操作系统 MIT 6.S081
MIT 6.S081 课程和实验
- 0 准备
-
- 实验环境搭建
- git使用
- 1 lab1
- 2 Lab2 system calls
-
- 2.1 System call tracing(moderate)
-
- 2.1.1 实验要求
- 2.1.2 实验解决代码
- 2.2 Sysinfo(moderate)
-
- 2.2.1 实验要求
- 2.2.2 实验解决代码
- 3 Lab3: page tables
-
- 3.1 前置知识:虚拟页表
- 3.2 Print a page table (easy)(编写一个打印页表内容的函数)
-
- 3.2.1 实验要求
- 3.2.2 实验解决代码
- 3.3 A kernel page table per process (hard)
-
- 3.3.1 实验要求
- 3.3.3 实验解决代码
- 3.4 Simplify copyin/copyinstr(hard)
-
- 3.4.1 实验要求
- 3.4.2 实验完成代码
- 4 Lab4: traps
-
- 4.1 前置知识
-
- 4.1.1 trap代码执行流程
- 4.2 RISC-V assembly (easy)
-
- 4.2.1 实验要求
- 4.2.2 实验解答
- 4.3 Backtrace(moderate)
-
- 4.3.1 实验要求
- 4.3.2 实验相关知识
- 4.3.3 实验解答
- 4.4 Alarm(Hard)
-
- 4.4.1 实验要求
- 4.4.2 实验解答
- 5 Lab5: xv6 lazy page allocation
-
- 5.1 前置知识
- 5.2 Eliminate allocation from sbrk() (easy)
-
- 5.2.1 实验要求
- 5.2.2 实验解答
- 5.3 Lazy allocation (moderate)
-
- 5.3.1 实验要求
- 5.3.2 实验解答
- 5.4 Lazytests and Usertests (moderate)
-
- 5.4.1 实验要求
- 5.4.2 实验解答
- 6 Lab6 Copy-on-Write Fork for xv6
-
- 6.1 前置知识
- 6.2 Implement copy-on write (hard)
-
- 6.2.1 实验要求
- 6.2.2 实验解答
- 7 Lab7 : Multithreading
-
- 7.1 前置知识
- 7.2 Uthread: switching between threads (moderate)
-
- 7.2.1 实验要求
- 7.2.2 实验解答
- 7.3 Using threads (moderate)
-
- 7.3.1 实验要求
- 7.3.2 实验解答
- 7.4 Barrier(moderate)
-
- 7.4.1 实验要求
- 7.4.2 实验解答
- 8 Lab8: locks
-
- 8.1 Memory allocator(moderate)
-
- 8.1.1 实验要求
- 8.1.2 实验解答
- 8.2 Buffer cache(hard)
-
- 8.2.1 实验要求
- 8.2.2 实验解答
- 9 Lab9: file system
-
- 9.1 前置知识
-
- 9.1.1 概述
- 9.1.2 **Inode**
- 9.1.3 目录
- 9.1.4 Logging
- 9.2 Large files(moderate)
-
- 9.2.1 实验要求
- 9.2.2 实验解答
- 9.3 Symbolic links(moderate)
-
- 9.3.1 实验要求
- 9.3.2 实验解答
- 10 Lab10: mmap
-
- 10.1 mmap(hard)
-
- 10.1.1 实验要求
- 10.1.2 实验解答
0 准备
实验环境搭建
参考博客 https://blog.csdn.net/LostUnravel/article/details/120397168
git使用
-
首先将mit的实验代码克隆到本地
git clone git://g.csail.mit.edu/xv6-labs-2020 -
在github创建一个新的空仓库
创建完成后会有提示代码,请不要根据提示代码操作,并且记下右图中红色标注的仓库地址
-
添加git仓库地址
查看本地仓库的git配置文件,可以看到origin主机名下已经有了对应的上游仓库地址
cd xv6-labs-2020/ cat .git/config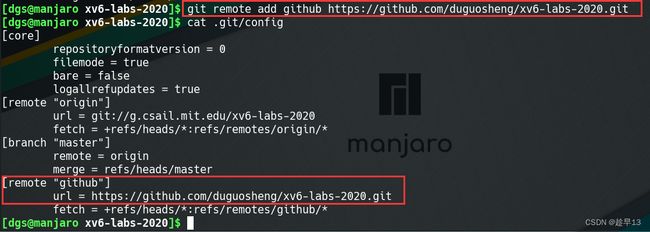
因此我们不要使用origin,可以使用其他主机名对应到github仓库,例如,我使用giteegit remote add github 你的仓库地址 cat .git/config
-
将实验代码推送githee仓库
每次修改完文件后 要将修改文件更新
git add . git commit -m "更新描述"使用push将修改推到远程仓库中的util分支中
git checkout util # 切换到util分支 git push gitee util # 推送到util分支
1 lab1
2 Lab2 system calls
在上一个实验室中,您使用系统调用编写了一些实用程序。在本实验室中,您将向xv6添加一些新的系统调用,这将帮助您了解它们是如何工作的,并使您了解xv6内核的一些内部结构。您将在以后的实验室中添加更多系统调用。
[!WARNING|label:Attention] 在你开始写代码之前,请阅读xv6手册《book-riscv-rev1》
的第2章、第4章的第4.3节和第4.4节以及相关源代码文件:
1、系统调用的用户空间代码在user/user.h和user/usys.pl中。
2、内核空间代码是kernel/syscall.h、kernel/syscall.c。
3、与进程相关的代码是kernel/proc.h和kernel/proc.c。
要开始本章实验,请将代码切换到syscall分支:
$ git fetch
$ git checkout syscall
$ make clean
如果运行make grade,您将看到测试分数的脚本无法执行trace和sysinfotest。您的工作是添加必要的系统调用和存根(stubs)以使它们工作。
2.1 System call tracing(moderate)
2.1.1 实验要求
在本作业中,您将添加一个系统调用跟踪功能,该功能可能会在以后调试实验时对您有所帮助。您将创建一个新的trace系统调用来控制跟踪。它应该有一个参数,这个参数是一个整数“掩码”(mask),它的比特位指定要跟踪的系统调用。例如,要跟踪fork系统调用,程序调用trace(1 << SYS_fork),其中SYS_fork是kernel/syscall.h中的系统调用编号。如果在掩码中设置了系统调用的编号,则必须修改xv6内核,以便在每个系统调用即将返回时打印出一行。该行应该包含进程id、系统调用的名称和返回值;您不需要打印系统调用参数。trace系统调用应启用对调用它的进程及其随后派生的任何子进程的跟踪,但不应影响其他进程。
我们提供了一个用户级程序版本的trace,它运行另一个启用了跟踪的程序(参见user/trace.c)。完成后,您应该看到如下输出:
$ trace 32 grep hello README
3: syscall read -> 1023
3: syscall read -> 966
3: syscall read -> 70
3: syscall read -> 0
$
$ trace 2147483647 grep hello README
4: syscall trace -> 0
4: syscall exec -> 3
4: syscall open -> 3
4: syscall read -> 1023
4: syscall read -> 966
4: syscall read -> 70
4: syscall read -> 0
4: syscall close -> 0
$
$ grep hello README
$
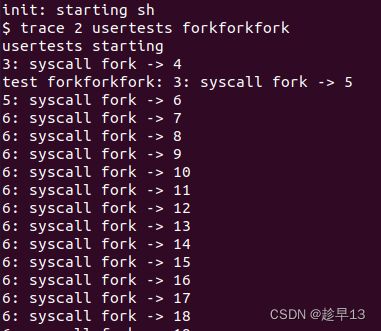
$ trace 2 usertests forkforkfork
usertests starting
test forkforkfork: 407: syscall fork -> 408
408: syscall fork -> 409
409: syscall fork -> 410
410: syscall fork -> 411
409: syscall fork -> 412
410: syscall fork -> 413
409: syscall fork -> 414
411: syscall fork -> 415
...
$
在上面的第一个例子中,trace调用grep,仅跟踪了read系统调用。32是1<
提示:
- 在Makefile的UPROGS中添加**$U/_trace**
- 运行make qemu,您将看到编译器无法编译user/trace.c,因为系统调用的用户空间存根还不存在:将系统调用的原型添加到user/user.h,存根添加到user/usys.pl,以及将系统调用编号添加到kernel/syscall.h,Makefile调用perl脚本user/usys.pl,它生成实际的系统调用存根user/usys.S,这个文件中的汇编代码使用RISC-V的ecall指令转换到内核。一旦修复了编译问题(注:如果编译还未通过,尝试先make clean,再执行make qemu),就运行trace 32 grep hello README;但由于您还没有在内核中实现系统调用,执行将失败。
- 在kernel/sysproc.c中添加一个sys_trace()函数,它通过将参数保存到proc结构体(请参见kernel/proc.h)里的一个新变量中来实现新的系统调用。从用户空间检索系统调用参数的函数在kernel/syscall.c中,您可以在kernel/sysproc.c中看到它们的使用示例。
- 修改fork()(请参阅kernel/proc.c)将跟踪掩码从父进程复制到子进程。
- 修改kernel/syscall.c中的**syscall()**函数以打印跟踪输出。您将需要添加一个系统调用名称数组以建立索引。
2.1.2 实验解决代码
- 在Makefile的UPROGS中添加**$U/_trace**

2.将 trace 加入系统调用中
user/user.h 中添加 int trace(void);(将系统调用的原型添加到user/user.h)
// system calls
......
int sleep(int);
int uptime(void);
int trace(int);
user/usys.pl 中添加 entry(“trace”);(存根添加到user/usys.pl)
......
entry("uptime");
entry("trace");
kernel/syscall.h 中添加 #define SYS_trace 22(将系统调用编号添加到kernel/syscall.h)
#define SYS_link 19
#define SYS_mkdir 20
#define SYS_close 21
#define SYS_trace 22
- 先在kernel/sysproc.c中添加一个**sys_trace()**函数(简单实现,后面会重写)
uint64
sys_trace(void)
{
printf("sysy_trace:Hi!\n");
return 0;
}
在kernel/syscall.c添加一些引用的变量定义
// ...
extern uint64 sys_trace(void);
static uint64 (*syscalls[])(void) = {
// ...
[SYS_trace] sys_trace,
};
static char *syscalls_name[] = {
[SYS_fork] "fork",
[SYS_exit] "exit",
[SYS_wait] "wait",
[SYS_pipe] "pipe",
[SYS_read] "read",
[SYS_kill] "kill",
[SYS_exec] "exec",
[SYS_fstat] "fstat",
[SYS_chdir] "chdir",
[SYS_dup] "dup",
[SYS_getpid] "getpid",
[SYS_sbrk] "sbrk",
[SYS_sleep] "sleep",
[SYS_uptime] "uptime",
[SYS_open] "open",
[SYS_write] "write",
[SYS_mknod] "mknod",
[SYS_unlink] "unlink",
[SYS_link] "link",
[SYS_mkdir] "mkdir",
[SYS_close] "close",
[SYS_trace] "trace",
};
- 在kernel/pro.h中添加掩码mask再proc结构体中添加一个数据字段,用于保存trace的参数。并在sys_trace()中实现参数的保存
// kernel/proc.h
struct proc {
// ...
int trace_mask; // trace系统调用参数
};
// kernel/sysproc.c
uint64
sys_trace(void)
{
int mask;
//mask是将上层用户态传入的参数接收
if(argint(0,&mask)<0) return -1;
struct proc *p = myproc();
p->trace_mask = mask;
return 0;
}
- 重新修改syscall函数,进行打印输出
void
syscall(void)
{
int num;
struct proc *p = myproc();
// 系统调用编号,参见书中4.3节
num = p->trapframe->a7;
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
p->trapframe->a0 = syscalls[num](); // 执行系统调用,然后将返回值存入a0
// 系统调用是否匹配
if ((1 << num) & p->trace_mask)
printf("%d: syscall %s -> %d\n", p->pid, syscalls_name[num], p->trapframe->a0);
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
这时已经初步实现功能了.但是,我们发现第三个命令不调用trace也会打印输出,发现这个输出和上面示例输出一致,意味着在这个命令中,mask值可能是上一次遗留的

原因是,我们需要在kernel/proc.c中的freeproc函数中,添加上p->trace_mask=0;,在每次释放freeproc时候,将mask值清空
//kernel/proc.c
static void
freeproc(struct proc *p)
{
......
p->state = UNUSED;
p->trace_mask = 0;
}
- 修改fork()(请参阅kernel/proc.c)将跟踪掩码从父进程复制到子进程。
//kernel/proc.c
........
// copy trace_mask in the child
np->trace_mask=p->trace_mask;
// increment reference counts on open file descriptors.
for(i = 0; i < NOFILE; i++)
if(p->ofile[i])
np->ofile[i] = filedup(p->ofile[i]);
np->cwd = idup(p->cwd);
2.2 Sysinfo(moderate)
2.2.1 实验要求
在这个作业中,您将添加一个系统调用sysinfo,它收集有关正在运行的系统的信息。系统调用采用一个参数:一个指向struct sysinfo的指针(参见kernel/sysinfo.h)。内核应该填写这个结构的字段:freemem字段应该设置为空闲内存的字节数,nproc字段应该设置为state字段不为UNUSED的进程数。我们提供了一个测试程序sysinfotest;如果输出“sysinfotest: OK”则通过。
提示:
-
在Makefile的UPROGS中添加$U/_sysinfotest
-
当运行make qemu时,user/sysinfotest.c将会编译失败,遵循和上一个作业一样的步骤添加sysinfo系统调用。要在user/user.h中声明sysinfo()的原型,需要预先声明struct sysinfo的存在:
struct sysinfo; int sysinfo(struct sysinfo *); 一旦修复了编译问题,就运行sysinfotest;但由于您还没有在内核中实现系统调用,执行将失败。 -
sysinfo需要将一个struct sysinfo复制回用户空间;请参阅**sys_fstat()(kernel/sysfile.c)和filestat()(kernel/file.c)以获取如何使用copyout()**执行此操作的示例。
-
要获取空闲内存量,请在kernel/kalloc.c中添加一个函数
-
要获取进程数,请在kernel/proc.c中添加一个函数
2.2.2 实验解决代码
- 在Makefile的UPROGS中添加 $U/_sysinfotest
- 将 sysinfo 加入系统调用中
user/user.h 中添加 int sysinfo(struct sysinfo);* 和 struct sysinfo; 声明(将系统调用的原型添加到user/user.h)
//user/user.h
struct stat;
struct rtcdate;
struct sysinfo;
........
int uptime(void);
int trace(int);
int sysinfo(struct sysinfo*);
user/usys.pl 中添加 entry(“sysinfo”);(存根添加到user/usys.pl)
......
entry("uptime");
entry("trace");
entry("sysinfo");
kernel/syscall.h 中添加 #define SYS_sysinfo 23(将系统调用编号添加到kernel/syscall.h)
#define SYS_link 19
#define SYS_mkdir 20
#define SYS_close 21
#define SYS_trace 22
#define SYS_sysinfo 23
- 先在kernel/sysproc.c中添加一个**sys_sysinfo()**函数(简单实现,后面会重写)
uint64
sys_trace(void)
{
printf("sysy_trace:Hi!\n");
return 0;
}
在kernel/syscall.c添加一些引用的变量定义
// kernel/syscall.c
//...
extern uint64 sys_trace(void);
extern uint64 sys_sysinfo(void);
static uint64 (*syscalls[])(void) = {
// ...
[SYS_trace] sys_trace,
[SYS_sysinfo] sys_sysinfo,
};
static char *syscalls_name[] = {
//......
[SYS_trace] "trace",
[SYS_sysinfo] "sys_sysinfo",
};
- 在kernel/kalloc.c中添加一个函数**uint64 acquire_freemem()**用于获取空闲内存量
在kernel/kalloc.c可以看到结构体kmem中freelist存贮空闲内存的链表,
//kernel/kalloc.c
struct run {
struct run *next;
};
struct {
struct spinlock lock;
struct run *freelist;
} kmem;
内存是使用链表进行管理的,因此遍历kmem中的空闲链表就能够获取所有的空闲内存,如下
//kernel/kalloc.c
uint64 acquire_freemem()
{
struct run *r;
uint64 cnt = 0;
//进行自旋锁加锁
acquire(&kmem.lock);
r = kmem.freelist;
//遍历freelist,累计有多少的空闲节点
while(r){
r = r->next;
cnt++;
}
//解锁
release(&kmem.lock);
//PGSIZE为4096
return cnt*PGSIZE;
}
- 在kernel/proc.c中添加一个函数acquire_nproc获取进程数
//kernel/proc.c
uint64 acquire_nproc(){
struct proc *p;
int count = 0;
//遍历p
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
//如果p->state不是UNUSED就计数+1
if(p->state != UNUSED) {
count++;
}
release(&p->lock);
}
return count;
}
- 在kernel/sysproc.c 中重新实现sys_sysinfo,将数据写入结构体并传递到用户空间
//kernel/sysproc.c
#include "sysinfo.h"
//先声明两个函数
uint64 acquire_freemem();
uint64 acquire_nproc();
...................
uint64
sys_sysinfo(void)
{
struct sysinfo info;
uint64 addr;
struct proc *p = myproc();
info.nproc = acquire_nproc();
intfo.freemem = acquire_freemem();
//从内核空间拷贝数据到用户空间 将接收到的第0个参数放到addr中
if(argaddr(0,&addr)<0)
return -1;
//从内核空间拷贝数据到用户空间 把计算过的结果放入info结构体中
if(copyout(p->pagetable,addr,(char *)&info,sizeof(info))<0)
return -1;
printf("sysinfo say Hi\n");
return 0;
}
运行成功!!!

3 Lab3: page tables
在本实验室中,您将探索页表并对其进行修改,以简化将数据从用户空间复制到内核空间的函数。
[!WARNING|label:Attention] 开始编码之前,请阅读xv6手册的第3章和相关文件:
kernel/memlayout.h,它捕获了内存的布局。
kernel/vm.c,其中包含大多数虚拟内存(VM)代码。
kernel/kalloc.c,它包含分配和释放物理内存的代码。
要启动实验,请切换到pgtbl分支:
$ git fetch
$ git checkout pgtbl
$ make clean
3.1 前置知识:虚拟页表
每个进程都有自己的page table!!!
当MMU在做地址翻译的时候,通过读取虚拟内存地址中的index可以知道物理内存中的page号,这个page号对应了物理内存中的4096个字节。之后虚拟内存地址中的offset指向了page中的4096个字节中的某一个,假设offset是12,那么page中的第12个字节被使用了。将offset加上page的起始地址,就可以得到物理内存地址。

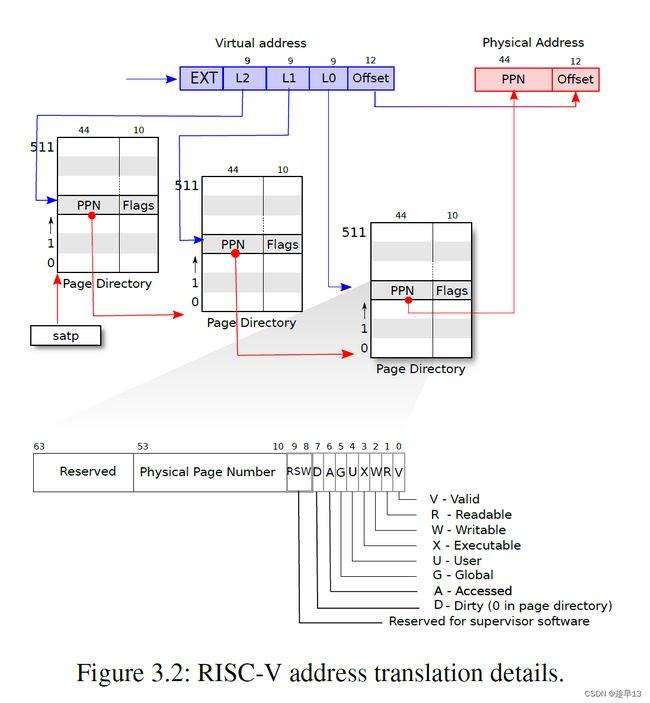
RSIC-V处理器上,虚拟内存地址中并不是所有的64bit都被使用了,也就是说高25bit并没有被使用。这样的结果是限制了虚拟内存地址的数量,虚拟内存地址的数量现在只有2^39个,大概是512GB。当然,如果必要的话,最新的处理器或许可以支持更大的地址空间,只需要将未使用的25bit拿出来做为虚拟内存地址的一部分即可。在剩下的39bit中,有27bit被用来当做index,一个进程的虚拟内存可以有 2 ^27个page对应到页表中就是2 ^27 个page table entry (PTE),12bit被用来当做offset页内偏移。offset必须是12bit,因为对应了一个page的4096(2 ^12)个字节。 在RISC-V中,物理内存地址是56bit,即每个物理地址的高44位是页表中存储的PPN,低12位是页内偏移,一个物理地址总共由56位构成。所以物理内存可以大于单个虚拟内存地址空间,但是也最多到2^56。
一个page table最多会有2^27个条目(虚拟内存地址中的index长度为27),这是个非常大的数字。如果每个进程都使用这么大的page table,进程需要为page table消耗大量的内存,并且很快物理内存就会耗尽。 (一个进程用2^27大小的物理内存太奢侈了)
所以实际上,硬件并不是按照上面的方式来存储page table,而是一个多级的结构。下图是一个真正的RISC-V page table结构和硬件实现。
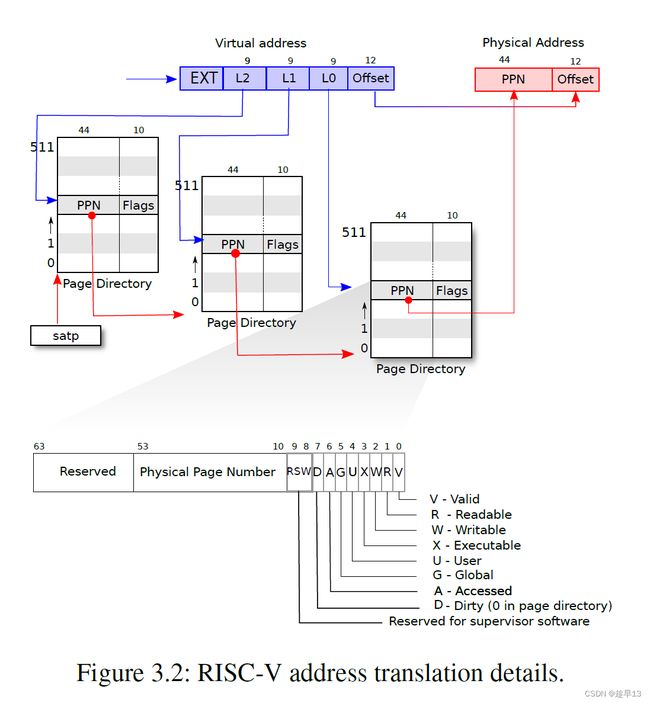
标志位的作用
- 第一个标志位是Valid。如果Valid bit位为1,那么表明这是一条合法的PTE,你可以用它来做地址翻译。对于刚刚举得那个小例子(应用程序只用了1个page的例子),我们只使用了3个page directory,每个page directory中只有第0个PTE被使用了,所以只有第0个PTE的Valid bit位会被设置成1,其他的511个PTE的Valid bit为0。这个标志位告诉MMU,你不能使用这条PTE,因为这条PTE并不包含有用的信息。
- 下两个标志位分别是Readable和Writable。表明你是否可以读/写这个page。
- Executable表明你可以从这个page执行指令。
- User表明这个page可以被运行在用户空间的进程访问。
- 其他标志位并不是那么重要,他们偶尔会出现,前面5个是重要的标志位。
之前提到的虚拟内存地址中的27bit的index,实际上是由3个9bit的数字组成(L2,L1,L0)。前9个bit被用来索引最高级的page directory。第一级页表是一个4096字节的页,包含了512个PTE(因为每个PTE需要8字节),每个PTE存储了下级页表的页物理地址,第二级列表由512个页构成,第三级列表由512*512个页构成。因为每个进程虚拟地址的高27位用来确定PTE,对应到3级页表就是最高的9位确定一级页表PTE的位置,中间9位确定二级页表PTE的位置,最低9位确定三级页表PTE的位置。如上图所示。第一级根页表的物理页地址存储在satp寄存器中,每个CPU拥有自己独立的satp。
映射过程:
- L0有 512(2 ^9) 个条目PTE(Page Table Entry),前9bit以此来找到L0的其中一条,得到PPN0。得到的PPN0与12bit的0拼接,得到第一个64位地址;(用44bit的PPN,再加上12bit的0,这样就得到了下一级page directory的56bit物理地址。这里要求每个page directory都与物理page对齐,也就是page directory的起始地址就是某个page的起始地址,所以低12bit都为0。)
- 64位地址地址指向第二个page_table :L1,中间9bit得到L1中的一条PTE,得到PPN1,PPN1与12bit的0拼接,得到第二个64 位地址;
- 第二个64 位地址指向最后一级page_table :L2,最后9bit得到L2中的一条PTE,得到PPN2,PPN2与虚拟地址中最后12位的offset拼接,得到第三个64 位地址,这个地址才是指向该进程的实际物理地址。
多级页表的优点:(时间换空间!)
在前一个方案中,如果我们只使用了一个page,还是需要2^27个PTE。这个方案中,我们只需要3 * 512个PTE。所需的空间大大减少了。这是实际上硬件采用这种层次化的3级page directory结构的主要原因。
实验目的:学习页表的实现机制,简化用户态拷贝数据到内核态的方法。
在xv6原本的设计中,用户进程在用户态使用各自的用户态页表,当需要进入内核态时(例如执行系统调用),则切换到内核页表(修改SATP寄存器的值),这个内核页表是全局共享的,在xv6源码中的定义在vm.c中。本次实验中,将其称之为全局内核页表。
若当进程处于内核态且需要访问用户页表中某个数据时,无法通过当前数据的在用户态中虚拟地址进行访问,因为此时内核态中使用的页表为全局内核页表,在该页表中不存在用户进程页表中的内容,所以内核无法使用CPU中硬件MMU来翻译对应的虚拟地址,只能通过软件模拟的方式(vm.c中的walkaddr函数)来访问,访问效率比较低。
该实验想要改变上述特性,希望内核能够访问用户进程对应的虚拟地址,在该实验中,需要给每个进程各自维护一张不同的进程内核页表(user_kernel_pagetable),当陷入内核时,将该进程的用户进程页表内容填入到进程内核页表中,然后切换到这个进程内核页表中,内核就可以直接使用虚拟地址来访问系统调用函数了。
3.2 Print a page table (easy)(编写一个打印页表内容的函数)
3.2.1 实验要求
定义一个名为vmprint()的函数。它应当接收一个pagetable_t作为参数,并以下面描述的格式打印该页表。在exec.c中的return argc之前插入if(p->pid==1) vmprint(p->pagetable)(pid==1的第一个进程在xv6中为sh进程,在user\init.c中所定义),以打印第一个进程的页表。如果你通过了pte printout测试的make grade,你将获得此作业的满分。
现在,当您启动xv6时,它应该像这样打印输出来描述第一个进程刚刚完成 ** exec() ** ing init时的页表:
page table 0x0000000087f6e000
..0: pte 0x0000000021fda801 pa 0x0000000087f6a000
.. ..0: pte 0x0000000021fda401 pa 0x0000000087f69000
.. .. ..0: pte 0x0000000021fdac1f pa 0x0000000087f6b000
.. .. ..1: pte 0x0000000021fda00f pa 0x0000000087f68000
.. .. ..2: pte 0x0000000021fd9c1f pa 0x0000000087f67000
..255: pte 0x0000000021fdb401 pa 0x0000000087f6d000
.. ..511: pte 0x0000000021fdb001 pa 0x0000000087f6c000
.. .. ..510: pte 0x0000000021fdd807 pa 0x0000000087f76000
.. .. ..511: pte 0x0000000020001c0b pa 0x0000000080007000

第一行显示vmprint的参数。之后的每行对应一个PTE,包含树中指向页表页的PTE。每个PTE行都有一些“…”的缩进表明它在树中的深度。每个PTE行显示其在页表页中的 PTE索引、PTE比特位以及从 PTE提取的物理地址。不要打印无效的PTE。在上面的示例中,顶级页表页具有条目0和255的映射。条目0的下一级只映射了索引0,该索引0的下一级映射了条目0、1和2。
提示:
- 你可以将 vmprint() 放在kernel/vm.c中
- 使用定义在kernel/riscv.h末尾处的宏
- 函数freewalk可能会对你有所启发
- 将vmprint的原型定义在kernel/defs.h中,这样你就可以在exec.c中调用它了
- 在你的printf调用中使用**%p来打印像上面示例中的完成的64比特的十六进制PTE和地址**
3.2.2 实验解决代码
- 在kernel/exec.c中的return argc之前插入if(p->pid==1) vmprint(p->pagetable)
//kernel/exec.c
//提前声明函数
void vmprint(pagetable_t pagetable,uint64 depth);
.......
p->trapframe->sp = sp; // initial stack pointer
proc_freepagetable(oldpagetable, oldsz);
f(p->pid==1) vmprint(p->pagetable)
return argc;
- 在kernel/vm.c中的加入vmprint()
//kernel/vm.c
//打印出地址
static char *prefix[] = {
[0] = "..",
[1] = ".. ..",
[2] = ".. .. .."
};
//pagetable depth递归深度
void vmprint(pagetable_t pagetable,uint64 depth)
{
//总共三级页表 深度大于2就可以直接返回
if(depth >2 ){
return;
}
if(depth == 0){
printf("page table %p",pagetable);
}
char *buf = prefix[depth];
// 遍历512个页表的PTE
for(int i = 0; i < 512; i++){
pte_t pte = pagetable[i];
if(pte & PTE_V){//如果PTE有效
// this PTE points to a lower-level page table.
printf("%s%d: pte %p pa %p\n",buf,i,pte,PTE2PA(pte));
uint64 child = PTE2PA(pte); // 获取PTE的地址
vmprint((pagetable_t) child,depth+1);
}
}
}
运行成功!!!


3.3 A kernel page table per process (hard)
3.3.1 实验要求
在这个任务中需要在用户进程中构建对应的用户进程内核页表,在实验过程中需要注意,要让进程的内核页表与全局的内核页表完全一致。
Xv6有一个单独的用于在内核中执行程序时的内核页表。内核页表直接映射(恒等映射)到物理地址,也就是说内核虚拟地址x映射到物理地址仍然是x。Xv6还为每个进程的用户地址空间提供了一个单独的页表,只包含该进程用户内存的映射,从虚拟地址0开始。因为内核页表不包含这些映射,所以用户地址在内核中无效。因此,当内核需要使用在系统调用中传递的用户指针(例如,传递给write()的缓冲区指针)时,内核必须首先将指针转换为物理地址。本节和下一节的目标是允许内核直接解引用用户指针。
你的第一项工作是修改内核来让每一个进程在内核中执行时使用它自己的内核页表的副本。修改struct proc来为每一个进程维护一个内核页表,修改调度程序使得切换进程时也切换内核页表。对于这个步骤,每个进程的内核页表都应当与现有的的全局内核页表完全一致。如果你的usertests程序正确运行了,那么你就通过了这个实验。
阅读本作业开头提到的章节和代码;了解虚拟内存代码的工作原理后,正确修改虚拟内存代码将更容易。页表设置中的错误可能会由于缺少映射而导致陷阱,可能会导致加载和存储影响到意料之外的物理页存页面,并且可能会导致执行来自错误内存页的指令。
提示:
- 在struct proc中为进程的内核页表增加一个字段
- 为一个新进程生成一个内核页表的合理方案是实现一个修改版的kvminit,这个版本中应当创造一个新的页表而不是修改kernel_pagetable。你将会考虑在allocproc中调用这个函数
- 确保每一个进程的内核页表都关于该进程的内核栈有一个映射。在未修改的XV6中,所有的内核栈都在procinit中设置。你将要把这个功能部分或全部的迁移到allocproc中
- 修改scheduler()来加载进程的内核页表到核心的satp寄存器(参阅kvminithart来获取启发)。不要忘记在调用完w_satp()后调用sfence_vma()
- 没有进程运行时scheduler()应当使用kernel_pagetable
- 在freeproc中释放一个进程的内核页表
- 你需要一种方法来释放页表,而不必释放叶子物理内存页面。
- 调式页表时,也许vmprint能派上用场
- 修改XV6本来的函数或新增函数都是允许的;你或许至少需要在kernel/vm.c和kernel/proc.c中这样做(但不要修改kernel/vmcopyin.c, kernel/stats.c, user/usertests.c, 和user/stats.c)
- 页表映射丢失很可能导致内核遭遇页面错误。这将导致打印一段包含sepc=0x00000000XXXXXXXX的错误提示。你可以在kernel/kernel.asm通过查询XXXXXXXX来定位错误。
3.3.3 实验解决代码
- 首先给kernel/proc.h里面的struct proc加上内核页表的字段
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
pagetable_t kernelpt; // 进程的内核页表
struct trapframe *trapframe; // data page for trampoline.S
2.在vm.c中添加新的方法proc_kpt_init,该方法用于在allocproc 中初始化进程的内核页表。这个函数还需要一个辅助函数uvmmap,该函数和kvmmap方法几乎一致,不同的是kvmmap是对Xv6的内核页表进行映射,而uvmmap将用于进程的内核页表进行映射。
// kernel\vm.c
// 仿照kvmmap() 采用uvmmap将用于进程的内核页表进行映射。
void
uvmmap(pagetable_t pagetable, uint64 va, uint64 pa, uint64 sz, int perm)
{
//给定一个页表、一个虚拟地址和物理地址,创建一个PTE以实现相应的映射
if(mappages(pagetable, va, sz, pa, perm) != 0)
panic("uvmmap");
}
// 创建一个属于进程的内核页表
pagetable_t
proc_kpt_init()
{
pagetable_t kernelpt = uvmcreate();
if(kernelpt == 0) return 0;
uvmmap(kernelpt, UART0, UART0, PGSIZE, PTE_R | PTE_W);
uvmmap(kernelpt, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
uvmmap(kernelpt, CLINT, CLINT, 0x10000, PTE_R | PTE_W);
uvmmap(kernelpt, PLIC, PLIC, 0x400000, PTE_R | PTE_W);
uvmmap(kernelpt, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
uvmmap(kernelpt, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
uvmmap(kernelpt, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
return kernelpt;
}
然后在kernel/proc.c里面的allocproc调用。
// kernel/proc.c
......
// An empty user page table.
p->pagetable = proc_pagetable(p);
if(p->pagetable == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// 初始化kpagetable
p->kernelpt = proc_kpt_init();
if(p->kernelpt == 0){
freeproc(p);//释放proc结构和挂起的数据,包括用户页面。p->lock必须持有。
release(&p->lock);//释放锁
return 0;
}
- 根据提示,为了确保每一个进程的内核页表都关于该进程的内核栈有一个映射。我们需要将procinit方法中相关的代码迁移到allocproc方法中。很明显就是下面这段代码,将其剪切到上述内核页表初始化的代码后。
// kernel/proc.c
......
// 初始化kpagetable
p->kernelpt = proc_kpt_init();
if(p->kernelpt == 0){
freeproc(p);//释放proc结构和挂起的数据,包括用户页面。p->lock必须持有。
release(&p->lock);//释放锁
return 0;
}
// Allocate a page for the process's kernel stack.
// Map it high in memory, followed by an invalid
// guard page.
char *pa = kalloc();
if(pa == 0)
panic("kalloc");
uint64 va = KSTACK((int) (p - proc));
uvmmap(p->kernelpt, va, (uint64)pa, PGSIZE, PTE_R | PTE_W);
p->kstack = va;
- 我们需要修改kernel/proc.c 中scheduler() 来加载进程的内核页表到SATP寄存器。提示里面请求阅读kernel\vm.c kvminithart()。
// Switch h/w page table register to the kernel's page table,
// and enable paging.
void
kvminithart()
{
w_satp(MAKE_SATP(kernel_pagetable));
sfence_vma();
}
kvminithart是用于原先的内核页表,我们将进程的内核页表传进去就可以。在vm.c里面添加一个新方法proc_inithart。
//kernel/vm.c
......
//将内核页表存储到SATP寄存器
void
proc_inithart(pagetable_t kpt){
w_satp(MAKE_SATP(kpt));
sfence_vma();
}
// Switch h/w page table register to the kernel's page table,
// and enable paging.
void
kvminithart()
{
w_satp(MAKE_SATP(kernel_pagetable));
sfence_vma();
}
然后在kernel/proc.c 中scheduler() 内调用即可,但在结束的时候,需要切换回原先的kernel_pagetable。直接调用调用上面的**kvminithart()**就能把Xv6的内核页表加载回去。
// kernel/proc.c 中scheduler()
.....
p->state = RUNNING;
c->proc = p;
//将内核页表存储到SATP寄存器
proc_inithart(p->kernelpt);
swtch(&c->context, &p->context);
// 再把Xv6的内核页表加载回去
kvminithart();
....
- 在kernel/proc.c freeproc()中释放一个进程的内核页表。首先释放页表内的内核栈,调用uvmunmap可以解除映射,最后的一个参数 为1 的时候,会释放实际内存。
// kernel/proc.c freeproc()
...
p->state = UNUSED;
// free the kernel stack in the RAM
uvmunmap(p->kernelpt, p->kstack, 1, 1);
p->kstack = 0;
...
然后释放进程的内核页表,先在kernel/proc.c里面添加一个方法proc_freekernelpt。如下,历遍整个内核页表,然后将所有有效的页表项清空为零。如果这个页表项不在最后一层的页表上,需要继续进行递归。
//kernel/proc.c
//释放进程的内核页表 历遍整个内核页表,
//然后将所有有效的页表项清空为零。如果这个页表项不在最后一层的页表上,需要继续进行递归。
void
proc_freekernelpt(pagetable_t kernelpt)
{
// similar to the freewalk method
// there are 2^9 = 512 PTEs in a page table.
for(int i = 0; i < 512; i++){
pte_t pte = kernelpt[i];
if(pte & PTE_V){
kernelpt[i] = 0;
if ((pte & (PTE_R|PTE_W|PTE_X)) == 0){
uint64 child = PTE2PA(pte);
proc_freekernelpt((pagetable_t)child);
}
}
}
kfree((void*)kernelpt);
}
- 将需要的函数定义添加到 kernel/defs.h 中
//kernel/defs.h
...
// vm.c
void kvminit(void);
pagetable_t proc_kpt_init(void);// 用于内核页表的初始化
void kvminithart(void);
void proc_inithart(pagetable_t);// 将进程的内核页表保存到SATP寄存器
uint64 kvmpa(uint64);
void kvmmap(uint64, uint64, uint64, int);
void uvmmap(pagetable_t,uint64, uint64, uint64, int);//辅助函数
...
- 修改vm.c中的kvmpa,将原先的kernel_pagetable改成myproc()->kernelpt,使用进程的内核页表。
//kernel/vm.c
#include "spinlock.h"
#include "proc.h"
uint64
kvmpa(uint64 va)
{
uint64 off = va % PGSIZE;
pte_t *pte;
uint64 pa;
pte = walk(myproc()->kernelpt, va, 0); // 修改这里
if(pte == 0)
panic("kvmpa");
if((*pte & PTE_V) == 0)
panic("kvmpa");
pa = PTE2PA(*pte);
return pa+off;
}
-
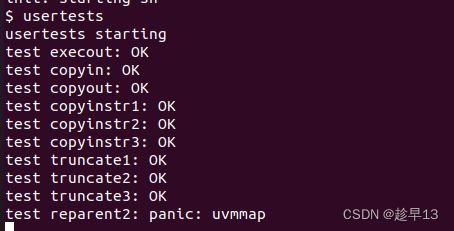
测试一下我们的代码,先跑起qemu,然后跑一下usertests。这部分耗时会比较长。
$ make qemu > usertests
运行很成功!!!
3.4 Simplify copyin/copyinstr(hard)
承接上一个任务,现在每个进程已经拥有独立的用户进程内核页表了,这个任务的目的就是在用户进程内核页表中添加用户页表映射的副本,这样当该进程陷入内核时,就能够通过内核正确翻译虚拟地址,从而访问用户进程中的数据。
这样做相比原来 copyin 的实现的优势是,原来的 copyin 是通过软件模拟访问页表的过程获取物理地址的,而在内核页表内维护映射副本的话,可以利用 CPU 的硬件(MMU)寻址功能进行寻址,效率更高并且可以受快表加速。
3.4.1 实验要求
内核的copyin函数读取用户指针指向的内存。它通过将用户指针转换为内核可以直接解引用的物理地址来实现这一点。这个转换是通过在软件中遍历进程页表来执行的。在本部分的实验中,您的工作是将用户空间的映射添加到每个进程的内核页表(上一节中创建),以允许copyin(和相关的字符串函数copyinstr)直接解引用用户指针。
将定义在kernel/vm.c中的copyin的主题内容替换为对copyin_new的调用(在kernel/vmcopyin.c中定义);对copyinstr和copyinstr_new执行相同的操作。为每个进程的内核页表添加用户地址映射,以便copyin_new和copyinstr_new工作。如果usertests正确运行并且所有make grade测试都通过,那么你就完成了此项作业。
此方案依赖于用户的虚拟地址范围不与内核用于自身指令和数据的虚拟地址范围重叠。Xv6使用从零开始的虚拟地址作为用户地址空间,幸运的是内核的内存从更高的地址开始。然而,这个方案将用户进程的最大大小限制为小于内核的最低虚拟地址。内核启动后,在XV6中该地址是0xC000000,即PLIC寄存器的地址;请参见kernel/vm.c中的kvminit()、kernel/memlayout.h和文中的图3-4。您需要修改xv6,以防止用户进程增长到超过PLIC的地址。
提示:
- 先用对copyin_new的调用替换copyin(),确保正常工作后再去修改copyinstr
- 在内核更改进程的用户映射的每一处,都以相同的方式更改进程的内核页表。包括fork(), exec(), 和sbrk().
- 不要忘记在userinit的内核页表中包含第一个进程的用户页表
- 用户地址的PTE在进程的内核页表中需要什么权限?(在 内核模式下,无法访问设置了PTE_U的页面)
- 别忘了上面提到的PLIC限制
Linux使用的技术与您已经实现的技术类似。直到几年前,许多内核在用户和内核空间中都为当前进程使用相同的自身进程页表,并为用户和内核地址进行映射以避免在用户和内核空间之间切换时必须切换页表。然而,这种设置允许边信道攻击,如Meltdown和Spectre。
解释为什么在copyin_new()中需要第三个测试srcva + len < srcva:给出srcva和len值的例子,这样的值将使前两个测试为假(即它们不会导致返回-1),但是第三个测试为真 (导致返回-1)。
3.4.2 实验完成代码

