jmeter
jmeter插件
http://jmeter-plugins.org/downloads/all/
JMeter 运行原理
JMeter以线程的方式运行,通过线程组来驱动多个线程运行测试脚本对被测试服务器发起负载。
MAC安装Jmeter
1、官网下载https://jmeter.apache.org/download_jmeter.cgi

2、解压,命令行进入/Users/yanguobin/apache-jmeter-5.1.1/bin目录下,输入sh jmeter即可启动
或者配置环境变量
vim ~/.bash_profile
内容输入举例:
export JMETER_HOME=/Users/yanguobin/apache-jmeter-5.1.1
export PATH= P A T H : PATH: PATH:JMETER_HOME/bin
使环境变量生效
source ~/.bash_profile
命令行输入jmeter启动jmeter
linux安装jmeter
1.下载:apache-jmeter-4.0.tgz,上传到服务器;(同时本地也要保留一份,以后会用到的)
2.然后解压到当前传的目录:jmeter
tar zxvf apache-jmeter-4.0.tgz jmeter
3.然后把解压的文件配置到对应的环境变量:
export JMETER_HOME=/root/jmeter
export CLASSPATH= J M E T E R H O M E / l i b / e x t / A p a c h e J M e t e r c o r e . j a r : JMETER_HOME/lib/ext/ApacheJMeter_core.jar: JMETERHOME/lib/ext/ApacheJMetercore.jar:JMETER_HOME/lib/jorphan.jar: C L A S S P A T H e x p o r t P A T H = CLASSPATH export PATH= CLASSPATHexportPATH=JMETER_HOME/bin: P A T H : PATH: PATH:HOME/bin
4.source /etc/profile 目的让配置文件生效
5.[root@yace01 ~]# jmeter -v

安装成功
MAC退出Jmeter
按键control+c
使用shutdown.sh
杀死进程
窗口关闭
配置中文
编辑/Users/yanguobin/apache-jmeter-5.1.1/bin目录下的jmeter.properties文件
language=zh_CN
jmeter安装包目录结构
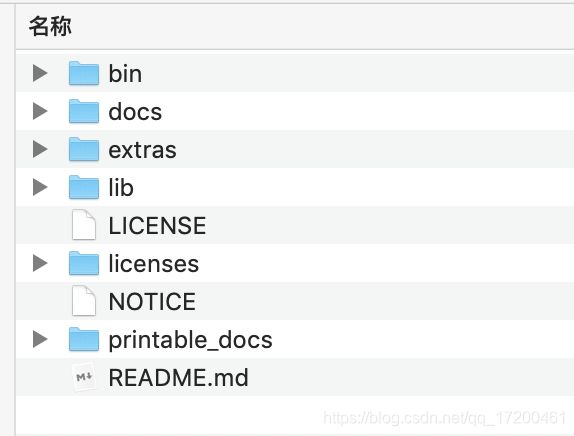
bin :核心可执行文件,包含配置文件
bin.jmeter : jmeter启动文件
bin.jmeter-service: 分布式压测使用的启动文件
bin.jmeter.properties: 核心配置文件
extras : 组件扩展的包,插件及二次开发都会使用这个包
lib: 核心依赖包
lib.ext : 核心包
lib.junit :单元测试包
组件
一组元件的集合

元件

setUPThreadGroup
在测试任务ThreadGroup 运行前先被运行。通常用在运行测试任务前,做初始化工作。例如建立数据库连接初始分化工作。
tearDownThreadGroup
在测试任务ThreadGroup 运行结束后被运行。通常用来做清理测试脏数据、登出、关闭资源等工作。例如关闭数据库连接。
ThreadGroup
一、在取样器错误后要执行的动作

