Java Web 实战 19 - What‘s HTTP ?
What's HTTP ?
- 一 . HTTP 是什么 ?
-
- 1.1 理解 HTTP 协议的工作过程
- 1.2 HTTP 的报文格式
-
- 1.2.1 准备工作
- 1.2.2 认识 HTTP 协议的报文详情
-
- 请求报文
- 请求响应
- 二 . HTTP 请求报文
-
- 2.1 URL
-
- URL 的 encode
- 2.2 HTTP 协议中的方法
-
- GET
- POST
- 常见面试题 : GET 和 POST 之间的区别
- 2.3 认识请求报头 (header)
-
- Host
- Content-Length / Content-Type
- User-Agent (简称 UA)
- Referer
- Cookie
-
- Cookie 和 Session 的区别
- 2.4 认识请求正文
- 三 . HTTP 响应报文
-
- 3.1 状态码
- 3.2 认识响应报头
-
- Content-Type
- 3.3 认识响应正文
- 四 . 通过代码构造 HTTP 请求
-
- 4.1 基于 form 构造 HTTP 请求
- 4.2 基于 ajax 构造 HTTP 请求
-
- 准备 jQuery
- 使用 jQuery
Hello , 大家好 , 好久没有更新 JavaWeb 模块的内容了 .
博主接下来准备更新 HTTP/HTTPS、Servlet、Linux、JVM 相关知识点
那接下来的知识点无疑都是面试重灾区
HTTP / HTTPS : HTTPS 加密的过程
Servlet : Cookie 和 Session 的区别
Linux : 常见的 Linux 指令
JVM : JVM 内存区域划分、垃圾回收机制、双亲委派模型
那希望大家跟紧步伐 , 站稳脚跟 !
大家也可以订阅 JavaWeb 专栏 , 点击即可跳转
准备好 , 我们要开始发车了 !

一 . HTTP 是什么 ?
当今互联网世界 , 数据的传输需要 “协议”
我们之前也讲过协议拆分和协议分层的问题 , 当前使用最多的协议就是 TCP/IP 五层协议
其中 , 它包括 应用层、传输层、网络层、数据链路层、物理层
我们虽然之前着重讲解的传输层里面的 TCP 机制 , 但是实际上跟程序员直接打交道的就是应用层
应用层是程序猿自己定义的
为了简化程序猿自己定义协议的成本 , 有大佬们 , 研发出了一些比较好使的协议 , 可以让别的程序猿直接来用
HTTP 就是属于其中之一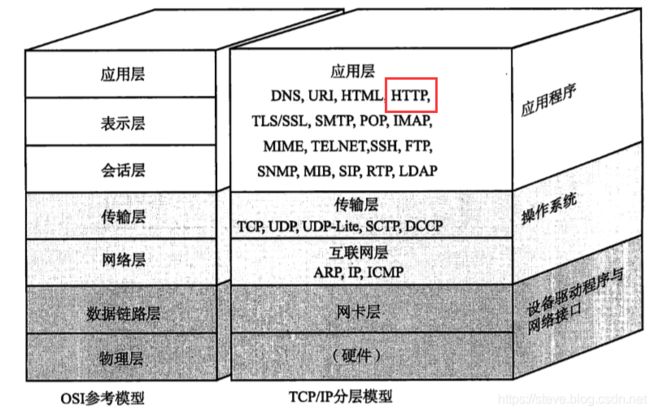
HTTP 是当下最广泛使用的协议
- 当使用浏览器打开一个网页的时候 , 浏览器和服务器之间的通信基本上就是基于 HTTP
- 当使用手机 app , 打开一个界面的时候 , app 和服务器之间的通信 , 绝大部分情况也是基于 HTTP 的.
- 分布式系统中 , 服务器和服务器之间的通信 , 也有一定概率使用 HTTP
HTTP 协议也就成为了日常开发中 , 最常用的协议 , 也是面试中最常考的协议
HTTP 发展到今天 , 有很多版本 , 但是现在互联网上最主流的是 HTTP 1.1
最新版本已经是 HTTP 3.0 (中间还有 HTTP 2.0)
1.1 理解 HTTP 协议的工作过程
HTTP 协议是一问一答的模式
在浏览器中输入网址 , 浏览器就会把用户操作的信息包装成一个 HTTP 请求发送给搜狗服务器 , 搜狗的服务器根据请求的内容去解析 , 比如 : 用户想要去获取搜狗主页 , 那搜狗的服务器就会把搜狗首页的 HTML 打包成一个响应 , 返回给浏览器 . 浏览器收到响应之后 , 再去将 HTML 文件渲染到前端页面上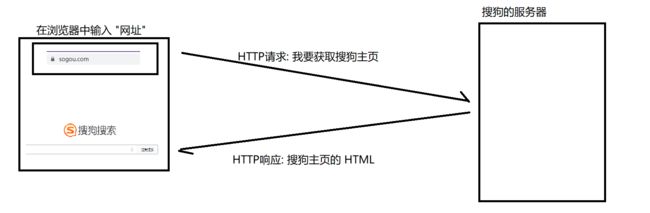
我们之前也讲过 : 客户端和服务器之间的通信模式
- 一问一答 : 请求和响应是一一对应的
- 多问一答 : N 个请求 , 对应一个响应 . (上传文件)
- 一问多答 : 一个请求 , 对应 N 个响应 . (下载文件)
- 多问多答 : N 个请求 , 对应 N 个响应 (直播/游戏串流)
1.2 HTTP 的报文格式
1.2.1 准备工作
学习 HTTP 的报文格式 , 我们需要用到抓包工具
我们可以使用谷歌浏览器给我们提供的抓包工具
通过 F12 即可打开控制台
Chrome 虽然能抓包 , 但是用起来不太方便 , 功能也有限 .
我们可以使用 Fiddler , 功能更丰富 , 使用更简单
FiddlerSetup.zip
安装之后打开 Fiddler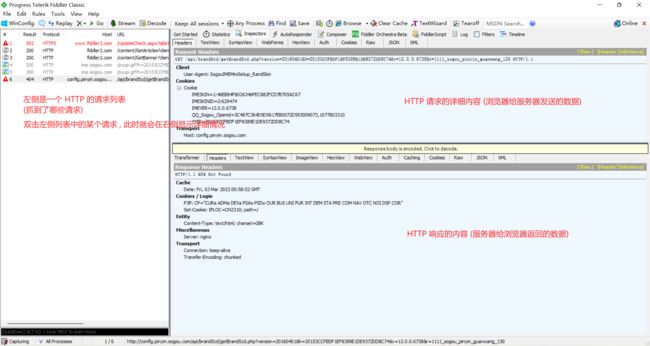
那我们有一个问题 , 为什么 Fiddler 就能获取到请求和响应的交互过程呢 ?
我们的 Fiddler 程序就相当于是一个 “代理” , 相当于在中间传话的 , 那传话的人肯定知道两方都说啥了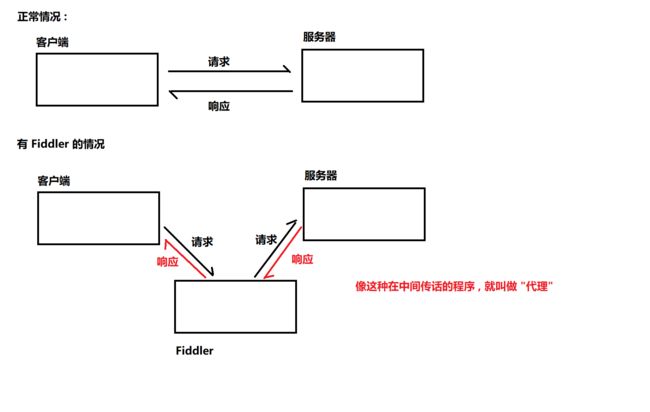
有的同学电脑里面本身就运行了一些其他的代理程序或者其他的 代理程序 / 浏览器插件 , 很容易和 Fiddler 产生冲突
尤其是一些 程序 , 或者 xxx 加速器等等
把这些程序关闭即可
那我们就通过 Fiddler 抓一个包 , 看看报文格式
这就是我们的浏览器向服务器发送的请求