- 先实现一个复制page table的函数u2kvmcopy来将user page table(用户页表)复制到process kernel page table(进程内核页表),注意在复制的过程中需要清除原先PTE中的PTE_U标志位,否则kernel无法访问
在kernel/vm.c中添加u2kvmcopy
kernel/vm.c
//实现一个复制page table的函数u2kvmcopy
//来将user page table复制到process kernel page table
//注意在复制的过程中需要清除原先PTE中的PTE_U标志位,否则kernel无法访问
void
u2kvmcopy(pagetable_t pagetable,pagetable_t kpagetable,uint64 oldsz,uint64 newsz){
//pagetable:用户页表
//kpagetable:进程内核页表
pte_t *pte_from,*pte_to;
uint64 a,pa;
uint64 flags;
if(newsz<oldsz){
return;
}
往高地址处对齐4k地址 PGROUNDUP(sz)的功能就是当sz不是页的倍数时进一位使其为页的倍数
oldsz = PGROUNDUP(oldsz);
for(a = oldsz;a<newsz;a+=PGSIZE){
if((pte_from=walk(pagetable,a,0))==0) // 找到用户页表地址的最后一级页表项
panic("u2kvmcopy: pte should exist");
if((pte_to = walk(kpagetable,a,1))==0)// 把进程内核页表地址的最后一级页表项置为0
panic("u2kvmcopy: walk fails");
// 将页表项转换为物理地址页起始位置
pa = PTE2PA(*pte_from);
// 必须设置该权限,让RISC-V 中内核可以直接访问用户页
flags = (PTE_FLAGS(*pte_from))&(~PTE_U);
// 将物理地址页起始位置转换为页表项
*pte_to = PA2PTE(pa)|flags;
}
}
- 在每个改变了user page table的地方要调用u2kvmcopy()使得process kernel page table跟上这个变化。这些地方出现在fork()、exec()、userinit()和sbrk()需要调用的growproc()。注意要防止user process过大导致virtual address超过PLIC
kernel/exec.c
int
exec(char *path, char **argv){
...
sp = sz;
stackbase = sp - PGSIZE;
// 添加复制逻辑
u2kvmcopy(pagetable, p->kernelpt, 0, sz);
// Push argument strings, prepare rest of stack in ustack.
for(argc = 0; argv[argc]; argc++) {
...
}
kernel/proc.c
int
fork(void){
...
// Copy user memory from parent to child.
if(uvmcopy(p->pagetable, np->pagetable, p->sz) < 0){
freeproc(np);
release(&np->lock);
return -1;
}
np->sz = p->sz;
...
// 复制到新进程的内核页表
u2kvmcopy(np->pagetable, np->kernelpt, 0, np->sz);
...
}
kernel/proc.c
int
userinit(void){
...
// allocate one user page and copy init's instructions
// and data into it.
uvminit(p->pagetable, initcode, sizeof(initcode));
p->sz = PGSIZE;
// 复制到新进程的内核页表
u2kvmcopy(np->pagetable, np->kernelpt, 0, np->sz);
...
}
sbrk(), 在kernel/sysproc.c里面找到sys_sbrk(void),可以知道只有growproc是负责将用户内存增加或缩小 n 个字节。以防止用户进程增长到超过PLIC的地址,我们需要给它加个限制。
kernel/proc.c
int
growproc(int n)
{
uint sz;
struct proc *p = myproc();
sz = p->sz;
if(n > 0){
// 加上PLIC限制
if (PGROUNDUP(sz + n) >= PLIC){
return -1;
}
if((sz = uvmalloc(p->pagetable, sz, sz + n)) == 0) {
return -1;
}
// 复制一份到内核页表
u2kvmcopy(p->pagetable, p->kernelpt, sz - n, sz);
} else if(n < 0){
sz = uvmdealloc(p->pagetable, sz, sz + n);
}
p->sz = sz;
return 0;
}
- 然后替换掉原有的copyin()和copyinstr()
kernel/vm.c
// Copy from user to kernel.
// Copy len bytes to dst from virtual address srcva in a given page table.
// Return 0 on success, -1 on error.
int
copyin(pagetable_t pagetable, char *dst, uint64 srcva, uint64 len)
{
return copyin_new(pagetable, dst, srcva, len);
}
// Copy a null-terminated string from user to kernel.
// Copy bytes to dst from virtual address srcva in a given page table,
// until a '\0', or max.
// Return 0 on success, -1 on error.
int
copyinstr(pagetable_t pagetable, char *dst, uint64 srcva, uint64 max)
{
return copyinstr_new(pagetable, dst, srcva, max);
}
4.将u2kvmcopy()、**copyin_new()和copyin_new()**添加到 kernel/defs.h 中
//vm.c
....
uint64 uvmdealloc(pagetable_t, uint64, uint64);
void u2kvmcopy(pagetable_t,pagetable_t,uint64,uint64); //复制用户页表至内核页表中
#ifdef SOL_COW
....
// vmcopyin.c
int copyin_new(pagetable_t, char *, uint64, uint64);
int copyinstr_new(pagetable_t, char *, uint64, uint64);
-
跑一下测试
$ make grade(未运行成功)
4 Lab4: traps
本实验探索如何使用陷阱实现系统调用。您将首先使用栈做一个热身练习,然后实现一个用户级陷阱处理的示例。
[!WARNING|label:Attention] 开始编码之前,请阅读xv6手册的第4章和相关源文件:
-kernel/trampoline.S:涉及从用户空间到内核空间再到内核空间的转换的程序集
-kernel/trap.c:处理所有中断的代码
要启动实验,请切换到traps分支:
$ git fetch
$ git checkout traps
$ make clean
4.1 前置知识
4.1.1 trap代码执行流程


例如:跟踪如何在Shell中调用write系统调用
- 从Shell的角度来说,这就是个Shell代码中的C函数调用,但是实际上,write通过执行ECALL指令来执行系统调用
- ECALL指令会切换到具有supervisor mode的内核中。在这个过程中,内核中执行的第一个指令是一个由汇编语言写的函数,叫做uservec。这个函数是内核代码trampoline.s文件的一部分。所以执行的第一个代码就是这个uservec汇编函数。
- 之后,在这个汇编函数中,代码执行跳转到了由C语言实现的函数usertrap中,这个函数在trap.c中。
- 在usertrap这个C函数中,我们执行了一个叫做syscall的函数。这个函数会在一个表单中,根据传入的代表系统调用的数字进行查找,并在内核中执行具体实现了系统调用功能的函数。
- 对于本例来说,这个函数就是sys_write。sys_write会将要显示数据输出到控制台上,当它完成了之后,它会返回给syscall函数。
- 因为我们现在相当于在ECALL之后中断了用户代码的执行,为了用户空间的代码恢复执行,需要做一系列的事情。在syscall函数中,会调用一个函数叫做usertrapret,它也位于trap.c中,这个函数完成了部分方便在C代码中实现的返回到用户空间的工作。
- 除此之外,最终还有一些工作只能在汇编语言中完成。这部分工作通过汇编语言实现,并且存在于trampoline.s文件中的userret函数中。

4.2 RISC-V assembly (easy)
4.2.1 实验要求
理解一点RISC-V汇编是很重要的,你应该在6.004中接触过。xv6仓库中有一个文件user/call.c。执行make fs.img编译它,并在user/call.asm中生成可读的汇编版本。
阅读call.asm中函数g、f和main的代码。RISC-V的使用手册在参考页上。以下是您应该回答的一些问题(将答案存储在answers-traps.txt文件中):
-
哪些寄存器保存函数的参数?例如,在main对printf的调用中,哪个寄存器保存13?
-
main的汇编代码中对函数f的调用在哪里?对g的调用在哪里(提示:编译器可能会将函数内联)
-
printf函数位于哪个地址?
-
在main中printf的jalr之后的寄存器ra中有什么值?
-
运行以下代码:
unsigned int i = 0x00646c72; printf("H%x Wo%s", 57616, &i);程序的输出是什么?这是将字节映射到字符的ASCII码表。
输出取决于RISC-V小端存储的事实。如果RISC-V是大端存储,为了得到相同的输出,你会把i设置成什么?是否需要将57616更改为其他值?
-
在下面的代码中,“y=”之后将打印什么(注:答案不是一个特定的值)?为什么会发生这种情况?
printf("x=%d y=%d", 3);
4.2.2 实验解答
执行make fs.img编译它,并在user/call.asm中生成可读的汇编版本。
-
在a0-a7中存放参数,13存放在a2中(user/call.asm 24)
-
在C代码中,main调用f,f调用g。而在生成的汇编中,main函数进行了内联优化处理。
从代码li a1,12可以看出,main直接计算出了结果并储存 -
在 user/call.asm 0x630
-
auipc(Add Upper Immediate to PC):auipc rd imm,将高位立即数加到PC上,从下面的指令格式可以看出,该指令将20位的立即数imm左移12位之后(右侧补0)加上当前PC的值,将结果保存到dest位置,图中为rd寄存器

jalr (jump and link register):jalr rd, offset(rs1)跳转并链接寄存器。jalr指令会将当前PC+4保存在rd中,然后跳转到指定的偏移地址offset(rs1)。来看XV6的代码**(user/call.asm 49)**:
30: 00000097 auipc ra,0x0 34: 600080e7 jalr 1536(ra) # 630第一行代码:00000097H=00…0 0000 1001 0111B,对比指令格式,可见imm=0,dest=00001,opcode=0010111,对比汇编指令可知,auipc的操作码是0010111,ra寄存器中是00001。这行代码将0x0左移12位(还是0x0)加到PC(当前为0x30)上并存入ra中,即ra中保存的是0x30
第2行代码:600080e7H=0110 0…0 1000 0000 1110 0111B,可见imm=0110 0000 0000,rs1=00001,funct3=000,rd=00001,opcode=1100111,rs1和rd的知识码都是00001,即都为寄存器ra。这对比jalr的标准格式有所不同,可能是此两处使用寄存器相同时,汇编中可以省略rd部分。
ra中保存的是0x30,加上0x600后为0x630,即printf的地址,执行此行代码后,将跳转到printf函数执行,并将PC+4=0X34+0X4=0X38保存到ra中,供之后返回使用。
-
57616=0xE110,0x00646c72小端存储为72-6c-64-00,对照ASCII码表
72:r 6c:l 64:d 00:充当字符串结尾标识
因此输出为:HE110 World
若为大端存储,i应改为0x726c6400,不需改变57616
-
原本需要两个参数,却只传入了一个,因此y=后面打印的结果取决于之前a2中保存的数据
4.3 Backtrace(moderate)
4.3.1 实验要求
回溯(Backtrace)通常对于调试很有用:它是一个存放于栈上用于指示错误发生位置的函数调用列表。
在kernel/printf.c中实现名为backtrace()的函数。在sys_sleep中插入一个对此函数的调用,然后运行bttest,它将会调用sys_sleep。你的输出应该如下所示:
backtrace:
0x0000000080002cda
0x0000000080002bb6
0x0000000080002898
在bttest退出qemu后。在你的终端:地址或许会稍有不同,但如果你运行addr2line -e kernel/kernel(或riscv64-unknown-elf-addr2line -e kernel/kernel),并将上面的地址剪切粘贴如下:
$ addr2line -e kernel/kernel
0x0000000080002de2
0x0000000080002f4a
0x0000000080002bfc
Ctrl-D
你应该看到类似下面的输出:
kernel/sysproc.c:74
kernel/syscall.c:224
kernel/trap.c:85
编译器向每一个栈帧中放置一个帧指针(frame pointer)保存调用者帧指针的地址。你的backtrace应当使用这些帧指针来遍历栈,并在每个栈帧中打印保存的返回地址。
提示:
-
在kernel/defs.h中添加backtrace的原型,那样你就能在sys_sleep中引用backtrace
-
GCC编译器将当前正在执行的函数的帧指针保存在s0寄存器,将下面的函数添加到kernel/riscv.h
static inline uint64
r_fp()
{
uint64 x;
asm volatile("mv %0, s0" : "=r" (x) );
return x;
}
并在backtrace中调用此函数来读取当前的帧指针。这个函数使用内联汇编来读取s0
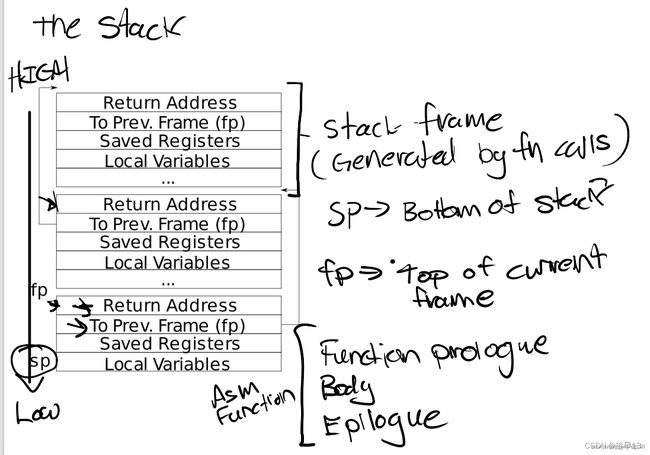
- 这个课堂笔记中有张栈帧布局图。注意返回地址位于栈帧帧指针的固定偏移**(-8)位置,并且保存的帧指针位于帧指针的固定偏移(-16)**位置
- XV6在内核中以页面对齐的地址为每个栈分配一个页面。你可以通过PGROUNDDOWN(fp)和PGROUNDUP(fp)(参见kernel/riscv.h)来计算栈页面的顶部和底部地址。这些数字对于backtrace终止循环是有帮助的。
一旦你的backtrace能够运行,就在kernel/printf.c的panic中调用它,那样你就可以在panic发生时看到内核的backtrace。
4.3.2 实验相关知识
-
函数调用栈(Stack)

- 由高地址往低地址增长
- 在xv6里,有一页大小(4KB)
- 栈指针 stack pointer 是该栈的顶部,保存在sp寄存器里
-
栈帧(Stack Frame)
上述的函数调用栈里面有若干个栈帧,每个栈帧代表着一个函数调用

- 当前栈帧的地址保存在 s0/fp寄存器里
- 当前栈帧的地址也叫栈帧的指针 (frame pointer, fp),指向该栈帧的最高处
- 栈帧指针往下偏移8个字节是函数返回地址 return address
- 往下偏移16个字节是上一个栈帧的栈帧指针 (previous frame pointer)
栈从高地址向低地址增长,每个大的box叫一个stack frame(栈帧),栈帧由函数调用来分配,每个栈帧大小不一定一样,但是栈帧的最高处一定是return address
sp是stack pointer,用于指向栈顶(低地址),保存在寄存器中
fp是frame pointer,用于指向当前帧底部(高地址),保存在寄存器中,同时每个函数栈帧中保存了调用当前函数的函数 (父函数) 的fp(保存在to prev frame那一栏中)
这些栈帧都是由编译器编译生成的汇编文件生成的
4.3.3 实验解答
- 在kernel/defs.h中加入backtrace函数调用
kernel/defs.h
......
// printf.c
void printf(char*, ...);
void panic(char*) __attribute__((noreturn));
void printfinit(void);
void backtrace(void);
- GCC编译器将当前正在执行的函数的帧指针保存在s0寄存器,通过将r_fp()函数添加到kernel/riscv.h 来得到当前函数的帧指针。
kernel/riscv.h
static inline uint64
r_fp()
{
uint64 x;
asm volatile("mv %0, s0" : "=r" (x) );
return x;
}
- 在kernel/printf.c中实现backtrace函数
kernel/printf.c
void
backtrace(void){
printf("backtrace:\n");
//获取当前正在执行的函数栈指针
uint64 fp = r_fp();
//用frame指针 来代指当前的函数栈指针
uint64 *frame = (uint64 *)fp;
//获取栈指针的上界 一个4096页面的顶
uint64 up = PGROUNDUP(fp);
//获取栈指针的下界 一个4096页面的底
uint64 down = PGROUNDDOWN(fp);
while(fp < up && fp>down){
//打印出函数返回地址 **return address**
printf("%p\n",frame[-1]);
//将指针指向上一个栈帧的栈帧指针**(previous frame pointer)**
fp = frame[-2];
frame = (uint64 *) fp;
}
}
- 在kernel/sysproc.c中的sys_call添加backtrace,以实现bttest的测试
kernel/sysproc.c
uint64
sys_sleep(void)
{
.......
release(&tickslock);
backtrace();
return 0;
}
启动 make qemu 后 输入 bttest 测试:

4.4 Alarm(Hard)
4.4.1 实验要求
[!TIP|label:YOUR JOB] 在这个练习中你将向XV6添加一个特性,在进程使用CPU的时间内,XV6定期向进程发出警报。这对于那些希望限制CPU时间消耗的受计算限制的进程,或者对于那些计算的同时执行某些周期性操作的进程可能很有用。更普遍的来说,你将实现用户级中断/故障处理程序的一种初级形式。例如,你可以在应用程序中使用类似的一些东西处理页面故障。如果你的解决方案通过了alarmtest和usertests就是正确的。
你应当添加一个新的sigalarm(interval, handler)系统调用,如果一个程序调用了sigalarm(n, fn),那么每当程序消耗了CPU时间达到n个“滴答”,内核应当使应用程序函数fn被调用。当fn返回时,应用应当在它离开的地方恢复执行。在XV6中,一个滴答是一段相当任意的时间单元,取决于硬件计时器生成中断的频率。如果一个程序调用了sigalarm(0, 0),系统应当停止生成周期性的报警调用。
你将在XV6的存储库中找到名为user/alarmtest.c的文件。将其添加到Makefile。注意:你必须添加了sigalarm和sigreturn系统调用后才能正确编译(往下看)。
alarmtest在test0中调用了sigalarm(2, periodic)来要求内核每隔两个滴答强制调用periodic(),然后旋转一段时间。你可以在user/alarmtest.asm中看到alarmtest的汇编代码,这或许会便于调试。当 alarmtest 产生如下输出并且usertests也能正常运行时,你的方案就是正确的:
$ alarmtest
test0 start
........alarm!
test0 passed
test1 start
...alarm!
..alarm!
...alarm!
..alarm!
...alarm!
..alarm!
...alarm!
..alarm!
...alarm!
..alarm!
test1 passed
test2 start
................alarm!
test2 passed
$ usertests
...
ALL TESTS PASSED
$
当你完成后,你的方案也许仅有几行代码,但如何正确运行是一个棘手的问题。我们将使用原始存储库中的alarmtest.c版本测试您的代码。你可以修改alarmtest.c来帮助调试,但是要确保原来的alarmtest显示所有的测试都通过了。
test0: invoke handler(调用处理程序)
首先修改内核以跳转到用户空间中的报警处理程序,这将导致test0打印“alarm!”。不用担心输出“alarm!”之后会发生什么;如果您的程序在打印“alarm!”后崩溃,对于目前来说也是正常的。
提示:
-
您需要修改Makefile以使alarmtest.c被编译为xv6用户程序。
-
放入user/user.h的正确声明是:
int sigalarm(int ticks, void (*handler)()); int sigreturn(void); -
更新user/usys.pl(此文件生成user/usys.S)、kernel/syscall.h和kernel/syscall.c以允许alarmtest调用sigalarm和sigreturn系统调用。
-
目前来说,你的sys_sigreturn系统调用返回应该是零。
-
你的sys_sigalarm() 应该将报警间隔和指向处理程序函数的指针存储在struct proc的新字段中(位于kernel/proc.h)。
-
你也需要在struct proc新增一个新字段。用于跟踪自上一次调用(或直到下一次调用)到进程的报警处理程序间经历了多少滴答;您可以在proc.c的allocproc()中初始化proc字段。
-
每一个滴答声,硬件时钟就会强制一个中断,这个中断在kernel/trap.c中的usertrap() 中处理。
-
如果产生了计时器中断,您只想操纵进程的报警滴答;你需要写类似下面的代码
if(which_dev == 2) ... -
仅当进程有未完成的计时器时才调用报警函数。请注意,用户报警函数的地址可能是0(例如,在user/alarmtest.asm中,periodic位于地址0)。
-
您需要修改usertrap(),以便当进程的报警间隔期满时,用户进程执行处理程序函数。当RISC-V上的陷阱返回到用户空间时,什么决定了用户空间代码恢复执行的指令地址?(要找出sys_sigalarm调用函数fn()应该放在哪里)
-
如果您告诉qemu只使用一个CPU,那么使用gdb查看陷阱会更容易,这可以通过运行
make CPUS=1 qemu-gdb -
如果alarmtest打印“alarm!”,则您已成功。
test1/test2(): resume interrupted code(恢复被中断的代码)
alarmtest打印“alarm!”后,很可能会在test0或test1中崩溃,或者alarmtest(最后)打印“test1 failed”,或者alarmtest未打印“test1 passed”就退出。要解决此问题,必须确保完成报警处理程序后返回到用户程序最初被计时器中断的指令执行。必须确保寄存器内容恢复到中断时的值,以便用户程序在报警后可以不受干扰地继续运行。最后,您应该在每次报警计数器关闭后“重新配置”它,以便周期性地调用处理程序。
作为一个起始点,我们为您做了一个设计决策:用户报警处理程序需要在完成后调用sigreturn系统调用。请查看alarmtest.c中的periodic作为示例。这意味着您可以将代码添加到usertrap和sys_sigreturn中,这两个代码协同工作,以使用户进程在处理完警报后正确恢复。
提示:
-
您的解决方案将要求您保存和恢复寄存器——您需要保存和恢复哪些寄存器才能正确恢复中断的代码?(提示:会有很多)
-
当计时器关闭时,让usertrap在struct proc中保存足够的状态,以使sigreturn可以正确返回中断的用户代码。
-
防止对处理程序的重复调用——如果处理程序还没有返回,内核就不应该再次调用它。test2测试这个。
-
一旦通过test0、test1和test2,就运行usertests以确保没有破坏内核的任何其他部分。
4.4.2 实验解答
- 在Makefile中添加 alarmtest 系统调用
UPROGS=\
......
$U/_wc\
$U/_zombie\
$U/_alarmtest\
- 在user/user.h中添加sigalarm、 sigreturn声明
user/user.h
// system calls
.....
int uptime(void);
int sigalarm(int ticks, void (*handler)());
int sigreturn(void);
- 在user/usys.pl(此文件生成user/usys.S)、kernel/syscall.h和kernel/syscall.c添加alarmtest 中的 sigalarm和sigreturn系统调用。
user/usys.pl
.....
entry("sleep");
entry("uptime");
entry("sigalarm");
entry("sigreturn");
kernel/syscall.h
....
#define SYS_close 21
#define SYS_sigalarm 22
#define SYS_sigreturn 23
kernel/syscall.c
......
extern uint64 sys_write(void);
extern uint64 sys_uptime(void);
extern uint64 sys_sigalarm(void);
extern uint64 sys_sigreturn(void);
static uint64 (*syscalls[])(void) = {
......
[SYS_close] sys_close,
[SYS_sigalarm] sys_sigalarm,
[SYS_sigreturn] sys_sigreturn,
};
- 在kernel/proc.h中对 pro 结构体中添加 sys_sigalarm 调用的参数字段
kernel/proc.h
// Per-process state
struct proc {
.......
char name[16]; // Process name (debugging)
int ticks; //sys_sigalarm调用的第一个参数 时钟数
int ticks_cnt; //调用sys_sigalarm后经过多少个时钟周期
uint64 handler; //sys_sigalarm调用的第2️个参数 调用应用程序函数地址
};
- 在kernel/proc.c中的allocproc函数对 tick 进行初始化
kernel/proc.c
static struct proc*
allocproc(void)
{
.......
// Set up new context to start executing at forkret,
// which returns to user space.
memset(&p->context, 0, sizeof(p->context));
p->context.ra = (uint64)forkret;
p->context.sp = p->kstack + PGSIZE;
p->ticks = 0;
return p;
}
- 在kernel/sysproc.c中实现 sys_sigalarm函数
uint64
sys_sigalarm(void)
{
//系统调用第一个参数 时钟数
int ticks;
//系统调用第二个参数 应用函数指针
uint64 handler;
//直接通过寄存器 把a0 即第一个参数赋值给tick
argint(0,&ticks);
//直接通过寄存器 把a1 即第二个参数赋值给handler
argaddr(1,&handler);
struct proc *p = myproc();
p->ticks = ticks;
p->handler = handler;
p->ticks_cnt = 0;
return 0;
}
- 在kernel/trap.c中对 usertrap函数进行修改,每一个滴答声(时钟期),硬件时钟就会强制一个中断(which_dev == 2),我们在此添加对sys_sigalarm时钟数的判断,并通过更改 epc 的值来执行 fn 函数
kernel/trap.c
void
usertrap(void)
{
......
if(p->killed)
exit(-1);
// give up the CPU if this is a timer interrupt.
//每一个滴答声(时钟期),硬件时钟就会强制一个中断
if(which_dev == 2){
//当p->ticks>0意味着有sys_sigalarm调用
if(p->ticks>0){
//记录经过多少个滴答声(时钟期)
p->ticks_cnt++;
//当达到设定的时钟期后
if(p->ticks_cnt > p->ticks){
p->ticks_cnt = 0;
//epc保存的是内核返回用户态应当执行的程序地址 我们设定为sys_sigalarm的调用函数
p->trapframe->epc = p->handler;
}
}
yield();
}
usertrapret();
}
-
执行 alarmtest

