasterListener masterListener = new MasterListener(masterName, hap.getHost(), hap.getPort());
//whether MasterListener threads are alive or not, process can be stopped
masterListener.setDaemon(true);
masterListeners.add(masterListener);
masterListener.start();
}
return master;
}
Cluster 获取连接原理
问题:使用 Jedis 连接 Cluster 的时候,我们只需要连接到任意一个或者多个 redis group 中的实例地址,那我们是怎么获取到需要操作的 Redis Master 实例的?
关键问题:在于如何存储 slot 和 Redis 连接池的关系。
1、程序启动初始化集群环境,读取配置文件中的节点配置,无论是主从,无论多少个,只拿第一个,获取 redis 连接实例(后面有个 break)。
// redis.clients.jedis.JedisClusterConnectionHandler#initializeSlotsCache
private void initializeSlotsCache(Set<HostAndPort> startNodes, GenericObjectPoolConfig poolConfig, String password){
for (HostAndPort hostAndPort : startNodes) {
//获取一个 Jedis 实例
Jedis jedis = new Jedis(hostAndPort.getHost(), hostAndPort.getPort());
if (password != null) {
jedis.auth(password);
}
try {
// 获取 Redis 节点和 Slot 虚拟槽
cache.discoverClusterNodesAndSlots(jedis);
//直接跳出循环 break;
} catch (JedisConnectionException e) {
//try next nodes
} finally {
if (jedis != null) {
jedis.close();
}
}
}
2、用获取的 redis 连接实例执行 clusterSlots ()方法,实际执行 redis 服务端 cluster slots 命令,获取虚拟槽信息。
该集合的基本信息为[long, long, List, List], 第一,二个元素是该节点负责槽点的起始位置,第三个元素是主节点信息,第四个元素为主节点对应的从节点信息。
该 list 的基本信息为[string,int,string],第一个为 host 信息,第二个为 port 信息,第三个为唯一id。
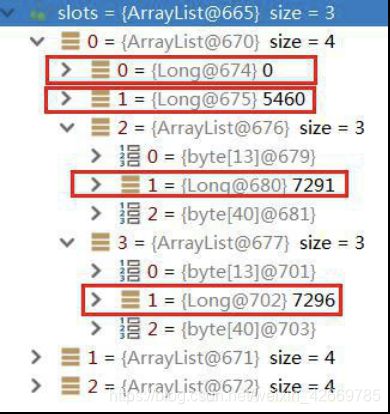
3、获取有关节点的槽点信息后,调用 getAssignedSlotArray(slotinfo)来获取所有的槽点值。
4、再获取主节点的地址信息,调用 generateHostAndPort(hostInfo)方法,生成一个 ostAndPort 对象。
5 、再根据节点地址信息来设置节点对应的 JedisPool ,即设置 Map
接下来判断若此时节点信息为主节点信息时,则调用 assignSlotsToNodes 方法,设置每个槽点值对应的连接池,即设置 Map
//redis.clients.jedis.JedisClusterInfoCache#discoverClusterNodesAndSlots
public void discoverClusterNodesAndSlots(Jedis jedis) {
w.lock();
try {
reset();
//获取节点集合
List<Object> slots = jedis.clusterSlots();
// 遍历 3 个 master 节点
for (Object slotInfoObj : slots) {
//slotInfo 槽开始,槽结束,主,从
//{[0,5460,7291,7294],[5461,10922,7292,7295],[10923,16383,7293,7296]}
List<Object> slotInfo = (List<Object>) slotInfoObj;
//如果<=2,代表没有分配 slot
if (slotInfo.size() <= MASTER_NODE_INDEX) {
continue;
}
//获取分配到当前 master 节点的数据槽,例如 7291 节点的{0,1,2,3……5460}
List<Integer> slotNums = getAssignedSlotArray(slotInfo);
// hostInfos
int size = slotInfo.size(); // size 是 4,槽最小最大,主,从
//第 3 位和第 4 位是主从端口的信息
for (int i = MASTER_NODE_INDEX; i < size; i++) {
List<Object> hostInfos = (List<Object>) slotInfo.get(i);
if (hostInfos.size() <= 0) {
continue;
}
// 根据 IP 端口生成 HostAndPort 实例
HostAndPort targetNode = generateHostAndPort(hostInfos);
//据 HostAndPort 解析出 ip:port 的 key 值,再根据 key 从缓存中查询对应的 jedisPool 实例。如果没有 jedisPool 实例,就创建 JedisPool 实例,最后放入缓存中。nodeKey 和 nodePool 的关系
setupNodeIfNotExist(targetNode);
//把 slot 和 jedisPool 缓存起来(16384 个),key 是 slot 下标,value 是连接池
if (i == MASTER_NODE_INDEX) {
assignSlotsToNode(slotNums, targetNode);
}
}
}
} finally {
w.unlock();
}
}
从集群环境存取值:
- 把 key 作为参数,执行 CRC16 算法,获取 key 对应的 slot 值。
- 通过该 slot 值,去 slots 的 map 集合中获取 jedisPool 实例。
- 通过 jedisPool 实例获取 jedis 实例,最终完成 redis 数据存取工作。
pipeline
前面我们实操的时候, 看到 set 2 万个 key 用了好几分钟,这个速度太慢了,完全没有把 Redis 10 万的 QPS 利用起来。但是单个命令的执行到底慢在哪里?