与 TCP / UDP / IP 不同的是 , HTTP 协议使用文本协议来组织的 , 拿记事本打开之后 , 里面不是乱码
TCP / UDP / IP 是二进制协议格式
下面的部分就是我们 HTTP 的响应数据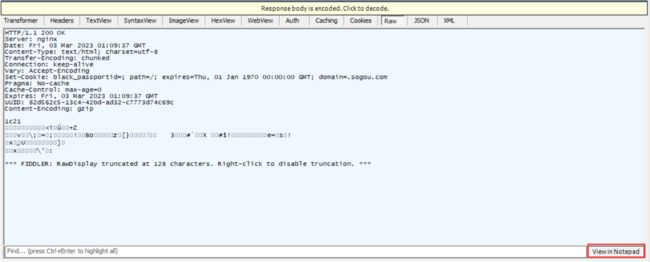
同样可以使用记事本打开
那这里为什么就变成乱码了呢 ? 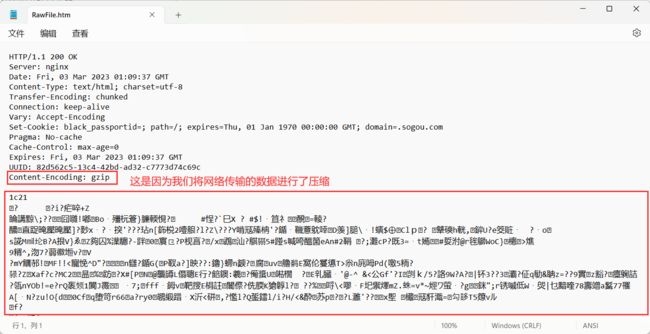
网络上传输的数据也可以进行压缩 , 对于 HTTP 协议来说 , 请求数据比较简短 , 就不必压缩
响应数据可能比较长 , 通过压缩 , 就可以节省传输的带宽
带宽是一个比较昂贵的硬件资源
Fiddler 也给我们提供了解压缩功能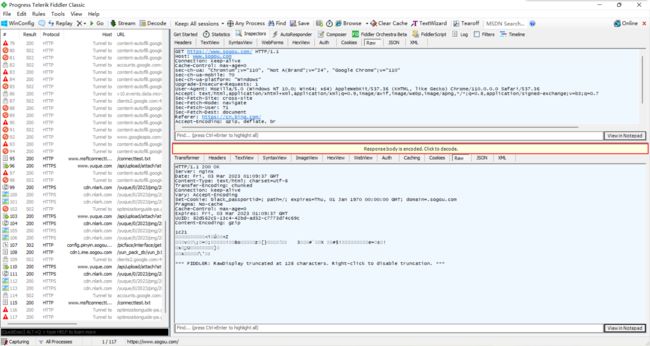
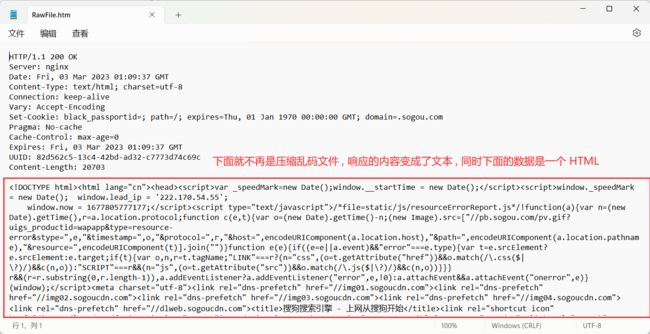
Fiddler 还可以抓 HTTPS , 但是没办法抓 TCP / UDP / IP 协议
HTTPS 就是带加密版本的 HTTP
现在很多网站也都是 HTTPS 的了 , 所以我们需要设置一下 , 让我们的 Fiddler 也能抓取 HTTPS
首次点击 HTTPS 会弹出一个对话框 , 询问你是否安装证书 , 选择是即可
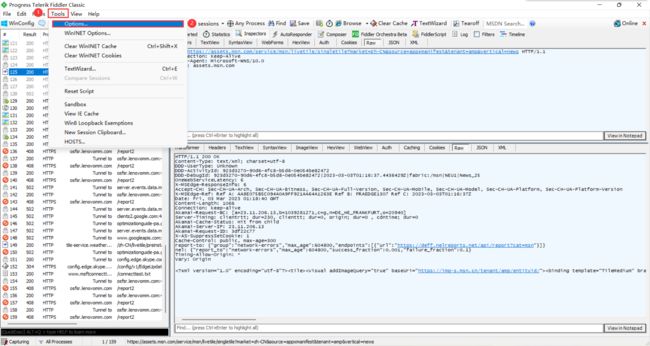

那接下来我们就需要看懂并且理解 HTTP 的协议报文
1.2.2 认识 HTTP 协议的报文详情
请求报文
这是我们抓取到的搜狗首页的请求报文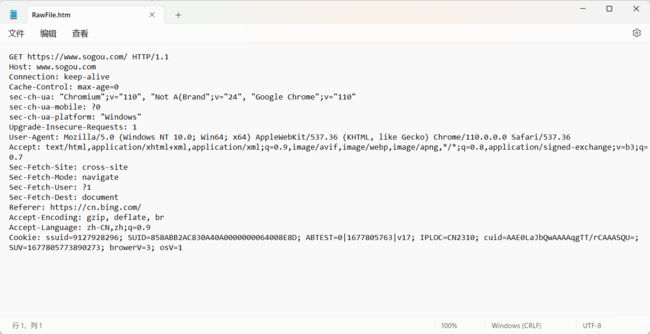
这里就包含了几个部分
- 首行 (请求行)

- 请求报头 (header) :

- 空行 :

- 正文 (body) : 不是所有的 HTTP 请求都有正文
像登陆场景 , 一般就会有正文部分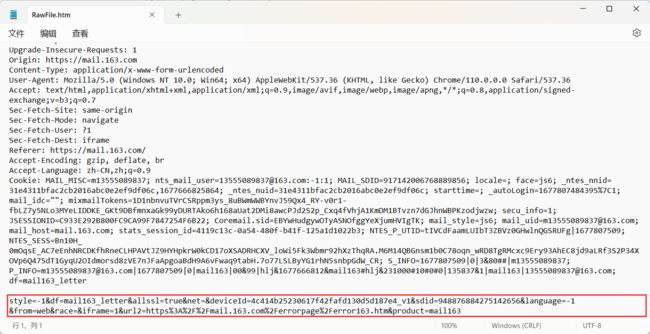

只要 Fiddler 开启状态 , 此时就会 “持续抓包”
咱的电脑上总会有程序在后台偷偷的通过 HTTP 和服务器进行交互
因此为了防止混淆 , 就可以把 Fiddler 原来已经抓到的包 , 清空一下 , 再抓新的
- 随便点一个报文
- Ctrl + A 全选
- 按 delete 清空即可
请求响应
HTTP 响应 , 也是四个部分
- 首行
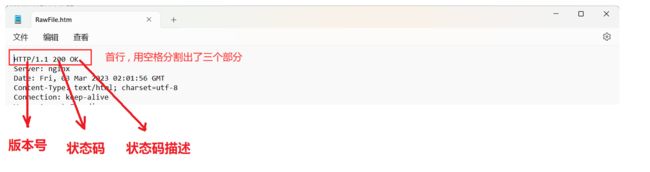
- 响应报头 (header) :
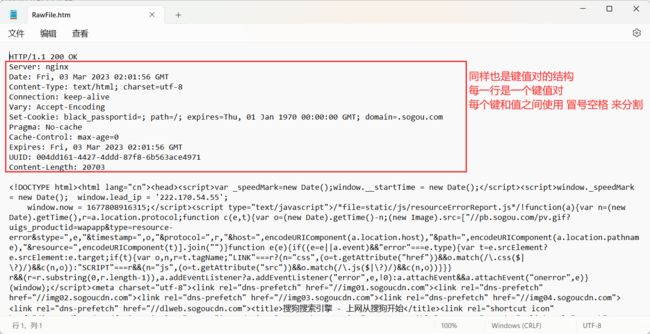
- 空行 : 作为响应报头结束的标记
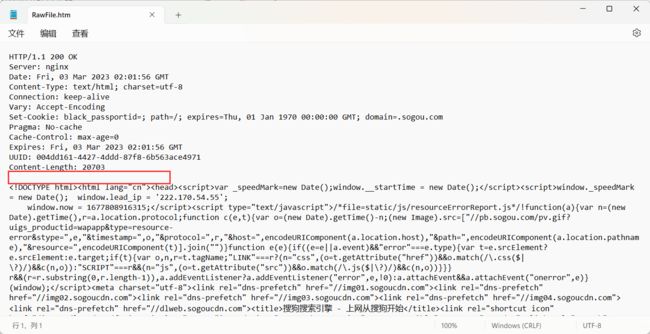
- 响应正文 (body) : 可能是 HTML , 也可能是 CSS , 或者 JS , 或者图片的二进制等
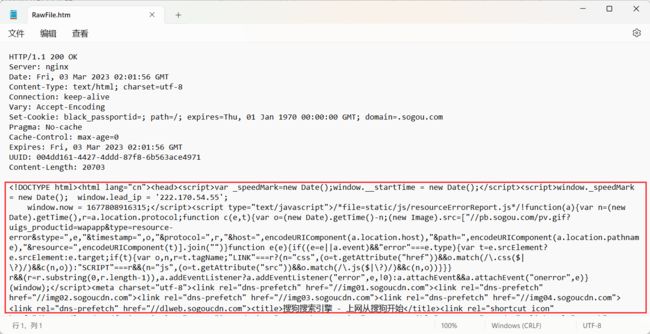
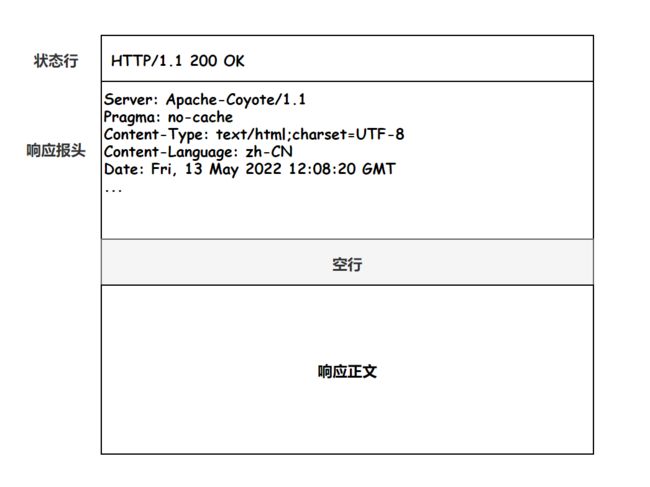
这里也有一张图 , 总结了报文的格式
二 . HTTP 请求报文
2.1 URL
URL 表示唯一资源定位符 , 相当于描述了互联网上的唯一的一个资源 , 俗称 “网址”
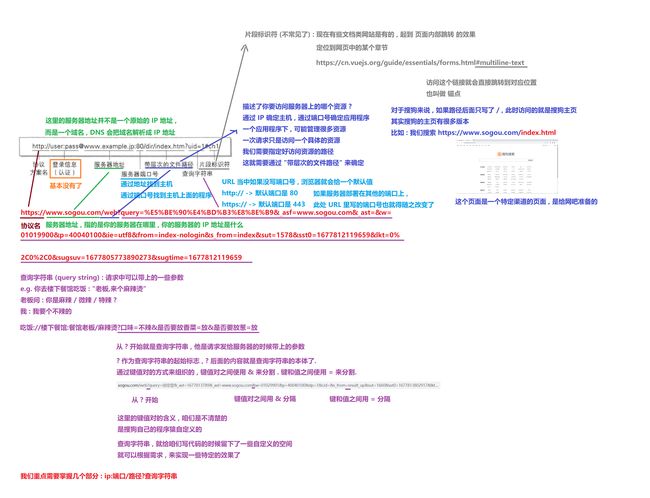
URL 的 encode
URL 里面是已经有一些特定的符号 , 带有特定含义了
如果在 Query String 中也出现同样的符号 , 此时就容易产生误会 , 此时就需要把这些特殊符号进行 “转码” , 就叫做 urlencode
举个栗子 : 我们搜索 C++
%2B 就是 + 这个符号 urlencode 之后得到的内容 , 不是 C++ 程序员是 2B 的意思
这个 urlencode 操作是非常有意义也是必要的 , 如果查询字符串中带有了特殊符号 , 很容易导致浏览器对 url 解析失败的 , 可能导致就无法跳转到对应的页面
我们要是想手动转码的话 , 就有许多在线工具可以进行转码
2.2 HTTP 协议中的方法
HTTP 协议中的方法 就是首行的第一个部分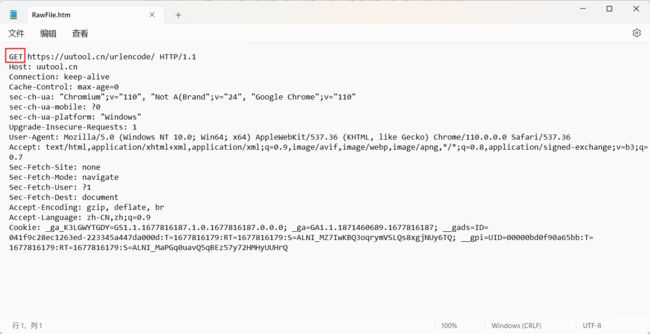
HTTP 里面的方法 , 种类是有很多的
虽然方法有很多 , 但是我们最常用的就是 GET POST , GET 和 POST 之中 GET 用的更多一点
GET
GET 是最常用的 HTTP 方法 , 常用于获取服务器上的某个资源 .
常用于获取服务器上的某个资源 , 这是这个方法原始的语义 , 不代表一定要听他的 (建议)
但是实际使用的时候 , 也不一定完全遵守
完全也可以使用 GET 让服务器新增一个数据 / 删除一个数据 / 修改一个数据
哪些场景会触发一个 GET 请求呢 ?
- 浏览器地址栏输入一个 URL 然后回车 , 或者点收藏夹里的收藏的网址 .
- 很多的 HTML 标签会触发 GET 请求 , 比如 : a、img、link , script 也会产生 GET 请求 .
- form 标签
- ajax 标签
GET 请求的典型特点 :
- URL 的 query string 有时候有 , 有时候没有
- body 通常是空
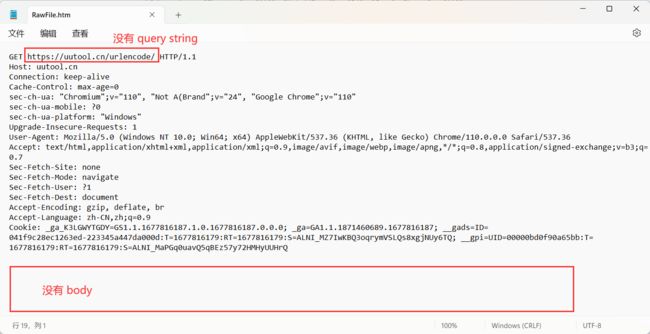
网上有个说法 , GET 请求 URL 的长度是有限制的 , 这是一个非常错误的说法
URL 的长度是没有上限的
在 HTTP 协议 RFC 2616 标准里已经说明了 : “Hypertext Transfer Protocol –
HTTP/1.1,” does not specify any requirement for URL length."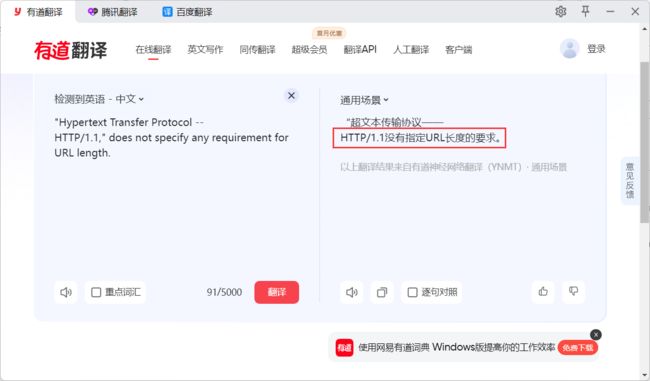
POST
POST 请求的初心是把信息上传/提交给服务器 , 主要有两个功能经常用到 POST
- 登录
- 上传文件
POST 请求的特点
- 首行的一个部分是 POST
- URL 里通常没有 query string
- 通常有 body
浏览器和服务器交互的时候 , 总是需要提交一些数据给服务器的
这里情况在提交的过程中 , 相关的信息 , 可以放到 query string 里 , 也可以放到 body 中
query string 是固定的键值对格式
body 中则是可以使用更多的格式来组织

常见面试题 : GET 和 POST 之间的区别
这两个方法没有本质区别 , 彼此之间是可以互相替代的
但是在使用习惯上还有一些区别的
- GET 主要使用用来获取数据 , POST 主要使用给服务器提交数据 (虽然不必强制遵守 , 但是习惯上大部分情况下还是会遵守的)
- GET 主要通过 query string 来传递数据 , POST 则是使用 body 传递数据 . (也不是强制遵守的 , 也是习惯用法)
- GET 请求一般是需要实现成 “幂等的” , POST 则不要求 “幂等”
如果多次输入的内容相同 , 多次得到的结果也完全相同 , 称为"幂等" . (类似事物的一致性)
实际开发中 , 对于幂等很多时候是有要求的
比如 : 实现"查看账户余额" , 这个功能显然就需要是幂等的
实现 “转账” : 这个功能显然就不能是幂等的
- GET 一般是可以被缓存的 / 可以放到收藏夹中的 , POST 一般不要求被缓存 / 不能放入收藏夹
因为 GET 一般要求是幂等的 , 这样的话每次发送请求得到的响应都是一样的 , 就可以进行缓存了
2.3 认识请求报头 (header)
请求报头中 , 是有很多的键值对的 . 重点认识一些常见 / 重要的键值对
Host
![]()
表示访问的服务器的主机 / 地址是什么 , 明确表示出了域名是从哪到哪
这个信息在 URL 当中也是有体现的
Content-Length / Content-Type
Content-Length 表示 body 的数据有多长
Content-Type 表示 body 中的数据格式
他们两个都是搭配 body 使用的 , 有 body 的时候 (比如 : 登录) 才会有 Content-Length、Content-Type 
使用 TCP 协议的时候 , TCP 是一个面向字节流的协议 .
基于 TCP 的应用层协议 , 务必要明确数据报和数据报之间的边界 , 否则就会出现粘包问题 .
那 HTTP 也是基于 TCP 的 , 当 HTTP 报文带有 body 的时候就需要显式的明确出 body 到哪里结束
那这个边界要不就是指定长度 (Content-Type) , 要不就是指定分隔符 (空行)
HTTP 请求的 body 的数据格式常见的有几个
- json
{"username":"123456789","password":"xxxx","code":"jw7l","uuid":"d110a05ccde64b16
a861fa2bddfdcd15"}
- urlencoded , 全称 application/x-www-form-urlencoded
格式就和 query string 是一样的. (键值对 , 键值对之间使用 & 分割 , 键和值之间使用 = 分割)
就相当于是把 query string 拿到了 body 中
title=test&content=hello
- form-data : 上传文件的时候会涉及到
在 HTTP 响应中 , 还有一些其他的 Content-Type
Content-Type:multipart/form-data; boundary=----
WebKitFormBoundaryrGKCBY7qhFd3TrwA
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="text"
title
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="file"; filename="chrome.png"
Content-Type: image/png
PNG ... content of chrome.png ...
------WebKitFormBoundaryrGKCBY7qhFd3TrwA--
User-Agent (简称 UA)
![]()

由于现代的浏览器 , Chrome、Edge、Safari , 已经差距很小了 , 就不会再根据不同版本的浏览器返回不同页面
现在 UA 起到的作用 , 主要是区分 , 请求是来自于 PC 还是移动端 . (操作系统)
其实 windows 也有移动设备 , android 也能模拟 PC 访问页面
Referer
![]()
表示了这个页面是从哪个页面跳转过来的
有的时候有 , 有的时候没有 , 主要还是看从哪个页面跳转过来的
如果直接从浏览器地址栏输入 / 点收藏夹 , 就不会有 referer
其实这个操作还是有一些用的
当点击广告的时候 , 报文中的 Referer 就会记录从哪个页面跳转过来的 , 广告主就得给该平台付钱 , 相当于搜狗给广告主的网站引流了 (让更多的人访问到这个网站)
Cookie
Cookie 是浏览器在本地存储数据的一种机制
一个用户的相关数据信息都是在服务器这里存的 , 有的时候 , 希望在浏览器这边也能存下来 , 简化一些操作
最典型的需要在浏览器这里存储的 , 就是用户的身份信息. (你是谁) , 这样就可以避免反复重复的进行登录
浏览器为了保证用户的安全 , 就针对页面上运行的代码 , 做出了很多的限制
最典型的 , 就是禁止浏览器页面代码 , 访问本地磁盘
如果放开这个限制 , 后果是非常严重滴 , 你珍贵的学习资料就会被恶意程序全部删除啦
浏览器不让访问磁盘 , 然后你还想持久化的在浏览器保存一些信息 , 就需要访问磁盘 , 这就产生冲突了
那大家就都各退一步 , 浏览器不是完全给你限制死 , 不是一点都不能使用磁盘 .
可以在限定条件下 , 能够使用一点点 (不能访问到磁盘的其他文件)
同时页面代码 , 也不能任意存数据 , 只能存简单键值对 , 这就是 cookie 机制
点击这个小锁头图标 , 就能看到当前页面的 cookie
浏览器为了进一步的保证安全 , cookie 都是分别存的 . 每个网站 (每个域名) 有一组自己的 cookie , 彼此之间互不干扰
如果我们把用户电脑的磁盘 , 比喻成一个大房子 , cookie 就是一个小鞋柜
页面无法往这个大房子里装其他家具的 , 更不能把现有的家具给搞走 . 唯一能使用的只是这个小鞋柜
鞋柜上还有很多个小门 , 每个域名就分一个鞋柜
甚至于 A 网站的鞋柜都不能被 B 网站来使用

