分布式锁——分布式锁的优化过程、分布式锁+AOP实现Redis缓存
分布式锁的优化流程以及结合AOP实现缓存
一、配置Redis缓存
1、为什么使用缓存
一个系统最大的性能瓶颈就是数据库的IO操作,从数据库入手也是调优的最好的切入点。
提高数据库的性能分为两部分
-
一是提高数据库SQL本身的性能,包括:使用索引,减少不必要的大表关联次数,控制查询字段的行数和列数。另外当数据量巨大是可以考虑分库分表,以减轻单点压力。
-
二是尽量避免频繁的查询数据库,解决的办法是缓存,任何请求只要能在缓存命中就不会直接查询数据库,缓存的出库性能是数据的10-100倍
2、SpringBoot整合Redis
由于redis作为缓存数据库,要被多个项目使用,所以要制作一个通用的工具类,方便工程中的各个模块使用。
依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
<version>2.6.0version>
dependency>
reids配置类
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.cache.interceptor.KeyGenerator;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import java.lang.reflect.Method;
import java.time.Duration;
/**
* Redis配置类
*
*/
@Configuration
@EnableCaching
public class RedisConfig {
// 使用默认标签做缓存
@Bean
public KeyGenerator wiselyKeyGenerator() {
return new KeyGenerator() {
@Override
public Object generate(Object target, Method method, Object... params) {
StringBuilder sb = new StringBuilder();
sb.append(target.getClass().getName());
sb.append(method.getName());
for (Object obj : params) {
sb.append(obj.toString());
}
return sb.toString();
}
};
}
// 声明模板
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(objectMapper);
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置序列化(解决乱码的问题),过期时间600秒
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(600))
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))
.disableCachingNullValues();
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.cacheDefaults(config)
.build();
return cacheManager;
}
}
3、使用Redis进行业务开发
于Redis不像数据库表那样有结构,其所有的数据全靠key进行索引,所以redis数据的可读性,全依靠key。
企业中最常用的方式就是:object:对象id:field
比如:sku:1314:info
user:1092:info
/**
* Redis常量配置类示例
*
*/
public class RedisConst {
public static final String SKUKEY_PREFIX = "sku:";
public static final String SKUKEY_SUFFIX = ":info";
//单位:秒
public static final long SKUKEY_TIMEOUT = 24 * 60 * 60;
//单位:秒 尝试获取锁的最大等待时间
public static final long SKULOCK_EXPIRE_PX1 = 1;
//单位:秒 锁的持有时间
public static final long SKULOCK_EXPIRE_PX2 = 1;
public static final String SKULOCK_SUFFIX = ":lock";
public static final String USER_KEY_PREFIX = "user:";
public static final String USER_CART_KEY_SUFFIX = ":cart";
public static final long USER_CART_EXPIRE = 60 * 60 * 24 * 7;
//用户登录
public static final String USER_LOGIN_KEY_PREFIX = "user:login:";
// public static final String userinfoKey_suffix = ":info";
public static final int USERKEY_TIMEOUT = 60 * 60 * 24 * 7;
//秒杀商品前缀
public static final String SECKILL_GOODS = "seckill:goods";
public static final String SECKILL_ORDERS = "seckill:orders";
public static final String SECKILL_ORDERS_USERS = "seckill:orders:users";
public static final String SECKILL_STOCK_PREFIX = "seckill:stock:";
public static final String SECKILL_USER = "seckill:user:";
//用户锁定时间 单位:秒
public static final int SECKILL__TIMEOUT = 60 * 60 * 1;
