集群(mysql,redis,elasticsearch,rabbitmq)
集群
1. 集群的目标
高可用(High Availability),是当一台服务器停止服务后,对于业务及用户毫无影响。 停止服务的原因可能由于网卡、路由器、机房、CPU负载过高、内存溢出、自然灾害等不可预期的原因导致,在很多时候也称单点问题。突破数据量限制,一台服务器不能储存大量数据,需要多台分担,每个存储一部分,共同存储完整个集群数据。最好能做到互相备份,即使单节点故障,也能在其他节点找到数据。数据备份容灾,单点故障后,存储的数据仍然可以在别的地方拉起。压力分担,由于多个服务器都能完成各自一部分工作,所以尽量的避免了单点压力的存在
2. 集群的基础基础形式
2.1 主从式
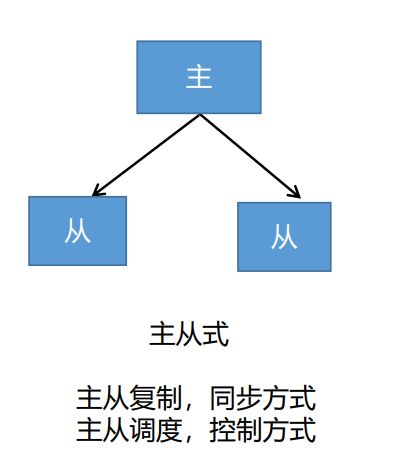
2.2 分片式
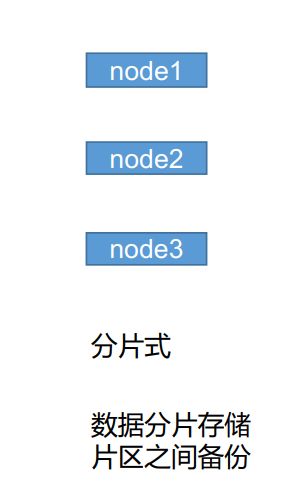
2.3 选主式

3. mysql集群
3.1 企业中常用的数据库解决方案

3.2 mysql常见的几种集群方式
3.2.1 MYSQl-MMM(Master-Master Replication Manager for MySQL
MySQL-MMM 是 Master-Master Replication Manager for MySQL(mysql 主主复制管理器) 的简称, 是 Google 的开源项目(Perl 脚本) 。
MMM 基于 MySQL Replication 做的扩展架构, 主要用来监控 mysql 主主复制并做失败转移。 其原理是将真实数据库节点的IP(RIP) 映射为虚拟 IP(VIP) 集。mysql-mmm 的监管端会提供多个虚拟 IP(VIP) , 包括一个可写 VIP,多个可读 VIP, 通过监管的管理, 这些 IP 会绑定在可用 mysql 之上, 当某一台 mysql 宕机时, 监管会将 VIP迁移至其他 mysql。在整个监管过程中, 需要在 mysql 中添加相关授权用户, 以便让 mysql 可以支持监理机的维护。 授权的用户包括一个mmm_monitor 用户和一个mmm_agent用户, 如果想使用 mmm 的备份工具则还要添加一个 mmm_tools 用户。

3.2.2 MYSQL-MHA(mysql 主主复制管理器)
MHA(Master High Availability) 目前在 MySQL 高可用方面是一个相对成熟的解决方案,由日本 DeNA 公司 youshimaton(现就职于 Facebook 公司) 开发, 是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在 MySQL故障切换过程中,MHA 能做到在 0~30 秒之内自动完成数据库的故障切换操作(以 2019 年的眼光来说太慢了) , 并且在进行故障切换的过程中, MHA 能在最大程度上保证数据的一致性, 以
达到真正意义上的高可用。
3.2.3 InnoDB Cluster
InnoDB Cluster 支持自动 Failover、 强一致性、 读写分离、 读库高可用、 读请求负载均衡, 横向扩展的特性, 是比较完备的一套方案。
但是部署起来复杂, 想要解决 router单点问题好需要新增组件, 如没有其他更好的方案可考虑该方案。 InnoDB Cluster 主要由 MySQL Shell、 MySQL Router 和 MySQL 服务器集群组成, 三者协同工作, 共同为MySQL 提供完整的高可用性解决方案。
MySQL Shell 对管理人员提供管理接口, 可以很方便的对集群进行配置和管理
MySQL Router 可以根据部署的集群状况自动的初始化, 是客户端连接实例。 如果有节点 down 机, 集群会自动更新配置。 集群包含单点写入和多点写入两种模式。 在单主模式下, 如果主节点 down 掉, 从节点自动替换上来,MySQL Router 会自动探测, 并将客户端连接到新节点。

3.3 Docker 安装模拟 MySQL 主从复制集群
3.3.1 下载 mysql 镜像
docker pull mysql:5.7
3.3.2 主节点创建
3.3.2.1 创建 Master 实例并启动
docker run -p 3307:3306 --name mysql-master \
-v /mydata/mysql/master/log:/var/log/mysql \
-v /mydata/mysql/master/data:/var/lib/mysql \
-v /mydata/mysql/master/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
参数说明
-p 3307:3306: 将容器的 3306 端口映射到主机的 3307 端口
-v /mydata/mysql/master/conf:/etc/mysql: 将配置文件夹挂在到主机
-v /mydata/mysql/master/log:/var/log/mysql: 将日志文件夹挂载到主机
-v /mydata/mysql/master/data:/var/lib/mysql/: 将配置文件夹挂载到主机
-e MYSQL_ROOT_PASSWORD=root: 初始化 root 用户的密码
3.3.2.2 修改 master 基本配置
vim /mydata/mysql/master/conf/my.cnf
为my.cnf写入一下配置 基本上就是设置字符集
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
注意: skip-name-resolve 一定要加, 不然连接 mysql 会超级慢
3.3.2.3 添加 master 主从复制部分配置
为my.cnf写入一下配置
server_id=1 #指定集群id
log-bin=mysql-bin #打开二进制日志功能
read-only=0 #关闭只读,可读可写
binlog-do-db=gulimall_ums #指定mysql的binlog日志记录哪个db
binlog-do-db=gulimall_pms
binlog-do-db=gulimall_oms
binlog-do-db=gulimall_sms
binlog-do-db=gulimall_wms
binlog-do-db=gulimall_admin
replicate-ignore-db=mysql #用来设置不需要同步的库,此处指定的mysql系统库
replicate-ignore-db=sys
replicate-ignore-db=information_schema
replicate-ignore-db=performance_schema
3.3.2.4 重启master
docker restart mysql-master
3.3.3 从节点创建
3.3.3.1 创建 Master 实例并启动
docker run -p 3317:3306 --name mysql-slaver-01 \
-v /mydata/mysql/slaver/log:/var/log/mysql \
-v /mydata/mysql/slaver/data:/var/lib/mysql \
-v /mydata/mysql/slaver/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
3.3.3.2 修改 slaver-01基本配置
vim /mydata/mysql/slaver/conf/my.cnf
为my.cnf写入一下配置 基本上就是设置字符集
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
3.3.3.3 添加 master 主从复制部分配置
server_id=2 #注意此处id不能与主节点相同
log-bin=mysql-bin
read-only=1binlog-do-db=gulimall_ums
binlog-do-db=gulimall_pms
binlog-do-db=gulimall_oms
binlog-do-db=gulimall_sms
binlog-do-db=gulimall_wms
binlog-do-db=gulimall_admin
replicate-ignore-db=mysql
replicate-ignore-db=sys
replicate-ignore-db=information_schema
replicate-ignore-db=performance_schema
3.3.3.4 重启slaver-01
docker restart mysql-master
3.3.4 为 master 授权用户来他的同步数据
3.3.4.1 进入docker容器
docker exec -it mysql-master /bin/bash
3.3.4.2 进入mysql内部
mysql –uroot -p
Enter password: root
3.3.4.2.1 授权 root 可以远程访问 ( 主从无关, 为了方便我们远程连接 mysql)
#授权
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
#刷新权限
flush privileges;
3.3.4.2.2 添加用来同步的用户
GRANT REPLICATION SLAVE ON *.* to 'backup'@'%' identified by '123456';
backup为账号名,123456为账号密码
3.3.4.3 查看master状态

3.3.5 为 slaver-01授权用户来他的同步数据
3.3.5.1 进入docker容器
docker exec -it mysql-slaver-01 /bin/bash
3.3.5.2 进入mysql内部
mysql –uroot -p
Enter password: root
3.3.5.2.1 授权 root 可以远程访问 ( 主从无关, 为了方便我们远程连接 mysql)
#授权
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
#刷新权限
flush privileges;
3.3.5.2.2 设置主库连接

change master to master_host='192.168.157.128',master_user='backup',master_password='123456',master_log_file='mysql-bin.000001',master_log_pos=0,master_port=3307;
master_host:主节点虚拟机ip
master_user:用于连接主机的集群账号
master_password:用于连接主机的集群密码
master_log_file必须与3.3.4.3的File字段一致,Position不用一致后面会自动同步
3.3.5.2.3 启用主从同步
start slave;
3.3.5.3 查看从库状态
show slave status

