Hive 学习历程
Hive 学习历程
使用Hive时需要打开Hadoop集群以及hiveserver
这里可以使用脚本来打开
[hadoop@node02 ~]$ all.sh start
[hadoop@node02 ~]$ hvservice.sh start
等待一段时间后,hiveserver2启动完成
远程连接sql数据库
[hadoop@node02 ~]$ beeline
beeline>!connect jdbc:hive2://node02:10000
Connecting to jdbc:hive2://node02:10000
Enter username for jdbc:hive2://node02:10000: hadoop
Enter password for jdbc:hive2://node02:10000: ******* #这里的密码是当初设置的密码:000000
1 数据库DDL
数据库操作一般是运维人员操作,数仓开发人员了解即可。
1.1 查看数据库
-- 查看数据库列表
show databases;
-- 使用like关键字模糊匹配,显示包含db前缀的数据库名称
show databases like 'db_*';
1.2 使用数据库
-- 切换到指定数据库
use db_name;
1.3 创建数据库
-- 创建数据库
create database db_name;
-- 创建数据库到指定路径
create database db_name location 'path路径'; #路径以HDFS的具体路径为主
-- 给数据库添加描述信息
create database db_name comment 'db_name描述信息';
1.4 删除数据库
-- 删除数据库(此删除方式,需要将数据库中的表全部删除,才能删除数据库)
drop database db_name;
或者
drop database if not exists db_name;
-- 强制删库(慎用,最好不用!!)
drop database db_name cascade;
1.5 查看数据库的详细描述信息
-- 查看数据库描述
desc database db_name;
1.6 数据库键值对信息
-- 创建带键值对的数据库
create database db_name with dbproperties ('own' = 'cc','day' = '20230324');
-- 查看数据库的键值对信息
desc database extended db_name;
-- 修改数据库的键值对信息
alter database db_name set dbproperties ('k1' = 'v1','k2' = 'v2');
2 数据表DDL
2.1 普通建表
create table test_1(id int comment 'id',name string comment 'xxx')
comment 'student table 1'
-- 列表分隔格式(常见的四种形式)
row format delimited fields terminated by '\t' -- 列分隔符
row format delimited collection items terminated by '_'-- STRUCT 和 ARRAY 的分隔符
row format delimited map keys terminated by ':' -- MAP中的key和value的分隔符
row format delimited lines terminated by '\n' -- 行分隔符
tblproperties('aaa'='bbb');
2.2 根据查询结果建表
create table xxx_table as
select name,
id
from test_1;
2.3 拷贝表结构
create table xxx_table like test_1;
2.4 查询表列表
show tables;
2.5 查询表结构
desc test_1;
2.6 查询更详细的信息
desc formatted test_1;
2.7 修改表 (#一般很少用到)
2.7.1 重命名
-- 重命名表格
alter table stu1 rename to stu2;
2.7.2 修改列

-- 修改列信息
alter table stu2 change column id id_stu bigint comment 'id_stu';

2.7.3 追加列信息
alter table stu2 add columns (age int comment 'stu_age',sex string comment 'stu_sex');

2.7.4 替换列信息
alter table stu2 replace columns (id string comment 'haha',age double comment 'jj');

2.7.5 删除表
-- 删除整个表
drop table stu2;
-- 删除表数据但表还在
truncate table stu2;
3 Hive DML
3.1 导入数据
-- 从本地系统将数据导入到表中
load data local inpath '/opt/module/hive-3.1.2/datas/test.txt' into table stu3; #重复此操作不会覆盖原数据,只会不断的导入数据到表中
-- 从本地系统中将数据覆盖地导入到表中
load data local inpath '/opt/module/hive-3.1.2/datas/test.txt' overwrite into table stu3;
-- 从HDFS中将数据导入到表中(覆盖地导入)
load data inpath '/user/datas/test.txt' overwrite into table stu3;
-- insert 插入
insert into stu4 values (1001,'zhangsan'),(1002,'lisi'); #太慢了,一般不会这样使用
-- insert 查询结果(最常用的,要记住)
insert into stu4 select id,name from stu3 where id < 1001;
-- insert 查询结果(覆盖掉原数据)
insert overwrite table stu4 select id,name from stu3 where id < 1001;
-- 不常用的方法
-- as select
create table stu4 as select * from stu4;
-- 通过location指定地址加载数据
-- 首先将数据上传到hdfs的文件目录:/user/hive/warehouse
create table stu5 (id int,name string)
row format delimited fields terminated by '\t'
location '/user/hive/warehouse';
3.2 导出数据 (基本不用,谁没事从hive导出数据)
-- insert 导出数据 (还可以指定格式导出)
-- 导出数据到本地
insert overwrite local directory '/opt/module/hive-3.1.2/datas/test'
row format delimited fields terminated by '\t'
select id,name from stu4;
-- 导出数据到hdfs
insert overwrite directory '/test'
row format delimited fields terminated by '\t'
select id,name from stu4;
-- import export (在hdfs上操作)
-- 迁移整个hive数据库的时候有用
export table stu4 to '/stu_out'; #将stu4的所有数据(表数据和元数据)导出到hdfs中
import table stu_in from '/stu_out'; #将hdfs上stu_out的表数据导入到表stu_in中
4 内部表和外部表
-- 普通的建表(管理表)
create table stu5 (id int,name string) row format delimited fields terminated by '\t';
-- 创建外部表
create external table stu5_ex (id int,name string) row format delimited fields terminated by '\t';
-- 向内部表中插入数据
insert into stu5 select id,name from stu4;
-- 删除内部表时,数据会一起删除
drop table stu5;
-- 删除外部表时,数据不会删
drop table stu5_ex;
-- 外部表和内部表的转换
create table stu5_ex (id int,name string) row format delimited fields terminated by '\t';
-- 通过修改表将内部表转换为外部表(key value都要大写)
alter table stu5_ex set tblproperties('EXTERNAL'='TURE');
-- 通过修改表将外部表转换为内部表
alter table stu5 set tblproperties('EXTERNAL'='FALSE');
5 基本查询和分组过滤
查询顺序:
SELECT -->FROM -->WHERE -->GROUP BY -->HAVING -->ORDER BY …
SQL的执行顺序:
FROM -->JOIN -->ON -->WHERE -->GROUP BY -->AVG SUM 等聚合函数 -->HAVING -->计算所有表达式 -->SELECT -->DISTINCT -->ORDER BY -->LIMIT …
HIVE的执行顺序:
FROM --> ON --> JOIN --> WHERE --> GROUP BY --> HAVING -->SELECT --> DISTINCT --> DISTRIBUTE BY --> CLUSTER BY --> SORT BY --> ORDER BY --> LIMIT --> UNION/UNION ALL
Hive的执行顺序也是MapReduce的执行顺序:
map阶段:
1.执行from加载,进行表的查找与加载
2.执行where过滤,进行条件过滤与筛选
3.执行select查询:进行输出项的筛选
4.执行group by分组:描述了分组后需要计算的函数
5.map端文件合并:map端本地溢出写文件的合并操作,每个map最终形成一个临时文件。 然后按列映射到对应的Reduce阶段:
reduce阶段:
1.group by:对map端发送过来的数据进行分组并进行计算。
2.select:最后过滤列用于输出结果
3.limit:限制输出的行数,排序后进行结果输出到HDFS文件
5.1 基本查询
用如下两张表进行操作:

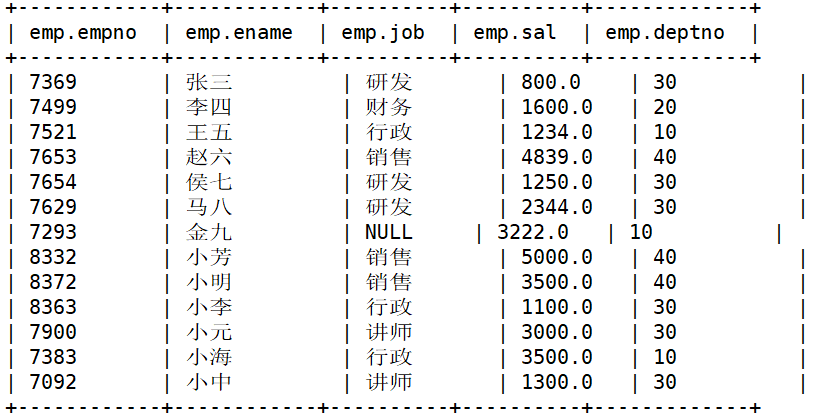
-- 查询特定列
select sal,ename from emp;
-- 起别名,as可以省略
select ename as name,sal salary from emp; -- 与上一行输出结果一致,不过属性名不一样
-- 查询中可以使用算数运算符
select ename,sal + 10 from emp;
-- 常用函数(UDAF),UDAF函数执行的时候,NULL不参与运算
select count(1) cnt, -- 数个数
sum(sal) sum_sal,
avg(sal) avg_sal,
min(sal) min_sal,
max(sal) max_sal
from emp;
-- count(1) 的用法
select 1 from emp;
相当于数行的个数,新开一列,数1的个数
-- limit用法
-- 显示前5
select ename from emp limit 5;
-- 显示2-5名(从0开始计数)
select ename from emp limit 1,4;
-- 过滤 查询工资大于1000的人
select ename from emp where sal>1000;
-- 查询工资在1600-3000的人
select ename,sal from emp where sal between 1600 and 3000; -- 左闭右闭区间
-- 查询工资为1600,3000的人
select ename,sal from emp where sal in (1600,3000); -- 类似集合
-- = 与 <=>(安全等于号) 的区别
select ename,job from emp where job = null;
-- <=>安全等于号
select ename,job from emp where job <=> null;

-- 字符串(通配符)
select ename,job from emp where ename like '张%';
-- 字符串(正则表达式)
-- A rlike B ,B是基于Java的正则表达式
select ename,job from emp where ename rlike '^张';
-- 上述两个语句输出结果一致
5.2 分组查询 GROUP BY
-- 查询各个部门的平均工资
select deptno,avg(sal) avg_sal from emp group by deptno;
-- 查询平均工资大于2000的部门及其平均工资
select deptno,avg(sal) avg_sal from emp group by deptno having avg_sal>2000;
5.3 连接
-- 查询员工姓名以及员工所属部门名称
-- 默认inner join内连接
select emp.ename,dept.dname from emp join dept on emp.deptno = dept.dept.no;
select emp.ename,dept.dname from emp inner join dept on emp.deptno = dept.dept.no; -- 效果一样

Hive 尽量写等值连接,等值连接效率高很多,如果用join……where……效率会低,在SQL中无所谓。
-- 向emp和dept两张表插入数据来演示不同的连接效果
insert into emp values(7498,'jason','学生',NULL,50);
insert into dept values(60,'不存在',1700);
-- 内连接
select emp.ename,dept.dname from emp join dept on emp.deptno = dept.deptno;

-- 左连接
select emp.ename,dept.dname from emp left join dept on emp.deptno = dept.deptno;

-- 右连接
select emp.ename,dept.dname from emp right join dept on emp.deptno = dept.deptno;

从以上三个连接的结果可以看出,
内连接的结果是输出两张表都存在的内容,
左连接输出结果包含连接表不存在的内容,
右连接输出结果包含被连接表不存在的内容。
-- 全连接
select emp.ename,dept.dname from emp full join dept on emp.deptno = dept.deptno;

全连接输出结果包含两张表都不存在的内容
-- 多表连接
-- 查询员工姓名,员工部门,部门地点
select e.ename,d.dname,l.loc_name
from emp e
join dept d on e.deptno = d.deptno
join location l on d.loc = l.loc;

-- 笛卡尔积(不写查询条件就会生成笛卡尔积)
select * from emp join dept;
5.4 排序
降序——desc 升序——asc 默认升序排序
-- 按照工资从高到低给员工排序
select * from emp order by sal desc;
-- 也可以对别名进行排序
select ename,sal salary from emp order by salry desc;
-- 二次排序
-- 先按照部门编号升序排序,同部门按照工资降序排序
select * from emp order by dept asc,sal desc;
-- 分组排序
-- 按照部门平均工资降序给部门排序
select deptno,avg(sal) avg_sal from emp group by deptno order by avg_sal desc;
-- 以上是全局排序,全局排序在数据量大的时候会遇到性能问题,因为做全排序时map不做分区,这时解决方法最好是搭配limit使用
-- 原因:每个map只输出前几条数据,reduce的时候压力没那么大
select * from emp order by sal desc limit 10;
分区和分区排序(hive特有)
-- 首先设置reduce数量,默认值为-1(即hive动态估算数据量来自行设置reduce数量)
set mapreduce.job.reduces = 3;
-- distribute by 指定查询按照什么字段的hash值分区
-- sort by 在分区内部排序
select * from emp distribute by deptno sort by sal desc;
-- 当 distribute by 和 sort by字段相同且为升序时,可以用cluster by代替
-- 如下两个语句的输出内容一致
select * from emp disttibute by deptno sort by deptno;
select * from emp cluster by deptno;
6 HIVE 函数
6.1 系统自带函数的查询和使用
-- 查询所有系统函数
show functions;
-- 查询包含特定关键字的函数
show functions like "*date*";
-- 查询特定函数的使用方法
desc function 'current_date';
-- 查询特定函数更详细的使用方法
desc function extended 'current_date';
-- 其他函数使用建议百度
6.2 常用函数——空值替换
-- 在emp表中存在空值
-- 两个输入
-- nvl(col,default_value) 如果col不为null,返回col,否则返回default_value
select ename,job,nvl(job,'没工作') from emp;
-- 多个输入
-- coalesece(col1,col2,col3,....) 从左到右找第一个不为null的值
select ename,job,sal,coalesce(job,sal,'nothing') from emp;

