内存一致性模型笔记 (Memory Consistency Model)
参考文档:
[1] Multiprocessors should support simple memory consistency models
[2] Shared Memory Consistency Models: A Tutorial
一、什么是内存模型?
内存模型 (memory model),也叫内存一致性模型 (memory consistency model),它可以简单的理解为一系列对内存读写操作的规定,包括针对内存读写操作的重排序规则、可见性规则(一次读操作能否看到最近一次写入的结果?)等等。根据内存模型包含的一系列规定,我们可以推断出内存操作的结果,例如:
- 对于一次内存读操作,它读到的是哪个值?
- 一个内存读写操作会不会和其他内存读写操作发生重排序?
- 等等
看一个具体的例子,对于下面的代码,初始时A=0,B=0,两个线程并发执行,有没有可能打印出0?
// 线程 1
A = 1;
B = 1;
// 线程 2
while (B == 0);
print(A);
根据内存模型,我们可以推断出最终打印出的是多少:
- 假如内存模型明确告诉我们了,不会发生
store/store和load/load重排序,那么最终打印出来的结果一定是1; - 而如果内存模型允许
store/store和load/load重排序,那么最终打印出来的可能是0,也可能是1。
所以说,内存模型其实是一种抽象 (abstraction)。抽象这个概念在计算机领域内应用可以说是极为广泛了,抽象可以向我们屏蔽底层复杂的细节。例如,汇编语言对机器代码进行了抽象,使得我们不需要自己编写0101...的二进制来操纵计算机;高级语言又对汇编代码进行了抽象,使得我们可以更高效的编写代码,等等等等。
以硬件级别的内存模型为例,它实际上是对底层硬件内存系统的抽象,有了内存模型,我们不需要了解底层的物理内存、cache和处理器到底怎么工作的,我们只需要参照内存模型的规定,就能知道两个内存操作指令会被会发生重排序,我这次读内存操作得到的值可能是多少,等等。
为什么这里特别强调硬件级别的内存模型呢? 下文会看到,内存模型分为软件级别的和硬件级别的
二、内存模型的分类
参考 [2]
内存模型可以分为软件层面的内存模型和硬件层面的内存模型。正如第一小节介绍的那样,它们其实都是一系列对于内存读写操作的规定,根据它们可以推测内存读写操作的结果。
1. 软件层面的内存模型
软件层面的内存模型最为人熟知的应该就是 Java内存模型(JMM) 了。JMM本质上是在硬件内存模型之上又做了一层抽象,使得Java程序员只需要了解JMM就可以编写出正确的并发代码,而无需过多了解硬件层面的内存模型。下面是JMM和硬件层面的存储系统的对应:
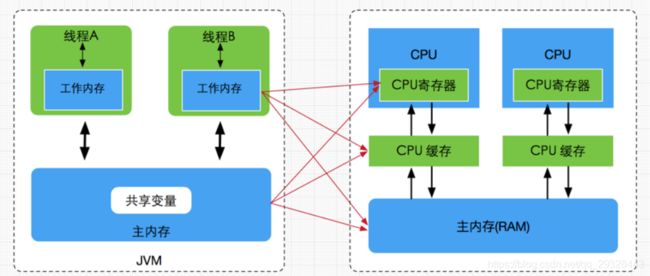
可以看到,JMM中的工作内存、主内存其实都是对硬件级别的寄存器、缓存、主存的抽象。
2. 硬件层面的内存模型
硬件层面的内存模型则是直接建立在硬件存储系统(内存、缓存、寄存器) 上的抽象。
系统软件等一些底层的软件会用到硬件层面的内存模型,例如编译器、设备驱动、操作系统等等。
举个例子,我们使用汇编语言进行编程就需要了解硬件层面的内存模型,因为汇编语言没有提供软件级别的内存模型抽象。
3. 总结
这两种内存模型的关系如下图所示,其中横线表示内存模型(或者说内存模型提供的抽象):
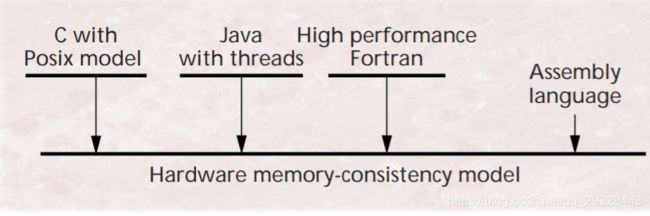
总结起来就是,软件层面的内存模型建立在硬件层面的内存模型之上,硬件层面的内存模型又是对硬件存储系统的抽象。
三、理解内存模型带来的影响
参考 [2] “Memory Consistency Models - Who Should Care?”
内存模型这层抽象对它的上层和下层都有影响,对可移植性也有影响。
以软件层面的内存模型JMM为例,它不仅影响了Java程序的编写者(JMM这层抽象之上),也会影响Java编译器的设计者(JMM这层抽象之下),编译器设计者应该确保编译器对指令的重排序等操作不会违反JMM规定。
同样,对于硬件层面的内存模型,它不仅对其上层的系统程序的编写者有影响,也会对其下层的硬件设计者有影响。同样也会影响程序的可移植性,例如把一个遵循强内存模型机器上编写的程序移植到一个弱内存模型的机器上,结果可能会出错。
四、常见的内存模型
本节将讨论硬件层面的内存模型,对于软件层面的内存模型不做讨论。
1. 顺序一致性内存模型 (Sequential Consistency, SC)
顺序一致性模型最初由Lamport针对多处理器系统定义:
- the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and
- the operations of each individual processor were to appear in this sequence in the order specified by its program.
对于定义中的operation究竟指的是何种操作,Lamport没给出定义。如果将顺序一致性的定义运用于内存模型,则顺序一致性的定义如下,参考[2] “4. Understanding Sequential Consistency”:
(1) 所有处理器核心对于内存的读写操作的最终结果和某种按顺序执行的结果一样
(2) 一个处理器核心上(或者说一个线程中)的内存读写操作的最终结果和按程序声明的顺序 (program order) 执行的结果一样。
要实现(1),就必须要求内存操作看起来像是原子的 (atomically),参考[2] “4. Understanding Sequential Consistency”。
上述顺序一致性的定义中,只要求最终结果和“按照xxx顺序”执行的一样,并不是说处理器一定得“按照xxx顺序”依次执行指令,只要最终结果一样就符合顺序一致性模型。
结合上一小节来理解,对于SC模型之上的程序员来讲,他看到的内存操作是顺序一致的,无须考虑硬件层面可能采取的优化措施,他可以简单地认为指令就是按照程序顺序原子执行的(可能硬件层面并非是这样执行);但是对于SC模型之下的硬件设计者,由于只要求最终结果一样,因此可以采取适当的优化措施,例如指令重排序等等,只要确保最终结果符合顺序一致的标准即可。
额外补充一点,顺序一致性定义中 (1) 的 “按顺序执行”是什么意思呢,请看下面的图:
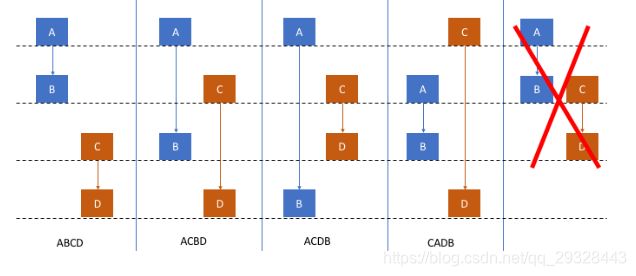
假设有两个线程T1和T2,T1在代码中依次定义了A、B两个内存操作,T2依次定义了C、D两个内存操作,所谓 “按顺序执行” 的意思就是:
- 单看T1或T2的执行流不能发生内存操作的重排序。即T1中A必须在B之前完成,T2中C必须在D之前完成。⚠️ 注意:这里说的是完成,而非开始执行。
- 线程T1和T2之间的操作不可能同时发生。上面也说了,顺序一致性内存模型要求内存操作都是原子的,自然也不可能同时发生。
顺序一致性模型给程序员的视角
顺序一致性内存模型呈现给程序员的抽象视图如下:
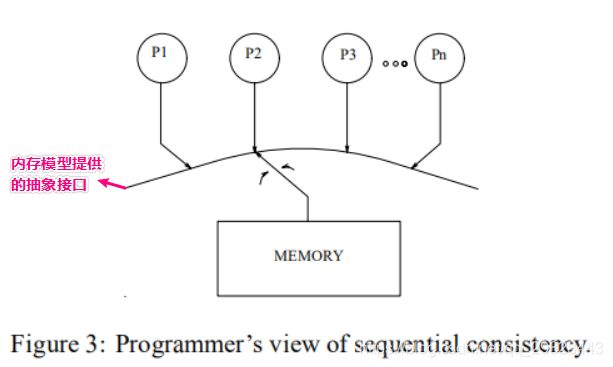
如图所示,内存和处理器之间有一层内存模型提供的抽象接口,这层接口就像一个“多口开关”,每次只能拨给一个处理器,原子的处理该处理器上的一个内存操作,可以按照任意的顺序在各个处理器之间拨来拨去;每个处理器按顺序发射 (issue) 指令。
⚠️ 这只是顺序一致性模型提供给程序员的抽象视图,程序员可以认为内存操作是原子的,且是按程序顺序执行的,但是对于硬件层面来说,不一定非得原子的、按程序顺序的执行指令。
顺序一致性模型的优缺点分析
显然,顺序一致性模型的优点就是对程序员很友好,因为根据顺序一致性,程序员可以很容易的推测出自己程序的执行结果。
但是,顺序一致性对于硬件设计者就不那么友好了,它限制了store buffer等优化措施的使用,从而限制了程序在硬件上执行所能获取的性能。
因此,为了获取更高的程序执行性能,现代计算机往往都不采用顺序一致性内存模型,而是使用放松的内存一致性模型 (Relaxed Memory Model),这些模型相对于顺序一致性模型的要求做了一些放松,对硬件设计者更加友好,使得硬件设计者可以采取更多的优化措施 (重排序、store buffer等等),提升程序的执行性能;但是另一方面,对于软件程序员就不像顺序一致性模型那么友好了,程序员推断程序的执行结果变得有点困难,有时候还需要手动采用内存屏障等策略来确保得到自己想要的结果。
2. 放松的内存一致性模型 (Relaxed Memory Model)
阅读本小节之前,需要对cache相关的知识有所了解,包括缓存一致性、store buffer、store bypassing (store forwarding) 等概念有所理解,可以参考 Memory Barriers: a Hardware View for Software Hackers。
所谓放松的一致性模型,正如上一小节所说,就是对顺序一致性模型中的某些条件进行了放松。根据放松的条件不同,又有不同的分类。本文将介绍最常见的一种放松的内存模型——允许发生StoreLoad重排序的内存模型。
这种放松的内存模型允许StoreLoad重排序,那么硬件设计者如何利用这个放松了的条件来获取更快的执行速度呢?
答案就是store buffer。store buffer是一个先进先出的缓冲,位于CPU核心和Cache之间,用于缓存内存写操作。

在顺序一致性模型中,要求一个处理器上对变量的修改,能被其他处理器上后续的读操作看到。对于一个存在Cache和缓存一致性协议的计算机来说,这就意味着一个处理器在写变量之前,必须先在总线上发送通知,通知其他处理器将自己对应的副本置为失效,在收到其他处理器的完成置为失效操作的确认之后,该处理器才能执行写操作。这一操作的开销是比较大的。
而在允许StoreLoad重排序的系统中,由于我们有store buffer,所以可以把写操作缓存在store buffer,等到特定的时机再将store buffer多条内容一并刷新到cache或主存,并通知其他处理器将副本置为失效,从而整体上减少了内存写操作带来的延迟,提高了速度和性能。
硬件设计者是爽了,提升了内存操作的速度,但是这却给软件程序员带来一个问题,就是一个处理器上对变量的修改其他处理器上不是立即可见的,因为。为了解决这个问题,需要程序员显式地加上内存屏障等指令来保证可见性。
既然其他处理器不能立马看到当前处理器的修改,那么当前处理器能看到自己的修改吗?例如 x = 1; print(x)打印出来的会是 1 吗?
这个问题的答案取决于具体的硬件实现,不过在当前主流的处理器中,都可以看到自己做出的修改,正如上面的图所示,处理器核心可以同时看到store buffer和cache中的内容,所以处理器核心是可以看到缓存在当前处理器store buffer中的写操作的 (这一技术被叫做 store bypassing 或 store forwarding)。
允许StoreLoad重排序的常见内存模型有:
- Wisconsin/Stanford的Processor Consistency模型
- IBM 370 模型
- Total Store Order (TSO) 模型 ⭐️ (x86计算机使用的就是TSO模型)
这些内存模型在具体实现上稍有不同,例如处理器P1对变量x作出了修改,并缓存在store buffer中,那么当处理器P1读取x的新值的时候,是不是也确保其他处理器也能看到新值。
这些内存模型都有提供一个额外的特性——causality(参考 [1] )。假设有4个处理器,P1, P2, P3, P4,x初始值为0。如果处理器P1修改了变量x=1,causality确保了只要P2, P3, P4中一个看到x=1,其他的处理器也都能看到x=1,不会说有的看到x=0,有的看到x=1。
放松的内存模型总结
主要介绍了允许StoreLoad重排序的内存模型,该模型用store buffer实现,可使用store bypassing来确保当前处理器可以看到自己的修改,具有causality特性。
x86平台采用的TSO模型就属于该类模型。
更多不同处理器支持的重排序可以参考 https://en.wikipedia.org/wiki/Memory_ordering 中的表格。