1.继续:继续执行接下来的操作
2.Start Next Loop:忽略错误,执行下一个循环
3.停止线程:退出该线程(不再进行此线程的任何操作)
4.停止测试:等待当前执行的采样器结束后,结束整个测试
5.Stop Test Now:直接停止整个测试
二、线程属性
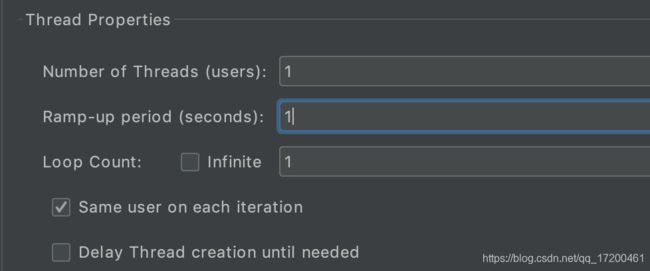
1.线程数:模拟的用户数量
2.Ramp-up Period(in seconds):达到指定线程数所需要的时间。举例:线程数设置为50,此处设置为5,那么
每秒启动的线程数 = 线程数50/5 = 10
3.循环次数:选中“永远”,则一直循环下去。
4. same user on each iteration:每次迭代使用相同的线程
4.Delay Thread creation until needed:当线程需要执行的时候,才会被创建。如果不选择这个选项,那么,在计划开始的时候,所有需要的线程就都被创建好了。
三、调度器配置specify thread lifetime
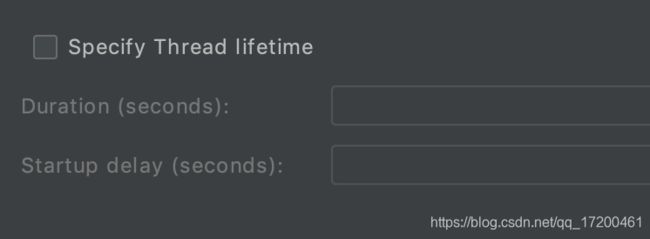
1、duration:持续时间(秒),说明这个计划,从某个开始时间算起,执行N秒后结束。(会忽略 结束时间 的选项)
Loop Count 必须勾选In finite永久,否则即使设置了Duration运行时间,也不会生效。只会根据Loop Count设置的次数运行。
2、startup delay : 启动延迟(秒),手动点击开始执行计划,然后延迟N秒后,计划才真正开始执行。(会忽略 启动时间 的选项)
HttpRequest
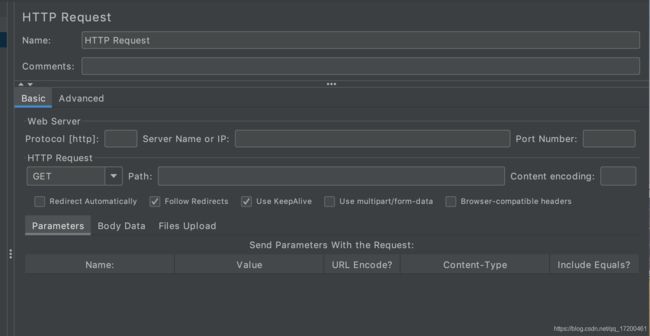
一、http请求下4个选项
1. user Keepalive:
jmeter与目标服务器使用Keep-Alive 方式进行HTTP通信,默认选中
2. use multipart/form-data 提交表单
选项是用来指定提交多个表单数据的,一般不勾选(注:如果不是提交多个表单数据)
3. follow redirects 跟随重定向
Http Request取样器的默认选项,当响应code是3xx时,自动跳转到目标地址。
Jmeter会记录重定向过程中的所有请求响应,在查看结果树时可以看到服务器返回的内容
4. redirect Automatically 自动重定向
只针对Get和Head请求,自动重定向可以自动转向到最终目标页面,
但是Jmeter是不记录重定向的过程内容;
自动重定向和跟随重定向的区别只在于是否记录多个跳转的请求
5. Browser-compatible headers:当勾选multipart/form-data时,勾选此项会截掉http请求头中的Content-Type和Content-Transfer-Encoding,而只发送Content-Disposition部分
二、
在请求中发送URL参数,对于带参数的URL ,jmeter提供了一个简单的对参数化的方法。用户可以将URL中所有参数设置在本表中,表中的每一行是一个参数值对(对应RUL中的 名称1=值1)。编码这个选项最好勾选,因为如果参数值内含有ASCII Control Chars或者Non-ASCII characters或者其他符号的话,如果不勾选会导致发送失败,勾选的话会自动将含有的这些特殊符号进行编码。