test0 通过!!! -
在kernel/proc.h中对 proc 结构体中添加 :alarm_trapframe 来保存原始trapframe的所有值 即返回用户态后需要各个寄存器状态;handler_cnt来防止对hander函数(fn)的重复调用
kernel/proc.h
// Per-process state
struct proc {
.......
char name[16]; // Process name (debugging)
int ticks; //sys_sigalarm调用的第一个参数 时钟数
int ticks_cnt; //调用sys_sigalarm后经过多少个时钟周期
uint64 handler; //sys_sigalarm调用的第2️个参数 调用应用程序函数地址
};
struct trapframe *alarm_trapframe; //保存原始trapframe的所有值 即返回用户态后需要各个寄存器状态
int handler_cnt; //防止对hander函数(fn)的重复调用
- 在kernel/trap.c中对 usertrap函数进行修改,在(which_dev == 2)时将将原始陷阱帧trapframe的所有值保存到p->alarm_trapframe中
kernel/trap.c
// give up the CPU if this is a timer interrupt.
//每一个滴答声(时钟期),硬件时钟就会强制一个中断
if(which_dev == 2){
......
if(p->handler_cnt == 0 && p->ticks_cnt > p->ticks){
p->ticks_cnt = 0;
//将原始trapframe的所有值保存 即返回用户态后需要各个寄存器状态
memmove(p->alarm_trapframe,p->trapframe,sizeof(struct trapframe));
//epc保存的是内核返回用户态应当执行的程序地址 我们设定为sys_sigalarm的调用函数fn
p->trapframe->epc = p->handler;
//置为1 不会再调用fn函数
p->handler_cnt = 1;
}
}
- 在 kernel/proc.c 中allocproc和freeproc中设定好相关分配,回收内存的代码
kernel/proc.c
static struct proc*
allocproc(void)
{
......
p->context.sp = p->kstack + PGSIZE;
// 初始化告警字段
if((p->alarm_trapframe = (struct trapframe*)kalloc()) == 0) {
freeproc(p);
release(&p->lock);
return 0;
}
p->ticks = 0;
p->ticks_cnt = 0;
p->handler_cnt = 0;
p->handler = 0;
return p;
}
static void
freeproc(struct proc *p)
{
......
p->xstate = 0;
p->state = UNUSED;
//回收相关资源
if(p->alarm_trapframe)
kfree((void*)p->alarm_trapframe);
p->ticks = 0;
p->ticks_cnt = 0;
p->handler_cnt = 0;
p->handler = 0;
}
- 在 kernel/sysproc.c 中添加sys_sigreturn,恢复陷阱帧
kernel/sysproc.c
uint64
sys_sigreturn(void)
{
struct proc *p = myproc();
//恢复陷阱帧
memmove(p->trapframe, p->alarm_trapframe, sizeof(struct trapframe));
// 返回用户态置为0 在内核态其为1时 就不会再调用handler(fn)函数
p->handler_cnt = 0;
return 0;
}
- 执行 alarmtest

test1 test2 通过!!!
5 Lab5: xv6 lazy page allocation
操作系统可以使用页表硬件的技巧之一是延迟分配用户空间堆内存(lazy allocation of user-space heap memory)。Xv6应用程序使用sbrk()系统调用向内核请求堆内存。在我们给出的内核中,sbrk()分配物理内存并将其映射到进程的虚拟地址空间。内核为一个大请求分配和映射内存可能需要很长时间。例如,考虑由262144个4096字节的页组成的千兆字节;即使单独一个页面的分配开销很低,但合起来如此大的分配数量将不可忽视。此外,有些程序申请分配的内存比实际使用的要多(例如,实现稀疏数组),或者为了以后的不时之需而分配内存。为了让sbrk()在这些情况下更快地完成,复杂的内核会延迟分配用户内存。也就是说,sbrk()不分配物理内存,只是记住分配了哪些用户地址,并在用户页表中将这些地址标记为无效。当进程第一次尝试使用延迟分配中给定的页面时,CPU生成一个页面错误(page fault),内核通过分配物理内存、置零并添加映射来处理该错误。您将在这个实验室中向xv6添加这个延迟分配特性。
[!WARNING|label:Attention] 在开始编码之前,请阅读xv6手册的第4章(特别是4.6),以及可能要修改的相关文件:
- kernel/trap.c
- kernel/vm.c
- kernel/sysproc.c
要启动实验,请切换到lazy分支:
$ git fetch
$ git checkout lazy
$ make clean
5.1 前置知识
- 原有逻辑

- 懒分配(lazy allocation)

懒分配的好处:1. 加快sbrk的执行速度。 2. 提高内存利用率。
5.2 Eliminate allocation from sbrk() (easy)
5.2.1 实验要求
[!TIP|label:YOUR JOB] 你的首项任务是删除sbrk(n)系统调用中的页面分配代码(位于sysproc.c中的函数sys_sbrk())。sbrk(n)系统调用将进程的内存大小增加n个字节,然后返回新分配区域的开始部分(即旧的大小)。新的sbrk(n)应该只将进程的大小(myproc()->sz)增加n,然后返回旧的大小。它不应该分配内存——因此您应该删除对growproc()的调用(但是您仍然需要增加进程的大小!)。
试着猜猜这个修改的结果是什么:将会破坏什么?
进行此修改,启动xv6,并在shell中键入echo hi。你应该看到这样的输出:
init: starting sh
$ echo hi
usertrap(): unexpected scause 0x000000000000000f pid=3
sepc=0x0000000000001258 stval=0x0000000000004008
va=0x0000000000004000 pte=0x0000000000000000
panic: uvmunmap: not mapped
“usertrap(): …” 这条消息来自trap.c中的用户陷阱处理程序;它捕获了一个不知道如何处理的异常。请确保您了解发生此页面错误的原因。“stval=0x0…04008”表示导致页面错误的虚拟地址是0x4008。
5.2.2 实验解答
这个实验很简单,就仅仅 kaernel/sysproc.c 改动 sys_sbrk() 函数即可,将实际分配内存的函数删除,而仅仅改变进程的sz属性
kaernel/sysproc.c
uint64
sys_sbrk(void)
{
int addr;
int n;
if(argint(0, &n) < 0)
return -1;
addr = myproc()->sz;
// if(growproc(n) < 0)
// return -1;
myproc()->sz += n;
return addr;
}
输入 echo hi 进行测试:

得到一个page fault。
因为在Shell中执行程序,Shell会先fork一个子进程,子进程会通过exec执行echo。在这个过程中,Shell会申请一些内存,所以Shell会调用sys_sbrk,然后就出错了(注,因为前面修改了代码,调用sys_sbrk不会实际分配所需要的内存)。

- 这里输出了SCAUSE寄存器内容,我们可以看到它的值是15,表明这是一个store page fault(详见8.1)。
- 我们可以看到进程的pid是3,这极可能是Shell的pid。
- 我们还可以看到SEPC寄存器的值,是0x12ac(在用户态中发生错误的程序计数器值)。
- 最后还可以看到出错的虚拟内存地址,也就是STVAL寄存器的内容,是0x4008(xv6中Shel就只分配4k地址,4008就超出4个page分配,发生page fault)。
5.3 Lazy allocation (moderate)
5.3.1 实验要求
[!TIP|label:YOUR JOB] 修改trap.c中的代码以响应来自用户空间的页面错误,方法是新分配一个物理页面并映射到发生错误的地址,然后返回到用户空间,让进程继续执行。您应该在生成“usertrap(): …”消息的printf调用之前添加代码。你可以修改任何其他xv6内核代码,以使echo hi正常工作。
提示:
- 你可以在usertrap() 中查看r_scause() 的返回值是否为13或15来判断该错误是否为页面错误
- stval寄存器中保存了造成页面错误的虚拟地址,你可以通过r_stval() 读取
- 参考vm.c中的uvmalloc() 中的代码,那是一个sbrk() 通过growproc() 调用的函数。你将需要对kalloc() 和mappages() 进行调用
- 使用PGROUNDDOWN(va) 将出错的虚拟地址向下舍入到页面边界
- 当前uvmunmap() 会导致系统panic崩溃;请修改程序保证正常运行
- 如果内核崩溃,请在kernel/kernel.asm中查看sepc
- 使用pgtbl lab 的vmprint 函数打印页表的内容
- 如果您看到错误 incomplete type proc ,请 include“spinlock.h” 然后是 “proc.h”。
如果一切正常,你的 lazy allocation 应该使 echo hi 正常运行。您应该至少有一个页面错误(因为延迟分配),也许有两个。
5.3.2 实验解答
- 修改uvmunmap()(kernel/vm.c) 此函数的功能主要是释放虚拟地址的pte映射,之所以修改这部分代码是因为 lazy allocation 中首先并未实际分配内存,所以当解除映射关系的时候对于这部分内存要略过,而不是使系统崩溃,这部分在课程视频中已经解答。
kernel/vm.c
void
uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)
{
......
for(a = va; a < va + npages*PGSIZE; a += PGSIZE){
if((pte = walk(pagetable, a, 0)) == 0)
panic("uvmunmap: walk");
// PTE_V代表着Valid。如果Valid bit位为1,
// 那么表明这是一条合法的PTE,你可以用它来做地址翻译。
// 然而懒分配,这些页面还未映射,pet不存在
if((*pte & PTE_V) == 0){
// panic("uvmunmap: not mapped");
continue;
}
if(PTE_FLAGS(*pte) == PTE_V)
panic("uvmunmap: not a leaf");
if(do_free){
uint64 pa = PTE2PA(*pte);
kfree((void*)pa);
}
*pte = 0;
}
}
- 在 kernel/trap.c 的 usertrap 的系统陷入中添加对page fault 的处理
kernel/trap.c
void
usertrap(void)
{
......
} else if((which_dev = devintr()) != 0){
// ok
}else if(r_scause() == 15 || r_scause() == 13) { //为13或者15时,就是发生page fault
//获取造成页面错误的虚拟地址
uint64 va = r_stval();
//分配的物理地址
char *pa;
//当发生错误的虚拟地址大于栈地址 且 小于sbrk分配增加后的虚拟地址时
if(PGROUNDUP(p->trapframe->sp)-1 < va && va < p->sz){
//kalloc 分配物理地址需要成功(可能因为内存不够,物理地址分配失败)
if((pa = kalloc())!=0){
//给定进程页表、一个虚拟地址和物理地址,创建一个PTE以实现va到pa相应的映射
if(mappages(p->pagetable,PGROUNDDOWN(va),PGSIZE,(uint64)pa,PTE_R | PTE_W | PTE_X |PTE_U)!=0){
kfree(pa);
p->killed = 1;
}
}else{ //分配物理地址失败 杀死进程
printf("分配物理地址失败!! \n");
p->killed = 1;
}
}else{ //发生page fault的虚拟地址不合法 杀死进程
printf("发生page fault的虚拟地址不合法!! \n");
p->killed = 1;
}
}
测试 echo hi 发现不再报错

5.4 Lazytests and Usertests (moderate)
5.4.1 实验要求
我们为您提供了lazytests,这是一个xv6用户程序,它测试一些可能会给您的惰性内存分配器带来压力的特定情况。修改内核代码,使所有lazytests和usertests都通过。
- 处理sbrk()参数为负的情况。
- 如果某个进程在高于sbrk()分配的任何虚拟内存地址上出现页错误,则终止该进程。
- 在fork()中正确处理父到子内存拷贝。
- 处理这种情形:进程从sbrk()向系统调用(如read或write)传递有效地址,但尚未分配该地址的内存。
- 正确处理内存不足:如果在页面错误处理程序中执行kalloc()失败,则终止当前进程。
- 处理用户栈下面的无效页面上发生的错误。
如果内核通过lazytests和usertests,那么您的解决方案是可以接受的:
$ lazytests
lazytests starting
running test lazy alloc
test lazy alloc: OK
running test lazy unmap...
usertrap(): ...
test lazy unmap: OK
running test out of memory
usertrap(): ...
test out of memory: OK
ALL TESTS PASSED
$ usertests
...
ALL TESTS PASSED
$
5.4.2 实验解答
- 处理 sys_sbrk()(kernel/sysproc.c ) 参数为负数的情况,参考之前sbrk()调用的 growproc(kernel/growproc.c ) 程序,如果为负数,就调用 uvmdealloc() 函数,但需要限制缩减后的内存空间不能小于0
kernel/sysproc.c
uint64
sys_sbrk(void)
{
int addr;
int n;
if(argint(0, &n) < 0)
return -1;
struct proc *p = myproc();
addr = myproc()->sz;
uint64 sz = p->sz;
//当n>0 增加虚拟地址
if(n>0){
p->sz += n;
}else{
//当减小的虚拟地址大于n时 即到grand stack时
if(p->sz + n < 0){
//返回错误
return -1;
}else{ //当减小的虚拟地址小于n时 合法
//解除从 sz 到 sz+n 的pte映射关系
sz = uvmdealloc(p->pagetable, sz ,sz+n);
p->sz = sz;
}
}
return addr;
}
- 在5.3.2节第二步 中 ,对 下面三种都做了处理
- 如果某个进程在高于sbrk()分配的任何虚拟内存地址上出现页错误,则终止该进程。
- 正确处理内存不足:如果在页面错误处理程序中执行kalloc()失败,则终止当前进程。
- 处理用户栈下面的无效页面上发生的错误。
kernel/trap.c
void
usertrap(void)
{
......
} else if((which_dev = devintr()) != 0){
// ok
}else if(r_scause() == 15 || r_scause() == 13) { //为13或者15时,就是发生page fault
//获取造成页面错误的虚拟地址
uint64 va = r_stval();
//分配的物理地址
char *pa;
//当发生错误的虚拟地址大于栈地址 且 小于sbrk分配增加后的虚拟地址时
if(PGROUNDUP(p->trapframe->sp)-1 < va && va < p->sz){
//kalloc 分配物理地址需要成功(可能因为内存不够,物理地址分配失败)
if((pa = kalloc())!=0){
//给定进程页表、一个虚拟地址和物理地址,创建一个PTE以实现va到pa相应的映射
if(mappages(p->pagetable,PGROUNDDOWN(va),PGSIZE,(uint64)pa,PTE_R | PTE_W | PTE_X |PTE_U)!=0){
kfree(pa);
p->killed = 1;
}
}else{ //分配物理地址失败 杀死进程
printf("分配物理地址失败!! \n");
p->killed = 1;
}
}else{ //发生page fault的虚拟地址不合法 杀死进程
//高于sbrk()分配的任何虚拟内存地址
//用户栈下面的**无效页面**上发生的错误
printf("发生page fault的虚拟地址不合法!! \n");
p->killed = 1;
}
}
- 正确处理 fork(kernel/proc.c) 的内存拷贝:fork调用了 uvmcopy(kernel/vm.c) 进行内存拷贝,所以修改 uvmcopy 如下
kernel/vm.c
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
...
for(i = 0; i < sz; i += PGSIZE){
//用walk获取父进程虚拟地址的pte映射 但是lazy情况下可能没有pte映射
//此时直接忽略
if((pte = walk(old, i, 0)) == 0){
// panic("uvmcopy: pte should exist");
continue;
}
//父进程的pte映射因为lazy情况下PTE_V为0
//此时直接忽略
if((*pte & PTE_V) == 0){
// panic("uvmcopy: page not present");
continue;
}
...
}
...
}
- 还需要继续修改uvmunmap(kernel/vm.c),否则会运行出错
kernel/vm.c
void
uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)
{
...
for(a = va; a < va + npages*PGSIZE; a += PGSIZE){
//用walk获取父进程虚拟地址的pte映射 但是lazy情况下可能没有pte映射
//此时直接忽略
if((pte = walk(pagetable, a, 0)) == 0){
// panic("uvmunmap: walk");
continue;
}
// PTE_V代表着Valid。如果Valid bit位为1,
// 那么表明这是一条合法的PTE,你可以用它来做地址翻译。
// 然而懒分配,这些页面还未映射,pet不存在
if((*pte & PTE_V) == 0){
// panic("uvmunmap: not mapped");
continue;
}
...
}
}
- sbrk 申请内存后,但是系统并未分配实际的物理地址给相应的内存,但是可以从 kernel/trap.c 中看到系统调用的处理会先陷入内核 (r_scause() == 8) ,如果此时传入的地址还未实际分配 r_scause() == 15 || r_scause() == 13 代码在其后面,就不能走到上文usertrap中判断scause是13或15后进行内存分配的代码,syscall执行就会失败。以此就需要在系统调用时分配物理地址,保证程序的正确性。

例如可以通过查看 sys_write 的系统调用,可以看到将地址传入系统调用后,会通过 argaddr 函数 (kernel/syscall.c) 从寄存器中读取。我们可以早argaddr 函数中添加虚拟地址到实际物理地址的映射,以此确保系统调用可以正常执行。
(kernel/syscall.c)
int
argaddr(int n, uint64 *ip)
{
//从寄存器读出来的虚拟地址
*ip = argraw(n);
struct proc *p = myproc();
//walkaddr查找虚拟地址,返回物理地址
//如果是0就是没有对应的物理地址
if(walkaddr(p->pagetable,*ip)==0){
//检查虚拟地址的合法性
if(PGROUNDUP(p->trapframe->sp) - 1 < *ip && *ip < p->sz){
char *pa = kalloc();
//没有内存分配物理地址
if(pa == 0)
return -1;
memset(pa,0,PGSIZE);
// 使用mappages创建从虚拟地址ip到物理地址pa的pte映射
if(mappages(p->pagetable,PGROUNDDOWN(*ip),PGSIZE,(uint64)pa,PTE_R | PTE_W | PTE_X | PTE_U)!=0){
kfree(pa);
return -1;
}
}else{
return -1;
}
}
调用 lazytests:

调用 usertests:

==全部通过!!!! ==
6 Lab6 Copy-on-Write Fork for xv6
虚拟内存提供了一定程度的间接寻址:内核可以通过将PTE标记为无效或只读来拦截内存引用,从而导致页面错误,还可以通过修改PTE来更改地址的含义。在计算机系统中有一种说法,任何系统问题都可以用某种程度的抽象方法来解决。Lazy allocation实验中提供了一个例子。这个实验探索了另一个例子:写时复制分支(copy-on write fork)。
在开始本实验前,将仓库切换到cow分支:
$ git fetch
$ git checkout cow
$ make clean
6.1 前置知识
问题:
xv6中的 fork() 系统调用将父进程的所有用户空间内存复制到子进程中。如果父进程较大,则复制可能需要很长时间。更糟糕的是,这项工作经常造成大量浪费;例如,子进程中的 fork() 后跟 exec() 将导致子进程丢弃复制的内存,而其中的大部分可能都从未使用过。另一方面,如果父子进程都使用一个页面,并且其中一个或两个对该页面有写操作,则确实需要复制。
解决方案:
copy-on-write (COW) fork() 的目标是推迟到子进程实际需要物理内存拷贝时再进行分配和复制物理内存页面。
COW fork() 只为子进程创建一个页表,用户内存的PTE指向父进程的物理页 (共享一个物理页) 。COW fork()将父进程和子进程中的所有用户PTE标记为不可写。当任一进程试图写入其中一个COW页时,CPU将强制产生页面错误 (page fault) 。内核页面错误处理程序检测到这种情况将为出错进程分配一页物理内存,将原始页复制到新页中,并修改出错进程中的相关PTE指向新的页面,将PTE标记为可写。当页面错误处理程序返回时,用户进程将能够写入其页面副本。
COW fork() 将使得释放用户内存的物理页面变得更加棘手。给定的物理页可能会被多个进程的页表引用,并且只有在最后一个引用消失时才应该被释放。
6.2 Implement copy-on write (hard)
6.2.1 实验要求
[!TIP|label:YOUR JOB] 您的任务是在xv6内核中实现copy-on-write fork。如果修改后的内核同时成功执行cowtest和usertests程序就完成了。
为了帮助测试你的实现方案,我们提供了一个名为 cowtest 的xv6程序(源代码位于user/cowtest.c)。cowtest运行各种测试,但在未修改的xv6上,即使是第一个测试也会失败。因此,最初您将看到:
$ cowtest
simple: fork() failed
“simple”测试分配超过一半的可用物理内存,然后执行一系列的fork()。fork失败的原因是没有足够的可用物理内存来为子进程提供父进程内存的完整副本。
完成本实验后,内核应该通过 cowtest 和 usertests 中的所有测试。即:
$ cowtest
simple: ok
simple: ok
three: zombie!
ok
three: zombie!
ok
three: zombie!
ok
file: ok
ALL COW TESTS PASSED
$ usertests
...
ALL TESTS PASSED
$
合理的攻克计划:
- 修改 uvmcopy() 将父进程的物理页映射到子进程,而不是分配新页。在子进程和父进程的PTE中清除PTE_W标志(可以写的标志)。
- 修改 usertrap() 以识别页面错误。当COW页面出现页面错误时,使用 kalloc() 分配一个新页面,并将旧页面复制到新页面,然后将新页面添加到PTE中并设置PTE_W。
- 确保每个物理页在最后一个PTE对它的引用撤销时被释放——而不是在此之前。这样做的一个好方法是为每个物理页保留引用该页面的用户页表数的“引用计数”。当 kalloc() 分配页时,将页的引用计数设置为1。当fork导致子进程共享页面时,增加页的引用计数;每当任何进程从其页表中删除页面时,减少页的引用计数。 kfree() 只应在引用计数为零时将页面放回空闲列表。可以将这些计数保存在一个固定大小的整型数组中。你必须制定一个如何索引数组以及如何选择数组大小的方案。例如,您可以用页的物理地址除以4096对数组进行索引,并为数组提供等同于kalloc.c中 kinit() 在空闲列表中放置的所有页面的最高物理地址的元素数。
- 修改copyout()在遇到COW页面时使用与页面错误相同的方案。
提示:
- lazy page allocation实验可能已经让您熟悉了许多与copy-on-write相关的xv6内核代码。但是,您不应该将这个实验室建立在您的lazy allocation解决方案的基础上;相反,请按照上面的说明从一个新的xv6开始。
- 有一种可能很有用的方法来记录每个PTE是否是COW映射。您可以使用RISC-V PTE中的RSW(reserved for software,即为软件保留的)位来实现此目的
- usertests 检查 cowtest 不测试的场景,所以别忘两个测试都需要完全通过。
- kernel/riscv.h 的末尾有一些有用的宏和页表标志位的定义。
- 如果出现COW页面错误并且没有可用内存,则应终止进程
6.2.2 实验解答
- 在kernel/riscv.h中选取PTE中的保留位定义标记一个页面是否为COW Fork页面的标志位
kernel/riscv.h
......
#define PTE_X (1L << 3)
#define PTE_U (1L << 4) // 1 -> user can access
// 记录应用了COW策略后fork的页面
#define PTE_F (1L << 8) // 标志位 标志着是否为写时复制
-
在kernel/kalloc.c中进行如下修改
-
定义引用计数的全局变量 ref,其中包含了一个自旋锁和一个引用计数数组,由于ref是全局变量,会被自动初始化为全0。
这里使用自旋锁是考虑到这种情况:进程P1和P2共用内存M,M引用计数为2,此时CPU1要执行fork产生P1的子进程,CPU2要终止P2,那么假设两个CPU同时读取引用计数为2,执行完成后CPU1中保存的引用计数为3,CPU2保存的计数为1,那么后赋值的语句会覆盖掉先赋值的语句,从而产生错误
kernel/kalloc.c struct ref_stru { struct spinlock lock; //引用计数数组 数组每个位置代表一个页面的引用次数 int cnt[PHYSTOP/PGSIZE]; } ref;- 在kinit函数中初始化ref的自旋锁
kernel/kalloc.c void kinit() { // 初始化ref中的自旋锁 initlock(&ref.lock,"ref"); initlock(&kmem.lock, "kmem"); freerange(end, (void*)PHYSTOP); }- 修改kalloc和kfree函数,在kalloc中初始化内存引用计数为1,在kfree函数中对内存引用计数减1,如果引用计数为0时才真正删除
kernel/kalloc.c // Free the page of physical memory pointed at by v, // which normally should have been returned by a // call to kalloc(). (The exception is when // initializing the allocator; see kinit above.) void kfree(void *pa) { struct run *r; if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP) panic("kfree"); //只有当引用计数为0时才回收空间 //否则只是引用计数减1 acquire(&ref.lock); // 检测物理地址pa的引用计数是否为0 if(--ref.cnt[(uint64)pa / PGSIZE]==0){ release(&ref.lock); r = (struct run*)pa; // Fill with junk to catch dangling refs. memset(pa, 1, PGSIZE); acquire(&kmem.lock); r->next = kmem.freelist; kmem.freelist = r; release(&kmem.lock); }else{ // 如果计数不为0 减1 release(&ref.lock); } } // Allocate one 4096-byte page of physical memory. // Returns a pointer that the kernel can use. // Returns 0 if the memory cannot be allocated. void * kalloc(void) { struct run *r; acquire(&kmem.lock); r = kmem.freelist; if(r){ kmem.freelist = r->next; acquire(&ref.lock); // 初始化 将分配的物理地址r(在空闲列表中取下来的) // 进行计数初始化为1 ref.cnt[(uint64)r / PGSIZE] = 1; release(&ref.lock); } release(&kmem.lock); if(r) memset((char*)r, 5, PGSIZE); // fill with junk return (void*)r; }- 添加如下四个函数,详细说明已在注释中,这些函数中用到了walk,记得在defs.h中添加声明,最后也需要将这些函数的声明添加到defs.h,在cowalloc中,读取内存引用计数,如果为1,说明只有当前进程引用了该物理内存(其他进程此前已经被分配到了其他物理页面),就只需要改变PTE使能PTE_W;否则就分配物理页面,并将原来的内存引用计数减1。该函数需要返回物理地址,这将在copyout中使用到。
kernel/kalloc.c /** * @brief cowpage 判断一个页面是否为COW的fork页面 * @param pagetable 指定查询的页表 * @param va 虚拟地址 * @return 0 是 -1 不是 */ int cowpage(pagetable_t pagetable,uint64 va){ if(va >= MAXVA){ return -1; } pte_t* pte = walk(pagetable,va,0); if(pte == 0){ return -1; } // 是否为valid的页面 if((*pte & PTE_V)==0){ return -1; } // 0 是 -1 不是 return (*pte & PTE_F ? 0 : -1); } /** * @brief cowalloc copy-on-write分配器 * @param pagetable 指定页表 * @param va 指定的虚拟地址,必须页面对齐 * @return 分配后va对应的物理地址,如果返回0则分配失败 */ void* cowalloc(pagetable_t pagetable,uint64 va){ //虚拟地址是否页面对齐 if(va % PGSIZE != 0) return 0; // 获取va对应的物理地址 uint64 pa = walkaddr(pagetable,va); if(pa == 0) return 0; // 获取对应的PTE pte_t *pte = walk(pagetable,va,0); //只有一个进程对此物理地址存在引用 if(krefcnt((char*)pa) == 1){ *pte |= PTE_W; // 该PTE设置为可写 *pte &= ~PTE_F; // 该PTE设置为不是cowfork页面 return (void*) pa; }else{ //多个进程对此页面存在引用 //需要重新分配新的页面,并拷贝旧页面的内容 char *mem = kalloc(); if(mem == 0){ return 0; } //复制旧页面内容到新页面 memmove(mem,(char*)pa,PGSIZE); // 清除PTE_V,否则在mappagges中会判定为remap *pte &= ~PTE_V; //为新页面添加映射 增加读权限和取消cowfork标志 if(mappages(pagetable,va,PGSIZE,(uint64)mem,(PTE_FLAGS(*pte) | PTE_W) & ~PTE_F)!=0){ kfree(mem); *pte |= PTE_V; return 0; } // 将原来的物理内存引用计数减1 kfree((char*)PGROUNDDOWN(pa)); return mem; } } /** * @brief krefcnt 获取内存的引用计数 * @param pa 指定的内存地址 * @return 引用计数 */ int krefcnt(void *pa){ return ref.cnt[(uint64)pa / PGSIZE]; } /** * @brief kaddrefcnt 增加内存的引用计数 * @param pa 指定的内存地址 * @return 0:成功 -1:失败 */ int kaddrefcnt(void* pa){ //判断pa是否合法 // 1 页面是否对齐 2 页面是否大于物理地址起点 // 3 页面是否小于物理地址终点 if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP){ return -1; } acquire(&ref.lock); ++ref.cnt[(uint64)pa / PGSIZE]; release(&ref.lock); return 0; }kernel/defs.h // kalloc.c void* kalloc(void); void kfree(void *); void kinit(void); int cowpage(pagetable_t, uint64);//判断一个页面是否为COW的fork页面 void* cowalloc(pagetable_t, uint64);//copy-on-write分配器 int krefcnt(void *);//获取内存的引用计数 int kaddrefcnt(void *);//增加内存的引用计数 ...... // vm.c ...... int copyinstr(pagetable_t, char *, uint64, uint64); pte_t* walk(pagetable_t, uint64, int);// 在defs.h上注册一下,使得walk函数全局有效- 修改freerange,在kfree中将会对cnt[]减1,这里要先设为1(在初始化时设置为1),否则就会减成负数
kernel/kalloc.c void freerange(void *pa_start, void *pa_end) { char *p; p = (char*)PGROUNDUP((uint64)pa_start); for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE){ // 在kfree中将会对cnt[]减1,这里要先设为1,否则就会减成负数 ref.cnt[(uint64)p / PGSIZE] = 1; kfree(p); } -
-
修改kernel/vm.c 下的uvmcopy,不为子进程分配内存,而是使父子进程共享内存,但禁用PTE_W,同时标记PTE_F,记得调用kaddrefcnt增加引用计数
kernel/vm.c
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
// char *mem;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
// 仅对可写页面设置COW标记
if(flags & PTE_W){
// 禁用写并设置COW Fork标记
flags = (flags | PTE_F) & ~PTE_W;
*pte = PA2PTE(pa) | flags;
}
if(mappages(new,i,PGSIZE,pa,flags)!=0){
uvmunmap(new,0,i/PGSIZE,1);
return -1;
}
//增加内存的引用计数
kaddrefcnt((char*)pa);
}
return 0;
}
- 修改kernel/trap.c 下的usertrap,处理页面错误
kernel/trap.c
void
usertrap(void)
{
......
if(r_scause() == 8){
// system call
if(p->killed)
exit(-1);
// sepc points to the ecall instruction,
// but we want to return to the next instruction.
p->trapframe->epc += 4;
// an interrupt will change sstatus &c registers,
// so don't enable until done with those registers.
intr_on();
syscall();
} else if((which_dev = devintr()) != 0){
// ok
} else if(r_scause() == 13 || r_scause() == 15){ //通过pagefault实现COW
uint64 fault_va = r_stval(); // 获取出错的虚拟地址
//先判断虚拟地址va是否合法
// 再通过cowpage判断va是否为COW页面
// 再通过cowalloc为va分配单独的物理地址
if(fault_va >= p->sz
|| cowpage(p->pagetable,fault_va)!=0
|| cowalloc(p->pagetable,PGROUNDDOWN(fault_va))==0){
p->killed = 1;
}
} else {
......
}
- 在copyout中处理相同的情况,如果是COW页面,需要更换pa0指向的物理地址
kernel/vm.c
// Copy from kernel to user.
// Copy len bytes from src to virtual address dstva in a given page table.
// Return 0 on success, -1 on error.
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
while(len > 0){
va0 = PGROUNDDOWN(dstva);
pa0 = walkaddr(pagetable, va0);
// 处理COW页面的情况
if(cowpage(pagetable,va0)==0){
// 处理COW页面的情况
pa0 = (uint64)cowalloc(pagetable,va0);
}
if(pa0 == 0)
return -1;
n = PGSIZE - (dstva - va0);
if(n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}
分别 测试 cowtest 和 usertests :

测试通过!!!
7 Lab7 : Multithreading
本实验将使您熟悉多线程。您将在用户级线程包中实现线程之间的切换,使用多个线程来加速程序,并实现一个屏障。
[!WARNING|label:Attention] 在编写代码之前,您应该确保已经阅读了xv6手册中的“第7章: 调度”,并研究了相应的代码。
要启动实验,请切换到thread分支:
$ git fetch
$ git checkout thread
$ make clean
7.1 前置知识
7.2 Uthread: switching between threads (moderate)
7.2.1 实验要求
在本练习中,您将为用户级线程系统设计上下文切换机制,然后实现它。为了让您开始,您的xv6有两个文件:user/uthread.c和user/uthread_switch.S,以及一个规则:运行在Makefile中以构建uthread程序。uthread.c包含大多数用户级线程包,以及三个简单测试线程的代码。线程包缺少一些用于创建线程和在线程之间切换的代码。
[!TIP|label:YOUR JOB] 您的工作是提出一个创建线程和保存/恢复寄存器以在线程之间切换的计划,并实现该计划。完成后,make grade应该表明您的解决方案通过了uthread测试。
完成后,在xv6上运行uthread时应该会看到以下输出(三个线程可能以不同的顺序启动):
$ make qemu
...
$ uthread
thread_a started
thread_b started
thread_c started
thread_c 0
thread_a 0
thread_b 0
...
thread_c 99
thread_a 99
thread_b 99
thread_c: exit after 100
thread_a: exit after 100
thread_b: exit after 100
thread_schedule: no runnable threads
$
该输出来自三个测试线程,每个线程都有一个循环,该循环打印一行,然后将CPU让出给其他线程。
然而在此时还没有上下文切换的代码,您将看不到任何输出。
您需要将代码添加到 user/uthread.c 中的 thread_create() 和thread_schedule(),以及user/uthread_switch.S中的thread_switch。一个目标是确保当thread_schedule()第一次运行给定线程时,该线程在自己的栈上执行传递给thread_create()的函数。另一个目标是确保thread_switch保存被切换线程的寄存器,恢复切换到线程的寄存器,并返回到后一个线程指令中最后停止的点。您必须决定保存/恢复寄存器的位置;修改struct thread以保存寄存器是一个很好的计划。您需要在thread_schedule中添加对thread_switch的调用;您可以将需要的任何参数传递给thread_switch,但目的是将线程从t切换到next_thread。
提示:
-
thread_switch只需要保存/还原被调用方保存的寄存器(callee-save register,参见LEC5使用的文档《Calling Convention》)。为什么?
-
您可以在user/uthread.asm中看到uthread的汇编代码,这对于调试可能很方便。
-
这可能对于测试你的代码很有用,使用riscv64-linux-gnu-gdb的单步调试通过你的thread_switch,你可以按这种方法开始:
(gdb) file user/_uthread Reading symbols from user/_uthread... (gdb) b uthread.c:60这将在uthread.c的第60行设置断点。断点可能会(也可能不会)在运行uthread之前触发。为什么会出现这种情况?
一旦您的xv6 shell运行,键入“uthread”,gdb将在第60行停止。现在您可以键入如下命令来检查uthread的状态:
(gdb) p/x *next_thread
使用“x”,您可以检查内存位置的内容:
(gdb) x/x next_thread->stack
您可以跳到thread_switch 的开头,如下:
(gdb) b thread_switch
(gdb) c
您可以使用以下方法单步执行汇编指令:
(gdb) si
7.2.2 实验解答
本实验是在给定的代码基础上实现用户级线程切换,相比于XV6中实现的内核级线程,这个要简单许多。因为是用户级线程,不需要设计用户栈和内核栈,用户页表和内核页表等等切换,所以本实验中只需要一个类似于 context 的结构,而不需要费尽心机的维护 trapframe
-
在 user/uthread.c 定义存储上下文的结构体 tcontext
user/uthread.c // 用户线程的上下文结构体 struct tcontext { uint64 ra; uint64 sp; // callee-saved uint64 s0; uint64 s1; uint64 s2; uint64 s3; uint64 s4; uint64 s5; uint64 s6; uint64 s7; uint64 s8; uint64 s9; uint64 s10; uint64 s11; }; -
在 user/uthread.c 修改thread结构体,添加context字段
struct thread { char stack[STACK_SIZE]; /* the thread's stack */ int state; /* FREE, RUNNING, RUNNABLE */ struct tcontext context; // 用户线程的上下文 }; -
模仿kernel/swtch.S,在user/uthread_switch.S中写入如下代码
.text /* * save the old thread's registers, * restore the new thread's registers. */ .globl thread_switch thread_switch: /* YOUR CODE HERE */ sd ra, 0(a0) sd sp, 8(a0) sd s0, 16(a0) sd s1, 24(a0) sd s2, 32(a0) sd s3, 40(a0) sd s4, 48(a0) sd s5, 56(a0) sd s6, 64(a0) sd s7, 72(a0) sd s8, 80(a0) sd s9, 88(a0) sd s10, 96(a0) sd s11, 104(a0) ld ra, 0(a1) ld sp, 8(a1) ld s0, 16(a1) ld s1, 24(a1) ld s2, 32(a1) ld s3, 40(a1) ld s4, 48(a1) ld s5, 56(a1) ld s6, 64(a1) ld s7, 72(a1) ld s8, 80(a1) ld s9, 88(a1) ld s10, 96(a1) ld s11, 104(a1) ret /* return to ra */ -
在 user/uthread.c 修改 thread_scheduler ,添加线程切换语句
user/uthread.c ... if (current_thread != next_thread) { /* switch threads? */ ... /* YOUR CODE HERE */ thread_switch((uint64)&t->context, (uint64)¤t_thread->context); } else next_thread = 0; -
在 user/uthread.c 的 thread_create 中对 thread 结构体做一些初始化设定,主要是ra返回地址和sp栈指针,其他的都不重要
user/uthread.c void thread_create(void (*func)()) { struct thread *t; for (t = all_thread; t < all_thread + MAX_THREAD; t++) { if (t->state == FREE) break; } t->state = RUNNABLE; // YOUR CODE HERE t->context.ra = (uint64)func; // 设定函数返回地址 t->context.sp = (uint64)t->stack+STACK_SIZE; // 设定栈指针 }
7.3 Using threads (moderate)
7.3.1 实验要求
在本作业中,您将探索使用哈希表的线程和锁的并行编程。您应该在具有多个内核的真实Linux或MacOS计算机(不是xv6,不是qemu)上执行此任务。最新的笔记本电脑都有多核处理器。
这个作业使用UNIX的pthread线程库。您可以使用man pthreads在手册页面上找到关于它的信息,您可以在web上查看,例如这里、这里和这里。
文件 notxv6/ph.c 包含一个简单的哈希表,如果单个线程使用,该哈希表是正确的,但是多个线程使用时,该哈希表是不正确的。在您的xv6主目录(可能是 ~/xv6-labs-2020 )中,键入以下内容:
$ make ph
$ ./ph 1
请注意,要构建ph,Makefile使用操作系统的gcc,而不是6.S081的工具。ph的参数指定在哈希表上执行put和get操作的线程数。运行一段时间后,ph 1将产生与以下类似的输出:
100000 puts, 3.991 seconds, 25056 puts/second
0: 0 keys missing
100000 gets, 3.981 seconds, 25118 gets/second
您看到的数字可能与此示例输出的数字相差两倍或更多,这取决于您计算机的速度、是否有多个核心以及是否正在忙于做其他事情。
ph运行两个基准程序。首先,它通过调用put()将许多键添加到哈希表中,并以每秒为单位打印puts的接收速率。之后它使用get()从哈希表中获取键。它打印由于puts而应该在哈希表中但丢失的键的数量(在本例中为0),并以每秒为单位打印gets的接收数量。
通过给ph一个大于1的参数,可以告诉它同时从多个线程使用其哈希表。试试ph 2:
$ ./ph 2
100000 puts, 1.885 seconds, 53044 puts/second
1: 16579 keys missing
0: 16579 keys missing
200000 gets, 4.322 seconds, 46274 gets/second
这个ph 2输出的第一行表明,当两个线程同时向哈希表添加条目时,它们达到每秒53044次插入的总速率。这大约是运行ph 1的单线程速度的两倍。这是一个优秀的“并行加速”,大约达到了人们希望的2倍(即两倍数量的核心每单位时间产出两倍的工作)。
然而,声明16579 keys missing的两行表示散列表中本应存在的大量键不存在。也就是说,puts应该将这些键添加到哈希表中,但出现了一些问题。请看一下notxv6/ph.c,特别是 put() 和 insert() 。
[!TIP|label:YOUR JOB] 为什么两个线程都丢失了键,而不是一个线程?确定可能导致键丢失的具有2个线程的事件序列。在answers-thread.txt中提交您的序列和简短解释。
[!TIP] 为了避免这种事件序列,请在notxv6/ph.c中的put和get中插入lock和unlock语句,以便在两个线程中丢失的键数始终为0。相关的pthread调用包括:
pthread_mutex_t lock; // declare a lock
pthread_mutex_init(&lock, NULL); // initialize the lock
pthread_mutex_lock(&lock); // acquire lock
pthread_mutex_unlock(&lock); // release lock
当make grade说您的代码通过ph_safe测试时,您就完成了,该测试需要两个线程的键缺失数为0。在此时,ph_fast测试失败是正常的。
不要忘记调用 pthread_mutex_init()。首先用1个线程测试代码,然后用2个线程测试代码。您主要需要测试:程序运行是否正确呢(即,您是否消除了丢失的键?)?与单线程版本相比,双线程版本是否实现了并行加速(即单位时间内的工作量更多)?
在某些情况下,并发put()在哈希表中读取或写入的内存中没有重叠,因此不需要锁来相互保护。您能否更改ph.c以利用这种情况为某些put()获得并行加速?提示:每个散列桶加一个锁怎么样?
[!TIP|label:YOUR JOB] 修改代码,使某些put操作在保持正确性的同时并行运行。当make grade说你的代码通过了ph_safe和ph_fast测试时,你就完成了。ph_fast测试要求两个线程每秒产生的put数至少是一个线程的1.25倍。
7.3.2 实验解答
来看一下程序的运行过程:设定了五个散列桶,根据键除以5的余数决定插入到哪一个散列桶中,插入方法是头插法.
为什么为造成数据丢失:
假设现在有两个线程T1和T2,两个线程都走到put函数,且假设两个线程中key%NBUCKET相等,即要插入同一个散列桶中。两个线程同时调用insert(key, value, &table[i], table[i]),insert是通过头插法实现的。如果先insert的线程还未返回另一个线程就开始insert,那么前面的数据会被覆盖
因此只需要对插入操作上锁即可.
- 为每个散列桶定义一个锁,将五个锁放在一个数组中,并进行初始化
user/ph.c
pthread_mutex_t lock[NBUCKET] = { PTHREAD_MUTEX_INITIALIZER }; // 每个散列桶一把锁
- 在 put 函数中对 insert 上锁
if(e){
// update the existing key.
e->value = value;
} else {
pthread_mutex_lock(&lock[i]);
// the new is new.
insert(key, value, &table[i], table[i]);
pthread_mutex_unlock(&lock[i]);
}
运行:

7.4 Barrier(moderate)
7.4.1 实验要求
在本作业中,您将实现一个屏障**(Barrier)**:应用程序中的一个点,所有参与的线程在此点上必须等待,直到所有其他参与线程也达到该点。您将使用pthread条件变量,这是一种序列协调技术,类似于xv6的sleep和wakeup。
您应该在真正的计算机(不是xv6,不是qemu)上完成此任务。
文件notxv6/barrier.c包含一个残缺的屏障实现。
$ make barrier
$ ./barrier 2
barrier: notxv6/barrier.c:42: thread: Assertion `i == t' failed.
2指定在屏障上同步的线程数(barrier.c中的nthread)。每个线程执行一个循环。在每次循环迭代中,线程都会调用barrier(),然后以随机微秒数休眠。如果一个线程在另一个线程到达屏障之前离开屏障将触发断言(assert)。期望的行为是每个线程在barrier()中阻塞,直到nthreads的所有线程都调用了barrier()。
[!TIP|label:YOUR JOB] 您的目标是实现期望的屏障行为。除了在ph作业中看到的lock原语外,还需要以下新的pthread原语;详情请看这里和这里。
// 在cond上进入睡眠,释放锁mutex,在醒来时重新获取
pthread_cond_wait(&cond, &mutex);
// 唤醒睡在cond的所有线程
pthread_cond_broadcast(&cond);
确保您的方案通过make grade的barrier测试。
pthread_cond_wait在调用时释放mutex,并在返回前重新获取mutex。
我们已经为您提供了barrier_init()。您的工作是实现barrier(),这样panic就不会发生。我们为您定义了struct barrier;它的字段供您使用。
有两个问题使您的任务变得复杂:
- 你必须处理一系列的barrier调用,我们称每一连串的调用为一轮(round)。bstate.round记录当前轮数。每次当所有线程都到达屏障时,都应增加bstate.round。
- 您必须处理这样的情况:一个线程在其他线程退出barrier之前进入了下一轮循环。特别是,您在前后两轮中重复使用bstate.nthread变量。确保在前一轮仍在使用bstate.nthread时,离开barrier并循环运行的线程不会增加bstate.nthread。
使用一个、两个和两个以上的线程测试代码。
7.4.2 实验解答
保证下一个round的操作不会影响到上一个还未结束的round中的数据就可
user/barrier
#include 8 Lab8: locks
在本实验中,您将获得重新设计代码以提高并行性的经验。多核机器上并行性差的一个常见症状是频繁的锁争用。提高并行性通常涉及更改数据结构和锁定策略以减少争用。您将对xv6内存分配器和块缓存执行此操作。
[!WARNING|label:Attention] 在编写代码之前,请确保阅读xv6手册中的以下部分:
- 第6章:《锁》和相应的代码。
- 第3.5节:《代码:物理内存分配》
- 第8.1节至第8.3节:《概述》、《Buffer cache层》和《代码:Buffer cache》
要开始本实验,请将代码切换到lock分支:
$ git fetch
$ git checkout lock
$ make clean
8.1 Memory allocator(moderate)
8.1.1 实验要求
程序user/kalloctest.c强调了xv6的内存分配器:三个进程增长和缩小地址空间,导致对kalloc和kfree的多次调用。kalloc和kfree获得kmem.lock。kalloctest打印(作为“#fetch-and-add”)在acquire中由于尝试获取另一个内核已经持有的锁而进行的循环迭代次数,如kmem锁和一些其他锁。acquire中的循环迭代次数是锁争用的粗略度量。完成实验前,kalloctest的输出与此类似:
$ kalloctest
start test1
test1 results:
--- lock kmem/bcache stats
lock: kmem: #fetch-and-add 83375 #acquire() 433015
lock: bcache: #fetch-and-add 0 #acquire() 1260
--- top 5 contended locks:
lock: kmem: #fetch-and-add 83375 #acquire() 433015
lock: proc: #fetch-and-add 23737 #acquire() 130718
lock: virtio_disk: #fetch-and-add 11159 #acquire() 114
lock: proc: #fetch-and-add 5937 #acquire() 130786
lock: proc: #fetch-and-add 4080 #acquire() 130786
tot= 83375
test1 FAIL
acquire为每个锁维护要获取该锁的acquire调用计数,以及acquire中循环尝试但未能设置锁的次数。kalloctest调用一个系统调用,使内核打印kmem和bcache锁(这是本实验的重点)以及5个最有具竞争的锁的计数。如果存在锁争用,则acquire循环迭代的次数将很大。系统调用返回kmem和bcache锁的循环迭代次数之和。
对于本实验,您必须使用具有多个内核的专用空载机器。如果你使用一台正在做其他事情的机器,kalloctest打印的计数将毫无意义。你可以使用专用的Athena 工作站或你自己的笔记本电脑,但不要使用拨号机。
kalloctest中锁争用的根本原因是kalloc()有一个空闲列表,由一个锁保护。要消除锁争用,您必须重新设计内存分配器,以避免使用单个锁和列表。基本思想是为每个CPU维护一个空闲列表,每个列表都有自己的锁。因为每个CPU将在不同的列表上运行,不同CPU上的分配和释放可以并行运行。主要的挑战将是处理一个CPU的空闲列表为空,而另一个CPU的列表有空闲内存的情况;在这种情况下,一个CPU必须“窃取”另一个CPU空闲列表的一部分。窃取可能会引入锁争用,但这种情况希望不会经常发生。
[!TIP|label:YOUR JOB] 您的工作是实现每个CPU的空闲列表,并在CPU的空闲列表为空时进行窃取。所有锁的命名必须以“kmem”开头。也就是说,您应该为每个锁调用initlock,并传递一个以“kmem”开头的名称。运行kalloctest以查看您的实现是否减少了锁争用。要检查它是否仍然可以分配所有内存,请运行usertests sbrkmuch。您的输出将与下面所示的类似,在kmem锁上的争用总数将大大减少,尽管具体的数字会有所不同。确保usertests中的所有测试都通过。评分应该表明考试通过。
$ kalloctest
start test1
test1 results:
--- lock kmem/bcache stats
lock: kmem: #fetch-and-add 0 #acquire() 42843
lock: kmem: #fetch-and-add 0 #acquire() 198674
lock: kmem: #fetch-and-add 0 #acquire() 191534
lock: bcache: #fetch-and-add 0 #acquire() 1242
--- top 5 contended locks:
lock: proc: #fetch-and-add 43861 #acquire() 117281
lock: virtio_disk: #fetch-and-add 5347 #acquire() 114
lock: proc: #fetch-and-add 4856 #acquire() 117312
lock: proc: #fetch-and-add 4168 #acquire() 117316
lock: proc: #fetch-and-add 2797 #acquire() 117266
tot= 0
test1 OK
start test2
total free number of pages: 32499 (out of 32768)
.....
test2 OK
$ usertests sbrkmuch
usertests starting
test sbrkmuch: OK
ALL TESTS PASSED
$ usertests
...
ALL TESTS PASSED
$
提示:
- 您可以使用kernel/param.h中的常量NCPU
- 让freerange将所有可用内存分配给运行freerange的CPU。
- 函数cpuid返回当前的核心编号,但只有在中断关闭时调用它并使用其结果才是安全的。您应该使用push_off()和pop_off()来关闭和打开中断。
- 看看kernel/sprintf.c中的snprintf函数,了解字符串如何进行格式化。尽管可以将所有锁命名为“kmem”。
8.1.2 实验解答
本实验完成的任务是为每个CPU都维护一个空闲列表,初始时将所有的空闲内存分配到某个CPU,此后各个CPU需要内存时,如果当前CPU的空闲列表上没有,则窃取其他CPU的。例如,所有的空闲内存初始分配到CPU0,当CPU1需要内存时就会窃取CPU0的,而使用完成后就挂在CPU1的空闲列表,此后CPU1再次需要内存时就可以从自己的空闲列表中取。
- 在 kernel/kalloc.c 将kmem定义为一个数组,包含NCPU个元素,即每个CPU对应一个
kernel/kalloc.c
//将kmem定义为一个数组,包含NCPU个元素,即每个CPU对应一个
struct {
struct spinlock lock;
struct run *freelist;
} kmem[NCPU];
- 在 kernel/kalloc.c 修改kinit,为所有锁初始化以“kmem”开头的名称(使用snprintf()函数),该函数只会被一个CPU调用,freerange调用kfree将所有空闲内存挂在该CPU的空闲列表上
kernel/kalloc.c
void
kinit()
{
char lockname[8];
for(int i=0;i < NCPU; i++){
// 将每个cpu锁的名字格式化为kmem_i
snprintf(lockname,sizeof(lockname),"kmem_%d",i);
// 初始化每个cpu的锁
initlock(&kmem[i].lock,lockname);
}
freerange(end, (void*)PHYSTOP);
}
- 修改kfree,使用cpuid()和它返回的结果时必须关中断,请参考《XV6使用手册》第7.4节
kernel/kalloc.c
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
push_off(); // 关中断
//函数cpuid返回当前的核心编号,但只有在中断关闭时调用它并使用其结果才是安全的
int id = cpuid();
acquire(&kmem[id].lock);
r->next = kmem[id].freelist;
kmem[id].freelist = r;
release(&kmem[id].lock);
pop_off(); // 开中断
}
- 修改kalloc,使得在当前CPU的空闲列表没有可分配内存时窃取其他内存的
kernel/kalloc.c
//使得在当前CPU的空闲列表没有可分配内存时窃取其他内存的
void *
kalloc(void)
{
struct run *r;
push_off();
int id = cpuid();
acquire(&kmem[id].lock);
r = kmem[id].freelist;
// 如果当前cpu有空闲内存 直接使用
if(r)
kmem[id].freelist = r->next;
// 如果当前cpu没有空闲内存 窃取其他cpu的内存
else{
int antid;
//遍历所有cpu的空闲列表
for(antid=0;antid<NCPU;antid++){
if(antid == id)
continue;
acquire(&kmem[antid].lock);
r = kmem[antid].freelist;
if(r){
// 将另一个cpu的内存空间赋值给r
kmem[antid].freelist = r->next;
release(&kmem[antid].lock);
break;
}
release(&kmem[antid].lock);
}
}
release(&kmem[id].lock);
pop_off(); //开中断
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
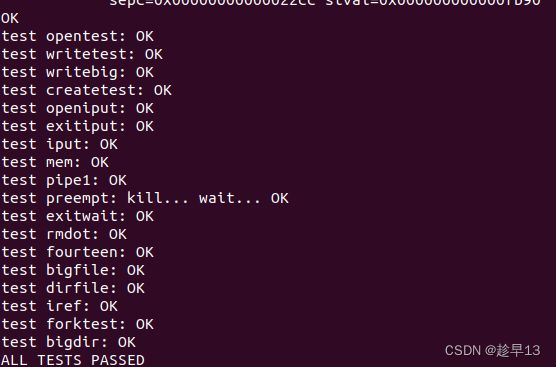
测试:
8.2 Buffer cache(hard)
前置课程
https://mit-public-courses-cn-translatio.gitbook.io/mit6-s081/lec14-file-systems-frans/14.7-sleep-lock
8.2.1 实验要求
如果多个进程密集地使用文件系统,它们可能会争夺bcache.lock,它保护kernel/bio.c中的磁盘块缓存。bcachetest创建多个进程,这些进程重复读取不同的文件,以便在bcache.lock上生成争用;(在完成本实验之前)其输出如下所示:
$ bcachetest
start test0
test0 results:
--- lock kmem/bcache stats
lock: kmem: #fetch-and-add 0 #acquire() 33035
lock: bcache: #fetch-and-add 16142 #acquire() 65978
--- top 5 contended locks:
lock: virtio_disk: #fetch-and-add 162870 #acquire() 1188
lock: proc: #fetch-and-add 51936 #acquire() 73732
lock: bcache: #fetch-and-add 16142 #acquire() 65978
lock: uart: #fetch-and-add 7505 #acquire() 117
lock: proc: #fetch-and-add 6937 #acquire() 73420
tot= 16142
test0: FAIL
start test1
test1 OK
您可能会看到不同的输出,但bcache锁的acquire循环迭代次数将很高。如果查看kernel/bio.c中的代码,您将看到bcache.lock保护已缓存的块缓冲区的列表、每个块缓冲区中的引用计数(b->refcnt)以及缓存块的标识(b->dev和b->blockno)。
[!TIP|label:YOUR JOB] 修改块缓存,以便在运行bcachetest时,bcache(buffer cache的缩写)中所有锁的acquire循环迭代次数接近于零。理想情况下,块缓存中涉及的所有锁的计数总和应为零,但只要总和小于500就可以。修改bget和brelse,以便bcache中不同块的并发查找和释放不太可能在锁上发生冲突(例如,不必全部等待bcache.lock)。你必须保护每个块最多缓存一个副本的不变量。完成后,您的输出应该与下面显示的类似(尽管不完全相同)。确保usertests仍然通过。完成后,make grade应该通过所有测试。
$ bcachetest
start test0
test0 results:
--- lock kmem/bcache stats
lock: kmem: #fetch-and-add 0 #acquire() 32954
lock: kmem: #fetch-and-add 0 #acquire() 75
lock: kmem: #fetch-and-add 0 #acquire() 73
lock: bcache: #fetch-and-add 0 #acquire() 85
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4159
lock: bcache.bucket: #fetch-and-add 0 #acquire() 2118
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4274
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4326
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6334
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6321
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6704
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6696
lock: bcache.bucket: #fetch-and-add 0 #acquire() 7757
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6199
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4136
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4136
lock: bcache.bucket: #fetch-and-add 0 #acquire() 2123
--- top 5 contended locks:
lock: virtio_disk: #fetch-and-add 158235 #acquire() 1193
lock: proc: #fetch-and-add 117563 #acquire() 3708493
lock: proc: #fetch-and-add 65921 #acquire() 3710254
lock: proc: #fetch-and-add 44090 #acquire() 3708607
lock: proc: #fetch-and-add 43252 #acquire() 3708521
tot= 128
test0: OK
start test1
test1 OK
$ usertests
...
ALL TESTS PASSED
$
请将你所有的锁以“bcache”开头进行命名。也就是说,您应该为每个锁调用initlock,并传递一个以“bcache”开头的名称。
减少块缓存中的争用比kalloc更复杂,因为bcache缓冲区真正的在进程(以及CPU)之间共享。对于kalloc,可以通过给每个CPU设置自己的分配器来消除大部分争用;这对块缓存不起作用。我们建议您使用每个哈希桶都有一个锁的哈希表在缓存中查找块号。
在您的解决方案中,以下是一些存在锁冲突但可以接受的情形:
- 当两个进程同时使用相同的块号时。bcachetest test0始终不会这样做。
- 当两个进程同时在cache中未命中时,需要找到一个未使用的块进行替换。bcachetest test0始终不会这样做。
- 在你用来划分块和锁的方案中某些块可能会发生冲突,当两个进程同时使用冲突的块时。例如,如果两个进程使用的块,其块号散列到哈希表中相同的槽。bcachetest test0可能会执行此操作,具体取决于您的设计,但您应该尝试调整方案的细节以避免冲突(例如,更改哈希表的大小)。
bcachetest的test1使用的块比缓冲区更多,并且执行大量文件系统代码路径。
提示:
- 请阅读xv6手册中对块缓存的描述(第8.1-8.3节)。
- 可以使用固定数量的散列桶,而不动态调整哈希表的大小。使用素数个存储桶(例如13)来降低散列冲突的可能性。
- 在哈希表中搜索缓冲区并在找不到缓冲区时为该缓冲区分配条目必须是原子的。
- 删除保存了所有缓冲区的列表(bcache.head等),改为标记上次使用时间的时间戳缓冲区(即使用kernel/trap.c中的ticks)。通过此更改,brelse不需要获取bcache锁,并且bget可以根据时间戳选择最近使用最少的块。
- 可以在bget中串行化回收(即bget中的一部分:当缓存中的查找未命中时,它选择要复用的缓冲区)。
- 在某些情况下,您的解决方案可能需要持有两个锁;例如,在回收过程中,您可能需要持有bcache锁和每个bucket(散列桶)一个锁。确保避免死锁。
- 替换块时,您可能会将struct buf从一个bucket移动到另一个bucket,因为新块散列到不同的bucket。您可能会遇到一个棘手的情况:新块可能会散列到与旧块相同的bucket中。在这种情况下,请确保避免死锁。
- 一些调试技巧:实现bucket锁,但将全局bcache.lock的acquire/release保留在bget的开头/结尾,以串行化代码。一旦您确定它在没有竞争条件的情况下是正确的,请移除全局锁并处理并发性问题。您还可以运行make CPUS=1 qemu以使用一个内核进行测试。
8.2.2 实验解答
主题是设计散列桶结构,以减少多进程情况下对于buff cache(磁盘块缓存)的争抢冲突
- 在 kernel/bio.c 定义哈希桶结构,并在bcache中删除全局缓冲区链表,改为使用素数个散列桶
kernel/bio.c
// 定义哈希桶结构 并且使用素数13减少哈希冲突
#define NBUCKET 13
#define HASH(id) (id%NBUCKET)
struct hashbuf{
struct buf head; //头结点
struct spinlock lock; //锁
};
struct {
// struct spinlock lock;
struct buf buf[NBUF]; //一个磁盘块的结构体
struct hashbuf buckets[NBUCKET]; // 散列桶
// Linked list of all buffers, through prev/next.
// Sorted by how recently the buffer was used.
// head.next is most recent, head.prev is least.
// 删除全局的buff cache缓冲链表
// struct buf head;
} bcache;
- 在 kernel/bio.c 的binit中
(1)初始化散列桶的锁,
(2)将所有散列桶的head->prev、head->next都指向自身表示为空,
(3)将所有的缓冲区挂载到bucket[0]桶上,代码如下
kernel/bio.c
void
binit(void)
{
struct buf *b;
char lockname[16];//锁的名称
for(int i=0;i<NBUCKET;++i){
//设置锁的名称开头为bcache
snprintf(lockname,sizeof(lockname),"bcache_%d",i);
//初始化散列桶的自旋锁
initlock(&bcache.buckets[i].lock,lockname);
//初始化散列桶的头结点
bcache.buckets[i].head.prev = &bcache.buckets[i].head;
bcache.buckets[i].head.next = &bcache.buckets[i].head;
}
// 创造一个磁盘缓冲区
for(b=bcache.buf;b<bcache.buf+NBUF;b++){
// 利用头插法初始化缓冲区列表,全部放到散列桶0上
b->next = bcache.buckets[0].head.next;
b->prev = &bcache.buckets[0].head;
initsleeplock(&b->lock,"buffer");
bcache.buckets[0].head.next->prev = b;
bcache.buckets[0].head.next = b;
}
// initlock(&bcache.lock, "bcache");
// // Create linked list of buffers
// bcache.head.prev = &bcache.head;
// bcache.head.next = &bcache.head;
// for(b = bcache.buf; b < bcache.buf+NBUF; b++){
// b->next = bcache.head.next;
// b->prev = &bcache.head;
// initsleeplock(&b->lock, "buffer");
// bcache.head.next->prev = b;
// bcache.head.next = b;
// }
}
- 在 kernel/buf.h 中增加新字段timestamp,这里来理解一下这个字段的用途:在原始方案中,每次brelse都将被释放的缓冲区挂载到链表头,禀明这个缓冲区最近刚刚被使用过,在bget中分配时从链表尾向前查找,这样符合条件的第一个就是最久未使用的(LRU)。而在提示中建议使用时间戳作为LRU判定的法则,这样我们就无需在brelse中进行头插法更改结点位置。timestamp是trap中的 ticks ,当最近用对于该磁盘块用到较多时,ticks越大
kernel/buf.h
struct buf {
int valid; // has data been read from disk?
int disk; // does disk "own" buf?
uint dev;
uint blockno;
struct sleeplock lock;
uint refcnt;
struct buf *prev; // LRU cache list
struct buf *next;
uchar data[BSIZE];
uint timestamp; //时间戳
};
- 更改 kernel/bio.c 的bget,当没有找到指定的缓冲区时进行分配,分配方式是优先从当前列表遍历,找到一个没有引用且timestamp最小的缓冲区,如果没有就申请下一个桶的锁,并遍历该桶,找到后将该缓冲区从原来的桶移动到当前桶中,最多将所有桶都遍历完。在代码中要注意锁的释放
kernel/bio.c
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
int bid = HASH(blockno);
acquire(&bcache.buckets[bid].lock);
// 首先判断当前散列桶缓冲区是否已经有需要的磁盘块
for(b = bcache.buckets[bid].head.next;b != &bcache.buckets[bid].head;b = b->next){
// 判断设备号和块号是否符合
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
// 记录使用时间戳
acquire(&tickslock);
b->timestamp = ticks;
release(&tickslock);
release(&bcache.buckets[bid].lock);
acquiresleep(&b->lock);
return b;
}
}
//首先判断当前散列桶缓冲区没有找到后
b = 0;
struct buf* tmp;
// 采用最近最久未使用(LRU)算法先从当前散列桶缓冲区开始查找是否有空余空间块
// 如果没有,通过i的循环来从其他散列桶中获取空余空间块
for(int i = bid,cycle = 0; cycle != NBUCKET;i = (i+1)%NBUCKET){
++cycle;
//如果遍历当前散列桶,则不重新获取锁
if(i != bid){
if(!holding(&bcache.buckets[i].lock)){
acquire(&bcache.buckets[i].lock);
}else{
continue;
}
}
//遍历查看当前散列桶是否有空闲块
for(tmp = bcache.buckets[i].head.next;tmp != &bcache.buckets[i].head;tmp = tmp->next){
// 通过比较时间戳将最近最久未使用的块换出 timestamp越小 最近使用次数越小
if(tmp->refcnt == 0 && (b == 0 || tmp->timestamp < b->timestamp))
b = tmp;
}
//找到要替换的buff cache
if(b){
// 如果从其他散列桶窃取的,用头插法插入当前桶
if(i != bid){
b->next->prev = b->prev;
b->prev->next = b->next;
release(&bcache.buckets[i].lock);
b->next = bcache.buckets[bid].head.next;
b->prev = &bcache.buckets[bid].head;
bcache.buckets[bid].head.next->prev = b;
bcache.buckets[bid].head.next = b;
}
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
acquire(&tickslock);
b->timestamp = ticks;
release(&tickslock);
release(&bcache.buckets[bid].lock);
acquiresleep(&b->lock);
return b;
}else{
//在当前散列桶中未找到 则直接释放锁
if(i!=bid){
release(&bcache.buckets[i].lock);
}
}
}
panic("bget: no buffers");
// acquire(&bcache.lock);
// // Is the block already cached?
// for(b = bcache.head.next; b != &bcache.head; b = b->next){
// if(b->dev == dev && b->blockno == blockno){
// b->refcnt++;
// release(&bcache.lock);
// acquiresleep(&b->lock);
// return b;
// }
// }
// // Not cached.
// // Recycle the least recently used (LRU) unused buffer.
// for(b = bcache.head.prev; b != &bcache.head; b = b->prev){
// if(b->refcnt == 0) {
// b->dev = dev;
// b->blockno = blockno;
// b->valid = 0;
// b->refcnt = 1;
// release(&bcache.lock);
// acquiresleep(&b->lock);
// return b;
// }
// }
// panic("bget: no buffers");
}
- 更改 kernel/bio.c 的brelse,不再获取全局锁
kernel/bio.c
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
int bid = HASH(b->blockno);
releasesleep(&b->lock);
acquire(&bcache.buckets[bid].lock);
b->refcnt--;
//使用kernel/trap.c中的ticks更新时间戳
//由于LRU改为使用时间戳判定,不再需要头插法
if(b->refcnt == 0){
acquire(&tickslock);
b->timestamp = ticks;
release(&tickslock);
}
release(&bcache.buckets[bid].lock);
// if (b->refcnt == 0) {
// // 使用LRU 最近最常使用算法
// // 在链表头部插入新的block cache ,将尾部的不常使用cache删除
// // no one is waiting for it.
// b->next->prev = b->prev;
// b->prev->next = b->next;
// b->next = bcache.head.next;
// b->prev = &bcache.head;
// bcache.head.next->prev = b;
// bcache.head.next = b;
// }
// release(&bcache.lock);
}
- 最后将末尾的两个小函数也改一下
kernel/bio.c
void
bpin(struct buf *b) {
int bid = HASH(b->blockno);
acquire(&bcache.buckets[bid].lock);
b->refcnt++;
release(&bcache.buckets[bid].lock);
}
void
bunpin(struct buf *b) {
int bid = HASH(b->blockno);
acquire(&bcache.buckets[bid].lock);
b->refcnt--;
release(&bcache.buckets[bid].lock);
}
- 注意:
-
bget中重新分配可能要持有两个锁,如果桶a持有自己的锁,再申请桶b的锁,与此同时如果桶b持有自己的锁,再申请桶a的锁就会造成死锁!因此代码中使用了 ** if(!holding(&bcache.bucket[i].lock)) ** 来进行检查。此外,代码优先从自己的桶中获取缓冲区,如果自身没有依次向后查找这样的方式也尽可能地避免了前面的情况。
-
在bget中搜索缓冲区并在找不到缓冲区时为该缓冲区分配条目必须是原子的!在提示中说bget如果未找到而进行分配的操作可以是串行化的,也就是说多个CPU中未找到,应当串行的执行分配,同时还应当避免死锁。于是在发现未命中(Not cached)后,写了如下的代码(此时未删除bcache.lock)
// 前半部分查找缓冲区的代码 // Not cached release(&bcache.buckets[bid].lock); acquire(&bcache.lock); acquire(&bcache.buckets[bid].lock); // 后半部分分配缓冲区的代码这段代码中先释放了散列桶的锁之后再重新获取,之所以这样做是为了让所有代码都保证申请锁的顺序:先获取整个缓冲区的大锁再获取散列桶的小锁,这样才能避免死锁。但是这样做却破坏了程序执行的原子性。
在release桶的锁并重新acquire的这段时间,另一个CPU可能也以相同的参数调用了bget,也发现没有该缓冲区并想要执行分配。最终的结果是一个磁盘块对应了两个缓冲区,破坏了最重要的不变量,即每个块最多缓存一个副本。这样会导致usertests中的manywrites测试报错:panic: freeing free block
测试!!!!

