【JavaEE初阶】计算机是如何工作的
☕导航小助手☕
写在前面
一、计算机发展历史
二、冯诺依曼体系
三、CPU
3.1 浅谈CPU
3.2 寄存器
3.3 指令
3.4 CPU的操作流程
3.5 时钟周期
四、编程语言
写在前面
本篇博客 主要介绍的是 计算机组成原理 的知识, 其重点在于介绍 计算机是如何工作的,计算机系统的各个组成部分,编程语言的发展史 等等的内容~~

一、计算机发展历史
人类历史上很多发明的东西,其最早的目的 就是为了 "军事"~~
计算机诞生于 "普林斯顿大学",发明者是 约翰·冯·诺依曼~~
最初计算机的诞生,是用来计算 "弹道导弹" 的轨迹~~

计算机硬件的发展过程:
第一代:电子管计算机
第二代:晶体管计算机
第三代:中小规模集成电路计算机
第四代:大规模和超大规模集成电路计算机
第五代:人工智能和大数据云服务的结合
摩尔定律:
集成电路上的晶体管数量每18月就会翻一翻,所以每18月计算机的处理效率就会提高一倍~~
二、冯诺依曼体系

存储器:分为 内存 和 外存~~
那么,内存和外存到底有哪些区别呢?
- 从存储空间上来看,内存空间一般要小于外存空间
- 从访问速度上来看, 访问内存的速度要比访问外存的速度快上3~4个数量级,要快上几千上万倍
- 内存所需要的成本要更高,一个非常大的内存,需要超超超超级氪金玩家才会用得起
- 对于内存来说,断电就会导致数据的丢失;对于外存来说,断电数据仍然不丢失(因此就引出了数据 "持久化"存储,即 把数据存储到外存(硬盘)里面)
输入设备:
输入设备主要有:键盘、鼠标、麦克风、摄像头......
它们都可以把外界的信息采集进来,传输到计算机里面
输出设备:
输出设备主要就是用来 给用户反馈一下信息的效果,
比如说,显示器、音箱......都是输出设备
不过需要注意的是,输入设备和输出设备不是严格意义上的分隔开的,
有的设备就是 既是输入设备,又是输出设备。
比如说,戳摸屏(如 手机上的触摸屏,既可以用来去看,又可以用来去摸)
比如说,网卡(上网的时候,通过网卡,既可以接收别人发过来的数据,又可以把自己想要发送的数据发送过去)
CPU:
中文名 "中央处理器",主要由 "运算器"和"控制器"组成~~
其中,控制器的功能是控制计算机各部分协调工作,运算器则是负责计算机的算术运算和逻辑运算~~
一台计算机,能够运行程序,能够进行算术运算,能够进行逻辑判断,全部都是靠 CPU~~
CPU 就相当于是计算机的大脑,是当前人类科技水平的巅峰之作~~
CPU特别特别重要,据说比氢弹还牛掰(据说 全世界 只有两个国家才可以制造出 CPU)~~
注意:
显卡和 CPU 本质上没有啥区别,
主要就是 CPU叫做通用计算芯片,应对各种计算场景;
而 显卡叫做专用计算芯片,特别擅长计算大规模浮点数,尤其是矩阵计算,运算量贼大(当然,这个CPU也可以做到,但是CPU可以做到的事情,显卡不一定可以做到),尤其是在游戏领域~~
可以类比于,CPU类似于大学生,学的东西可多啦;
而显卡类似于小学生,只会算 1+1;
而大学生也可以算 1+1哇~~
但是邀请小学生的代价低啊(即便有许多许多个小学生 也可能会低于 一个大学生)~~
所以说,显卡本质上也是 CPU,只不过这个 CPU 只是专门算 浮点运算的~~
三、CPU
3.1 浅谈CPU
由于 CPU 特别特别重要,特别特别牛掰,所以还需要浅浅的介绍一下 CPU 了......
