常用文本处理命令---sort、uniq、tr、cut、split、eval
文章目录
- 1 排序---sort
- 2 去重---uniq
- 3 删除替换压缩---tr
-
- 3.1 扩充1 ${i%,*}。。。
- 3.1 扩充2
- 4 截取字段或者字符串---cut
- 4.1 字符串替换和截取
- 5 拆分文件---split
- 6 扫描命令---eval
1 排序—sort
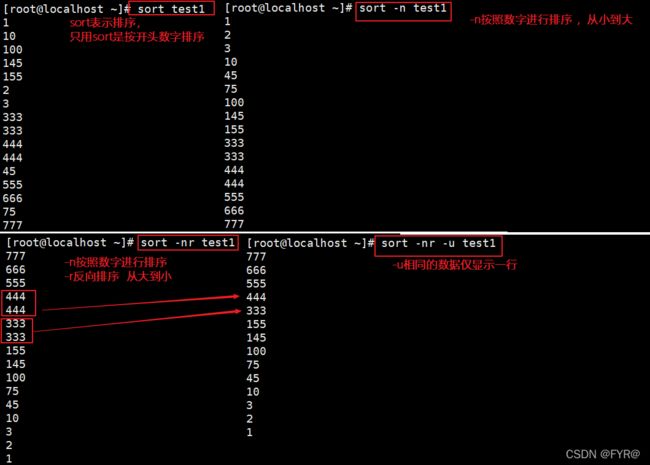
sort命令—以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
语法格式
sort [选项] 参数
cat file | sort 选项
常用选项:
| -n | 按照数字进行排序 |
|---|---|
| -r | 反向排序 |
| -u | 等同于uniq,表示相同的数据仅显示一行 |
| -t | 指定字段分隔符,默认使用[Tab]键分隔 |
| -k | 指定排序字段 |
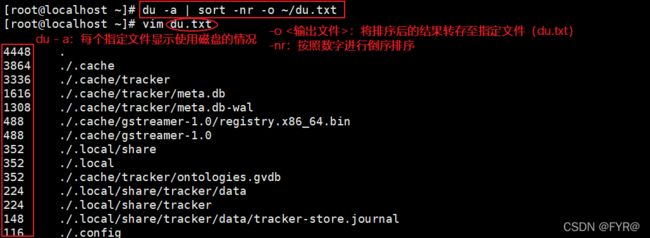
| -o <输出文件> | 将排序后的结果转存至指定文件 |
| -f | 忽略大小写,会将小写字母都转换为大写字母来进行比较 |
| -b | 忽略每行前面的空格 |
 |
|
 |
|
 |
|
 |
2 去重—uniq
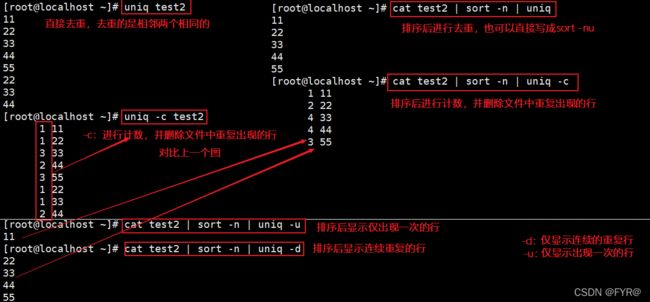
uniq命令—用于报告或者忽略文件中连续的重复行,常与 sort 命令结合使用
语法格式:
uniq [选项] 参数
cat file | uniq 选项
常用选项:
| -c | 进行计数,并删除文件中重复出现的行 |
|---|---|
| -d | 仅显示连续的重复行 |
| -u | 仅显示出现一次的行 |
 |
|
 |
3 删除替换压缩—tr
tr命令—常用来对来自标准输入的字符进行替换、压缩和删除
语法格式:
tr [选项] [参数]
tr [选项] 参数1 参数2
字符集1 字符集2
常用选项:
| -c | 保留字符集1的字符,其他的字符(包括换行符\n)用字符集2替换 |
|---|---|
| -d | 删除所有属于字符集1的字符 |
| -s | 将重复出现的字符串压缩为一个字符串;用字符集2替换字符集1 |
| -t | 字符集2替换字符集1,不加选项同结果 |
| 参数 | |
| 字符集1:指定要转换或删除的原字符集。当执行转换操作时,必须使用参数 “字符集2” 指定转换的目标字符集。但执行删除操作时,不需要参数 “字符集2” | |
| 字符集2:指定要转换成的目标字符集 |
- -c:保留字符集1的字符,其他的字符

注意:
echo -n
echo -e "XXXXXXX\c"
除了以上两种方式输出的内容结尾不会携带换行符,echo其它输出方法都会在内容结尾默认携带一个换行符\n
- -s:将重复出现的字符串压缩为一个字符串