3.4 主从同步测试
主节点新建数据库gulimall_admin,从机刷新后也有相同数据库,只要此处同步其实就代表成功了

在主节点执行gulimall_admin.sql文件
主节点的表结构与数据也同步过来了

3.5 mysql主从配置总结
- 主从数据库在自己配置文件中声明需要同步哪个数据库, 忽略哪个数据库等信息。并且 server-id 不能一样
- 主库授权某个账号密码来同步自己的数据
- 从库使用这个账号密码连接主库来同步数据
3.6 mysql分库,分表,读写分离(shardingsphere)
Apache ShardingSphere 产品定位为 Database Plus,旨在构建异构数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。ShardingSphere 站在数据库的上层视角,关注他们之间的协作多于数据库自身。
连接、增量和可插拔是 Apache ShardingSphere 的核心概念。
连接:通过对数据库协议、SQL 方言以及数据库存储的灵活适配,快速的连接应用与多模式的异构数据库;增量:获取数据库的访问流量,并提供流量重定向(数据分片、读写分离、影子库)、流量变形(数据加密、数据脱敏)、流量鉴权(安全、审计、权限)、流量治理(熔断、限流)以及**流量分析(服务质量分析、可观察性)**等透明化增量功能;可插拔:项目采用微内核 + 三层可插拔模型,使内核、功能组件以及生态对接完全能够灵活的方式进行插拔式扩展,开发者能够像使用积木一样定制属于自己的独特系统。
Apache ShardingSphere 由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的基于数据库作为存储节点的增量功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
3.6.1 shardingsphere三大组件
3.6.1.1 ShardingSphere-JDBC
定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC;
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库。

3.6.1.2 ShardingSphere-Proxy
定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前提供 MySQL 和 PostgreSQL(兼容 openGauss 等基于 PostgreSQL 的数据库)版本,它可以使用任何兼容 MySQL/PostgreSQL 协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat 等)操作数据,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用;
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端。

3.6.1.3 ShardingSphere-Sidecar(TODO)
定位为 Kubernetes 的云原生数据库代理,以 Sidecar 的形式代理所有对数据库的访问。 通过无中心、零侵入的方案提供与数据库交互的啮合层,即 Database Mesh,又可称数据库网格。
Database Mesh 的关注重点在于如何将分布式的数据访问应用与数据库有机串联起来,它更加关注的是交互,是将杂乱无章的应用与数据库之间的交互进行有效地梳理。 使用 Database Mesh,访问数据库的应用和数据库终将形成一个巨大的网格体系,应用和数据库只需在网格体系中对号入座即可,它们都是被啮合层所治理的对象。

3.6.1.4 对比(独立部署)
| ShardingSphere-JDBC | ShardingSphere-Proxy | ShardingSphere-Sidecar | |
|---|---|---|---|
| 数据库 | 任意 | MySQL/PostgreSQL | MySQL/PostgreSQL |
| 连接消耗数 | 高 | 低 | 高 |
| 异构语言 | 仅 Java | 任意 | 任意 |
| 性能 | 损耗低 | 损耗略高 | 损耗低 |
| 无中心化 | 是 | 否 | 是 |
| 静态入口 | 无 | 有 | 无 |
3.6.1.5 混合架构
ShardingSphere-JDBC 采用无中心化架构,与应用程序共享资源,适用于 Java 开发的高性能的轻量级 OLTP 应用; ShardingSphere-Proxy 提供静态入口以及异构语言的支持,独立于应用程序部署,适用于 OLAP 应用以及对分片数据库进行管理和运维的场景。
Apache ShardingSphere 是多接入端共同组成的生态圈。 通过混合使用 ShardingSphere-JDBC 和 ShardingSphere-Proxy,并采用同一注册中心统一配置分片策略,能够灵活的搭建适用于各种场景的应用系统,使得架构师更加自由地调整适合于当前业务的最佳系统架构。
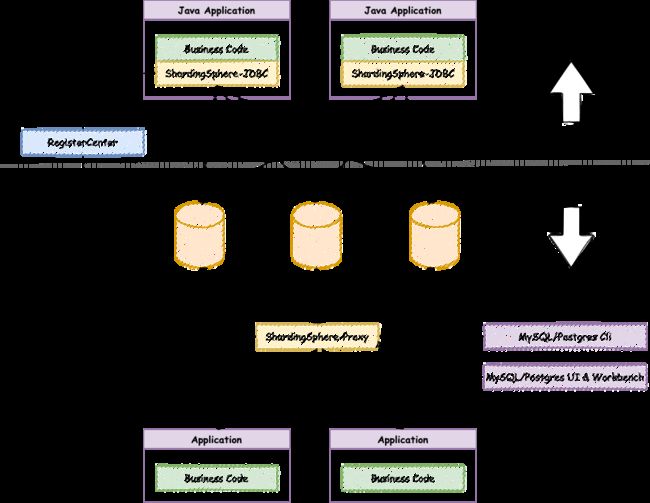
3.6.1.6 解决方案
| 解决方案/功能 | 分布式数据库 | 数据安全 | 数据库网关 | 全链路压测 |
|---|---|---|---|---|
| 数据分片 | 数据加密 | 异构数据库支持 | 影子库 | |
| 读写分离 | 行级权限(TODO) | SQL 方言转换(TODO) | 可观测性 | |
| 分布式事务 | SQL 审计(TODO) | |||
| 弹性伸缩 | SQL 防火墙(TODO) | |||
| 高可用 |
3.6.2 ShardingSphere-Proxy实现分库分表,读写分离

3.6.2.1 下载 ShardingSphere-Proxy 的最新发行版。
ShardingSphere-Proxy历史版本下载地址
此处我使用的4.1.1版本老师使用的4.0.0版本我没有找到
3.6.2.2 数据库驱动-jdbc下载
mysql-jdbc下载地址
将 MySQL 的 JDBC 驱动程序复制至目录 lib目录下。
3.6.2.3 修改配置文件
解压缩后修改 conf/server.yaml 和以 config- 前缀开头的文件,如:conf/config-xxx.yaml 文件,进行分片规则、读写分离规则配置。配置方式请参考配置手册。
3.6.2.3.1 配置认证信息(server.yaml)
可配置注册中心,认证信息,及一些共有属性
authentication:
users:
root:
password: root
sharding:
password: sharding
authorizedSchemas: sharding_db
props:
# max.connections.size.per.query: 1
# acceptor.size: 16 # The default value is available processors count * 2.
executor.size: 16 # Infinite by default.
# proxy.frontend.flush.threshold: 128 # The default value is 128.
# # LOCAL: Proxy will run with LOCAL transaction.
# # XA: Proxy will run with XA transaction.
# # BASE: Proxy will run with B.A.S.E transaction.
# proxy.transaction.type: LOCAL
# proxy.opentracing.enabled: false
# proxy.hint.enabled: false
# query.with.cipher.column: true
sql.show: true
# allow.range.query.with.inline.sharding: false

3.6.2.3.2 分库分表配置(conf/config-sharding.yaml)
配置mysql的分库分表策略
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
######################################################################################################
#
# Here you can configure the rules for the proxy.
# This example is configuration of sharding rule.
#
# If you want to use sharding, please refer to this file;
# if you want to use master-slave, please refer to the config-master_slave.yaml.
#
######################################################################################################
#
#schemaName: sharding_db
#
#dataSources:
# ds_0:
# url: jdbc:postgresql://127.0.0.1:5432/demo_ds_0?serverTimezone=UTC&useSSL=false
# username: postgres
# password: postgres
# connectionTimeoutMilliseconds: 30000
# idleTimeoutMilliseconds: 60000
# maxLifetimeMilliseconds: 1800000
# maxPoolSize: 50
# ds_1:
# url: jdbc:postgresql://127.0.0.1:5432/demo_ds_1?serverTimezone=UTC&useSSL=false
# username: postgres
# password: postgres
# connectionTimeoutMilliseconds: 30000
# idleTimeoutMilliseconds: 60000
# maxLifetimeMilliseconds: 1800000
# maxPoolSize: 50
#
#shardingRule:
# tables:
# t_order:
# actualDataNodes: ds_${0..1}.t_order_${0..1}
# tableStrategy:
# inline:
# shardingColumn: order_id
# algorithmExpression: t_order_${order_id % 2}
# keyGenerator:
# type: SNOWFLAKE
# column: order_id
# t_order_item:
# actualDataNodes: ds_${0..1}.t_order_item_${0..1}
# tableStrategy:
# inline:
# shardingColumn: order_id
# algorithmExpression: t_order_item_${order_id % 2}
# keyGenerator:
# type: SNOWFLAKE
# column: order_item_id
# bindingTables:
# - t_order,t_order_item
# defaultDatabaseStrategy:
# inline:
# shardingColumn: user_id
# algorithmExpression: ds_${user_id % 2}
# defaultTableStrategy:
# none:
######################################################################################################
#
# If you want to connect to MySQL, you should manually copy MySQL driver to lib directory.
#
######################################################################################################
schemaName: sharding_db
dataSources: #数据源配置
ds_0:
url: jdbc:mysql://192.168.157.128:3307/demo_ds_0?serverTimezone=UTC&useSSL=false
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
ds_1:
url: jdbc:mysql://192.168.157.128:3307/demo_ds_1?serverTimezone=UTC&useSSL=false
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
shardingRule: #分片规则
tables: #针对那几张表
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1} #真实的数据节点对应上面配置的数据源
tableStrategy: #分库策略
inline:
shardingColumn: order_id #根据什么字段
algorithmExpression: t_order_${order_id % 2} #分片算法
keyGenerator: #主键生成策略
type: SNOWFLAKE #类型
column: order_id #主键字段
t_order_item:
actualDataNodes: ds_${0..1}.t_order_item_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_item_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_item_id
bindingTables: #绑定表,即分片规则一致的关系表,互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,可以提升关联查询效率。
- t_order,t_order_item
defaultDatabaseStrategy: #默认分库策略
inline:
shardingColumn: user_id
algorithmExpression: ds_${user_id % 2}
defaultTableStrategy: #默认分表策略
none:
注意事项