CPU本质上是一系列的 "门电路" 来构成的~~
而所谓的 "门电路",就是最基本的 "与门"、"或门"、"非门" 等等门电路~~
在这里先不做过多解释,感兴趣的铁铁们 可以去看看关于数电、模电之类的书籍......
通过门电路,我们可以得到加法器来算出加法了,之后也可以算减法(补码存在的意义,就是是用加法来代替减法);再进一步,也可以算出乘法和除法了~~
也就是说,通过这些门电路,就构造出了计算单元~~
除此之外,还能够造出 控制单元,也可以构造处 存储单元~~
这些基本的组件,就够造成了完整的 CPU ~~
所以说,为啥我们认为 CPU 里面的制程越小越好?
——一个 CPU 芯片的面积是固定的,如果制程越小,单个门电路的体积就越小,整个 CPU 上面能够搭载的 门电路 数量就越多;数量越多,说明 CPU 上面的功能模块就越多,算的就越快(俗称 人多力量大)~~
说明:虽然我们希望它越小越好,但是也不能无限小(从物理角度上来说,现有科技在量子领域中还有很长的路要走)~~
刚刚介绍到,CPU 不可以无限小,而到了现在,CPU的算力已经接近于极限了~~
于是,现在的 CPU 发展路线,已经不仅仅是追求小了, 还要追求 "多核"了:
"单核" 搞不定的,可以用 "多核" 来凑,通过这样的方式,也可以从整体上提高 CPU 的算力~~
3.2 寄存器
寄存器 也是用来存储数据的一个组件,和内存(主储存器)都是属于储存器,除此之外,还包括外存(硬盘,磁盘等)~~
功能和内存都差不多,都是存储数据,都是断电就消失~~
只不过 寄存器 不是单独的硬件设备,而是长在 CPU 上的一个部件~~
换句话说, CPU 自身也有一定的数据存储能力~~
相比于内存来说,寄存器与它是有一定的区别的:
- 储存空间更小(内存可以有几十个G,而 寄存器一般就是几百个字节,最多只有几K)
- 访问速度更快(比内存又快了 3~4 个数量级)
寄存器搞这么小,是因为成本就比内存还要高出很多很多~~
现在,寄存器所起到的效果,就是用来辅助程序运行,存储程序运行中产生的一些中间结果~~
比如说,想计算一个 10+20,
就需要:
- 从 内存 中读取 10 到寄存器A中
- 从 内存 中读取 20 到寄存器B中
- 执行相加指令,把两个寄存器相加的值,保存到 寄存器A(或 寄存器B)中
- 把寄存器A(或 寄存器B)中的值写回内存
CPU 的计算是针对寄存器中的值进行的~~
3.3 指令
什么是指令?
简单的来说,指令就是人给计算机发布的命令~~
不过,计算机要想好好干活,那么程序员就需要把计算机所要干的活指定清楚、明确无歧义~~
而 程序员指定计算机干啥活的 过程就叫做 "编程",换句话说,程序员所写好的程序,里面就包含了许多的 "指令"~~
说明:
人写的 Java、C/C++ 这样的编程语言构成的代码(相对于来说更接近自然语言),
计算机并不认识,计算机所认识的是 二进制的指令,
因此 就会有这样一个环节,把人写的代码(高级语言) 翻译成 计算机所能识别的指令(机器语言),这个翻译的过程,就叫做 编译;完成这个 编译工作的程序,就叫做 编译器~~
那么,指令究竟是长什么样的呢?