}
实现缓存的流程
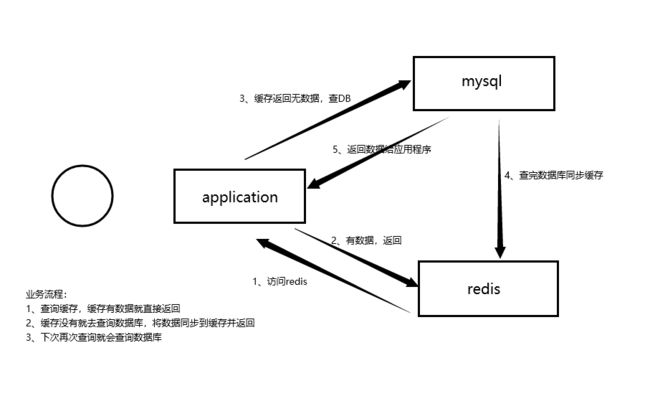
4 缓存常见问题(面试)
缓存最常见的3个问题:
-
缓存穿透
缓存穿透: 是指查询一个不存在的数据,由于缓存无法命中,将去查询数据库,但是数据库也无此记录,并且出于容错考虑,我们没有将这次查询的null写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
解决方案:空结果也进行缓存,但它的过期时间会很短,最长不超过五分钟。
-
缓存雪崩
缓存雪崩:是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决方案:原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
-
缓存击穿
缓存击穿: 是指对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:如果这个key在大量请求同时进来之前正好失效,那么所有对这个key的数据查询都落到db,我们称为缓存击穿。
注意: 与缓存雪崩的区别:
-
击穿是一个热点key失效
-
雪崩是很多key集体失效
解决方案:锁
-
二、分布式锁的优化流程
1、微服务单点下,不使用锁的缓存
Service层模拟redis的key存在时,每访问一次value值自增1
//Service层:
@Resource
private RedisTemplate redisTemplate;
@Override
public void setRedis() {
Integer i = (Integer) redisTemplate.opsForValue().get("java0924");
if (i != null) {
i++;
redisTemplate.opsForValue().set("java0924",i);
}
}
//controller层:
@GetMapping("/testRedis")
public Result test(){
testService.setRedis();
return Result.ok();
}
测试结果:
(1)使用浏览器单次访问正常,value值可以自增1
(2)使用ab工具模拟多请求并发测试
之前在redis中,玩过ab测试工具:httpd-tools(yum install -y httpd-tools)
# ab -n(一次发送的请求数) -c(请求的并发数) 访问路径
# 5000请求,100并发
ab -n 5000 -c 100 http://192.168.200.1:8206/api/product/test/testRedis
可以发现redis中key对应的value值没有自增到5000
结论:
不加锁时在并发下存在时间差,导致同一时间很多操作同时进行
2、微服务单点下,使用本地锁
使用本地锁解决并发问题,保证同一时间只能有一个请求操作数据
//修改Service代码,加上同步关键字,排他锁
@Override
public synchronized void setRedis() {
Integer i = (Integer) redisTemplate.opsForValue().get("java0924");
if (i != null) {
i++;
redisTemplate.opsForValue().set("java0924",i);
}
}
使用ab工具压力测试:5000次请求,并发100
ab -n 5000 -c 100 http://192.168.200.1:8206/api/product/test/testRedis
测试结果:
value值自增到了5000,并发问题解决
新问题:
本地锁能解决并发问题,但是一旦微服务成为集群,本地锁就会失效
接下来启动8206 8216 8226 三个运行实例。
运行多个service-product实例模拟微服务集群:

通过网关压力测试:
启动网关:
ab -n 5000 -c 100 http://192.168.200.1/redis/product/test/demo1
查看redis中的值:

以上测试,可以发现:
本地锁只能锁住同一工程内的资源,在分布式系统里面都存在局限性。
此时需要分布式锁
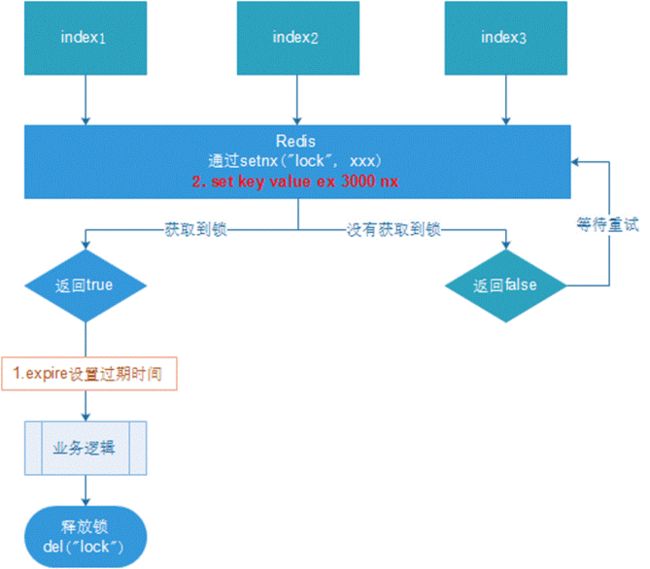
3、微服务集群,setnx分布式锁
分布式锁主流的实现方案:
-
基于数据库实现分布式锁
-
基于缓存(Redis等)
-
基于Zookeeper
每一种分布式锁解决方案都有各自的优缺点:
-
性能:redis最高
-
可靠性:zookeeper最高
使用Redis实现分布式锁
set设置值,值存在就覆盖值
setNX如果key存在则set失败,不存在才设置成功
setXX如果key不存在set失败,存在就覆盖

//修改service的方法,使用分布式锁
@Override
public void setRedis() {
//添加锁
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "lock");
if (lock) {
Integer i = (Integer) redisTemplate.opsForValue().get("java0924");
if (i != null) {
i++;
redisTemplate.opsForValue().set("java0924",i);
//释放锁
redisTemplate.delete("lock");
}
} else {
try {
//线程休息后重试方法
Thread.sleep(1000);
setRedis();//重新调用一次方法
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
重启,服务集群,通过网关使用ab工具进行压力测试
测试结果:
微服务下key对应的value值可以自增到5000
新问题:
当前方法获取锁以后,可能因为业务问题抛异常被捕获,但是还没有执行释放锁操作,导致锁一直不能被别人使用,造成死锁
==解决:设置过期时间,自动释放锁。==不至于让锁一直在同一个人手里
4、微服务集群,setnx分布式锁,同时设置过期时间
- 在set时指定过期时间(推荐)