Redis 使用的是客户端/服务器(C/S)模型和请求/响应协议的 TCP 服务器。这意味着通常情况下一个请求会遵循以下步骤:
- 客户端向服务端发送一个查询请求,并监听 Socket 返回,通常是以阻塞模式,等待服务端响应。
- 服务端处理命令,并将结果返回给客户端。
Redis 客户端与 Redis 服务器之间使用 TCP 协议进行连接,一个客户端可以通过一个 socket 连接发起多个请求命令。每个请求命令发出后 client 通常会阻塞并等待 redis 服务器处理,redis 处理完请求命令后会将结果通过响应报文返回给 client,因此当执行多条命令的时候都需要等待上一条命令执行完毕才能执行。
执行过程如图:

Redis 本身提供了一些批量操作命令,比如 mget,mset,可以减少通信的时间,但是大部分命令是不支持 multi 操作的,例如 hash 就没有。
由于通信会有网络延迟,假如 client 和 server 之间的包传输时间需要 10 毫秒,一次交互就是 20 毫秒(RTT:Round Trip Time)。这样的话,client 1 秒钟也只能也只能发送 50 个命令。这显然没有充分利用 Redis 的处理能力。另外一个,Redis 服务端执行 I/O 的次数过多也会有影响。
Pipeline 管道
https://redis.io/topics/pipelining
那我们能不能像数据库的 batch 操作一样,把一组命令组装在一起发送给 Redis 服务端执行,然后一次性获得返回结果呢?这个就是 Pipeline 的作用。Pipeline 通过一个队列把所有的命令缓存起来,然后把多个命令在一次连接中发送给服务器。

先来看一下效果(先 flushall):
PipelineSet.java,PipelineGet.java
要实现 Pipeline,既要服务端的支持,也要客户端的支持。对于服务端来说,需要能够处理客户端通过一个 TCP 连接发来的多个命令,并且逐个地执行命令一起返回 。
对于客户端来说,要把多个命令缓存起来,达到一定的条件就发送出去,最后才处理 Redis 的应答(这里也要注意对客户端内存的消耗)。
jedis-pipeline 的 client-buffer 限制:8192bytes,客户端堆积的命令超过 8192 bytes 时,会发送给服务端。
源码:redis.clients.util.RedisOutputStream.java
public RedisOutputStream(final OutputStream out) {
this(out, 8192);
}
pipeline 对于命令条数没有限制,但是命令可能会受限于 TCP 包大小。
如果 Jedis 发送了一组命令,而发送请求还没有结束,Redis 响应的结果会放在接收缓冲区。如果接收缓冲区满了,jedis 会通知 redis win=0,此时 redis 不会再发送结果给 jedis 端,转而把响应结果保存在 Redis 服务端的输出缓冲区中。
输出缓冲区的配置:redis.conf
client-output-buffer-limit
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit replica 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
| 配置 | 作用 |
|---|---|
| class | 客户端类型,分为三种。 a)normal:普通客户端; b)slave:slave 客户端,用于复制; c)pubsub:发布订阅客户端 |
| hard limit | 如果客户端使用的输出缓冲区大于,客户端会被立即关闭,0 代表不限制 |
| soft limit | 如果客户端使用的输出缓冲区超过了并且持续了秒,客户端会被立即 |
| soft seconds | 关闭 |
每个客户端使用的输出缓冲区的大小可以用 client list 命令查看
redis> client list
id=5 addr=192.168.8.1:10859 fd=8 name= age=5 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=5 qbuf-free=32763 obl=16380 oll=227 omem=4654408 events=rw cmd=set
-
obl : 输出缓冲区的长度(字节为单位, 0 表示没有分配输出缓冲区)
-
oll : 输出列表包含的对象数量(当输出缓冲区没有剩余空间时,命令回复会以字符串对象的形式被入队到这个队列里)
-
omem : 输出缓冲区和输出列表占用的内存总量
使用场景
- Pipeline 适用于什么场景呢?