6.3 常用函数——分支控制
-- if (boolean,result1,result2) 如果boolean为真,返回result1,否则返回result2
-- case col
-- when value1 then result1
-- when value2 then result2
-- else result3
-- end
-- 如果col值为value1,返回result1;若值为value2,返回result2,否则返回result3
-- case when
-- boolean1 then result1
-- boolean2 then result2
-- else result3
-- end
-- 如果boolean1为真,返回result1;若boolean1为假,boolean2为真,返回result2;否则返回result3
对如下表进行操作
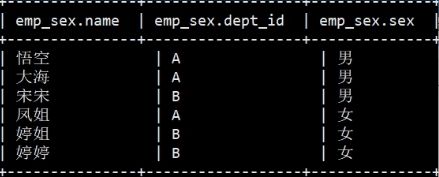
-- 求每个部门的男女人数个多少人 (if用法)
select dept_id,
count(name) cnt,
count(if(sex='男',name,null)) male,
count(if(sex='女',name,null)) female
from emp_sex
group by dept_id;
-- 求每个部门的男女人数个多少人 (case用法)
select dept_id,
count(case when sex='男' then name else null end) male,
count(case when sex='女' then name else null end) female
from emp_sex
group by dept_id;

6.4 行转列和列转行
- 行转列
对如下表进行操作


-- collect_set(col) collect_list(col)
-- 这两个函数都是聚合函数,将属于同一组的col的值聚合成一个数组,set会去重,list不会去重
select constellation,
blood_type,
collect_list(name) names
from person_info
group by constellation,blood_type;
-- 会出现如下效果,但还是达不到需求

-- 字符串拼接
-- concat(v1,v2,v3,...) 将输入的多列拼成一列字符串输出v1v2v3...
-- concat_ws(sep,array|v1,v2,v3,...) 将数组内的多个元素拼成字符串,按照sep分隔
select concat(constellation,',',blood_type) xzxx,
concat_ws('|',collect_list(name)) names
from person_info
group by constellation,blood_type;
-- 最终输出结果会满足需求
-
列转行
对如下表进行操作

-- explode(array/map) UDTF函数,可以将一行输入变成多行多列
-- 如果数据的参数是array,结果只有一列;如果数据的参数是map,结果有key,value两列
-- split(str,sep) 将字符串按照sep分成字符串数组
select explode(split(category,',')) from movie_info;
-- 输出结果如下:

-- 列转行:lateral view (列转行固定写法,要背下来)
-- 将原表和UDTF结合查询
select m.movie,
tbl.category_id
from movie_info m
lateral view explode(split(category,',')) tbl as category_id;
-- 使用lateral view一定要写新的表名和列名,生成一列就写一列,生成两列就写两列
7 窗口函数

7.1 给聚合函数开操作的状况(在明细查询中,展现汇总结果)
-
使用如下表

-
需求1:查询在2017年4月份购买过的顾客及总人数
-
-- substring(str,pos,len) 返回str字符串从pos(下标从1开始)位置开始长度为len的字串 -- 若想查询2017年4月购买过的人 select distinct name from business where substring(orderdate,1,7) = '2017-04'; -- 若想求2017年4月购买过的人数 select count(distinct name ) from business where substring(orderdate,1,7) = '2017-04'; -- 将两个结果放在一张表里 select distinct name count(distinct name) over() from business where substring(orderdate,1,7) = '2017-04';
-
需求2:查看顾客的购买明细及月购买总额
-
select name, orderdate, cost sum(cost) over(partition by substring(orderdate,1,7)) month_total from business;
-
需求3:查询每个顾客的截止到当日的累计消费
-
select name, orderdate, cost, sum(cost) over(partition by name order by orderdate rows between unbounded preceding and current row) -- 本组的第一行到当前行 from business;-
需求4:查询每个顾客当天与前一天的累计消费
-
select name, orderdate, cost, sum(cost) over(partition by name order by orderdate rows between 1 preceding and current row) from business;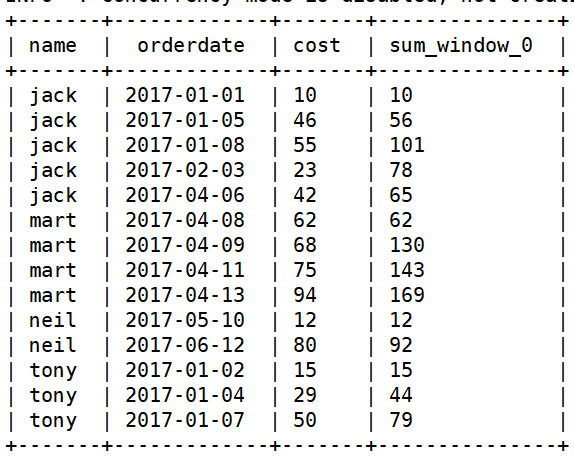
需求5:查询累计到店消费的人
select name,orderdate,cost, collect_set(name) over(order by orderdate rows between unbounded preceding and current row) from business;