设置过期时间:
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "lock",10, TimeUnit.SECONDS);
测试结果:
并发测试没问题
新问题:
误删锁,删掉别人的锁
场景:如果业务逻辑的执行时间是7s。执行流程如下
-
index1业务逻辑没执行完,3秒后锁被自动释放。
-
index2获取到锁,执行业务逻辑,3秒后锁被自动释放。
-
index3获取到锁,执行业务逻辑
-
index1业务逻辑执行完成,开始调用del释放锁,这时释放的是index3的锁,导致index3的业务只执行1s就被别人释放。
最终等于没锁的情况。
解决:setnx获取锁时,设置一个指定的唯一值(例如:uuid);释放前获取这个值,判断是否自己的锁
5、微服务集群,setnx分布式锁,设置过期时间,设置UUID防误删

//优化service代码
//使用UUID来指定锁的值,删除的时候核对是不是自己的,自己上的锁只能自己删
String uuid = UUID.randomUUID().toString().replace("_", "");
//添加锁:设置过期时间防止死锁
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid,10, TimeUnit.SECONDS);
新问题:
问题:删除操作缺乏原子性。
场景:
- index1执行删除时,查询到的lock值确实和uuid相等
uuid=v1
set(lock,uuid);
- index1执行删除前,lock刚好过期时间已到,被redis自动释放
在redis中没有了lock,没有了锁。
- index2获取了lock
index2线程获取到了cpu的资源,开始执行方法
uuid=v2
set(lock,uuid);
- index1执行删除,此时会把index2的lock删除
index1 因为已经在方法中了,所以不需要重新上锁。index1有执行的权限。index1已经比较完成了,这个时候,开始执行删除
删除的index2的锁
6、微服务集群, 优化之LUA脚本保证删除的原子性
lua脚本
if redis.call('get', KEYS[1]) == ARGV[1] then
return redis.call('del', KEYS[1])
else
return 0
end
service代码优化
@Override
public void setRedis() {
String uuid = UUID.randomUUID().toString().replace("_", "");
//添加锁:设置过期时间防止死锁
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid,10, TimeUnit.SECONDS);
if (lock) {
Integer i = (Integer) redisTemplate.opsForValue().get("java0924");
if (i != null) {
i++;
redisTemplate.opsForValue().set("java0924",i);
//释放锁
//核对是不是自己的锁
// String lock1 = (String) redisTemplate.opsForValue().get("lock");
// if (uuid.equals(lock1)) {
// //释放锁
// redisTemplate.delete("lock");
// }
//使用lua脚本保持操作的原子性
DefaultRedisScript<Long> script = new DefaultRedisScript<>();
//设置lua脚本
script.setScriptText("if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end");
//设置返回类型
script.setResultType(Long.class);
//执行脚本释放锁
redisTemplate.execute(script, Arrays.asList("lock"),uuid);
}
} else {
try {
//线程休息后重试方法
Thread.sleep(1000);
setRedis();//重新调用一次方法
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
总结
为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件:
-
互斥性: 在任意时刻,只有一个客户端能持有锁;
-
不会发生死锁: 即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁;
-
解铃还须系铃人: 加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了;
-
加锁和解锁必须具有原子性;
7、使用redisson 解决分布式锁
Github 地址:https://github.com/redisson/redisson
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。其中包括(BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service) Redisson提供了使用Redis的最简单和最便捷的方法。Redisson的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。
官方文档地址:https://github.com/redisson/redisson/wiki
7.1 实现代码
<dependency>
<groupId>org.redissongroupId>
<artifactId>redissonartifactId>
<version>3.11.2version>
dependency>
import lombok.Data;
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.redisson.config.SingleServerConfig;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.util.StringUtils;