9 Lab9: file system
在本实验室中,将向xv6文件系统添加大型文件和符号链接。
[!WARNING|label:Attention] 在编写代码之前,您应该阅读《xv6手册》中的《第八章:文件系统》,并学习相应的代码。
获取实验室的xv6源代码并切换到fs分支:
$ git fetch
$ git checkout fs
$ make clean
9.1 前置知识
9.1.1 概述
xv6文件系统实现分为七层,如下表所示。

磁盘层读取和写入virtio硬盘上的块。
缓冲区高速缓存层缓存磁盘块并同步对它们的访问,确保每次只有一个内核进程可以修改存储在任何特定块中的数据。
日志记录层允许更高层在一次事务(transaction)中将更新包装到多个块,并确保在遇到崩溃时自动更新这些块(即,所有块都已更新或无更新)。
索引结点层(Inode) 提供单独的文件,每个文件表示为一个索引结点,其中包含唯一的索引号(i-number)和一些保存文件数据的块。
目录层将每个目录实现为一种特殊的索引结点,其内容是一系列目录项,每个目录项包含一个文件名和索引号。路径名层提供了分层路径名,如***/usr/rtm/xv6/fs.c***,并通过递归查找来解析它们。
文件描述符层使用文件系统接口抽象了许多Unix资源(例如,管道、设备、文件等),简化了应用程序员的工作。
sectors和blocks。
- sector通常是磁盘驱动可以读写的最小单元,它过去通常是512字节。
- block == 块通常是操作系统或者文件系统视角的数据。它由文件系统定义,在XV6中它是1024字节。所以XV6中一个block对应两个sector。通常来说一个block对应了一个或者多个sector。
文件系统必须有将索引节点和内容块存储在磁盘上哪些位置的方案。为此,xv6将磁盘划分为几个部分,如图所示。

块0 要么没有用,要么被用作boot sector来启动操作系统。文件系统不使用(它保存引导扇区)。
块1称为超级块:它包含有关文件系统的元数据(文件系统大小(以块为单位)、数据块数、索引节点数和日志中的块数)。超级块由一个名为mkfs的单独的程序填充,该程序构建初始文件系统。
从2开始的块保存日志。 log从block2开始,到block32结束。实际上log的大小可能不同,这里在super block中会定义log就是30个block。
日志之后是索引节点(inodes),每个块有多个索引节点。多个inode会打包存在一个block中,一个inode是64字节。
位图块(bit map),跟踪正在使用的数据块。
其余的块是数据块:每个都要么在位图块中标记为空闲,要么保存文件或目录的内容。
9.1.2 Inode

- 通常来说它有一个type字段,表明inode是文件还是目录。
- nlink字段,也就是link计数器,用来跟踪究竟有多少文件名指向了当前的inode。
- size字段,表明了文件数据有多少个字节。
- 直接块号 ,不同文件系统中的表达方式可能不一样,不过在XV6中接下来是一些block的编号,例如编号0,编号1,等等。XV6的inode中总共有12个block编号。这些被称为direct block number。这12个block编号指向了构成文件的前12个块。举个例子,如果文件只有2个字节,那么只会有一个block编号0,它包含的数字是磁盘上文件前2个字节的block的位置。
- indirect block number 间接块号,它对应了磁盘上一个block,这个block包含了256个block number,这256个block number包含了文件的数据。所以inode中block number 0到block number 11都是direct block number,而block number 12保存的indirect block number指向了另一个block。
9.1.3 目录
在XV6中,每一个目录包含了directory entries,每一条entry都有固定的格式:
- 前2个字节包含了目录中文件或者子目录的inode编号,
- 接下来的14个字节包含了文件或者子目录名。

例如查找路径名“/y/x”,我们该怎么做呢?
- 从路径名我们知道,应该从root inode开始查找。通常root inode会有固定的inode编号,在XV6中,这个编号是1。
- 我们该如何根据编号找到root inode呢?从前面我们可以知道,inode从block 32开始,如果是inode1,那么必然在block 32中的64到128字节的位置(0-64为Inode0)。所以文件系统可以直接读到root inode的内容。
- 接下来就是扫描root inode包含的所有块,以找到“y”。该怎么找到root inode所有对应的block呢?根据前一节的内容就是读取所有的direct block number(直接块号)和indirect block number(间接块号)。
- 如果找到了,那么目录y也会有一个inode编号,假设是251,我们可以继续从inode 251查找,先读取inode 251的内容,之后再扫描inode所有对应的block,找到“x”并得到文件x对应的inode编号,最后将其作为路径名查找的结果返回。
示例:将“hi”写入到x文件中

- 首先是分配inode,因为首先写的是block 33
- 之后inode被初始化,然后又写了一次block 33
- 之后是写block 46,是将文件x的inode编号写入到x所在目录的inode的data block中
- 之后是更新root inode,因为文件x创建在根目录,所以需要更新根目录的inode的size字段,以包含这里新创建的文件x
- 最后再次更新了文件x的inode
9.1.4 Logging
优点:
- 确保文件系统的系统调用是原子性的。比如调用create/write系统调用,这些系统调用的效果是要么完全出现,要么完全不出现,这样就避免了一个系统调用只有部分写磁盘操作出现在磁盘上。
- 支持快速恢复(Fast Recovery)。在重启之后,我们不需要做大量的工作来修复文件系统,只需要非常小的工作量。这里的快速是相比另一个解决方案来说,在另一个解决方案中,你可能需要读取文件系统的所有block,读取inode,bitmap block,并检查文件系统是否还在一个正确的状态,再来修复。而logging可以有快速恢复的属性。
- 原则上来说,它可以非常的高效,尽管我们在XV6中看到的实现不是很高效
Logging的操作流程:
-
log write:当需要更新文件系统时,并不是更新文件系统本身。假设我们在内存中缓存了bitmap block(位图块),也就是block 45。当需要更新bitmap时,我们并不是直接写block 45,而是将数据写入到log中,并记录这个更新应该写入到block 45。对于所有的写 block都会有相同的操作,例如更新inode,也会记录一条写block 33的log。
-
commit op:文件系统的操作结束了,比如说我们前面看到的4-5个写block操作都结束,并且都存在于log中,我们会commit 文件系统的操作。这意味着我们需要在log的某个位置记录属于同一个文件系统的操作的个数,例如5。
-
install log:当在log中存储了所有写block的内容时,如果我们要真正执行这些操作,只需要将block从log分区移到文件系统分区。我们知道第一个操作该写入到block 45,我们会直接将数据从log写到block45,第二个操作该写入到block 33,我们会将它写入到block 33,依次类推。
-
clean log:一旦完成了,就可以清除log。清除log实际上就是将属于同一个文件系统的操作的个数设置为0。
log的组成:

- header block,也就是我们的commit record,里面包含了:
(1)数字n代表有效的log block的数量
(2)每个log block的实际对应的block编号 - log的数据,也就是每个block的数据,依次为bn0对应的block的数据,bn1对应的block的数据以此类推。这就是log中的内容,并且log也不包含其他内容。(需要更新到数据块46的数据,暂时存贮在log数据块中)
当文件系统在运行时,在内存中也有header block头块的一份拷贝,拷贝中也包含了n和block编号的数组。这里的block编号数组就是log数据对应的实际block编号,并且相应的block也会缓存在block cache中。与前一节课对应,log中第一个block编号是45,那么在block cache(块缓存器)的某个位置,也会有block 45的cache。
9.2 Large files(moderate)
9.2.1 实验要求
在本作业中,您将增加xv6文件的最大大小。目前,xv6文件限制为268个块或268*BSIZE字节(在xv6中BSIZE为1024)。此限制来自以下事实:一个xv6 inode包含12个“直接”块号(direct block number)和一个“间接”块号(indirect block number),“一级间接”块指一个最多可容纳256个块号的块,总共12+256=268个块。
bigfile 命令可以创建最长的文件,并报告其大小:
$ bigfile
..
wrote 268 blocks
bigfile: file is too small
$
测试失败,因为bigfile希望能够创建一个包含65803个块的文件,但未修改的xv6将文件限制为268个块。
您将更改xv6文件系统代码,以支持每个inode中可包含256个一级间接块地址的二级间接块 ,每个一级间接块最多可以包含256个数据块地址。结果将是一个文件将能够包含多达65803个块,或256*256+256+11个块(11而不是12,因为我们将为二级间接块牺牲一个直接块号)。
预备
mkfs 程序创建xv6文件系统磁盘映像,并确定文件系统的总块数;此大小由 kernel/param.h 中的FSSIZE控制。您将看到,该实验室存储库中的FSSIZE设置为200000个块。您应该在make输出中看到来自mkfs/mkfs的以下输出:
nmeta 70 (boot, super, log blocks 30 inode blocks 13, bitmap blocks 25) blocks 199930 total 200000
这一行描述了mkfs/mkfs构建的文件系统:它有70个元数据块(用于描述文件系统的块)和199930个数据块,总计200000个块。
如果在实验期间的任何时候,您发现自己必须从头开始重建文件系统,您可以运行make clean,强制make重建fs.img。
看什么
修改bmap(),以便除了直接块和一级间接块之外,它还实现二级间接块。你只需要有11个直接块,而不是12个,为你的新的二级间接块腾出空间;不允许更改磁盘inode的大小。ip->addrs[]的前11个元素应该是直接块;第12个应该是一个一级间接块(与当前的一样);13号应该是你的新二级间接块。当bigfile写入65803个块并成功运行usertests时,此练习完成:
$ bigfile
..................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
wrote 65803 blocks
done; ok
$ usertests
...
ALL TESTS PASSED
$
运行bigfile至少需要一分钟半的时间。
提示:
- 确保您理解bmap()。写出ip->addrs[]、间接块、二级间接块和它所指向的一级间接块以及数据块之间的关系图。确保您理解为什么添加二级间接块会将最大文件大小增加256*256个块(实际上要-1,因为您必须将直接块的数量减少一个)。
- 考虑如何使用逻辑块号索引二级间接块及其指向的间接块。
- 如果更改NDIRECT的定义,则可能必须更改file.h文件中struct inode中addrs[]的声明。确保struct inode和struct dinode在其addrs[]数组中具有相同数量的元素。
- 如果更改NDIRECT的定义,请确保创建一个新的fs.img,因为mkfs使用NDIRECT构建文件系统。
- 如果您的文件系统进入坏状态,可能是由于崩溃,请删除fs.img(从Unix而不是xv6执行此操作)。make将为您构建一个新的干净文件系统映像。
- 别忘了把你bread()的每一个块都brelse()。
- 您应该仅根据需要分配间接块和二级间接块,就像原始的bmap()。
- 确保itrunc释放文件的所有块,包括二级间接块。
9.2.2 实验解答

- 在 kernel/fs.h 中添加宏定义
kernel/fs.h
// BSIZE = 1024
#define NDIRECT 11 //直接块数量
#define NINDIRECT (BSIZE/sizeof(uint)) // 第一级间接块数量 1024/4 = 256
#define NDINDIRECT ((BSIZE/sizeof(uint)) * (BSIZE/sizeof(uint))) // 第二级间接块数量 256*256
#define MAXFILE (NDIRECT + NINDIRECT + NDINDIRECT)
#define NADDR_PER_BLOCK (BSIZE / sizeof(uint)) //一个块中的地址数量
- 由于NDIRECT定义改变,其中一个直接块变为了二级间接块,需要修改 inode 结构体中 addrs 元素数量
kernel/fs.h
struct dinode {
...
uint addrs[NDIRECT + 2]; // Data block addresses
};
kernel/file.h
struct inode {
...
uint addrs[NDIRECT + 2];
};
- 在 kernel/fs.c 修改bmap支持二级索引
// Return the disk block address of the nth block in inode ip.
// If there is no such block, bmap allocates one.
static uint
bmap(struct inode *ip, uint bn)
{
uint addr, *a;
struct buf *bp;
// 直接块情况
if(bn < NDIRECT){
if((addr = ip->addrs[bn]) == 0)
ip->addrs[bn] = addr = balloc(ip->dev);
return addr;
}
bn -= NDIRECT;
// 第一级间接块情况
if(bn < NINDIRECT){
// Load indirect block, allocating if necessary.
if((addr = ip->addrs[NDIRECT]) == 0)
ip->addrs[NDIRECT] = addr = balloc(ip->dev);
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if((addr = a[bn]) == 0){
a[bn] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
return addr;
}
bn -= NINDIRECT;
// 第二级间接块情况
if(bn < NDINDIRECT){
int level2_idx = bn / NADDR_PER_BLOCK; // 要查找的块号位于二级间接块中的位置
int level1_idx = bn % NADDR_PER_BLOCK; // 要查找的块号位于一级间接块中的位置
//读出二级间接块
if((addr = ip->addrs[NDIRECT + 1]) == 0){
//分配一个空磁盘
ip->addrs[NDIRECT + 1] = addr = balloc(ip->dev);
}
bp = bread(ip->dev,addr);
a = (uint*)bp->data;
if((addr = a[level2_idx]) == 0) {
a[level2_idx] = addr = balloc(ip->dev);
// 更改了当前块的内容,标记以供后续写回磁盘
log_write(bp);
}
brelse(bp);
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if((addr = a[level1_idx]) == 0) {
a[level1_idx] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
return addr;
}
panic("bmap: out of range");
}
- 在 kernel/fs.c 修改itrunc支持二级索引
// Truncate inode (discard contents).
// Caller must hold ip->lock.
void
itrunc(struct inode *ip)
{
int i, j;
struct buf *bp;
uint *a;
for(i = 0; i < NDIRECT; i++){
if(ip->addrs[i]){
bfree(ip->dev, ip->addrs[i]);
ip->addrs[i] = 0;
}
}
if(ip->addrs[NDIRECT]){
bp = bread(ip->dev, ip->addrs[NDIRECT]);
a = (uint*)bp->data;
for(j = 0; j < NINDIRECT; j++){
if(a[j])
bfree(ip->dev, a[j]);
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT]);
ip->addrs[NDIRECT] = 0;
}
struct buf* bp1;
uint* a1;
if(ip->addrs[NDIRECT + 1]) {
bp = bread(ip->dev, ip->addrs[NDIRECT + 1]);
a = (uint*)bp->data;
for(i = 0; i < NADDR_PER_BLOCK; i++) {
// 每个一级间接块的操作都类似于上面的
// if(ip->addrs[NDIRECT])中的内容
if(a[i]) {
bp1 = bread(ip->dev, a[i]);
a1 = (uint*)bp1->data;
for(j = 0; j < NADDR_PER_BLOCK; j++) {
if(a1[j])
bfree(ip->dev, a1[j]);
}
brelse(bp1);
bfree(ip->dev, a[i]);
}
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT + 1]);
ip->addrs[NDIRECT + 1] = 0;
}
ip->size = 0;
iupdate(ip);
}
测试成功

9.3 Symbolic links(moderate)
9.3.1 实验要求
在本练习中,您将向xv6添加符号链接。符号链接(或软链接)是指按路径名链接的文件;当一个符号链接打开时,内核跟随该链接指向引用的文件。符号链接类似于硬链接,但硬链接仅限于指向同一磁盘上的文件,而符号链接可以跨磁盘设备。尽管xv6不支持多个设备,但实现此系统调用是了解路径名查找工作原理的一个很好的练习。
你的工作:
[!TIP|label:YOUR JOB] 您将实现symlink(char *target, char *path)系统调用,该调用在引用由target命名的文件的路径处创建一个新的符号链接。有关更多信息,请参阅symlink手册页(注:执行man symlink)。要进行测试,请将symlinktest添加到Makefile并运行它。当测试产生以下输出(包括usertests运行成功)时,您就完成本作业了。
$ symlinktest
Start: test symlinks
test symlinks: ok
Start: test concurrent symlinks
test concurrent symlinks: ok
$ usertests
...
ALL TESTS PASSED
$
提示:
- 首先,为symlink创建一个新的系统调用号,在user/usys.pl、user/user.h中添加一个条目,并在kernel/sysfile.c中实现一个空的sys_symlink。
- 向kernel/stat.h添加新的文件类型(T_SYMLINK)以表示符号链接。
- 在kernel/fcntl.h中添加一个新标志(O_NOFOLLOW),该标志可用于open系统调用。请注意,传递给open的标志使用按位或运算符组合,因此新标志不应与任何现有标志重叠。一旦将user/symlinktest.c添加到Makefile中,您就可以编译它。
- 实现 symlink(target, path) 系统调用,以在path处创建一个新的指向target的符号链接。请注意,系统调用的成功不需要target已经存在。您需要选择存储符号链接目标路径的位置,例如在inode的数据块中。symlink应返回一个表示成功(0)或失败(-1)的整数,类似于link和unlink。
- 修改open系统调用以处理路径指向符号链接的情况。如果文件不存在,则打开必须失败。当进程向open传递O_NOFOLLOW标志时,open应打开符号链接(而不是跟随符号链接)。
- 如果链接文件也是符号链接,则必须递归地跟随它,直到到达非链接文件为止。如果链接形成循环,则必须返回错误代码。你可以通过以下方式估算存在循环:通过在链接深度达到某个阈值(例如10)时返回错误代码。
- 其他系统调用(如link和unlink)不得跟随符号链接;这些系统调用对符号链接本身进行操作。
- 您不必处理指向此实验的目录的符号链接。
9.3.2 实验解答
这个实验是要实现类似linux上的symlink软链接功能, 比如symlink(‘a’, ‘b’)后, open(‘b’)这个指令会实际上索引到文件’a’所对应的文件data block.
- 添加有关 symlink 系统调用的定义声明. 包括 kernel/syscall.h, kernel/syscall.c, user/usys.pl 和 user/user.h.
kernel/syscall.h
....
extern uint64 sys_uptime(void);
extern uint64 sys_symlink(void); // 系统调用声明
static uint64 (*syscalls[])(void) = {
...
[SYS_close] sys_close,
[SYS_symlink] sys_symlink,
};
kernel/syscall
// System call numbers
...
#define SYS_close 21
#define SYS_symlink 22
user/usys.pl
...
entry("uptime");
entry("symlink");
user/user.h
// system calls
...
int uptime(void);
int symlink(char *target,char *path);
- 添加新的文件类型 T_SYMLINK 到 kernel/stat.h 中.
kernel/stat.h
#define T_DIR 1 // Directory
#define T_FILE 2 // File
#define T_DEVICE 3 // Device
#define T_SYMLINK 4 // 新的文件类型(T_SYMLINK)以表示符号链接。
- 添加新的文件标志位 O_NOFOLLOW 到 kernel/fcntl.h 中.
kernel/fcntl.h
#define O_RDONLY 0x000
#define O_WRONLY 0x001
#define O_RDWR 0x002
#define O_CREATE 0x200
#define O_TRUNC 0x400
#define O_NOFOLLOW 0x004 //新标志(O_NOFOLLOW),该标志可用于open系统调用
- 在
kernel/sysfile.c中实现sys_symlink()函数.
该函数即用来生成符号链接. 符号链接相当于一个特殊的独立的文件, 其中存储的数据即目标文件的路径.
因此在该函数中, 首先通过 create() 创建符号链接路径对应的 inode 结构(同时使用 T_SYMLINK 与普通的文件进行区分). 然后再通过 writei() 将链接的目标文件的路径写入 inode (的 block)中即可. 在这个过程中, 无需判断连接的目标路径是否有效.
需要注意的是关于文件系统的一些加锁释放的规则. 函数 create() 会返回创建的 inode, 此时也会持有其 inode 的锁. 而后续 writei() 是需要在持锁的情况下才能写入. 在结束操作后(不论成功与否), 都需要调用 iunlockput() 来释放 inode 的锁和其本身, 该函数是 iunlock() 和 iput() 的组合, 前者即释放 inode 的锁; 而后者是减少一个 inode 的引用(对应字段 ref, 记录着内存中指向该 inode 的指针数, 这里的 inode 实际上是内存中的 inode, 是从内存的 inode 缓存 icache 分配出来的, 当 ref 为 0 时就会回收到 icache 中), 表示当前已经不需要持有该 inode 的指针对其继续操作了.
kernel/sysfile.c
// 生成符号链接.
uint64 sys_symlink(void){
char target[MAXPATH],path[MAXPATH];
struct inode *ip;
int n;
if((n = argstr(0,target,MAXPATH)) < 0 || argstr(1,path,MAXPATH < 0)){
return -1;
}
begin_op();
//create the symlink's inode
if((ip = create(path,T_SYMLINK,0,0)) == 0){
end_op();
return -1;
}
// write the target path to the inode
if(write(ip,0,(uint64)target,0,n)!=n){
iunlockput(ip);
end_op();
return -1;
}
iunlockput(ip);
end_op();
return 0;
}
- 修改
kernel/sysfile的sys_open()函数.
该函数使用来打开文件的, 对于符号链接一般情况下需要打开的是其链接的目标文件, 因此需要对符号链接文件进行额外处理.
考虑到跟踪符号链接的操作相对独立, 此处编写了一个独立的函数 follow_symlink() 用来寻找符号链接的目标文件.
在跟踪符号链接时需要额外考虑到符号链接的目标可能还是符号链接, 此时需要递归的去跟踪目标链接直至得到真正的文件. 而这其中需要解决两个问题: 一是符号链接可能成环, 这样会一直递归地跟踪下去, 因此需要进行成环的检测; 另一方面是需要对链接的深度进行限制, 以减轻系统负担(这两点也是实验的要求).
对于链接的深度, 此处在 kernel/fs.h 中定义了 NSYMLINK 用于表示最大的符号链接深度, 超过该深度将不会继续跟踪而是返回错误.
kernel/fs.h
// the max depth of symlinks - lab9-2
#define NSYMLINK 10
而对于成环的检测, 此处也是选择了最简单的算法: 创建一个大小为 NSYMLINK 的数组 inums[] 用于记录每次跟踪到的文件的 inode number, 每次跟踪到目标文件的 inode 后都会将其 inode number 与 inums 数组中记录的进行比较, 若有重复则证明成环.
因此整体上 follow_symlink() 函数的流程其实比较简单, 就是至多循环 NSYMLINK 次去递归的跟踪符号链接: 使用 readi() 函数读出符号链接文件中记录的目标文件的路径, 然后使用 namei() 获取文件路径对应的 inode, 然后与已经记录的 inode number 比较判断是否成环. 直到目标 inode 的类型不为 T_SYMLINK 即符号链接类型.
而在 sys_open() 中, 需要在创建文件对象 f=filealloc() 之前, 对于符号链接, 在非 NO_FOLLOW 的情况下需要将当前文件的 inode 替换为由 follow_symlink() 得到的目标文件的 inode 再进行后续的操作.
kernel/sysfile
// 通过ip的软链接找到目标文件
static struct inode* follow_symlink(struct inode* ip){
uint inums[NSYMLINK];
int i,j;
char target[MAXPATH];
for(i=0;i<NSYMLINK;i++){
inums[i] = ip->inum;
//使用 readi() 函数读出符号链接文件中记录的目标文件的路径
if(readi(ip,0,(uint64)target,0,MAXPATH) <= 0){
iunlockput(ip);
printf("open_symlink: open symlink failed\n");
return 0;
}
iunlockput(ip);
// 使用 namei() 获取文件路径对应的 inode
if((ip = namei(target)) == 0) {
printf("open_symlink: path \"%s\" is not exist\n", target);
return 0;
}
//检查是否成环
for(j=0;j<=i;j++){
if(ip->inum == inums[j]){
printf("open_symlink: links form a cycle\n");
return 0;
}
}
ilock(ip);
if(ip->type != T_SYMLINK){
return ip;
}
}
iunlockput(ip);
printf("open_symlink: the depth of links reaches the limit\n");
return 0;
}
uint64
sys_open(void)
{
// ...
if(ip->type == T_DEVICE && (ip->major < 0 || ip->major >= NDEV)){
iunlockput(ip);
end_op();
return -1;
}
// 软链接查找成为目标文件
if(ip->type == T_SYMLINK && (omode & O_NOFOLLOW) == 0) {
if((ip = follow_symlink(ip)) == 0) {
// 此处不用调用iunlockput()释放锁,因为在follow_symlinktest()返回失败时ip的锁在函数内已经被释放
end_op();
return -1;
}
}
if((f = filealloc()) == 0 || (fd = fdalloc(f)) < 0){
if(f)
fileclose(f);
iunlockput(ip);
end_op();
return -1;
}
// ...
}
最后考虑这个过程中的加锁释放的规则. 对于原本不考虑符号链接的情况, 在 sys_open() 中, 由 create() 或 namei() 获取了当前文件的 inode 后实际上就持有了该 inode 的锁, 直到函数结束才会通过 iunlock() 释放(当执行成功时未使用 iput() 释放 inode 的 ref 引用, 笔者认为后续到 sys_close() 调用执行前该 inode 一直会处于活跃状态用于对该文件的操作, 因此不能减少引用). 而对于符号链接, 由于最终打开的是链接的目标文件, 因此一定会释放当前 inode 的锁转而获取目标 inode 的锁. 而在处理符号链接时需要对 ip->type 字段进行读取, 自然此时也不能释放 inode 的锁, 因此在进入 follow_symlink() 时一直保持着 inode 的锁的持有, 当使用 readi() 读取了符号链接中记录的目标文件路径后, 此时便不再需要当前符号链接的 inode, 便使用 iunlockput() 释放锁和 inode. 当在对目标文件的类型判断是否不为符号链接时, 此时再对其进行加锁. 这样该函数正确返回时也会持有目标文件 inode 的锁, 达到了函数调用前后的一致.
测试成功:
10 Lab10: mmap
10.1 mmap(hard)
10.1.1 实验要求
mmap和munmap系统调用允许UNIX程序对其地址空间进行详细控制。它们可用于在进程之间共享内存,将文件映射到进程地址空间,并作为用户级页面错误方案的一部分,如本课程中讨论的垃圾收集算法。在本实验室中,您将把mmap和munmap添加到xv6中,重点关注内存映射文件(memory-mapped files)。
获取实验室的xv6源代码并切换到mmap分支:
$ git fetch
$ git checkout mmap
$ make clean
手册页面(运行man 2 mmap)显示了mmap的以下声明:
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
可以通过多种方式调用mmap,但本实验只需要与内存映射文件相关的功能子集。您可以假设addr始终为零(NULL),这意味着内核应该决定映射文件的虚拟地址。mmap返回该地址,如果失败则返回0xffffffffffffffff。length是要映射的字节数;它可能与文件的长度不同。prot指示内存是否应映射为可读、可写,以及/或者可执行的;您可以认为prot是PROT_READ或PROT_WRITE或两者兼有。flags要么是MAP_SHARED(映射内存的修改应写回文件),要么是MAP_PRIVATE(映射内存的修改不应写回文件)。您不必在flags中实现任何其他位。fd是要映射的文件的打开文件描述符。可以假定offset为零(它是要映射的文件的起点)。
允许进程映射同一个MAP_SHARED文件而不共享物理页面。
munmap(addr, length)应删除指定地址范围内的mmap映射。如果进程修改了内存并将其映射为MAP_SHARED,则应首先将修改写入文件。munmap调用可能只覆盖mmap区域的一部分,但您可以认为它取消映射的位置要么在区域起始位置,要么在区域结束位置,要么就是整个区域(但不会在区域中间“打洞”)。
[!TIP|label:YOUR JOB] 您应该实现足够的mmap和munmap功能,以使mmaptest测试程序正常工作。如果mmaptest不会用到某个mmap的特性,则不需要实现该特性。
完成后,您应该会看到以下输出:
$ mmaptest
mmap_test starting
test mmap f
test mmap f: OK
test mmap private
test mmap private: OK
test mmap read-only
test mmap read-only: OK
test mmap read/write
test mmap read/write: OK
test mmap dirty
test mmap dirty: OK
test not-mapped unmap
test not-mapped unmap: OK
test mmap two files
test mmap two files: OK
mmap_test: ALL OK
fork_test starting
fork_test OK
mmaptest: all tests succeeded
$ usertests
usertests starting
...
ALL TESTS PASSED
$
提示:
- 首先,向UPROGS添加_mmaptest,以及mmap和munmap系统调用,以便让user/mmaptest.c进行编译。现在,只需从mmap和munmap返回错误。我们在kernel/fcntl.h中为您定义了PROT_READ等。运行mmaptest,它将在第一次mmap调用时失败。
- 惰性地填写页表,以响应页错误。也就是说,mmap不应该分配物理内存或读取文件。相反,在usertrap中(或由usertrap调用)的页面错误处理代码中执行此操作,就像在lazy page allocation实验中一样。惰性分配的原因是确保大文件的mmap是快速的,并且比物理内存大的文件的mmap是可能的。
- 跟踪mmap为每个进程映射的内容。定义与第15课中描述的VMA(虚拟内存区域)对应的结构体,记录mmap创建的虚拟内存范围的地址、长度、权限、文件等。由于xv6内核中没有内存分配器,因此可以声明一个固定大小的VMA数组,并根据需要从该数组进行分配。大小为16应该就足够了。
- 实现mmap:在进程的地址空间中找到一个未使用的区域来映射文件,并将VMA添加到进程的映射区域表中。VMA应该包含指向映射文件对应struct file的指针;mmap应该增加文件的引用计数,以便在文件关闭时结构体不会消失(提示:请参阅filedup)。运行mmaptest:第一次mmap应该成功,但是第一次访问被mmap的内存将导致页面错误并终止mmaptest。
- 添加代码以导致在mmap的区域中产生页面错误,从而分配一页物理内存,将4096字节的相关文件读入该页面,并将其映射到用户地址空间。使用readi读取文件,它接受一个偏移量参数,在该偏移处读取文件(但必须lock/unlock传递给readi的索引结点)。不要忘记在页面上正确设置权限。运行mmaptest;它应该到达第一个munmap。
- 实现munmap:找到地址范围的VMA并取消映射指定页面(提示:使用uvmunmap)。如果munmap删除了先前mmap的所有页面,它应该减少相应struct file的引用计数。如果未映射的页面已被修改,并且文件已映射到MAP_SHARED,请将页面写回该文件。查看filewrite以获得灵感。
- 理想情况下,您的实现将只写回程序实际修改的MAP_SHARED页面。RISC-V PTE中的脏位(D)表示是否已写入页面。但是,mmaptest不检查非脏页是否没有回写;因此,您可以不用看D位就写回页面。
- 修改exit将进程的已映射区域取消映射,就像调用了munmap一样。运行mmaptest;mmap_test应该通过,但可能不会通过fork_test。
- 修改fork以确保子对象具有与父对象相同的映射区域。不要忘记增加VMA的struct file的引用计数。在子进程的页面错误处理程序中,可以分配新的物理页面,而不是与父级共享页面。后者会更酷,但需要更多的实施工作。运行mmaptest;它应该通过mmap_test和fork_test。
运行usertests以确保一切正常。
10.1.2 实验解答
本实验是实现一个内存映射文件的功能,将文件映射到内存中,从而在与文件交互时减少磁盘操作。
-
添加有关 mmap 和 munmap 系统调用的定义声明. 包括 kernel/syscall.h, kernel/syscall.c, user/usys.pl 和 user/user.h.
kernel/syscall.c .... extern uint64 sys_uptime(void); extern uint64 sys_mmap(void);// 系统调用声明 extern uint64 SYS_munmap(void); static uint64 (*syscalls[])(void) = { ... [SYS_close] sys_close, [SYS_mmap] sys_mmap, [SYS_munmap] sys_mnumap, };kernel/syscall.h // System call numbers ... #define SYS_close 21 #define SYS_mmap 22 #define SYS_munmap 23user/usys.pl ... entry("uptime"); entry("mmap"); entry("mnumap");user/user.h // system calls ... int uptime(void); void *mmap(void *addr, int length, int prot, int flags, int fd, int off); int munmap(void *addr, int length);本实验中addr和off一直都是0,因此可以不在sys_mmap传入这两个参数。length是需要映射的字节数,可能和文件大小不相等,prot表示映射到的内存的权限为PROT_READ还是PROT_WRITE。flag可以是MAP_SHARED或MAP_PRIVATE,如果是前者就需要将内存中修改的相应部分写回文件中。fd是需要映射的已打开的文件描述符。
munmap(addr, length)需要将从addr开始的length长度的mmap全部取消映射,这里的假设是只能从VMA的头部或尾部取消映射,不能对中间部分取消映射。
-
向Makefile中添加$U_mmaptest\
UPROGS=\ ... $U/_zombie\ $U/_mmaptest\ -
在kernel/proc.h中添加对vma结构体的定义,每个进程中最多可以有16个VMA。
kernel/proc.h #define NVMA 16 struct vma_area{ int used; // 是否已被使用 uint64 addr; // VMA的起始虚拟地址 int len; // VMA的长度,uint:bytes int prot; // permission int flags; // flag int vfd; // 对应的文件描述符 struct file *vfile; // map文件的指针 int offset; // 有效映射地址的偏移量 }; // Per-process state struct proc { ... char name[16]; // Process name (debugging) struct vma_area vma[NVMA]; // 虚拟内存区域 }; -
在kernel/proc.c 的allocproc中将vma数组初始化为全0
kernel/proc.c
static struct proc*
allocproc(void)
{
...
found:
...
memset(&p->vma, 0, sizeof(p->vma));
return p;
}
- 在 kernel\sysfile.c 根据提示2、3、4,参考lazy实验中的分配方法(将当前p->sz作为分配的虚拟起始地址,但不实际分配物理页面),此函数写在sysfile.c中就可以使用静态函数argfd同时解析文件描述符和struct file
kernel\sysfile.c
// 根据提示2、3、4,参考lazy实验中的分配方法(将当前p->sz作为分配的虚拟起始地址,但不实际分配物理页面)
uint64
sys_mmap(void)
{
uint64 addr;
int length;
int prot;
int flags;
int vfd;
struct file *vfile;
int offset;
uint64 err = 0xffffffffffffffff;
//从各个寄存器中获取系统调用参数
if(argint(0, &addr) < 0 || argint(1,&length)<0 || argint(2,&prot) ||
argint(3,&flags)<0 || argfd(4,&vfd,&vfile)<0 || argint(5, &offset) < 0){
return err;
}
//实验提示中假定addr和offset为0,简化程序可能发生的情况
if(addr != 0 || offset!=0 || length<0)
return err;
// 文件不可写则不允许拥有PROT_WRITE权限时,
// 映射为MAP_SHARED(映射内存的修改应写回文件),即权限发生错误
if(vfile->writable == 0 && (prot & PROT_WRITE) !=0 && flags == MAP_SHARED)
return err;
struct proc *p = myproc();
// 没有足够的虚拟地址
if(p->sz > MAXVA)
return err;
// 遍历查找未使用的VMA结构体
for(int i=0; i<NVMA; i++){
if(p->vma[i].used == 0){
p->vma[i].used = 1;
// 将当前p->sz作为分配的虚拟起始地址,但不实际分配物理页面,等page fault
p->vma[i].addr = p->sz;
p->vma[i].len = length;
p->vma[i].flags = flags;
p->vma[i].prot = prot;
p->vma[i].vfile = vfile;
p->vma[i].vfd = vfd;
p->vma[i].offset = offset;
// 增加文件的引用计数
filedup(vfile);
p->sz += length;
return p->vma[i].addr;
}
}
return err;
}