-
-
7.2 其他结合有序窗口使用的函数(有序排序相关)
-
lag/lead
-- lag(col, n, default_value) over(有序窗口) -- 显示col这一列n行之前的数据,如果没有,展示default_value -- lead(col, n, default_value) over(有序窗口) -- 显示col这一列n行之后的数据,如果没有,展示default_value-- 查询购买明细和每个人上一次的到店时间 select name,orderdate,cost, lag(orderdate,1,'null') over(partition by name order by orderdate) last_order from business;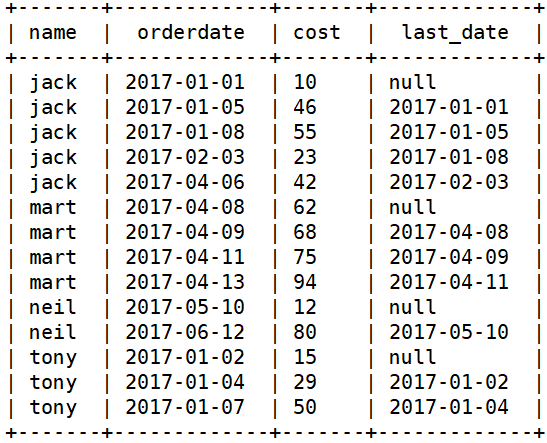
select name,orderdate,cost, lead(orderdate,1,'null') over(partition by name order by orderdate) from business;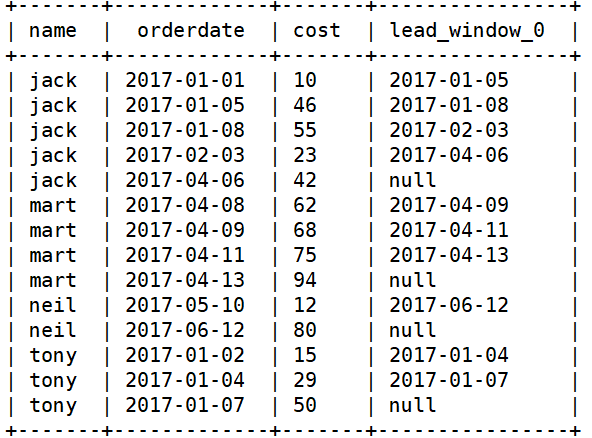
-
ntile
-- ntile(n) over(有序窗口) -- 将数据分为n组,返回当前行的组号-- 将订单明细按照下单时间分5组 select name,orderdate,cost,ntile(5) over(order by orderdate) from business;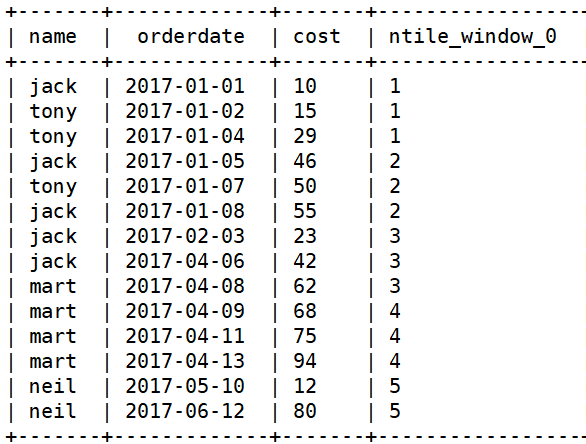
-
rank()/dense_rank()/row_number()
-- rank() over(有序窗口) -- rank 是我们常见的排序,生成数据项在分组中的排名,排名相等会在名次中留下空位 -- dense_rank 生成数据项在分组中的排名,排名相等会在名次中留下空位 -- row_number 是行号-- 各科成绩排名 select name,subject,score, rank() over(partition by subject order by score desc) 'rank', dense_rank() over(partition by subject order by score desc) 'dense_rank', row_number() over(partition by subject order by score desc) 'row_number' from score; -
first_value/last_value
-- first_value(col,boolean) over(有序窗口) -- boolean为false,返回这个窗口中col的第一行,boolean为true,返回这个窗口中col不为null的第一行 -- last_value(col,boolean) over(有序窗口) -- boolean为false,返回这个窗口中col的最后一行,boolean为true,返回这个窗口中col不为null的最后一行-- 查询business表明细,以及截止消费当日每人的第一笔和最后一笔大于50元的消费日期 select name, orderdate, cost, if(cost>50,orderdate,null), first_value(if(cost>50,orderdate,null),true) over(partition by name order by orderdate rows between unbounded preceding and current row) fir, last_value(if(cost>50,orderdate,null),true) over(partition by name order by orderdate rows between unbounded preceding and current row) las from business;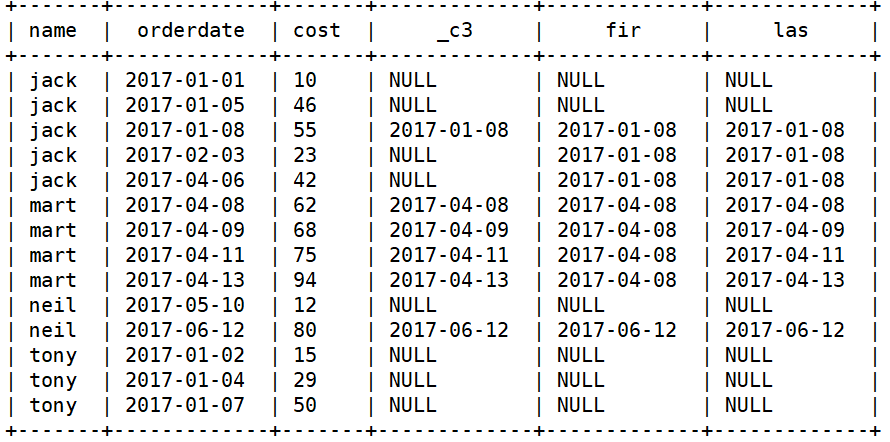
7.3 其他常用函数
-
日期相关函数
-- current_date() 返回当前日期 select current_date(); -- date_add(date,n) 返回从date开始n天之后的日期 select date_add(current_date(),1); -- date_sub(date,n) 返回从date开始n天之前的日期 select date_sub(current_date(),1); -- datediff(date1,date2) 返回date1-date2的日期差 select datediff(current_date(),'2022-04-05');-- year(date) 返回日期的年份 -- month(date) 返回日期的月份 -- day(date) 返回日期的日 -- dayofweek(date) 返回星期几(星期天是第一天) -- weekofyear(date) 返回日期在该年的第几周 -
取整相关函数
函数声明 解释 演示 ceil(num) 向上取整 select ceil(5.1); 结果返回6 floor(num) 向下取整 select floor(5.1); 结果返回5 round(num) 四舍五入 select round(5.5); 结果返回6 -
复杂类型包装函数
函数声明 解释 str_to_map(str,field_sep,kv_sep) 将str按照field_sep分段,再按照kv_sep分成key value ,返回一个map named_struct(name1,col1,name2,col2,…) 将col1,col2,…包装为结构体,名称为name1,name2,… -- str_to_map(str,field_sep,kv_sep) select str_to_map('a:b,c:d,e:f',',',':'); -- named_struct(name1,col1,name2,col2,...) select named_struct('name_1',name,'haha',orderdate) from business;
7.4 自定义函数
基本不需要,hive的函数能满足99%的业务需求,自己写函数基本都写UDF函数
-
UDF函数(User-Defined-Function)
一进一出
-
UDTF函数(User-Defined Table-Generating Function)
用户自定义表生成函数,一进多出
如:lateral view explode()
-
UDAF函数(User-Defined Aggregation Function)
用户自定义聚合函数,多进一出
如:count、max、min
7.5 与时间相关的函数
- date_format
date_format(date/timestamp/string,fmt) -- 将一个date/timestamp/string变量转化为fmt的格式
fmt:"yyyy-MM-dd HH:mm:ss"
select date_format(current_time(),"yyyy/MM");
-
current_timestamp
current_timestamp() -- 显示sql执行时的时间戳select current_timestamp(); -
from_unixtime
from_unixtime(unix_time,format) -- 将long型数据,单位为秒,转换为format格式的时间戳select from_unixtime(1655595312,'yyyy-MM-dd'); -
from_utc_timestamp
from_utc_timestamp(timestamp,string timezone) -- 假设给定timestamp是UTC时间,转换到timezone时区select from_utc_timestamp(current_time(),'GMT+'); -
to_unix_timestamp / unix_timestamp
unix_timestamp(date[,pattern]) -- 将时间类型转换为long型,单位为秒 如果date是标准类型,符合"yyyy-MM-dd HH:mm:ss",可以直接转换 否则需要pattern声明类型select to_unix_timestamp(current_timestamp()); -
to_utc_timestamp
to_utc_timestamp(timestamp,string timezone) -- 假设给定timestamp是timezone时区,将其转化为UTC时间select to_utc_timestamp(current_time(),'GMT+09:00');
8 分区表和分桶表
8.1 分区表
-- 创建分区表
create table dept_partition(
deptno int,
dname string,
loc int)
partitioned by (dt string) -- 与普通建表区别在此
row format delimited fields terminated by '\t';
-- 导入数据(load)
load data local inpath '/opt/module/hive-3.1.2/datas/dept.txt'
into table dept_partition
partition(dt='2023-04-05'); -- 与普通导入的区别在此
-- 插入数据(insert)
insert overwrite table dept_partition partition(dt='2023-04-06') -- 可插入到不同的分区
select deptno,dname,loc from dept;
-- 另一种插入方法
insert overwrite table dept_partition
select deptno,dname,loc,'2022-04-07' from dept;