如果某些操作需要马上得到 Redis 操作是否成功的结果,这种场景就不适合。
有些场景,例如批量写入数据,对于结果的实时性和成功性要求不高,就可以用Pipeline。
Jedis 实现分布式锁
原文地址:https://redis.io/topics/distlock
中文地址:http://redis.cn/topics/distlock.html
分布式锁的基本特性或者要求:
-
互斥性:只有一个客户端能够持有锁。
-
不会产生死锁:即使持有锁的客户端崩溃,也能保证后续其他客户端可以获取锁。
-
只有持有这把锁的客户端才能解锁。
distlock.DistLock.java
public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) {
// set 支持多个参数 NX(not exist) XX(exist) EX(seconds) PX(million seconds)
String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime);
if (LOCK_SUCCESS.equals(result)) {
return true;
}
return false;
}
参数解读:
-
lockKey 是 Redis key 的名称,也就是谁添加成功这个 key 代表谁获取锁成功。
-
requestId 是客户端的 ID(设置成 value),如果我们要保证只有加锁的客户端才能释放锁,就必须获得客户端的 ID(保证第 3 点)。
-
SET_IF_NOT_EXIST 是我们的命令里面加上 NX(保证第 1 点)。
-
SET_WITH_EXPIRE_TIME,PX 代表以毫秒为单位设置 key 的过期时间(保证第 2 点)。expireTime 是自动释放锁的时间,比如 5000 代表 5 秒。
释放锁,直接删除 key 来释放锁可以吗?就像这样:
public static void wrongReleaseLock1(Jedis jedis, String lockKey) {
jedis.del(lockKey);
}
没有对客户端 requestId 进行判断,可能会释放其他客户端持有的锁。先判断后删除呢?
public static void wrongReleaseLock2(Jedis jedis, String lockKey, String requestId) {
//判断加锁与解锁是不是同一个客户端
if (requestId.equals(jedis.get(lockKey))) {
//若在此时,这把锁突然不是这个客户端的,则会误解锁
jedis.del(lockKey);
}
}
如果在释放锁的时候,这把锁已经不属于这个客户端(例如已经过期,并且被别的客户端获取锁成功了),那就会出现释放了其他客户端的锁的情况。
所以我们把判断客户端是否相等和删除 key 的操作放在 Lua 脚本里面执行。
public static boolean releaseDistributedLock(Jedis jedis, String lockKey, String requestId) {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(requestId));
if (RELEASE_SUCCESS.equals(result)) {
return true;
}
return false;
}
这个是 Jedis 里面分布式锁的实现。
我们了解了一下 Jedis 的使用和实现,在 ck-jedis 里面还有很多其他的案例,大家可以再去学习一下。
Luttece
https://lettuce.io/
特点
与 Jedis 相比,Lettuce 则完全克服了其线程不安全的缺点:Lettuce 是一个可伸缩的线程安全的 Redis 客户端,支持同步、异步和响应式模式(Reactive)。多个线程可以共享一个连接实例,而不必担心多线程并发问题。
同步调用
异步的结果使用 RedisFuture 包装,提供了大量回调的方法。
异步调用
它基于 Netty 框架构建,支持 Redis 的高级功能,如 Pipeline、发布订阅,事务、Sentinel,集群,支持连接池。
Lettuce 是 Spring Boot 2.x 默认的客户端,替换了 Jedis。集成之后我们不需要单独使用它,直接调用 Spring 的 RedisTemplate 操作,连接和创建和关闭也不需要我们操心。
org.springframework.boot
spring-boot-starter-data-redis
Redisson
https://redisson.org/
https://github.com/redisson/redisson/wiki/目录
本质
Redisson 是一个在 Redis 的基础上实现的 Java 驻内存数据网格(In-Memory Data Grid),提供了分布式和可扩展的 Java 数据结构。
特点
-
基于 Netty 实现,采用非阻塞 IO,性能高
-
支持异步请求
-
支持连接池、pipeline、LUA Scripting、Redis Sentinel、Redis Cluster 不支持事务,官方建议以 LUA Scripting 代替事务
-
主从、哨兵、集群都支持。Spring 也可以配置和注入 RedissonClient。
实现分布式锁
在 Redisson 里面提供了更加简单的分布式锁的实现。
加锁:
public static void main(String[] args) throws InterruptedException {
RLock rLock=redissonClient.getLock("updateAccount");
//最多等待 100 秒、上锁 10s 以后自动解锁
if(rLock.tryLock(100,10, TimeUnit.SECONDS)){
System.out.println("获取锁成功");
}
//do something
rLock.unlock();
}
在获得 RLock 之后,只需要一个 tryLock 方法,里面有 3 个参数:
1、watiTime:获取锁的最大等待时间,超过这个时间不再尝试获取锁
2、leaseTime:如果没有调用 unlock,超过了这个时间会自动释放锁
3、TimeUnit:释放时间的单位
Redisson 的分布式锁是怎么实现的呢?