/**
* redisson配置信息
*/
@Data
@Configuration
@ConfigurationProperties("spring.redis")
public class RedissonConfig {
private String host;
private String addresses;
private String password;
private String port;
private int timeout = 3000;
private int connectionPoolSize = 64;
private int connectionMinimumIdleSize=10;
private int pingConnectionInterval = 60000;
private static String ADDRESS_PREFIX = "redis://";
/**
* 自动装配
*
*/
@Bean
RedissonClient redissonSingle() {
Config config = new Config();
if(StringUtils.isEmpty(host)){
throw new RuntimeException("host is empty");
}
SingleServerConfig serverConfig = config.useSingleServer()
.setAddress(ADDRESS_PREFIX + this.host + ":" + port)
.setTimeout(this.timeout)
.setPingConnectionInterval(pingConnectionInterval)
.setConnectionPoolSize(this.connectionPoolSize)
.setConnectionMinimumIdleSize(this.connectionMinimumIdleSize);
if(!StringUtils.isEmpty(this.password)) {
serverConfig.setPassword(this.password);
}
return Redisson.create(config);
}
}
7.2 可重入锁(Reentrant Lock)
基于Redis的Redisson分布式可重入锁RLock Java对象实现了java.util.concurrent.locks.Lock接口。
大家都知道,如果负责储存这个分布式锁的Redisson节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是30秒钟,也可以通过修改Config.lockWatchdogTimeout来另行指定。
另外Redisson还通过加锁的方法提供了leaseTime的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
快速入门使用的就是可重入锁。也是最常使用的锁。
//最常见的使用:
RLock lock = redisson.getLock("anyLock");
// 最常使用
lock.lock();
// 加锁以后10秒钟自动解锁 // 无需调用unlock方法手动解锁
lock.lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) { try { ... } finally { lock.unlock(); } }
改造程序本次的测试程序:
@Autowired
private RedissonClient redissonClient;
@Override
public void testRedisson() {
//获取锁
RLock lock = redissonClient.getLock("lock");
//抢锁
try {
//10秒内一值尝试加锁
if (lock.tryLock(30,10,TimeUnit.SECONDS)) {
//拿到锁
try {
Integer i = (Integer) redisTemplate.opsForValue().get("java0924");
if (i != null) {
i++;
redisTemplate.opsForValue().set("java0924",i);
}
} catch (Exception e) {
System.out.println("业务出错");
e.printStackTrace();
} finally {
//释放锁---lua表达式
lock.unlock();
}
}
} catch (InterruptedException e) {
System.out.println("抢锁失败");
e.printStackTrace();
}
}
重启使用浏览器和ab工具测试
7.3 读写锁(ReadWriteLock)
基于Redis的Redisson分布式可重入读写锁RReadWriteLock Java对象实现了java.util.concurrent.locks.ReadWriteLock接口。其中读锁和写锁都继承了RLock接口。
分布式可重入读写锁允许同时有多个读锁和一个写锁处于加锁状态。
RReadWriteLock rwlock = redisson.getReadWriteLock("anyRWLock");
// 最常见的使用方法
rwlock.readLock().lock();
// 或
rwlock.writeLock().lock();
// 10秒钟以后自动解锁
// 无需调用unlock方法手动解锁
rwlock.readLock().lock(10, TimeUnit.SECONDS);
// 或
rwlock.writeLock().lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = rwlock.readLock().tryLock(100, 10, TimeUnit.SECONDS);
// 或
boolean res = rwlock.writeLock().tryLock(100, 10, TimeUnit.SECONDS);
...