MIME TYPE 参考:https://www.cnblogs.com/jsean/articles/1610265.html 
三、加强配置
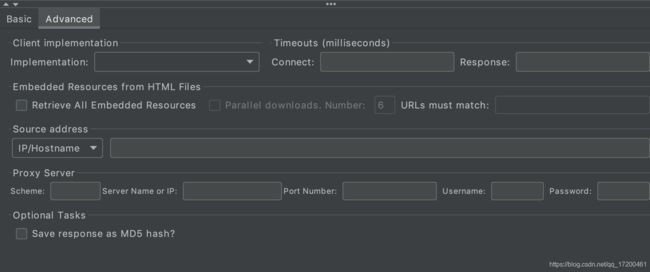
Client implementation
Implementation:发送http请求的方式,可选项为java和HttpClient4,默认为HttpClient4;
Timeouts(milliseconds)
Connect:连接超时时间,单位为毫秒;
Response:响应等待超时时间,单位为毫秒;
Embedded Resources from HTML Files
从HTML文件获取所有内含的资源:当该选项被选中时,jmeter在发出HTTP请求并获得响应的HTML文件内容后,还对该HTML进行解析 并获取HTML中包含的所有资源(图片、flash等),默认不选中,如果用户只希望获取页面中的特定资源,可以在下方的Embedded URLs must match 文本框中填入需要下载的特定资源表达式,这样,只有能匹配指定正则表达式的URL指向资源会被下载。
Parallel downloads.:是否使用自设资源池,勾选后可设置大小;
Number:资源池大小,默认为6。
URLs must match:URL匹配过滤,填写此项则只会下载与此内容项匹配的url的资源,例如要获取http://example.com/下的所有资源,使用正则表达式http://example.com/.*;
Source address
Source address:只用于http协议且Implementation为HttpClient4的情况。
此属性用于启用IP欺骗。会重写了这个http请求使用的默认本地IP地址。用于Jmeter主机具有多个IP地址(即IP别名、网络接口、设备)的情况。该值可以是主机名、IP地址或网络接口设备,如“ey0”或“l0”或“wlan0”。
- IP/Hostname:IP /主机名以使用特定的IP地址或(本地)主机名
- Device:选择设备以选择该接口的第一个可用地址,该设备可以是IPv4或IPv6。
- Device IPV4:选择IPv4设备来选择名称设备的IPv4地址(如eth0, lo, em0);
- Device IPV6:选择IPv6设备来选择名称设备的IPv4地址(如eth0, lo, em0);
Proxy Server(比如不想用本机的地址来发送Http请求而想使用代理服务器则填写这部分)
服务器名称或IP:代理服务器的名称或者IP地址;
端口号:该代理的端口号;
用户名:使用该代理的用户名;
密码:用户密码;
其他任务
Save response as MD5 hash:选中该项,在执行时仅记录服务端响应数据的MD5值,而不记录完整的响应数据。在需要进行数据量非常大的测试时,建议选中该项以减少取样器记录响应数据的开销;
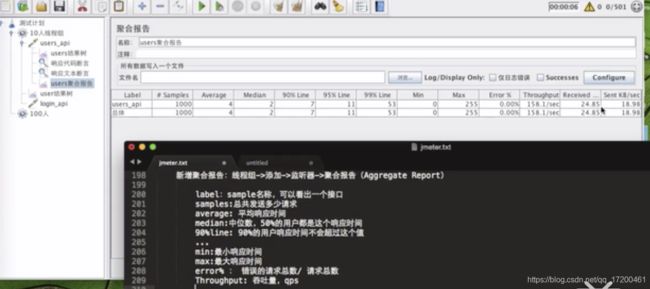
聚合报告
Timer 定时器
一、Constant Throughput Timer 常数吞吐量定时器

使用场景:测试负载为xxQPS时,接口的响应时间等
1、Target throughput(in samples per minute):目标吞吐量。注意这里是每分钟发送的请求数,因此,对应测试需求中所要求的20 QPS ,这里的值应该是1200 。
2、Calculate Throughput based on :有5个选项,分别是:
This thread only :控制每个线程的吞吐量,选择这种模式时,总的吞吐量为设置的 target Throughput 乘以矣线程的数量。
All active threads : 设置的target Throughput 将分配在每个活跃线程上,每个活跃线程在上一次运行结束后等待合理的时间后再次运行。活跃线程指同一时刻同时运行的线程。
All active threads in current thread group :设置的target Throughput将分配在当前线程组的每一个活跃线程上,当测试计划中只有一个线程组时,该选项和All active threads选项的效果完全相同。
All active threads (shared ):与All active threads 的选项基本相同,唯一的区别是,每个活跃线程都会在所有活跃线程上一次运行结束后等待合理的时间后再次运行。
All cative threads in current thread group (shared ):与All active threads in current thread group 基本相同,唯一的区别是,每个活跃线程都会在所有活跃线程的上一次运行结束后等待合理的时间后再次运行。
3、Constant Throughput Timer只有在线程组中的线程产生足够多的request 的情况下才有意义,因此,即使设置了Constant Throughput Timer的值,也可能由于线程组中的线程数量不够,或是定时器设置不合理等原因导致总体的QPS不能达到预期目标。 所以线程数一定要设置很大,2000
jmeter文件结构
https://www.cnblogs.com/shengulong/p/8157252.html
用户自定义变量
变量定义

