《Redis开发与运维》学习笔记1:Redis内置的附加功能及应用场景
最近在看《Redis开发与运维》 决定将重要的内容整理出来,其他没讲到的暂时用不上的内容请回书上去看
这篇主要整理第三章的内容,该节详细讲解了redis内置的各种功能,转载注明出处:https://blog.csdn.net/Koikoi12

如果想详细了解各类api可以看如下文档:Redis 命令参考。里面有比较详细的说明,如 set 的使用,还会附带 redis 分布式锁的实现等。
慢查询分析
所谓的慢查询,就是记录命令前后执行时间(不包含网络传输时间,因此不解决超时问题)MySQL也有该功能
配置参数
- 设置慢查询日志最大长度:
config set slowlog-max-len 1000线上建议调大慢查询列表,可设置1000以上,长度超出时会将最早的日志移除 - 设置预设阀值:
config set slowlog-log-slower-than 1000默认值超过10毫秒判断为慢查询,对于高ops场景建议设置为1毫秒,注意配置里设的是1000微秒(1秒=1 000毫秒=1 000 000微秒) - 最后应用配置:
config rewrite
命令参数
slowlog get [n]可以获取所有或指定n条日志slowlog len当前慢查询日志条数slowlog reset重制,其实就是清零
get获取的日志由四部分组成:id,发生时间戳,耗时,执行命令+参数
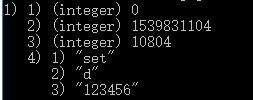
因为慢查询不包括命令排队和网络传输时间,实际客户端执行时间会大于实际命令执行时间
慢查询日志是fifio队列,超出长度会导致丢失日志,可以持久化到其他地方,如定期slowlog get后存到db里去
Redis Shell
Redis提供了redis-cli,redis-server,redis-benchmark等shell工具
redis-cli
要了解全部参数,执行redis-cli -help查看,这里只介绍几个常用的参数
$ redis-cli -r 3 -i 1 ping
-r (repeat) 重复3次,-i (interval) 间隔1秒执行命令
PONG
PONG
PONG
$ redis-cli --slave
把当前客户端模拟成redis从节点,有关这条命令可以看主从复制
$ redis-cli --rdb
请求redis生成rdb持久化,可用该命令做定期备份
$ redis-cli --bigkeys
该选项会使用scan命令对redis中的key进行采样,从而找出内存占用大的key
redis-server
除了启动redis外,还有一个--test-memory选项,作用是检测当前操作系统能否稳定分配指定容量的内存给redis
$ redis-server --test-memory 1024
检查该os是否有1G内存分配给redis,该命令检测时间较长,只是简单检测,更偏向于调试
redis-benchmark
该工具可以为redis做基准性能测试
-c(clients) 代表客户端的并发数量(默认50)
-n(num) 代表客户端请求总量(默认100 000)
$ redis-benchmark -c 100 -n 20000
代表100个客户端同时请求redis,共执行20000次。之后会返回各类性能指标
-q 显示每秒请求requests per second信息
-t 对指定命令进行测试
$ redis-benchmark -t get,set -q
代表对get,set命令测试并返回每秒请求信息
-r(random) 随机插入更多的key
-P 代表每个请求pipeline的数据量(默认1)
-k 代表客户端是否使用keepalive,1使用0不使用,默认1
–csv 按照csv个数输出,便于导出到Excel
Pipeline
1.概念
Redis执行一次命令的往返时间称为RTT(Round Trip Time)
Redis批量操作命令(如mget,mset等),可以有效节约RTT,但大部分命令不支持批量操作,如执行n次hgetall命令,因为没有mhgetall,所以需要消耗n次RTT。
这会在跨机房的情况下无限放大执行时间,假如客户端到服务端的物理距离很遥远(往返时间 RTT 变长),且一次执行了大量n次命令,来回执行n次RTT会很吃时间和网络资源
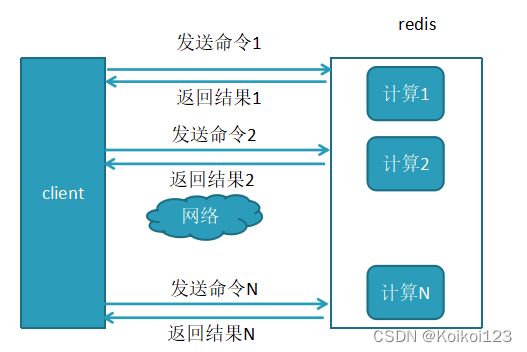
这里引用到了Pipeline机制,它能将一组命令组装起来,通过一次RTT传输给Redis
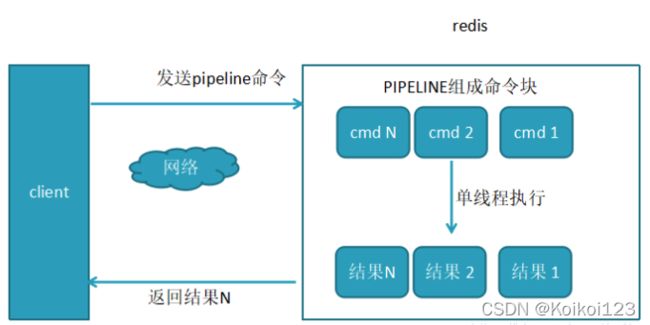
redis-cli 的 --pipe 选项使用了Pipeline机制,一般我们都通过高级语言客户端来使用,如Java通过Jedis调方法来使用,具体去依赖包内找轮子使用
2.性能对比
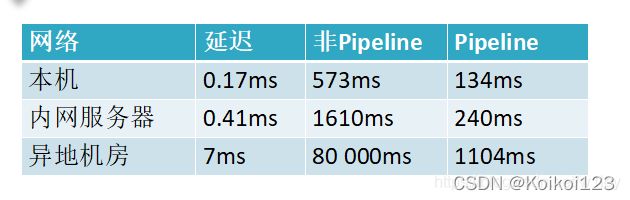
执行一万次set操作下Pipeline和非Pipeline对比,可以发现执行时间效果明显
3.原生批量命令和Pipeline对比
- 原生批量命令是原子的,Pipeline是非原子性
- 原生批量命令是一命令对应多个key,Pipeline支持多个命令
- 原生批量命令是服务端支持实现的,而Pipeline需要服务端与客户端共同实现
4.Jedis使用Pipeline
import org.junit.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
@Test
public void pipeCompare() {
Jedis redis = new Jedis("127.0.0.1", 6379);
redis.auth("123456");//授权密码 对应redis.conf的requirepass密码
Map<String, String> data = new HashMap<String, String>();
redis.select(8);//使用第8个库
redis.flushDB();//清空第8个库所有数据
// hmset
long start = System.currentTimeMillis();
// 直接hmset
for (int i = 0; i < 10000; i++) {
data.clear(); //清空map
data.put("k_" + i, "v_" + i);
redis.hmset("key_" + i, data); //循环执行10000条数据插入redis
}
long end = System.currentTimeMillis();
System.out.println(" 共插入:[" + redis.dbSize() + "]条 .. ");
System.out.println("1,未使用PIPE批量设值耗时" + (end - start) / 1000 + "秒..");
redis.select(8);
redis.flushDB();
// 使用pipeline hmset
Pipeline pipe = redis.pipelined();
start = System.currentTimeMillis();
//
for (int i = 0; i < 10000; i++) {
data.clear();
data.put("k_" + i, "v_" + i);
pipe.hmset("key_" + i, data); //将值封装到PIPE对象,此时并未执行,还停留在客户端
}
pipe.sync(); //将封装后的PIPE一次性发给redis
end = System.currentTimeMillis();
System.out.println(" PIPE共插入:[" + redis.dbSize() + "]条 .. ");