| 指令 | 功能说明 | 4位 opcode(指令编码) | 操作的内存地址或者寄存器 |
|---|---|---|---|
| LOAD_A |
从 RAM 的指定地址,将数据加载到 A 寄存器
|
0010 |
4 位 RAM 地址
|
| LOAD_B |
从 RAM 的指定地址,将数据加载到 B 寄存器
|
0001 |
4 位 RAM 地址
|
| STORE_A |
将数据从 A 寄存器写RAM 的指定地址 | 0100 |
4 位 RAM 地址
|
| ADD |
计算两个指定寄存器的数据的和,并将结果放入第二个寄存器
|
1000 |
2 位的寄存器 ID
2 位的寄存器 ID
|
上面的 "指令表"中的指令 是一个极简版本,实际上 计算机(CPU)上面支持的指令很多~~
内存地址:把内存进行了编号~
把内存想象成 宿舍楼的大走廊,每个房间都有编号,按照一定的顺序 依次往下累加,
而内存是 从0开始依次往下累加的,
这个房间号,就是内存的地址~
以八位的指令为例,前四位表示操作码,后四位表示被操作数据的地址:
LOAD_A指令:0010 0111 表示将 0111 地址的数据加载到寄存器A~~
LOAD_B指令:0001 0101 表示将 0101 地址的数据加载到寄存器B~~
STORE_A指令:0100 0011 表示将寄存器A中的数据保存到 0011 所处的空间~~
ADD指令:将两个寄存器的结果相加,并将结果保存至第二个寄存器,如1000 0001将00寄存器的数据与01寄存器的数据进行相加,并将计算结果放入寄存器01~~但是,以上的规则是咋们自己设定的,真实的计算机是一个套路,但是情况比这个要复杂的多(比如说 并不是拿4个比特位 表示一个操作码,比如说 操作地址并不是4位,也有可能是32位、64位等等)~~
3.4 CPU的操作流程
| 地址(十进制) | 数据(二进制) |
|---|---|
| 0 | 0010 1110 |
| 1 | 0001 1111 |
| 2 | 1000 0100 |
| 3 | 0100 1101 |
| 4 | 0000 0000 |
| 5 | 0000 0000 |
| 6 | 0000 0000 |
| 7 | 0000 0000 |
| 8 | 0000 0000 |
| 9 | 0000 0000 |
| 10 | 0000 0000 |
| 11 | 0000 0000 |
| 12 | 0000 0000 |
| 13 | 0000 0000 |
| 14 | 0000 0011 |
| 15 | 0000 1110 |
这个表表示内存中的一个片段,每一个内存地址里存的都是一个指令~~
每一个指令都是按照上述 "指令表" 来展开的~~
接下来指令加载到内存之后,CPU就可以执行程序了~~
(1)CPU 先从内存中读取指令~~
从哪个地址开始读?
在 CPU 里有一个特殊的寄存器,叫做 "程序计数器",也称为 "PC指针"~~
实际上在 x86_32 CPU 叫做 eip寄存器~~
程序计数器中就包含了一个 "地址",表示接下来要读哪个内存里的指令~~
(程序计数器 就像书签一样,书签往书里面一夹,就知道书已经读到哪里了)
程序一启动的时候,程序计数器一般就会有一个初始值,就会从程序的入口代码开始读取指令了~~
初始情况下,如上表 就会读到 地址是 0 的数据 0010 1110~~
(2)解析指令
读取指令之后,就需要解析指令了~~
对照前面的 "指令表" 来看,0010 1110 是啥意思~~
按照上述设定,每个指令 是 8 bit,包含两个部分:
前 4 bit 是指令的操作码(opcode),指令要干啥;
后 4 bit 是操作数,不同的指令操作数不一样~~
对照前面的 "指令表" 可以知道,0010是LOAD_A,1110是 要读的内存地址,
所以它的意思是:从 1110 这个地址里 读一个字节到 A 寄存器中~~
(3)执行指令
二进制1110 翻译成十进制 就是 14 ,可以观察上表,发现 地址是14的 数据为 0000 0011,也就是十进制的3~~
于是,就向寄存器A 放了一个3~~
此时,执行完第一条指令以后,程序计数器就会累加,从一开始的 0 变成了 1,执行下一条指令(地址是1,数据是 0001 1111)......
这就是CPU基本的工作过程:读取指令、解析指令、执行指令~~
但是,虽然看起来好像是 CPU先读一条指令,解析指令,执行指令;再读下一条指令,......
可是实际上并不是这样,反而是类似于 "流水线" 的方式执行的:
这种方式 禁止摸鱼!!!