变量使用

csv可变参数
通过配置元件->CSV data set config 或者 前置处理器->用户参数 配置
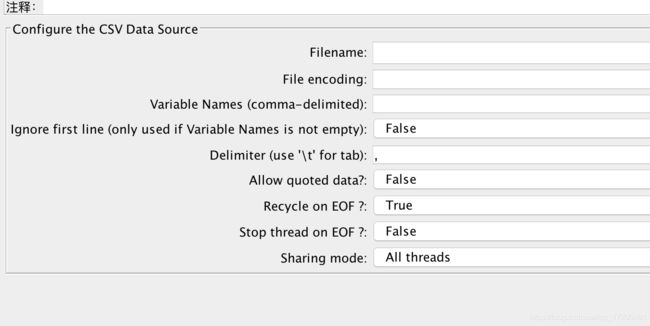
filename:引用文件地址
File encoding: 读取参数文件用到的编码格式
Variable Name:定义参数名称
Delimiter:用来分割参数文件的分隔符 \T
Allow quoted data:是否允许拆分参数里有分隔符出现 如: ”s,d,f“,sss
Recycle on EOF:参数文件循环遍历 True
Stop thread on EOF:当Recycle on EOF为False时,Stop thread on EOF为True:停止测试
sharing mode:参数文件共享模式: ALL Threads:同一计划中的不同线程组共享参数
Current thread group:仅对当前线程组中的线程共享
Current thread:仅对当前线程获取
使用参数:${}
配比
1、按线上接口请求里进行配置
2、配比原理
比如压测过程中,要访问百度和谷歌的请求占比是2:8。现在生产100个随机数,0-99,当随机数的取值是0-19时访问百度,当随机数的取值是20-99时访问谷歌。
3、方法:
添加->配置元件->Random Variable
设置随机数的变量名称Variable Name为num,设置取值范围Minimun value:0 , Maxinum为100
添加 —>逻辑控制器->如果(if)控制器 两个
设置条件 ${num} >20
每个if控制器下,分别添加1个请求。
k8s搭建jmeter环境
一、创建k8s集群
参考:https://www.cnblogs.com/yjmyzz/p/install-k8s-on-mac-using-minikube.html
二、安装jmeter
https://github.com/kubernauts/jmeter-operator
Jmeter + Grafana + InfluxDB 性能测试监控
参考:https://www.cnblogs.com/yyhh/p/5990228.html
http://jmeter.apache.org/usermanual/realtime-results.html
前提:Grafana安装,InfluxDB安装配置
参考:https://zhuanlan.zhihu.com/p/128058280
一、jmeter上添加 Backend Listener ,将实时压测数据写入InfluxDB.两种写入influxdb的数据不一样
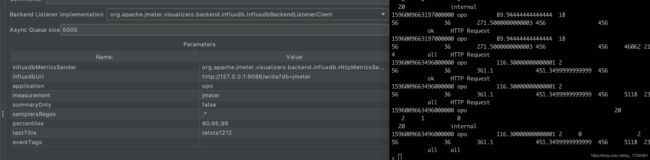
这种需要在influxdb上手动创建数据库
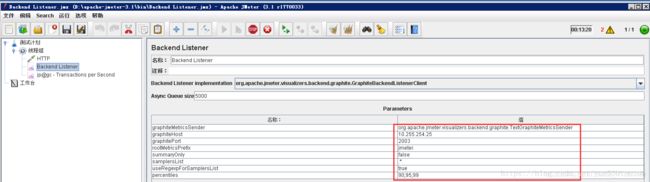
数据量小的时候InfluxDB的性能还可以,但是要存储几个月的数据,性能有问题。
二、Grafana添加InfluxDB数据库,输入帐号密码“admin / admin”,点击Test & Save 提示“Success”说明成功了