System.out.println("2,使用PIPE批量设值耗时" + (end - start) / 1000 + "秒 ..");
//--------------------------------------------------------------------------------------------------
// hmget
Set<String> keys = redis.keys("key_*"); //将上面设值所有结果键查询出来
// 直接使用Jedis hgetall
start = System.currentTimeMillis();
Map<String, Map<String, String>> result = new HashMap<String, Map<String, String>>();
for (String key : keys) {
//此处keys根据以上的设值结果,共有10000个,循环10000次
result.put(key, redis.hgetAll(key)); //使用redis对象根据键值去取值,将结果放入result对象
}
end = System.currentTimeMillis();
System.out.println(" 共取值:[" + redis.dbSize() + "]条 .. ");
System.out.println("3,未使用PIPE批量取值耗时 " + (end - start) / 1000 + "秒 ..");
// 使用pipeline hgetall
result.clear();
start = System.currentTimeMillis();
for (String key : keys) {
pipe.hgetAll(key); //使用PIPE封装需要取值的key,此时还停留在客户端,并未真正执行查询请求
}
pipe.sync(); //提交到redis进行查询
end = System.currentTimeMillis();
System.out.println(" PIPE共取值:[" + redis.dbSize() + "]条 .. ");
System.out.println("4,使用PIPE批量取值耗时" + (end - start) / 1000 + "秒 ..");
redis.disconnect();
}
代码参考:Redis系列十:Pipeline详解
事务与Lua
Redis事务
Redis支持事务,只需要将一起执行的命令放在multi和exec两个命令之间即可。如要停止事务,使用discard替代exec。
命令错误时会回滚,如把set写出sett
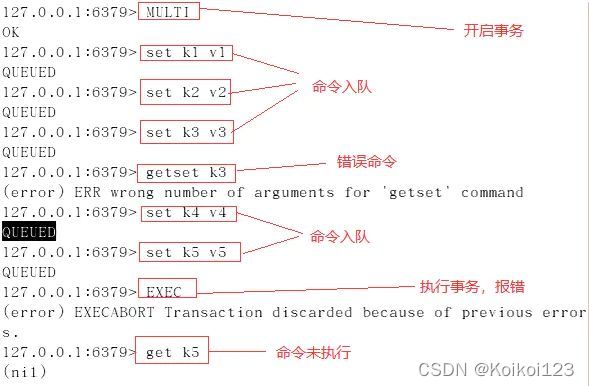
运行时错误不会回滚,如误把sadd写出zadd,因为不会报语法错误
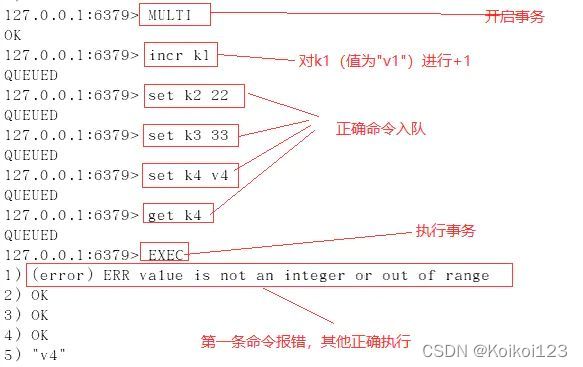
在使用事务之前,要确保事务中的key没有被其他客户端修改,才去执行事务,否则不执行。可以使用watch命令来解决,只需在multi之前执行watch key

如果再跑事务时,其他客户端修改了该key,则事务执行失败

Lua脚本
Lua的基础语法书上讲过了一遍,想要具体了解可自行百度
Redis通过eval和evalsha来执行Lua脚本,内容很多很杂,都是命令,整理比较废时间,具体去看书或其他人整理的文章:cnblogs-Redis事务与Lua
Bitmaps
1.概念
通过bit位来表示某个元素对应的值或者状态,众所周知 8bit=1Byte,所以bitmap本身会极大的节省储存空间。
一般使用我们可以将字符串改成位进行操作,转成二进制后插入bitmap数组中,存在的部分置为1标记,不存在为0。
bitmap其实更适合做数字比较,可以看我之前写的这篇:
布隆过滤器实践,缓存穿透的预防及和bitmap的区别
在Redis应用中和一般Bitmaps有些不同,key就作为元素本身,通过偏移量去存值。
2.常用命令
setbit key offset value
设置key在偏移量offset处(从0算起)的value值(只能设置0或1)。
举例:假设现在有20个用户,userid=0,5,11,15,19的用户对网站进行了访问, 那么初始化结果如图
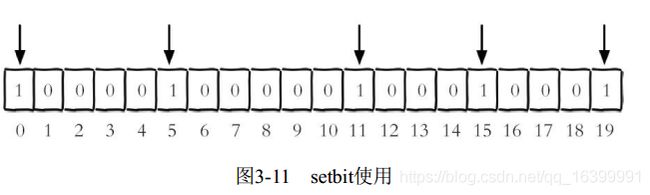
具体操作如下:
127.0.0.1:6379> setbit unique:users:2016-04-05 0 1
(integer) 0
127.0.0.1:6379> setbit unique:users:2016-04-05 5 1
(integer) 0
127.0.0.1:6379> setbit unique:users:2016-04-05 11 1
(integer) 0
127.0.0.1:6379> setbit unique:users:2016-04-05 15 1
(integer) 0
127.0.0.1:6379> setbit unique:users:2016-04-05 19 1
(integer) 0
如果用户id存入1后再存入10000,数组中间空档全是0,势必会造成很大的浪费,因为偏移量非常大, 整个初始化过程执行会比较慢,造成Redis的阻塞。
getbit key offset
获取key在偏移量offset上的值(存在返回1,不存在返回0)
bitcount key [start end]
获取指定范围内值为1的个数
3.对比分析
假设网站有1亿用户, 每天独立访问的用户有5千万, 如果每天用集合类型和Bitmaps分别存储活跃用户可以得到如下


但Bitmaps并不是万金油, 假如该网站每天的访问用户很少,两者的对比如下
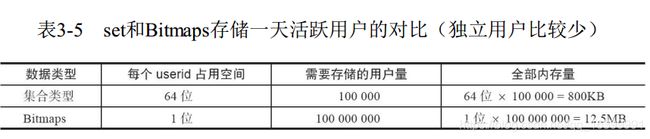
一句话总结,用户量很大的情况下就用bitmap,位存储很省空间
书上的大部分内容看这篇:
redis-Bitmaps 基础概念
4.Spring中Redis Bitmaps使用
基于RedisTemplate封装bitmap方法,传参的这三个参数上面都说过了
/**
* bitmaps存储
* @param key
* @param offset
* @param isExist
*/
public void bitmapAdd(String key, Long offset, boolean isExist) {
redisTemplate.opsForValue().setBit(key, offset, isExist);
}
/**
* bitmaps获取
* @param key
* @param offset
* @return
*/
public boolean bitmapExist(String key, Long offset) {
return redisTemplate.opsForValue().getBit(key, offset);
}
HyperLogLog
HyperLogLog 是用来做基数统计的算法
- 优点是在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定并且很小。
- 缺点是存在错误率,官方给出的数字是0.81%失误率,开发实际使用只需注意如下两条即可:1.只为了计算独立总数,2.可以容忍误差率
使用方式就三条命令,菜鸟教程:Redis HyperLogLog
发布订阅
一般还是不建议用redis实现消息队列,因为消息丢失后是追不回来的
命令分为三种,发布频道,订阅频道,取消订阅。菜鸟教程:Redis 发布订阅
还有一个geo功能,用于实现地理位置信息,其实底层用的是zset,存经纬度