lock.unlock();
测试
/**
* 读锁
*
* @return
*/
@Override
public String readLock() {
RReadWriteLock lock = redissonClient.getReadWriteLock("lock");
//读锁:3秒
lock.readLock().lock(10, TimeUnit.SECONDS);
//redis读数据
String s = stringRedisTemplate.boundValueOps("msg").get();
return s;
}
/**
* 写锁
*/
@Override
public String writeLock() {
RReadWriteLock lock = redissonClient.getReadWriteLock("lock");
//写锁
lock.writeLock().lock(10, TimeUnit.SECONDS);
//写数据
stringRedisTemplate.boundValueOps("msg").set(UUID.randomUUID().toString());
return "写完了";
}
打开开两个浏览器窗口测试:
localhost:8206/admin/product/test/read
http://localhost:8206/admin/product/test/write
- 同时访问写:一个写完之后,等待一会儿(约10s),另一个写开始
- 同时访问读:不用等待
- 先写后读:读要等待(约10s)写完成
- 先读后写:写要等待(约10s)读完成
三、分布式锁进行缓存业务测试
// service层
@Override
public SkuInfo getSkuInfoRedisAndMysql(Long skuId) {
//参数校验
if (skuId == null) {
return null;
}
//先查缓存
SkuInfo skuInfo = (SkuInfo) redisTemplate.opsForValue().get("sku:" + skuId + ":info");
//判断
if (skuInfo != null) {
return skuInfo;
}
//为空查数据库
// 先抢锁
RLock lock = redissonClient.getLock("sku:" + skuId + ":lock");
try {
if (lock.tryLock(10,10, TimeUnit.SECONDS)) {
//拿到锁后
try {
//查数据库
skuInfo = skuInfoMapper.selectById(skuId);
if (skuInfo == null || skuInfo.getId() == null) {
//数据库里面没有这条数据,返回一个空的数据,并设置一个较短的缓存时间
skuInfo = new SkuInfo();
redisTemplate.opsForValue().set("sku:" + skuId + ":info", skuInfo, 300, TimeUnit.SECONDS);
}else {
//将数据存入缓存
redisTemplate.opsForValue().set("sku:" + skuId + ":info", skuInfo, 24*60*60, TimeUnit.SECONDS);
}
//返回数据
return skuInfo;
} catch (Exception e) {
log.error("业务出现错误,请检查。");
} finally {
//释放锁
lock.unlock();
}
}
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
可以编写controller测试
四、分布式锁+AOP实现缓存
随着业务中缓存及分布式锁的加入,业务代码变的复杂起来,除了需要考虑业务逻辑本身,还要考虑缓存及分布式锁的问题,增加了程序员的工作量及开发难度。而缓存的玩法套路特别类似于事务,而声明式事务就是用了aop的思想实现的。
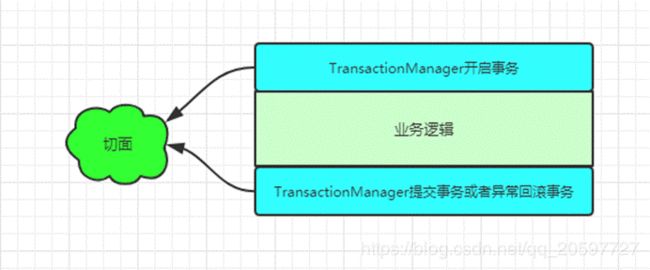
-
以 @Transactional 注解为植入点的切点,这样才能知道@Transactional注解标注的方法需要被代理。
-
@Transactional注解的切面逻辑类似于@Around
模拟事务,缓存可以这样实现:
-
自定义缓存注解@GmallCache(类似于事务@Transactional)
-
编写切面类,使用环绕通知实现缓存的逻辑封装
4.1自定义注解
import java.lang.annotation.*;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface GmallCache {
String prefix() default "cache";
}
4.2 定义一个切面类加上注解
Spring aop 参考文档:
https://docs.spring.io/spring/docs/5.2.6.BUILD-SNAPSHOT/spring-framework-reference/core.html#aop-api-pointcuts-aspectj
import com.alibaba.fastjson.JSONObject;
import org.apache.commons.lang.StringUtils;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.reflect.MethodSignature;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.util.Arrays;
import java.util.concurrent.TimeUnit;
/*
* 切面类
* 2022/3/23 18:42
* @param null
* @return
*/
@Component
@Aspect
public class GmallCacheAspect {
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private RedissonClient redissonClient;
/**
* 增强方法
* 2022/3/23 18:42
* @param point:切点
* @return java.lang.Object
*/
@Around("@annotation(com.atguigu.gmall.common.cache.GmallCache)")
public Object cacheAroundAdvice(ProceedingJoinPoint point){
/*
1. 获取参数列表
2. 获取方法上的注解
3. 获取前缀
4. 获取目标方法的返回值
*/
// 初始化返回结果
Object result = null;
try {
//获取方法的参数
Object[] args = point.getArgs();
//拿到方法的签名
MethodSignature signature = (MethodSignature) point.getSignature();
//通过签名去获取注解
GmallCache gmallCache = signature.getMethod().getAnnotation(GmallCache.class);
// 获取前缀 getSkuInfo:
String prefix = gmallCache.prefix();
// 拼接key getSkuInfo:[1]
String key = prefix + Arrays.asList(args).toString();
// 从缓存中获取数据
result = cacheHit(signature, key);
if (result!=null){
// 缓存有数据,直接返回
return result;
}
// 初始化分布式锁
RLock lock = redissonClient.getLock(key + ":lock");
boolean flag = lock.tryLock(100, 100, TimeUnit.SECONDS);
if (flag){
//成功加锁
try {
try {
//执行方法:查询数据库
result = point.proceed(point.getArgs());
// 防止缓存穿透:判断数据库是否有数据
if (null==result){
// 数据库为空,缓存一个空对象,并设置一个短一点的过期时间
Object o = new Object();
this.redisTemplate.opsForValue().set(key, JSONObject.toJSONString(o),300,TimeUnit.SECONDS);
return null;
} else {
// 并把结果放入缓存
this.redisTemplate.opsForValue().set(key, JSONObject.toJSONString(result),24*60*60,TimeUnit.SECONDS);
}
} catch (Throwable throwable) {
throwable.printStackTrace();
}
return result;
}catch (Exception e){
e.printStackTrace();
}finally {
// 释放锁
lock.unlock();
}
}
}catch (Exception e){
e.printStackTrace();
}
//boolean flag = lock.tryLock(10L, 10L, TimeUnit.SECONDS);
return result;
}
// 获取缓存数据
private Object cacheHit(MethodSignature signature, String key) {
// 1. 查询缓存
String cache = (String)redisTemplate.opsForValue().get(key);
if (StringUtils.isNotBlank(cache)) {
// 有,则反序列化,直接返回
Class returnType = signature.getReturnType(); // 获取方法返回类型
// 不能使用parseArray,因为不知道List中的泛型
return JSONObject.parseObject(cache, returnType);
}
return null;
}
}
4.3 使用注解完成缓存
//controller层
/**
* 根据skuId获取SKU信息
* 2022/3/22 16:45
* @param skuId
* @return com.atguigu.gmall.model.product.SkuInfo
*/
@GmallCache(prefix = "getSkuInfo:")
@GetMapping("/getSkuInfo/{skuId}")
public SkuInfo getSkuInfo(@PathVariable("skuId") Long skuId) {
return itemService.getSkuInfoById(skuId);
}
ce();
}
//boolean flag = lock.tryLock(10L, 10L, TimeUnit.SECONDS);
return result;
}
// 获取缓存数据
private Object cacheHit(MethodSignature signature, String key) {
// 1. 查询缓存
String cache = (String)redisTemplate.opsForValue().get(key);
if (StringUtils.isNotBlank(cache)) {
// 有,则反序列化,直接返回
Class returnType = signature.getReturnType(); // 获取方法返回类型
// 不能使用parseArray
return JSONObject.parseObject(cache, returnType);
}
return null;
}
}
#### 4.3 使用注解完成缓存
```java
//controller层
/**
* 根据skuId获取SKU信息
* 2022/3/22 16:45
* @param skuId
* @return com.atguigu.gmall.model.product.SkuInfo
*/
@GmallCache(prefix = "getSkuInfo:")
@GetMapping("/getSkuInfo/{skuId}")
public SkuInfo getSkuInfo(@PathVariable("skuId") Long skuId) {
return itemService.getSkuInfoById(skuId);
}