3.6.2.3.3 主从读写分离配置(conf/config-master_slave.yaml)
配置两主两从
config-master_slave.yaml改名config-master_slave1.yaml,再复制config-master_slave2.yaml
config-master_slave1.yaml
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
######################################################################################################
#
# Here you can configure the rules for the proxy.
# This example is configuration of master-slave rule.
#
# If you want to use master-slave, please refer to this file;
# if you want to use sharding, please refer to the config-sharding.yaml.
#
######################################################################################################
#
#schemaName: master_slave_db
#
#dataSources:
# master_ds:
# url: jdbc:postgresql://127.0.0.1:5432/demo_ds_master?serverTimezone=UTC&useSSL=false
# username: postgres
# password: postgres
# connectionTimeoutMilliseconds: 30000
# idleTimeoutMilliseconds: 60000
# maxLifetimeMilliseconds: 1800000
# maxPoolSize: 50
# slave_ds_0:
# url: jdbc:postgresql://127.0.0.1:5432/demo_ds_slave_0?serverTimezone=UTC&useSSL=false
# username: postgres
# password: postgres
# connectionTimeoutMilliseconds: 30000
# idleTimeoutMilliseconds: 60000
# maxLifetimeMilliseconds: 1800000
# maxPoolSize: 50
# slave_ds_1:
# url: jdbc:postgresql://127.0.0.1:5432/demo_ds_slave_1?serverTimezone=UTC&useSSL=false
# username: postgres
# password: postgres
# connectionTimeoutMilliseconds: 30000
# idleTimeoutMilliseconds: 60000
# maxLifetimeMilliseconds: 1800000
# maxPoolSize: 50
#
#masterSlaveRule:
# name: ms_ds
# masterDataSourceName: master_ds
# slaveDataSourceNames:
# - slave_ds_0
# - slave_ds_1
######################################################################################################
#
# If you want to connect to MySQL, you should manually copy MySQL driver to lib directory.
#
######################################################################################################
schemaName: sharding_db_2
dataSources:
master_0_ds:
url: jdbc:mysql://192.168.157.128:3307/demo_ds_0?serverTimezone=UTC&useSSL=false
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
slave_ds_0:
url: jdbc:mysql://192.168.157.128:3317/demo_ds_0?serverTimezone=UTC&useSSL=false
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
masterSlaveRule:
name: ms_ds
masterDataSourceName: master_0_ds
slaveDataSourceNames:
- slave_ds_0
# - slave_ds_1
loadBalanceAlgorithmType: ROUND_ROBIN
config-master_slave2.yaml
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
######################################################################################################
#
# Here you can configure the rules for the proxy.
# This example is configuration of master-slave rule.
#
# If you want to use master-slave, please refer to this file;
# if you want to use sharding, please refer to the config-sharding.yaml.
#
######################################################################################################
#
#schemaName: master_slave_db
#
#dataSources:
# master_ds:
# url: jdbc:postgresql://127.0.0.1:5432/demo_ds_master?serverTimezone=UTC&useSSL=false
# username: postgres
# password: postgres
# connectionTimeoutMilliseconds: 30000
# idleTimeoutMilliseconds: 60000
# maxLifetimeMilliseconds: 1800000
# maxPoolSize: 50
# slave_ds_0:
# url: jdbc:postgresql://127.0.0.1:5432/demo_ds_slave_0?serverTimezone=UTC&useSSL=false
# username: postgres
# password: postgres
# connectionTimeoutMilliseconds: 30000
# idleTimeoutMilliseconds: 60000
# maxLifetimeMilliseconds: 1800000
# maxPoolSize: 50
# slave_ds_1:
# url: jdbc:postgresql://127.0.0.1:5432/demo_ds_slave_1?serverTimezone=UTC&useSSL=false
# username: postgres
# password: postgres
# connectionTimeoutMilliseconds: 30000
# idleTimeoutMilliseconds: 60000
# maxLifetimeMilliseconds: 1800000
# maxPoolSize: 50
#
#masterSlaveRule:
# name: ms_ds
# masterDataSourceName: master_ds
# slaveDataSourceNames:
# - slave_ds_0
# - slave_ds_1
######################################################################################################
#
# If you want to connect to MySQL, you should manually copy MySQL driver to lib directory.
#
######################################################################################################
schemaName: sharding_db_1
dataSources:
master_1_ds:
url: jdbc:mysql://192.168.157.128:3307/demo_ds_1?serverTimezone=UTC&useSSL=false
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
slave_ds_1:
url: jdbc:mysql://192.168.157.128:3317/demo_ds_1?serverTimezone=UTC&useSSL=false
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
masterSlaveRule:
name: ms_ds
masterDataSourceName: master_1_ds
slaveDataSourceNames:
# - slave_ds_0
- slave_ds_1
loadBalanceAlgorithmType: ROUND_ROBIN
启动测试
出现以下日志信息,代表没有找到对应的数据源信息,只需要创建对应数据库即可

3.6.2.3.4 新增主从复制关联数据库
修改主节点配置
vim /mydata/mysql/master/conf/my.cnf
#新增以下配置
binlog-do-db=demo_ds_0
binlog-do-db=demo_ds_1
修改从节点配置
vim /mydata/mysql/slaver/conf/my.cnf
#新增以下配置
binlog-do-db=demo_ds_0
binlog-do-db=demo_ds_1
重启mysql集群
docker restart mysql-master mysql-slaver-01
在主节点新建数据库demo_ds_0 demo_ds_1,因为之前配置的主从复制在从节点中也会增加两个对应的数据库


3.6.2.3.5 启动连接测试
启动成功

指定端口启动
C:\Users\eric\Desktop\apache-shardingsphere-4.1.1-sharding-proxy-bin\bin>start.bat 3388
3.6.2.3.6 Navicat天坑注意
使用Navicat连接测试
此处我遇到了一个天坑要注意,我可以正常使用Navicat连上代理,但是就是有问题,jdbc驱动换了5.1.47和8.0.11都不行,推测是我的Navicat版本和老师的不一样


最后我使用命令行的方式连接代理,就是正常的whats up,10.0.0.124是我本机地址

3.6.2.3.7 分库分表测试
切换到sharding_db数据库
use sharding_db
创建测试表
t_order
CREATE TABLE `t_order` (
`order_id` bigint(20) NOT NULL,
`user_id` int(11) NOT NULL,
`status` varchar(50) COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
创建测试表
t_order_item
CREATE TABLE `t_order_item` (
`order_item_id` bigint(20) NOT NULL,
`order_id` bigint(20) NOT NULL,
`user_id` int(11) NOT NULL,
`content` varchar(255) COLLATE utf8_bin DEFAULT NULL,
`status` varchar(50) COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (`order_item_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
向
t_order插入数据
INSERT INTO t_order (user_id, status) VALUES (1, 1);
INSERT INTO t_order (user_id, status) VALUES (2, 1);
INSERT INTO t_order (user_id, status) VALUES (3, 1);
INSERT INTO t_order (user_id, status) VALUES (4, 1);
INSERT INTO t_order (user_id, status) VALUES (5, 1);
INSERT INTO t_order (user_id, status) VALUES (6, 1);
INSERT INTO t_order (user_id, status) VALUES (7, 1);
查询sharding_db中
t_order的数据
select * from t_order;

查询主节点,demo_ds_0分库的t_order_0分表
无数据

查询主节点,demo_ds_0分库的t_order_1分表
有三条数据

查询主节点,demo_ds_1分库的t_order_0分表
有四条数据
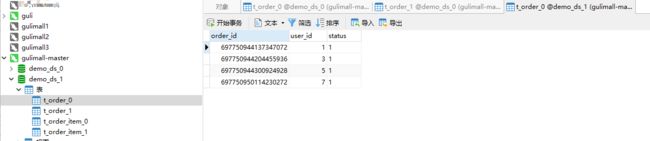
查询主节点,demo_ds_1分库的t_order_1分表
无数据

4. Redis集群
4.1 redis集群形式
4.1.1 数据分区方案

优点:
不使用 第三方中间件, 分区逻辑 可控, 配置 简单, 节点之间无关联, 容易 线性扩展, 灵活性强。
缺点:
**客户端 无法 动态增删 服务节点, 客户端需要自行维护 分发逻辑, 客户端之间 无连接共享,会造成 连接浪费。 **
4.1.2 代理分区
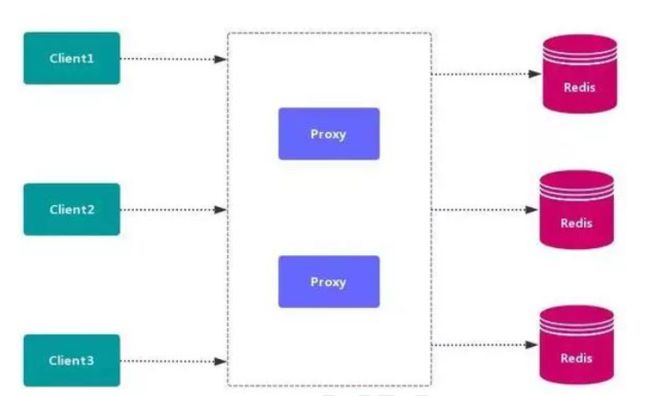
代理分区常用方案有 Twemproxy 和 Codis,类似于mysql的sharding proxy。
4.1.3 redis-cluster

Redis Cluster 是 Redis 原生的数据分片实现,可以自动在多个节点上分布数据,不需要依赖任何外部的工具。
优点:
高性能- Redis Cluster 的性能与单节点部署是同级别的。
高可用- Redis Cluster 支持标准的
master-replica配置来保障高可用和高可靠。 - Redis Cluster 也实现了一个类似 Raft 的共识方式,来保障整个集群的可用性。
- Redis Cluster 支持标准的
易扩展- 向 Redis Cluster 中添加新节点,或者移除节点,都是透明的,不需要停机。水平、垂直方向都非常容易扩展。
原生- 部署 Redis Cluster 不需要其他的代理或者工具,而且 Redis Cluster 和单机 Redis 几乎完全兼容。
缺点(限制):
-
需要客户端支持- 客户端需要修改,以便支持 Redis Cluster。虽然 Redis Cluster 已经发布有几年时间了,但仍然有些客户端是不支持的,所以需要到 Redis 官网去查询一下。
-
只支持一个数据库- 不像单机Redis,Redis Cluster 只支持一个数据库(database 0),
select命令就不能用了,但实际也很少有人使用多数据库,所以这个限制并没什么影响。
- 不像单机Redis,Redis Cluster 只支持一个数据库(database 0),
-
Multi-Key 操作受限
-
Redis Cluster 要求,只有这些 key 都在同一个 slot 时才能执行。
-
例如,有2个key,key1 和 key2。
key1 是映射到 5500 这个 slot 上,存储在 Node A。
key2 是映射到 5501 这个 slot 上,存储在 Node B。
那么就不能对 key1 和 key2 做事务操作。
-
-
4.1.3.1 Multi-Key 限制的处理
对于多key场景,需要做好数据空间的设计,Redis Cluster 提供了一个 hash tag 的机制,可以让我们把一组key 映射到同一个 slot。
例如:user1000.following 这个 key 保存用户 user1000 关注的用户;user1000.followers 保存用户 user1000 的粉丝。
这两个 key 有一个共同的部分 user1000,可以指定对这个共同的部分做 slot 映射计算,这样他们就可以在同一个槽中了。
使用方式:
{user1000}.following 和 {user1000}.followers
就是把共同的部分使用 { } 包起来,计算 slot 值时,如果发现了花括号,就会只对其中的部分进行计算。
Multi-Key 这一点是 Redis Cluster 对于我们日常使用中最大的限制,一定要注意,如果多key不在同一个 slot 中就会报错,例如:
(error) CROSSSLOT Keys in request don't hash to the same slot
需要使用 hash tag 设计好 key 的空间。
4.2 高可用方式
4.2.1 Sentinel( 哨兵机制) 支持高可用
前面介绍了主从机制, 但是从运维角度来看, 主节点出现了问题我们还需要通过人工干预的方式把从节点设为主节点, 还要通知应用程序更新主节点地址, 这种方式非常繁琐笨重, 而且主节点的读写能力都十分有限, 有没有较好的办法解决这两个问题, 哨兵机制就是针对第一个问题的有效解决方案, 第二个问题则有赖于集群! 哨兵的作用就是监控 Redis 系统的运行状况, 其功能主要是包括以下三个:
监控(Monitoring): 哨兵(sentinel) 会不断地检查你的 Master 和 Slave 是否运作正常。提醒(Notification): 当被监控的某个 Redis 出现问题时, 哨兵(sentinel) 可以通过 API向管理员或者其他应用程序发送通知。自动故障迁移(Automatic failover): 当主数据库出现故障时自动将从数据库转换为主数据库。
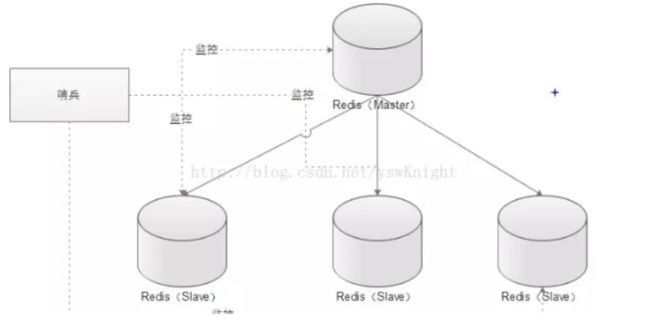
4.2.1.1 哨兵原理
Redis 哨兵的三个定时任务, Redis 哨兵判定一个 Redis 节点故障不可达主要就是通过三个定时监控任务来完成的:
-
每隔 10 秒每个哨兵节点会向主节点和从节点发送"info replication" 命令来获取最新的拓扑结构
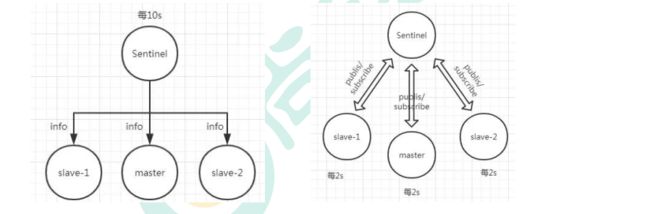
-
每隔 2 秒每个哨兵节点会向 Redis 节点的_sentinel_:hello 频道发送自己对主节点是否故障的判断以及自身的节点信息, 并且其他的哨兵节点也会订阅这个频道来了解其他哨兵节点的信息以及对主节点的判断
-
每隔 1 秒每个哨兵会向主节点、 从节点、 其他的哨兵节点发送一个 “ping” 命令来做心跳检测
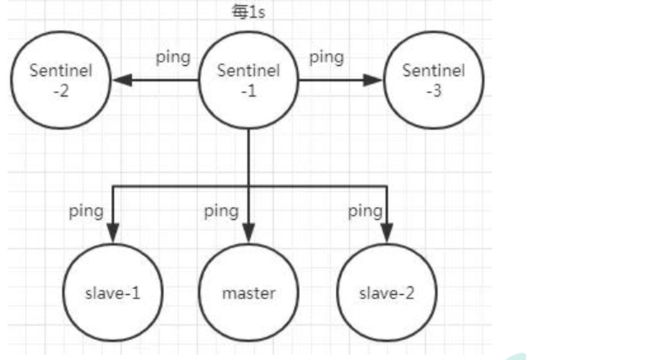
如果在定时 Job3 检测不到节点的心跳, 会判断为**“主观下线”。 如果该节点还是主节点那么还会通知到其他的哨兵对该主节点进行心跳检测, 这时主观下线的票数超过了数时, 那么这个主节点确实就可能是故障不可达了, 这时就由原来的主观下线变为了“客观下线”**。
故障转移和 Leader 选举
如果主节点被判定为客观下线之后, 就要选取一个哨兵节点来完成后面的故障转移工作, 选举出一个 leader, 这里面采用的选举算法为 Raft。 选举出来的哨兵 leader 就要来完成故障转移工作, 也就是在从节点中选出一个节点来当新的主节点, 这部分的具体流程可参考引用
4.2.2 Redis-Cluster
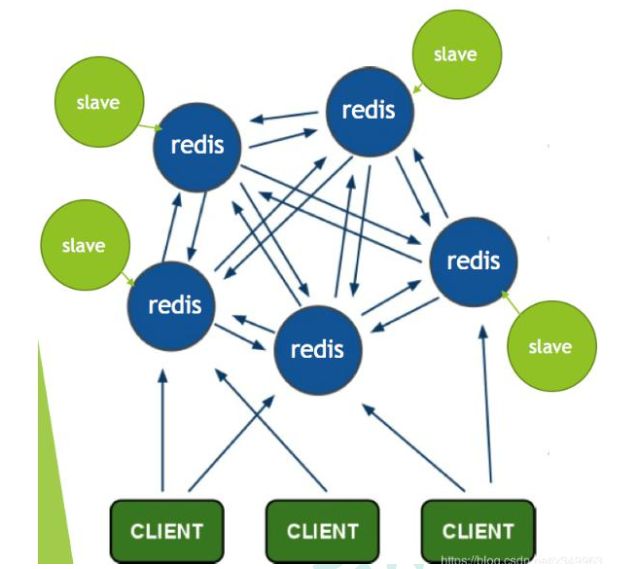
https://redis.io/topics/cluster-tutorial/
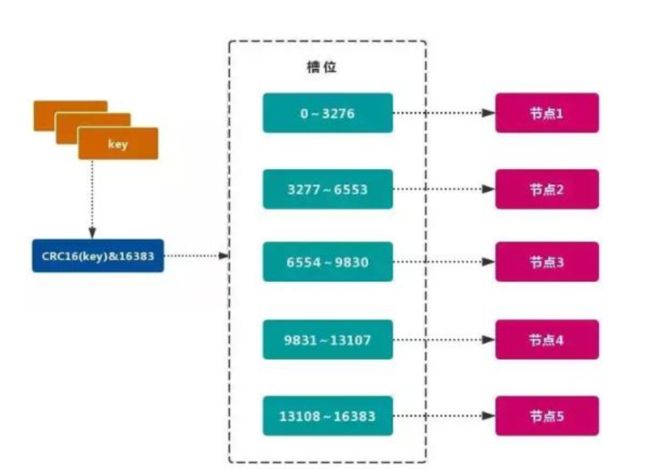
Redis 的官方多机部署方案, Redis Cluster。 一组 Redis Cluster 是由多个 Redis 实例组成, 官方推荐我们使用 6 实例, 其中 3 个为主节点, 3 个为从结点。 一旦有主节点发生故障的时候,Redis Cluster 可以选举出对应的从结点成为新的主节点, 继续对外服务, 从而保证服务的高可用性。那么对于客户端来说, 知道知道对应的 key 是要路由到哪一个节点呢? Redis Cluster把所有的数据划分为 16384 个不同的槽位, 可以根据机器的性能把不同的槽位分配给不同的 Redis 实例, 对于 Redis 实例来说, 他们只会存储部分的 Redis 数据, 当然, 槽的数据是可以迁移的, 不同的实例之间, 可以通过一定的协议, 进行数据迁移。
4.2.2.1 槽
Redis 集群的功能限制; Redis 集群相对 单机 在功能上存在一些限制, 需要 开发人员 提前了解, 在使用时做好规避。 [JAVA CRC16 校验算法](JAVA CRC16校验算法_Levent的博客-CSDN博客_javacrc16校验)
-
key 批量操作 支持有限。
- 类似 mset、 mget 操作, 目前只支持对具有相同 slot 值的 key 执行 批量操作。对于 映射为不同 slot 值的 key 由于执行 mget、 mget 等操作可能存在于多个节点上, 因此不被支持。
-
key 事务操作 支持有限。
- 只支持 多 key 在 同一 节点上 的 事务操作, 当多个 key 分布在 不同 的节点上时 无法 使用事务功能。
-
key 作为 数据分区 的最小粒度
-
不能将一个 大的键值 对象如 hash、 list 等映射到 不同的节点。
-
不支持 多数据库空间
- 单机 下的 Redis 可以支持 16 个数据库(db0 ~ db15) , 集群模式 下只能使用 一个 数据库空间, 即 db0。
-
复制结构 只支持一层
- 从节点 只能复制 主节点, 不支持 嵌套树状复制 结构。
-
命令大多会重定向, 耗时多
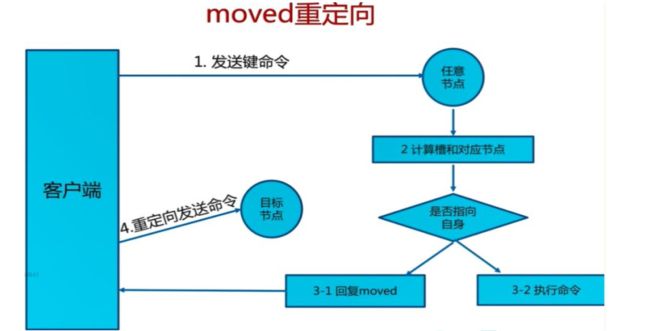
4.2.2.2 一致性 hash
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n 个关键字重新映射,其中K是关键字的数量, n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。