这样的设计 主要的目的是:可以提高程序的执行效率,可以保证各单位都在满负荷工作~~

在流水线的过程中 涉及到一个很重要的关键的环节——谁是第二条指令~~
如果只是单纯的顺序语句,第二条指令 地址往后累加就行了~~
如果是条件判断,循环,函数等等,程序计数器就不是单纯累加,就有可能会跳过很多地址~~
可是,如果不知道谁是第二条指令,那应该怎么办去读呢?
——既然不知道下一条指令是哪一个,那么 CPU 就会猜一下(即 分支预测)
如果 CPU 猜中了,那么 流水线仍然可以继续好好跑;
如果 CPU 猜错了,也没有关系,重新按照实际情况再读一遍指令就可以了~~
3.5 时钟周期
前面所说过,CPU 是按照 "流水线" 的方式来执行的~~
如果要想这几个流水线之间可以相互协同工作、有节奏的配合的话~~
那就需要:"时钟周期" 来进行帮助~~
类似于拔河比赛,除了有运动员使劲拽绳子,还需要有一个人喊口号:需要让运动员们 力气向着一处使~~
而这个 喊口号的人 就相当于是 时钟周期~~

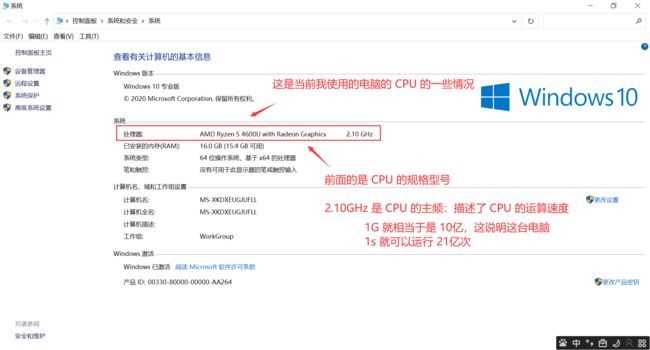
如上图所示,当前我使用的电脑的主频是 2.10GHz,也可以看作当前电脑 CPU 1秒钟就有 2.10亿个时钟周期~~
其实,每一个指令的执行都需要消耗 几个时钟周期的,但是 在流水线的生产环境下,可以简单的视为 一个指令消耗了一个时钟周期~~
四、编程语言
机器语言:
又称为 二进制代码语言,需要程序员来记忆每一条指令的代码~~
但是,在这种情况下,效率贼低~~
可是,机器语言 却是计算机唯一可识别和执行的语言~~
汇编语言:
为了提升编程的效率,最早创造了汇编语言的概念~~
汇编语言就是 用英文单词或者其缩写代替二进制的代码,使人们更容易记忆和理解~~
其实,汇编语言 和 机器语言(也就是指令)是一一对应的,只是相对于0、1这些数字,发明了一些帮助人类理解和记忆的 符号将其对应起来,也就是 上面的 类似于LOAD_A,LOAD_B等等~~
程序员完成编译之后,需要使用 汇编器 将汇编语言翻译成机器语言,以便计算机可以识别和执行~~
高级语言:
虽然汇编语言降低了程序员的记忆成本,但是仍然要求程序员必须掌握 计算机硬件的所有知识~~
但是,随着计算机的厂商越来越多,一次编写的程序 往往只适用于一类计算机~~
但是这仍然不够,所以更高级的语言诞生了(如 C/C++,Java 等等),屏蔽了各种细节,程序员可以站在更高的层面上思考自己的业务~~
总结来说,我们所写的代码 都会被编译器转换成 许多条 CPU 可以识别的机器语言指令,CPU 执行这些指令以后,实现程序的功能~~
注意:高级语言的一条语句 往往对应很多条指令 才能完成~~
这一篇文章的目标 是为了让大家了解到 计算机是如何工作的,了解到计算机是如何编写我们所写的代码的~~
如果感觉这篇文章对大家有帮助的话,点赞评论关注走一波,非常非常感谢啦~~