在加锁的时候,在 Redis 写入了一个 HASH,key 是锁名称,field 是线程名称,value是 1(表示锁的重入次数)。
源码:
tryLock()——tryAcquire()——tryAcquireAsync()——tryLockInnerAsync()
最终也是调用了一段 Lua 脚本。里面有一个参数,两个参数的值。
| 占位 | 填充 | 含义 | 实际值 |
|---|---|---|---|
| KEYS[1] | getName() | 锁的名称(key) | updateAccount |
| ARGV[1] | internalLockLeaseTime | 锁释放时间(毫秒) | 10000 |
| ARGV[2] | getLockName(threadId) | 线程名称 | b60a9c8c-92f8-4bfe-b0e7-308967346336:1 |
//KEYS[1] 锁名称 updateAccount
//ARGV[1] key 过期时间 10000ms
//ARGV[2] 线程名称
//锁名称不存在
if (redis.call('exists', KEYS[1]) == 0) then
//创建一个 hash,key=锁名称,field=线程名,value=1
redis.call('hset', KEYS[1], ARGV[2], 1);
//设置 hash 的过期时间
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
//锁名称存在,判断是否当前线程持有的锁
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
//如果是,value+1,代表重入次数+1
redis.call('hincrby', KEYS[1], ARGV[2], 1);
//重新获得锁,需要重新设置 Key 的过期时间
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
//锁存在,但是不是当前线程持有,返回过期时间(毫秒)
return redis.call('pttl', KEYS[1]);
释放锁,源码:
unlock——unlockInnerAsync
| 占位 | 填充 | 含义 | 实际值 |
|---|---|---|---|
| KEYS[1] | getName() | 锁名称 | updateAccount |
| KEYS[2] | getChannelName() | 频道名称 | redisson_lock__channel:{updateAccount} |
| ARGV[1] | LockPubSub.unlockMessage | 解锁时的消息 | 0 |
| ARGV[2] | internalLockLeaseTime | 释放锁的时间 | 10000 |
| ARGV[3] | getLockName(threadId) | 线程名称 | b60a9c8c-92f8-4bfe-b0e7-308967346336:1 |
//KEYS[1] 锁的名称 updateAccount
//KEYS[2] 频道名称 redisson_lock__channel:{updateAccount}
//ARGV[1] 释放锁的消息 0
//ARGV[2] 锁释放时间 10000
//ARGV[3] 线程名称
//锁不存在(过期或者已经释放了)
if (redis.call('exists', KEYS[1]) == 0) then
//发布锁已经释放的消息
redis.call('publish', KEYS[2], ARGV[1]);
return 1;
end;
//锁存在,但是不是当前线程加的锁
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then
return nil;
end;
//锁存在,是当前线程加的锁
//重入次数-1
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
//-1 后大于 0,说明这个线程持有这把锁还有其他的任务需要执行
if (counter > 0) then
//重新设置锁的过期时间
redis.call('pexpire', KEYS[1], ARGV[2]);
return 0;
else
//-1 之后等于 0,现在可以删除锁了
redis.call('del', KEYS[1]);
//删除之后发布释放锁的消息
redis.call('publish', KEYS[2], ARGV[1]);
return 1;
end;
//其他情况返回 nil
return nil;
这个是 Redisson 里面分布式锁的实现,我们在调用的时候非常简单。
Redisson 跟 Jedis 定位不同,它不是一个单纯的 Redis 客户端,而是基于 Redis 实现的分布式的服务,如果有需要用到一些分布式的数据结构,比如我们还可以基于Redisson 的分布式队列实现分布式事务,就可以引入 Redisson 的依赖实现。
By the way
有问题?可以给我留言或私聊
有收获?那就顺手点个赞呗~
想找工作机会也可以联系我噢~
当然,也可以到我的公众号下「6曦轩」,
回复“学习”,即可领取一份
【Java工程师进阶架构师的视频教程】~
回复“面试”,可以获得:
【本人呕心沥血整理的 Java 面试题】
回复“MySQL脑图”,可以获得
【MySQL 知识点梳理高清脑图】
还有【阿里云】【腾讯云】的购买优惠噢~具体请联系我
曦轩我是科班出身的程序员,php,Android以及硬件方面都做过,不过最后还是选择专注于做 Java,所以有啥问题可以到公众号提问讨论(技术情感倾诉都可以哈哈哈),看到的话会尽快回复,希望可以跟大家共同学习进步,关于服务端架构,Java 核心知识解析,职业生涯,面试总结等文章会不定期坚持推送输出,欢迎大家关注~~~