分区表就是将一张大表分成不同的文件夹去管理
-- 查询分区表的分区数
show partitions dept_partition;
-- 分区过滤查询
select * from dept_partition where dt='2023-04-05';
-- 直接对分区表的分区进行操作
-- 添加分区
alter table dept_partition add partition(dt='2023-04-08');
alter table dept_partition add partition(dt='2023-04-09') partition(dt='2023-04-10');
-- 删除分区
alter table dept_partiton drop partition(dt='2023-04-10');
alter table dept_partiton drop partition(dt='2023-04-10'),partition(dt='2023-04-09');
-- 注意:直接在分区表数据目录里面建立文件夹,分区表不能直接识别,因为每一个分区都有元数据记录
-- 解决方法
-- 方案一:add partition
-- 方案二:官方修复分区表的命令
msck repair table dept_partition;
8.2 二级分区表
-- 建表
create table dept_partition2(
deptno int,
dname string,
loc int)
partitioned by (month string,day string) -- 与普通分区表区别在此
row format delimited fields terminated by '\t';
-- 导入数据
load data local inpath '/opt/module/hive-3.1.2/datas/dept.txt' into table dept_partition2 partition(month='2023-04',day='05'); -- 父目录和子目录
-- 插入数据
insert overwrite table dept_partition2 partition(month='2023-04',day='05')
select deptno,dname,loc from dept;
-- 二级分区表的操作与一级分区表的操作类似,只不过需要指定所有级别的分区

8.3 动态分区
普通表格无法直接转换成分区表,只能先建新的分区表,再将旧数据插入这个新的分区表
-- 例:将business表转化为按照orderdate分区的分区表
-- 1、新建分区表
create table bus_par(
name string,
cost int
) partitioned by (orderdate string)
row format delimited fields terminated by '\t';
-- 2、插入数据:
-- 方法一:一次一次插入
insert into bus_par partition(orderdate='2022-04-06')
select name,cost from business where orderdate='2022-04-06';
-- 方法二:动态分区一次搞定
insert into bus_par
select name,cost,orderdate from business;
-- 分区号一定要写在最后
- 分区表的好处
- 一般数据量很大的表格,我们按照分区存储
- 分布表按照分区过滤时,可以减少数据扫描量
- 一般来说,在生产环境中,只要是分区表,尽量不要做全表扫描
8.4 分桶表
-- 建表
create table bus_buck(
name string,
orderdate string,
cost int)
clustered by (cost) sorted by (cost) into 4 buckets
row format delimited fields terminated by '\t';
-- 向分桶表中插入数据,一般不要load,因为在一个分布式系统中导入一个本地的数据,很容易出问题。如果要用load,也要用HDFS上的文件
load data inpath '/test/business' into table bus_buck;
-- 最好用insert插入
insert overwrite into bus_buck
select * from business;
-- 既分区也分桶
create table bus_par_buck(
name string,
ordate string,
cost int)
partitioned by (dt string)
clustered by (cost) sorted by (cost) into 4 buckets
row format delimited fields terminated by '\t';
-- 插入数据
insert into bus_par_buck
select name,cost,orderdate,'2022-04-05' from business;
注意:
- 必须先分区再分桶,建表语序也是先写分区再写分桶
- 分区是将表拆分成不同的文件夹下的表进行管理,分桶是将表分成不同的表
9 HIVE文件存储
9.1 文件存储格式
Apache Hive支持Apache Hadoop中使用的几种熟悉的文件格式,如TextFile,RCFile,SequenceFile,AVRO,ORC和Parquet格式。在建表时使用STORED AS (TextFile|RCFile|SequenceFile|AVRO|ORC|Parquet)来指定存储格式。
- TextFile每一行都是一条记录,每行都以换行符(\ n)结尾。数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
- SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。
- RCFile是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
- ORC文件格式提供了一种将数据存储在Hive表中的高效方法。这个文件系统实际上是为了克服其他Hive文件格式的限制而设计的。Hive从大型表读取,写入和处理数据时,使用ORC文件可以提高性能。(主要用ORC存储方式)
- Parquet是一个面向列的二进制文件格式。Parquet对于大型查询的类型是高效的。对于扫描特定表格中的特定列的查询,Parquet特别有用。Parquet使用压缩Snappy,gzip;目前Snappy默认。
- AVRO是开源项目,为Hadoop提供数据序列化和数据交换服务。Avro是一种用于支持数据密集型的二进制文件格式。它的文件格式更为紧凑,若要读取大量数据时,Avro能够提供更好的序列化和反序列化性能。
9.1.1 列式存储和行式存储

9.2 数据压缩
为了节省集群磁盘的存储资源,数据一般都是需要压缩的,目前在 Hadoop 中用的比较多的有 lzo、gzip、snappy、bzip2。
那么是否选择文件压缩呢?在hadoop作业执行过程中,job执行速度更多的是局限于I/O,而不是受制于CPU。如果是这样,通过文件压缩可以提高hadoop性能。然而,如果作业的执行速度受限于CPU的性能,那么压缩文件可能就不合适,因为文件的压缩和解压会花费掉较多的时间。当然确定适合集群最优配置的最好方式是通过实验测试,然后衡量结果。

-- 建表建议数据格式
stored as orc
tblproperties('orc.compress'='SNAPPY');
10 性能调优
10.1 explain查看SQL执行过程
Hive提供的执行计划目前可以查看的信息有以下几种(只列出常见常用的):
(1)explain:查看执行计划的基本信息。
(2)explain dependency :dependency在explain语句中使用,会产生有关计划中输入的额外信息,它显示了输入的各种属性。
(3)explain authorization:查看SQL操作相关权限的信息。通过explain authorization可以知道当前SQL访问的数据来源(INPUTS)和数据输出(OUTPUTS),以及当前Hive的访问用户(CURRENT_USER)和操作(OPERATION)。

(4)explain vectorization:查看SQL的向量化描述信息。


(5)explain extended:加上 extended 可以输出有关计划的额外信息。这通常是物理信息,例如文件名,这些额外信息对我们用处不大。
explain的用法
【功能说明】:Hive提供了explain命令来展示一个查询的执行计划,这个执行计划对于我们了解底层原理、Hive 调优、排查数据倾斜等很有帮助。
使用语法如下:explain query;
【代码示例】:
-- 代码1:
explain select sum(price) as total_price from olist_order_items_dataset;
--代码2:
explain select product_id,sum(price) as total_price from olist_order_items_dataset group by product_id order by product_id desc limit 5;
【执行结果】:
代码1的执行结果:

代码2的执行结果:

【输出说明】:一个HIVE查询被转换为一个由一个或多个stage组成的序列(有向无环图DAG)。这些stage可以是MapReduce stage,也可以是负责元数据存储的stage,也可以是负责文件系统的操作(比如移动和重命名)的stage。
我们将上述结果拆分看,先从最外层开始,包含两个大的部分:
(1) stage dependencies:各个stage之间的依赖性;
(2) stage plan:各个stage的执行计划
详细说明:
先看第一部分stage dependencies,包含两个stage,Stage-1是根stage,说明这是开始的stage,Stage-0依赖 Stage-1,Stage-1执行完成后执行Stage-0。
再看第二部分 stage plan,里面有一个 Map Reduce,一个MR的执行计划分为两个部分:
(1)Map Operator Tree:MAP端的执行计划树
(2)Reduce Operator Tree:Reduce端的执行计划树
这两个执行计划树里面包含这条sql语句的 operator:
(1)TableScan:表扫描操作,map端第一个操作肯定是加载表,所以就是表扫描操作,常见的属性:
Ø alias:表名称
Ø Statistics:表统计信息,包含表中数据条数,数据大小等
(2)Select Operator:选取操作,常见的属性 :
Ø expressions:需要的字段名称及字段类型
Ø outputColumnNames:输出的列名称
Ø Statistics:表统计信息,包含表中数据条数,数据大小等
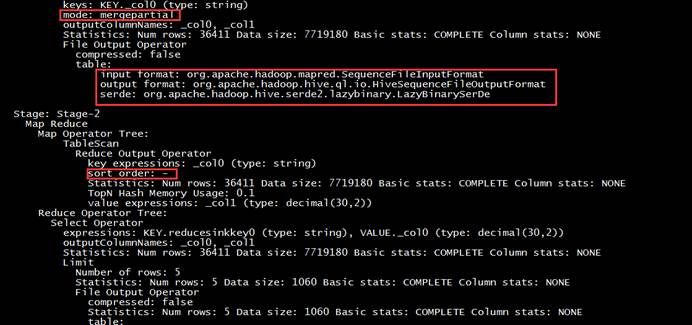
(3)Group By Operator:分组聚合操作,常见的属性:
Ø aggregations:显示聚合函数信息
Ø mode:聚合模式,值有hash:随机聚合,就是hash partition;partial:局部聚合;final:最终聚合
Ø keys:分组的字段,如果没有分组,则没有此字段
Ø outputColumnNames:聚合之后输出列名
Ø Statistics:表统计信息,包含分组聚合之后的数据条数,数据大小等
(4)Reduce Output Operator:输出到reduce操作,常见属性:
Ø sort order:值为空 不排序;值为 + 正序排序,值为 - 倒序排序;值为 ± 排序的列为两列,第一列为正序,第二列为倒序
(5)Filter Operator:过滤操作,常见的属性:
Ø predicate:过滤条件,如sql语句中的where id>=1,则此处显示(id >= 1)
(6)Map Join Operator:join 操作,常见的属性:
Ø condition map:join方式 ,如Inner Join 0 to 1 Left Outer Join 0 to 2
Ø keys: join 的条件字段
Ø outputColumnNames: join 完成之后输出的字段
Ø Statistics: join 完成之后生成的数据条数,大小等
(7)File Output Operator:文件输出操作,常见的属性:
Ø compressed:是否压缩
Ø table:表的信息,包含输入输出文件格式化方式,序列化方式等
(8)Fetch Operator:客户端获取数据操作,常见的属性:
Ø limit,值为 -1 表示不限制条数,其他值为限制的条数
10.2 explain dependency
explain dependency的用法
**【功能说明】**explain dependency用于描述一段SQL需要的数据来源,输出是一个json格式的数据(该格式的数据可以在https://www.bejson.com/进行格式化查看),里面包含以下两个部分的内容:
Ø input_partitions:描述一段SQL依赖的数据来源表分区,里面存储的是分区名的列表,如果整段SQL包含的所有表都是非分区表,则显示为空。
Ø input_tables:描述一段SQL依赖的数据来源表,里面存储的是Hive表名的列表。
【非分区表依赖】 使用explain dependency查看SQL查询非分区普通表,在 hive cli 中输入以下命令:
代码示例:
explain dependency select product_id,count(1) num from olist_order_items_dataset group by product_id;
执行结果:

格式化一下输出结果:
{
"input_tables": [{
"tablename": "sh_hive@olist_order_items_dataset",
"tabletype": "MANAGED_TABLE"
}],
"input_partitions": []
}
【分区表依赖】 使用explain dependency查看SQL查询分区表,在 hive cli 中输入以下命令:
代码示例:student_part是分区表
explain dependency select user_year,count(1) num from student_part group by user_year;
执行结果:

格式化一下输出结果:
{
"input_tables": [{
"tablename": "sh_hive@student_part",
"tabletype": "MANAGED_TABLE"
}],
"input_partitions": [{
"partitionName": "sh_hive@student_part@user_year=1990/sex=male"
}, {
"partitionName": "sh_hive@student_part@user_year=1995/sex=female"
}, {
"partitionName": "sh_hive@student_part@user_year=1998/sex=male"
}, {
"partitionName": "sh_hive@student_part@user_year=1999/sex=male"
}, {
"partitionName": "sh_hive@student_part@user_year=2000/sex=female"
}, {
"partitionName": "sh_hive@student_part@user_year=2000/sex=male"
}, {
"partitionName": "sh_hive@student_part@user_year=2001/sex=female"
}, {
"partitionName": "sh_hive@student_part@user_year=2002/sex=male"
}]
}
explain dependency的使用场景
常见的使用场景
explain dependency的使用场景有两个:
场景一:快速排除。快速排除因为读取不到相应分区的数据而导致任务数据输出异常。例如,在一个以天分区的任务中,上游任务因为生产过程不可控因素出现异常或者空跑,导致下游任务引发异常。通过这种方式,可以快速查看SQL读取的分区是否出现异常。
场景二:理清表的输入。帮助理解程序的运行,特别是有助于理解有多重子查询,多表连接的依赖输入。
10.3 优化
10.3.1开启Fetch抓取(默认已开启)
【机制说明】:
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。
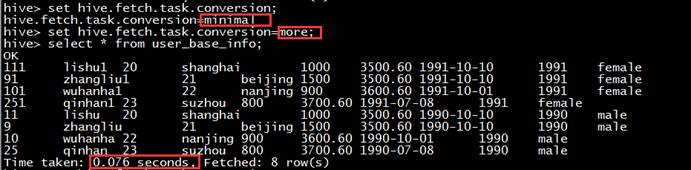
例如:select * from user_base_info;
在这种情况下,Hive可以简单地读取user_base_info对应的存储目录下的文件, 然后输出查询结果到控制台。
【参数设置】:
在hive-default.xml.template文件中 hive.fetch.task.conversion默认是 more或者minimal),在全局查找、字段查找、limit查找等都不走mapreduce。
但是把hive.fetch.task.conversion设置成none,然后执行查询语句,全局查找、字段查找、limit查找等都会执行mapreduce程序。
【执行结果】:很明显的可以看出,开启和关闭Fetch 抓取时查询时间差距达几百倍,并且关闭Fetch 抓取时查询启动了MapReduce工作。

10.3.2本地模式(默认未开启)
【机制说明】:
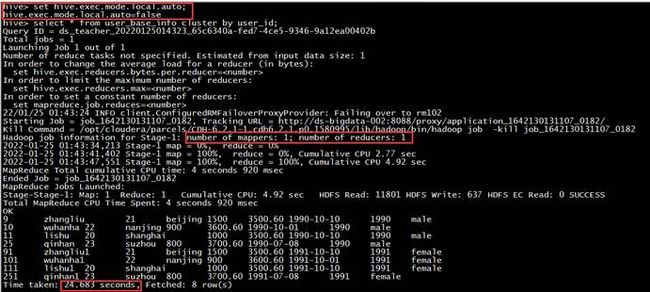
大多数的Hadoop Job是需要Hadoop提供的完整的可扩展性来处理大数据集的。不过有时Hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务时消耗可能会比实际job的执行时间要多的多。对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
用户可以通过设置hive.exec.mode.local.auto的值为true,来让Hive在适当的时候自动启动这个优化。
【参数设置】:
//开启本地 mr
set hive.exec.mode.local.auto=true;
//设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式,
默认为 134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;
//设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr 的方式,
默认为 4
set hive.exec.mode.local.auto.input.files.max=8;
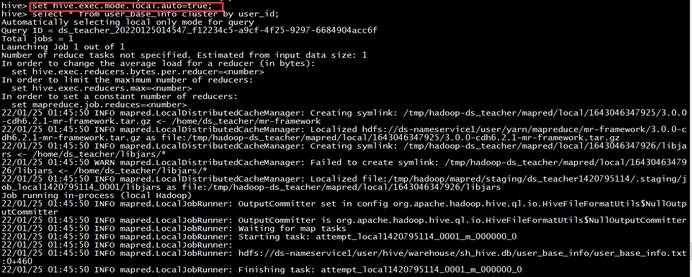
【执行结果】:开启和关闭本地模式对比如下:

10.3.3表的优化
小表Join大表:
将 key 相对分散,并且数据量小的表放在 join 的左边,这样可以有效减少内存溢出错误发生的几率;再进一步,可以使用 Group 让小的维度表(1000 条以下的记录条数)先进内存,在map 端完成 reduce。
新版的 hive( hive 0.11.0之后)已经对小表JOIN大表和大表JOIN小表进行了优化。小表放在左边和右边已经没有明显区别。
此外,需要注意的是Join小表默认进内存的大小为25M,可以通过修改hive.mapjoin.smalltable.filesize=2500000配置,改变默认大小,但一般修改最大值不能超过128M,这个值刚好是MapReduce分块的最小单元,也是HDFS一个块的默认大小。
大表Join大表:
- 空KEY过滤
有时 join 超时是因为某些 key 对应的数据太多, 而相同 key 对应的数据都会发送到相同的reducer上,从而导致内存不够。此时我们应该仔细分析这些异常的 key,很多情况下,这些 key 对应的数据是异常数据,我们需要在 SQL 语句中进行过滤。
此外,在大多数业务中,除了要对null key 过滤,有时也会对key值为0的情况下进行过滤。事实上,就是过滤掉非法的或者异常的、无效的或者无意义的key值。
- 空key转换
有时虽然某个 key 为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在 join 的结果中,此时我们可以表 a 中 key 为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的 reducer 上。
#设置 5 个 reduce 个数
set mapreduce.job.reduces = 5;
#JOIN 两张表
select n.* from nullidtable n left join ori o on case when n.id is null then concat('hive', rand()) else n.id end = o.id;
10.3.4 MapJoin(默认已开启)
如果不指定 MapJoin 或者不符合 MapJoin 的条件,那么 Hive 解析器会将 Join操作转换成Common Join,即:在 Reduce 阶段完成 join。容易发生数据倾斜。可以用 MapJoin 把小表全部加载到内存在 map 端进行 join,避免 reducer 处理。
1.开启MapJoin 参数设置:
#设置自动选择 Mapjoin
set hive.auto.convert.join = true; 默认为 true
\#大表小表的阀值设置(默认25M 以下认为是小表)
set hive.mapjoin.smalltable.filesize=25000000;
可根据实际情况来调整小表的阈值设置,以控制触发 MapJoin。但一般修改最大值不能超过128M,这个值刚好是MapReduce分块的最小单元,也是HDFS一个块的默认大小。
2.MapJoin工作机制:
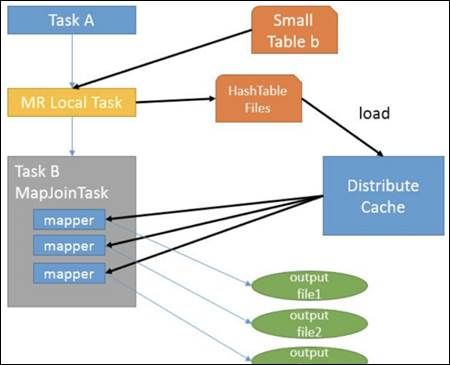
首先是 Task A,它是一个Local Task(在客户端本地执行的 Task),负责扫描小表b的数据,将其转换成一个HashTable的数据结构,并写入本地的文件中,之后将该文件加载到 DistributeCache中。
接下来是Task B,该任务是一个没Reduce的MR, 启动MapTasks扫描大表 a,在 Map阶段,根据a的每一条记录去和 DistributeCache 中 b 表对应的HashTable 关联,并直接输出结果。
由于MapJoin没有Reduce,所以由Map直接输出结果文件,有多少个 MapTask,就有多少个结果文件。
10.3.5 Group By优化
默认情况下,Map 阶段同一Key 数据分发给一个reduce,当一个 key 数据过大时就会产生数据倾斜。但在数据计算时,并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。
#是否在 Map 端进行聚合, 默认为 **True**
set hive.map.aggr = true;
# 在 Map 端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000;
#有数据倾斜的时候进行负载均衡(默认是 **false**)
set hive.groupby.skewindata = true;
当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job中,Map 的输出结果会随机分布到Reduce中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照Group By Key 分布到Reduce中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
10.3.6 Count(Distinct)去重统计
数据量小的时候无所谓,数据量大的情况下,由于 COUNT DISTINCT 操作需要用一个Reduce Task 来完成,这一个Reduce 需要处理的数据量太大,就会导致整个Job很难完成,一般 COUNT DISTINCT使用先GROUP BY再COUNT的方式替换。
#直接去重
select count(distinct id) from bigtable;
#改写后去重
select count(id) from (select id from bigtable group by id) a;
虽然会多用一个Job来完成,但在数据量大的情况下,group by 依旧是去重的一个优化手段。如果说需要统计的字段有Null 值,最后只需要null值单独处理后union即可。
10.3.7 笛卡尔积
尽量避免笛卡尔积,join 的时候不加on条件,或者无效的on条件都有可能会产生笛卡尔积。Hive 只能使用1个reducer来完成笛卡尔积,会导致计算性能较低。
10.3.8 行列过滤
列处理:
在SELECT中,只拿需要的列,如果有,尽量使用分区过滤,少用SELECT *。
行处理:
在分区剪裁中, 当使用外关联时, 如果将副表的过滤条件写在 Where后面, 那么就会先全表关联,之后再过滤。
10.3.9 动态分区调整
关系型数据库中, 对分区表 Insert 数据时候,数据库自动会根据分区字段的值,将数据插入到相应的分区中,Hive 中也提供了类似的机制,即动态分区(Dynamic Partition),只不过使用Hive的动态分区,需要进行相应的配置。
#开启动态分区功能(默认 **true**, 开启)
hive.exec.dynamic.partition=true
#设置为非严格模式(动态分区的模式默认strict,表示必须指定至少一个分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区。)
hive.exec.dynamic.partition.mode=nonstrict
#在所有执行MR的节点上,最大一共可以创建多少个动态分区。
hive.exec.max.dynamic.partitions=1000
# 在每个执行 MR 的节点上, 最大可以创建多少个动态分区。该参数需要根据实际的数据来设定。
比如:源数据中包含了一年的数据,即day字段有365个值,那么该参数就需要设置成大于365,
如果使用默认值 100,则会报错。
hive.exec.max.dynamic.partitions.pernode=100
#整个MR Job中,最大可以创建多少个HDFS 文件。
hive.exec.max.created.files=100000
#当有空分区生成时, 是否抛出异常。 一般不需要设置。
hive.error.on.empty.partition=false
11 数据倾斜问题(☆☆☆重点掌握)
11.1数据倾斜的现象
有的时候,我们可能会遇到大数据计算中一个最棘手的问题——数据倾斜,此时作业的性能会比期望差很多。数据倾斜调优,就是使用各种技术方案解决不同类型的数据倾斜问题,以保证作业的性能。
数据倾斜的现象就是:
绝大多数task执行得都非常快,但个别task执行极慢。比如,总共有1000个task,997个task都在1分钟之内执行完了,但是剩余两三个task却要一两个小时,这种情况很常见。进入任务的执行界面:reduce阶段卡在99.99%不动;各种container报错OOM(内存溢出);读写数据量很大,超过其他正常reduce。
11.2数据倾斜的原理
数据倾斜的原理很简单:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作。此时如果某个key对应的数据量特别大的话,就会发生数据倾斜。比如大部分key对应10条数据,但是个别key却对应了100万条数据,那么大部分task可能就只会分配到10条数据,然后1秒钟就运行完了;但是个别task可能分配到了100万数据,要运行一两个小时。因此,整个作业的运行进度是由运行时间最长的那个task决定的。
发生数据倾斜的原因在于Task的数据分配不均衡。分为两种情况:数据本身就是倾斜的,数据中某种数据出现的次数过多;分区规则导致这些相同的数据都分配给了同一个Task,导致这个Task拿到了大量的数据,而其他Task数据量比较少,所以运行起来较慢。
11.3数据倾斜的处理
11.3.1 group by产生数据倾斜
【场景描述】:使用 Hive 对数据做一些类型统计的时候遇到过某种类型的数据量特别多,而其他类型数据的数据量特别少。当按照类型进行group by的时候,会将相同的group by 字段的reduce任务需要的数据拉取到同一个节点进行聚合, 而当其中每一组的数据量过大时,会出现其他组的计算已经完成而这里还没计算完成, 其他节点的一直等待这个节点的任务执行完成, 所以会看到一直map 100%和reduce99%的情况。
【解决方法】:
(1)开启 Map 端聚合参数设置(详见上文Group By)。
(2)或者根据业务,合理调整分组维度。
11.3.2 count(distinct)产生数据倾斜
【场景描述】:如果数据量非常大,执行如select a,count(distinct b) from t group by a;类型的SQL 时,会出现数据倾斜的问题。
【解决方法】:
(1)使用 sum…group by 代替。如select a,sum(1) from (select a, b from t group by a,b) group by a;(详见上文Count(Distinct)去重统计)
(2)在业务逻辑优化效果的不大情况下,有些时候是可以将倾斜的数据单独拿出来处理,最后union回去。
11.3.3大表和小表 join产生数据倾斜
【场景描述】:当遇到一个大表和一个小表进行join操作时。
【解决方法】:使用 mapjoin 将小表加载到内存中。(详见上文小表 join 大表)
11.3.4 空值产生数据倾斜
【场景描述】: 遇到需要进行 join 的但是关联字段有数据为空。如日志中,常会有信息丢失的问题,比如日志中的user_id,如果取其中的user_id和用户表中的user_id 关联,会碰到数据倾斜的问题。数据量大时也会产生数据倾斜,如表一的 id 需要和表二的 id 进行关联。
【解决方法】:
(1) id 为空的不参与关联:
select * from log a join users b
on a.user_id is not null and a.user_id = b.user_id
union all
select * from log a where a.user_id is null;
(2) 给空值分配随机的key值:
select * from log a left outer join users b
on case when a.user_id is null then
concat('hive',rand() ) else a.user_id end = b.user_id;
一般分配随机 key 值得方法更好一些。
11.3.5 合理设置map和reduce数避免数据倾斜
【调整Map****数】
1.小文件进行合并,减少map数(默认开启)
在 map 执行前合并小文件,减少 map 数:
set hive.input.format= org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
注意: CombineHiveInputFormat具有对小文件进行合并的功能(系统默认的格式)。但是HiveInputFormat 没有对小文件合并功能。
2.复杂文件增加Map数
当input的文件都很大,任务逻辑复杂,map执行非常慢的时候,可以考虑增加 Map数,来使得每个map处理的数据量减少,从而提高任务的执行效率。
MapReduce中没有办法直接控制 map 数量,可以通过设置每个map中处理的数据量进行设置。
#HDFS默认数据块大小128M、最小分片大小1、最大分片大小256M
set dfs.blocksize=134217728;
set mapreduce.input.fileinputformat.split.minsize=1;
set mapreduce.input.fileinputformat.split.maxsize=256000000;
增加map的方法为:根据公式,调整maxSize最大值:
computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M
让maxSize 最大值低于 blocksize 就可以增加 map 的个数。
【调整Reduce数】
调整 reduce 个数方法一:
#每个 Reduce 处理的数据量默认是 256MB
hive.exec.reducers.bytes.per.reducer=256000000
#每个任务最大的 reduce 数,默认为 1009
hive.exec.reducers.max=1009
#计算 reducer 数的公式:
N=min(hive.exec.reducers.max,总输入数据量/hive.exec.reducers.bytes.per.reducer)
调整 reduce 个数方法二:
#在hadoop的mapred-default.xml文件中修改设置每个job的Reduce个数
set mapreduce.job.reduces = 15;