案例一
[root@localhost ~]# tr 123 abc //只要出现123 就转换成abc
[root@localhost ~]# tr 12345678 abc //最后一个一直用
[root@localhost ~]# tr -d abc //删除
2a34bc
234
[root@localhost ~]# tr -s " "
1 2 3 4
1 2 3 4
[root@localhost ~]# tr -s "a"

案例二:删除空行的方法
方法一:grep -v "^$" 文件
方法二:cat 文件 | tr -s "\n"

案例三:面试题生成随机密码
[root@fyr ~]# cat /dev/urandom |tr -dc '[:alnum:]' | head -c12

案例四
[root@fyr ~]# cat 1.txt
aaaaa 11111
bbbbb 22222
[root@fyr ~]# cat 1.txt |tr -c "[a-z]" " " //用 空格替换除了小写字母之外的所有字符
[root@fyr ~]# cat 1.txt |tr -sc "[a-z]" " " //加s压缩

3.1 扩充1 ${i%,*}。。。
${i%,*}字符串从右往左,最短匹配逗号的部分被删除
${i%%,*}字符串从右往左,最长匹配逗号的部分被删除
${i#*,}字符串从左往右,最短匹配的部分被删除
${i##*,}字符串从左往右,最长匹配逗号的部分被删除

3.1 扩充2
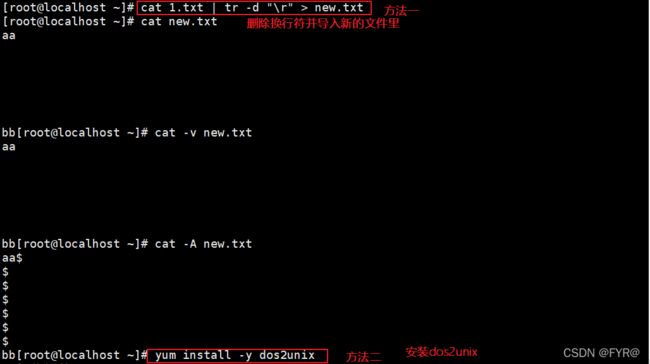
- Linux 中遇到换行符(“\n”)会进行回车+换行的操作,回车符反而只会作为控制字符(“^M”)显示,不发生回车的操作。
- Windows 中要回车符+换行符(“\r\n”)才会回车+换行,缺少一个控制符或者顺序不对都不能正确的另起一行。
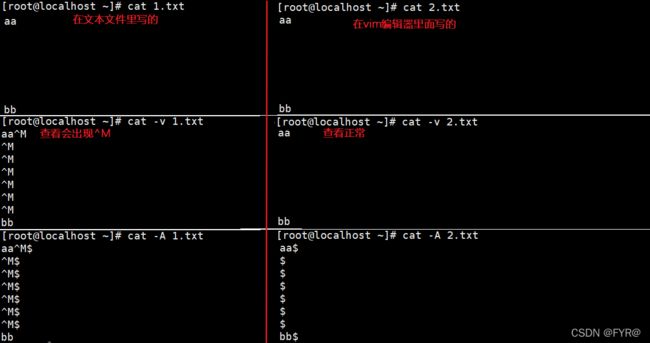
解决Windows里面的文件放在Linux中使用会被识别
方法一:cat 文件 | tr -d "\r" > 新的文件
方法二:
安装dos2unix(yum install -y dos2unix)
dos2unix 文件
4 截取字段或者字符串—cut
cut命令—显示行中的指定部分删除文件中指定字段
语法格式:
cut 参数
cat file | cut选项
常用选项:
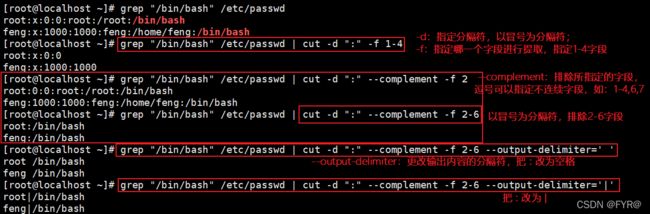
| -f | 通过指定哪一个字段进行提取。cut命令使用"TAB"作为默认的字段分隔符 |
|---|---|
| -d | "TAB"是默认的分隔符,使用此选项可以更改为其他的分隔符 |
| –complement | 此选项用于排除所指定的字段 |
| –output-delimiter | 更改输出内容的分隔符 |
#: 第#个字段,例如 3
#,#[,#]:离散的多个字段,例如 1,3,6
#-#:连续的多个字段, 例如 1-6
混合使用:1-3,7
举例一
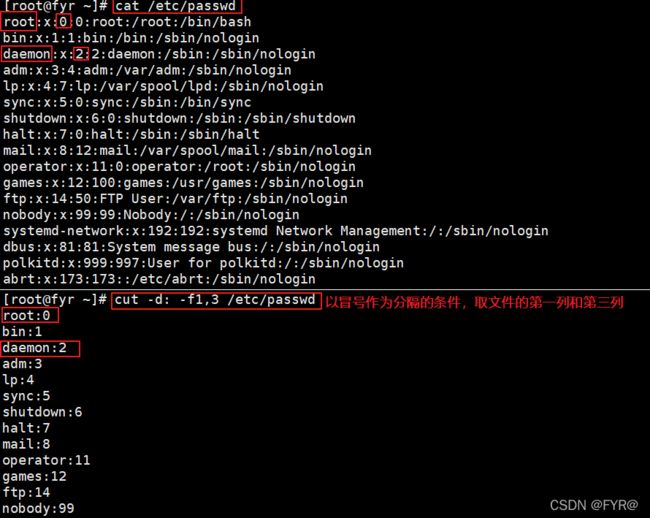
[root@fyr ~]# cut -d : -f1,3 /etc/passwd
//以冒号作为分隔的条件,取文件的第一列和第三列
案例二
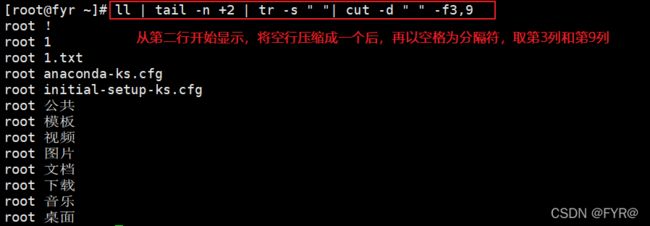
[root@fyr ~]# ll | tail -n +2 | tr -s " "| cut -d " " -f3,9
//从第二行开始,将空行压缩成一个后,再以空格为分隔符,取第3 和第9列
案例三
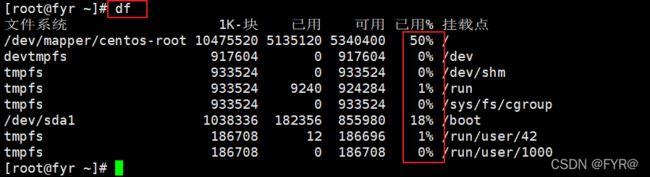
[root@fyr ~]# df | tail -n +2 | tr -s " " | cut -d " " -f5 | tr -d %
# df |tail -n +2 不显示第一行字段
# tr -s " " 将多个空格压缩成一个
# cut -d " " -f5 已空格为分隔符,取第五列
# tr -d % 删除百分号
[root@fyr ~]# df | tail -n +2 | tr -s " " % | cut -d % -f5
# df |tail -n +2 不显示第一行字段
# tr -s " " 将多个空格压缩成一个后 将空格替换成%
# cut -d % -f5 已%为分隔符 取第5列