对一致性哈希的理解
原文链接:https://juejin.cn/post/6844903750860013576
简单的说,一致性哈希是将整个哈希值空间组织成一个虚拟的圆环,如假设哈希函数H的值空间为0-2^32-1(哈希值是32位无符号整形),整个哈希空间环如下:
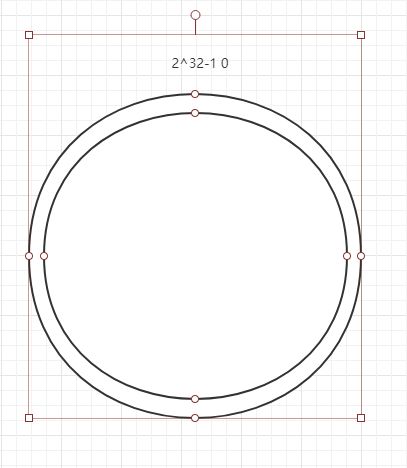
整个空间按顺时针方向组织,0和2^32-1在零点中方向重合。
接下来,把服务器按照IP或主机名作为关键字进行哈希,这样就能确定其在哈希环的位置。

然后,我们就可以使用哈希函数H计算值为key的数据在哈希环的具体位置h,根据h确定在环中的具体位置,从此位置沿顺时针滚动,遇到的第一台服务器就是其应该定位到的服务器。
例如我们有A、B、C、D四个数据对象,经过哈希计算后,在环空间上的位置如下:
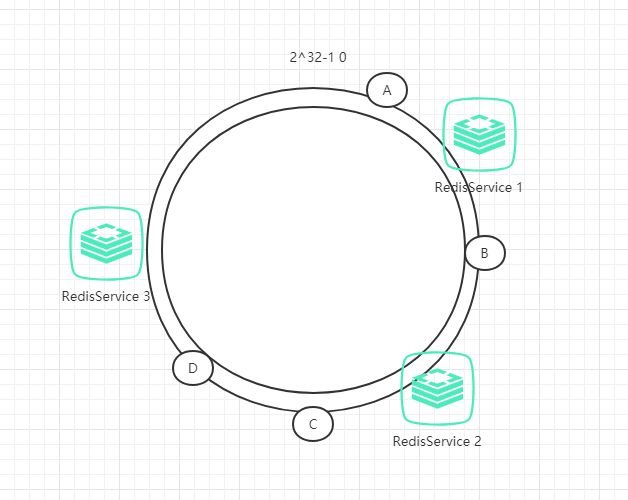
根据一致性哈希算法,数据A会被定为到Server 1上,数据B被定为到Server 2上,而C、D被定为到Server 3上。
4.2.2.2.1 一致性hash,hash倾斜问题
如果节点很少, 容易出现倾斜, 负载不均衡问题。 一致性哈希算法, 引入了虚拟节点, 在整个环上, 均衡增加若干个节点。 比如 a1, a2, b1, b2, c1, c2, a1 和 a2 都是属于 A 节点的。 解决 hash 倾斜问题
具体做法
具体做法可以在服务器IP或主机名的后面增加编号来实现,例如上面的情况,可以为每个服务节点增加三个虚拟节点,于是可以分为 RedisService1#1、 RedisService1#2、 RedisService1#3、 RedisService2#1、 RedisService2#2、 RedisService2#3,具体位置如下图所示:

对于数据定位的hash算法仍然不变,只是增加了虚拟节点到实际节点的映射。例如,数据C保存到虚拟节点Redis1#2,实际上数据保存到Redis1中。这样,就能解决服务节点少时数据不平均的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
4.2.3 部署Cluster

4.2.3.1 创建6个redis节点(3 主 3 从方式,从为了同步备份,主进行 slot 数据分片 )
for port in $(seq 7001 7006); \
do \
mkdir -p /mydata/redis/node-${port}/conf
touch /mydata/redis/node-${port}/conf/redis.conf
cat << EOF >/mydata/redis/node-${port}/conf/redis.conf
port ${port}
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 192.168.157.128
cluster-announce-port ${port}
cluster-announce-bus-port 1${port}
appendonly yes
EOF
docker run -p ${port}:${port} -p 1${port}:1${port} --name redis-${port} \
-v /mydata/redis/node-${port}/data:/data \
-v /mydata/redis/node-${port}/conf/redis.conf:/etc/redis/redis.conf \
-d redis:5.0.7 redis-server /etc/redis/redis.conf; \
done
port:节点端口;requirepass:添加访问认证;masterauth:如果主节点开启了访问认证,从节点访问主节点需要认证;protected-mode:保护模式,默认值 yes,即开启。开启保护模式以后,需配置bind ip或者设置访问密码;关闭保护模式,外部网络可以直接访问;daemonize:是否以守护线程的方式启动(后台启动),默认 no;appendonly:是否开启 AOF 持久化模式,默认 no;cluster-enabled:是否开启集群模式,默认 no;cluster-config-file:集群节点信息文件;cluster-node-timeout:集群节点连接超时时间;cluster-announce-ip:集群节点 IP,填写宿主机的 IP;cluster-announce-port:集群节点映射端口;cluster-announce-bus-port:集群节点总线端口。


如想停用或删除所有节点
#停用所有节点
docker stop $(docker ps -a |grep redis-700 | awk '{ print $1}')
#删除所有容器
docker rm $(docker ps -a |grep redis-700 | awk '{ print $1}')
4.2.3.2 使用redis建立集群
这里我们将redis-7001作为主节点
#进入redis-7001容器
docker exec -it redis-7001 bash
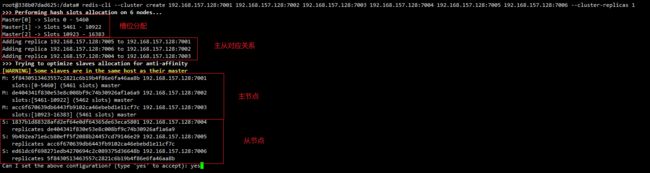
#创建一个集群,拉入集群成员
redis-cli --cluster create 192.168.157.128:7001 192.168.157.128:7002 192.168.157.128:7003 192.168.157.128:7004 192.168.157.128:7005 192.168.157.128:7006 --cluster-replicas 1
redis-cluster会为我们自动分配节点
4.2.3.3 测试集群效果
#随便进入一个redis容器
docker exec -it redis-7002 /bin/bash
#使用 redis-cli 的 cluster 方式进行连接(get/set命令可以对其他节点进行操作)
redis-cli -c -h 192.168.157.128 -p 7006
#获取节点信息
cluster info
#获取集群节点
cluster nodes
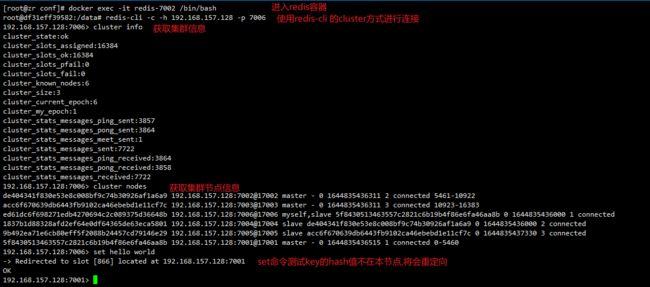
之前set了一个key为hello的数据,被重定向到7001,使用redis-manager连上7001及7001的从机7006看看



