036、目标检测-锚框
之——对边缘框的简化
目录
之——对边缘框的简化
杂谈
正文
1.锚框操作
2.IoU交并比
3.锚框标号
4.非极大值抑制
5.实现
拓展
杂谈
边缘框这样一个指定roi区域的操作对卷积神经网络实际上是很不友好的,这可能会对网络感受野提出一些特定的要求,所以诞生了锚框的技术:
锚框(Anchor Box),也被称为先验框(Prior Box),是目标检测领域中一种用于提高模型准确性的技术。目标检测任务涉及识别图像中的对象并定位它们的位置。锚框在这方面发挥了关键作用。
在目标检测任务中,模型通常需要为图像中的每个位置预测对象的存在以及其边界框(bounding box)。锚框的作用是为模型提供一组预定义的框,这些框具有不同的大小和宽高比。模型通过这些锚框进行预测,然后根据实际目标的位置和形状进行调整。
以下是锚框的一些关键概念和作用:
多尺度和宽高比: 锚框通常涵盖了多个尺度和宽高比,以适应不同大小和形状的目标。这使得模型能够更好地适应各种对象的特征。
预测框的基准: 锚框充当了模型预测目标框的基准。模型会输出一个较为粗糙的框,然后通过与相应的锚框进行比较,进而调整和修正最终的边界框。
位置敏感性: 锚框使模型能够在图像的不同区域检测目标,而不仅仅是在固定位置。这提高了模型对目标位置变化的适应能力。
减少计算量: 锚框可以减少模型需要预测的边界框数量,从而减少计算复杂度。相较于在图像的每个位置都预测一个框,使用锚框可以更有效地处理目标检测任务。
锚框技术广泛应用于基于深度学习的目标检测方法,如Faster R-CNN、SSD(Single Shot Multibox Detector)和YOLO(You Only Look Once)等。这些方法通过锚框提高了模型在复杂场景中检测目标的能力,使其更具鲁棒性和泛化性。
锚框使得神经网络可以从不同尺度去关注图片以确定最好的物体roi。
正文
1.锚框操作
很多目标检测算法都是基于锚框的:
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边界从而更准确地预测目标的真实边界框(ground-truth bounding box)。 不同的模型使用的区域采样方法可能不同。 这里我们介绍其中的一种方法:以每个像素为中心,生成多个缩放比和宽高比(aspect ratio)不同的边界框。 这些边界框被称为锚框(anchor box)。

可以理解为,当图片进来的时候,需要有一个算法来衡量我要关注的区域,因为各个图片感兴趣的物体的大小肯定是不一样的,那么对于每一个图片就需要生成一些区域来投入到卷积网络中。 这更多的是为了解决预测时候的需求,因为预测时候才会需要考虑各个尺寸的框。
2.IoU交并比
度量两个框之间的相似度:
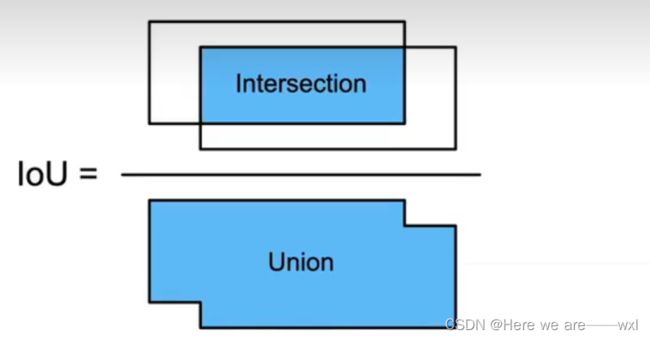
IoU,或称为交并比(Intersection over Union),是在目标检测和图像分割等计算机视觉任务中常用的评估指标之一。它用于衡量模型预测的两个框之间的重叠程度。
IoU的计算方式是通过目标的真实区域(或边界框)和模型预测的区域的交集面积除以它们的并集面积得到的。具体而言,IoU的计算公式如下:
IoU的取值范围在0到1之间,通常以百分比表示。值越大,表示两个框重叠程度越高,因此训练的时候IoU越大通常意味着模型的性能越好。
在目标检测任务中,通常将IoU用作评估模型在定位目标方面的准确性的指标。一般来说,训练时候,当模型某一锚框样本的置信度达到一定阈值,且与真实框IoU达到一定阈值(例如0.5或0.75)时,认为模型的预测是正确的。
测试时候,也常用于非极大值抑制(Non-Maximum Suppression,NMS)阶段,以过滤掉IoU低于阈值的冗余边界框,从而提高检测结果的质量。
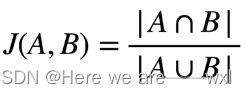
3.锚框标号
要对每个锚框进行预测,要么认为是背景什么都没有,要么跟某一个真实类关联并标注差距,这是在训练时候需要的:

通过计算所有锚框与真实边缘框的IoU,找到最大值,可以绑定锚框和边缘框的类别:

注意看上面的过程,每次读取一张图片都会按照锚框数生成多个训练样本,所以才需要进行锚框标号,将与真实边缘框相关的锚框赋予类别,但一个锚框又只能用一次,所以才会这样做 ,要保证每个真实框被分配到一个或多个锚框,其他低于要求的锚框变成负样本,这样就可以一次性处理所有生成的锚框并给他们赋予类别。上面这种方案比较极端,只保留了和真实框最接近的锚框,实际情况肯定是有阈值的。
在目标检测任务中,使用锚框的目的是通过预定义的一组框来提高模型的泛化能力和训练效果。将锚框赋予标号后,通常会采用两阶段的方法:
生成锚框: 在训练之前,使用一些先验知识(比如目标的大小和形状分布)生成一组锚框,这些锚框覆盖了图像中可能出现目标的多种尺寸和宽高比。这组锚框充当了模型的预测目标的基准。
赋予标号: 将这些锚框与真实目标进行匹配,赋予标号。匹配的标准通常是通过计算IoU(交并比)来判断一个锚框与真实目标的重叠程度。如果IoU高于某个阈值,就将锚框标记为正样本,表示这个锚框内有目标。如果IoU低于另一个阈值,将锚框标记为负样本,表示这个锚框内没有目标。对于中间情况,可以根据具体的情况进行处理,例如,有的方法会将这些框排除在训练中,而有的方法则将其视为中性样本。
训练模型: 使用带有标号的锚框进行训练。正样本用于训练模型识别目标和调整边界框的位置,负样本用于训练模型辨别图像中不包含目标的区域。这种两阶段的训练方式有助于模型学习如何准确地预测目标的位置。
直接使用真实边界框进行训练存在一些问题。首先,如果直接使用真实边界框,模型可能会过于依赖这些具体的框,而泛化能力较差。其次,由于目标的尺寸和形状变化较大,事先定义一组具有多样性的锚框能够更好地覆盖不同的情况。
因此,通过为锚框赋予标号,并采用两阶段的训练方式,可以更好地引导模型学习目标的特征,提高模型的泛化性能。
4.非极大值抑制
原理:

步骤就是,要输出时候,对于每一个锚框,也就是先验框,先去掉属于背景的(保留 softmax有类别输出的);然后确定softmax预测最大值也就是置信度最高的类别;然后去掉所有其他和这个框的IoU值过大的框(去掉重复的)。
5.实现
对于每个像素为中心,生成不同宽度和高度的锚框:
import torch
from d2l import torch as d2l
torch.set_printoptions(2) # 精简输出精度
def multibox_prior(data, sizes, ratios):
"""生成以每个像素为中心具有不同形状的锚框"""
in_height, in_width = data.shape[-2:]
device, num_sizes, num_ratios = data.device, len(sizes), len(ratios)
boxes_per_pixel = (num_sizes + num_ratios - 1)
size_tensor = torch.tensor(sizes, device=device)
ratio_tensor = torch.tensor(ratios, device=device)
# 为了将锚点移动到像素的中心,需要设置偏移量。
# 因为一个像素的高为1且宽为1,我们选择偏移我们的中心0.5
offset_h, offset_w = 0.5, 0.5
steps_h = 1.0 / in_height # 在y轴上缩放步长
steps_w = 1.0 / in_width # 在x轴上缩放步长
# 生成锚框的所有中心点
center_h = (torch.arange(in_height, device=device) + offset_h) * steps_h
center_w = (torch.arange(in_width, device=device) + offset_w) * steps_w
shift_y, shift_x = torch.meshgrid(center_h, center_w, indexing='ij')
shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1)
# 生成“boxes_per_pixel”个高和宽,
# 之后用于创建锚框的四角坐标(xmin,xmax,ymin,ymax)
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),
sizes[0] * torch.sqrt(ratio_tensor[1:])))\
* in_height / in_width # 处理矩形输入
h = torch.cat((size_tensor / torch.sqrt(ratio_tensor[0]),
sizes[0] / torch.sqrt(ratio_tensor[1:])))
# 除以2来获得半高和半宽
anchor_manipulations = torch.stack((-w, -h, w, h)).T.repeat(
in_height * in_width, 1) / 2
# 每个中心点都将有“boxes_per_pixel”个锚框,
# 所以生成含所有锚框中心的网格,重复了“boxes_per_pixel”次
out_grid = torch.stack([shift_x, shift_y, shift_x, shift_y],
dim=1).repeat_interleave(boxes_per_pixel, dim=0)
output = out_grid + anchor_manipulations
return output.unsqueeze(0)查看:
img = d2l.plt.imread('../img/catdog.jpg')
h, w = img.shape[:2]
print(h, w)
X = torch.rand(size=(1, 3, h, w))
Y = multibox_prior(X, sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5])
Y.shape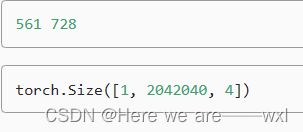
非常贵的锚框数量。
拓展
其他的一些方法:
- 直接把图片隔开成很多个块预测
- 对每个像素中去比例预测
- 其他的聚焦方法