4.1 字符串替换和截取
字符串匹配替换
${i/a/b}#将第一个a替换成b
${i//a/b}#将所有a替换成b
${i/%a/b}#将最后一个a替换成b
截取字符串
方法一:
${i:0:3}下标从0开始:截取的字符长度
方法二:
echo $i | cut -b 1-3 下标从1开始起始位置-终止位置
方法三:
expr substr $i 1 3下标从1开始 1代表起始位置 3代表截取的字符长度

注意:cut命令如果使用-b选项,执行时会先把-b后面所有的定位进行从小到大排序,然后再提取,不能颠倒顺序。
5 拆分文件—split
split命令—linux下将一个大的文件拆分成若干小文件
语法格式:
split 选项 参数 原始文件 拆分后文件名前缀
常用选项:
| -l | 以行数拆分 |
|---|---|
| -b | 以大小拆分 |
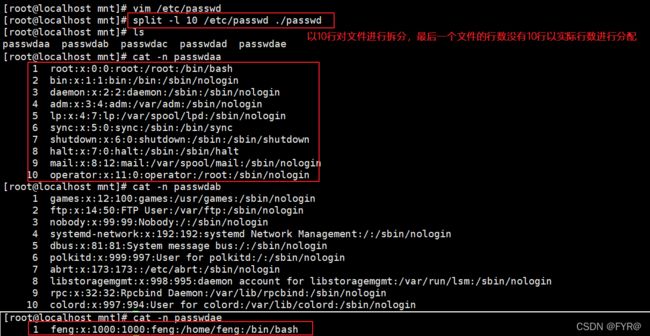
split -l 10 /etc/pasawd passwd #以10行对文件进行拆分,最后一个文件的行数没有10行以实际行数进行分配(不满10行也会单独放一个文件)
6 扫描命令—eval
eval命令—命令字前加上 eval 时,shell 会在执行命令之前扫描它两次。eval 命令将首先会先扫描命令行进行所有的置换,然后再执行该命令。该命令适用于那些一次扫描无法实现其功能的变量。该命令对变量进行两次扫描。
扫描命令2次,第一次会把$变量转换成值,然后再执行命令

案例一:

案例二:
