实用小算法
开头提醒:
打开自己本地任意一个SpringBoot项目,复制代码到test包下跟着敲。
后面几篇文章不再提醒,希望大家养成习惯。看10篇文章,不如自己动手做一次。
我们不执着于一天看多少篇,但求把每一篇都搞懂,慢就是快。
给大家分享一个非常、非常、非常实用的小算法。严格意义上,它不是一个算法,而是一种编码技巧。但其中涉及的思想层面的东西是共通的,如果能熟练掌握它,在某些场景下将大幅提升我们程序的执行效率。
这个算法能解决什么问题呢?它主要处理两个数据集合的匹配问题。
比如,现在有两个数据集合:
public class Demo {
public static void main(String[] args) {
// 老公组
List husbands = new ArrayList<>();
husbands.add(new Couple(1, "梁山伯"));
husbands.add(new Couple(2, "牛郎"));
husbands.add(new Couple(3, "干将"));
husbands.add(new Couple(4, "工藤新一"));
husbands.add(new Couple(5, "罗密欧"));
// 老婆组
List wives = new ArrayList<>();
wives.add(new Couple(1, "祝英台"));
wives.add(new Couple(2, "织女"));
wives.add(new Couple(3, "莫邪"));
wives.add(new Couple(4, "毛利兰"));
wives.add(new Couple(5, "朱丽叶"));
}
}
@Data
@AllArgsConstructor
class Couple{
private Integer familyId;
private String userName;
} 要求对数据进行处理,最终输出:
梁山伯爱祝英台
牛郎爱织女
干将爱莫邪
工藤新一爱毛利兰
罗密欧爱朱丽叶
第一版算法
优秀的代码都不是一蹴而就的,需要不断地优化和重构。所以一开始我们不要想太多,先把需求完成了再说:
public static void main(String[] args) {
// 用于计算循环次数
int count = 0;
// 老公组
List husbands = new ArrayList<>();
husbands.add(new Couple(1, "梁山伯"));
husbands.add(new Couple(2, "牛郎"));
husbands.add(new Couple(3, "干将"));
husbands.add(new Couple(4, "工藤新一"));
husbands.add(new Couple(5, "罗密欧"));
// 老婆组
List wives = new ArrayList<>();
wives.add(new Couple(1, "祝英台"));
wives.add(new Couple(2, "织女"));
wives.add(new Couple(3, "莫邪"));
wives.add(new Couple(4, "毛利兰"));
wives.add(new Couple(5, "朱丽叶"));
for (Couple husband : husbands) {
for (Couple wife : wives) {
// 记录循环的次数
count++;
if (husband.getFamilyId().equals(wife.getFamilyId())) {
System.out.println(husband.getUserName() + "爱" + wife.getUserName());
}
}
}
System.out.println("----------------------");
System.out.println("循环了:" + count + "次");
} 输出结果
梁山伯爱祝英台
牛郎爱织女
干将爱莫邪
工藤新一爱毛利兰
罗密欧爱朱丽叶
----------------------
循环了:25次
总结一下第一版算法的优缺点。
- 优点:代码逻辑非常直观,外层for遍历husband,内层for根据husband的familyId匹配到wife
- 缺点:循环次数过多
当前数据量较小,可能看不出明显差距。实际上这是非常糟糕的一种算法。
想象一下,如果现在男女cp各1000人,那么全部匹配需要1000*1000 = 100w次循环。
如何改进?
我们要明确,在当前这个需求中,每位男嘉宾只能选一位女嘉宾。比如当外层for刚好轮到牛郎时,内层for需要遍历wives找出织女。一旦牛郎和织女牵手成功,其实就没必要继续往下遍历wives了,遍历完了又如何呢,反正只能带走织女。所以明智的做法是,牛郎匹配到织女后,就赶紧下去,换干将上场。
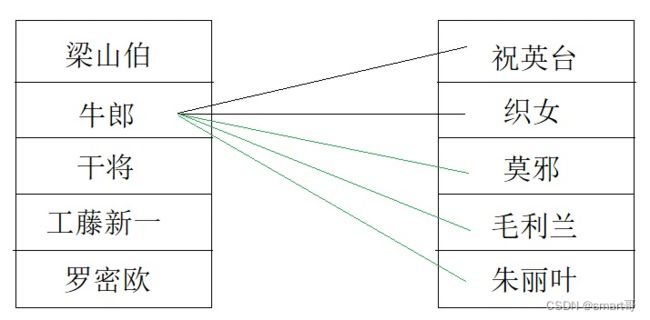
后面的三次其实是没必要的
第二版算法
public static void main(String[] args) {
// 用于计算循环次数
int count = 0;
// 老公组
List husbands = new ArrayList<>();
husbands.add(new Couple(1, "梁山伯"));
husbands.add(new Couple(2, "牛郎"));
husbands.add(new Couple(3, "干将"));
husbands.add(new Couple(4, "工藤新一"));
husbands.add(new Couple(5, "罗密欧"));
// 老婆组
List wives = new ArrayList<>();
wives.add(new Couple(1, "祝英台"));
wives.add(new Couple(2, "织女"));
wives.add(new Couple(3, "莫邪"));
wives.add(new Couple(4, "毛利兰"));
wives.add(new Couple(5, "朱丽叶"));
for (Couple husband : husbands) {
for (Couple wife : wives) {
// 记录循环的次数
count++;
if (husband.getFamilyId().equals(wife.getFamilyId())) {
System.out.println(husband.getUserName() + "爱" + wife.getUserName());
// 牵手成功,换下一位男嘉宾
break;
}
}
}
System.out.println("----------------------");
System.out.println("循环了:" + count + "次");
} 输出结果:
梁山伯爱祝英台
牛郎爱织女
干将爱莫邪
工藤新一爱毛利兰
罗密欧爱朱丽叶
----------------------
循环了:15次
我们发现,循环次数从第一版的25次减少到了15次,区别仅仅是增加了一个break:一旦牵手成功,就换下一位男嘉宾。
break:跳出当前循环(女嘉宾for循环),但不会跳出男嘉宾的for循环。
总结一下第二版算法的优缺点。
- 优点:执行效率比第一版高
- 缺点:理解难度稍微提升了一些
这是最终版了吗?不,远远不够。
哈?还能优化吗?
问大家一个问题:
看过《非诚勿扰》吗?一位男嘉宾和一位女嘉宾牵手成功后,这位女嘉宾就要离开舞台了,对吧?
对呀?怎么了?
请你重新看看我们的第二版代码,你会发现即使牛郎和织女牵手成功了,下一位男嘉宾(干将)入场时还是会在循环中碰到织女。织女在上一轮循环中,已经确定和牛郎在一起了,本次干将再去遍历织女是没有意义的。
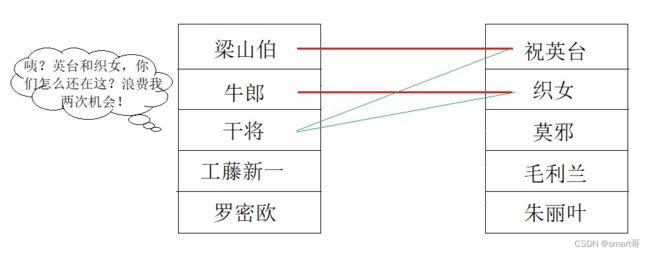
在前两轮中,梁山伯、牛郎已经确定牵手祝英台、织女,应该把她们两个从舞台请下去
第三版算法
public static void main(String[] args) {
// 用于计算循环次数
int count = 0;
// 老公组
List husbands = new ArrayList<>();
husbands.add(new Couple(1, "梁山伯"));
husbands.add(new Couple(2, "牛郎"));
husbands.add(new Couple(3, "干将"));
husbands.add(new Couple(4, "工藤新一"));
husbands.add(new Couple(5, "罗密欧"));
// 老婆组
List wives = new ArrayList<>();
wives.add(new Couple(1, "祝英台"));
wives.add(new Couple(2, "织女"));
wives.add(new Couple(3, "莫邪"));
wives.add(new Couple(4, "毛利兰"));
wives.add(new Couple(5, "朱丽叶"));
for (Couple husband : husbands) {
for (Couple wife : wives) {
// 记录循环的次数
count++;
if (husband.getFamilyId().equals(wife.getFamilyId())) {
System.out.println(husband.getUserName() + "爱" + wife.getUserName());
// 牵手成功,把女嘉宾从舞台请下来,同时换下一位男嘉宾上场
wives.remove(wife);
break;
}
}
}
System.out.println("----------------------");
System.out.println("循环了:" + count + "次");
} 输出结果:
梁山伯爱祝英台
牛郎爱织女
干将爱莫邪
工藤新一爱毛利兰
罗密欧爱朱丽叶
----------------------
循环了:5次
我们发现,循环次数从第二版的15次减少到了5次,因为牵手成功的女嘉宾都被请下舞台了:wives.remove(wife)。
如果说,第二版算法是打断wives的循环,那么第三版算法则是直接把wives请出场外。
总结一下第三版算法的优缺点。
- 优点:执行效率比第二版高了不少
- 缺点:理解难度稍微提升了一些,平均性能不高
我靠,这还有缺点啊?太牛逼了好吗,我都想不到。什么叫“平均性能不高”?
比如我现在把男嘉宾的出场顺序倒过来:
public static void main(String[] args) {
// 用于计算循环次数
int count = 0;
// 老公组,原先梁山伯第一个出场,现在换罗密欧第一个
List husbands = new ArrayList<>();
husbands.add(new Couple(5, "罗密欧"));
husbands.add(new Couple(4, "工藤新一"));
husbands.add(new Couple(3, "干将"));
husbands.add(new Couple(2, "牛郎"));
husbands.add(new Couple(1, "梁山伯"));
// 老婆组
List wives = new ArrayList<>();
wives.add(new Couple(1, "祝英台"));
wives.add(new Couple(2, "织女"));
wives.add(new Couple(3, "莫邪"));
wives.add(new Couple(4, "毛利兰"));
wives.add(new Couple(5, "朱丽叶"));
for (Couple husband : husbands) {
for (Couple wife : wives) {
// 记录循环的次数
count++;
if (husband.getFamilyId().equals(wife.getFamilyId())) {
System.out.println(husband.getUserName() + "爱" + wife.getUserName());
// 牵手成功,把女嘉宾从舞台请下来,同时换下一位男嘉宾上场
wives.remove(wife);
break;
}
}
}
System.out.println("----------------------");
System.out.println("循环了:" + count + "次");
} 输出结果
罗密欧爱朱丽叶
工藤新一爱毛利兰
干将爱莫邪
牛郎爱织女
梁山伯爱祝英台
----------------------
循环了:15次
循环次数从5次变成15次,和第二版算法是一样的。
这是怎么回事呢?
第一次是顺序遍历的:
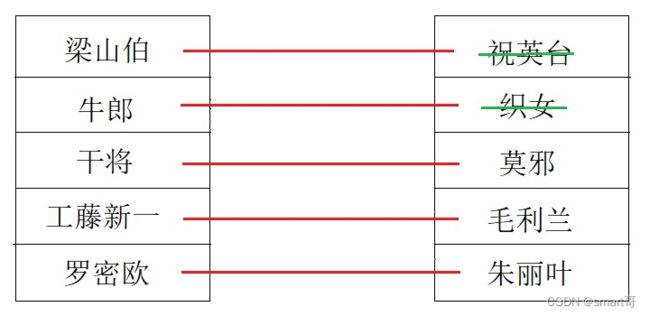
第一位男嘉宾梁山伯上场:遇到第一位女嘉宾祝英台,直接牵手成功。
第二位男嘉宾牛郎上来了,此时祝英台不在了,他遇到的第一位女嘉宾是织女,也直接牵手成功。
第三位男嘉宾干将上场后一看,这不是莫邪吗,也牵手成功走了。
...
但是颠倒顺序后:
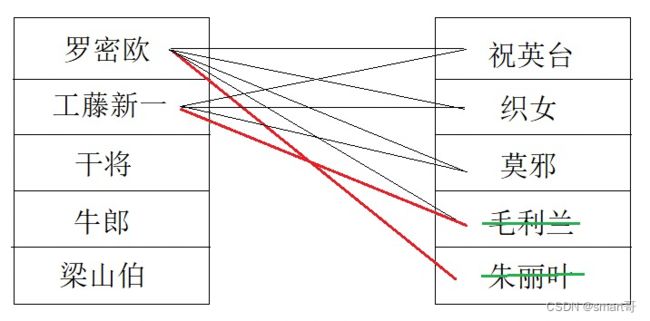
之前顺着来的时候,梁山伯带走了祝英台,牛郎出场就直接跳过祝英台了,这就是上一次循环对下一次循环的影响。
而这次,罗密欧错了4次以后终于带走了朱丽叶,但是工藤新一上场后,还是要试错3次才能找到毛利兰。提前离场的朱丽叶在毛利兰后面,所以罗密欧试错积累的优势无法传递给下一次循环。
对于某些算法而言,元素的排列顺序会改变算法的复杂度。在数据结构与算法中,对一个算法往往有三个衡量维度:
- 最好复杂度
- 平均复杂度
- 最坏复杂度
现实生活中,我们往往需要结合实际业务场景与算法复杂度挑选出合适的算法。
在本案例中,第三版算法在男嘉宾顺序时可以得到最好的结果(5次),如果倒序则得到最差的结果(15次)。
第四版算法
终于要向大家介绍第四种算法了。
第四种算法是一种复杂度一致的算法,无论男嘉宾的出场顺序如何改变,效率始终如一。
这是一种怎么样的算法呢?
不急,我们先思考一个问题:
我们为什么要用for遍历?
咋一听,好像有点莫名其妙。不用for循环,我怎么遍历啊?
其实无论何时,使用for都意味着我们潜意识里已经把数据泛化,牺牲数据的特性转而谋求统一的操作方式。想象一下,假设一个数组存了国家男子田径队的队员们,比如110米栏的刘翔、100米项目的苏炳添和谢震业。你如果写一个for循环:
for(sportsMan : sportsMen){
sportsMan.kualan();
}在循环中,你只能调用运动员身上的一项技能执行。
- 你选跨栏吧,苏炳添和谢震业不会啊...
- 你选100米短跑吧,刘翔肯定比不过专业短跑运动员啊...
所以,绝大多数情况下,for循环意味着抽取共同特性,忽略个体差异。好处是代码通用,坏处是无法发挥个体优势,最终影响效率。
回到案例中来。
每次男嘉宾上场后,他都要循环遍历女嘉宾,挨个问过去:你爱我吗?
哦,不爱。我问问下一位女嘉宾。
他为什么要挨个问?因为“女人心海底针”,他根本不知道哪位女嘉宾是爱他的,所以场上女嘉宾对他来说就是无差异的“黑盒”。
如果我们给场上的女嘉宾每人发一个牌子,让他们在上面写上自己喜欢的男嘉宾号码,那么男嘉宾上场后就不用挨个问了,直接找到写有自己号码的女嘉宾即可牵手成功。
这个算法的思想其实就是让数据产生差异化,外部通过差异快速定位目标数据。
public static void main(String[] args) {
// 用于计算循环次数
int count = 0;
// 老公组
List husbands = new ArrayList<>();
husbands.add(new Couple(1, "梁山伯"));
husbands.add(new Couple(2, "牛郎"));
husbands.add(new Couple(3, "干将"));
husbands.add(new Couple(4, "工藤新一"));
husbands.add(new Couple(5, "罗密欧"));
// 老婆组
List wives = new ArrayList<>();
wives.add(new Couple(1, "祝英台"));
wives.add(new Couple(2, "织女"));
wives.add(new Couple(3, "莫邪"));
wives.add(new Couple(4, "毛利兰"));
wives.add(new Couple(5, "朱丽叶"));
// 给女嘉宾发牌子
Map wivesMap = new HashMap<>();
for (Couple wife : wives) {
// 女嘉宾现在不在List里了,而是去了wivesMap中,前面放了一块牌子:男嘉宾的号码
wivesMap.put(wife.getFamilyId(), wife);
count++;
}
// 男嘉宾上场
for (Couple husband : husbands) {
// 找到举着自己号码牌的女嘉宾
Couple wife = wivesMap.get(husband.getFamilyId());
System.out.println(husband.getUserName() + "爱" + wife.getUserName());
count++;
}
System.out.println("----------------------");
System.out.println("循环了:" + count + "次");
} 输出结果
梁山伯爱祝英台
牛郎爱织女
干将爱莫邪
工藤新一爱毛利兰
罗密欧爱朱丽叶
----------------------
循环了:10次
此时无论你如何调换男嘉宾出场顺序,都只会循环10次。

男嘉宾出场后,无需遍历女嘉宾,直接“按图索骥”找到配偶
小结
第一版和第二版就不讨论了,我们只谈谈第三版和第四版代码。
假设两组数据长度分别是n和m:
第三版的循环次数是n ~ ![]()
,是波动的,最好效率是n,这是非常惊人的(最差效率同样惊人...)。
第四版始终是 n + m。
在数据量较小的情况下,其实两者差距不大,CPU执行时间差可以忽略不计。我们设想n, m=1000的情况。
此时第三版的循环次数是:1000 ~ ![]()
最好的结果是1000,固然可喜。但是最差的结果是1000+999+...+1=500500。
而此时第四版的循环次数是 1000+1000=2000,与第三版最好的结果相比也只差了1000次而已,对于CPU而言可以忽略不计。
考虑到实际编程中,数据库的数据往往是非常杂乱的,使用第三版算法几乎不可能得到最大效率。
所以推荐使用第四版算法。
它的精髓就是利用HashMap给其中一列数据加了“索引”,每个数据的“索引”(Map的key)是不同的,让数据差异化。
了解原理后,如何掌握这简单有效的小算法呢?
记住两步:
- 先把其中一列数据由线性结构的List转为Hash散列的Map,为数据创建“索引”
- 遍历另一列数据,依据索引从Map中匹配数据
相比第三版在原有的两个List基础上操作数据,第四版需要额外引入一个Map,内存开销稍微多了一点点。算法中,有一句特别经典的话:空间换时间。第四版勉强算吧。但要清楚,实际上Couple对象并没有增多,Map只是持有原有的Couple对象的引用而已。新增的内存开销主要是Map的索引(Key)。
请大家务必掌握这个小算法,后面很多地方会用到它。
拓展思考
我们都知道,实际开发中我们从数据库查询得到的数据都是由Mapper封装到单个List中,也就是说不具备“两个数据集合匹配”这种前提呀。
此时转换一下思维即可,比如前端要全量获取城市,而且是二级联动:
|-浙江省
|-杭州市
|-宁波市
|-温州市
|-...
|-安徽省
|-合肥市
|-黄山市
|-芜湖市
|-...