【注意】URL的端口是8086,而刚才配置的8083是UI的端口。
- 8083端口是InfluxDB的UI界面展示的端口
- 8086端口是Grafana用来从数据库取数据的端口
- 2003端口则是刚刚设置的,Jmeter往数据库发数据的端口
三、添加一个展示项目
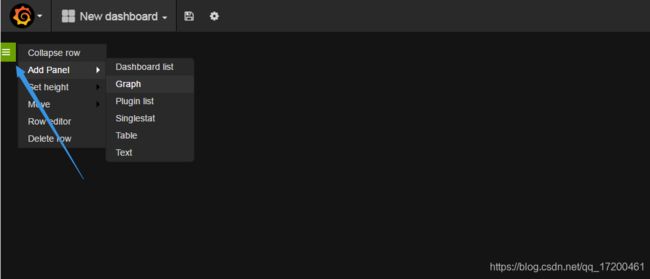
点击“Home -> New”
四、添加一个图表
点击旁边的绿点“Add Panel -> Graph”
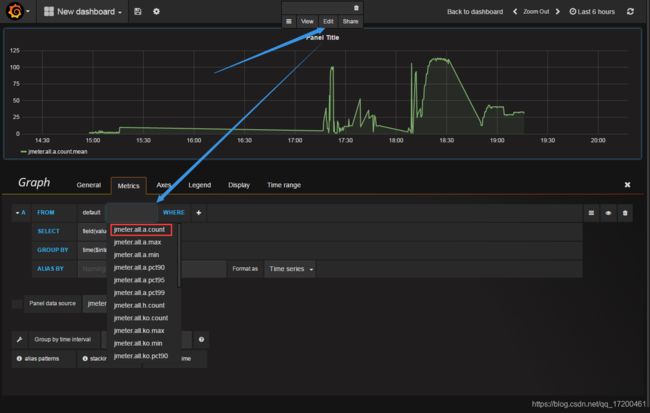
六、配置图表
配置好了,就能看到图了。如果看不到图,请用Jmeter多发几次Java请求。下图中选择监控的选项,可以在Jmeter的官网上查看到对应的解释。
jmeter分布式部署及操作
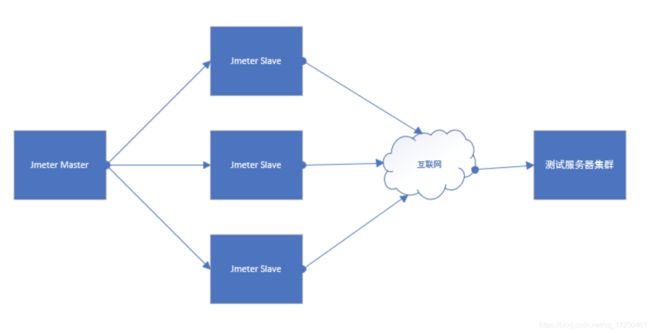
一、整体架构图
二、Jmeter分布式执行原理:
1、Jmeter分布式测试时,选择其中一台作为调度机(master),其它机器做为执行机(slave)。
2、执行时,master会把脚本发送到每台slave上,slave 拿到脚本后就开始执行,slave执行时不需要启动GUI,我理解它应该是通过命令行模式执行的。
3、执行完成后,slave会把结果回传给master,master会收集所有slave的信息并汇总。
4、比如我在jmeter server配置线程数为10,循环次数为100,也就是会对测试服务器发起1000次请求,我有3台agent服务器,如果我在server端选择远程启动压力测试,那么每台agent都会对测试服务器发起10100次请求,那么这次压力测试产生的请求就是10100*3=3000次。
三、部署及操作
1、准备几台压力机,在机器上装好Java环境和jmeter;版本保持一致,将其中一台作为调度机,其余做执行机。
(1)压力机最好和被压系统的服务器在一个网段中,这样可以排除网络的影响。
(2)压力测试瓶颈大都在带宽上面,需要保证压力机的带宽要比服务器的带宽高,不然压力上不去。
(3)需要保证server和agent之间的时间同步。
(4)关闭防火墙。
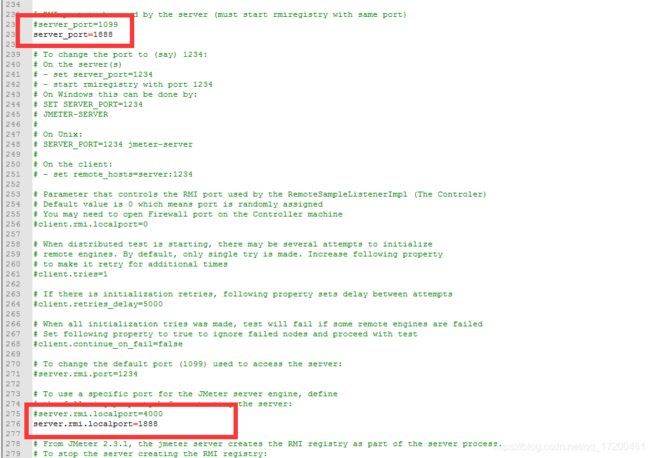
3、在调度机上打开jmeter的bin目录,编辑jmeter.properties文件,设置remote_hosts,将所有的执行机的ip和之前设置的端口写入用逗号隔开。