4.2.3.3.1 模拟主节点宕机
关闭主节点7001
docker stop redis-7001
查看节点信息
7001节点失去连接,其从节点7006变为主节点

重启7001,查看节点信息
7001变为7006的从节点

5. ElasticSearch集群
5.1 ElasticSearch集群原理
集群内的原理 | Elasticsearch: 权威指南 | Elastic
elasticsearch 是天生支持集群的, 他不需要依赖其他的服务发现和注册的组件, 如 zookeeper这些, 因为他内置了一个名字叫 ZenDiscovery 的模块, 是 elasticsearch 自己实现的一套用于节点发现和选主等功能的组件, 所以 elasticsearch 做起集群来非常简单, 不需要太多额外的配置和安装额外的第三方组件。
5.1.1 单节点
- 一个运行中的 Elasticsearch 实例称为一个节点, 而集群是由一个或者多个拥有相同cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。 当有节点加入集群中或者从集群中移除节点时, 集群将会重新平均分布所有的数据。
- 当一个节点被选举成为 主节点时, 它将负责管理集群范围内的所有变更, 例如增加、删除索引, 或者增加、 删除节点等。 **而主节点并不需要涉及到文档级别的变更和搜索等操作, 所以当集群只拥有一个主节点的情况下, 即使流量的增加它也不会成为瓶颈。**任何节点都可以成为主节点。 我们的示例集群就只有一个节点, 所以它同时也成为了主节点。
- 作为用户, 我们可以将请求发送到 集群中的任何节点 , 包括主节点。 **每个节点都知道任意文档所处的位置, 并且能够将我们的请求直接转发到存储我们所需文档的节点。**无论我们将请求发送到哪个节点, 它都能负责从各个包含我们所需文档的节点收集回数据, 并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。
5.1.2 集群健康
Elasticsearch 的集群监控信息中包含了许多的统计数据, 其中最为重要的一项就是 集群健康 , 它在 status 字段中展示为 green 、 yellow 或者 red 。
GET /_cluster/health
status 字段指示着当前集群在总体上是否工作正常。 它的三种颜色含义如下:
green: 所有的主分片和副本分片都正常运行。
yellow: 所有的主分片都正常运行, 但不是所有的副本分片都正常运行。
red: 有主分片没能正常运行。
5.1.3 分片
- 一个 分片 是一个底层的 工作单元 , 它仅保存了全部数据中的一部分。 我们的文档被存储和索引到分片内, 但是应用程序是直接与索引而不是与分片进行交互。 分片就认为是一个数据区
- 一个分片可以是
主分片或者副本分片。 索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量。 - 在索引建立的时候就已经确定了主分片数, 但是副本分片数可以随时修改。
- 让我们在包含一个空节点的集群内创建名为 blogs 的索引。 索引在默认情况下会被分配 5 个主分片, 但是为了演示目的, 我们将分配 3 个主分片和一份副本(每个主分片拥有一个副本分片) :
PUT /blogs{
"settings" : {
"number_of_shards" : 3, #分片数量
"number_of_replicas" : 1 #副本数量
}}

此时集群的健康状况为 yellow 则表示全部 主分片都正常运行(集群可以正常服务所有请求) , 但是 副本 分片没有全部处在正常状态。 实际上, 所有 3 个副本分片都是 unassigned—— 它们都没有被分配到任何节点。 在同一个节点上既保存原始数据又保存副本是没有意义的, 因为一旦失去了那个节点, 我们也将丢失该节点上的所有副本数据。当前我们的集群是正常运行的, 但是在硬件故障时有丢失数据的风险。
5.1.4 新增节点(绿色框代表主分片)
当你在同一台机器上启动了第二个节点时, 只要它和第一个节点有同样的 cluster.name 配置, 它就会自动发现集群并加入到其中。 但是在不同机器上启动节点的时候, 为了加入到同一集群, 你需要配置一个可连接到的单播主机列表。 详细信息请查看最好使用单播代替组播

此时, cluster-health 现在展示的状态为 green , 这表示所有 6 个分片(包括 3 个主分片和3 个副本分片) 都在正常运行。 我们的集群现在不仅仅是正常运行的, 并且还处于 始终可用 的状态。
5.1.5 水平扩容-启动第三个节点 (绿色框代表主分片)

Node 1 和 Node 2 上各有一个分片被迁移到了新的 Node 3 节点, 现在每个节点上都拥有 2 个分片, 而不是之前的 3 个。 这表示每个节点的硬件资源(CPU, RAM, I/O) 将被更少的分片所共享, 每个分片的性能将会得到提升。
在运行中的集群上是可以动态调整副本分片数目的, 我们可以按需伸缩集群。 让我们把副本数从默认的 1 增加到 2
PUT /blogs/_settings
{
"number_of_replicas" : 2
}
blogs 索引现在拥有 9 个分片: 3 个主分片和 6 个副本分片。 这意味着我们可以将集群扩容到 9 个节点, 每个节点上一个分片。 相比原来 3 个节点时, 集群搜索性能可以提升 3 倍。

5.1.6 应对故障

- 我们关闭的节点是一个主节点。 而集群必须拥有一个主节点来保证正常工作, 所以发生的第一件事情就是选举一个新的主节点: Node 2 。
- 在我们关闭 Node 1 的同时也失去了主分片 1 和 2 , 并且在缺失主分片的时候索引也不能正常工作。 如果此时来检查集群的状况, 我们看到的状态将会为 red : 不是所有主分片都在正常工作。
- 幸运的是, 在其它节点上存在着这两个主分片的完整副本, 所以新的主节点立即将这些分片在 Node 2 和 Node 3 上对应的副本分片提升为主分片, 此时集群的状态将会为 yellow 。 这个提升主分片的过程是瞬间发生的, 如同按下一个开关一般。
- 为什么我们集群状态是 yellow 而不是 green 呢? 虽然我们拥有所有的三个主分片,但是同时设置了每个主分片需要对应 2 份副本分片, 而此时只存在一份副本分片。 所以集群不能为 green 的状态, 不过我们不必过于担心: 如果我们同样关闭了 Node 2 ,我们的程序 依然 可以保持在不丢任何数据的情况下运行, 因为 Node 3 为每一个分片都保留着一份副本。
- 如果我们重新启动 Node 1 , 集群可以将缺失的副本分片再次进行分配。 如果 Node 1依然拥有着之前的分片, 它将尝试去重用它们, 同时仅从主分片复制发生了修改的数据文件。
5.1.7 问题与解决
5.1.7.1 主节点
主节点负责创建索引、 删除索引、 分配分片、 追踪集群中的节点状态等工作。 Elasticsearch中的主节点的工作量相对较轻, 用户的请求可以发往集群中任何一个节点, 由该节点负责分发和返回结果, 而不需要经过主节点转发。 而主节点是由候选主节点通过 ZenDiscovery 机制选举出来的, 所以要想成为主节点, 首先要先成为候选主节点。
5.1.7.2 候选主节点
在 elasticsearch 集群初始化或者主节点宕机的情况下, 由候选主节点中选举其中一个作为主节点。 指定候选主节点的配置为: node.master: true。
当主节点负载压力过大, 或者集中环境中的网络问题, 导致其他节点与主节点通讯的时候,主节点没来的及响应, 这样的话, 某些节点就认为主节点宕机, 重新选择新的主节点, 这样的话整个集群的工作就有问题了, 比如我们集群中有 10 个节点, 其中 7 个候选主节点, 1个候选主节点成为了主节点, 这种情况是正常的情况。 但是如果现在出现了我们上面所说的主节点响应不及时, 导致其他某些节点认为主节点宕机而重选主节点, 那就有问题了, 这剩下的 6 个候选主节点可能有 3 个候选主节点去重选主节点, 最后集群中就出现了两个主节点
的情况, 这种情况官方成为**“脑裂现象”**;
脑裂现象导致的问题
集群中不同的节点对于 master 的选择出现了分歧, 出现了多个 master 竞争, 导致主分片和副本的识别也发生了分歧, 对一些分歧中的分片标识为了坏片。
5.1.7.3 数据节点
数据节点负责数据的存储和相关具体操作, 比如 CRUD、 搜索、 聚合。 所以, 数据节点对机器配置要求比较高, 首先需要有足够的磁盘空间来存储数据, 其次数据操作对系统 CPU、Memory 和 IO 的性能消耗都很大。 通常随着集群的扩大, 需要增加更多的数据节点来提高可用性。 指定数据节点的配置: node.data: true。
elasticsearch 是允许一个节点既做候选主节点也做数据节点的, 但是数据节点的负载较重,所以需要考虑将二者分离开, 设置专用的候选主节点和数据节点, 避免因数据节点负载重导致主节点不响应。
5.1.7.4 客户端节点
客户端节点就是既不做候选主节点也不做数据节点的节点, 只负责请求的分发、 汇总等等,但是这样的工作, 其实任何一个节点都可以完成, 因为在 elasticsearch 中一个集群内的节点都可以执行任何请求, 其会负责将请求转发给对应的节点进行处理。 所以单独增加这样的节点更多是为了负载均衡。 指定该节点的配置为:
node.master: false
node.data: false
5.1.7.5 脑裂问题可能的原因
网络问题: 集群间的网络延迟导致一些节点访问不到 master, 认为 master 挂掉了从而选举出新的 master, 并对 master 上的分片和副本标红, 分配新的主分片节点负载: 主节点的角色既为 master 又为 data, 访问量较大时可能会导致 ES 停止响应造成大面积延迟, 此时其他节点得不到主节点的响应认为主节点挂掉了, 会重新选取主节点。内存回收: data 节点上的 ES 进程占用的内存较大, 引发 JVM 的大规模内存回收, 造成 ES进程失去响应。
5.1.7.5.1 脑裂问题的解决方案
-
角色分离: 即 master 节点与 data 节点分离, 限制角色; 数据节点是需要承担存储和搜索的工作的, 压力会很大。 所以如果该节点同时作为候选主节点和数据节点,那么一旦选上它作为主节点了, 这时主节点的工作压力将会非常大, 出现脑裂现象的概率就增加了。 -
减少误判: 配置主节点的响应时间, 在默认情况下, 主节点 3 秒没有响应, 其他节点就认为主节点宕机了, 那我们可以把该时间设置的长一点, 该配置是:discovery.zen.ping_timeout: 5 -
选举触发: discovery.zen.minimum_master_nodes:1(默认是 1) , 该属性定义的是为了形成一个集群, 有主节点资格并互相连接的节点的最小数目。-
一 个 有 10 节 点 的 集 群 , 且 每 个 节 点 都 有 成 为 主 节 点 的 资 格 ,
discovery.zen.minimum_master_nodes 参数设置为 6。 -
正常情况下, 10 个节点, 互相连接, 大于 6, 就可以形成一个集群。
-
若某个时刻, 其中有 3 个节点断开连接。 剩下 7 个节点, 大于 6, 继续运行之
前的集群。 而断开的 3 个节点, 小于 6, 不能形成一个集群。 -
该参数就是为了防止”脑裂”的产生。
-
建议设置为(候选主节点数 / 2) + 1,
-
5.2 ElasticSearch集群搭建

注意:需要将虚拟机的内存和核心数调大一点不然elasticsearch集群启动后有些节点会自动退出,我使用的4核8g内存
5.2.1 修改最大map数(准备工作)
防止 JVM 报错,设置最大map数,该参数确保内核允许创建至少
262144个内存映射区
所有之前先运行:
![]()
sysctl -w vm.max_map_count=262144
我们只是测试, 所以临时修改。 永久修改使用下面
echo vm.max_map_count=262144 >> /etc/sysctl.conf
sysctl -p
5.2.2 准备docker网络(准备工作)
Docker 创建容器时默认采用 bridge 网络, 自行分配 ip, 不允许自己指定。
在实际部署中, 我们需要指定容器 ip, 不允许其自行分配 ip, 尤其是搭建集群时, 固定 ip是必须的。
我们可以创建自己的 bridge 网络 : mynet, 创建容器的时候指定网络为 mynet 并指定 ip即可。
查看网络模式
docker network ls
创建一个新的 bridge 网络
docker network create --driver bridge --subnet=172.18.12.0/16 --gateway=172.18.1.1 mynet

#再次查看网络模式
docker network ls

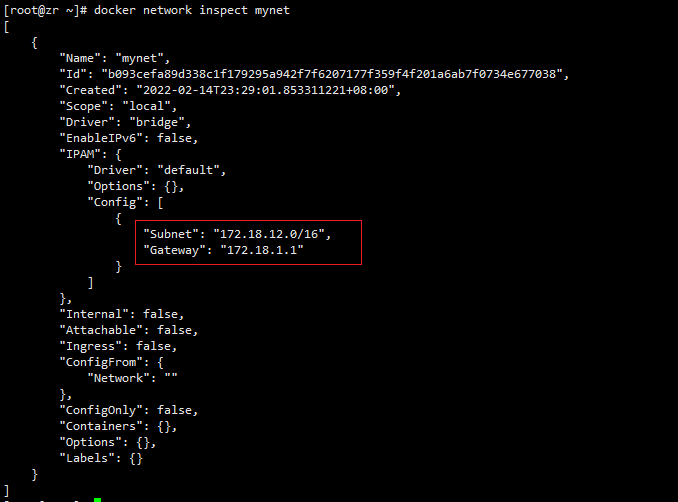
查看网络信息
docker network inspect mynet
以后使用–network=mynet --ip 172.18.12.x 指定 ip (就可以在docker中使用这个网段的ip了)
5.2.3 Master节点创建
for port in $(seq 1 3); \
do \
mkdir -p /mydata/elasticsearch/master-${port}/config
mkdir -p /mydata/elasticsearch/master-${port}/data
chmod -R 777 /mydata/elasticsearch/master-${port}
cat << EOF >/mydata/elasticsearch/master-${port}/config/elasticsearch.yml
cluster.name: my-es #集群的名称, 同一个集群该值必须设置成相同的
node.name: es-master-${port} #该节点的名字
node.master: true #该节点有机会成为 master 节点
node.data: false #该节点可以存储数据
network.host: 0.0.0.0
http.host: 0.0.0.0 #所有 http 均可访问
http.port: 920${port}
transport.tcp.port: 930${port}
discovery.zen.minimum_master_nodes: 2 #设置这个参数来保证集群中的节点可以知道其它 N 个有 master 资格的节点。
#官方推荐(N/2) +1
discovery.zen.ping_timeout: 10s #设置集群中自动发现其他节点时 ping 连接的超时时间
discovery.seed_hosts: ["172.18.12.21:9301", "172.18.12.22:9302", "172.18.12.23:9303"] #设置集群中的 Master 节点#的初始列表, 可以通过这些节点来自动发现其他新加入集群的节点, es7的新增配置
cluster.initial_master_nodes: ["172.18.12.21"] #新集群初始时的候选主节点, es7 的新增配置
EOF
docker run --name elasticsearch-node-${port} \
-p 920${port}:920${port} -p 930${port}:930${port} \
--network=mynet --ip 172.18.12.2${port} \-e ES_JAVA_OPTS="-Xms300m -Xmx300m" \
-v /mydata/elasticsearch/master-${port}/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/master-${port}/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/master-${port}/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
done
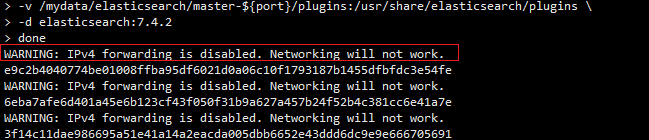
5.2.3.1 WARNING: IPv4 forwarding is disabled. Networking will not work.问题
在启动elasticsearch集群容器时出现IPv4 forwarding is disabled. Networking will not work.问题
解决方案
#修改配置文件
vim /usr/lib/sysctl.d/00-system.conf
#追加
net.ipv4.ip_forward=1
#重启网络
systemctl restart network
5.2.3.2 再次启动elasticsearch集群
清除之前操作遗留
#删除之前创建的文件夹
rm -rf /mydata/elasticsearch master-1 master-2 master-3
#停止elasticsearch集群容器
docker stop $(docker ps -a |grep elasticsearch-node-* | awk '{ print $1}')
#删除elasticsearch集群容器
docker rm $(docker ps -a |grep elasticsearch-node-* | awk '{ print $1}')
#再次使用5.2.3章节shell
5.2.4 Data-Node 创建
for port in $(seq 4 6); \
do \
mkdir -p /mydata/elasticsearch/node-${port}/config
mkdir -p /mydata/elasticsearch/node-${port}/data
chmod -R 777 /mydata/elasticsearch/node-${port}
cat << EOF >/mydata/elasticsearch/node-${port}/config/elasticsearch.yml
cluster.name: my-es #集群的名称, 同一个集群该值必须设置成相同的
node.name: es-node-${port} #该节点的名字
node.master: false #该节点有机会成为 master 节点
node.data: true #该节点可以存储数据
network.host: 0.0.0.0
#network.publish_host: 192.168.157.128 #互相通信 ip, 要设置为本机可被外界访问的 ip, 否则无法通信
http.host: 0.0.0.0 #所有 http 均可访问
http.port: 920${port}
transport.tcp.port: 930${port}
#discovery.zen.minimum_master_nodes: 2 #设置这个参数来保证集群中的节点可以知道其它 N 个有 master 资格的节点。
#官方推荐(N/2) +1
discovery.zen.ping_timeout: 10s #设置集群中自动发现其他节点时 ping 连接的超时时间
discovery.seed_hosts: ["172.18.12.21:9301", "172.18.12.22:9302", "172.18.12.23:9303"] #设置集群中的 Master 节点#的初始列表, 可以通过这些节点来自动发现其他新加入集群的节点, es7的新增配置
cluster.initial_master_nodes: ["172.18.12.21"] #新集群初始时的候选主节点, es7 的新增配置
EOF
docker run --name elasticsearch-node-${port} \
-p 920${port}:920${port} -p 930${port}:930${port} \
--network=mynet --ip 172.18.12.2${port} \
-e ES_JAVA_OPTS="-Xms300m -Xmx300m" \
-v /mydata/elasticsearch/node-${port}/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/node-${port}/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/node-${port}/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
done
5.2.5 测试集群
$ curl localhost:9200/_cat
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
分别查看http://192.168.157.128:920(1-6)/,所有节点都如下图就代表成功了
http://192.168.157.128:9201/_nodes/process?pretty 查看节点状况
http://192.168.157.128:9201/_cluster/stats?pretty 查看集群状态
http://192.168.157.128:9201/_cluster/health?pretty 查看集群健康状况

http://192.168.157.128:9202/_cat/nodes 查看各个节点信息

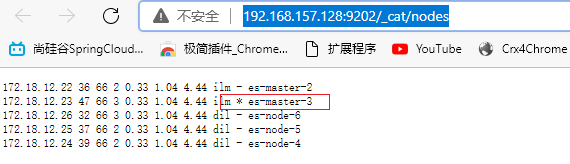
5.2.5.1 关闭主节点测试
#关闭主节点
docker stop elasticsearch-node-1
192.168.157.128:9202/_cat/nodes查看各个节点健康状况
主节点切换到之前的备选主节点es-master-3
#启动主节点
docker start elasticsearch-node-1
192.168.157.128:9202/_cat/nodes查看各个节点健康状况
es-node-1变为备选主节点,es-node-3变为主节点

6. RabbitMQ集群
6.1 集群形式
RabbiMQ 是用 Erlang 开发的, 集群非常方便, 因为 Erlang 天生就是一门分布式语言, 但其本身并不支持负载均衡。
RabbitMQ 集群中节点包括内存节点(RAM)、 磁盘节点(Disk, 消息持久化), 集群中至少有一个 Disk 节点。
6.1.1 普通模式(默认)
对于普通模式, 集群中各节点有相同的队列结构, 但消息只会存在于集群中的一个节点。 对于消费者来说, 若消息进入 A 节点的 Queue 中, 当从 B 节点拉取时, RabbitMQ 会将消息从 A 中取出, 并经过 B 发送给消费者。
应用场景: 该模式各适合于消息无需持久化的场合, 如日志队列。 当队列非持久化, 且创建该队列的节点宕机, 客户端才可以重连集群其他节点, 并重新创建队列。 若为持久化,只能等故障节点恢复。
6.1.2 镜像模式
与普通模式不同之处是消息实体会主动在镜像节点间同步, 而不是在取数据时临时拉取, 高可用; 该模式下, mirror queue 有一套选举算法, 即 1 个 master、 n 个 slaver, 生产者、 消费者的请求都会转至 master。
应用场景: 可靠性要求较高场合, 如下单、 库存队列。
缺点: 若镜像队列过多, 且消息体量大, 集群内部网络带宽将会被此种同步通讯所消耗。
(1) 镜像集群也是基于普通集群, 即只有先搭建普通集群, 然后才能设置镜像队列。
(2) 若消费过程中, master 挂掉, 则选举新 master, 若未来得及确认, 则可能会重复消费。
6.2 搭建集群(普通模式)
6.2.1 首先创建容器映射目录
#创建rabbitmq用于存放rabbitmq集群映射信息
mkdir /mydata/rabbitmq
#分别创建各集群映射目录
cd rabbitmq/
mkdir rabbitmq01 rabbitmq02 rabbitmq03
6.2.2 启动集群镜像容器
rabbitmq01
docker run -d --hostname rabbitmq01 --name rabbitmq01 -v /mydata/rabbitmq/rabbitmq01:/var/lib/rabbitmq -p 15673:15672 -p 5673:5672 -e RABBITMQ_ERLANG_COOKIE='zr' rabbitmq:3.8.2-management
rabbitmq02
docker run -d --hostname rabbitmq02 --name rabbitmq02 -v/mydata/rabbitmq/rabbitmq02:/var/lib/rabbitmq -p 15674:15672 -p 5674:5672 -e RABBITMQ_ERLANG_COOKIE='zr' --link rabbitmq01:rabbitmq01 rabbitmq:3.8.2-management
rabbitmq03
docker run -d --hostname rabbitmq03 --name rabbitmq03 -v /mydata/rabbitmq/rabbitmq03:/var/lib/rabbitmq -p 15675:15672 -p 5675:5672 -e RABBITMQ_ERLANG_COOKIE='zr' --link rabbitmq01:rabbitmq01 --link rabbitmq02:rabbitmq02 rabbitmq:3.8.2-management
注意事项:
–hostname 设置容器的主机名
RABBITMQ_ERLANG_COOKIE节点认证作用, 部署集成时 需要同步该值RABBITMQ_ERLANG_COOKIE 为rabbitmq多节点之间通信所用到的cookie,rabbitmq集群就是利用这一特性实现的
启动成功后
http://192.168.157.128:15673/#/
http://192.168.157.128:15674/#/
http://192.168.157.128:15675/#/
账号:guest
密码:guest
登录查看一下,目前都是单节点
6.2.3 节点加入集群
设置rabbitmq01为主节点
docker exec -it rabbitmq01 /bin/bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
Exit

如果出现以下情况说明rabbitmq版本太高了,新拉一个镜像3.8.2(老师对应的),当然也可以按照高版本的配置
docker pull rabbitmq:3.8.2

将rabbitmq02加入rabbitmq01
docker exec -it rabbitmq02 /bin/bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbitmq01
rabbitmqctl start_app
exit

将rabbitmq02加入rabbitmq01
docker exec -it rabbitmq03 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbitmq01
rabbitmqctl start_app
exit
最后能看到其他节点信息也就成功了(普通模式)

6.2.4 普通模式集群测试
说明一下端口15673为rabbitmq01 ,15674为rabbitmq02,15675为rabbitmq03
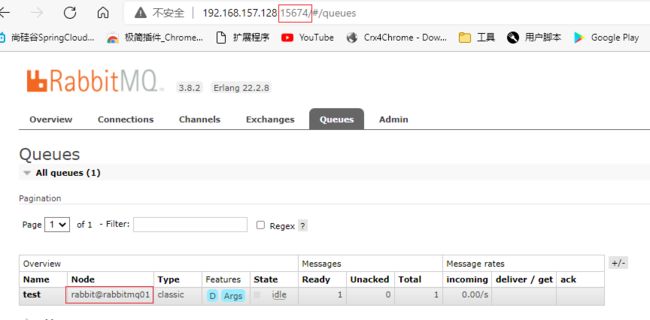
在rabbitmq01新建test队列

在rabbitmq01新建test交换机,并绑定关系


同时发现rabbitmq02,rabbitmq03中也创建了相同的交换机,队列,绑定关系

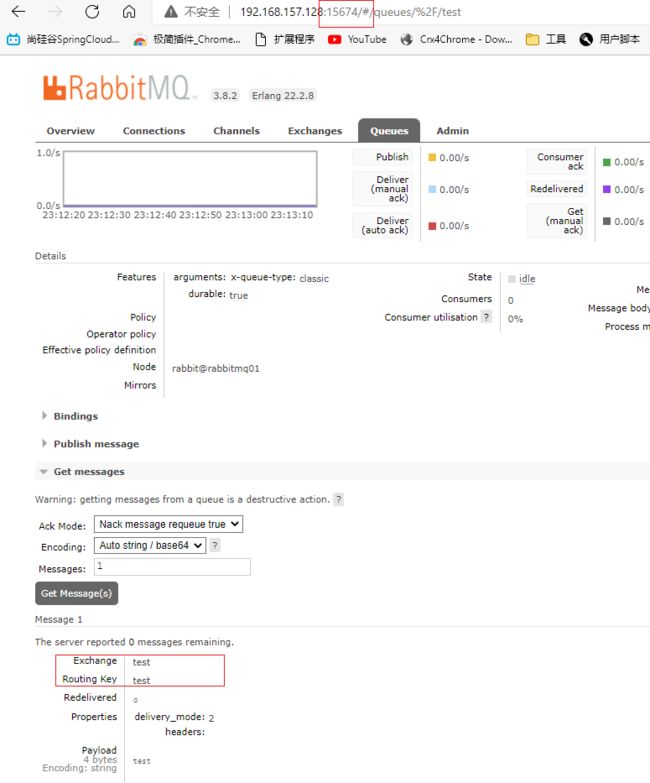
向rabbitmq01的交换机发送消息

在rabbitmq02 rabbitmq03中也能拿到消息

在一个节点中消费了该消息,其他节点中将不会存在该消息
6.3 实现镜像集群
在普通模式集群的条件下才能搭建镜像集群,并且需要选择一个主节点,此处我们选择rabbitmq01为主节点
#进入rabbitmq01容器
docker exec -it rabbitmq01 bash
首先查看此时的策略什么,发现为空,默认普通模式
rabbitmqctl list_policies -p /

增加镜像模式策略
策略模式 all 即复制到所有节点, 包含新增节点,
策略正则表达式为 “^” 表示所有匹配所有队列名称。
“^hello”表示只匹配名为 hello 开始的队列
rabbitmqctl set_policy -p / ha "^" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
查看此时的策略

管理页面查看
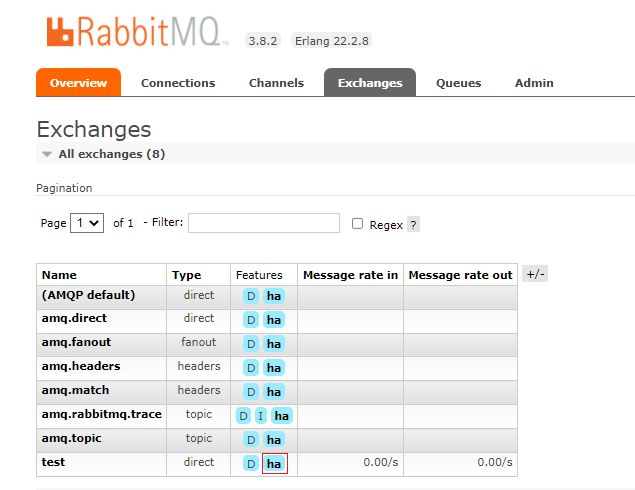

再次向rabbitma01的test交换机发送信息,正常情况与普通模式一致
当我向rabbitma01发送消息后,宕机了,普通模式由于本质是其他节点比如rabbitma02去拿rabbitma01的消息再转交给我,所以当rabbitma01宕机后就拿不到消息了.
镜像模式由于是同步的,当rabbitma01宕机后客户端是直接可以向其他节点拿到消息的
(个人理解普通模式就是代理,源头断了也就什么都没有了;镜像模式就是复制cv,一个地方断掉了,但是还可以从其他地方还能拿到)