而数据库查出来的是:
id name pid
1 浙江省 0
2 杭州市 1
3 宁波市 1
4 温州市 1
5 安徽省 0
6 合肥市 5
7 黄山市 5
8 芜湖市 5
此时,List需要“自匹配”。
我们可以把“自匹配”转为“两个数据集合匹配”(List转Map,然后List和Map匹配):
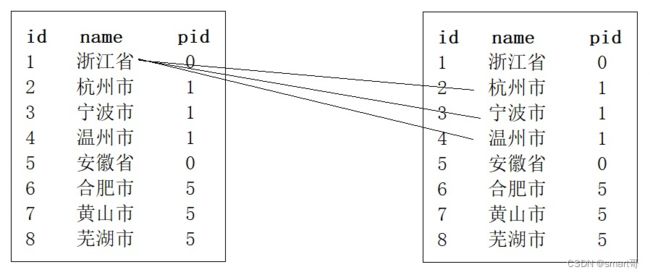
是不是觉得似曾相识呀。
上面这种情况属于自关联匹配,强行把同一张表的数据当成两个数据通过id和pid匹配。而实际开发中,更为常见的是两张表的数据匹配:

因为有些公司不允许过多的JOIN查询,此时就只能根据主表先把分页的10条数据查出来,再根据主表数据的ids把从表的10条数据查出来,最后在内存中匹配。(其实对于10条数据,用for循环也没问题)
尝试封装工具类
很多时候,我们只是想做一下List转Map,写一大串Stream确实挺烦的,此时可以考虑专门封装一个转换类:
public class ConvertUtil {
private ConvertUtil() {
}
/**
* 将List转为Map
*
* @param list 原数据
* @param keyExtractor Key的抽取规则
* @param Key
* @param Value
* @return
*/
public static Map listToMap(List list, Function keyExtractor) {
if (list == null || list.isEmpty()) {
return new HashMap<>();
}
Map map = new HashMap<>(list.size());
for (V element : list) {
K key = keyExtractor.apply(element);
if (key == null) {
continue;
}
map.put(key, element);
}
return map;
}
/**
* 将List转为Map,可以指定过滤规则
*
* @param list 原数据
* @param keyExtractor Key的抽取规则
* @param predicate 过滤规则
* @param Key
* @param Value
* @return
*/
public static Map listToMap(List list, Function keyExtractor, Predicate predicate) {
if (list == null || list.isEmpty()) {
return new HashMap<>();
}
Map map = new HashMap<>(list.size());
for (V element : list) {
K key = keyExtractor.apply(element);
if (key == null || !predicate.test(element)) {
continue;
}
map.put(key, element);
}
return map;
}
/**
* 将List映射为List,比如List personList转为List nameList
*
* @param originList 原数据
* @param mapper 映射规则
* @param 原数据的元素类型
* @param 新数据的元素类型
* @return
*/
public static List resultToList(List originList, Function mapper) {
if (originList == null || originList.isEmpty()) {
return new ArrayList<>();
}
List newList = new ArrayList<>(originList.size());
for (T originElement : originList) {
R newElement = mapper.apply(originElement);
if (newElement == null) {
continue;
}
newList.add(newElement);
}
return newList;
}
/**
* 将List映射为List,比如List personList转为List nameList
* 可以指定过滤规则
*
* @param originList 原数据
* @param mapper 映射规则
* @param predicate 过滤规则
* @param 原数据的元素类型
* @param 新数据的元素类型
* @return
*/
public static List resultToList(List originList, Function mapper, Predicate predicate) {
if (originList == null || originList.isEmpty()) {
return new ArrayList<>();
}
List newList = new ArrayList<>(originList.size());
for (T originElement : originList) {
R newElement = mapper.apply(originElement);
if (newElement == null || !predicate.test(originElement)) {
continue;
}
newList.add(newElement);
}
return newList;
}
// ---------- 以下是测试案例 ----------
private static List list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
Map nameToPersonMap = listToMap(list, Person::getName);
System.out.println(nameToPersonMap);
Map personGt18 = listToMap(list, Person::getName, person -> person.getAge() >= 18);
System.out.println(personGt18);
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
} 大家还可以继续自行扩展哟~
比如,现在的listToMap()方法只支持 key:object,如果我希望是key:field,该怎么封装呢?(答案见评论区)
部分同学可能会觉得有点难,甚至会有一系列疑问:这参数什么意思啊?哪来的接口?写法好诡异…等等,这是因为缺少泛型和Java8的相关知识。不要慌,暂时有个印象即可,我们会在学习Java8新特性后再复习上面这段代码。
留个坑
我在第三版算法中留了一个坑,但它是隐性的,刚好这个场景下不会暴露。大家可以试着把第三版的break去掉,看看会不会出问题。
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
进群,大家一起学习,一起进步,一起对抗互联网寒冬