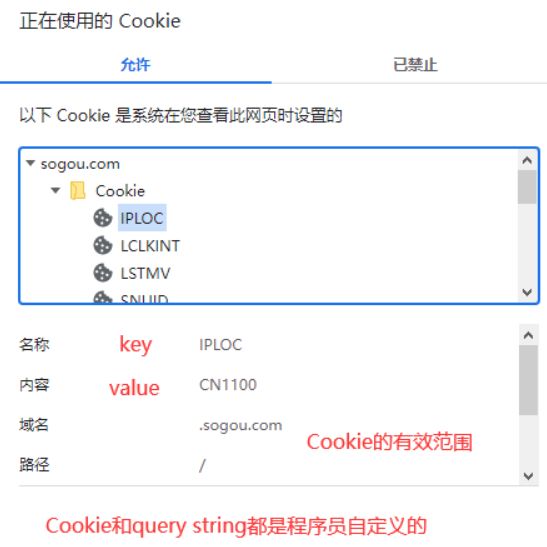
这些 cookie 内容都是存储在硬盘 (浏览器) 上的 , 只不过页面代码不能直接任意的访问硬盘 .
而是只能够存储和修改 cookie 这样的简单键值对
我们上面也讲解了 , cookie 是啥 ? -> 浏览器允许页面在本地持久化存储数据的一种机制
cookie 的内容从哪里来呢 ? -> 是从服务器来的 , 网站上面主要的数据存储仍然是在服务器上的 , 数据也是从服务器写回给浏览器的
cookie 的内容到哪里去呢? -> 再传回给服务器 , 例如网站通过登录之后 , 明确了用户的身份信息 , 就把身份标识返回给了浏览器 . 浏览器下次访问服务器 , 就会带着身份标识 , 服务器就可以认出用户是谁了
那 cookie 里面还有一系列键值对 , 都是什么意思呢 ?
cookie 中的键值对 , 都是自定义的 , 只有实现这个功能的程序员才能清除 cookie 的具体含义
我们接下来来看一下 cookie 在报文中长什么样子
我们以码云为例 , 在登录码云之前先要清空一下 cookie
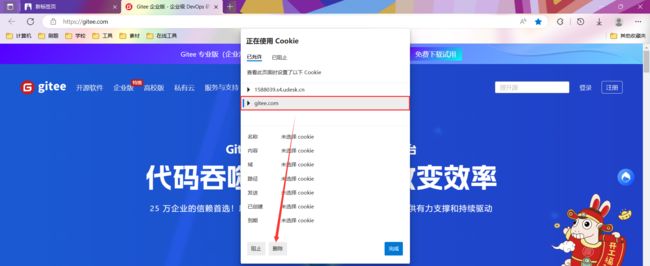
在清空 cookie 之后 , 第一次访问码云的服务器 , 触发的请求当中并没有 cookie
上面这个 Set-Cookie 效果就是服务器给客户端写 Cookie
每个 Set-Cookie 都对应一个键值对 , 当浏览器保存了这些 Cookie 之后 , 就会在后续的请求中 , 带上这个 Cookie内容
上述这些 Cookie 的键值对 , 都是前面的 HTTP 响应 , 返回给浏览器的数据
我们再举个栗子帮助大家更好地理解
再举个栗子 : session 就相当于银行的保险柜 , cookie 就相当于银行卡
使用银行卡就可以找到对应的银行把钱取出来
Cookie 和 Session 的区别
Cookie : 客户端浏览器用来保存服务器端数据的一种机制 . 当我们通过浏览器去进行网页访问的时候 , 服务器可以把一些状态数据以 key-value 的形式写入到 Cookie 中 , 然后存储到客户端的浏览器上 ; 当客户端下次再访问服务器的时候 , 我们可以携带这些状态数据发送到服务器端 , 服务器端就可以根据 Cookie 里面携带的数据去识别使用者
Session : 表示一个会话 , 他是属于服务器端的一个容器对象 , 默认情况下他会针对每一个浏览器的请求 , Servlet 容器都会分配一个 Session 对象 , Session 本质上可以认为他是一个 ConcurrentHashMap , 他可以用来存储当前会话产生的一些状态数据 . HTTP 协议本身就是一个无状态协议 , 也就是说服务器端并不知道客户端发送过来的多次请求是属于同一个用户 , 所以 Session 是用来弥补 HTTP 无状态的一个不足
简单来说 , 服务器端可以利用 Session 来存储客户端在同一个会话里面产生的多次请求的一个记录
基于服务器端的 Session 的存储机制 , 再结合客户端的 Cookie 机制 , 我们就可以实现一个有状态的 HTTP 协议
首先 , 客户端第一次访问服务器端的时候 , 服务器端会针对这次请求创建一个会话 , 并且生成一个唯一的 sessionId 来标注这个会话 , 然后服务器端把这个 sessionId 写入到客户端浏览器的 Cookie 里面 , 用来去实现客户端状态的一个保存 ; 那么在后续的请求里面 , 每一次都会携带 SessionId , 服务器端就可以根据 sessionId 来识别当前会话的状态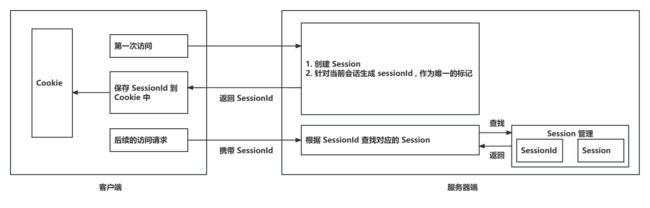
总的来看 , Cookie 是客户端的存储机制 , 而 Session 则是服务器端的存储机制
2.4 认识请求正文
请求正文是由 Content-Type 和 Content-Length 一起决定的
三 . HTTP 响应报文
HTTP 响应中的大部分内容 , 都是和请求类似的
3.1 状态码
![]()
此处的 200 就是状态码 , 表示这次请求成功还是失败 . 如果失败 , 是因为什么失败的 .
常见的状态码有很多 :
- 200 : 成功了 , 没出错
- 404 : 要访问的资源没找到
- 403 : 访问被拒绝 (你访问的资源存在 , 但是你没权限)
- 405 : 表示请求的方法不支持
比如 : 你使用 DELETE 方法来访问人家服务器 , 但是人家的服务器不支持 DELETE
- 500 : 服务器内部错误 (服务器挂了 , 出了异常)
- 504 : 超时 . (请求发过去之后 , 迟迟没收到回应 , 浏览器等待的时间到了 , 就超时了)
- 302 / 301 : 重定向 (301 : 永久重定向 , 302 : 临时重定向)
类似呼叫转移
我有一个用了好久的手机号码 , 但是我想换一个手机号码
不过我的朋友同学亲人都是存的旧的号码 , 我想让他们都重新存新号码 , 就比较麻烦 .
因此直接去运营商搞个呼叫转移的业务 , 如果有人打旧的号码 , 自动转接到新号码上
在网页中就类似于有的人只记住了这个域名 , 然后他就一直访问这个
但是我们的网页换了域名 , 大家不知道 , 就只要弄一个重定向 , 让用户访问老的域名也能跳转到新的域名
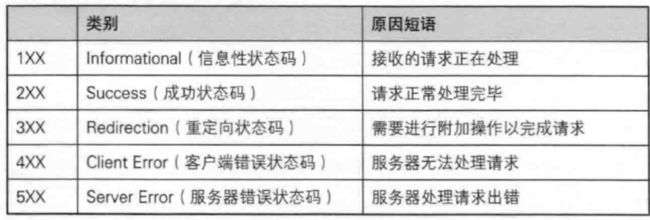

1** : 请求正在处理 -> 等会
2** : 请求成功 -> 你来对了
3** : 重定向 -> 快走开
4** : 用户访问资源有问题 -> 你出错了
5** : 服务器挂了 -> 我出错了
3.2 认识响应报头
Content-Type
响应报头的 Content-Type 和请求报头的 Content-Type 取值上差别挺大的
请求报头的 Content-Type 无非就那几个
- JSON
- urlencoded
- form-data
响应报头的 Content-Type 取值种类很多 , 主要是看返回的响应数据是什么东西
- text/html : body 数据格式是 HTML
- text/css : body 数据格式是 CSS
- application/javascript : body 数据格式是 JavaScript
- application/json : body 数据格式是 JSON
- …
3.3 认识响应正文
他是根据 Content-Type 决定的
在响应正文中 , 存在一个问题 : 字符编码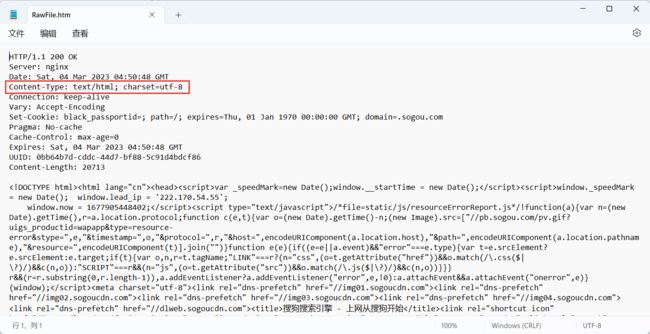
有的时候写代码的时候需要手动指定字符编码 , 保证返回的内容 , 不是乱码
四 . 通过代码构造 HTTP 请求
最基本的操作就是直接在浏览器地址栏输入地址 , 然后回车 , 这样的话就能构造出 get 请求
那我们想要使用代码构造 , 主要有两种途径
- 基于 form 表单
- 基于 ajax
4.1 基于 form 构造 HTTP 请求
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>formtitle>
head>
<body>
<form action="https://www.sogou.com" method="get">
form>
body>
html>
要想使用 form 标签 , 必须搭配其他标签一起使用
单独的 form 标签没啥用 , 页面上没有任何显示的内容
我们可以搭配 input 标签一起使用
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>formtitle>
head>
<body>
<form action="https://www.sogou.com" method="get">
<input type="text">
form>
body>
html>
但是还存在一些问题
form 提交的数据 , 是键值对的结构 , 就需要明确 : 键是什么 , 还有其对应的值是什么
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>formtitle>
head>
<body>
<form action="https://www.sogou.com" method="get">
<input type="text" name="username">
form>
body>
html>

当我们提交 form 表单的时候 , 就会构造出 username = hahaha 这样的键值对 , 通过 query string 或者 body 传送给服务器
最后 , 我们添加一个提交按钮 , 将 HTTP 请求发送给服务器
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>formtitle>
head>
<body>
<form action="https://www.sogou.com" method="get">
<input type="text" name="username">
<input type="submit" value="通过 form 表单发送 HTTP 请求到服务器">
form>
body>
html>
我们来看一下效果
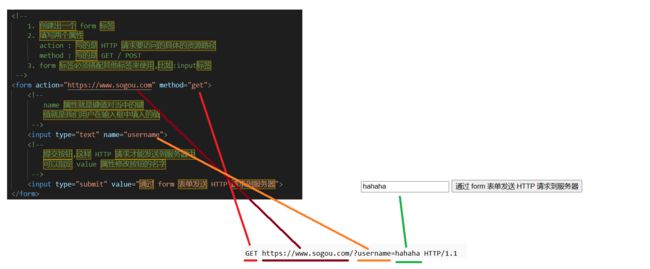
一个 form 表单中 , 可以有很多组键值对
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>formtitle>
head>
<body>
<form action="https://www.sogou.com" method="get">
<input type="text" name="username">
<input type="text" name="password">
<input type="submit" value="通过 form 表单发送 HTTP 请求到服务器">
form>
body>
html>
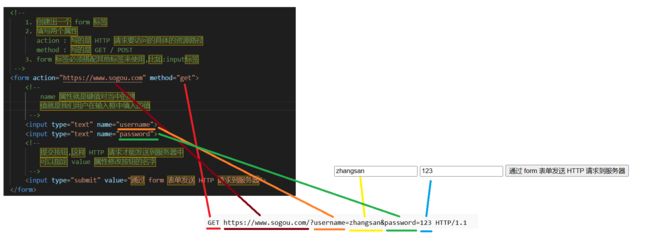
现在就是两组键值对了
除了使用 GET , 还可以使用 POST
改成 POST 之后 , 我们构造的键值对就会出现在 body 部分了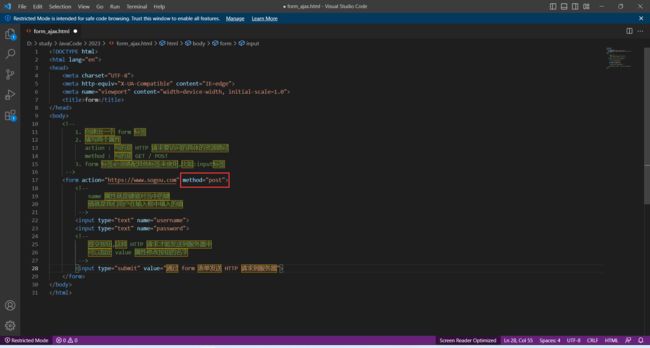
看一下效果
但是 form 表单只支持 GET 和 POST 请求 , 不支持其他方法 (其实够用了)
那提交的数据 , 是放到 URL 里比较好 , 还是放到 body 里比较好呢 ?
那意思就是 POST 比 GET 更安全 ?
这个结论是不成立的 !!!
保证安全的关键 , 是针对密码进行加密 . 而不是放到 body 里不能直接看到就算安全
放到 body 中 , 如果不加密的话 , 虽然浏览器不能直接显示 , 但是随便—抓包 , 密码也就抓出来了
只不过就是 POST 用户体验更好一点

小结 :
form 效果就是构造 HTTP 请求 .
action 描述了 HTTP 请求 URL 的地址 / 端口 / 路径
method 描述了 HTTP 请求的方法 .
搭配一些 input 标签 , 就可以构造出一些键值对数据 .
这些键值对根据方法是 GET 还是 POST , 来分别通过 URL 的 query string 还是 body 来进行传输
4.2 基于 ajax 构造 HTTP 请求
ajax 全称是 Asynchronous Javascript And XML
Asynchronous 大家可能会有点眼熟 , 他跟 synchronized 其实是不同词性的
synchronized 指的是同步 , 在前面加上了 A 就代表不是同步 -> 异步
我们平时所说的同步有多种含义 , 而且不同含义还都是用 synchronized 关键字 , 就很坑
我们之前学习多线程的同步 , 指的其实就是互斥 (有我没你 , 有你没我 . 我在进行一个操作 , 其他线程不能参与)
那这里的同步异步指的就是进行 IO 操作的时候 , 结果是发送方自己来主动获取 , 还是接收方把结果主动推送回发送方
举个栗子 : 去楼下的餐馆吃饭 , 跟老板说 : “来个蛋炒饭”
- 点完单之后 , 就站在前台这里等 , 等的过程中 , 你可以专心等待 (同步阻塞) , 也可以干点别的事(同步非阻塞)当饭做好了 , 你自己把饭端走
- 点完单之后 , 你就找个地方坐下 , 可以专心等待 (异步阻塞) , 也可以干点别的 (异步非阻塞) . 当饭好了 , 服务员会把饭端给你
客户端自己主动获取结果 -> 同步
客户端等着服务器把数据推送过来 -> 异步
ajax 是浏览器和服务器之间异步交互数据的方式
虽然 ajax 全称里面有 xml , 但是并不代表 ajax 只能传输 xml , ajax 还可以传输其他格式的数据
ajax 是浏览器给 JS 提供的一个和服务器交互数据的机制 , 浏览器就提供了一组原生的 API , 比如 : XMLHttpRequest , 但是这个原生的库并不好用
于是就有了很多的第三方库 , 针对 ajax 进行了封装 , 最典型的就是 jQuery
准备 jQuery
我们去浏览器搜索 jQuery cdn
链接我也直接给大家了
https://releases.jquery.com/


然后创建一个 jquery.min.js 文件 , 将刚才 jQuery 的源代码粘贴到此文件中
一粘贴怎么成两行了 ? 浏览器里面看不是那么多东西吗 ?
这个问题其实是浏览器自动帮我们换行了 , 实际上他真的只有两行
由于 js 文件 , 是要通过网络被下载到用户的浏览器上 , 才能正常工作的
如果 js 文件比较大 , 下载过程就更耗时 / 需要消耗更多的带宽
因此前端圈子里就诞生了一系列的 “压缩工具” , 能够对 js 代码进行 “压缩”
但是这里的压缩 , 还跟我们平常说的压缩不太一样
zip/rar 这些压缩是对文件内容重新编码了 , 文件就短了.
js 的压缩 , 是把代码中的换行 / 空白给去掉 , 把变量名 / 函数名替换成特别短的函数名(比如 : a、b、c、d)
jquery.min.js
接下来 , 我们就可以使用这个 jQuery 文件了
当然 , 我们可以不必这么麻烦 , 也可以直接这样写
那这个方法毕竟访问的是外国的服务器 , 有时候就可能出岔子了 , 访问不了了 , 还是保存在本地用吧
使用 jQuery
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
head>
<body>
<script src="jquery.min.js">script>
<script>
// 核心函数: $.ajax();
// 也可以写成这样: jQuery.ajax();
// 这里的 $ 是一个变量名,是 jQuery 里面的一个特殊对象
// jQuery 里面提供的各种 API,都是以 $ 对象的方法的方式来体现的
$.ajax();
script>
body>
html>
那 $.ajax() 里面还有参数 , 是一个 JS 的对象
JS 语言的函数参数是很灵活的
在 JS 中 , 流行一种使用对象作为参数的方法
这样做的好处就是这些参数是什么意思 , 是自解释的 .
同时参数的顺序都没有限制 , 参数有和没有也很灵活
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
head>
<body>
<script src="jquery.min.js">script>
<script>
// 核心函数: $.ajax();
// 也可以写成这样: jQuery.ajax();
// 这里的 $ 是一个变量名,是 jQuery 里面的一个特殊对象
// jQuery 里面提供的各种 API,都是以 $ 对象的方法的方式来体现的
$.ajax({
type: 'GET', // 请求类型
url: 'http://www.baidu.com', // 请求地址
// data: '这是 body 部分的内容,可以没有', // 请求的 body,一般 GET 请求没有
// 成功的情况下执行的函数
success: function(body) {
// 参数 body 表示 HTTP 响应的正文部分
// 该函数是一个回调函数,这个函数不是立即被执行的,而是在浏览器拿到服务器的响应数据之后,才执行这个回调函数
console.log(body);
}
});
script>
body>
html>
在这里面 , 我们提到了一个回调函数 , 实际上我们并不陌生
数据结构中 , 有一个数据结构叫做 “优先级队列”
如果我们是要给优先级队列里插入一个自己写的类 , 需要指定比较规则 , 可以使用比较器 , 也可以使用构造器(Comparable.compareTo, Comparator.compare)
在多线程中 , 我们创建线程有很多种方式 , 但是这些方式都需要指定要干什么活 , 比如 : 继承 Thread , 重写 run , run 方法就描述了线程要完成的任务 , run 方法也可以视为是一个 “回调函数” .
回调函数 , 就是现在不着急执行 , 而是等满足一定的条件 / 时机的时候 , 再去执行
但是什么时候收到响应 , 是不知道的 . 但是没关系 , 啥时候收到 , 就啥时候执行 .
为什么 ajax 叫做异步 ?
发送请求的程序员 , 只管发送 , 不必主动的去获取结果
等到结果回来 , 自然有人(浏览器)来通知咱们 , 触发咱们的回调函数
我们的代码已经编写完成了 , 但是如果直接执行还会出现问题
控制台报错了 , 这就是 ajax 一个典型的问题 : 跨域问题
实际上跨域问题就是一个 张家人莫管李家事 的问题
那针对 HTTP 的分析 , 我们就到这里了
我们主要了解到了这几点
- HTTP 的报文
a. 请求报文
b. 响应报文 - HTTP 的方法 : GET / POST
- URL 的组成
- 怎样构造 HTTP 请求
那大家在阅读完这一篇文章之后 , 是否了解到了上面的内容呢 , 可以针对自己的学习情况进行投票

如果大家觉得我的文章带给你帮助的话 , 就请给我一键三连 ~ 十分感谢