4、在执行机上打开jmeter的bin目录,编辑jmeter.properties文件,设置server.rmi.localport和server_port端口
5、运行所有执行机jmeter的bin目录下jmeter-server.bat,出现下图表示运行成功,图中端口是之前设置的端口表示你设置成功,否则重新设置下。

7、运行调度机的jmeter,添加好脚本,设置好线程数,点击远程启动所有即刻。

四、其它说明:
1、调度机(master)和执行机(slave)最好分开,由于master需要发送信息给slave并且会接收slave回传回来的测试数据,所以mater自身会有消耗,所以建议单独用一台机器作为mater。
2、参数文件:如果使用csv进行参数化,那么需要把参数文件在每台slave上拷一份且路径需要设置成一样的。
3、每台机器上安装的Jmeter版本和插件最好都一致,否则会出一些意外的问题。
使用命令行执行jmeter
一、示例: jmeter -n -t testplan.jmx -l test.jtl
表示以命令行模式 运行testplan.jmx文件,输出的日志文件为test.jtl
二、使用非 GUI 模式运行测试脚本时可以使用的一些命令
-h 帮助 -> 打印出有用的信息并退出
-n 非 GUI 模式 -> 在非 GUI 模式下运行 JMeter
-t 测试文件 -> 要运行的 JMeter 测试脚本文件
-l 日志文件 -> 记录结果的文件
-r 远程执行 -> 在Jmter.properties文件中指定的所有远程服务器
-e 在脚本运行结束后生成html报告
-o 用于存放html报告的目录
-H 代理主机 -> 设置 JMeter 使用的代理主机
-P 代理端口 -> 设置 JMeter 使用的代理主机的端口号


遇到问题:
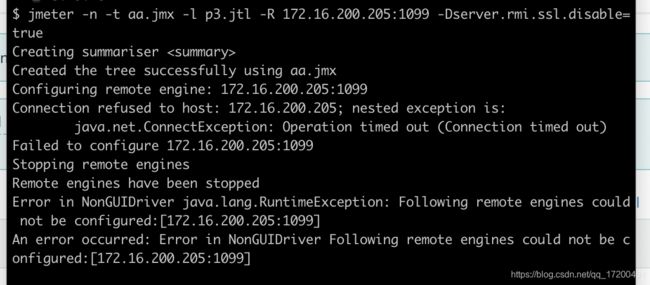
k8s搭建分布式压测环境
https://github.com/kubernauts/jmeter-operator
https://github.com/kubernauts/jmeter-kubernetes
kubectl执行压测命令
// 获取主节点信息
master_pod= ( k u b e c t l g e t p o − n " (kubectl get po -n " (kubectlgetpo−n"tenant" | grep jmeter-master | awk ‘{print $1}’)
// 将jmx文件拷贝到主节点根目录下
kubectl cp “ j m x d i r / {jmx_dir}/ jmxdir/{jmx_dir}.jmx” -n “ t e n a n t " " tenant" " tenant""master_pod”
// 获取从节点
slave_pods=( ( k u b e c t l g e t p o − n " (kubectl get po -n " (kubectlgetpo−n"tenant" | grep jmeter-slave | awk ‘{print $1}’))
// 获取从节点的总数
slavesnum=KaTeX parse error: Expected '}', got '#' at position 2: {#̲slave_pods[@]} …{#slavesnum}"
//切割csv文件并上传到多个节点
for csvfilefull in “ j m x d i r " / ∗ . c s v d o c s v f i l e = " {jmx_dir}"/*.csv do csvfile=" jmxdir"/∗.csvdocsvfile="{csvfilefull##/}"
printf “Processing %s file…\n” “ c s v f i l e " s p l i t − − s u f f i x − l e n g t h = " csvfile" split --suffix-length=" csvfile"split−−suffix−length="{slavedigits}” --additional-suffix=.csv -d --number=“l/ s l a v e s n u m " " {slavesnum}" " slavesnum""{jmx_dir}/ c s v f i l e " " {csvfile}" " csvfile""jmx_dir”/
j=0
for i in ( s e q − f " (seq -f "%0 (seq−f"{slavedigits}g" 0 ( ( s l a v e s n u m − 1 ) ) ) d o p r i n t f " C o p y ((slavesnum-1))) do printf "Copy %s to %s on %s\n" " ((slavesnum−1)))doprintf"Copy{i}.csv" “ c s v f i l e " " {csvfile}" " csvfile""{slave_pods[j]}”
kubectl -n “ t e n a n t " c p " tenant" cp " tenant"cp"{jmx_dir}/ i . c s v " " {i}.csv" " i.csv""{slave_pods[j]}”
kubectl -n “ t e n a n t " e x e c " tenant" exec " tenant"exec"{slave_pods[j]}” – mv -v /“ i . c s v " / " {i}.csv" /" i.csv"/"{csvfile}”
rm -v “ j m x d i r / {jmx_dir}/ jmxdir/{i}.csv”
let j=j+1
done # for i in "KaTeX parse error: Expected 'EOF', got '#' at position 23: …pods[@]}" done #̲ for csvfile in…{jmx_dir}/.csv”
//执行压测
kubectl exec -ti -n “ t e n a n t " " tenant" " tenant""master_pod” – /jmeter/load_test “/${jmx_dir}.jmx”
GraphiteBackendListenerClient
一、Jmeter默认选中的Implementatin是 GraphiteBackendListenerClient ,它是Jmeter 2.13就开始提供了;在Jmeter 3.2时又加多了一个 InfluxDBBackendListenerClient

graphiteHost:InfluxDB安装的服务器的ip
graphitePort:端口;默认就是2003,除非你自己安装InfluxDB时设置了其他端口是哦(可见上面安装InfluxDB后关于graphite的配置)
rootMetricsPrefix:指标的根前缀;将测试结果存入数据库时,不同指标会生成不同表,但这些表都最好要有一个共同的前缀,这个就是了;后面会讲到不同的指标的含义(重点哦)
summaryOnly:当你线程组有多个请求又想知道每个请求的结果数据时,最好填false,因为true只会返回所有请求的集合数据报告,不会输出每条请求的数据报告
samplersList:取样器列表;想收集哪些请求就填哪些,最好用正则去匹配,减轻工作量
useRegexpForSamplersList:是否使用正则;如果true则使用,samplersList里可以匹配正则表达式
percentiles:百分比;即类似聚合报告里90% Line,95% Line,99% Line的数据;倘若想要99.9时,需要写成【99_9】,用下划线代替点
二、
GraphiteBackendListenerClient,基于Graphite数据库
InfluxdbBackendListenerClient,基于InfluxDB数据库
二者都是基于时间序列的数据库,使用场景基本都偏向于监控系统的数据存储,从目前搜集的资料来看,InfluxDB的使用明显要高于Graphite
三、为什么每个表都有jmeter前缀呢?
因为在Jmeter的Backend Listener配置了rootMetricsPrefix 值为 jmeter. ,你不喜欢前缀或者想起其他名,在Backend Listener里直接改 rootMetricsPrefix 的值就可以了
四、每个前缀的含义
jmeter.all :代表了所有请求;当summaryOnly=true时,就只有samplerName=all的表了
jmeter.get :代表了HTTP请求的名字是get,即samplerName=get
jmeter.post :代表了HTTP请求的名字是post,即samplerName=post
InfluxdbBackendListenerClient
一、配置项:

1、summaryOnly
· summaryOnly是针对有多个接口同时测试的情况,只有summaryOnly为false时才会写入每个接口的数据,否则只会记录internal和all两个transaction的数据
· internal用来记录当前线程相关数据,已启动、运行中、已结束等线程数
· all用来记录汇总之后的测试数据,没有区分接口
2、samplersRegex
· 在summaryOnly=false的前提下(summaryOnly=true下是无效的),设samplersRegex为TestApi002时,这个时候只有002接口的数据写入了数据库
3、percentiles:根据自己需要配置所需的中位数
4、testTitle
测试名称;在 events 表中对应的字段是 text ,JMeter在测试的开始和结束时自动生成注释,该注释的值以’start’和’end’结尾
5、eventTags:Grafana允许为每个注释显示标签;在 events 表中对应的字段是 tags
二、数据库表:
运行过程中,influx会写入两个measurement
events:时间表,记录任务开始、结束等内容
jmeter:配置项measurement的值,对应着具体的测试数据
三、监听器内部运行过程
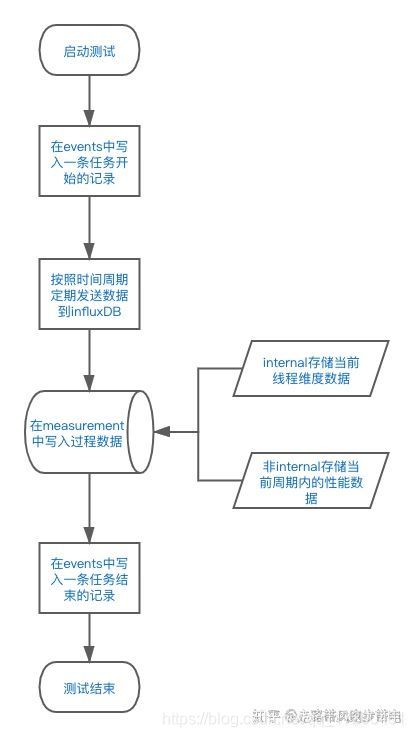
四、使用InfluxDBBackendListenerClient好处就是,再多的请求也只会生成两张表
Grafana&InfluxDB集成,展示测试结果数据
本方法只适合于使用InfluxDBBackendListenerClient的场景
首先,进入官方模板库: https://grafana.com/dashboards

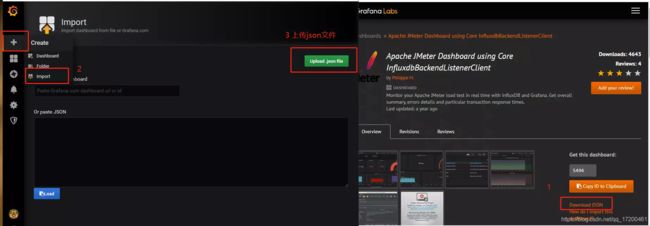

只要你的数据源,表名配的没有错,Jmeter再执行一下测试计划,DashBoard中筛选下时间,就可以成功看到数据啦!

模板自带了三个下拉筛选框
data_source:数据源,在Grafana配置了多少个就显示多少个
application:在Jmeter配置好的application,如果每次测试计划执行时的application都不一样,你就可以通过这个筛选出对应测试时机的结果数据了
transaction:在Jmeter配置好的sampleList,譬如我只发了get、post请求,这里就只会给你选get、post;可以滑到页面下面看到针对某个请求的数据展示
发压模式
压力模式有两种:并发模式(虚拟用户模式)、RPS模式(Requests Per Second,每秒请求数,吞吐量模式)。
并发模式:“并发”是指虚拟并发用户数,从业务角度,也可以理解为同时在线的用户数。 适用场景:如果需要从客户端的角度出发,摸底业务系统各节点能同时承载的在线用户数,可以使用该模式设置目标并发。
RPS模式:RPS(Requests Per Second)是指每秒请求数。 适用场景:RPS模式即“吞吐量模式”,通过设置每秒发出的请求数,从服务端的角度出发,直接衡量系统的吞吐能力,免去并发到RPS的繁琐转化,一步到位
RPS模式举例:某个API接口(如电商加购物车、下单等)有预期的TPS或通过以往经验得出最大承压量,可以选择该模式,直接按照预期的TPS设置RPS。如果希望检验“下单”接口是否能达到500 TPS的预期,直接设置预期RPS为500, 该模式支持压测过程中动态增加/减少QPS,规则同增减并发数,所以也可在运行过程中,不断调整QPS数。
RPS模式时,单台线程数和单台QPS如何设置? 在可估计出被测接口的平均响应时间或TP99时:如TP99大约在200ms左右, 200:1000=1:5,即单台线程数与单台QPS的最佳比例关系是1:5,也可1:6,1:7等,最好不要超过1:10。 不知道被测接口响应时间时,可按照默认设置进行试压测,然后根据压测情况调整。 对于响应时间过大,比如TP99超过2000ms,建议用并发模式逐步加并发到预期QPS。